
融合多粒度全局信息的临床问诊信息抽取模型
2022-04-08 11:23:58李珊如乔晓辉杨丹青
中国新技术新产品 2022年2期
李珊如 乔晓辉 杨丹青 刘 彦
(1.河北汉光重工有限责任公司, 河北 邯郸 056017;2.河北省双介质动力技术重点实验室,河北 邯郸 056017)
0 引言
电子病历(Electronic Medical Record,EMR) 在现代医疗信息系统中被广泛应用,但医生为病人写电子病历是一项非常耗费精力和时间的任务。因此,为了减轻医生的沉重负担,将医患对话自动转换为电子病历是近年来自然语言处理领域的新兴课题。
为了应对上述挑战,该文提出了一个新的医学信息抽取模型,该模型充分利用了对话中潜在的相关上下文,这是因为当前转折后的对话内容可能会改变医学实体的状态。首先,模型从当前对话窗口中检索词级的相关信息,并将整个窗口文本编码为窗口。其次,该文在整个对话中合并2种类型的信息:1)细粒度信息。集成了整个对话中的所有共现词特征。2)粗粒度信息。选择一个信息最丰富的下方窗口作为该文的全局信息,并与当前窗口进行融合,从而预测所有可能的医学标签。
在试验中,该文用公开的研究性数据集MIE对该文的模型性能进行评估。该文在完成MIE任务过程中获得了48.61%的分数(分数为准确率和召回率的调和平均数),该结果是目前最先进的结果,这也验证了该文所提出的模型的有效性。
1 相关工作
从医学对话文本中提取信息是一个新的研究热点。文献[3]提出通过一个管道模型(包括5个模块)来生成电子病历,主要研究基于规则与监督的机器学习相结合的提取医学知识的方法。文献[4]旨在提取症状及其对应的状态,在工作中预先定义了186个症状和3个状态,还提出了一个跨属性标记模型,该模型预测所提到的症状的文本段,然后使用上下文特性进一步预测症状名称和状态。还用BIO(即开端、内部或其他)模式注释了中文在线医学对话。但是,该方法只将症状标注为实体类别,而没有考虑其状态,这与实际场景并不兼容。
最新的工作是执行MIE任务,它有一个更详细的标注模式,其包括4个医学类别、71个子项和5个状态。研究人员提出的管道模型由4个子模块组成,迭代地对整个标签集进行分类预测。虽然该文的标签与MIE是一致的,但是MIE部署了不合理的状态更新机制,后续的状态会盲目覆盖之前的状态。由该文对MIE数据集的分析可知,这种机制只对一小部分实体有效,对其他实体无效。
2 模型
该文所述的模型是一个端到端的临床问诊医学信息抽取模型。模型的框架如图1所示,它包括5个部分:1)窗口编码层将原始输入转换为上下文。2) 细粒度文档感知融合模块。该模块利用每个词在全局对话中的共现实体信息。3) 标签-句子注意力机制。采用窗口对标签信息的相关度进行建模。4) 粗粒度全局上下文信息融合模块。该模块将全局窗口中信息最丰富的窗口融合到当前窗口中。5)MIE预测器模块。该模块用1个二分类器去预测标签集中的所有候选项。

图1 模型结构图
2.1 窗口编码层
该文将2个连续的语句定义为1个窗口,分别由医生和病人所表达的句子组成。因此,整个问诊文本可以划分为多个窗口={,,…,x},为窗口的个数。对于每个窗口x来说,该文连接医患话语,并使用BiLSTM网络将其编码为语境词,如公式(1)所示。

式中:x为窗口;h为窗口的LSTM隐层。
对每个候选标签来说,该文也采用公式(1)所表述的方法将其编码为标签h。该文的模型还设计了标签-句子注意机制,利用该机制对提取出来的词级标签相关信息()在窗口()内的上下文相关性进行建模。因此,该文将标签h作为注意机制的一个询问,从而计算窗口的注意力分数,进而可以得到特定于标签的窗口c,如公式(2)~公式(4)所示。

