
机载激光雷达数据的三维深度学习树种分类*
2022-04-06 09:56刘茂华韩梓威陈一鸣刘正军韩颜顺
国防科技大学学报 2022年2期
刘茂华,韩梓威,陈一鸣,刘正军,韩颜顺
(1. 沈阳建筑大学 交通工程学院, 辽宁 沈阳 110168; 2. 中国测绘科学研究院, 北京 100089)
树种分类是生态环境、林业测量、遥感等众多行业和领域的重点研究课题,因为树种识别对生态系统评估、生物多样性监测和森林资源利用起着至关重要的作用[1-2]。传统的树种分类方法通常是利用高光谱遥感技术,通过树木的光谱信息区分不同的树种。然而,高光谱数据冗余度大,且存在着“同谱异物”和“同物异谱”的现象,忽略了树木的三维结构信息[3]。激光雷达(Light Detection And Ranging, LiDAR)是一种先进的主动遥感技术,它能够高精度地快速获取地表目标的高度信息和三维结构信息,且具有抗干扰能力强、低空探测性能好等优点[4-5]。随着无人机技术的快速发展,无人机LiDAR为快速、准确的植被精细分类提供了有力的技术支撑[6]。
近年来,深度学习技术在三维数据上取得了很好的发展,根据输入网络的表达方式可以概括为以下三种:①基于体素的方法一般是将三维模型划分为三维网格后再进行3D卷积,代表模型有VoxNet、3D ShapeNets、O-CNN等[7-9];②基于多视图的方法是先将三维模型通过投影等方法得到二维图像,再利用图像领域的方法进行处理,代表模型有MVCNN、FPNN、DeepPano等[10-12];③基于点的方法是网络能够适应三维数据的特点,直接对点云进行处理,代表模型有PointNet、PointNet++、PointCNN等[13-15]。
由于深度学习在特征提取上的优势,近年来有学者将该技术运用到基于LiDAR数据的树种识别。Guan等[16]基于体素实现了滤波和单木分割,然后将树的点密度用波形表示,再利用深度玻尔兹曼机(Deep Boltzmann Machine, DBM)实现了对城市树种的分类;Zou等[17]利用栅格化的方法在样本空间中划分体素,将每个体素格网中的点云数累积,投影到包含树木轮廓的二维图像上,每30°重复投影,并用一个深度信念网络(Deep Belief Network, DBN)来生成高级特征,从而进行树种分类;Hamraz等[18]将点云转化为数字表面模型(Digital Surface Model, DSM)和2D视图,再利用深度卷积神经网络(Convolutional Neural Networks, CNN)对针叶树和落叶树分类。
