
基于深度卷积特征的场景全局与局部表示方法
2022-04-12 06:47林潮威李菲菲
电子科技 2022年4期
林潮威,李菲菲,陈 虬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
场景识别指计算机根据给定的场景图片对场景的语义标签进行预测。场景识别可以为后续的一些视觉任务例如物体识别、目标检测等提供先验知识。与物体识别任务对比,场景识别有两点不同:首先,识别场景图片是一项复杂的工作,算法不仅需要考虑场景图片的全局背景信息,还需要考虑场景的局部信息,包括一些特定的局部场景模式和局部的物体信息;其次,场景识别存在语义鸿沟的问题。场景图片的标签通常具有很强的概括性,导致场景图片中所包含的语义信息和标签所表示的语义信息之间有较大的差距。若忽略这两点差异,仅单纯地将擅长物体识别的卷积神经网络用于场景识别,则不能达到较好的效果。其原因在于卷积神经网络无法同时捕捉全局特征和局部特征。此外,由于语义鸿沟的存在,使用全连接层的卷积神经网络很难构建从特征至场景类别标签的映射。本文提出的场景综合表示方法能够对传统的卷积神经网络进行改进,并较好地解决上述两个问题。
场景识别主要分为3个阶段,分别是特征提取、特征变换和分类器的训练。早期的场景识别方法主要研究特征的提取方法,一些手工设计的低级特征提取方法被广泛使用。这些低级特征分为全局描述子和局部描述子两大类别,其中GIST[1]、CENTRIST(CENsus TRansform hISTogram)[2]和多通道CENTRIST[3]属于全局描述子;SIFT(Scale Invariant Feature Transform)[4]、HOG(Histogram of Oriented Gradients)[5]、LBP(Local Binary Patterns)[6]和SURF(Speeded Up Robust Features)[7]属于局部描述子。低级手工特征在场景识别任务中取得了一定的效果,但这些低级特征无法有效表示一些复杂的场景图片,限制了场景识别的发展。因此,研究者开始从特征提取以外的角度对场景识别方法进行创新,即提出特征变换的方法将低级特征编码为中级特征来提升特征的表示能力。这些特征编码方法包括BoVW(Bag-of-Visual-Words)[8]、Spatial Pyramid Matching(SPM)[9]、Improved SPM[10]以及Fisher Vector(FV)[11]。受限于低级特征的表示能力,即使应用一些特征变换的方法,场景识别的性能提升还是遇到了瓶颈。