式中:a为注意力分数;p为注意力权重;c为特定于标签的窗口;h为第个窗口;h为标签。
2.2 细粒度的文档感知信息融合
每个实体的状态与整个对话中同一实体的所有实例有关。例如,对实体“冠心病”来说,上文窗口的“冠心病”状态信息直接由下文窗口的“冠心病”决定。因此,为了获得一些上下文知识,模型必须将所有来自其他实例的整体信息利用到当前实体中。
通过利用MemoryNet,该文引入了每个实体的文档感知。该文定义了1个内存集={,},{,},…,{k,v}为每个词存储对话中的所有共现词的实例。其中,键值k为x的词嵌入向量;值v为第个词的隐藏状态;为实例个数。词嵌入在训练过程中会被微调,从而更新记忆网络的参数。
对每个单词x来说,为了融合其文档感知,该文用其词向量k作为注意力的键值,计算记忆集中隐藏状态v之间的注意得分,如公式(5)所示。

式中:d为单词嵌入的维数;o为注意力得分;k为键值v(转置后)的值。
文档感知如公式(6)~公式(7)所示。

式中:α为注意力分数;d为文档感知;o为注意力得分;为单词个数;为文档个数。
该文将当前词的隐藏状态h与文档感知d融合,并将其提供给标签-句子注意力模块,如公式(8)所示。

式中:为超参数,用于平衡隐藏状态h和文档感知d。
2.3 标签-句子注意力机制
标签-句子注意力机制在窗口g中对所提取的词级标签相关信息h的上下文相关性进行建模。具体来说,该文将标签h作为注意力机制中的一个查询来计算窗口的注意力得分,从而该文可以获得标签特定的窗口c,如公式(9)~公式(11)所示。

式中:α为注意力分数;h为标签;p为注意力权重;c为标签特定的窗口。
综上可得,模型可以将当前标签的信息融合到当前的对话窗口中。
2.4 粗粒度全局上下文信息融合
因为当前窗口的状态不仅由当前对话窗口信息决定,而且还由下方窗口的相关信息决定,所以该文需要考虑窗口之间的交互信息。值得注意的是,由于状态更新是基于下方的问诊文本,而不是之前的文本,因此该文没有必要考虑当前窗口之前的窗口,即历史信息。
该文采用了一个动态的注意机制来融合下方窗口信息。具体来说,该文将当前窗口c作为注意力机制的查询,将下面的窗口{c+1,…,c}作为键矩阵和值矩阵。当当前窗口下降时,后续窗口的个数减少,最后一个窗口没有后续窗口。
其中,下方窗口中注意力得分最高的窗口c被认为是对当前窗口信息最充分的下方窗口,该文将采用c作为全局信息,并将其连接到当前窗口,以辅助预测后续的状态。具体步骤如下:给定当前窗口c,计算下方窗口的注意力分数,如公式(12)~公式(13)所示(∈(+ 1,))。将注意力分数最高的窗口c连接到该文当前的窗口c,将其作为该文的全局c(如公式(14)所示),表示连接操作,如果当前窗口是问诊文本中的最后一个窗口,则c被设置为0。

2.5 MIE预测器
将全局-局部上下文聚合模块c的输出作为该模块的输入。具体来说,该文迭代每个MIE中的标签项,并采用二分类器来预测该窗口是否表达了后续的MIE标签,如公式(15)~公式(16)所示。

式中:forward为前馈神经网络;sigmoid为二分类器;c为前馈神经网络结果;y为二分类概率。。
3 试验
该文在MIE数据集上进行试验。首先,该文在3.1节中详细地阐述了模型细节、基线和评价指标。其次,在3.2节中提供了详细的试验结果,也分析了不同模型成分对消融研究的影响。最后,该文提供了1个案例研究和1个应用场景。
3.1 基线模型与评估指标
在试验中,该文对MIE任务中提出的基线模型进行了对比。其中,Plain-Classifier利用1个基本的类分类器模型,使用1条简单的策略来完成任务。MIE-single表示只考虑单个话语内的交互的模型,所获得的表示相互独立。multi能够捕捉不同话语之间的相互作用。为了获取其他话语的相关状态信息,它将类别表示作为查询,获取对状态的注意值,然后获得该话语的候选表示。
对MIE任务来说,该文只使用对话级度量,因为窗口级度量包括大量的标签冗余,所以每个标签都可能被多次计算,从而对其进行评估。首先,该文将属于同一个临床问诊窗户的结果进行合并。其次,评估每篇问话文本的结果。最后,报告测试集中的微平均值。
对模型参数和试验设置来说,为了保证公平,该文基本上与MIE任务保持一致。该文使用300维Skip-Gram词嵌入,预先训练了来自中国在线健康社区的医学对话,前馈网络和Bi-LSTM的隐藏状态大小均为400。该文使用Adam优化,使用学习率衰退和正则化来缓解过拟合问题,并采用根据验证集的得分进行训练的提前停止(Early Stop)。
3.2 结果与分析
在测试集中,该文分别评估了该文所述模型在类别级(Category Only)和全级(Category and State)中的性能。其中,类别级表示模型只需要关注医学标签本身,不需要关注其状态;而在全级中,模型只有在医学标签和状态都正确的状态下才会被认为模型预测是正确的。
该试验结果见表1和表2。MIE-single和MIE-multi模型所获得的结果都比Plain-Classifier模型获得的结果好,这表明MIE体系结构比基本的LSTM表示方法更有效。与MIE中的基线模型相比,该文的模型不仅可以捕获话语和标签之间的交互,还可以整合来自以下窗口的信息。因此,该文提出的CLINER在类别级和全级评价中分别比这些基线高2.78%和0.58%(分值)。