然而,这些研究都是先将点云进行规则化处理,例如转换成体素或二维图像,而没有直接利用三维数据进行特征提取或分类。体素划分不仅会呈指数级地增加计算成本,还会受到分辨率的限制,存在局部信息丢失的现象。多视图投影的方法不能充分利用点云的三维结构信息,在点分类和场景理解等3D任务上具有较大的局限性。因此,本文基于森林样区内获取的无人机LiDAR点云数据,提出了一种新的树种分类方法,该方法将无序的点云数据作为神经网络的输入,直接利用其三维信息进行特征提取,实现白桦树和落叶松两个树种的分类。
1 方法与实验
1.1 研究区概况与数据获取
研究区域为中国河北省承德市围场满族蒙古族自治县内的塞罕坝国家森林公园(42°24′N,117°19′E)的一部分,海拔高度为1 500~2 067 m,植被覆盖度约为80%。研究区内包括白桦和落叶松两类树种共计约1 790棵,两类树主要以一条较宽的土路为分隔,其中白桦树主要分布在路的西北部,约870棵;落叶松分布在路的东南部,约920棵。
实验数据由大疆无人机搭载的Riegl公司miniVUX 1U激光雷达扫描仪于2019年8月24日获取,航线间距40 m,航高50 m,飞行速度5 m/s,激光雷达扫描角90°~270°,扫描线速度100 m/s。基于该无人机LiDAR系统获得的原始数据如图1所示,两类树种点云样例数据如图2所示,样区内各树种的结构特征见表1。

图1 无人机LiDAR原始数据Fig.1 Airborne LiDAR raw data
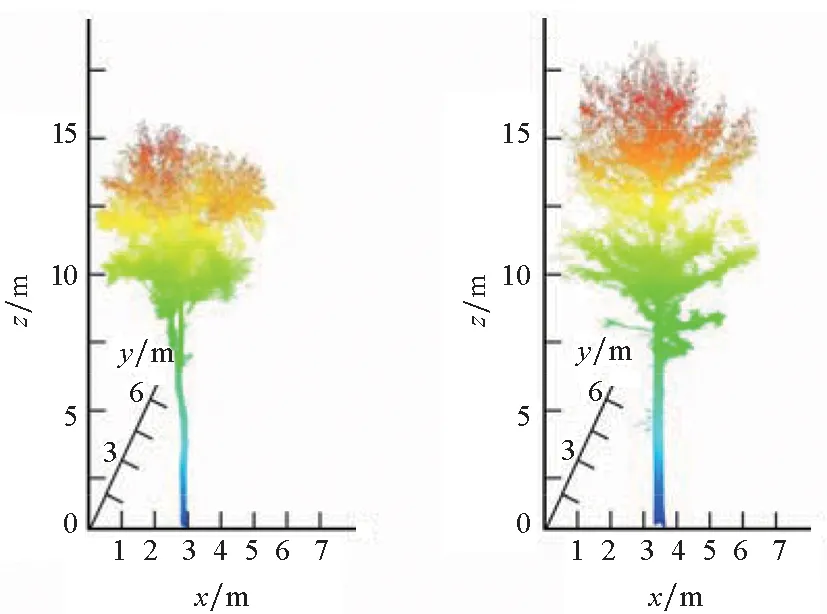
(a) 白桦(a) Birch (b) 落叶松(b) Larch图2 基于无人机LiDAR系统的点云样本示例Fig.2 Example of point cloud sample based on airborne LiDAR system

表1 样本树木结构特征
1.2 工作流程
对于获取的原始无人机LiDAR点云数据,首先进行预处理,包括去噪和地面滤波。其次,对预处理后的森林点云数据进行单木分割,获取单木点云。再次,对单木点云添加标签,制作数据集。训练集用于训练神经网络模型,测试集用于对得到的模型测试树种分类精度。最后,对可能的分类精度影响因素进行分析,并做对比实验。基于机载LiDAR数据的三维深度学习树种分类工作流程如图3所示。
