
基于半监督学习的中文社交文本事件聚类方法
2022-04-12 04:15郭恒睿王中卿朱巧明李培峰
中文信息学报 2022年2期
郭恒睿,王中卿,朱巧明,李培峰
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
在如今的网络时代,随着移动互联网的发展,信息交互变得前所未有的简便快捷。QQ、微信、微博、抖音、快手等社交媒体广泛地走进了人们的生活,改变了人们的生活习惯。研究表明,社交媒体对于新事件的反应比传统媒体更加敏锐[1]。因此,对社交媒体中的文本进行数据分析具有非常重要的意义。其中,事件聚类是社交媒体中事件检测的重要步骤[2]。
事件聚类旨在根据文本事件特征的不同特征对文本进行聚类。社交媒体中多为短文本,且文本内容具有多样性、随意性,包含较多的干扰词。传统的无监督聚类模型难以准确提取社交文本的事件特征,事件聚类结果准确度较低。Wang等人[3]采用了有监督的深度神经网络模型对社交文本进行聚类,增强了聚类效果,但面对海量的社交文本,该方法需要大量的文本标注工作。
基于此,本文提出了一种基于半监督学习的中文事件增量聚类模型SemiEC(Semi-supervised Chinese Incremental Event Clustering Model)。该模型利用LSTM[4]提取文本特征,利用线性模型计算两个文本属于同一事件的概率,在此基础上进行增量聚类。然后,该模型利用增量聚类过程产生的标注样本对模型进行再训练。在无需额外数据标注工作的同时,帮助模型学习更多的事件信息,提高聚类效果。同时,对于聚类过程中的不确定样本,暂时不进行聚类,在结束后用再训练后的模型进行重新聚类,如此可以防止较差样本影响簇心表征,影响模型再训练,提高对不确定样本的聚类准确度。在社交文本上的实验表明,SemiEC模型与基准模型相比在各项聚类指标上均得到较大提高。
1 相关工作
目前,大部分事件聚类研究主要基于词的特征。与长文本不同,短文本聚类存在高维稀疏的问题[2], 因此一些学者考虑引入外部特征。其中Mathioudakis等人[5]以及Saeed等人[6]利用突发性关键词来预测短文本的重要性,并通过这些重要的短文本来检测事件进行聚类。Nguyen等人[7]通过考虑事件的发布时间、扩散程度和扩散敏感性,采用时间特征来检测事件,并进行聚类。除此之外,Li等人[8]探索了用户在社交媒体数据中的影响,利用文本内容特征、用户特征和使用特征来检测事件并进行聚类。McMinn等人[9]借助了文本的命名实体特征来加强事件检测的效果。
