
基于三维卷积和哈希方法的视频检索算法
2022-04-12 06:47陈汗青李菲菲
电子科技 2022年4期
陈汗青,李菲菲,陈 虬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着互联网技术和以5G为代表的高速移动通信技术的发展,每天都有海量的视频信息被上传到互联网上。视频信息携带内容丰富、便于理解,被广泛应用于信息传输。近年来各种智能手机与短视频平台的兴起使得人们可随时随地拍摄并上传视频。人们在浏览互联网信息的同时还可以对视频进行编辑操作,并将视频二次上传到互联网上。因此,设计一个有效的视频检索算法,从庞大的视频库中快速检索出人们需要的视频是一个重要的研究方向。
典型的视频检索系统主要分为特征提取和相似性匹配两个方面。一些已有的算法主要通过提取出视频关键帧,然后按照图像特征处理方式来进行特征提取操作,例如使用颜色直方图(Color Histogram)[1]、局部二值模式(Local Binary Patterns)[2]和SIFT(Scale-Invariant Feature Transform)[3]等特征描述子来提取特征。为了得到更好的特征表示,多特征融合的方法逐渐被用于视频检索。
近年来随着深度学习在计算机视觉领域的应用,多种卷积神经网络模型被相继提出,并被广泛应用于包括视频检索任务在内的各种特征提取工作。文献[4]使用GoogLeNet[5]提取视频帧特征,然后使用稀疏编码来对特征进行处理。文献[6]使用孪生卷积神经网络来对视频帧特征进行提取,通过真实值与预测值之间的误差来训练网络。文献[7]使用预训练的卷积神经网络提取特征,然后使用视觉词袋方法处理提取到的特征。
然而,这些基于单个视频帧的处理方式往往忽略了视频帧之间的时间相关性,损失了时序特征,导致视频特征提取不够充分,影响了检索精度。因此,还需要增加一些后续时间对其进行操作,例如基于霍夫投票的时间对齐[8]和基于时间网络的时间对齐[9]方法。这些操作虽然增加了算法的复杂度,但降低了检索效率。
在进行相似度计算时,相比于图片或者其他多媒体信息,视频信息特征量较大,导致在计算相似度时计算消耗过大,因此对内存和存储空间都有着较高的要求。近年来,哈希方法被广泛运用于各种多媒体信息检索任务中。借助于快速的异或操作,在二进制空间用汉明距离来衡量相似度,处理速度快且内存消耗小。但哈希方法主要还是应用在图片检索领域[10],在视频检索领域的应用还较少[11]。
