
地区差异城市群大气污染多维度数据采集仿真
2022-04-18 10:00:58姜志奇王习东
计算机仿真 2022年3期
姜志奇,王习东
(北京大学工学院,北京 100000)
1 引言
通常情况下,大气污染是指由自然形成与人类活动作用形成的污染。自然环境本身造成的污染属于自然污染,人类对环境作用形成的污染属于人为污染源[1-2]。其中,人为污染源能够划分成两种不同的形式,分别为:①不可移动污染源;②非固定污染源。人为污染源与自然污染源之间存在一定差异,前者具有普遍性以及规律性,所以日益受到人们的关注。
近几年以来,我国环境污染问题日益严峻引起人们极大关注,其中最为严重的就是大气污染问题,它会对人类的生命安全产生威胁,同时由于烟尘污染也十分严重,人类的呼吸系统也遭受很大隐患。另外,我国的水污染、垃圾污染问题日益严重。我国属于拥有不少河流的陆地大国,但是我国百分之七十以上的河流中都存在污染问题,大部分的固体垃圾聚集在居民居住地附近,很大程度上降低了人类的生活质量。针对我国环境污染问题日益严重的现状,数据采集工作就变得十分重要,实时监测大气污染数据的运行状态,及时采取对应的防护措施是当前的首要工作。
为了有效解决环境污染问题,构建地区差异城市群大气污染多维度数据采集模型。引入决策树组织,结合定点采集监测数据分析地区差异城市群大气污染多维度数据,以此降低数据后续整合耗时。采用多维度采集数据库,计算不同污染气体的实际排放量,提升污染数据采集精度。通过具体的仿真数据全面验证了所设计模型的有效性以及实用性。
2 城市群大气污染多维度数据采集模型的构建
2.1 建立气象决策树
通过构成决策树来求取大气污染值的期望值大于等于零的概率,是评价项目风险,判断其可行性的决策分析方法。本文利用大气污染的大数据构建决策树。
由于决策树的组建过程与人为决策行为模型十分相似,因此需要设定一个数据集S,在不同的数据集中应包含多种不同的属性,需要采取对应的统计方法对属性A进行划分,将其划分成多个不同的子集。重复上述操作过程,直到获取特定的终止条件。
在大数据环境中,由于样本数量较大,同时存在其它问题,首先需要进行特征选择,既能有效避免无关特征产生的负面影响,还能够有效降低运行时间,提升最终采集结果的准确性[6]。在组建大数据气象决策树的过程中,需要选择对应的特征并简化模型,确保模型优势。
2.2 大气污染定点监测体系
在研究区域内,组建多个大气污染监测站。各个标准微环境监测站采集的参数主要包括空气温度、空气湿度等多项指标。监测站每隔5分钟采集一次数据,一天内采集288条数据,利用GPRS[7-8]网络或者北斗星报文的形式将数据传输至远程服务器,同时存储在对应的数据库中,具体如图1所示。

