
基于时空卷积神经网络的数据缺失交通流预测
2022-04-08 03:43:02张壮壮屈立成张明皓李昭璐
计算机工程与应用 2022年7期
张壮壮,屈立成,李 翔,张明皓,李昭璐
长安大学 信息工程学院,西安 710064
作为智能交通系统的基础,交通流预测在路径规划和出行诱导等方面正在发挥着越来越重要的作用[1]。有效的交通流预测不仅可以为交通管理部门提供有力的决策支持,还可以为出行者提供及时的路况信息,从而避免交通拥堵,节约出行时间[2]。
为了对交通运行状态进行更加准确地感知,各种类型的交通检测装置正在被广泛地安装与使用,越来越多的交通状态数据被统一收集和储存,极大地推动了以深度学习为代表的数据驱动型交通流预测算法的蓬勃发展[3]。如刘明宇等人[4]使用基于门控循环单元(gated recurrent unit,GRU)的递归神经网络,利用交叉验证法进行了交通流预测。戢晓峰等人[5]利用深度学习理论建立了LSTM-SVR预测模型实现交通流预测。Li等人[6]将交通流建模表示为有向图上的扩散过程,并且引入扩散卷积循环神经网络(DCRNN)进行交通预测。刘钊等人[7]提出了一种混合预测模型(KNN-SVR),利用K近邻方法的搜索机制,重建与当前交通状态近似的历史交通流时间序列,结合支持向量回归模型的特征实现短时交通流预测。这些预测模型使用大量历史数据进行训练,挖掘交通流数据之间的隐含关系并实现交通流状态预测功能,但是在实际使用时均需要保障用于预测的数据序列的正确性和完整性,所以也就无法应对数据缺失情况下的预测场景。
由于数据缺失会对预测结果产生巨大的影响,现实中的交通检测装置却常常会因为供电、通信等原因不可避免地产生数据缺失或传输错误,从而导致预测模型的精度下降甚至失效,因此保障预测数据的完整性和连续性就显得非常重要。交通数据中的缺失值可以通过数据插补方法来进行处理[8],如平均值法、张量法等。平均值法是将某个变量的缺失值替换为该变量的对所有观测值的平均值[9],该方法隐式地假设变量间彼此独立并且服从正态分布,而不考虑属性之间的内在关联结构。张量法通过引入张量模式对交通数据进行建模[10],采用一种高效的张量方法完成高精度张量补全,并推导缺失的序列数据。很多学者使用这些方法进行带有缺失值的交通流预测。如Chen等人[11]将贝叶斯矩阵分解模型扩展到一个高阶案例,用于了解时空交通数据中的基础统计模式-贝叶斯高斯CANDECOMP/PARAFAC(BGCP)张量分解模型。何领朝等人[12]提出了一种基于自适应秩动态张量分析的算法来进行短时交通流预测。