由于深度卷积神经网络[12]在ImageNet大型视觉识别挑战[13]上取得了成功,各个计算机视觉任务开始使用卷积特征来取代手工低级特征。在场景识别领域,卷积特征也逐渐成为了主流。研究者也将用于低级特征的编码方法[8-11]应用到了卷积特征上,衍生出MOP-CNN(Multi-Scale Orderless Pooling)[14]、SFV(Semantic FV)[15]等算法。此外,利用稀疏字典编码卷积特征的方法也在场景识别领域取得了成功,例如Sparse Decomposition of Convolutional Features(SDCF)[16]、改进的稀疏自动编码机[17]和Non-Negative Sparse Decomposition Model(NNSD)[18]。文献[19]根据场景图片的特性提出了多尺度空间编码方法来编码场景图片的卷积特征。
本文提出了一个特征变换模型,通过编码深度卷积特征以生成场景图片的全局和局部表示,并与负责特征提取的卷积神经网络和负责分类任务的全连接层相结合,形成了一个端到端的场景识别模型,如图1所示。在此模型内,本文首先使用了两个在不同数据集预训练的卷积神经网络提取场景图片的场景特征和物体特征;然后进行特征变换,使用注意力机制融合场景特征和物体特征,形成场景图片的全局表示。本文使用类激活映射(Class Activation Mapping,CAM)提取场景图片中的关键区域,从关键区域提取卷积特征并使用LSTM(Long Short-Term Memory)模块进行特征的编码,形成场景的局部表示。最后,使用全连接层进行分类。相较于之前的方法,本文考虑到了场景图片中包含的各方面的信息,构建了场景图片的综合表示,在场景识别的任务中达到了较好的效果。
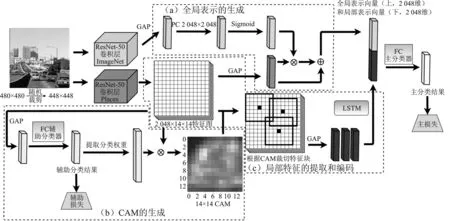
图1 提出模型的框架Figure 1. The framework of proposed model
1 模型整体框架及损失函数
1.1 端到端场景识别模型
本文提出模型的结构如图1所示,从上到下的3个模块分别是:(1)全局特征生成模块;(2)局部场景特征裁切、编码模块;(3)CAM生成模块。其中,GAP(Global Average Pooling)代表全局平均池化,FC(Fully Connected)表示全连接层,CAM(Class Activation Map)表示类激活图,LSTM(Long Short-Term Memory)表示长短期记忆。从总体上看,整个模型分为3部分,第1部分是特征提取部分;第2部分是特征变换部分;第3部分则是主分类器部分,负责输出最后的分类结果。其中,第2部分是本文的重点。
上述模型也是一个端到端模型。对于分类任务来说,端到端即输入模型一张图片,模型能够直接给出分类的结果。端到端是目前场景识别的一个趋势,其优点在于能够在使用随机梯度下降算法的同时训练模型的各个部分,使模型能够达到一个联合最优点。同时,端到端模型无需保留分步的输出结果,因此节省了磁盘空间,也无需人工干预。