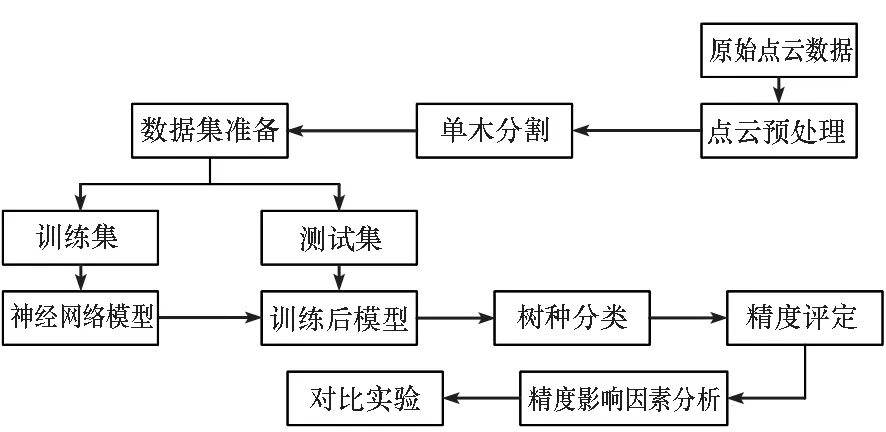
图3 树种分类工作流程Fig.3 Work flow of tree species classification
1.3 数据预处理
1.3.1 去噪与地面滤波
由于森林环境的复杂性,获取机载LiDAR数据的过程中会产生粗差,因此必须先对原始点云数据去噪。对每一个点搜索相同个数的邻域点,经多次实验发现,当邻近点个数为10时,去噪效果最好。然后计算该点到邻域点的距离平均值Dmean及其中值m和标准差σ。计算最大距离Dmax:
Dmax=m+Kσ
(1)
其中,K为标准差倍数,设置为5。若Dmean大于Dmax,则认为该点为噪点,将其去除。
为消除地形影响,需要先对去噪后的点云数据进行地面滤波,以获得更准确的单木分割结果。本文利用改进的渐进加密三角网滤波算法[19]对地面点与非地面点进行分离。首先对LiDAR点云以1 m的尺寸划分网格,取每个网格的最低点进行光栅化,再利用形态学开操作选取潜在地面种子点Gpotential。然后,利用平移平面拟合法滤除Gpotential中的非地面点,进而获得准确的地面种子点Gseeds。最后,建立TIN模型,执行先向下再向上的迭代加密,得到地面点Gresult。地面点和非地面点的分类结果如图4所示,其中蓝色点为地面点Gresult,白色点是树木点,删除地面点即完成滤波。

图4 地面点与非地面点的分类结果Fig.4 Classification results of ground points and non-ground points
1.3.2 单木分割
为了制作深度学习的数据集,向每棵树添加代表树种的标签,需要对原始的森林数据进行单木分割。单木提取存在一定的错误率,例如欠分割、多树粘连等情况,所以使用单一方法分割得到的高质量单木数量较少。因不同分割方法得到的单木三维形状有所差异,可作为数据增强的一种方法,故本实验分别采取改进的分水岭分割算法[20]和基于点云距离的分割方法[21]对原始的森林点云数据进行分割,以筛选出数量足够多的高质量单木点云。改进的分水岭分割算法首先从原始的激光脉冲生成数字表面模型和数字高程模型,进而得到冠层高度模型;然后,通过在具有可变窗口大小的冠层最大值模型中搜索局部最大值来检测树梢,其窗口大小由冠部大小和树高度之间的回归曲线预测间隔的下限确定,该步骤可有效减少对树顶点的判别错误;最后,利用Marker-controlled分水岭算法完成单木分割,如图5所示。基于点云距离的分割将点按顺序从高到低进行分类,间距大于指定阈值的点排除在目标树之外,间距小于阈值的点根据最小间距规则进行分类,分割结果如图6所示。通过这两种算法,共分割出单木3 598棵,经人工筛选,删除过分割、欠分割以及粘连严重的树,保留1 200棵高质量树作为实验数据。