Cui等人[13]提出了一种用于时空数据预测的图马尔可夫网络(GMN)来同时处理缺失值和预测交通状态。Whitlock等人[14]开发马尔可夫链蒙特卡罗(Markov chain Monte Carlo)方法用于提供缺失序列的预测,进而用于生成其他序列中的一些预测。这类方法通常需要覆盖很长一段时间的大型数据集才能获得良好的插补性能,但是这类大型数据集并不总是可用,大多数的交通预测模型都要求在预测之前先对历史数据进行插补操作以提高预测的精确程度,但当前的插补方法多集中于解决少量随机发生的数据缺失,无法应对数据长时间连续缺失的状况。根据连续数据缺失的补全进行交通流预测仍然是一个热点研究领域。
考虑到路网中检测器之间的时空关系和交通流的连续特性,以及交通流状态数据的周期性和随机性特征,本文提出了一种利用时空卷积神经网络(spatialtemporal convolutional neural network,ST-CNN)进行多种数据缺失情况下的路网交通流预测方法。通过构建路网时空矩阵,体现观测点横向分布的时间相关性和纵向分布的空间相关性,并通过掩码矩阵来标记交通状态数据的缺失情况,利用卷积神经网络提取整个路网交通状态的分布特征和依赖关系,实现在数据连续缺失情况下的交通流预测,这对于交通流时间预测的发展有很大优势。
1 时空卷积神经网络模型
时空卷积神经网络模型框架如图1所示。为了能够使预测结果更有效,本文使用时空卷积神经网络模型,首先输入历史数据,根据时空矩阵和掩码矩阵来标记路网数据的缺失情况,然后使用时空卷积神经网络模型进行模型训练,提取交通流特征,最后根据其交通流特征进行交通流预测。

图1 时空卷积神经网络模型框架Fig.1 Framework of spatial-temporal convolutional neural network model
1.1 时空序列矩阵
时空序列矩阵主要从时间和空间两个维度进行构建[15]。时间主要是前后顺序的记录,空间主要是检测器位置的记录,根据检测器在特定时间记录的有关车辆速度和位置的特定信息,估算每个路段的时空交通信息,并将其进一步集成到时空矩阵中,成为时空图像。
在时间维度上,时间通常从一天的某个时间点开始到第二天的时间点开始,进而确保时间的完整性,并通过给定的时间间隔Δt收集交通流数据,例如,5 min、15 min和60 min,具体取决于检测器设备的采样分辨率。为了获得更有效的交通数据并使交通预测更加有效,可以对这些数据进行汇聚来选取更合适的时间间隔,例如10 min、15 min等。