1.2 损失函数
从图1中可以看到,整个模型具有两个分类器,分别是主分类器和辅助分类器。其中,辅助分类器依附于CAM生成部分存在,其目的是为了提供生成CAM的分类器权重;主分类器则负责输出场景图片的最终类别。两个分类器的损失分别称为主损失和辅助损失。对于分类任务,常使用交叉熵损失,如式(1)所示
(1)
其中,y′表示预测值;y表示真实值。
主损失的作用是训练整个端到端的网络模型,辅助损失则是为CAM生成部分提供监督信号。由于两个损失的存在,因此在训练的时候需要将两个损失相加合并为一个总损失,如式(2)所示。
lModel=lMain+lAux
(2)
2 场景图片的特征提取及全局表示的生成
2.1 卷积特征的提取
由于深度卷积特征表示性能的优异,在场景识别中,卷积特征已基本取代传统的手工特征。卷积神经网络需要经过预训练后才能够具备提取特征的能力。文献[14,20]使用在大型物体数据集ImageNet上预训练的卷积神经网络提取场景图片的特征,取得了一定的效果。但是,在物体数据集上预训练的卷积神经网络只对场景图片中的物体信息激活,单纯使用基于物体数据集预训练的卷积神经网络无法全面地提取场景图片的特征。因此,需要使用Places[21]数据集预训练的卷积神经网络提取图片中的场景特征。本文同时使用了这两组预训练的卷积神经网络以提取图片的场景特征和物体特征。
在一系列卷积神经网络的变种中,本文选择ResNet-50[22]作为特征提取器。相较于其他卷积神经网络(AlexNet、GoogLeNet、VGG),ResNet-50网络更深,参数更少。而且,由于ResNet具有残差连接,其更容易训练和收敛。为了进行特征提取,本文去除了ResNet-50的全连接分类层,只保留其卷积部分。
2.2 场景图片的全局表示方法
为了将场景的物体信息融入到场景图片的全局表示中,本文使用了一种基于注意力机制的方法,即CCG(Correlative Context Gating)[23],来生成全局表示向量。同时,本文对此方法进行了改进,使其适用于不存在物体信息的室外场景。
如图1(a)(竖矩形均为2 048维的向量)所示,本文首先通过全局平均池化从物体卷积神经网络和场景卷积神经网络生成的两组特征图(Feature Maps)中获得两个表示向量,叫做全局物体信息向量和全局场景信息向量。全局物体向量由一个全连接层映射后通过Sigmoid激活函数得到一个权重向量,为全局物体向量的每一个通道赋予一个权重。然后,将这个权重向量和全局场景向量逐点相乘,以校准全局场景每个通道的数值强度。最后,将校准之后的全局场景向量和原始的全局场景向量逐点相加,得到场景图片的一个全局表示向量。上述的过程实现了基于注意力机制的校准,权重向量每个通道的大小体现注意力分配的情况,权重越大,得到的关注也越高,反之亦然。
