
兽药致病命名实体Att-Aux-BERT-BiLSTM-CRF识别
2022-04-07 14:02:22郑丽敏田立军
农业机械学报 2022年3期
杨 璐 张 恬 郑丽敏,2 田立军
(1.中国农业大学信息与电气工程学院, 北京 100083; 2.食品质量与安全北京实验室, 北京 100083)
0 引言
兽药残留会对人体健康造成巨大危害[1]。文献[2]提出了一种根据兽药通过环境间接接触人类的可能性及其毒性概况来对兽药进行排序的方法,但是由于许多数据缺失,所以准确性不高。如何快速准确地从兽药致病文本中获得相关信息,是构建兽药致病知识图谱中的关键环节。兽药致病命名实体识别是兽药致病信息抽取的重要任务之一,目的是从兽药致病非结构化文本数据中获得兽药名称、实验动物、不良反应等信息。
命名实体识别的方法包含基于规则、机器学习和深度学习三大类。基于规则的命名实体识别的方法耗时耗力且可移植性差[3]。基于机器学习的方法将命名实体识别问题转化为序列标注问题,如文献[4]采用条件随机场(Conditional random field,CRF)进行命名实体识别,文献[5]采用CRF对农业病虫害实体进行识别。但是传统的机器学习方法仍然需要人工选取特征[6]。
基于深度学习的命名实体识别方法广泛应用于渔业[7]、农业病虫害[8]、电子病历[9]、医学文献[10]和新闻社论[11]等领域。文献[12]采用LSTM和CRF对文献中药物名称进行命名实体识别,在DDI2011语料库上精度达到93.26%。文献[13]首次联合采用BiLSTM和CRF进行命名实体识别,获得了F1值为90.10%。基于BiLSTM方法学习文本的长距离依赖,相较于LSTM方法,可以充分结合上下文信息,同时CRF可以获得相邻标签之间的依赖关系。双向编码表征模型(Bidirectional encoder representations from transformers,BERT)[14]的出现提升了命名实体识别的效率,文献[15]采用双向编码表征-双向门限循环-条件随机场模型(Bidirectional encoder representations from transformers-Bidirectional gated recurrent unit-Conditional random field,BERT-BiGRU-CRF)进行命名实体识别,解决了传统的词向量表示方法只是将字映射为单一向量,无法表征字的多义性的问题,在MSRA语料上的F1值达到95.43%。文献[16]采用BERT-BiLSTM-CRF模型对人民日报语料库进行命名实体识别, F1值为95.67%。基于深度学习的方法命名实体识别任务转化为字级别的序列标注任务,减少了特征工程的工作量,同时结合了上下文信息,提高了模型的性能,但是需要大量的标注语料。