在空间维度上,所选的上下游检测器位置被视为具有内部状态的点序列,包括交通状态、平均速度等。由于点序列中的许多区域都是稳定的,并且缺乏多样性,数据密集或不足都将影响交通流量预测的准确性。因此,为了使纵轴有意义,将点分为多个部分,每个部分代表相似的交通状态。根据检测器在道路上的位置,对检测器进行空间分类,将其装入纵轴,同时,为该段选择合适的时间,将其装入横轴,然后用矩阵表示状态,最后生成图像。图2中显示了路网中的检测器、交通状态数据、时空矩阵和最终生成的图像之间的关系。
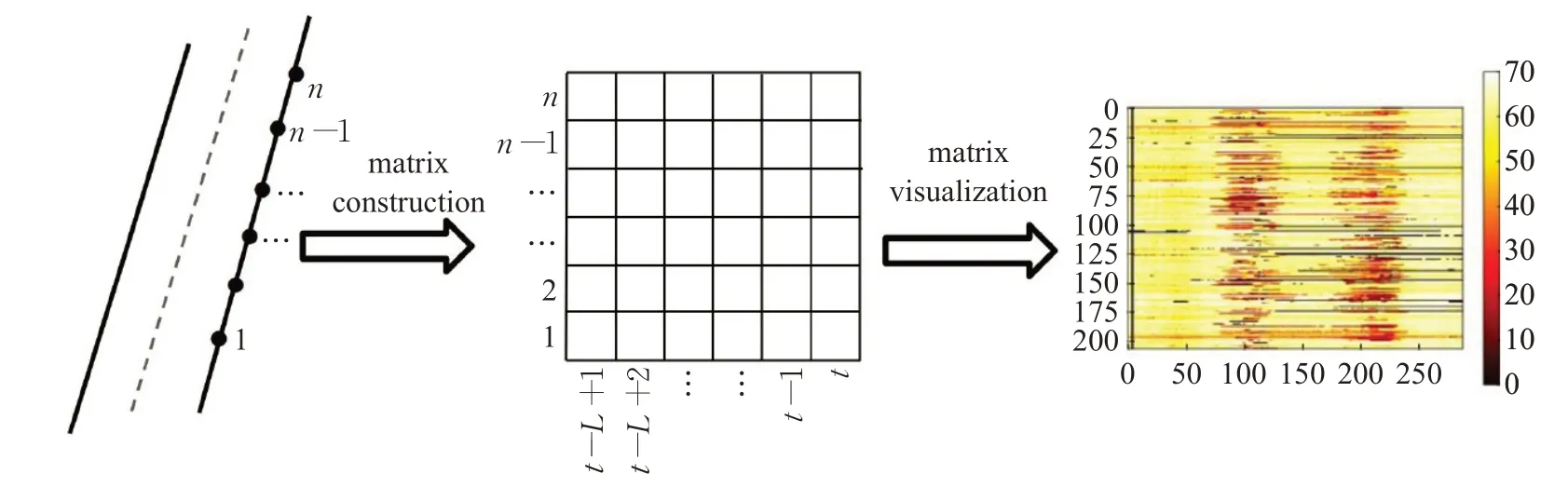
图2 交通状态时空矩阵的构建与可视化Fig.2 Construction and visualization of spatial-temporal matrix of traffic state
最后,可以根据时空维度信息构建时空矩阵。在数学上,通过以下方式表示时空矩阵x t:

式中,是第n个检测器在t时刻的交通状态,n是检测器的数量,n∈ℕ*,t是时间点,L为时间序列的长度。
1.2 缺失掩码矩阵
掩码是指用一串二进制数字,通过与目标字段进行位与运算,达到屏蔽指定位的目的,掩码矩阵不仅可以模拟数据的缺失,还可以区分缺失值和真实数据的情况。在空间状态下,可以使用掩码矩阵来表示数据的缺失状态。在复杂的实际环境中,可能无法对历史数据进行数据插补并顺序预测未来的交通状态,因为当交通状态数据量巨大且设备的计算能力受到限制时,它将无法应付长期连续的数据丢失。在这些情况下,可以使用掩码矩阵来表示缺失值。交通状态数据可以通过使用检测器检测车辆来收集。当检测器发生故障或未检测到车辆通过道路时,收集的交通状态数据可能会出现缺失值。由于交通网络是一个动态系统,在车辆的运动过程中,各个环节的状态不断变化,在收集的交通数据中存在缺失值时,使用一系列掩码矩阵m t∈ℝ1×n,其中m t表示交通状态序列x t中缺失值的位置。掩码矩阵的某一个元素可以表示为:
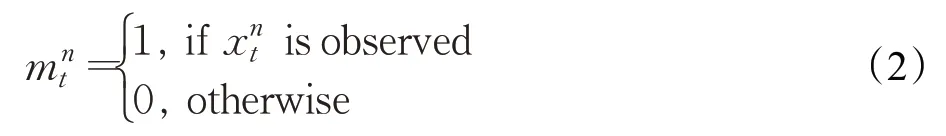
1.3 卷积神经网络
完整的卷积神经网络主要由模型输入、特征提取、预测和模型输出四部分构成。如图3所示,首先将检测器所捕获的数据根据掩码矩阵和时空矩阵的特征输入模型,通常将模型的输入数据表示为在t时间有一个交通时间序列矩阵,以下表示的是模型输入矩阵X t,如下所示:

图3 时空卷积神经网络模型Fig.3 Spatial-temporal convolutional neural network model

流量序列数据的范围是从t-L+1到t。时间序列以时空矩阵x t和掩码矩阵m t的形式集成,其次是通过卷积层和池化层进行交通状态特征的提取,在进行模型训练前首先要初始化卷积层和输出层的卷积核即权重和偏置。卷积层的参数是一些滤波器的集合,可以提取多个交通流量特征,也可以看作是神经元的输出,通过权值共享可以降低参数的数量,以提取更高层次和更抽象的流量特征。其卷积操作可表示为如下:

其中,σ是激活函数,进行卷积操作,是第l个时间单位在r个检测器的交通状态,r∈[1,m],l∈[1,n],为权重,b l为卷积层的偏差。
接下来是池化层,其目的是为了简化卷积层的输出,降低数据体的空间尺寸。其池化操作可表示为如下:
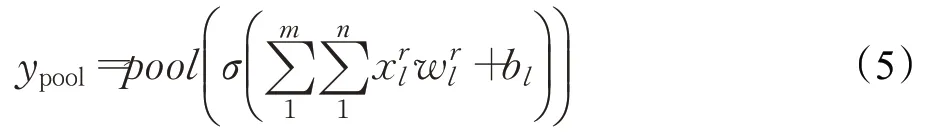
最后通过一个全连接的层将该向量转换为模型输出,因此,模型的输出可以表示为:
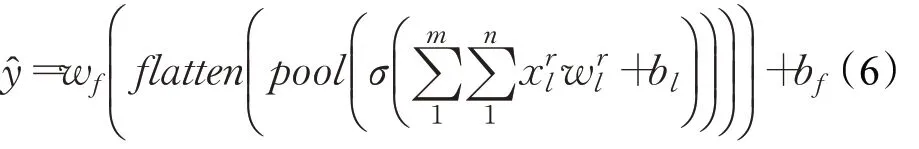
其中,w f和b f为全连接层的权重和偏差,ŷ是预测的交通流量。
该模型的目标是找到一个映射函数,以满足ypool到ŷ之间的转换,并输出预测结果,其中变量的定义和范围与上述变量相同。由于输入数据的不同维度,例如小时通常在0到23之间,而交通速度通常限制在60 m/s左右。
2 实验分析
实验选取METR-LA和PEMS-BAY两个真实的数据集来对模型的性能和效率进行评估[6],METR-LA交通数据集包含从洛杉矶县高速公路上的线圈检测器产生的交通状态数据,收集了从2012年3月1日至2012年6月30日的4个月的实验数据。PEMS-BAY数据集由加州运输机构(加州跨线)性能测量系统收集,收集了2017年1月1日至2017年5月31日的6个月的实验数据。由于这两个数据集规模较大,数据比较全面,交通流状况复杂,具有一定的代表性,是交通流预测的理想选择。在本实验中将数据集分为训练集、验证集和测试集,各个数据集所占比例为6∶2∶2。
2.1 评估指标
所有测试模型的预测准确性均通过3个指标进行评估,包括平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)。计算公式如式(7)~(9)所示[4]:
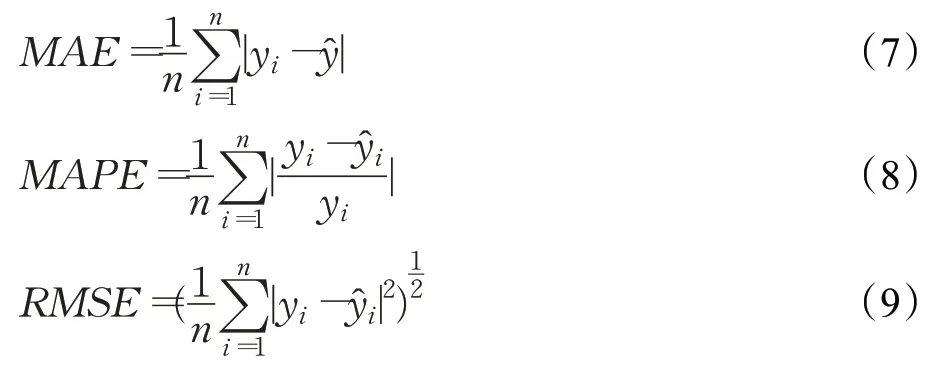