图1 地区差异城市群的大气质量监测体系
现阶段大气污染监测站在运行的过程中,存在能源耗尽等原因导致数据丢失的情况,不仅说明了大气污染监测站可能存在能源短缺的问题,需要减少大气污染监测站的能源消耗。而且在使用数据之前,需要对数据进行预处理。由于样本数据量较大,后续的数据处理过程十分复杂,因此需要选取对应的指标[9]作为研究对象,具体的操作过程如下所示:
1)导出全部的大气污染数据,通过监测点的不同设备号ID值,将全部数据进行划分处理。
2)将全部监测点的数据按照天数进行划分,同时设定样本为每天的大气污染监测数据,将全部样本按照列进行排列,组建一个数据集。
3)将全部的大气污染监测数据样本组建为样本集,同时对其进行列归一化处理[10],并且将其划分为测试样本集以及训练样本集。
2.3 城市群间的监测数据共享
为了实现城市群间大气污染监测数据的共享,需要做到以下两点:
1)实现数据库之间的转换;
2)实现数据的透明访问。
在进行数据库访问的过程中,不能废弃原始数据库,而是需要将其转换到新的系统中继续发挥作用,对资源进行再利用。从而实现在不同的数据库之间,也能够将源数据库中的数据转换到目的数据库中的目的。
在进行转换的过程中,实现严格的等价转换十分困难,首先需要确保模型中存在的冲突,具体如下所示:
1)命名冲突
源模型中的标识符号可能是目的模型中需要保留的部分,此时需要重新命名;
2)格式冲突
相同类型的数据可能存在不同形式的表示方法以及语义差异,此时需要定义不同模型之间的变换函数;
3)结构冲突
为了实现数据共享,服务器需要具有安全、稳定等特点,同时要求服务器具有负载均衡以及容错功能等优势,并支持热部署,即在不间断服务条件下能够对软件版本或者配置进行更新升级。
在实现纵向数据整合的过程中,还需要完成数据的横向整合,利用大数据共享平台实现跨部门数据共享,丰富横向数据库,为系统提供有力的数据支撑。
导致大气污染的因素众多,使得与大气污染情况关联的数据种类十分复杂,其中包含不同类型污染源[11]、空气可见度等气象数据。以上数据分别来源于政府不同部门,但是现阶段跨部门、跨领域整合存在信息交流阻塞以及数据整合分析不足等问题,很大程度上影响了大气污染的溯源、成因结构等分析。
组建数据共享、数据管理等功能集成的大型数据共享平台,能够有效促进大气污染相关数据高效流通,还能够实现数据的全面整合分析,最终提升大气污染监测的准确性以及治理决策的科学性。
2.4 基于污染气体排放量的大气污染数据多维度采集
本文主要采用GPS伪距差分定位方法组建对应的观测方程,通过序贯平方差方法获取双差模糊度浮点解;再利用双差模糊度浮点解有效提取大气中的延迟分量,并组建区域大气模型[12],利用流动站近似坐标计算获取流动站和与参考站之间的大气延迟改正;最后通过差分改正数改正参考站的观测值,进而获取求解单差观测方程,获取流动站坐标。
当数据采集到需要的全部数据上传至控制卡后,利用这些数据编写对应程序,在此过程中涉及到了数据库设计的问题。通过数据管理器为VB以及数据库链接提供的基本方法,能够有效帮助VB程序组建维护数据库,利用查询放置查找数据库中的相关信息,不必再通过其它的数据库软件进行数据库管理,通过以上操作能够有效实现多维度采集数据库的建立。
重点针对污染源的监测选取了二氧化硫减排的过程进行分析,其中降低二氧化硫的产生以及排放重点包括以下三种途径:
1)从源头上降低二氧化硫排放量
例如通过洗、选煤技术来降低炉煤硫分,用燃气发电代替燃煤电厂技术等。该方法在减污之前需要考虑前两种源头控制技术的应用,但是并没有考虑到循环流化床炉内脱硫技术对削污的贡献。
2)提升发电效率
有效降低原材料的消耗,提升资源利用效率,同时降低二氧化硫的产量。
3)利用烟气脱硫技术降低二氧化硫的排放量。
以下给出二氧化硫减排计算公式
Qb,y=ΔQgas+ΔQsar,y+ΔQGT,y+ΔQEPT,y+Qfinal
(1)
式中,Qb,y代表二氧化硫基准减排量;ΔQgas代表燃气发电减排量;ΔQsar,y代表硫分变化减排量;ΔQGT,y代表先进发电技术减排量;ΔQEPT,y代表烟气治理减排量;Qfinal代表最终的排放量。
基准产污量主要指不采取任何减排措施以及技术的情况下二氧化硫的产生量。基准产物量的计算公式可以表示为以下形式
Qb,y=Fb*Gy/100
(2)
式中,Fb代表基准技术单位发电量二氧化硫的减排绩效;Gy代表设定年限内的火力发电量。
燃气发电减排量的计算公式能够表示为以下的形式
ΔQgas=Ggas,y*Fb/100
(3)
式中,Ggas,y代表设定年限内的燃气发电量。
硫分变化减排量的计算公式为
ΔQsar,y=Gcoal,y*Fb*(1-Sy/Sbasic)/100
(4)
Gcoal,y=Gy-Ggas,y
(5)
先进发现技术减排量的计算式为
ΔQGT,y=Gcoal,y-ΔFb*(Sy/Sbasic)*(1-My/Mbasic)/100
(6)
烟气治理技术减排量的计算式为
ΔQEPT,y=(Qbasic-ΔQCPT,y)*ηy
(7)
在上述分析的基础上,组建地区差异城市群大气污染多维度数据采集模型:
1)模型自适应参数优化技术研究较长时间段内模型预测结果与实际历史气象测量数据之间的关联,准确得出模型预测误差的规律以及统计特征,进而实现模型参数的自适应优化,有效提升预测结果的准确性。
2)多模型集合预测技术:
将两个原本独立的模型进行整合,有效提升数值的预测能力,同时输出集合预测的最优结果。
通过组建的地区差异城市群大气污染多维度数据采集模型,能够实现数据采集,同时有效提升计算结果的准确性。
3 仿真研究
为了验证所提地区差异城市群大气污染多维度数据采集模型的综合有效性,需要进行仿真测试,实验环境:windows XP,SPI,CPU Pentium(R)4,基本频率2.4GHZ,软件平台为MatlabR2010a。
1)不同方法的数据整合时间对比
实验分别选取文献[4]、文献[5]中的传统采集模型作为对比模型,实验对比三种采集模型的数据整合时间,具体的实验对比结果如图2所示。