为了解决传统方法高维稀疏的问题,Cai等人[10]通过局部保存索引(LPI)将高维文本映射到低维语意空间,同时使语意相关的文本在低维空间中也彼此接近。Qimin等人[11]使用K-means聚类算法对特征词集进行聚类得到特征簇,用特征簇表示句向量,从而解决了向量空间模型维度爆炸的问题,同时提高了聚类效果。Zhou等人[12]以Word2Vec词向量为基础,结合时序关系,提出了JS-ID'F顺序来进行文本嵌入。Arora等人[13]提出了对文本的SIF Embedding,通过对词向量进行加权平均,再用PCA和SVD对其进行一些修改,得到文本的低维向量表示。Xu等人[14-15]采用了基于DCNN的深度神经网络学习文本的深度特征表示。该模型首先通过现有无监督降维方法得到文本的二进制编码,然后将文本通过Word Embedding输入卷积神经网络,将文本的二进制编码作为模型的训练目标,将卷积层与输出层之间的中间特征向量作为文本的深度特征表示,这是一种基于自训练的无监督模型。
对于社交媒体中的流式数据,常用的聚类算法有Singlepass增量算法和局部敏感哈希(LSH)算法。对于获得新样本,Singlepass聚类算法首先需要计算新来文本与已有事件的相似度,若相似度超过阈值,则将其加入相似度最大的已有事件,否则将其设为新事件[16]。该算法的关键步骤在于计算文本相似度,目前最为常用的是余弦相似度cosine。局部敏感哈希(LSH)聚类算法主要基于新事件检测模型(FSD),其思路是通过LSH算法找到新来文本在已聚类文本中的近邻文本集合,从该集合中找到新来文本的最近邻文本,若两者最大相似度大于设定阈值,则为已有事件,否则为新事件[1]。在局部敏感哈希(LSH)聚类算法中,其关键步骤在于通过LSH算法尽快找到新来文本的近邻文本。Wurzer等人[17]对寻找最近邻文本的哈希算法做了改进,提高了效率,但准确率与Petrovi[1]相当。Xie等人[18]提出了一种基于自训练的深度嵌入式聚类模型。该模型使用深度神经网络同时学习特征表示和聚类分配,是一种基于划分的聚类模型,不适合处理流式数据。Hadifar等人[19]使用SIF Embedding进行句子表征,采用自编码器提取文本的低维特征表示,采用类似Xie等人[18]的聚类算法通过自训练的神经网络模型同时学习文本特征表示和聚类分配,得到聚类结果。Finley等人[20]利用有监督的SVM模型判断两个文本是否相关,通过Bansal等人[21]的方法进行文本聚类,该聚类方法将样本分布视为一个图模型,通过最大化簇内的样本对相似性实现聚类。Haponchyk等人[22]对Finley等人[20]的方法进行改进,用于对话系统中用户问题聚类,从而分析用户意图。Wang等人[3]采用了有监督的LSTM模型提取文本特征,计算文本相似度,采用增量聚类算法进行社交文本聚类,相比此前的聚类算法其性能有所提高,但需要大量的数据对模型进行训练。目前,在面向社交媒体的事件聚类方法中, 还没有采用半监督的方法。
2 半监督的社交媒体事件增量事件聚类模型(SemiEC)