表1 MIE数据上类别级的试验结果

表2 MIE数据上全级的试验结果
同时,该文对模型进行消融试验,从而评估在MIE数据中不同模型组件的有效性。其中,该文所述模型代表了具有最佳性能的所有模块的完整模型。表3的结果表明,去除细粒度的文档感知将导致值下降1.25%。该文可以推断模型性能与实体的所有实例的信息有直接关系,这些信息决定了实体级状态的变化。此外,在去掉粗粒度的全局上下文聚合的情况下,模型性能下降了1.70%,它没有将信息量最大的窗口嵌入下面的文本中(以帮助当前窗口捕获状态的变化)。如果忽略标签 - 句子注意力信息,那么模型的值在MIE任务中降低了1.12%,这表明标签句注意能够捕捉当前候选标签与话语之间的交互信息(会强调话语中最相关的单词)。
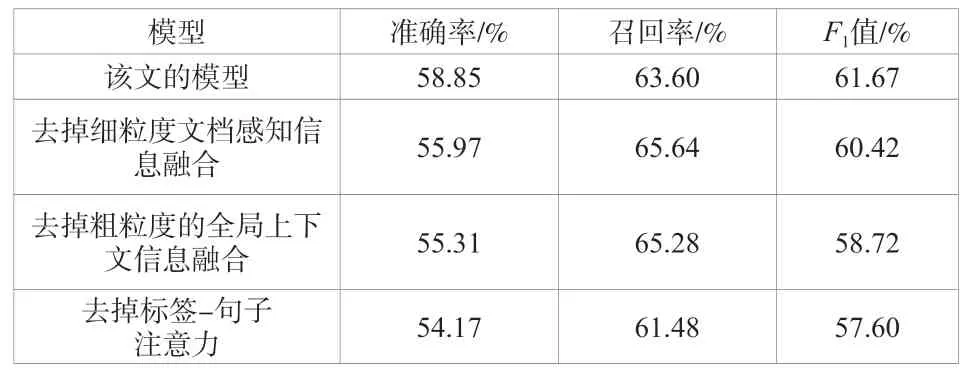
表3 不同设置下的消融试验
为了进一步验证该文所述模型的有效性,该文在测试集中挑选了图2中的实例,并对对话级和窗口级注意力热图进行可视化操作。对话级注意可视化表明,该文的模型检测到与给定类别“心肌梗死”语义相关的标记。该文可以很容易地发现标签“心肌梗死”与当前窗口中权重最大的文本“心肌梗死”相关。
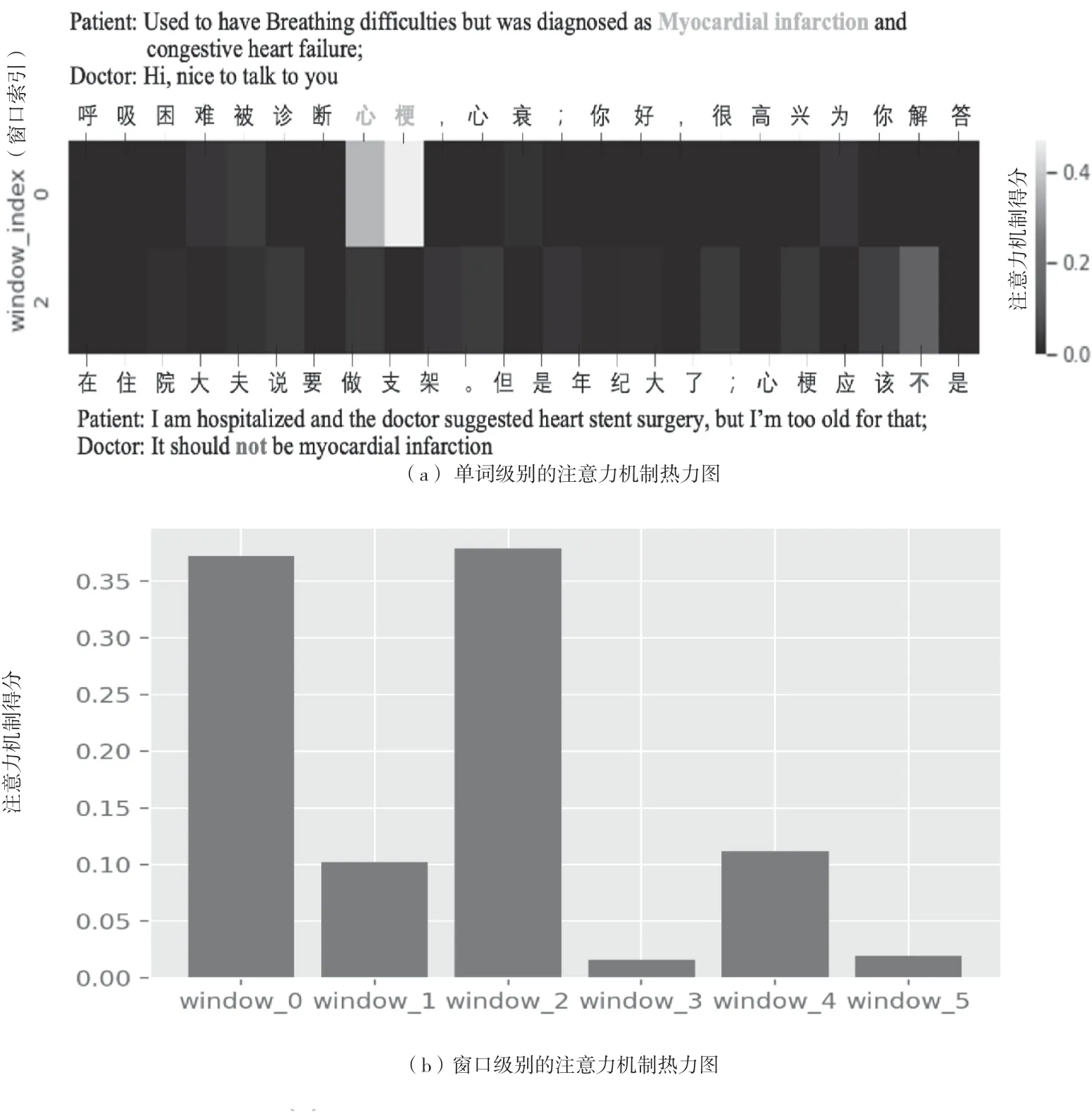
图2 该文所述模型的可视化例子
为了进一步确定状态,模型计算当前窗口和以下窗口之间的注意分数。该文选择关注度最高的窗口2作为该文的全局信息,并将其添加到状态预测中。在热力图中,该文注意到标记“No”被突出显示,并进一步用作关键参考,以正确预测当前窗口中给定标签的状态为“negative”。而传统的方法如果不考虑窗口2的信息,则无法正确预测该标签,最终导致该窗口状态预测失败。
4 结论
在该文中,该文建立了1个临床医学对话文本的信息抽取的模型,该模型由4个模块组成,可以充分利用以下窗口中的相关上下文,从而更好地捕获状态的更新情况。在MIE任务中的试验表明,该文的模型可以有效地提高性能(性能优于基线模型)。该模型在临床试验中有较高的应用价值,为提取临床问诊信息的提取提供了一种很有前景的解决方案。在未来的工作中,该文将进一步利用标签中的内部关系,尝试将丰富的医学领域知识引入该文的模型中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国新闻周刊(2021年26期)2021-07-27 04:02:12
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
传媒评论(2017年3期)2017-06-13 09:18:10
信息安全研究(2016年4期)2016-12-01 06:06:54
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
公民与法治(2016年10期)2016-05-17 04:12:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机工程(2015年8期)2015-07-03 12:20:27