其中,yt是t时间点交通数据的真实值,是同一时间点的预测值,n表示捕获的交通数据量个数。
2.2 模型参数
在卷积神经网络模型中,学习率、批量大小、训练迭代次数等参数的选择对实验结果有很大的影响。学习率决定了模型中权值更新的速度,批量大小为模型训练过程中的一次处理的样本的数量,迭代次数表示在一个训练集上学习的次数。经过多次预训练和优化调整,将学习率设置为0.01,批量大小设置为64。在本文实验中,所提出的模型在METR-LA数据集上迭代90次时学习误差趋于稳定,在PEMS-BAY数据集上迭代110次时误差指标趋于稳定。
2.3 数据缺失模拟
PEMS-BAY和METR-LA数据集最初存在缺失值,其缺失值百分比分别为0.003%和8.11%,为了测试模型在不同缺失率情况下的性能表现,在数据集原始缺失的基础上,根据特定的缺失比率将数据集中的部分数值随机设置为零,并相应地生成掩码矩阵进行图像模拟。使用这两个数据集进行数据随机缺失和连续缺失的模拟。
PEMS-BAY数据集数据随机缺失模拟如图4所示,图(a)表示数据随机缺失率为10%的图像,图(b)表示数据随机缺失率为20%的图像,图(c)表示数据随机缺失率为30%的缺失情况的图像。图像中黑色的像素点表示数据缺失情况,在图像中随机分布的黑色像素点表示为离散分布,从图中可以看出随机缺失率越大,图像中的黑色像素点越多。
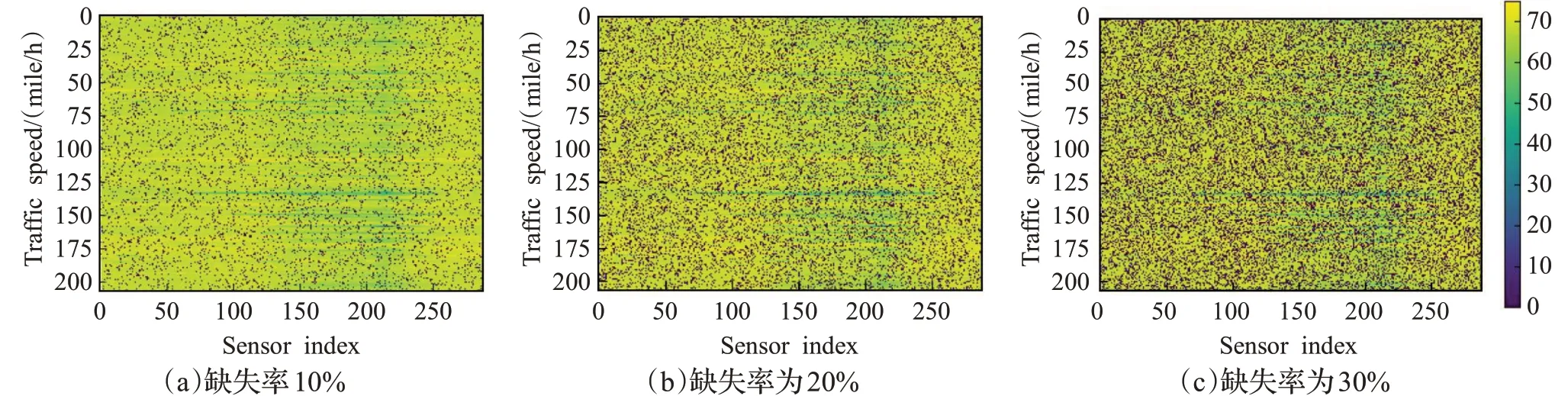
图4 PEMS-BAY数据集随机缺失数据模拟结果Fig.4 Simulation of random missing data in PEMS-BAY dataset
METR-LA数据集连续缺失的数据模拟如图5所示,图(a)为数据连续缺失率为10%时的图像,图(b)表示数据连续缺失率为20%时的图像,图(c)表示数据缺失率为30%时的图像,从图像中黑色像素点的分布情况可以看出,当数据时连续缺失时,图像中的黑色像素点表示为线性分布,数据连续缺失率越大,图像中呈现为黑色的像素点越多。
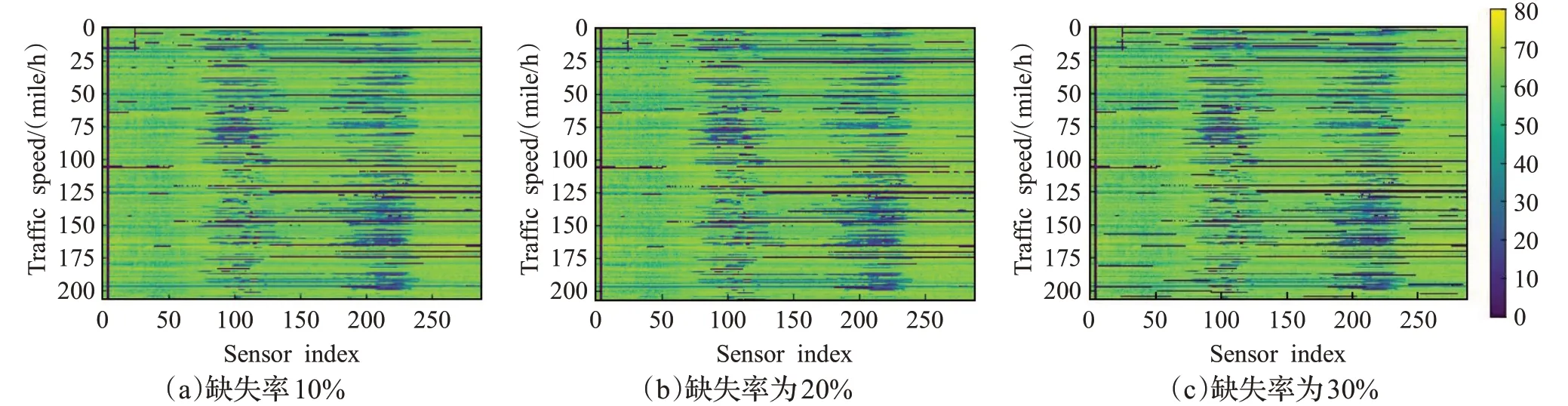
图5 METR-LA数据集连续缺失数据模拟结果Fig.5 Simulation of continuously missing data in METR-LA dataset
2.4 不同日期的交通流预测