3 场景局部表示的生成
场景的全局表示能够描述场景的全局空间布局信息。但对于场景识别来说,光有全局表示是不够的,因此需要提取场景图片的一个局部信息。局部表示的生成过程包括两个主要步骤:第1步如图1(b)所示,目的是通过类激活映射来生成CAM;第2步如图1(c)所示,首先在CAM上寻找局部最大值,局部最大值的位置即是热点区域。然后,将热点区域投射至卷积神经网络提取到的场景特征图上,裁切得到热点区域的特征。最后,通过LSTM 对热点区域的特征进行编码得到场景的局部表示。本文提出的局部表示方法是对文献[24]中方法的改进。
3.1 使用类激活映射生成CAM
类激活映射由文献[25]提出,主要目的是为了对卷积特征进行可视化以及实现弱监督的物体定位。类激活映射能够利用分类层的信息(即某个类别A的分类权重)来生成CAM。CAM以数值大小的方式在卷积特征上标记不同空间位置的热度,数值大的空间位置即为热点区域。本文将类激活映射与负责提取场景特征的卷积神经网络相结合,即如图1(b)所示,CAM生成部分接在了场景卷积神经网络生成的场景特征的后面,构成了能够端到端训练的在线CAM生成器。
CAM生成器的核心是辅助分类器,生成CAM的过程即是一个分类的过程。如图2所示,假设特征图的尺寸为4×(7×7),分类权重尺寸为4×4。对于一个给定的类别B,在生成CAM的过程中,特征图的每个通道将乘上对应的分类权重,然后沿着通道的方向对特征图的数值进行相加,得到一张尺寸为1×(7×7)的CAM。对于一个给定的类别B,在分类的过程中,首先对特征图进行GAP得到特征向量。特征向量的每个通道将乘上相应的分类权重,然后沿着通道的方向将特征图的数值相加,得到一个尺寸为1×(1×1)的分类结果。结合上述CAM的生成过程和分类的过程能够得出结论:将 CAM进行GAP即能得到分类结果。因此,生成CAM的过程即是分类的过程,只是分类的过程中多做了一步GAP。具体的数学推导过程如下:
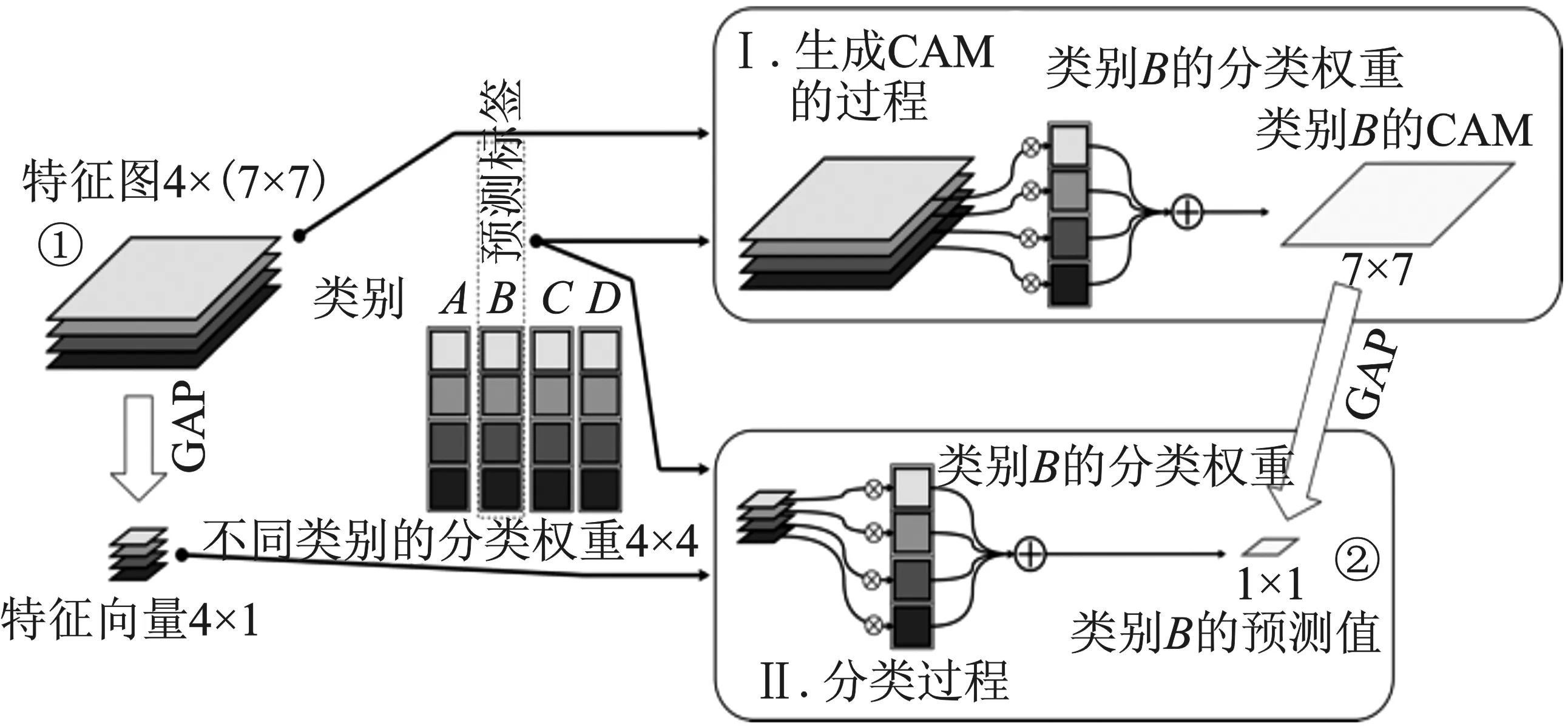
图2 CAM生成的过程与分类的过程Figure 2. The generating and classfication process of CAM
假设有特征图fk(x,y),k∈[1,…,C],x和y代表特征图上的位置坐标,k代表通道的数量。假设通道总数为C,那么GAP就可以表示为
(3)
假设类别c的分类权重表示为wc,计算类别c的分类结果Sc为
(4)
将式(3)带入式(4),可得式(5)。
(5)