图5 基于改进的分水岭分割的单木分割结果Fig.5 Results of individual tree segmentation based on improved watershed segmentation

图6 基于点云距离的单木分割结果Fig.6 Results of individual tree segmentation based on point cloud distance
1.3.3 样本集准备
深度神经网络需要输入样本具有相同的点云数,故将所有单木均匀采样2 048个点,并将每棵树零均值归一化至单位球内,以解决点的平移不变性。向每棵树添加标签,其中白桦树记为0,落叶松记为1。为了避免因种植区域相同而导致分类器可能过于适合研究地点的情况,从不同的空间中划分数据。将整个数据集按照8 ∶2的比例随机分成训练集和测试集,其中训练数据取自研究区西侧,测试数据选取研究区的东侧树。最后,将包含(x,y,z)坐标的原始点云数据、标签值和归一化数据转换成HDF5格式。详见表2。

表2 训练集与测试集
1.4 网络模型构建
网络模型分为特征映射模块、对称函数模块和分类器模块,如图7所示。对每一个单木点云取固定值N个点,每个点有三个维度的特征(x,y,z),即点的三维坐标。在特征映射模块中,输入的是N×3的矩阵,经过三层权重共享的多层感知器(Multi-Layer Perceptron, MLP)将每个点映射到1 024维的高维空间,得到N×1 024的特征矩阵。在对称函数模块,通过对称函数max pooling得到1×1 024维的全局特征。最后,在分类器模块,以全局特征作为输入,通过两个全连接层和一个softmax分类器得到两个树种的分类概率。
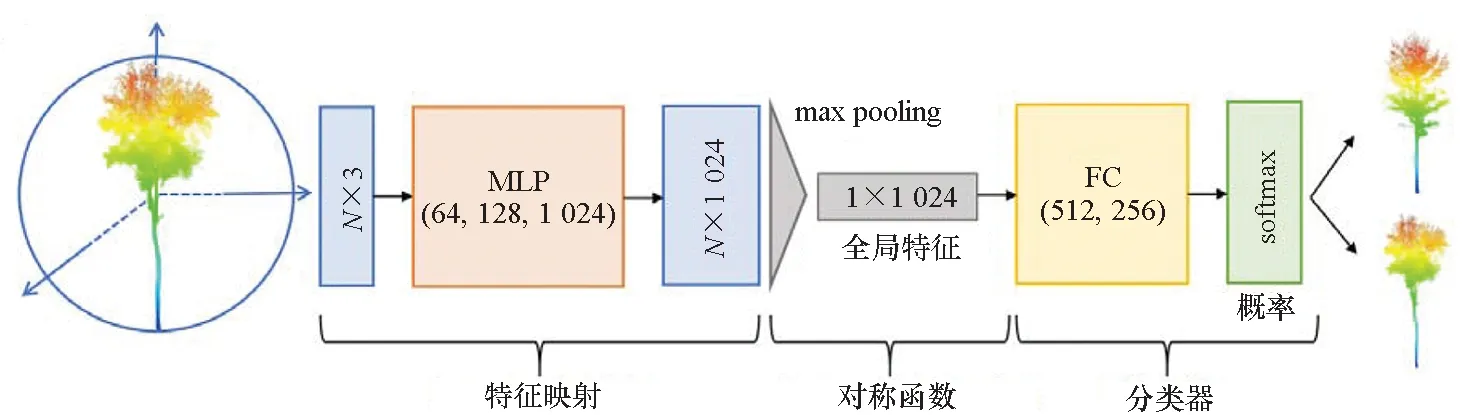
图7 神经网络模型Fig.7 Neural network model
1)特征映射模块:多层感知器是一种前向结构的人工神经网络,层与层之间全连接,在输入与输出的向量之间能够进行非线性映射。将输入层向量记为X,则隐藏层的输出为f(W1X+b1),其中W1为权重(也叫连接系数),b1为偏置,f是激活函数。在该网络模型中,感知器的每一层都使用了ReLU激活函数和批处理归一化,输出大小依次为64、128、1 024。