选取PEMS-BAY数据集中的测试数据输入到训练好的ST-CNN模型中,生成预测结果,将2017年2月和3月的数据集用作训练集;2017年4月和5月的数据用作模型优化的数据集;2017年6月的数据作为测试集。2017年6月23日(工作日)的预测和评估结果如图6(a)所示,2017年6月25日(非工作日)的预测和评估结果如图6(b)所示。其中图6(a)的上部表示的是周内的预测结果和真实值的曲线拟合图,下部表示的是每个时间点的预测值和真实值的绝对误差(AE);图6(b)的上部表示的是的是周末的预测结果和真实值的曲线拟合图,下部表示的是每个时间点的预测值和真实值的绝对误差(AE)。
从图6中可以看出,工作日和非工作日的交通流量有些差异,但使用ST-CNN模型可以很好地识别出其发展的规律和特征,其交通流的预测结果在真实值周围的波动幅度较小,并且其绝对误差最大为3 mile/h,预测误差的绝对值在合理的范围之内。
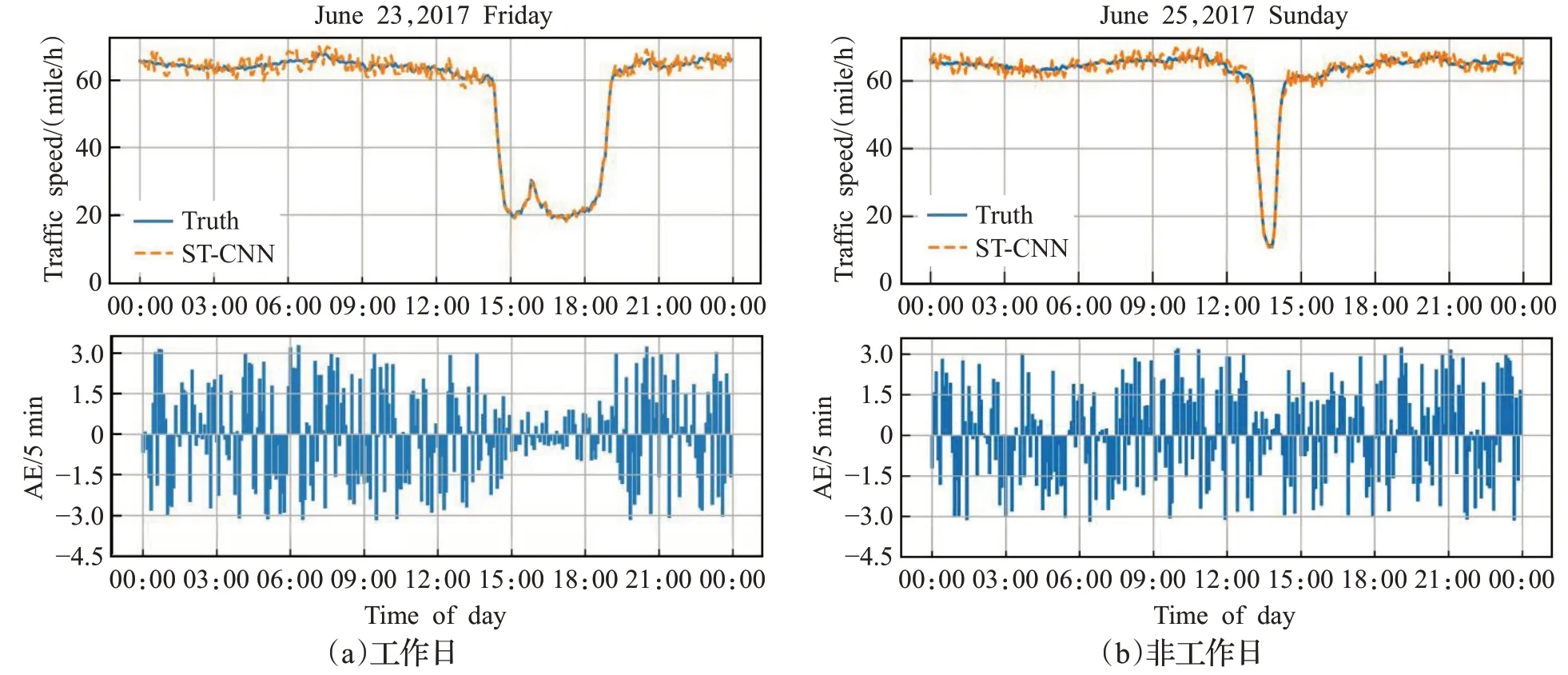
图6 不同日期交通流预测结果Fig.6 Traffic flow speed prediction results of different dates
2.5 不同位置的交通流预测
选取PEMS-BAY数据集中的测试数据输入到训练好的ST-CNN模型中,生成预测结果,将2017年2月和3月的数据集用作训练集;2017年4月和5月的数据用作模型优化的数据集;2017年6月的数据作为测试集。2017年6月23日12:00(工作日)的不同检测器上的交通流的预测和评估如图7(a)所示,2017年6月25日12:00(非工作日)的不同检测器上的交通流的预测和评估如图7(b)所示。其中图7(a)的上部表示的是的是周内的预测结果和真实值的曲线拟合图,下部表示的是每个时间点的预测值和真实值的绝对误差(AE);图7(b)的上部表示的是的是周末的预测结果和真实值的曲线拟合图,下部表示的是每个时间点的预测值和真实值的绝对误差(AE)。
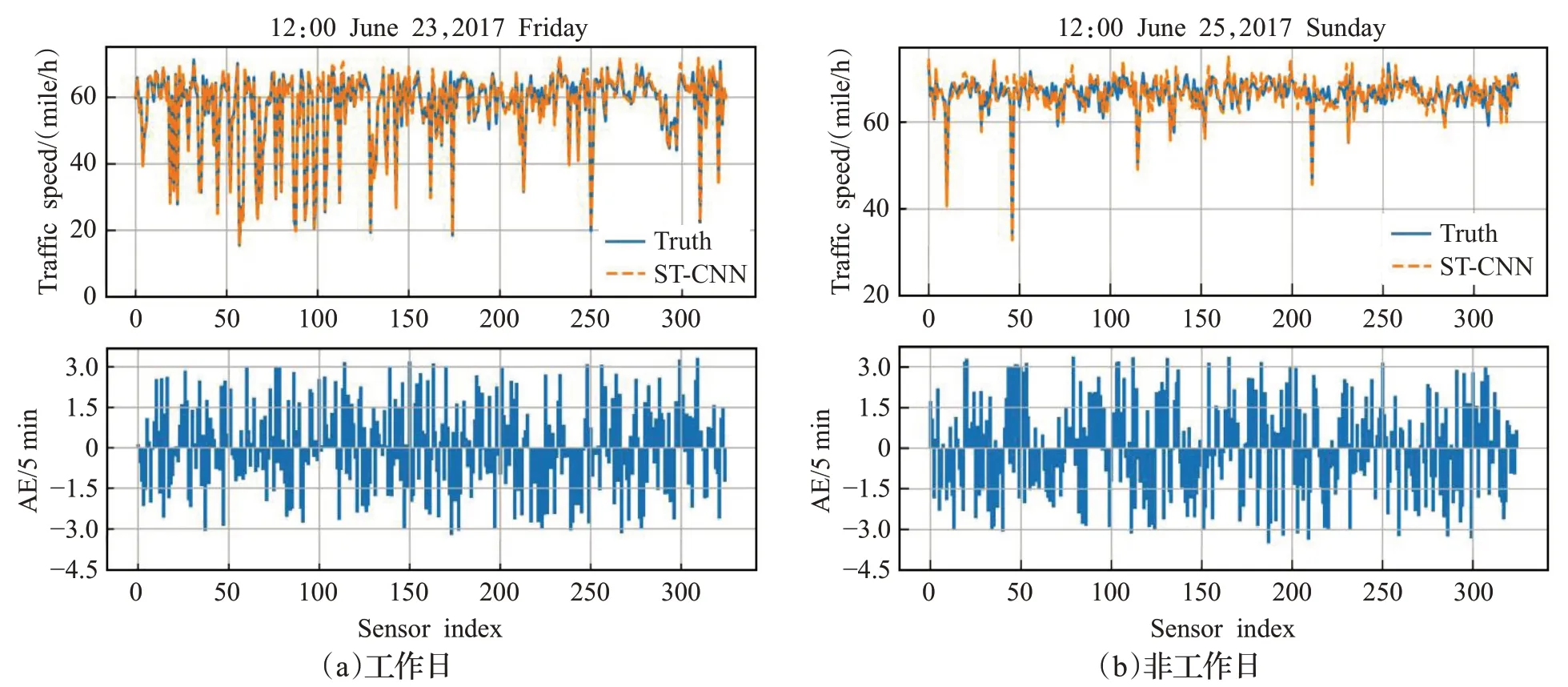
图7 不同检测器交通流预测结果Fig.7 Traffic flow speed prediction results of different sensors
从图7中可以看出,工作日和非工作日的交通流量有些差异,但使用ST-CNN模型可以很好地识别出其发展的规律和特征,其交通流的预测结果在真实值周围的波动幅度较小,并且其绝对误差最大为3 mile/h,预测误差的绝对值在合理的范围之内。
2.6 不同预测模型的交叉验证