有监督聚类算法虽然聚类效果较好,但需要大量的数据标注工作来训练模型提高效果。无监督方法的性能又往往不能满足实用的需求。基于此,本文提出了一种半监督的中文社交文本增量事件聚类模型(SemiEC),相比Wang等人[3]采用的模型,在相同训练的情况下能进一步提高聚类效果。
所提模型聚类过程如图1所示,对于输入的社交媒体文本ti, 首先对其进行事件聚类,判断ti是属于已有事件还是新生事件,或是无法确定。若ti属于已有事件,则将其加入该簇;若为新事件,则基于ti建立新的簇,否则设ti为不确定样本,加入Buffer。该过程中使用LSTM提取文本特征,利用线性模型计算文本相似度。由于增量聚类算法可以得到实时的聚类结果,因此每次对部分数据进行聚类后,从聚类结果中抽取样本组成训练集对模型进行再训练,使模型进一步学习新的事件特征,增强聚类效果。在结束后,将聚类结果中所含元素较少的簇中的样本全部设为不确定样本。然后用经过多次再训练后的模型对不确定样本进行聚类,得到最终的聚类结果。下面将对聚类过程进行详细介绍。
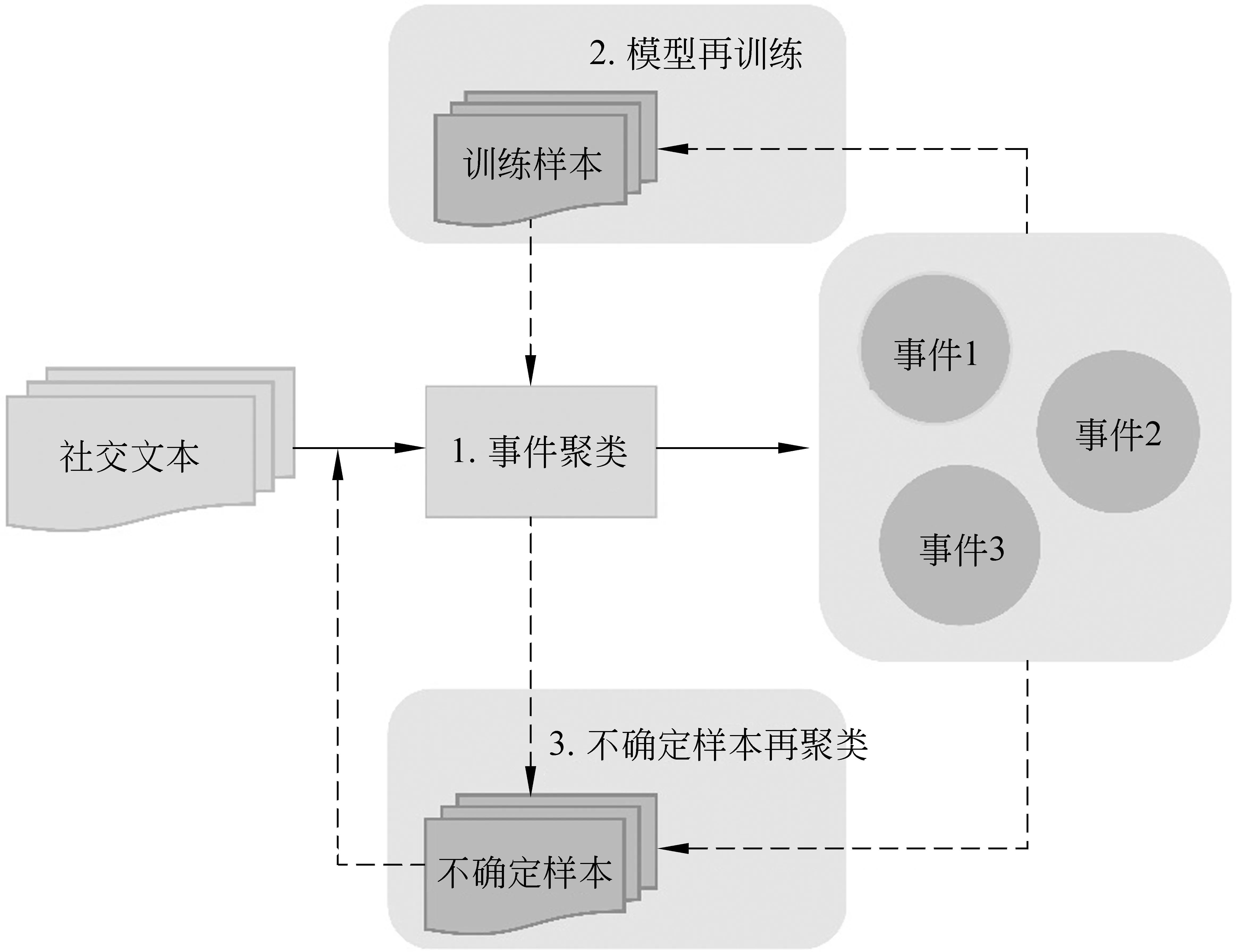
图1 基于半监督学习的增量聚类过程
2.1 文本表示
类似Wang等人[3]的方法,SemiEC采用LSTM模型提取文本特征,记为Mencoder。在文本输入前,首先进行分词和去停用词。将预处理后的文本用X={w1,w2,…,wn}表示。其中,wi表示句子中第i个词在词表中的编号,n表示句子中的词数。使用由百度百科预训练的中文词向量对句子进行词嵌入,用d维词向量xi表示词wi,xi∈n×d。将文本向量X={x1,x2,…,xn}通过LSTM模型得到一个隐藏序列{h1,h2,…,hn},其中ht由当前输入向量xt和前一时刻的输出ht-1计算得到,t∈(1,n),即
ht=LSTM(xt,ht-1)
(1)
模型初始参数随机生成,我们采用低维向量ht来表示文本向量X。
2.2 文本相似度计算
对于两个文本Xi和Xj,首先通过Mencoder得到两个文本的特征向量hi和hj。将特征向量hi和hj进行拼接后通过一个线性层得到一个低维向量hc,最后通过Sigmoid激活函数得到Xi和Xj的相似度Pc,Pc∈[0,1],计算如式(2)、式(3)所示。
2.3 聚类算法
SemiEC模型的聚类过程主要分为三个步骤: ① 对社交媒体文本的事件聚类;②对模型的再训练; ③对不确定样本重新聚类。具体过程见算法1。
2.3.1 对社交文本的事件聚类(1)算法1第1~11行。
对于一个新到来的社交文本ti,要判断其与已有事件的最大相似度。对于已有事件簇C={C1,C2,…,Ck}。对于C中任意簇Ck,用Ck中的前N个文本来作为簇心,若样本数不足N,则将簇中全部样本作为簇心,簇心记为Ak。将ti与代表簇心的各个文本的相似度平均值作为ti与该簇的相似度。将该过程记为ClusterSim,计算过程见算法2。