本文提出一种将三维卷积[12]和哈希方法相结合的视频检索算法,算法的整体框架如图1所示。该算法分为3步:(1)在大型视频数据集上预训练网络,得到一个能有效提取视频特征的三维卷积神经网络;(2)在目标检索数据集下微调网络,使用目标数据集数据来训练加入了哈希层的网络,以便使得网络具备哈希映射能力。随后,将视频特征映射得到二值编码;(3)最后为视频检索阶段。查询视频与待检索视频分别通过网络得到二值编码后,通过在汉明空间计算汉明距离快速得到两个视频之间的相似度,从而进行检索操作。
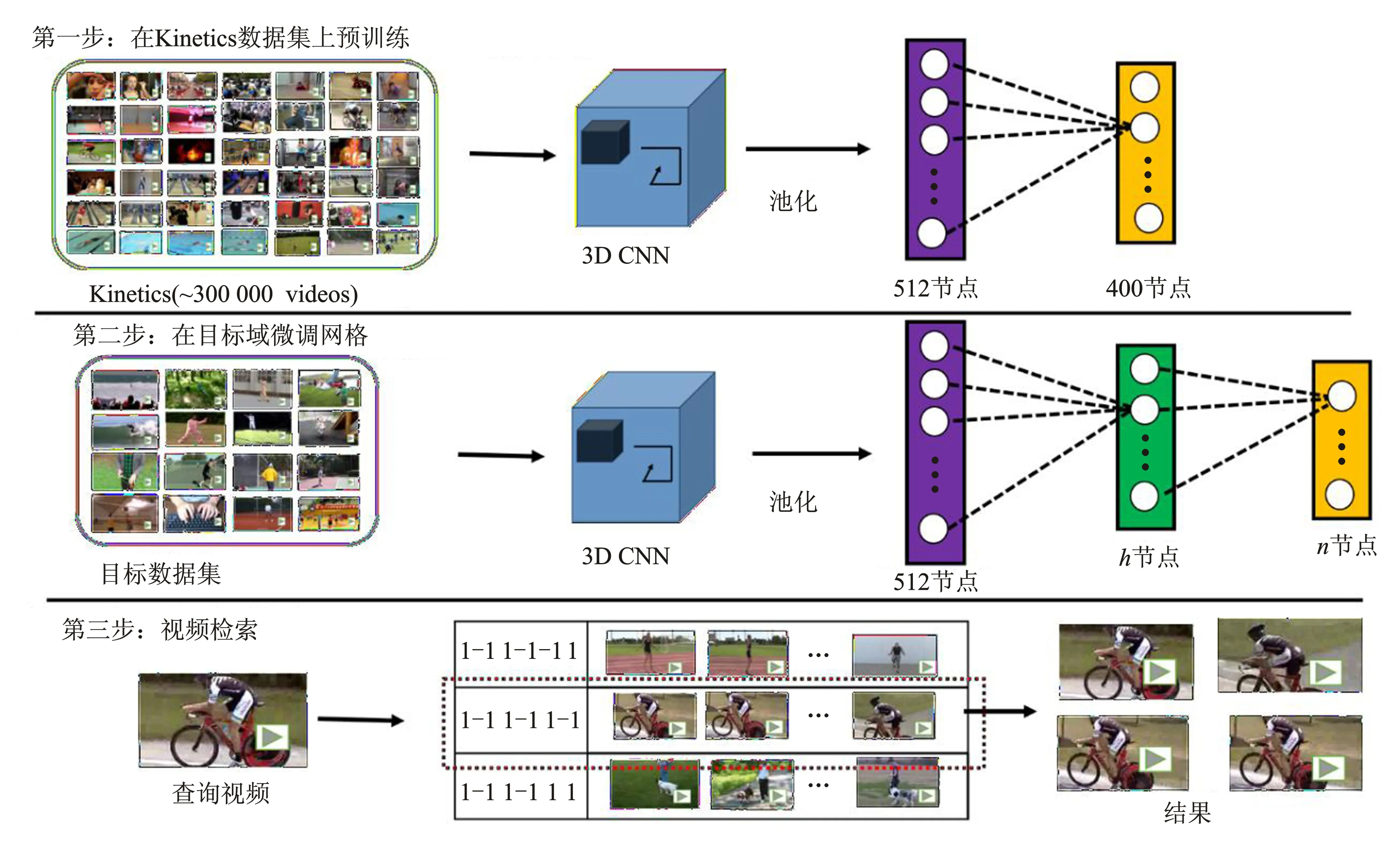
图1 本文视频检索算法整体框架Figure 1. The framework of theproposed video retrieval algorithm
接下来本文将分别介绍视频特征的提取、视频特征编码与视频检索过程中本文应用的一些技术与原理,最后在实验部分验证提出的算法在两个公开视频数据集上的实验效果,并进行实验分析。
1 视频特征提取
使用三维卷积处理视频信息时首先需要从视频中提取出一定量的视频帧。一个视频片段是由一系列视频场景构成。一个视频场景由多个镜头组成,而每一个镜头里包含了多个视频帧,因此视频帧是组成视频的基本单位。一段很短的视频中往往包含着大量的视频帧,相邻的帧之间场景和镜头变化通常较小,所以在对视频进行特征提取操作时,如果对每一帧逐帧提取特征,会导致计算量偏大。
为此,本文将整个视频片段均匀分割成固定个数的视频片段,从每个片段中选出代表帧用于代表视频片段的特征信息,最终由一系列代表帧的特征信息来表示整个视频的信息。图2展示了代表帧的提取方式。使用这种视频帧选择方式能够显著减小计算量。
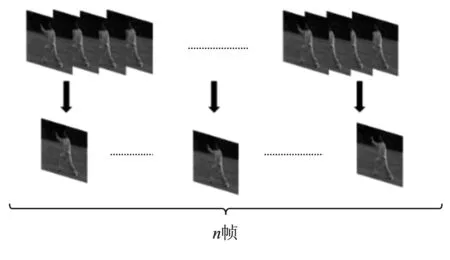
图2 代表帧提取Figure 2. Extraction of representative frame
为了同时提取到视频的时间和空间信息,并保留视频帧之间的时间相关性,本文使用三维卷积神经网络来提取视频特征。如图3所示,三维卷积神经网络和二维卷积神经网络的一个最大不同就是三维卷积神经网络同时作用于多个视频帧,而二维卷积神经网络在提取特征时只作用于单个的图像。图3(a)中,二维卷积的卷积核是二维的,在卷积运算时只在平面上移动,而图3(b)中三维卷积卷核是立体的,在做卷积运算时在时间和空间维度同时进行。按时间顺序采样提取出的视频帧在三维卷积核作用下提取出的特征包含了帧与帧之间的时间关系。通过三维卷积提取出的视频特征不仅包含单个视频帧的特征信息还包含帧与帧之间的时间信息,所以三维卷积神经网络输出的特征能更好地代表原视频信息。

图3 二维卷积和三维卷积(a)二维卷积 (b)三维卷积Figure 3. 2D convolution and 3D convolution(a)2D convolution (b)3D convolution
