
基于改进竞争深度Q 网络算法的微电网能量管理与优化策略
2022-04-11 06:18黎海涛申保晨杨艳红韩雨庭
电力系统自动化 2022年7期
黎海涛,申保晨,杨艳红,裴 玮,吕 鑫,韩雨庭
(1. 北京工业大学信息学部,北京市 100124;2. 中国科学院电工研究所,北京市 100190)
0 引言
可再生能源发电技术的大规模应用给传统电网的运行和负荷侧的能量管理带来新的挑战。微电网利用其调控性和灵活性可以有效解决该问题,被认为是接纳可再生能源高度渗透的理想平台[1-3]。在运行过程中,微电网既可以并网运行,也可以单独运行,自主利用本地发电和存储能量[4-6]。因此,对运行过程中的微电网进行合理能量管理会带来较高的经济效益。
近年来,学术界对微电网能量管理与优化进行了深入研究。文献[7]针对光伏发电的微电网混合储能系统采用基于粒子群算法进行策略求解,以达到全生命周期费用和买卖电量费用之和最小的目标。文献[8]采用分布式次梯度算法对微电网分布式能量优化管理架构进行能量优化管理策略求解,从而达到关键负荷供电可靠的目的。其他常用的求解方法包括多种群萤火虫算法[9]、随机规划算法[10]和改进非支配排序遗传算法(non-dominated sorting genetic algorithms,NSGA-Ⅱ)算法[11]等。但是,这些算法均是模型预测控制的方法,很大程度上依赖于本领域专家为微电网构建精确的模型和参数,其最后的优化结果取决于不确定因素预测。当不确定性随时间变化时,模型、预测器和求解器必须进行相应的重新设计[12],导致开发成本较高,使得该方法不具备可移植性和可扩展性。
研究人员开始关注强化学习的发展,提出了各种基于强化学习的方法来解决微电网能量管理与优化问题。文献[13]提出一种基于Q 学习的微电网能量管理策略应对储能的效率和可靠性问题,但该文献所采用的Q 学习算法面临着数据使用效率低、维数高、转移函数具有不确定性等问题。文献[14]提出一种基于深度Q 网络算法的微电网能量管理策略求解算法,但该算法的Q 值往往存在被高估的现象,而且应用到微电网能量管理场景中的稳定性还有待提高。文献[15]提出一种基于多智能体的Q学习算法应对不同负荷的能量调度,但多智能体算法存在维度灾难,这意味着当特征数量超过一定值的时候,算法的效果会有所下降。除此之外,基于Rainbow 的深度强化学习算法[16]、深度确定性策略梯度算法[17]和基于贝叶斯网络的双深度期望Q 网络算法[18]等均被采用进行了微电网优化运行的尝试。
为进一步优化微电网的能量管理问题,本文提出一种基于多参数动作探索机制的竞争深度Q 网络算法,并设计神经网络结构,以高效地对微电网进行能量管理与优化,解决文献[13-15]中存在的数据使用效率低下、稳定性不高和维度灾难等问题。
1 系统模型
微电网系统主要由3 个部分组成,分别是分布式发电组件、储能组件和电力负荷组件[19]。本文采用一个可以与主电网进行能量交互的微电网系统,该系统以经济性为目标,根据分布式发电组件的发电功率与电力负荷组件的用电功率,进行系统能量管理优化,具体操作主要包括恒温控制负荷需求响应、价格响应负荷需求响应、从电网购电、向电网售电、储能组件充电和储能组件放电,最终达到系统功率合理分配的目的。
1.1 分布式发电组件
风能、太阳能等清洁能源的应用加剧了能源市场的波动,传统的化石能源占比开始降低。本文采用风力发电机模型和来自芬兰风力发电厂的发电数据[20]。