基于注意力机制的神经网络是深度学习研究的一个热点。受人类观察图像时会对特定部分集中注意力的启发,注意力机制首先应用在图像处理领域。文献[17]将模型最后层的输出和中间层的输出结合起来,在图像分类领域和图像分割领域[18]取得了较好的结果。注意力机制[19]在自然语言处理领域也得到广泛应用。文献[20]提出使用注意力机制将字级别和词级别的嵌入结合起来,可以获得更好的结果。文献[21]分析使用不同的注意力计算函数对于命名实体识别模型的影响。
发布于有害物质数据库的兽药致病文本表达不规范,没有特定的规则,且部分实体词长度较长、使用缩写简称等情况,导致实体识别难度较大。兽药致病实体词汇较长是多个一般词汇组合导致的,同一实体的缩写简称也表现为多种形式。这就需要结合上下文,充分利用词汇的句法和语法信息,而不能仅仅依靠基于统计的方法来设计规则。针对这一问题,本文采用预训练语言模型的方法,学习包含兽药致病领域上下文语义信息的词向量,提出基于注意力机制的端到端的Att-Aux-BERT-BiLSTM-CRF神经网络模型。首先将兽药致病领域命名实体识别任务转换为字级别的序列标注任务,然后基于BERT进行字向量的提取,使用BERT中文预训练兽药致病领域词向量作为BiLSTM网络的输入,将模型的BERT层输出用作辅助分类层,BiLSTM层输出作为主分类层,引入皮尔逊相关系数作为注意力值计算函数,计算2个层的相似度。最后输入条件随机场,通过相邻标签的依赖关系确定输出序列。
1 数据获取与标注
1.1 数据获取
本文通过爬虫获得兽药致病数据集。研究兽药残留致病信息的数据主要来自于两个网站。有害物质数据库(HSDB)(https:∥www.nlm.nih.gov/toxnet/index.html)是一个毒理学数据库,着眼于分析存在潜在危险的化学物质。它提供了兽药对于人体健康的影响和非人类毒性摘要等信息。粮农组织/世卫组织食品添加剂联合专家委员会(JECFA)网站(https:∥apps.who.int/food-additives-contaminants-jecfa-database/search.aspx)可搜索的数据包含JECFA对风味、食品添加剂、污染物、有毒物质和兽药进行的所有评估的摘要。每个摘要均包含基本化学信息、最新报告、专著的链接、规格数据库以及JECFA评估的历史记录。可通过部分名称或编号来搜索数据。
《食品安全国家标准 食品中兽药最大限量》中规定的兽药共包含3类:可以使用但是有残留限制的兽药、不需要设定残留限制的兽药、不得检出的兽药。从兽药残留致病的角度考虑,选择第1类和第3类兽药共计113种。利用爬虫在这两个网站中以兽药名称为关键词进行检索,获得相关的兽药致病数据,共计10 643个句子,485 711个字符。
1.2 数据标注
语料库共包含实体14 189个,具体分布如表1所示。使用BIO标注方法进行标注,B表示实体的开始,I表示实体的内部,O表示非实体。

表1 标注数据数量Tab.1 Label data quantity
2 模型框架