为了更好地验证ST-CNN模型的优越性,选取在交通流预测中应用较为广泛的GRU、LSTM、DCRNN和GMN模型作为对比预测模型。
(1)GRU:门控单元循环网络[4],可以捕获时间序列中的长期时间依赖性,主要模型参数隐藏单元数目是64,梯度下降算法是Adam(adaptive moment estimation),输入时间步长是12。
(2)LSTM:长短期记忆网络[5],可以克服梯度爆炸或消失问题,主要模型参数隐藏单元数目是64,梯度下降算法是Adam,输入时间步长是12。
(3)DCRNN:扩散卷积循环神经网络[6],可以捕获路网数据的交通依赖,主要模型参数包括:隐藏单元数目是64,梯度下降算法是Adam,输入时间步长是12。
(4)GMN:图马尔可夫神经网络[7],可以进行时空数据预测,可以用邻接矩阵表示交通网络的拓扑结构。
在实验中,所有测试模型的预测结果都通过平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)进行评估。在数据缺失率为10%、20%和30%的情况下,模型的预测结果如表1和表2所示。
表1和表2分别展示了在PEMS-BAY和METR-LA数据集上测试的不同缺失率下的预测结果。通过对比不同模型在不同缺失率下的预测结果,发现实验结果在三类指标下的表现均优于其他对比模型,在MAE指标降低的同时,MAPE和RMSE指标也在降低,在交通流数据缺失率增大的情况下,该模型仍然有效,其性能指标对比于其他模型来说仍然最优越。这是因为GRU、LSTM、GMN这些模型主要是根据时间序列的预测,捕获的是交通流数据的事件相关性,在获取空间关系的相关性上表现较差。本文提出的ST-CNN模型,通过建立时空矩阵,引入掩码矩阵来表示数据的缺失状况下的交通流预测,在缺失率为10%、20%和30%上都取得了最好的预测结果,充分说明了ST-CNN模型的正确性、有效性和广泛的适应性。同时,大多数交通流预测都是通过插补法解决少量的交通数据的随机缺失,当数据连续缺失时,预测精度会降低,从表1和表2中可以看出,随着缺失率的增高,以上模型的MAE、MAPE和RMSE这几类误差值也在增大,因此可以看出,缺失率越高,预测的精确率越低。
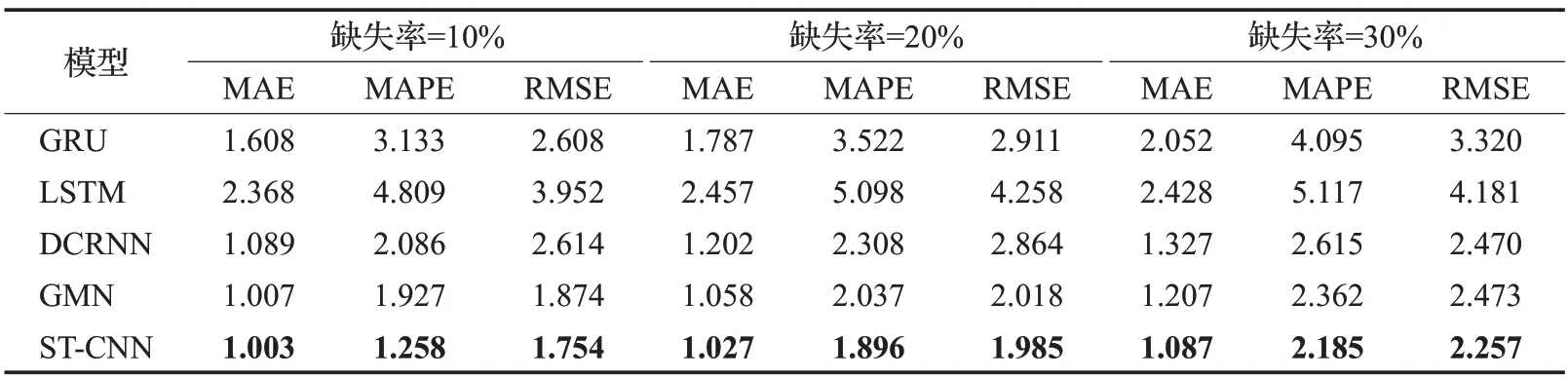
表1 PEMS-BAY数据集3种缺失情况下的预测结果Table 1 Prediction results in 3 missing cases of PEMS-BAY dataset
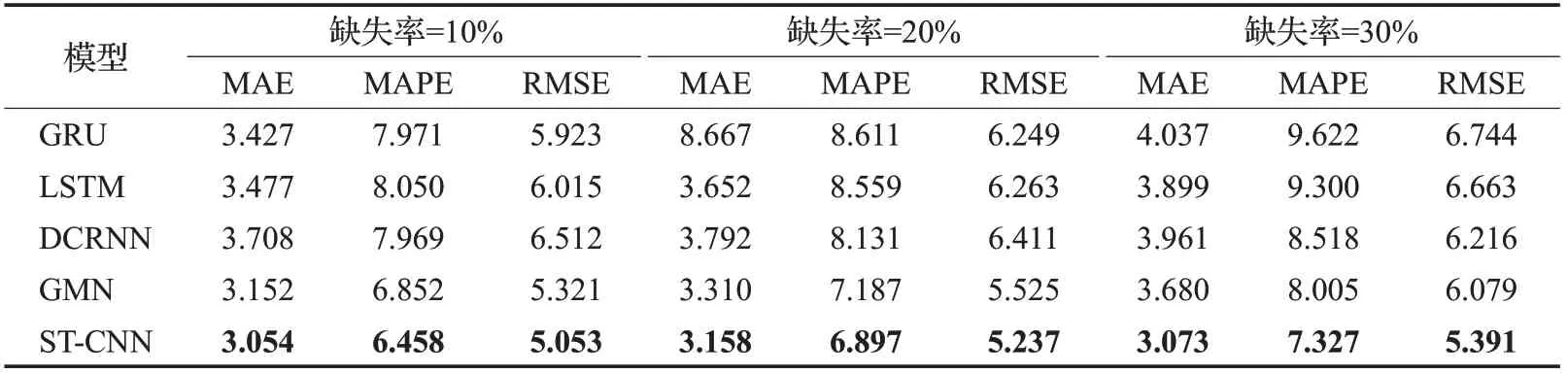