算法1 基于半监督学习的增量聚类算法输入: 社交文本T={t1,t2,…,tm}阈值L和H,表征簇的文本个数N特征提取模型Mencoder,相似度模型Msim更新阈值U,每次训练集样本数D输出: 事件聚类结果C={C1,C2,…,CK}初始化: 将第一个文本初始化为第一个簇C={C1}Buffer置为空1. For ti∈T: 2. 通过Mencoder得到ti的特征向量hi3. For Ck∈C: 4. simk=ClusterSim(Ck,hi,Msim)5. s=max(sim),对应的簇为Cr6. If s>H: 7. 将ti加入Cr8. Else if s≥L: 9. 将ti加入Buffer10. Else: 11. 将ti设为新的簇,加入C12. If 有U个样本加入C: 13. 抽取D组数据组成训练集14. 对模型Msim和Mencoder进行联合训练15. 通过Mencoder更新C中每个簇的簇心Ak16. For Ci∈{C1,…,Cn}: 17. If |Ci|
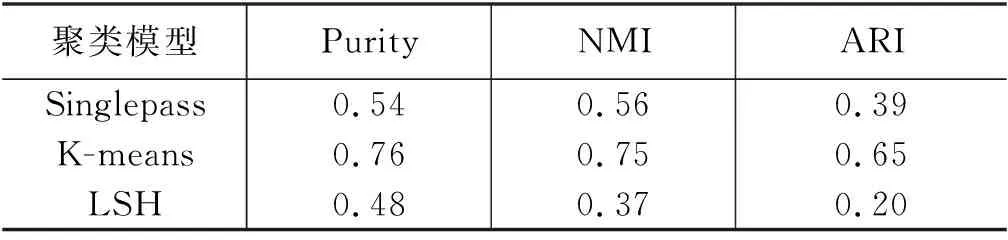
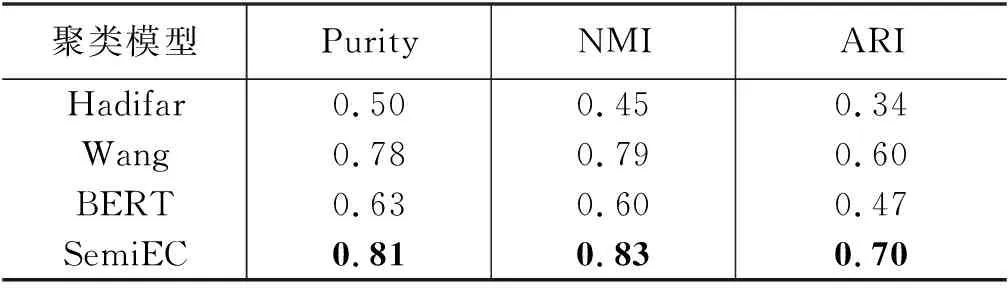
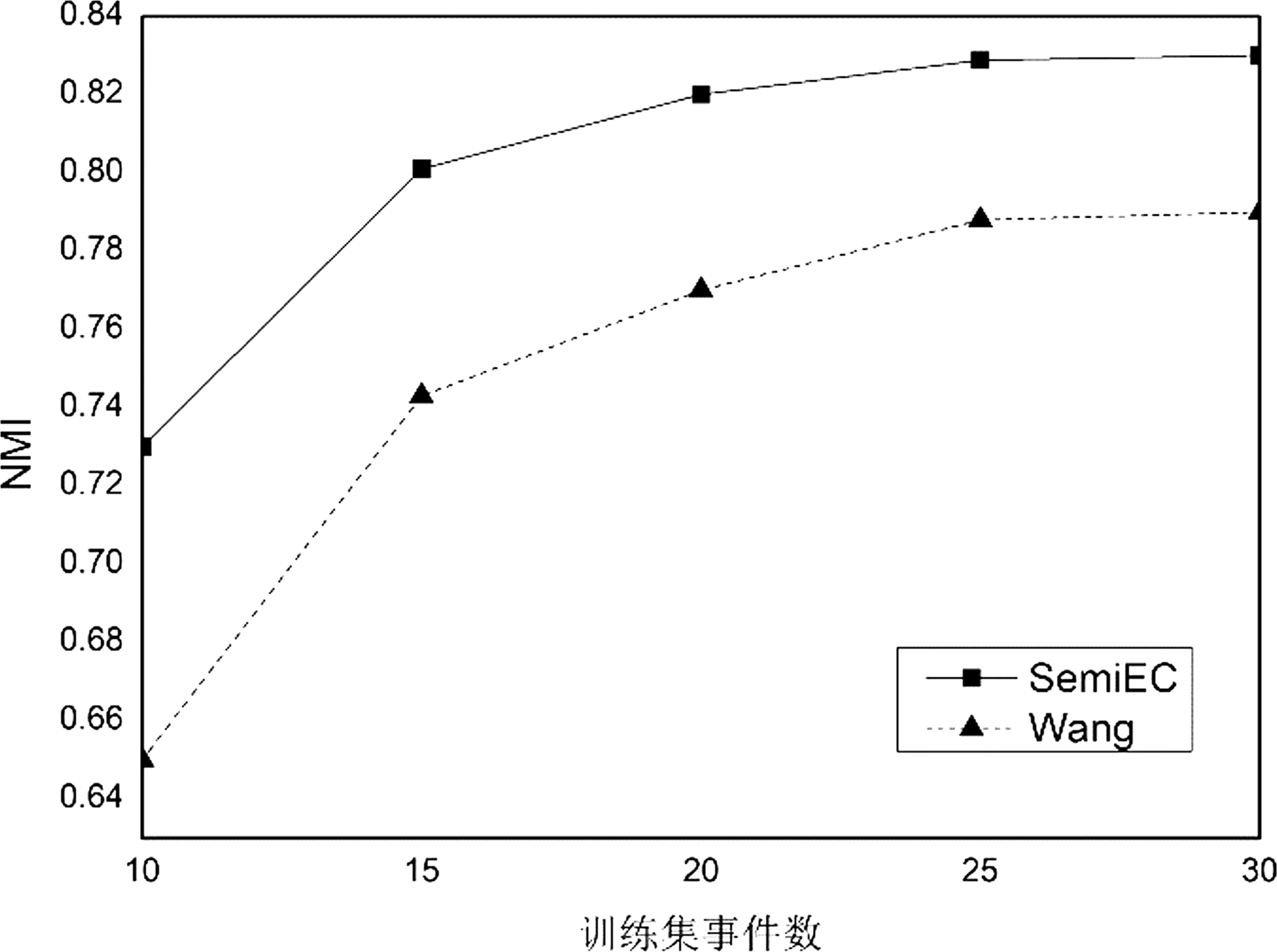
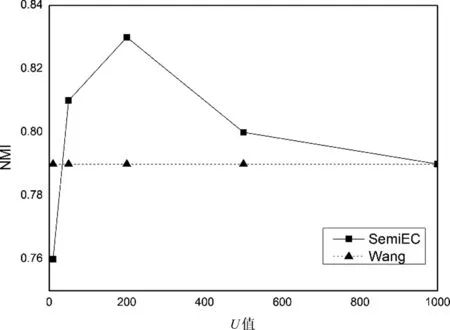
设定两个阈值L和H,其中,0 传统singlepass算法采用一个阈值判断文本ti属于已有事件还是属于新生事件。相比较而言,SemiEC模型加入了“不确定样本”这一分类,可以防止较差样本影响簇心表征和再训练的质量。 算法2 ClusterSim计算步骤输入: 文本ti的特征向量hi,事件簇Ck相似度模型Msim输出: 相似度s1. Ak为Ck簇心中文本对应的特征向量集合2. For hj∈Ak: 3. simj=Msim(hi,hj)4. s=mean(sim)5. 输出s 2.3.2 对模型的再训练(2)算法1第12~15行。 将特征提取模型Mencoder和相似度模型Msim拼接到一起同时训练。设置一个更新阈值U,每当有U个样本完成聚类,就从U个样本中抽取D组训练数据组成训练集,对模型进行再训练。训练集中正例与负例的比例为1∶ 1。正例抽取方法为: 从U个样本中随机选取一个样本p,再从U个样本中与p同簇的样本集中随机选取一个样本q,样本p与样本q组成一组正例,标签置为1。负例的抽取方法为: 从U个样本中随机选取一个样本p,再从U个样本中与p不同簇的样本集中随机选取一个样本q,若U中没有与p不同簇的,则从目前所有已聚类且与p不同簇的样本中随机选取一个样本q,样本p与样本q组成一组负例,标签置为0。若目前所有已聚类的样本中都没有与p不同簇的,则本次不进行训练。 相比Wang等人[3]的方法,SemiEC增加了模型再训练的步骤,利用增量聚类过程中产生的标注数据对模型进行再训练,可以使模型学习新事件的特征,进一步提高模型的泛化能力。 