2)对称函数模块:点云是一个无序点的集合,而点的顺序不会影响这个集合本身。如果把点云表示为一个N行D列的二维矩阵(其中N代表点的个数,D代表点的维度),对该矩阵做行变换则一共有N!种变换方式,而这N!种置换代表的是同一点集,因此网络需要拥有对点云的置换不变性。对称函数能够很好地解决这个问题,例如对某一点的集合X(x1,x2,…,xn),取该集合的最大值、最小值、平均值都与点的顺序无关。但是,直接对每个点做对称操作,例如取最大值,会得到整个点集的最远点值;取平均值,会得到点集的重心,这样会损失点集有意义几何信息。因此,在网络结构中,首先利用MLP对每个点做相同的高维映射,通过高维空间中信息的冗余性避免对称操作导致的信息丢失。该结构实质上是h、g、Υ的函数组合:
f(x1,x2,…,xn)=Υg(h(x1),h(x2),…,h(xn))
(2)
其中,h代表高维映射,g代表对称函数,Υ代表MLP整合信息。
3)分类器模块:对于得到的全局特征向量,将其输入两个全连接层(Fully Connected layers, FC)中,并在最后一个层(输出维度为256)中使用0.7的dropout防止过拟合。在softmax分类损失中加入一个正则化损失(权重为0.001),使矩阵接近正交。
1.5 实验过程
实验使用NVIDIA Tesla V100-PCIE-16 GB显卡,在Ubuntu 18.4系统下搭配cuda 10.0框架和cuDNN 7.4.1加速库训练。编译语言使用Python3.6,深度学习框架为Tensorflow-gpu-1.13.1。模型使用Adam优化器,初始学习率为0.001,最小学习率设定为0.000 01,通过指数衰减的方式实现学习率衰减,衰减率为0.7,动量为0.9,共训练200个周期,每20个周期学习率除以2,批处理归一化的衰减率从0.5开始,逐渐增加到0.99,训练时长18 min。为了更好地提高模型的泛化能力,在训练过程中,通过沿上轴随机旋转物体来动态地增强点云,并通过均值为0和标准偏差为0.02的高斯噪声来抖动每个点的位置。
为了探究单木分割效果对分类结果的影响,同时使本文方法和实验结果更具实际意义,本文又对数据集的结构做了改变。保持原数据集单木个数不变,随机抽取10%、20%、30%、40%、50%的树木样本,并加入同等数量的非完整分割单木。如图8所示,替换的样本有过分割和欠分割的单木,非完整分割的程度及替换次序为随机抽取,未经人工干预。

