
基于稀疏系统辨识的广义递归核风险敏感算法
2022-04-15 06:54王代丽王世元张涛齐乐天
西南大学学报(自然科学版) 2022年4期
王代丽,王世元,张涛,齐乐天
西南大学 电子信息工程学院/非线性电路与智能信息处理重庆市重点实验室,重庆 400715
自适应滤波是统计信号处理的重要组成部分,而稀疏自适应滤波是自适应滤波领域中不可或缺的部分,其显著特征是脉冲响应的大部分分量是零或者接近于零.在实际场景中,存在大量的稀疏系统,例如数字电视传输通道[1]、回波路径[2]、信道估计[3]等.由于稀疏系统通常是不确定的,因此需采用基于稀疏系统的自适应滤波算法对其进行辨识[4-5].
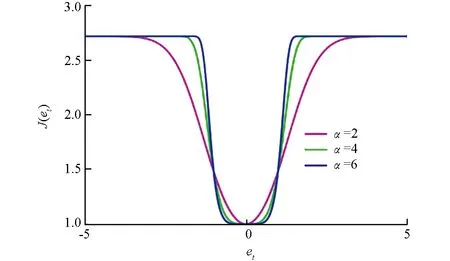
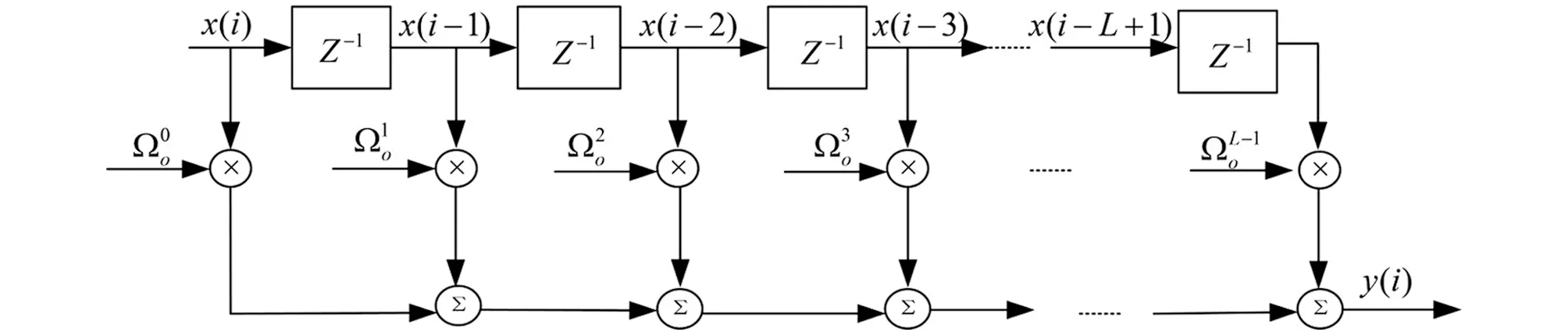
应用在稀疏系统中的自适应滤波算法通常采用与稀疏性相关的范数作为稀疏惩罚约束项(Sparse Penalty Constraint,SPC)[6-7],如l1范数,lp范数和l0范数,其中基于l1范数的最小均方自适应滤波算法包括零吸引最小均方(Zero-attracting Least Mean Square,ZA-LMS)算法[8]和加权零吸引最小均方(Reweighted Zero-attracting Least Mean Square,RZA-LMS)算法[9]等,但是ZA-LMS和RZA-LMS的收敛速率较慢,因此,为了提高收敛速率提出了基于零吸引的递归最小二乘(Zero-attracting Recursive Least Squares,ZA-RLS)算法[10].通常由于l1范数存在零点处的非光滑性的缺点,会导致算法性能降低,因此,引入lp范数作为SPC提高稀疏系统的滤波精度,进而提出了基于平方根变步长lp范数的LMS算法[11],以变步长的形式分析了稀疏系统中稳态均方误差和收敛速率之间的关系.通常最小任何lp范数(0 因为非高斯噪声在自然界中是普遍存在的,所以高斯噪声环境下的稀疏算法在非高斯噪声环境下会产生性能不稳定或退化等问题.从信息理论学习(Information Theoretic Learning,ITL)[14]的观点出发,为解决非高斯噪声对算法性能的影响,提出了广义相关熵(Generalized Correntropic,GC)准则.GC准则本质上是定义在特征空间中相似性度量的一种方法,利用数据的高阶统计特性消除非高斯噪声,其在自适应滤波中最经典的应用是广义相关熵损失(Generalized Correntropic Loss,GC-Loss)算法[15].