本文提出的Att-Aux-BERT-BiLSTM-CRF模型由BERT模块、BiLSTM模块、基于注意力机制的辅助分类器和CRF模块共4个模块组成,模型结构如图1所示。首先通过BERT预训练模型获取字向量,提取文本中的重要特征;然后使用BERT中文预训练兽药致病领域词向量作为BiLSTM网络的输入,通过BiLSTM层学习上下文特征;将模型的BERT层输出用作辅助分类层,BiLSTM层输出作为主分类层,接着将这两部分的结果通过注意力机制加权融合在一起,作为新的特征,输入到CRF层中,得到最后的输出序列。
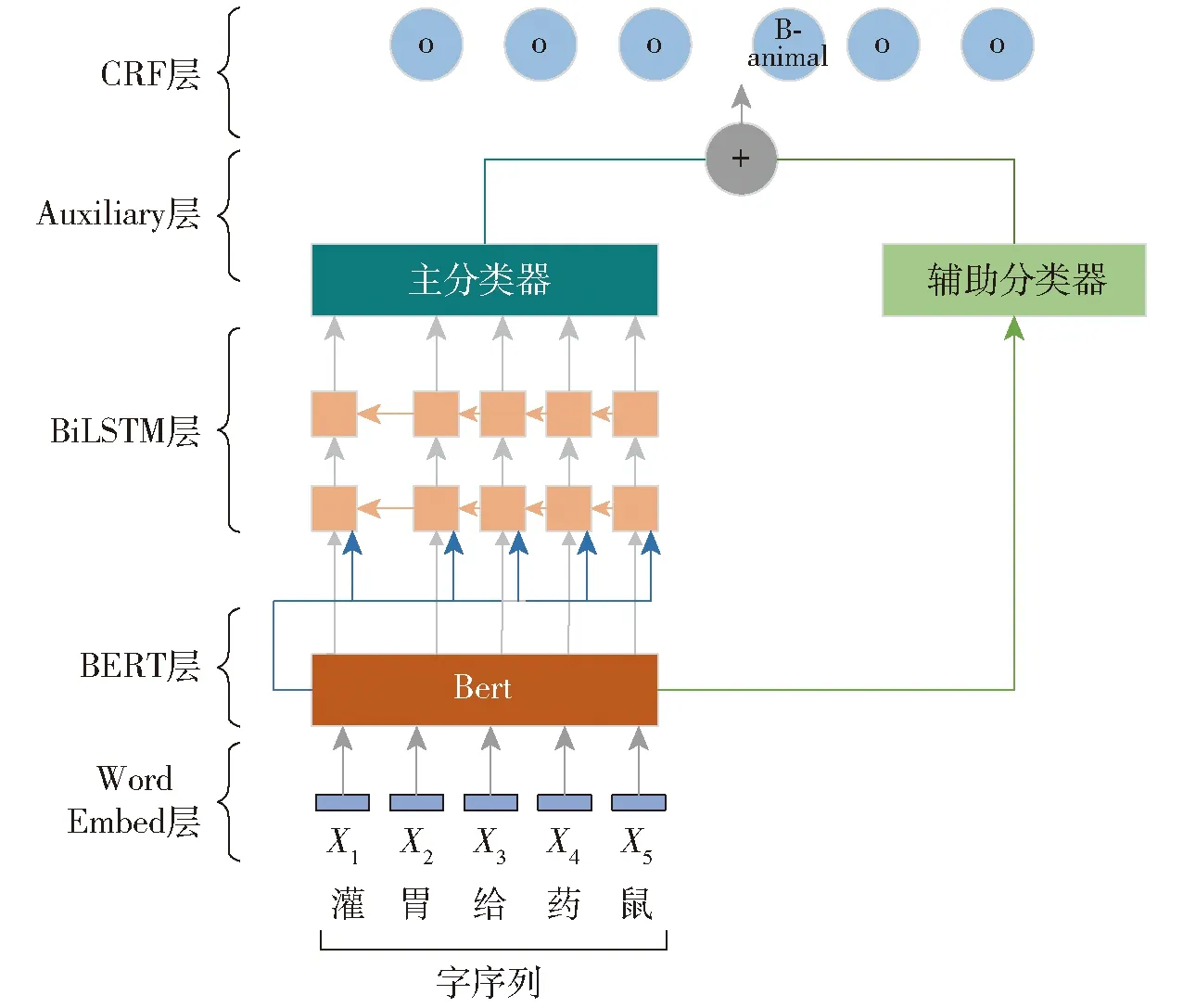
图1 Att-Aux-BERT-BiLSTM-CRF模型结构Fig.1 Att-Aux-BERT-BiLSTM-CRF model structure
2.1 BERT层
在自然语言预处理领域存在Word2Vec[22]、ELMo[23]、GPT[24]等多种预训练模型。BERT融合了这些模型的优点并克服了他们的缺点。BERT使用遮蔽语言模型(Masked language model,MLM)和下一句预测来进行预训练。这样得到的向量不仅包含隐含的上下文信息,还包含句子级别的特征。图2是BERT结构示意图。图中EN、TN、Trm分别代表输入的嵌入层、输出的BIO标志、Transformers编码器。

图2 BERT结构示意图Fig.2 BERT structure diagram
BERT模型中Transformer采用自注意力机制和全连接层处理输入的文本。Transformer采用的多头注意力机制,可以获得多个维度的信息。本文模型将BERT的输出结果输入到BiLSTM层中。
2.2 BiLSTM层

Ft=σ(Wf[Ht-1,Xt+bf])
(1)
It=σ(Wi[Ht-1,Xt+bi])
(2)
(3)
(4)
Ot=σ(W0[Ht-1,Xt+bo])
(5)
Ht=Ottanh(Ct)
(6)
式中σ——sigmoid激活函数
tanh——双曲正切激活函数
Ft、It、Ct、Ot——在t时刻遗忘门、输入门、记忆细胞和输出门
Wf、Wi、Wc、W0——不同门对应的权重矩阵
bf、bi、bc、bo——偏置向量
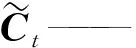
Xt——t时刻的输入向量
Ht——t时刻的输出向量
2.3 Attention层
在计算机视觉领域,已知将模型的中间层输出结果和最后输出结果相结合可以改善图像分割的性能。这是因为模型的中间层输出结果和最后输出结果对于图像分割都有作用,所以将中间层的输出结合起来进行图像分割。本文将BERT层输出结果作为辅助分类器,BiLSTM层输出结果作为主分类器。BERT可以获得丰富的语义信息,BiLSTM可以获得长距离的上下文信息。将两者结合起来,从而更好的进行序列标注。