如图2所示,可以看到由特征图(图中标记为1)得到预测结果(图中标记为2)有两条路径,即1-GAP-点乘-累加-2和1-点乘-累加-GAP-2,所以对于式(5),改变其中GAP的位置,并假定类别c的CAM为Mc(x,y),那么CAM的计算可以表示为如下形式。
(6)
3.2 搜寻CAM的局部最大值
章节3.1生成的CAM如图3所示(填充伪色)。为了后续的处理方便,已将CAM的数字扩展到[0,255]之间。由于整个模型的输入图片尺寸为448×448,因此网络输出CAM的尺寸为14×14。CAM上的每一个1×1的空间位置均能映射回原图,表示原图32×32区域的一个激活程度。若直接使用阈值T筛选CAM上的空间位置,得到的热点区域数量过于冗余,不利于后续的编码。因此,本文在CAM上搜索局部最大值,局部最大值和热点区域一一对应,局部最大值的坐标即为热点区域的中心坐标。
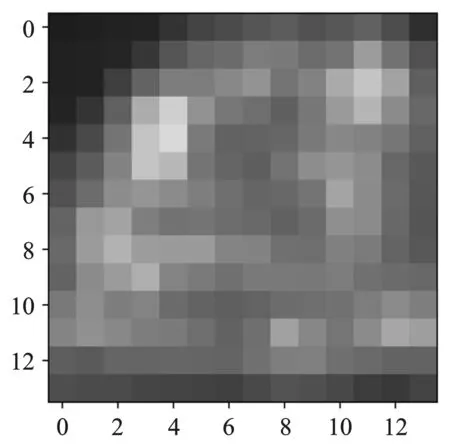
图3 类激活图Figure 3. Class activation diagram
局部最大值的搜索基于滑窗操作,如图4所示。首先,对CAM的四周进行一个补0操作,得到一个四边为0的尺寸为15×15的CAM。然后,使用一个3×3且步长为1的滑窗,在CAM的每一个位置计算局部最大值,即滑窗的中心值若是周围8个值中的最大值,那么滑窗中心位置则为局部最大值。接着,去除重叠滑窗的局部最大值,只保留一个。最后,使用阈值T对局部最大值进行筛选。图4中步骤II和步骤III目的是去除冗余的局部最大值,防止噪声和干扰影响后面的特征编码。阈值T和选取热点区域的数量(N)是重要的超参数,将通过实验选取。
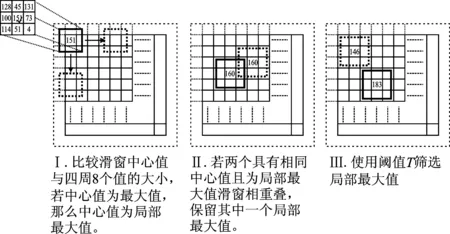
图4 局部最大值的搜索Figure 4. Searching for local maxima
3.3 裁切局部特征
章节3.2通过局部最大值的筛选,能够得到热点区域的中心坐标。以这个坐标为中心,可以在场景图片上裁切出热点区域,然后使用卷积神经网络在热点区域提取特征。但是该方法费时费力,且无法在一次前向传播中将特征提取完毕。因此,本文提出了新的裁切并提取热点区域的方法。本文直接将热点区域的中心坐标映射回卷积特征上,然后在14×14的特征图上裁切出7×7的特征块作为热点区域的特征。N个热点区域裁切得到N×2 048×7×7的特征块,经过GAP之后,能够得到N×2 048的特征,即N个2 048维的特征向量,每个热点区域能够使用一个2 048维的向量表示。接下来本文将使用LSTM来编码热点区域的特征。
3.4 LSTM原理
LSTM[26]是循环神经网络(Recurrent Neural Network)的一个变种,能够处理序列输入、学习序列输入之间的相互联系。LSTM能够有效地编码输入之间的长期依赖,其模块的标准结构如图5所示。