而在稀疏系统中,利用广义最大相关熵准则(Generalized Maximum Correntropy Criterion,GMCC),同时采用CIM作为稀疏惩罚约束项进而提出了具有稀疏惩罚约束的递归广义最大相关熵(Recursive Generalized Maximum Correntropy Criterion with Sparse Penalty Constraint,RGMCC-SPC)算法[16],该算法在CIMMCC算法基础上采用广义递归的更新方式提高了收敛速率和滤波精度.为了进一步解决RGMCC-SPC算法中非零均值误差在零处误差识别精度较差的问题,提出了可变中心的RGMCC-SPC(Variable Center RGMCC-SPC,RGMCCVC-SPC)算法[17].然而由于GC-Loss的性能表面具有高度非凸的特性,导致算法的收敛性能较差.为了解决这个问题,引入定义在特征空间的核风险敏感损失(Kernel Risk-Sensitive Loss,KRSL)函数[18],使其在非高斯噪声中的性能优于GC-Loss. 启发于KRSL和GMCC,本文提出了一种新的应用在稀疏系统下的广义自适应滤波算法,该算法以广义高斯密度(Generalized Gaussian Density,GGD)[19]函数作为KRSL函数中的核函数,结合稀疏惩罚约束项,以递归的方式进行更新,进而为稀疏系统辨识设计出具有稀疏惩罚约束项的广义递归核风险敏感损失(Generalized Recursive Kernel Risk-Sensitive Loss with Sparse Penalty Constraint,GRKRSL-SPC)算法.所提出的GRKRSL-SPC算法利用了特征空间中映射数据非二阶统计量的特征,以指数形式强调较大误差的相似性,使得算法在非高斯噪声环境下,能够同时具有强鲁棒性和高滤波精度的特性. 本节在核风险敏感损失函数和广义核风险敏感损失函数的基础上,提出了最小化广义核风险敏感损失函数准则. 核风险敏感损失函数是指定义在核空间中两个随机变量X和Y的相似度测量,其表达式如下所示: (1) 其中λ>0是风险敏感参数,E表示期望符号,FXY(x,y)表示关于随机变量X和Y的联合分布函数,kσ(·)是指带宽为σ的Mercer核.其表达式为 (2) 本质上,公式(1)表示核风险敏感损失函数的指数形式只包含二阶统计量,实际上,不同阶的统计量在实际应用中更为普遍.因此,可以利用广义高斯密度函数作为核风险敏感损失函数的核函数并以此设计广义核风险敏感损失函数. 给定如下具有零均值的广义高斯密度函数[19]: (3) 其中,Γ(·)表示伽马函数,b>0是带宽,α>0是形状参数,β=1/bα表示核参数.从公式(3)可以看出广义高斯密度具有普适性.当α=1时,广义高斯密度为拉普拉斯分布; 当α=2时,则为高斯分布; 而当α→∞时,则为均匀分布.