(a) 白桦(a) Birch
为了证明本实验方法的优越性,与以下三种方法进行比较。
方法1:参考Lin等[22]提出的方法,计算点云数据的9个点分布特征参数、13个冠内结构参数、11个树外结构参数,共计33个特征参数输入一个三层的MLP分类器中进行树种分类。
方法2:参考Guan等[16]提出的方法,如图9所示,取预定义的波形维数n为50,对分割得到的单木进行n个剖面的垂直剖分,将每个剖面的点统计值归一化至0~1内,以生成波形图。将得到的波形图输入一个两层的DBM模型中生成高级特征,进行树种分类。
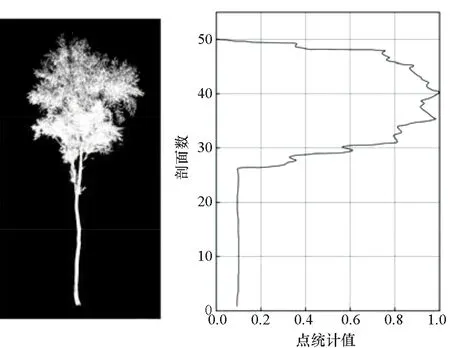
(a) 白桦树样本及其波形图(a) Sample of white birch tree and its waveform
方法3:参考Zou等[17]提出的方法,在样本空间中对单木做栅格化划分,计数每个网格块中的点数,沿y轴在xz平面上积累网格,得到类似灰度图像的图片。对单木点云以相同的旋转度数重复投影,得到的二维图像作为树木的低级特征输入一个三层的DBN,再使用softmax分类器对同一棵树的所有投影图像的分类结果进行投票。参与投票的每幅图像使用相同的权重,并通过赢得大部分选票的类别结果来判定树种。图10为每旋转36°后的栅格化示意,蓝色虚线框内为投影结果。实验中分类最优结果产生在旋转角度为10°时。

图10 单木的栅格化与投影Fig.10 Rasterization and projection of individual tree
2 结果
2.1 分类精度
实验分类结果如表3所示,树种分类的总体准确率(Overall Accuracy, OA)为86.7%,kappa系数为0.73;生产者精度(Producer′s Accuracy,PA)高于85.5%,用户精度(User Accuracy,UA)高于85.0%。图11显示了数据集中非完整分割单木所占比例对分类结果的影响。由图可以看出,当少量样本质量变低时(如占比10%),分类准确率并没有受到较大影响,说明该网络的鲁棒性较好。当低质量样本变多时(如占比30%以上),网络的分类精度会迅速下降,说明此时数据集的质量对网络的学习产生了较大的负面影响。当低质量样本占总样本的50%左右时,网络的分类准确率也降至50%附近,此时对于一个二分类问题来说,相当于网络能在样本中学到的东西是非常少的,近乎随机猜测。