在面对具体的检索任务时,通常存在整理好的可训练样本不足的问题。即使训练样本充足,从头开始训练一个网络也需要一定的时间,且需耗费大量的计算资源。为了解决这些问题,可采用预训练的卷积神经网络,然后根据实际任务的需要,在目标域微调神经网络的参数。这样既解决了训练样本不足的问题,又能够达到良好的效果。
很多卷积神经网络模型在大型图片数据集ImageNet取得了理想的分类精度,并且预训练的网络模型可以迁移到其他计算机视觉任务中。据此,本文使用了在Kinetic视频数据集上预训练的3D ResNet18[13]三维卷积神经网络。Kinetic数据集包含400类视频,视频总数超过30万,其中每一类视频至少包含400个视频。该数据集涵盖的视频种类丰富,包含人与物的互动、人与人的动作互动等。大规模的视频数据集保证了网络训练的数据量,而多样性的视频样本在一定程度上又保证了网络的泛化能力,为网络在目标数据下微调奠定了基础。
采用残差连接的卷积神经网络在保证网络深度的前提下能防止梯度消失,且ResNet[14](Residual Networks)卷积神经网络模型已经在各种计算机视觉任务中取得了良好的效果。为了更好地提取视频特征,本文采用和ResNet卷积神经网络模型类似的连接方式将三维卷积模块连接到一起。网络的具体结构和参数如表1所示。
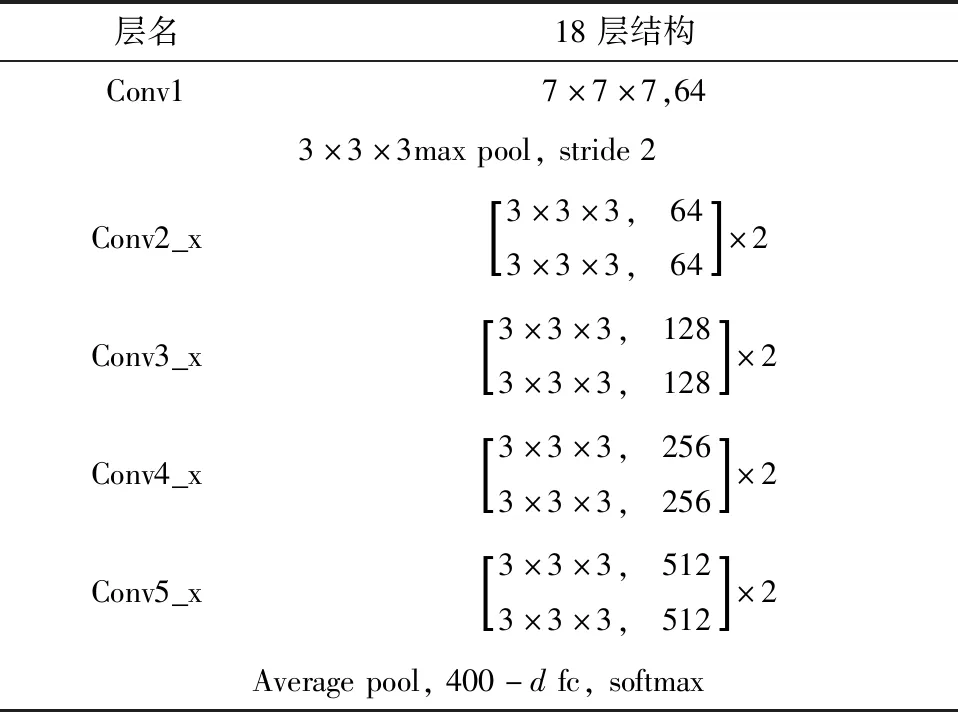
表1 3D ResNet18网络参数Table 1. Network parameters of 3D ResNet18
本文使用在大型数据集上预训练的网络来提取特征,不仅减少了工作量,还解决了数据不足带来的困扰。
2 特征编码与视频检索
为了检索出与查询视频相似的视频,需要计算两个视频之间的相似度。早期方法采用欧氏距离来计算相似度,计算量大,检索效率低下。本文采用哈希方法将视频编码为固定长度的哈希码,在二进制空间中使用汉明距离来计算相似度,精度高且计算迅速。
如图1第2步所示,本文在原始的分类网络分类层之前加入1个哈希层[15],通过1个tanh激活函数将特征映射到[-1,1]之间,从而得到每一个视频的哈希特征。再通过式(1)的sign函数,将特征二值化得到每一个视频对应的哈希编码。
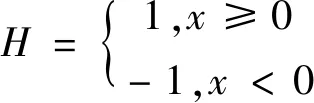
(1)
式中,H代表哈希码的值;x代表经过哈希层激活函数之后的输出值。在网络训练时,本文采用式(2)交叉熵损失函数来训练网络
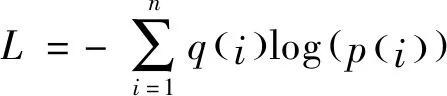
(2)
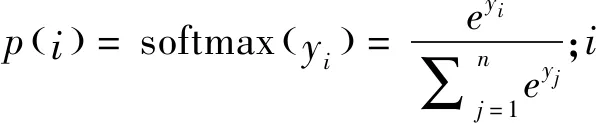