1.2 储能组件
储能组件的功能主要是对能量进行存储,在微电网能量管理过程中会与主电网、分布式发电组件和电力负荷组件进行能量交互[20]。
1)动态存储容量
储能组件t 时刻的动态存储容量Bt为:

3)充放电情况
储能组件的充放电行为由微电网系统直接控制,并在充放电行为的驱动下,与分布式发电组件、负荷组件进行能量传输。
在充电情况下,储能组件接收存储在电池中的功率,基于最大容量和最大充电率验证充电操作的可行性,进行能量的存储,并将剩余的电能返回给主电网。
在放电情况下,储能组件从微电网系统接收放电请求指令,验证供电条件,并相应地返回可用功率。若负荷所需的功率不能完全由储能组件供应,则会自动由主电网供电。
1.3 电力负荷组件
随着科技的发展,各种新型电力负荷不断涌现。目前,市场上主要由直接可控负荷、恒温控制负荷、价格响应负荷和电动汽车负荷组成[21-24]。本文主要对恒温控制负荷和价格响应负荷进行建模。
1)恒温控制负荷
恒温控制负荷是指空调、热水器、冰箱等需要恒温控制的负荷。这些负荷在每个时刻都被直接控制,且需要微电网分配一定量的电能。
恒温控制负荷由开关动作进行控制,以确保温度限制,t 时刻控制第i 个恒温控制负荷动作ucontrol,i,t的表达式为:

1.4 基于深度强化学习的微电网系统
微电网能量管理与优化可看作一个马尔可夫决策过程,可用状态、动作、状态转移概率和奖励表示为{ s,a,p,r },并利用深度强化学习求解得到最优的策略来控制各组件的运行,从而提高策略运用的可扩展性,避免领域专家重复开发,减少开发成本和维护费用,保证微电网运行的经济效益最大,其中s 为状态,a 为动作,p 为状态转移概率,r 为奖励。深度强化学习在一般强化学习方法基础上结合深度学习发展而来,结合了深度学习的感知能力和强化学习的决策能力,从而使其能够创新地解决复杂系统的感知决策问题。深度强化学习可分为基于值函数的深度强化学习算法和基于策略的深度强化学习算法[25]。基于值函数的深度强化学习算法采用深度神经网络逼近值函数;基于策略的深度强化学习算法通过计算关于动作的策略梯度,沿着梯度方向,不断调整动作,逐渐得到最优策略。本文主要研究基于值函数的深度强化学习算法在微电网能量管理中的运用。
将深度强化学习与微电网相结合进行微电网能量管理,是微电网与人工智能结合的尝试。基于上述微电网各组件定义,下面分析深度强化学习的微电网能量管理与优化模型。在该强化学习模型中,智能体是微电网动作选取的实体,与智能体进行交互的整个微电网运行环境是强化学习定义的环境,电力负荷组件和储能组件的操作是强化学习定义的动作值,微电网中各组件的基本信息是强化学习定义的环境状态值。
智能体从微电网环境接收奖励信号和环境状态信号,其中奖励信号是根据微电网运行规则人为制定的奖励机制,文中t 时刻的奖励rt定义为微电网能量交易的经济成本,即
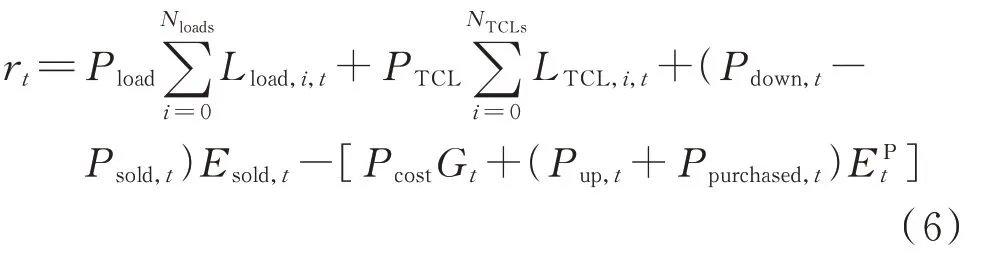
式中:Pload为价格响应负荷的电价,Pload=Pmarketρδt,其中Pmarket为市场电价,ρ 为调整δt的参数;Nloads为价格响应负荷的数量;PTCL为恒温控制负荷的电价;NTCLs为恒温控制负荷的数量;Pdown,t为向主电网卖电的价格;Pup,t为从主电网买电的价格;Psold,t为向主电网卖电的调控价格;Esold,t为向电网卖电的电量;Pcost为分布式发电组件发单位电量的成本值;Gt为分布式发电组件的发电功率;Ppurchased,t为从主电网买电的调控价格;EPt为从电网买电的电量。