2.3.3 不确定样本进行重新聚类(3)算法1第16~28行。 在增量聚类结束后,经常会出现个别样本数特别少的簇,这是增量聚类模型经常容易出现的问题。若聚类结束后,出现包含样本数少于N的事件簇,则删除这些簇,并将这些簇中的样本加入缓冲区Buffer,Buffer中包含聚类过程中的不确定样本。增量聚类结束后,再对Buffer中的样本进行重新聚类。计算不确定样本与已有事件的最大相似度,若样本与已有事件簇的最大相似度大于0.5,则将其加入该簇,否则为该样本建立新的簇。 相比Wang等人[3]的方法,SemiEC增加了不确定样本重新聚类的步骤,一方面,可以防止不确定样本加入簇心影响事件簇的表征以及进入训练集对模型进行错误的训练;另一方面,在聚类结束后,模型经过多次训练后效果有所增强,可以对这些不确定的样本进行更准确的聚类。 本次实验的数据来自微博。采用与Wang等人[3]相同的规则搜集了关于40次不同地震事件的微博,共计10 828个。采用30次地震事件作为训练数据,从中随机选取样本组成训练集。其中同一地震事件中的两个文本为正例,标签为1;不同地震事件中的两个文本为负例,标签为0。训练集中正例和负例之比为1∶1,总共抽取了400 000组样本训练模型。剩余的10次地震事件数据作为测试集,共包含2 518个文本,用于事件聚类实验。 聚类算法中N的取值为25,用事件簇中的前N个文本来表示该簇。N越大,对事件簇的代表性越强,但计算量也会增大。聚类过程中的阈值L和H的取值范围为0 模型基于Keras框架,后端为Tensorflow。特征提取模型Mencoder训练过程中使用了由百度百科预训练的词向量,向量维度为300,嵌入层设置为不可训练。LSTM层输出维度为128,Dropout=0.1, Recurrent Dropout=0.1,其余为默认参数。相似度模型Msim中的全连接层输出维度为128,激活函数为Relu,其中还包含两个Dropout层,Dropout=0.1。 将Mencoder和Msim拼接到一起,可以组成一个计算文本相似度的孪生神经网模型M。两个文本ti和tj分别通过Mencoder得到特征向量hi和hj,将hi和hj作为Msim的输入,最终得到两个文本的相似度Pc。 在聚类过程中,同一个文本ti需要与多个文本计算相似度,若采用完整的孪生神经网模型M计算相似度,会产生较大的时间开销,同一个文本ti会被多次重复编码。我们将M拆分为Mencoder和Msim,每个文本仅需被Mencoder编码一次,用较为简单的Msim来进行多次的相似度计算,可以大大减少聚类过程的时间开销。 模型训练时,我们将Mencoder和Msim拼接为孪生神经网络M,将M在训练集上训练5轮,再将M拆分为Mencoder和Msim,从而实现模型的训练。模型再训练同样是对孪生神经网络M进行再训练,训练轮数为5轮,再将M拆分为Mencoder和Msim,从而实现模型的再训练。 