如图1第3步所示,在测试检索阶段,本文直接提取哈希层输出的二值特征作为每一个视频的特征。获得查询视频和数据库中待检索视频对应的二值编码,并在二值空间中使用汉明距离度量两个视频的相似性,例如编码为“1 -1 1 -1-1 1”的视频与编码为“1 -1 1 -1 1 -1”的视频之间汉明距离为2,可以用汉明距离2来度量这两个视频之间的相似性。汉明距离越小则证明两个视频越相似;汉明距离越大,说明视频间相似性较低。这种特征编码方式不需要占用大量磁盘空间来存储神经网络提取出的视频特征,不仅可以提高检索效率,还能减少计算机的内存消耗。
3 实验描述
3.1 实验设置
为了验证所提出算法的效果,本文在两个公开的视频数据集UCF-101[16]和HMDB-51[17]上进行实验。UCF-101由101个类共13 320个视频数据构成。本文从数据集中划分出9 537个视频作为训练集,其余3 783个视频作为测试集。HMDB-51数据集共包含51类共6 766个短视频,本文从中选择出5 100个视频进行实验,其中训练集有3 570个视频,测试集有1 530个视频。
对于每一个视频,本文参照C3D网络结构[18]提取出16帧作为代表特征,每一帧的尺寸都为112×112。为了和已有的一些算法进行比较,本文将视频特征分别映射得到64位、128位、和256位的哈希编码。另外,本文采用了平均检索精度(mAP)作为评价指标。
在训练过程中,本文设置Batch Size大小为60,采用了带动量的随机梯度下降优化方法,初始学习率为0.01,每40个epoch后学习率降低为原来的1/10,一共训练了160个epoch。在测试过程中设置Batch Size大小为120。
3.2 实验结果
为了验证提出算法的性能,本文将新算法分别和两种传统的哈希方法LSH[19]、ITQ[20]以及两种深度学习方法DH[21]、DCNNH[22]进行对比,具体的实验数据如表2~表3以及图4~图5所示。

图4 UCF-101数据集下检索精度对比图Figure 4.Diagram of comparison of retrieval accuracy on UCF-101 data set

图5 HMDB-51数据集下检索精度对比图 Figure 5.Diagram of comparison of retrieval accuracy on HMDB-51 data set
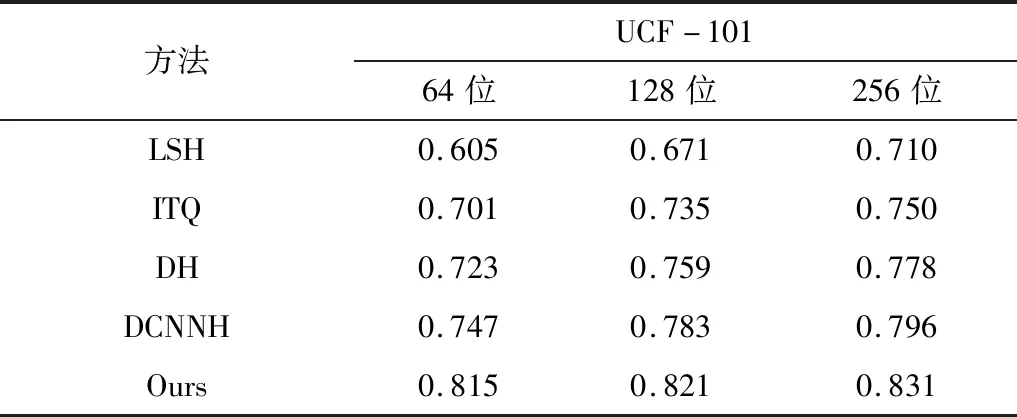
表2 UCF-101数据集下检索精度对比Table 2.Comparison of retrieval accuracy on UCF-101 data set