根据文献[15],定义广义相关熵损失函数的表达式为 (4) 结合公式(1)和公式(4),可得广义核风险敏感损失函数的表达式为 (5) 其中,当0<α≤2时,Gα,b(·)表示为Mercer核,所以在此范围内,广义核风险敏感损失函数可用传统风险敏感损失函数的类似形式重新表示为 (6) (7) 根据式(5)和式(7),关于广义核风险敏感损失函数的重要性质如下: 1)JG(X,Y)是对称、正定、有界的. 2)JG(X,Y)是具有广义特性的损失函数,在特定情况下可以转换为核风险敏感损失函数、广义熵损失函数和均值P幂误差[20]. 证黑塞矩阵如下: (8) 给定一个数学模型,如下所示: (9) (10) 通过最小化公式(10)可以获得广义核风险敏感损失函数的最优解,称之为最小化广义核风险敏感损失函数准则,其表达式如下: (11) 图1 不同α对 GKRSL误差的影响 最后,图1显示了不同α下对广义核风险敏感损失函数曲线平滑度的影响.从图中可以看出:当误差较小且α值越大时表面越光滑,表明广义核风险敏感损失函数的精度高于非广义形式. 这一小节主要介绍近似l0范数的稀疏惩罚约束项.实际上,在寻找最优稀疏项时需要最小化l0范数,而这是一个NP难问题.通常采用近似l0范数的方法来解决,一种是将其转化为无约束的l1范数正则化问题,可获得近似l0范数的解,但代价是增加采样过程中的测量次数[22]; 另一种则是采用CIM来近似l0范数,减少了测量中的计算消耗[12],其表达式如下: (12) (13) 定义如下带有稀疏惩罚约束项的广义核风险敏感损失函数为成本函数: (14) 其中,μ表示遗忘因子,ρh(i)代表稀疏惩罚约束项,ρ>0是控制权重向量的稀疏惩罚约束程度的正则化参数.采用梯度下降法最小化该成本函数,可得: (15) 其中, M(i)=exp(λ(1-exp(-β|e(i)|α)))exp(-β|e(i)|α)|e(i)|α-2 令公式(15)的梯度等于0可得权重Ω的解为 (16) 根据公式(16),定义Υ(i)和Θ(i)为 (17) 根据公式(17)将公式(16)改写为矩阵形式,其权向量可以表示为 Ω(i)=Θ-1(i)(Υ(i)-ρh′(i)) (18) Θ(i)通过递归形式进行更新可得: (19) 为了避免计算矩阵的逆运算,根据矩阵求逆引理[25]:(A+BCD)-1=A-1-A-1B(C-1+DA-1B)-1DA-1. 在公式(19)中令A=μΘ(i-1),B=X(i),C=M(i),D=XT(i),可得: (20) P(i)=μ-1(P(i-1)-M(i)G(i)XT(i)P(i-1)) (21) 所以 采用同样的方法可以得到下列表达式: Υ(i)=μΥ(i-1)+M(i)X(i)d(i) (22) 将公式(22)两端同时减去ρh′(i),可得: (23) 当迭代至算法性能稳定时,权向量几乎无变化.即当i→∞时,有h′(i-1)≈h′(i).