表2 METR-LA数据集3种缺失情况下的预测结果Table 2 Prediction results in 3 missing cases of METR-LA dataset
在PEMS-BAY数据集中任取一天的预测数据,将各模型的预测结果与真实数据进行对比,结果如图8所示。从图中可以看出,相对于LSTM、GMN模型来说,ST-CNN预测结果更加准确,其结果更接近真实值。

图8 不同模型5 min交通流预测结果Fig.8 Traffic flow speed prediction results of different models in 5 min interval
3 结论
本文利用交通流数据的时空相关性和时间序列的连续性特征,构建了路网交通数据时空矩阵和掩码矩阵,提出了一种基于时空卷积神经网络的交通流预测方法,实现了在数据连续缺失情况下的交通流预测。与多种先进的模型预测对比表明,该模型能够更好地挖掘交通流的时空关系,提高了在数据缺失情况下的交通流的预测精度。同时,利用时空矩阵和掩码矩阵可以更好的模拟出了交通数据的趋势状态,在数据缺失的情况下能够有效地预测交通流的发展趋势,提升了交流的预测效率,为智能交通系统提供了理论支持,对交通管制和交通路况信息分析具有重要的理论意义和参考价值。
本文提出的时空卷积预测模型仅在公开的高速公路数据集进行了实验验证工作,未来研究中,将会引入城市内部交通流数据,对交通数据进行全面分析验证,并且考虑影响交通流的外部环境因素,从而进一步优化完善模型的结构和预测性能。
猜你喜欢
通信学报(2019年5期)2019-06-11 03:05:56
通信技术(2018年3期)2018-03-21 00:56:37
中国交通信息化(2017年9期)2017-06-06 07:14:57
西南交通大学学报(2016年3期)2016-06-15 20:29:35
工业设计(2016年11期)2016-04-16 02:49:43
中国工程咨询(2016年1期)2016-02-14 06:47:44
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
电子设计工程(2015年20期)2015-01-29 02:58:24
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:12
河南科技(2014年22期)2014-02-27 14:18:12