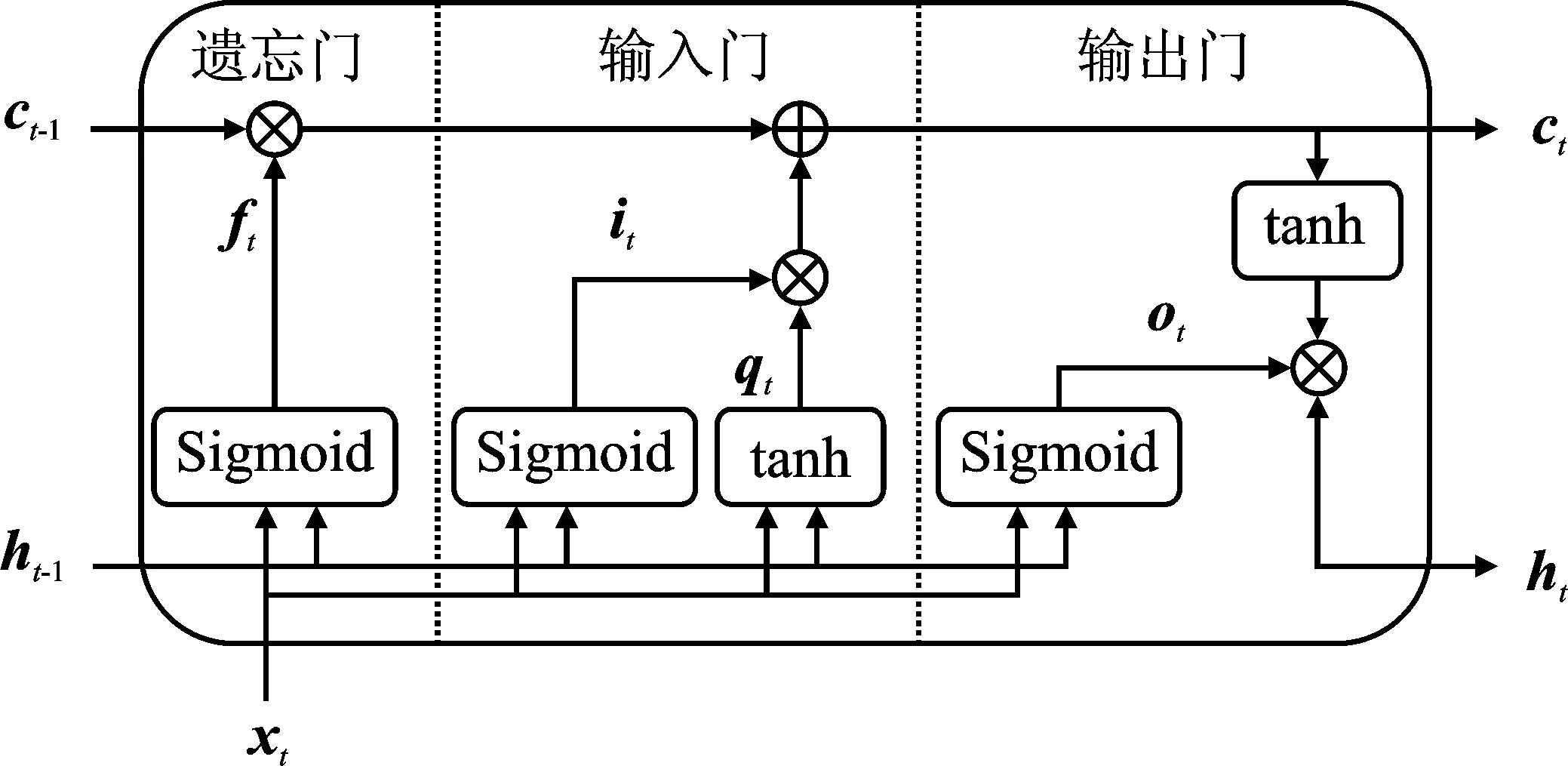
图5 LSTM模块的结构Figure 5. The architecture of the LSTM module
由图5可以看到,LSTM模块有两条主线,一条是细胞状态,另一条是隐藏状态。其中,细胞状态用于存储历史信息,而隐藏状态则用来实现模块的输出。LSTM模块还有3个非线性门控单元,分别是输入门f、遗忘门i和输出门o。
遗忘门f负责控制历史信息的存留,将当前输入xt和历史隐藏状态ht-1堆叠之后输入到遗忘门中。遗忘门可以得到一个遗忘系数向量ft,通过遗忘系数向量ft和历史细胞状态ct-1逐元素相乘,从历史细胞状态中筛选有用的信息,存入当前细胞中状态ct中。ft的计算式如下所示。
ft=σ(Wf[ht-1,xt]+bf)
(7)
输入由两个部分组成,第一部分负责计算模块的输入qt,第二部分则是输入门i,负责计算输入控制向量it。输入控制向量负责控制输入信息的多少,将当前输入xt和历史隐藏状态ht-1堆叠之后输入到输入门中,输入门可以得到一个输入控制向量it,计算过程为
it=σ(Wi[ht-1,xt]+bi)
(8)
模块的输入qt可由式(9)获得。
qt=tanh(Wq[ht-1,xt]+bq)
(9)
从LSTM模块的结构图中可知,细胞状态的更新由经过遗忘之后的历史细胞状态和经过输入门控制的模块输入共同组成,那么细胞状态的更新为
ct=ft·ct-1+it·qt
(10)
输出门o负责输出控制向量ot的计算,将当前输入xt和历史隐藏状态ht-1堆叠之后输入到输出门中,得到输出控制向量ot,输出控制向量的计算为
ot=σ(Wo[ht-1,xt]+bo)
(11)
将输出控制向量ot和经过激活函数激活的当前细胞状态ct逐元素相乘,得到当前隐藏状态ht
ht=ot·tanh(ct)
(12)
其中,σ代表Sigmoid激活函数;Wf、Wi、Wo、Wq表示权重。
3.5 使用LSTM编码局部场景特征
在章节3.3中,本文得到了尺寸为N×2 048的特征向量,代表N个热点区域的特征。因此,若要构成一个序列输入i={x1,x2,…,xN},其序列的长度为N,则本文需要堆叠N个LSTM模块。这些LSTM模块的参数是共享的,最后一个LSTM模块的输出表示为hN=LSTM(xN,hN-1)。本文选择最后一个LSTM模块的输出作为场景图片的局部表示,如图6所示。
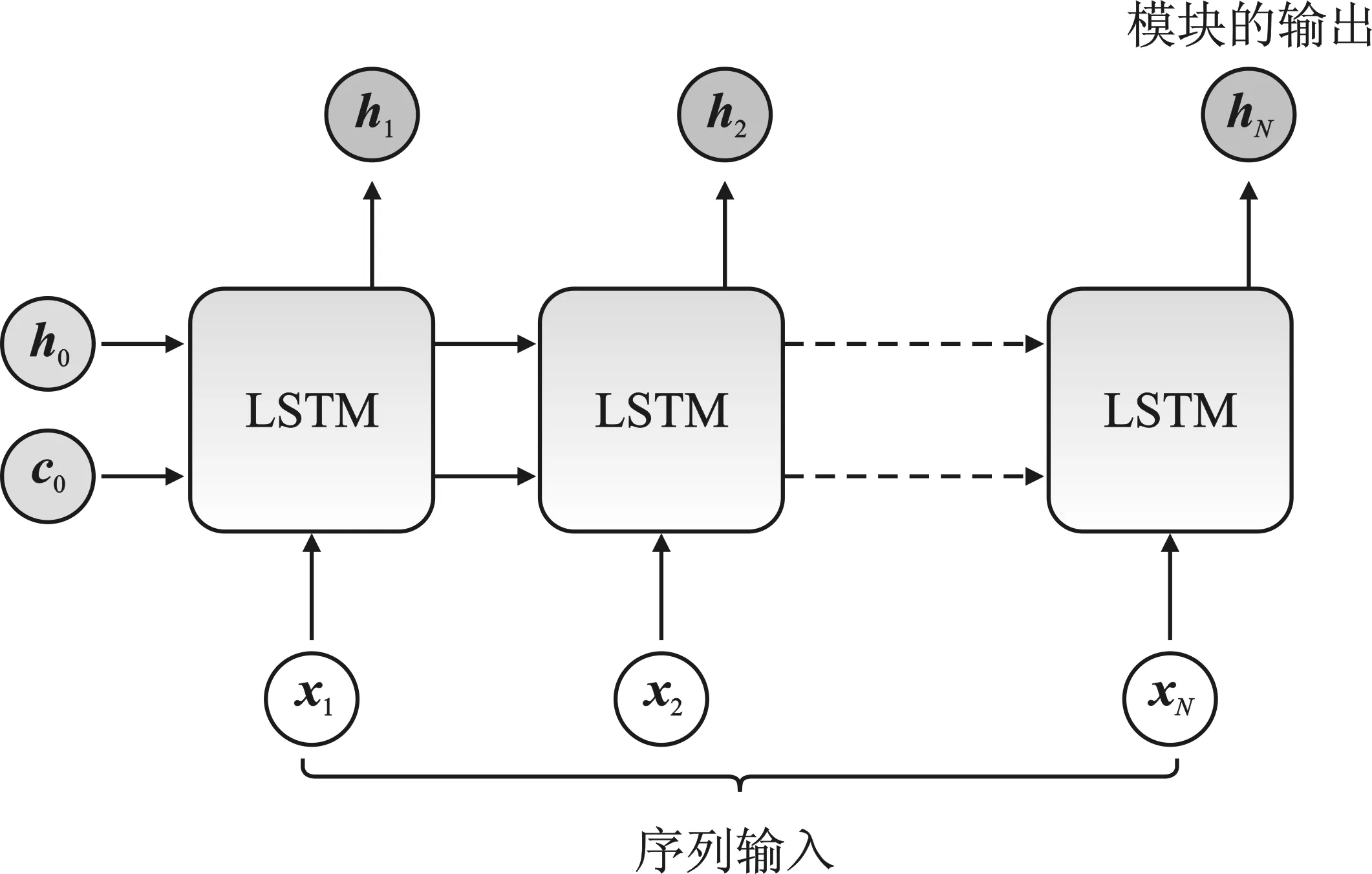
图6 LSTM编码序列输入Figure 6. Sequencing inputs encoded by LSTM
得到的局部表示将和全局表示相堆叠,然后送入到全连接层主分类器中进行分类,如图1所示。
4 实验
4.1 实验数据集