所以公式(23)成立. 将公式(21)和(23)代入公式(18)可得权重向量更新式为 Ω(i)=Ω(i-1)+G(i)M(i)e(i)-ρμ-1(1-μ)[I-M(i)G(i)XT(i)]P(i-1)h′(i) (24) 最后,根据上述的推导过程,总结GRKRSL-SPC算法如表1所示. 表1 GRKRSL-SPC算法更新过程 本节分析GRKRSL-SPC算法的计算复杂度,这里考虑每次迭代过程中的加法、除法以及乘法次数.以α=4为例,各种算法的计算复杂度比较如表2所示,其中,D表示输入数据的长度,比较算法为基于稀疏惩罚约束的递归广义最大相关熵(RecursiveGeneralizedMaximumCorrentropyCriterionwithSPC,RGMCC-SPC)算法[16]和基于稀疏惩罚约束的递归广义最大相关熵变中心(RecursiveGeneralizedMaximumCorrentropyCriterionwithVariableCenterunderSparsityConstrained,RGMCCVC-SPC)算法[17].从表2中可知,3种算法具有相同的除法次数,而在乘法和加法运算上,GRKRSL-SPC算法的计算量小于RGMCCVC-SPC算法,但高于RGMCC-SPC算法. 表2 RGMCC-SPC和RGMCCVC-SPC及GRKRSL-SPC算法每次迭代的计算复杂度比较 图2 稀疏系统的结构图 在进行实验仿真过程中,为了确保算法比较的公平性,选择在非高斯噪声环境下具有鲁棒性且采用递归更新方式的RGMCC-SPC[16]和RGMCCVC-SPC算法[17]作为比较算法,当RGMCCVC-SPC算法的变中心变为0时退化为RGMCC-SPC算法,设置比较算法的参数使得所有算法具有一致的收敛速率.为了进一步定量评价滤波精度,定义稳态均方偏差(Mean Square Deviation,MSD)如下,用MMSD表示: (25) 图3显示了GRKRSL-SPC算法在二进制噪声下的学习曲线和所有算法的参数设置,其中,图3(a)和图3(b)的稀疏度分别为1/16,5/30.从图3中可知3个算法在保持几乎一致的收敛速率下,GRKRSL-SPC算法的滤波精度显著高于RGMCC-SPC和RGMCCVC-SPC算法,尤其当α=4和α=6时,表现更明显.同样地,在稀疏度为1/16和5/30的正弦噪声环境下,GRKRSL-SPC算法提高了稀疏系统辩识中的精度,并且α=4和α=6的滤波性能优于α=2的性能,仿真结果如图4所示. 图3 在二进制噪声下不同算法的稳态均方偏差学习曲线 图4 在正弦噪声下不同算法的稳态均方偏差学习曲线 表3显示了在两种稀疏度以及两种噪声环境下算法的消耗时间. 