神经网络M的输出为ypre,真实标签为ytrue, 为0或1。优化器为Adam,采用交叉熵损失函数,计算步骤如式(4)所示。 (4) 我们采用纯度Purity、归一化互信息NMI和调整兰德系数ARI作为聚类效果的评价指标。Purity是正确计算的文本数与文本总数的比值。其定义如式(5)所示。 (5) 其中,N表示总的样本个数,Ω={o1,o2,…,ok}表示聚类模型得到的聚类簇划分,其中k表示预测得到的事件簇总个数;C={c1,c2,…,cj}表示真实类别划分,其中,j表示预测得到的事件簇总个数。Purity取值范围为[0,1],Purity越接近1,聚类效果越好。 NMI是一个基于熵的评价指标,其定义如式(6)所示。 (6) 其中,I表示互信息,如式(7)所示。 (7) H表示熵,如式(8)所示。 (8) NMI的取值范围为[0,1],NMI越接近1,聚类效果越好。 调整兰德系数ARI弥补了兰德系数RI惩罚力度不够的问题,其定义如式(9)、式(10)所示。 其中,a表示实际类簇与聚类预测类簇中都是同类别的元素对数,b表示实际类簇不同类别,在聚类预测类簇中也是不同类别的元素对数。mean(RI)为RI的平均值。ARI的取值范围为[0,1],ARI越接近1,聚类效果越好。 我们将提出的事件聚类模型得到的聚类结果与以下聚类方法进行对比。 (1)Singlepass: 该聚类方法采用向量空间模型表示文本,用cosine计算文本相似度,采用singlepass算法进行聚类,属于无监督聚类算法。模型由自己实现。 (2)K-means: 该聚类方法采用向量空间模型表示文本,用cosine计算文本相似度,采用K-means算法进行聚类,属于无监督聚类算法。实验中指定正确的事件个数。模型由自己实现。 (3)LSH[1]: 这是一种基于局部敏感哈希的聚类算法,采用向量空间模型表示文本,用cosine计算文本相似度,属于无监督聚类算法。模型由自己实现。 (4)Hadifar[19]: 该聚类模型采用SIF Embedding表示文本,通过自编码器学习文本的低维特征表示,采用类似Xie等人[18]的深度聚类算法进行短文本聚类,属于无监督聚类算法。该方法在实验中采用不同领域的短文本作为测试集,本次实验中的测试集为地震领域的不同事件。实验中指定正确的事件个数。模型采用了该论文中提供的代码。 (5)Wang[3]: 该聚类模型利用LSTM提取文本特征,利用线性神经网络模型计算文本相似度,通过增量聚类算法进行聚类,属于有监督聚类算法。模型由自己实现。 (6)BERT: 该方法将Wang等人[3]的模型换成了BERT词向量,属于有监督聚类算法。模型由自己实现。 由于聚类结果会受数据输入顺序的影响,因此我们将测试数据随机打乱顺序进行10次聚类,记录了各项聚类指标的平均值,聚类结果如表1所示。 