图2 不同采集模型的数据整合时间对比结果
分析图2中的实验数据可知,随着测试样本数量持续增加,各种采集模型的数据整合时间也在持续增加,但是相比传统的两种采集模型,所提模型的数据整合时间明显更快。
2)不同方法的采集成本对比
为了更进一步验证所提采集模型的有效性,以下需要对比三种采集模型的采集成本,具体的实验对比结果如下表所示。

表1 所提采集模型的采集成本

表2 文献[4]采集模型的采集成本

表3 文献[5]采集模型的采集成本
综合分析以上表格中的实验数据可知,所提采集模型的采集成本在三种模型中为最低;文献[4]采集模型的采集成本次之;文献[5]采集模型的采集成本最高。
3)不同方法数据采集相对误差对比
为了验证采集结果的准确性,实验选取相对误差作为评价指标,其中相对误差越低,则说明采集结果越准确,具体的实验对比结果如下表所示。
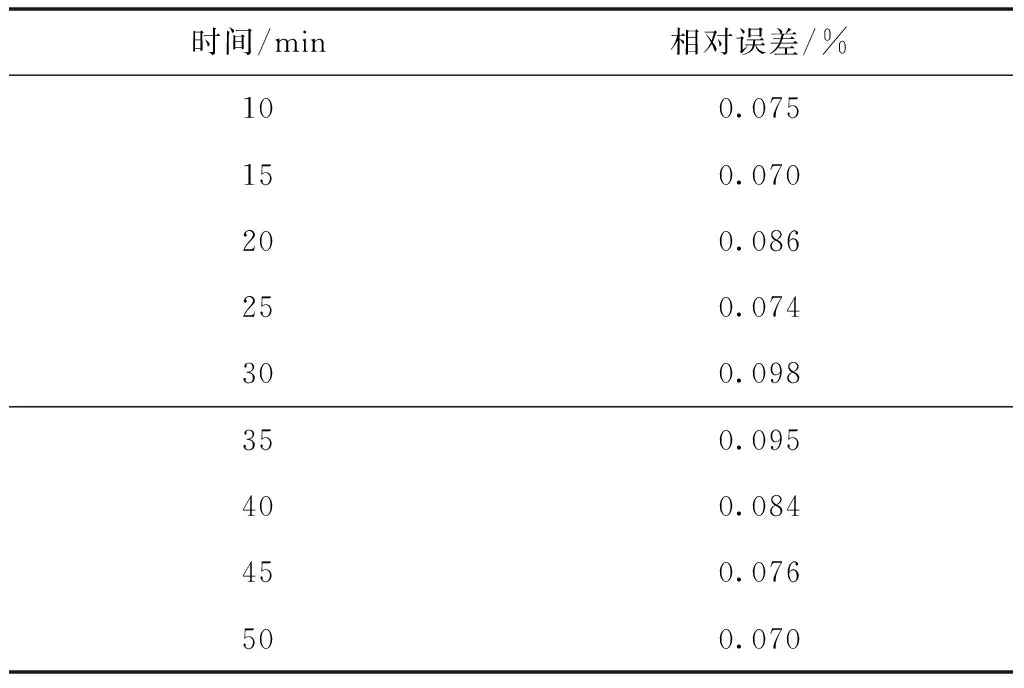
表4 所提采集模型的相对误差

表5 文献[4]采集模型的相对误差

表6 文献[5]采集模型的相对误差
综合分析上述表格中的实验数据可知,相比另外两种采集模型,所提采集模型的相对误差明显更低,这充分说明所提模型具有较高的采集精度。
4 结束语
1)针对传统的大气污染多维度数据采集模型存在数据整合时间较长、采集成本较高等问题,本文提出了地区差异城市群大气污染多维度数据采集模型。
2)实验结果显示:模型的数据整合时长不超过9.5min,模型的应用过程成本始终低于9000元人民币,比其余传统方法相比,该模型的可应用性更强。在误差实验中,模型表现出了在数据采集精度方面的优越性能。通过具体的实验数据有效验证了模型的可靠性。
3)但是本文还存在一定的不足,关于模型的时间局限性上后续将进一步丰富完善。
猜你喜欢
环境影响评价(2020年2期)2020-12-02 01:23:24
作文成功之路·小学版(2020年9期)2020-10-28 08:06:36
中成药(2018年1期)2018-02-02 07:20:31
环境保护与循环经济(2017年4期)2018-01-22 03:27:18
中国资源综合利用(2017年4期)2018-01-22 02:46:45
中成药(2017年8期)2017-11-22 03:19:01
商周刊(2017年7期)2017-08-22 03:36:22
中学生数理化·八年级物理人教版(2017年12期)2017-04-18 12:59:46
中学化学(2017年2期)2017-04-01 13:09:03
中国资源综合利用(2016年3期)2016-01-22 07:28:16