表3 3种算法在稀疏度为1/16和5/30和两种噪声下稀疏系统识别的仿真结果 从表3中可以得出:不论是在二进制噪声还是正弦噪声环境中,GRKRSL-SPC算法比RGMCCVC-SPC算法消耗更少的时间,比RGMCC-SPC算法消耗更多的时间,此结论与表2中计算复杂度结果相一致.总而言之,从稳态均方偏差和计算复杂度两方面而言,GRKRSL-SPC算法性能优于RGMCCVC-SPC算法和RGMCC-SPC算法. 本文利用广义高斯密度(GGD)函数作为核函数,提出了一种定义在核空间的非线性相似度量方法,即广义核风险敏感损失函数(GRKRSL).进一步结合递归更新方式提出了应用在稀疏系统模型中的基于稀疏惩罚约束的广义核递归风险敏感(GRKRSL-SPC)算法.从计算复杂度和滤波精度两个方面去验证了GRKRSL-SPC算法在非高斯噪声环境中的有效性和滤波精度.GRKRSL-SPC算法在保持与RGMCC-SPC和RGMCCVC-SPC算法相同计算复杂度的前提下,提高了稀疏系统的滤波性能,尤其是当α=4和α=6时滤波精度明显提高.蒙特卡洛仿真结果验证了GRKRSL-SPC算法对稀疏系统识别精度优于其他的鲁棒稀疏自适应滤波算法.1 背景介绍
1.1 核风险敏感损失函数
1.2 广义核风险敏感损失函数
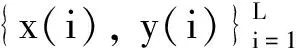
1.3 广义核风险敏感损失函数性质
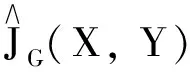
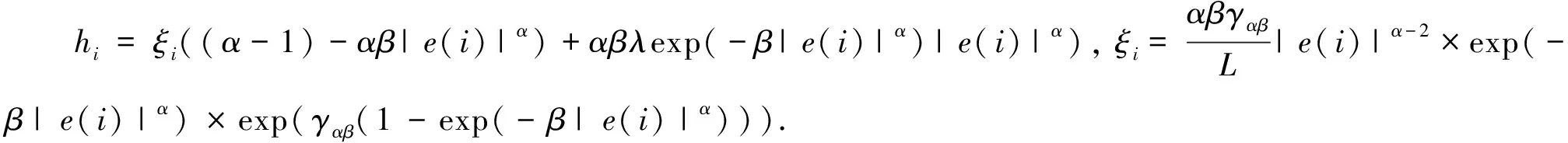
1.4 最小化广义核风险敏感损失函数准则

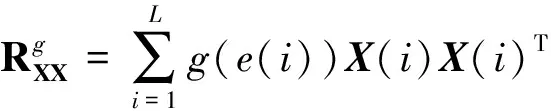
2 算法
2.1 稀疏惩罚约束
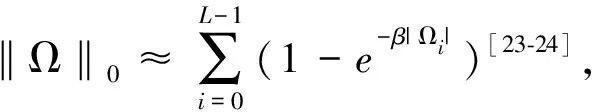
2.2 GRKRSL-SPC算法


2.3 计算复杂度分析

3 仿真结果和分析

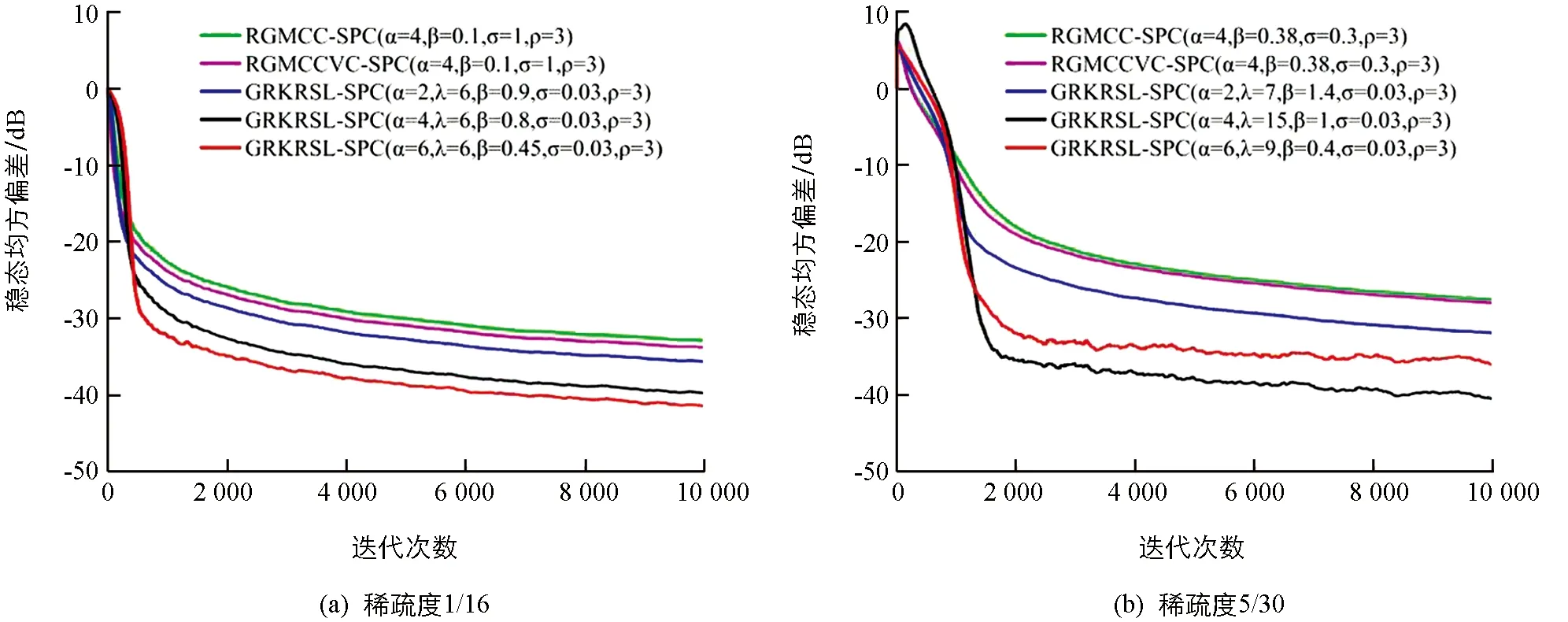
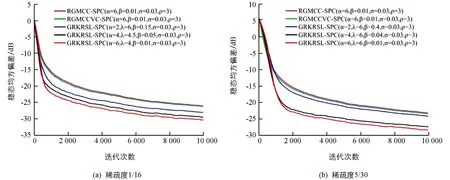
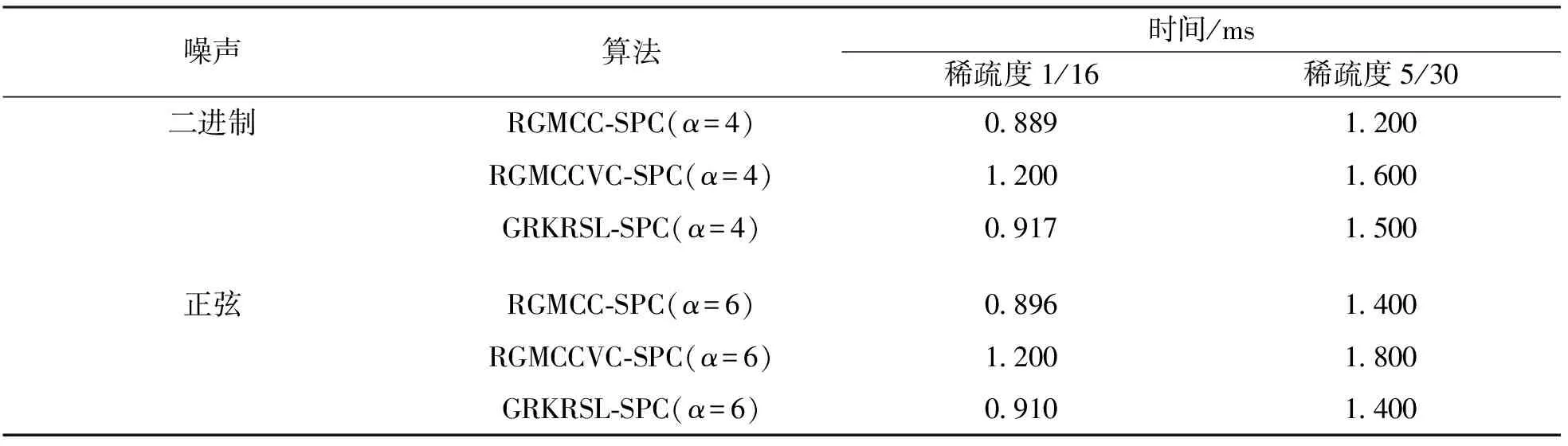
4 结论
猜你喜欢
波谱学杂志(2022年1期)2022-03-15
汉语世界(The World of Chinese)(2021年1期)2021-02-22
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
数学学习与研究(2018年12期)2018-08-17
上海师范大学学报·自然科学版(2018年3期)2018-05-14
中国校外教育(下旬)(2017年8期)2017-10-30
现代电子技术(2016年5期)2016-05-14
电影故事(2015年16期)2015-07-14