注意力机制起源于对人类注意力的模仿,其本质是通过注意力分配参数筛选出特定的信息,Attention层的主要作用是衡量特征权重。在之前的Aux-BERT-BiLSTM-CRF模型中,BERT层输出结果(辅助分类器)和BiLSTM层输出结果(主分类器)具有相同的权重,这样会产生两个弊端:BERT层输出的内容会被稀释掉;语义向量无法表示整个序列的所有信息。使用Attention机制可以计算两者的相关性,动态分配权重,让更重要的特征占据更大的权重,从而获得对于序列标注更为重要的信息。本文将BERT层输出结果(辅助分类器)和BiLSTM输出结果(主分类器)通过Attention机制结合起来。
在注意力层中,引入注意力机制来计算辅助分类器和主分类器的相似性得分。注意力值计算函数(Score函数)是衡量BERT层输出向量和BiLSTM输出向量之间相关性的得分函数。文献[22]设计了余弦距离、欧氏距离和感知机3种方案作为得分函数。皮尔逊相关系数、马氏距离分别是余弦距离和欧氏距离的改进,本文设计了皮尔逊相关系数、马氏距离、感知机3种方案,其Score函数计算公式为
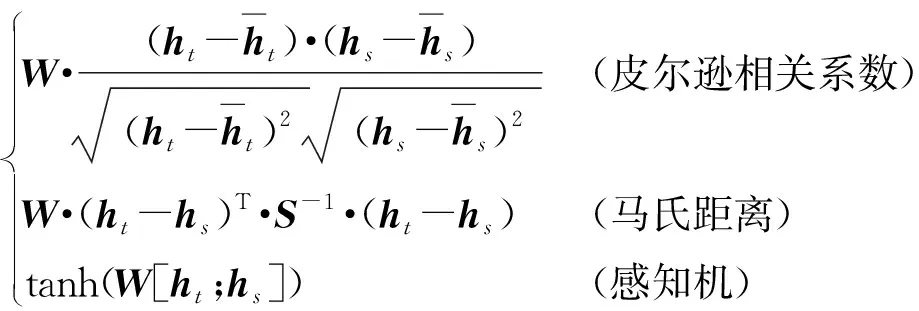
(7)
式中ht——BERT层输出的结果,即辅助分类器
hs——BiLSTM层输出的结果,即主分类器
W——权重矩阵
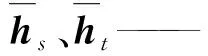
S——协方差矩阵
皮尔逊相关系数是数据中心化后的两个多维向量的夹角余弦。两个向量越相似,皮尔逊相关系数和感知机的计算结果得分越大。马氏距离是度量学习中常用的距离指标,用于评定数据之间的相似度。使用Score函数得到两个层的特征权重。然后通过这两个粒度的向量特征相乘得到新的特征输入到CRF层中。
2.4 CRF层
在命名实体识别任务中,BiLSTM可以处理长距离的文本信息,但是无法处理相邻标签之间的依赖关系。条件随机场(Conditional random field,CRF)可以通过临近标签获得一个最优的预测序列。
对于输入序列X=(X1,X2,…,Xn),提取特征得到输出矩阵P=[P1P2…Pn]。对于预测序列Y=(y1,y2,…,yn),其分数函数公式为
(8)
式中Ayi,yi+1——标签yi转移到标签yi+1的分数
Pi,yi——字符被预测为第yi个标签的分数
最后使用softmax层计算出所有可能标签的概率,输出一个得分最高的标记序列。
3 实验
实验采用Pytorch 1.7.1框架,运行环境为RTX 2080Ti GPU,内存为11 GB。
3.1 实验设置
参数配置如表2所示,为解决过拟合问题,引入dropout[26]机制,dropout值为0.5。优化算法为Adam[27]。
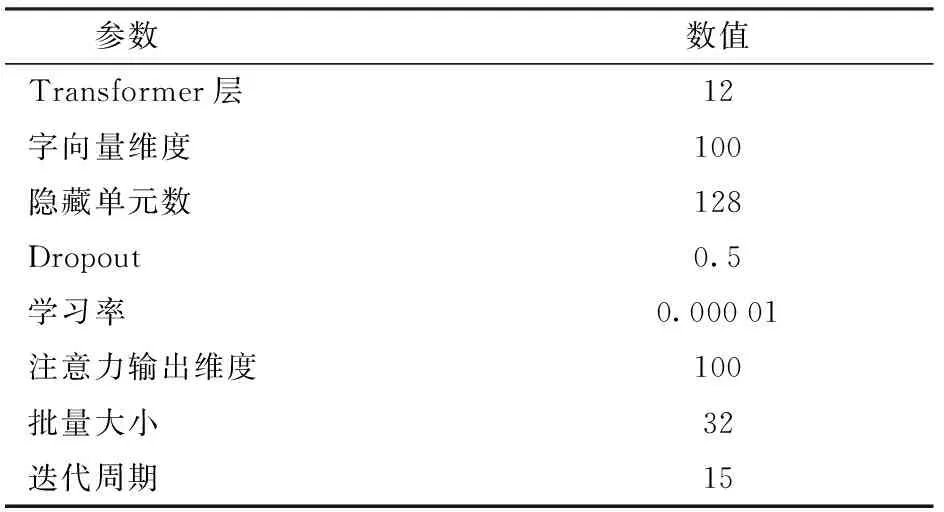
表2 参数配置Tab.2 Parameter configuration
3.2 评价方法
采用准确率、召回率、F1值作为评估指标[28]。
3.3 实验结果