表3 HMDB-51数据集下检索精度对比Table 3. Comparison of retrieval accuracy on HMDB-51 data set
在UCF-101数据集下的结果表明,本文提出的算法检索精度相较于传统方法及基于深度学习的方法都有明显的提升。和传统的哈希算法LSH和ITQ相比,本文提出的算法在各个哈希位精度的提升都在0.1左右,提升效果明显。同样是使用卷积神经网络来提取特征,相较于DCNNH[21]使用二维卷积神经网络对单个视频帧提取特征,然后加权平均计算得到视频特征的模式,本文使用三维卷积神经网络对多个视频帧进行特征提取,提取精度在哈希码为64、128和256位的情况下分别提升了0.068、0.038和0.035。该结果证明三维卷积神经网络在提取视频特征上相较于其它特征提取方式有一定的优越性,时空信息的保存也更为完整。
本文提出的算法在HMDB-51数据集上同样表现出了较好的效果。和传统哈希方法LSH和ITQ相比,本文算法精度在各个哈希位上的提升幅度都在0.1以上,最高的提升幅度达0.173,最低提升幅度为0.106。本文提出的算法精度也高于使用深度学习方法的DCNNH。此外通过观察哈希码长度与检索精度的关系可以发现随着哈希码长度的增加,检索精度也在增加。这给场景复杂视频和长视频检索提供了一个方向,即可以通过提高采样视频帧的频率,使用更多的视频帧作为代表帧来提高特征表示能力。还可以通过增加哈希编码的长度,在特征维度允许的情况下使用更多的二值编码表征视频信息来提高检索精度。
相较于UCF-101数据集,HMDB-51数据集训练视频更少,却依然能够取得不错的检索效果。该结果证明了使用在大型数据集上预训练的网络,然后在目标数据集上进行微调的方法的可行性。采用这种策略,本文所提方法在省去大量工作的前提下,依然可以得到较好的效果。
4 结束语
本文提出了一种基于三维卷积和哈希方法的视频检索算法。该方法使用三维卷积同时对多个视频帧进行特征提取操作,保留了视频时间信息,使得提取到的特征更具代表性。此外,为了高效地进行检索,本文还引入哈希方法,将视频特征通过哈希层映射得到视频的二值编码,进而快速地计算两个视频之间的汉明距离,从而进行相似度比较。在两个公开数据集上的结果表明,相比以往的方法,本文提出的方法在检索效果上有较大的提升。但是本文所提方法在对视频帧的选取方面还有一些不足,需要继续改进以提高其性能。
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
科学与财富(2017年28期)2017-10-14
中国铁路文艺(2016年6期)2016-05-14
电脑爱好者(2015年13期)2015-09-10
现代电子技术(2009年9期)2009-06-25