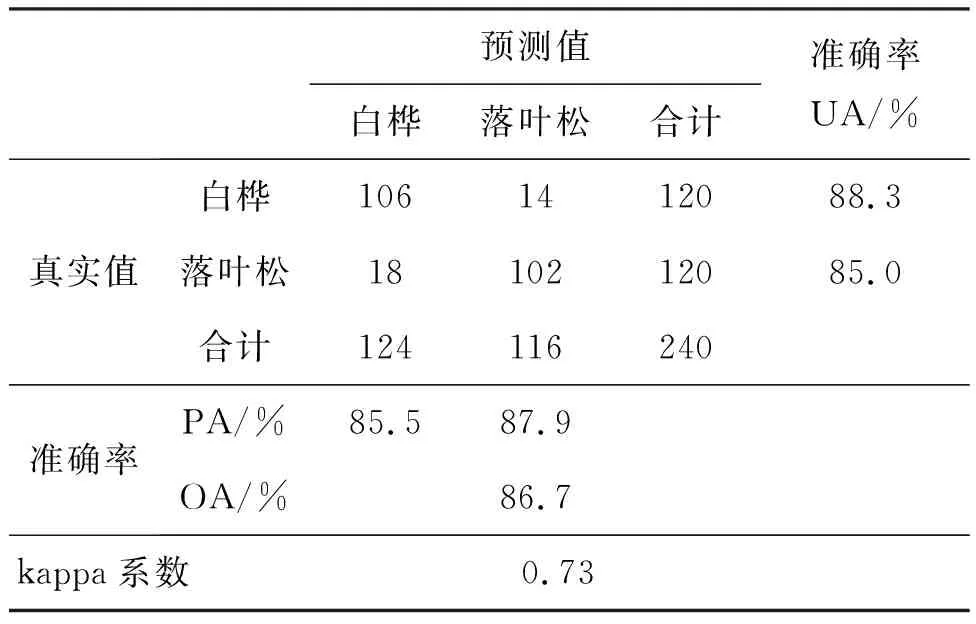
表3 树种分类结果的混淆矩阵
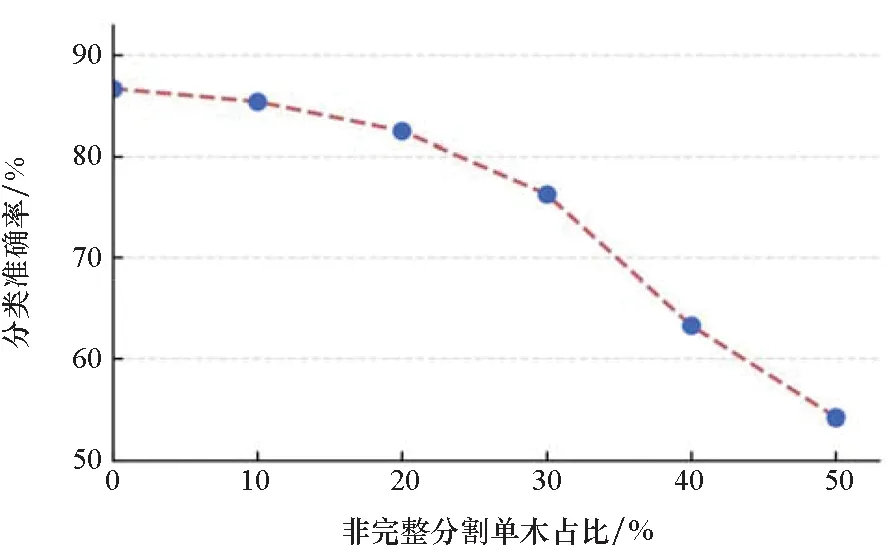
图11 数据集质量对分类准确率的影响Fig.11 Influence of data set quality on classification accuracy
由此可以得出,造成分类错误的原因主要有以下两点:一是白桦和落叶松两个树种在结构形态上具有较高的相似性;二是实验区内的树木比较密集,单木分割的效果会直接影响最后的分类结果。
2.2 方法对比结果
本文方法与1.5节所述三种方法的分类结果如表4所示。其中方法1的分类精度最低,总体精度为81.7%,kappa系数为0.63,该方法虽然统计了树木的33个不同的结构参数,但有限参数加浅层学习的分类方法仍限制了其分类精度。
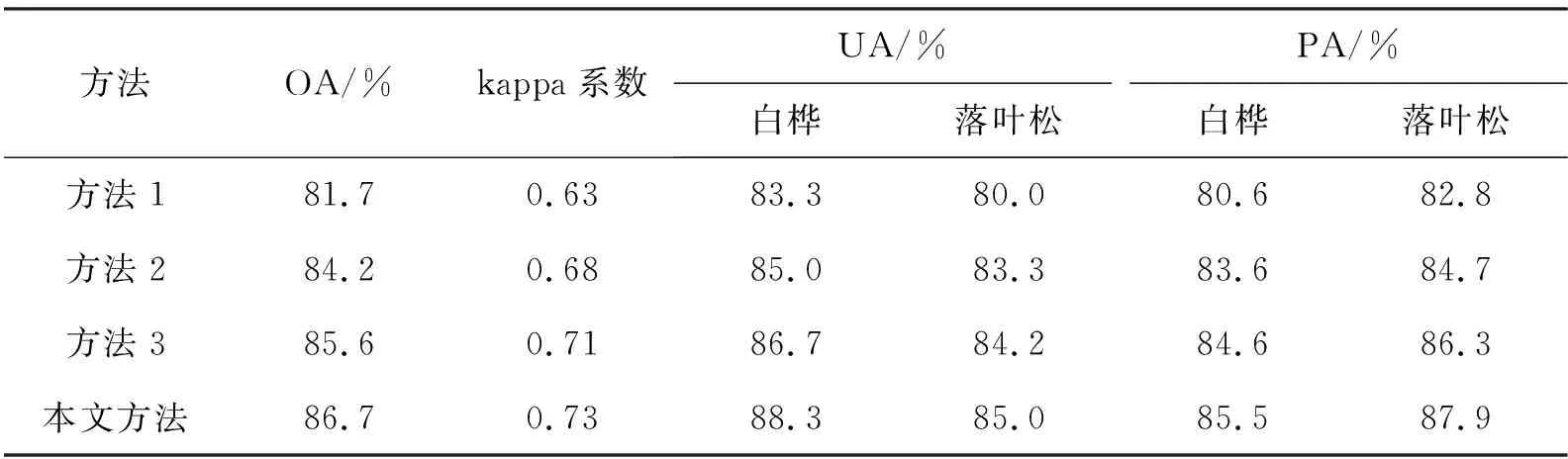
表4 四种方法的分类精度比较结果
方法2的总体准确度为84.2%,kappa系数为0.68,优于方法1,这是因为该方法通过波形数据更好地表示了不同树种独特的几何结构,且使用DBM模型生成了高级特征,减少了人工解译的错误。
方法3的总体精度为85.6%,kappa系数为0.71,优于前两个方法。相较于方法2对每棵树生成唯一的波形表示,每10°重复投影对树木信息的保留更加全面,且大大增加了样本量,有利于深度学习模型的学习,因此得到了更高的分类精度。
实验表明,本文方法优于以上三种方法,其原因是:①与将三维数据转化成二维表达形式的方法相比,基于点的深层神经网络能够有效减少数据转化过程中的信息损失,很好地保留树木的三维结构信息;②本文提出的网络模型能够有效地提取LiDAR数据的高维特征,有利于提高树种分类精度。
2.3 特征维度对分类结果的影响
为了避免点云数据几何信息的损失,本文在对称操作之前,通过参数共享的MLP将每个点映射到一个高维空间。为了探究点的特征维度对分类结果的影响,对使用128、256、512、1 024、2 048维特征的分类准确度进行了比较(如图12所示)。结果表明,随着特征维度的增加,总体分类准确度提高,点云的几何信息得到了更好的保留。当特征维度达到约1 000时,分类性能达到最好。当特征维度超过1 000以后,分类性能无明显提升。
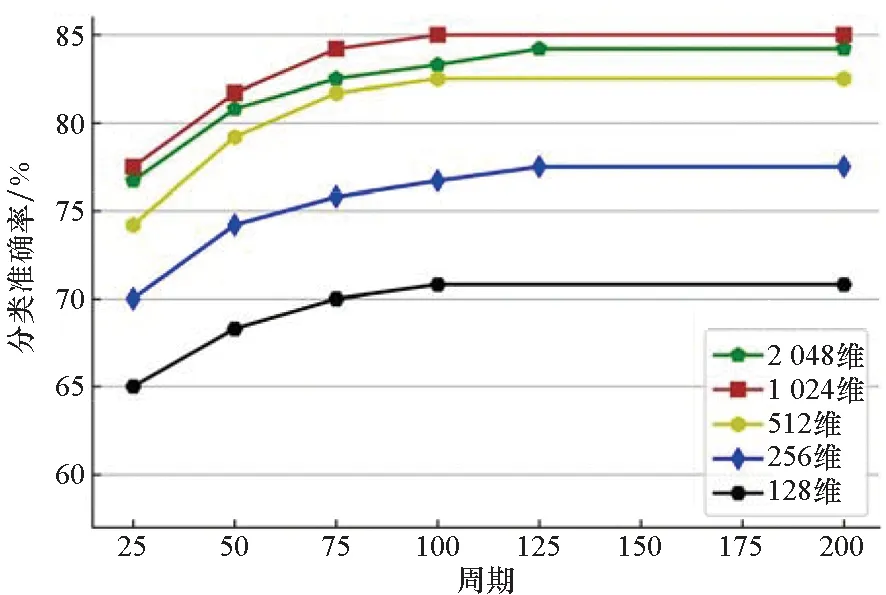