在标注数据集上验证模型的性能。语料库中的训练集、测试集按照8∶2进行分配,数据集之间无重叠,因此实验结果可以作为实体识别效果的评价指标。训练集和测试集实体数量见表3。
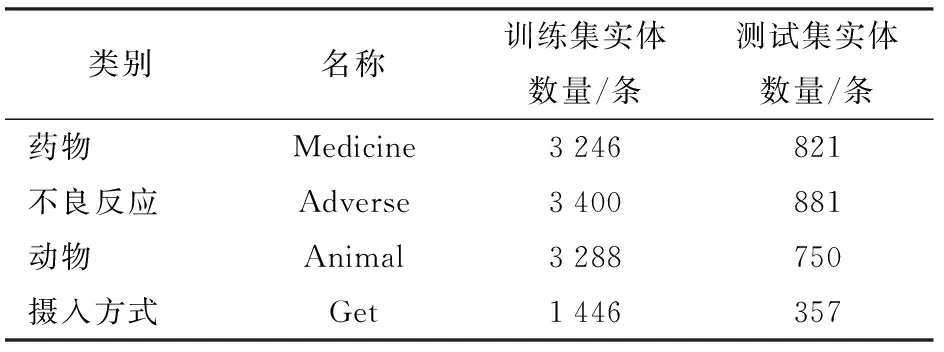
表3 数据集实体信息Tab.3 Dataset entity information
3.3.1不同模型的性能比较
在不同的模型上进行实验,模型包括BiLSTM-CRF[13]、BERT-BiLSTM-CRF[15]以及本文提出的Aux-BERT-BiLSTM-CRF和Att-Aux-BERT-BiLSTM-CRF。Aux-BERT-BiLSTM-CRF模型将BERT层输出的结果作为辅助分类器,BiLSTM层输出的结果作为主分类器,将两者拼接起来。Att-Aux-BERT-BiLSTM-CRF模型与前者不同之处在于,使用注意力机制,选择皮尔逊相关系数作为注意力值计算函数公式,将两者动态结合起来。
通过表4可知,BiLSTM-CRF模型F1值为94.1%。BERT-BiLSTM-CRF模型相较于BiLSTM-CRF模型,由于引入BERT可以获得丰富的上下文信息,模型F1值提高了1.1个百分点。将BERT输出的结果和BiLSTM输出的结果通过注意力机制结合起来,通过学习判断BERT输出的表征和BiLSTM捕获的长距离语义信息的重要性,按照重要程度加权结合得到新的表征,F1值为96.7%。本文提出的Att-Aux-BERT-BiLSTM-CRF模型较BERT-BiLSTM-CRF的F1值提高了1.5个百分点,较BiLSTM-CRF的F1值提高了2.6个百分点。
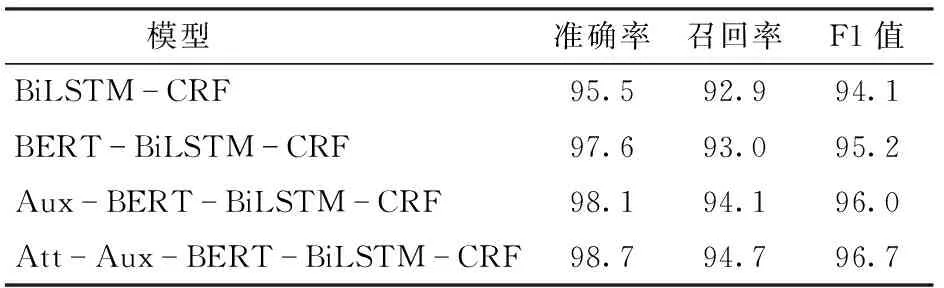
表4 不同模型的实验结果对比Tab.4 Comparison of experimental results of different models %
3.3.2不同注意力值计算函数对模型的影响
本文设计了3种不同的注意力值计算函数(皮尔逊相关系数、马氏距离、感知机)。为了选择最佳的注意力值计算函数,设计实验比较了这些函数对于模型性能的影响。在实验中,BERT层输出作为辅助分类层、BiLSTM层输出作为主分类器层,两者作为注意力值计算函数的输入。表5给出了Att-Aux-BERT-BiLSTM-CRF模型在兽药致病语料上使用不同注意力值函数计算的结果。
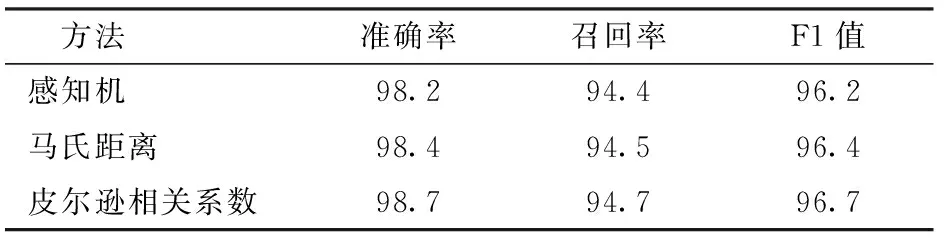
表5 不同注意力值计算函数的模型性能Tab.5 Influence of different attention calculation functions on model %
实验表明,感知机效果最差,马氏距离优于感知机,使用皮尔逊相关系数取得的效果最好,获得了最高的F1值(96.7%)。原因可能是马氏距离和皮尔逊相关系数是机器学习中简单有效的相似性度量方法。两者都对数据进行了规范化。与他们相比,感知机的结构更为复杂,更容易导致过拟合,优化更为困难。所以最终选择实验结果较好的皮尔逊相关系数作为注意力值计算函数。