本文在MIT indoor 67[27]数据集上进行实验来验证所提出表示方法的有效性。
MIT indoor 67场景识别数据集包含了15 620张共67类的彩色场景图片。每个类别至少包含100张场景图片,图片短边的最小分辨率为200像素。根据数据集规定的评估协议,本文在每个类别中选择80张图片进行训练,并用余下20张图片进行测试。
4.2 实现细节
本文方法使用了两个ResNet-50进行特征提取,分别在Places数据集和ImageNet数据集上进行了预训练。模型输入图片尺寸为448×448,图片经过特征提取后得到的特征图的尺寸为2 048×(14×14),其中2 048为通道的数量,因此经过GAP后的向量长度为2 048。本文中,除了最终表示向量的长度为4 096以外,所有向量的长度均为2 048。
为了初始化CAM生成器中的辅助分类器,本文首先将场景卷积神经网络和CAM生成器单独提出来进行训练。训练时,冻结场景卷积神经网络的权重,只训练辅助分类器的权重。训练的设定如下:batch size设置为32,epoch设置为40,初始学习率为0.01,且每个10个epoch下降为原来的1/10。网络输入图片的尺寸为224×224,为了进行数据增强,本文将训练集中的图片大小调整为256×256,然后随机裁切成224×224,同时对图片进行随机翻转。训练辅助分类器的结果将作为一个基准(Baseline),代表单场景卷积神经网络进行场景识别的性能。
在局部的场景表示中,本文将采样热点区域的数量定为N=9,热点区域筛选的阈值定为T=150,这两个重要超参数是由章节4.4节中的实验获得的。LSTM的隐藏层的尺寸为2 048,与本文特征的尺寸一致。
整个模型的训练设置如下:模型输入图片的尺寸为448×448,输入图片经过数据增强,即首先将输入图片调整为480×480,然后随机裁剪448×448的尺寸,然后随机水平翻转图片。Batch size设置为32,epoch设置为40。整个模型被分为3个部分来设置学习率:(1)将提取物体特征的卷积神经网络的学习率设置为0,表示冻结物体卷积神经网络的训练;(2)将场景卷积神经网络的初始学习率设置为0.000 1,目的是为了防止在前期训练的时候,过大的损失回传破坏场景卷积神经网络已学得的特征;(3)将模型的其他部分的初始学习率则设置为0.01。学习率在第34个epoch和第74个epoch缩减为原来的1/10。在测试阶段,本文使用5-crop测试方法,并取最后5个epoch测试结果的平均值。