表1 聚类结果对比 续表 其中,Wang[3]采用的有监督聚类模型与其他聚类模型相比聚类效果较好,因此以该模型为baseline。在经过相同训练的情况下,SemiEC模型相比baseline模型,在各项聚类指标上均有所提升,在Purity上提升3%,在NMI上提升4%,在ARI上提升10%。 社交媒体中的文本较短,表达具有随意性,即使对于同一事件的评论,其表述方式也各有不同。采用向量空间模型和词向量加权提取文本特征,都容易受干扰词的影响,从而导致关键特征信息无法突出,致使聚类效果较差。 通过对模型进行有监督的训练,相比无监督聚类模型,可以更准确地识别文本的事件特征,增强聚类效果。但基于BERT词向量的聚类方法相比基于Word2Vec词向量的方法,聚类结果反而有所下降,原因在于BERT词向量模型包含了更多的信息,模型容易过拟合已有事件。测试集中的事件并没有在训练集中出现过,因而预测效果较差,且BERT模型比Word2Vec词向量模型用时更多,对于海量的社交媒体文本而言效率偏低。 有监督聚类算法对训练集的依赖较大,要使模型更准确地区分各种事件,其关键在于训练集中是否有足够充分的事件类型。因此,分别选取10次、15次、20次、25次、30次地震事件作为训练数据,从中抽取400 000组文本对组成训练集对模型进行训练,以3.1节中的10次地震事件作为测试集,以Wang等人[3]的模型为baseline,以NMI为参考指标,将测试数据随机打乱进行10次聚类,对NMI取平均值,得到的结果如图2所示。 图2 训练集事件数对聚类结果的影响 由图2可以看出,在不同训练集事件数的情况下,SemiEC模型相比baseline模型聚类效果有所提高,但不同训练数据的聚类效果有所差别。当训练事件数为15时,SemiEC的性能已经超过了使用更多训练数据的baseline模型,这充分说明了本文半监督方法的有效性,可以在少量标注数据的基础上,通过利用聚类过程中产生的标注数据学习新的事件特征,获得更好的性能。 模型再训练和不确定样本重聚类步骤都需要设置一些额外的参数。其中对SemiEC模型聚类效果影响最大的是更新阈值U,主要用于控制模型再训练的频率。本次实验将U分别设置为10、50、200、500、1 000,每次训练集样本数D设置为U的4倍,分别为40、200、800、2 000、4 000。以3.1节中的10次地震事件作为测试集,以Wang等人[3]的模型为baseline,以NMI为参考指标,将测试数据随机打乱进行10次聚类,对NMI取平均值,得到的结果如图3所示。 图3 U值对聚类结果的影响 由图3结果可以看出,当U值较小,为10时,聚类效果较差,主要原因在于训练集较小,所属类别分布不均匀的概率较大,训练反而导致模型偏向于个别事件,使得聚类所得事件数比实际事件数少,聚类效果较差;当U值逐渐增大到200时,样本分布趋于均匀,聚类效果相对baseline会有明显提高;但不断增大U值会减少模型再训练的次数,导致大量数据仅能使用原始模型进行聚类,从而使聚类结果不断趋近但不低于baseline。