环境状态信号是微电网中各组件的基本信息,包括各电力负荷的状态值、储能组件的储能状况、分布式发电组件的功率、电网买卖电量的电价等信息。智能体通过学习环境状态信号完成对应动作,包括确定恒温控制负荷的优先级、确定价格响应负荷对应的价格档位、确定微电网供电方向。当对应动作施加于微电网各组件对应的环境中时,该环境会根据当前动作产生各组件间下一时刻的环境状态值以及该动作对应的奖励值。这些值作用于智能体,如此循环得到最优的策略,具体如图1 所示。

图1 基于深度强化学习的微电网能量管理系统Fig.1 Microgrid energy management system based on deep reinforcement learning
2 基于改进竞争深度Q 网络算法的能量管理策略
基于上述系统模型,提出改进竞争深度Q 网络算法寻找累计奖励最大的微电网能量管理策略。学习过程中,改进竞争深度Q 网络算法中的智能体通过接受当前环境的状态值来执行当下的最佳动作,形成完美的闭环控制。
传统竞争深度Q 网络算法把原深度Q 网络算法的输出分为静态环境状态的值函数和动态选择动作额外带来的优势函数[26],其优点是学习到对智能体最重要的状态,而无须了解每个动作对每个状态的影响,可以快速识别最佳动作。Q 网络算法的输出由价值函数网络输出和优势函数网络输出的线性组合得到,表达式为:

为解决竞争深度Q 网络算法在动作探索方面的不足和学习过程中稳定性低的问题,本文在动作探索机制上进行优化。
2.1 多参数动作机制
大部分基于值函数的强化学习算法采用ε-贪婪算法来选取最优动作。采用ε-贪婪算法的智能体以高概率选择Q 值最大的动作,以低概率选择随机动作。考虑到智能体执行动作产生的奖励是对该动作的评判。若利用当前时刻的奖励值与迭代时长内平均奖励值作为一个基准参数进行下一时刻的动作选取,则会有更高概率探索到可能的最优动作。因为其不单单是通过ε 概率进行探索,还会通过一个新的概率参数进行探索。这样虽然降低了随机探索的概率,但是增加了不同动作类型选取的概率。
定义新参数λ 并结合参数ε 来计算下一时刻动作选取的概率,称之为多参数动作探索。

式中:σ1和σ2为调整参数λ 的系数。
然后,结合ε-贪婪算法中的ε 值,计算在不同概率情况下如何选取下一时刻的动作值a't。因此,选取下一时刻的动作有3 种可能性。当概率为λ 时,选取当前时刻动作at作为下一时刻的动作a't;当概率为ε/|A|时,随机选取一个动作arandom作为下一时刻的动作a't;当概率为1-λ-ε 时,选取Q 值最大的动作arg max Q(s,at)作为下一时刻的动作a't。
最后,把选取的动作应用到微电网环境中,以此来学习新的策略。
结合多参数动作探索机制,改进竞争深度Q 网络算法的流程图如附录A 图A1 所示。
2.2 神经网络结构设计
深度Q 网络算法和竞争深度Q 网络算法中会使用双深度神经网络结构,采用2 个Q 网络算法进行交互的形式。当前网络用来选择动作,更新模型参数;目标网络用于计算目标Q 值。目标网络的网络参数不需要迭代更新,而是每隔一段时间从当前网络中复制过来,进行延时更新,从而减少目标Q值和当前Q 值的相关性。本文改进竞争深度Q 网络算法在使用双深度神经网络结构时,运用卷积层、池化层和全连接层进行神经网络结构设计,从而更好地提取特征信息。