可以看到,相比于基准,本文算法准确度提高了约3%;而相比于最近几年的算法,本文算法取得了SOTA(State-of-the-arts)水准。相较于传统的SPM算法,本文算法提升较大,证明了卷积特征的表示能力。相比于使用传统的特征变换手段编码卷积特征的方法,例如MOP-CNN、DSP、SFV、LS-DHM、VSAD、fgFV和DAG-CNN、MVML-LSTM、Multi-scale CNNs、Dual CNN-DL、SDO、Multi-Modal deep architectures等利用多尺度卷积特征、构建复杂场景表示的方法,本文方法也取得了不错的效果。本文构建的全局和局部表示,在一定程度上契合场景图片本身的性质,因此具有较强的表示能力和鲁棒性,更擅长于室内复杂场景的分类。
4.3 实验结果与对比
为了证明所提出方法的有效性,本文将实验结果与一些经典方法以及最近提出的方法进行了对比,结果如表1所示。

表1 MIT indoor 67 数据集的准确率Table 1. The accuracy on MIT indoor 67 data set
4.4 超参数选择实验
本节将对模型超参数,即热点区域的数量N和热点区域筛选阈值T进行选取。本文选取N∈[5,7,9]及T∈[100,125,150,175,200]进行实验,来探寻最优的超参数组合,实验结果如图7所示。
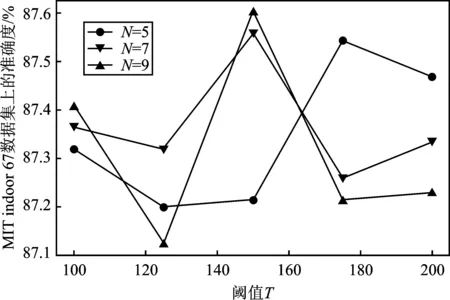
图7 不同超参数下模型准确度Figure 7. The accuracy of the model under different hyperparameters
由图7可以看出,在N=9且T=150的情况下,模型准确度达到最高值。
5 结束语
本文根据场景图片的组成特点,提出了一种场景综合表示方法,它能够将卷积特征转换为场景的全局和局部表示。为了构建全局表示,本文使用了基于注意力机制的方法;为了构建局部表示,本文使用了类激活映射来提取热点区域,并使用LSTM来编码热点区域的卷积特征。在如今的构建端到端场景识别模型的大趋势下,本文的方法能够进行端到端的训练和推理。在MIT indoor 67 数据集上的实验证明了本文方法的可行性。尽管本文的方法在场景识别数据上取得了一定的效果,但仍存在一些问题,需要在今后的研究中解决:(1)本文依靠隐式的方法(基于注意力机制)提取场景中的物体特征,但不是所有的物体特征都对分类起积极作用,需要后续开展研究,进行有效特征的筛选:(2)研究提取场景中显式物体特征的方法;(3)本文构建的局部表示是基于单尺度的,但是场景图片中的特征是多尺度的。在本文提取全局尺度特征、1/2尺度特征的基础上融合更小尺度的热点区域特征可能会对场景识别有所帮助。总之,场景识别准确度取决于构建的图片表示的辨识能力,构建综合的、多尺度的场景表示将是未来场景识别发展的主流方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机系统应用(2021年2期)2021-02-23
金桥(2018年4期)2018-09-26