图12 特征维度对分类准确率的影响Fig.12 Influence of feature dimensions on classification accuracy
2.4 点密度对分类结果的影响
本研究对分割得到的单木数据分别进行五次均匀下采样,如图13所示,采样点个数从128增加至2 048的过程中,分类准确度提升了13.1%。当每棵树的采样点数量超过2 000时,网络的分类性能趋于饱和。点密度的增加促使分类效果大幅提升的原因主要是白桦和落叶松两个树种相似度较高,增加点密度能够保留更多的几何结构信息,使得深度神经网络能够更好地学习。而当点密度增加到一定数值时,网络能学到的信息趋于饱和,过大的点密度只会增加信息的冗余程度而很难提升分类性能。
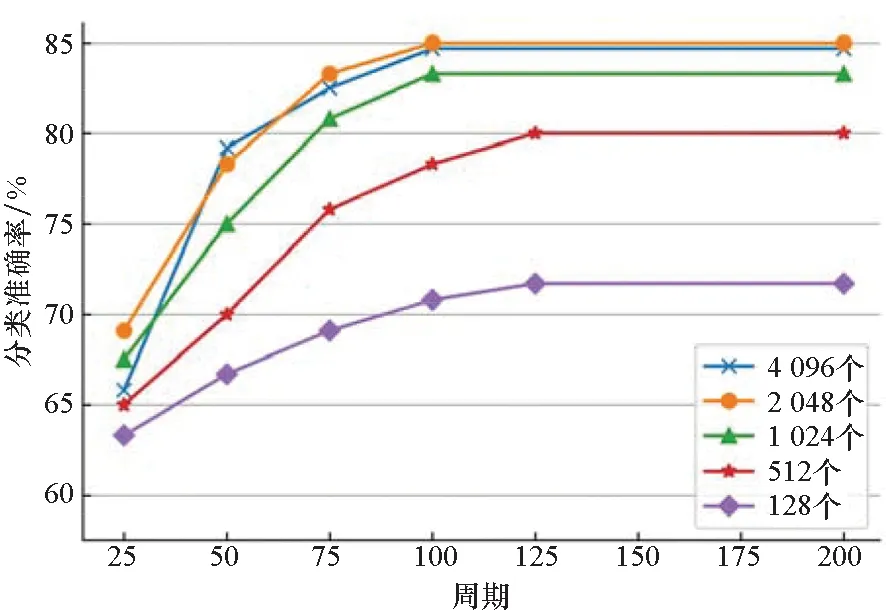
图13 密度对分类准确率的影响Fig.13 Effect of dot density on classification accuracy
3 结论
本研究提出了一种新的基于三维深度学习的树种分类方法。该方法对预处理后的点云数据做单木分割,将得到的单木点云作为模型的输入,利用由特征映射模块、对称函数模块和分类器模块组成的深度神经网络自动提取树木的高维特征并实现树种分类。通过实验得到以下结论:
1)本研究在树种分类任务上取得了较好的效果,在包含白桦树和落叶松两个树种的数据集上实现了86.7%的总体精度和0.73的kappa系数。
2)实验结果表明,相比于特征参数法、波形图法和栅格化投影法,本文方法在特征提取上存在优势,有助于提高树种分类精度。
3)随着点的特征维度和点密度的增加,分类准确率不断提高,但存在提高的临界值。在该数据集中,对每棵树取2 048个点,每个点取1 024维特征时,模型的分类效果最好。
猜你喜欢
一重技术(2021年5期)2022-01-18
数学小灵通(1-2年级)(2021年4期)2021-06-09
林业科技(2020年3期)2021-01-21
意林·少年版(2020年17期)2020-10-12
发明与创新·中学生(2020年4期)2020-04-17
电子制作(2018年11期)2018-08-04
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
华人时刊(2016年16期)2016-04-05
少儿科学周刊·少年版(2015年3期)2015-07-07