在进行神经网络结构设计过程中,采用输入层、隐藏层和输出层分模块设计的原则。输入层由神经元组成,对应输入的环境状态。隐藏层设计为卷积层、池化层和全连接层的相互配合,经输入层输入数据后,利用2 个卷积层对数据进行卷积处理,该卷积层采用n×n 的卷积核,但卷积核的大小依次递减;从卷积层输出数据后,通过全局平均池化层进行数据池化处理。然后,将数据通过全连接层输出到2 个子网络里。在子网络设计过程中,价值函数网络和优势函数网络分别采用2 层全连接层,价值函数网络设计为2 个输出,其输出均采用全连接层,神经元个数分别为对应可选择的策略数,优势函数网络全连接层的神经元个数满足对应可选择的策略数。最后,经式(8)运算后从输出层输出,该层神经元个数对应可选择的策略数。
2.3 能量管理策略生成与运行
在改进竞争深度Q 网络算法的能量管理策略生成过程中需要依赖大量数据,本文选取微电网历史运行数据构建训练集和测试集。该数据集包含不同的运行场景,主要包括恒温控制负荷所需的温度值、价格响应负荷所需的负荷值、风力发电的发电值、电量交易市场的交易价格等,具有环境状态覆盖全面的特点。
实际策略运行过程中,微电网能量管理决策分为离线系统和在线系统2 个部分。离线系统库存储微电网运行历史事件和动作记录,对微电网运行控制进行离线仿真,利用历史数据累计完善数据集,通过离线训练方法,对利用改进竞争深度Q 网络算法的智能体进行训练,更新智能体模型和参数,供在线运行的智能体使用。在线系统为实时运行系统,智能体根据微电网反馈的状态变量和奖励值,输出控制指令,微电网根据控制指令运行,并将更新的状态和奖励值反馈给在线智能体,同时存储在离线系统库。在线系统利用离线系统训练好的智能体模型,可以在秒级时间完成计算,保证微电网能量管理的实时性,其详细运行过程如图2 所示。
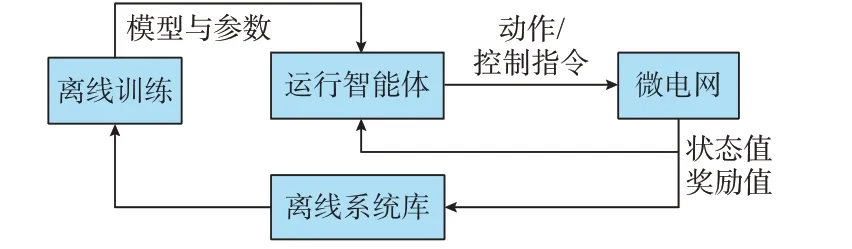
图2 微电网能量管理策略生成与运行过程Fig.2 Process of generation and operation of microgrid energy management strategy
3 算例分析
3.1 仿真环境设置
本文采用的风力发电数据和电力负荷数据来源于文献[27]的数据库中,数据样本每隔1 h 采集一次,包含了2 年的分布式发电组件和电力负荷组件的特征信息。设置的微电网环境主要参数包括:Bmax=500 kW,储能组件最大充电功率cmax=250 kW,储能组件最大放电功率Dmax=250 kW,Pcost=32 欧元/MW, NTCLs=100, Nloads=150,Pmarket=5.48 欧元/MW。
本文设计的神经网络结构参数如下:输入设计为107 个神经元,对应107 个环境状态,分别是100 个恒温控制负荷的功率信息、价格响应负荷的整体功率信息、价格响应负荷的价格水平信息、时间信息、储能组件的荷电状态信息、分布式发电组件的发电信息、从电网购买电量的电价以及向电网销售电量的电价,这107 个输入数据也是算法实际应用中的数据。2 个卷积层分别采用4×4 和2×2 的卷积核;从卷积层输出数据后,通过全局平均池化层进行数据池化处理。然后,将数据通过神经元个数为100 的全连接层输出到2 个子网络里;在子网络设计过程中,价值函数网络和优势函数网络分别采用2 层全连接层,价值函数网络全连接层的神经元个数分别为80 和1,优势函数网络全连接层的神经元个数均为80。输出层设计为80 个神经元,对应80 种动作组合,分别是恒温控制负荷对应的4 个优先级动作,价格响应负荷对应的5 个价格水平动作,电量过剩时确定向电网卖电或储能组件存储电量动作,电量短缺时确定电网供电或储能系统供电动作,一共有4×5×2×2=80 种组合动作。