3.3.3不同实体实验结果比较
表6列出了Att-Aux-BERT-BiLSTM-CRF对兽药致病数据集上各类实体的识别结果。由实验可知,相较于药物和不良反应,动物和摄入方式的准确率、召回率和F1值都较高。因为动物和摄入方式种类较少且不存在实体嵌套的现象,所以各项指标都较高。兽药致病4类实体在不同模型上实验结果对比见图3。从图3可以看出,Att-Aux-BERT-BiLSTM-CRF的各项指标都较高。
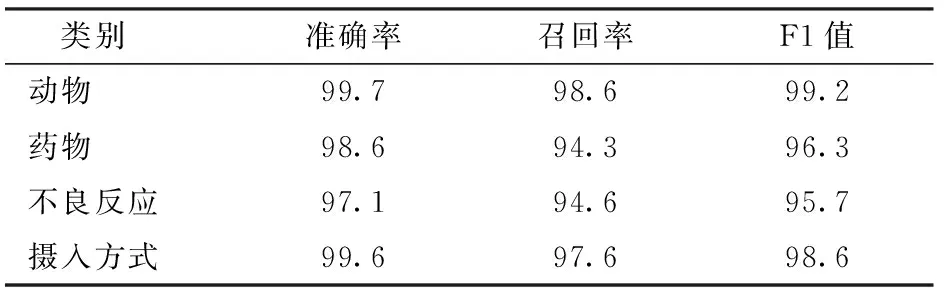
表6 Att-Aux-BERT-BiLSTM-CRF在各类实体上的识别结果Tab.6 Att-Aux-BERT-BiLSTM-CRF recognition results on various entities %

图3 兽药致病实体实验结果对比Fig.3 Comparison of experimental results of animal drugs
3.3.4案例分析
最后,本文在pubchem数据库中获得兽药致病文献摘要,使用本文提出的Att-Aux-BERT-BiLSTM-CRF模型识别兽药致病文献中的实体,结果如表7所示。

表7 实体识别结果Tab.7 Entity recognition results
4 结束语
针对兽药致病领域的命名实体识别任务,提出了基于Att-Aux-BERT-BiLSTM-CRF神经网络模型的方法。通过实验比较了3种不同注意力值计算函数(皮尔逊相关系数、马氏距离、感知机)对于模型的影响,最终选择了实验结果较好的皮尔逊相关系数作为注意力值计算函数进行计算。该模型将BERT层输出结果作为辅助分类器,BiLSTM层输出结果作为主分类器,通过注意力机制将两者动态加权融合在一起,丰富了语义信息。与其他典型模型相比,获得了最优的F1值(96.7%),说明了其在兽药致病命名实体识别方面的优越性。
猜你喜欢
今日畜牧兽医(2022年10期)2022-12-23 06:22:32
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
初中生世界(2020年43期)2020-12-18 19:11:47
初中生世界·九年级(2020年11期)2020-12-02 07:47:10
教育教学论坛(2019年7期)2019-03-18 11:50:12
科学与财富(2018年16期)2018-08-10 10:47:16
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
河南畜牧兽医(2016年24期)2016-11-29 01:28:18
兽医导刊(2015年7期)2016-01-04 11:59:54