因此,U的取值要在保证数据分布尽量均匀的情况下,取较小的值,此时可以使SemiEC模型达到最好的聚类效果。 为了证明模型再训练步骤和不确定样本再聚类步骤的有效性,分别对这两个步骤进行了测试。ReTrain表示仅加入模型再训练步骤,ReCluster表示仅加入不确定样本再聚类步骤。以3.1节中的10次地震事件作为测试集,以Wang等人[3]的模型为baseline,将测试数据随机打乱进行10次聚类,对各项聚类指标取平均值,得到的结果如表2所示。 表2 ReTrain和ReCluster有效性对比 由表2数据可以看出,ReTrain和ReCluster,相比baseline在各项聚类指标上均有所提高,这充分说明了模型再训练和不确定样本再聚类步骤的有效性。其中,模型再训练步骤可以帮助模型学习新的事件特征,增强对后续样本的聚类效果。不确定样本再聚类步骤可以防止不确定样本加入簇心,减少错误样本对簇心表征的影响,从而增强聚类效果。将两者结合后的SemiEC模型,通过不确定样本再聚类减少错误样本进入训练集,增强模型再训练的效果,同时对不确定样本用再训练后的模型重新聚类,进一步增强不确定样本的聚类效果,两者相互提高,得到最好的聚类效果。 本文提出了一种半监督增量型中文社交文本事件聚类模型SemiEC,采用LSTM提取文本特征,采用线性模型计算文本相似度,进行增量聚类。利用增量聚类过程产生的标注样本对模型进行再训练。对聚类过程中分配不确定的样本在结束后重新聚类。再训练过程可以让模型学习新的事件信息,使模型准确度随着聚类过程不断提高。对不确定样本的重新聚类可以防止不确定样本影响簇心表征,减少错误样本对模型进行再训练的概率,同时提高不确定样本的聚类准确度。SemiEC模型与经过同样预训练的有监督聚类模型相比,其各项聚类指标均有所提高。
3 实验部分
3.1 实验数据
3.2 实验参数
3.3 模型参数
3.4 模型训练
3.5 评价指标
3.6 聚类结果
4 分析
4.1 训练集事件数对SemiEC模型的影响
4.2 参数设置对SemiEC模型的影响
4.3 模型再训练和不确定样本再聚类的有效性

5 总结
猜你喜欢
意林彩版(2022年2期)2022-05-03新高考·高一数学(2022年3期)2022-04-28好日子(2021年8期)2021-11-04中学生数理化(高中版.高考数学)(2021年1期)2021-03-19第一财经(2020年4期)2020-04-14文苑(2018年17期)2018-11-09雷达学报(2017年6期)2017-03-26高中生学习·高三版(2016年9期)2016-05-14互联网天地(2016年1期)2016-05-04现代计算机(2016年17期)2016-02-28