3.2 实验结果及分析
在仿真环境中,分别利用深度Q 网络算法和竞争深度Q 网络算法以及基于多参数动作探索机制的改进竞争深度Q 网络算法进行训练,得到奖励值变化曲线如图3 所示。为了在图中更好地表示,将式(6)的奖励值进行了小数点左移3 位的处理。

图3 不同算法奖励值对比Fig.3 Comparison of reward values of different algorithms
由图3 可知,改进竞争深度Q 网络算法比深度Q 网络算法和传统竞争深度Q 网络算法具有更好的学习稳定性,并且得到的奖励值更高,主要是由于其采用了多参数动作探索机制。
图4 给出了微电网能量管理后得到的10 d 经济收益总和对比,除深度Q 网络算法、竞争深度Q 网络算法和改进竞争深度Q 网络算法外,还对比文献[10]中的随机规划算法。由图可知,采用改进竞争深度Q 网络算法进行微电网能量管理后所得到的经济收益高于另外3 种算法,该方法较基于场景的随机规划算法在策略控制上有了明显提升,并且在实际应用中,智能体可以根据历史数据不断学习,提前训练,实际控制时可直接使用,不存在收敛问题。
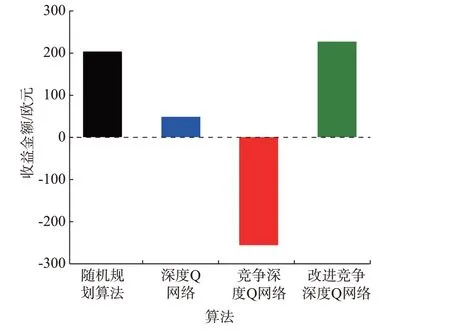
图4 不同算法经济收益对比Fig.4 Comparison of economic benefits of different algorithms
此外,针对第2.1 和2.2 节的改进,单独设置了实验,分别验证了改进前竞争深度Q 网络算法、只改进第2.1 节的竞争深度Q 网络算法、只改进第2.2 节的竞争深度Q 网络算法和同时改进第2.1 和2.2 节的竞争深度Q 网络算法,对比结果见附录A图A2 和图A3。
对采用竞争深度Q 网络算法与改进竞争深度Q网络算法的连续10 d 的每日经济收益进行对比如图5 所示。
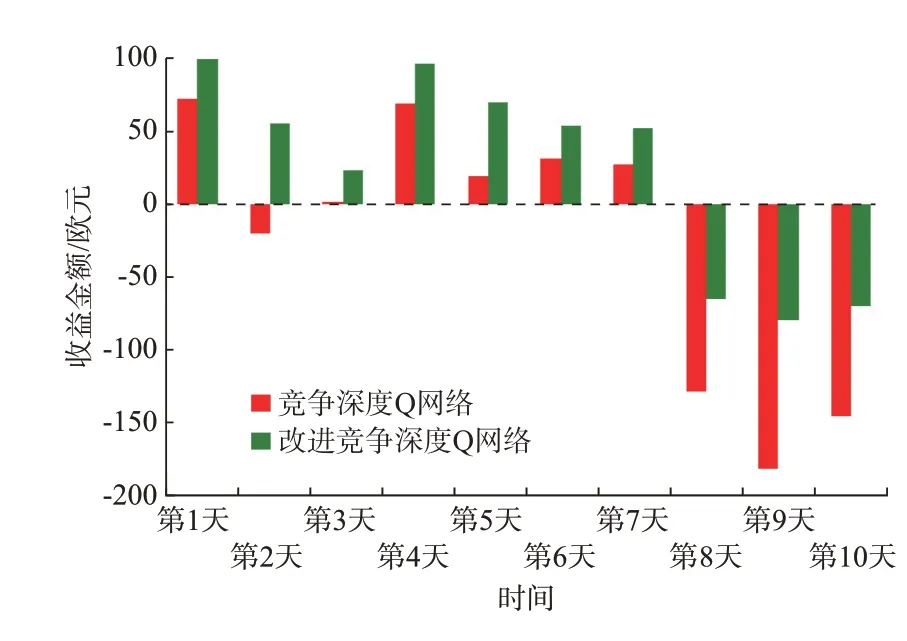
图5 竞争深度Q 网络算法改进前后经济收益对比Fig.5 Comparison of economic benefits before and after dueling deep Q network algorithm is improved
由图可知,在微电网能量管理过程中,改进竞争深度Q 网络算法每天的收益都优于改进前竞争深度Q 网络算法,具有更优的能量控制策略。此外,在第8、9、10 天,竞争深度Q 网络算法得到的收益值是远小于0 的。这是图4 中竞争深度Q 网络算法得到10 d 经济收益总和为负值的主要原因,也间接说明直接使用竞争深度Q 网络算法在第8、9、10 天的微电网能量管理场景中,能量控制策略不佳。
利用改进竞争深度Q 网络算法对不同发电和用电预测情况下的微电网进行能量管理。根据各组件与电量交易的3 种状态进行分析,具体如下:
1)风力发电组件运行过程中产生的发电功率与用电负荷处于一种均衡状态时,电力负荷组件和风力发电组件的预测曲线如附录A 图A4 所示。经过改进竞争深度Q 网络算法调节后,各电力负荷组件状态如附录A 图A5 所示,恒温控制负荷在07:00—23:00 时段随发电功率的减少会逐渐减少用电功率。储能组件在03:00—06:00 时段进行充电操作,在13:00—18:00 时段进行放电操作,其荷电状态和充放电功率如附录A 图A6 所示。当功率值为正时,表示充电操作;功率值为负时,表示放电操作。能源交易市场有电量出售和电量购买2 种操作,其中购买价格是Pup,t+Ppurchased,t,销售价格是Pdown,t-Psold,t,销售价格和购买价格随电量交易进行变化,如附录A 图A7 所示。
2)当风能发电功率小于用电功率时,电力负荷组件和风力发电组件的预测曲线如附录A 图A8 所示。经改进竞争深度Q 网络算法调节后,各电力负荷状态如附录A 图A9 所示。此时,储能组件在04:00—08:00 时段进行充电操作,在13:00—17:00时段进行放电操作,如附录A 图A10 所示。由于风力发电组件发电功率无法满足电力负荷的需求,因此,能源交易市场以购买电量为主,交易价格与交易电量的关系如附录A 图A11 所示。
3)当风能发电功率大于用电功率时,电力负荷组件和分布式发电组件的预测曲线如附录A 图A12所示。经改进算法调节后的各电力负荷状态如附录A 图A13 所示。此时,储能组件在00:00—02:00 时段进行充电操作,在16:00—22:00 时段进行放电操作,如附录A 图A14 所示。由于电力负荷消耗低于风力发电组件发出的电量,能源交易市场以出售电量为主,交易价格与交易电量的关系如附录A 图A15 所示。
综合上述数据表明,通过改进竞争深度Q 网络算法对微电网进行高效的能量管理,可以快速地解决用电优化问题。同时,微电网可以合理地与电网进行电量交易,提高经济收益,也可以充分利用可再生能源,间接减少电网配电过程中的电量损耗。
4 结语
微电网是应对可再生能源灵活接入和变化电力负荷的有效方式。为应对这种波动性和不确定性,本文提出一种基于多参数动作探索机制的改进竞争深度Q 网络算法,进行微电网能量管理与优化。通过场景仿真,验证了算法的可行性和有效性,并得出以下结论:
1)本文提出的改进竞争深度Q 网络算法最大特点是能够应对不断变化的微电网环境,通过多参数动作探索机制,输出更优的调整策略,且具有更好的稳定性。
2)利用改进竞争深度Q 网络算法进行微电网的能量管理,可以为微电网运行提供更具有经济效益的方案,从而达到获得最大经济收益的目的。
虽然深度强化学习算法在微电网能量管理领域得到了初步研究,解决了策略运用不可扩展、领域专家重复开发、开发成本和维护费用过高的问题,但由于其学习过程中较长的训练时长以及对训练数据依赖较大,解决上述问题也是未来的研究工作,以更好地把深度强化学习应用到微电网能量管理中。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
能源工程(2022年2期)2022-05-23
煤气与热力(2021年6期)2021-07-28
煤气与热力(2021年4期)2021-06-09
无线互联科技(2020年10期)2020-08-14
装备制造技术(2019年12期)2019-12-25
现代企业文化·综合版(2017年5期)2017-06-14
人生十六七(2015年26期)2015-08-22
小说月刊(2015年9期)2015-04-23
营销界(2015年22期)2015-02-28
中国管理信息化(2015年23期)2015-01-02
