
时间维度下的史籍全文自动重组研究—数字人文视角下的探索
2022-04-01 01:57张琪王东波黄水清李斌孟凯邓三鸿
图书情报知识 2022年1期
张琪 王东波 黄水清 李斌 孟凯 邓三鸿
(1.南京大学信息管理学院,南京,210023; 2.南京农业大学信息管理学院,江苏,21095; 3.南京师范大学文学院,南京,210023; 4.南京农业大学马克思主义学院,南京,210095; 5.江苏省数据工程与知识服务重点实验室,南京,210023)
1 引言
时间是信息空间的重要维度[1],也是历史学家研究历史主体的重要工具[2]。在时间序列中,史学家“通古今之变”,揭示社会、经济、文化的发展线索与规律。然而,在以纪传体、国别体、纪事本末体等体裁写就的史书中,时间线索被斩断。一方面,描述同一时间段历史事件的史料分散于一部史书的各卷乃至多部史书之中;另一方面,史书中的时间描述存在省略、共指、歧义、模糊等特点。在两者的共同作用下,增加了读者收集和处理信息的负担。
知识重组旨在重新组织知识客体,从而克服因知识分散而造成的检索困难[3]。以时间为线索重组史籍能够有效解决时间维度下史料分散的问题,帮助读者快速定位与时间相关联的所有相关史料。然而,古汉语史书时间描述中时间元素的多样性与复杂性使得任务具有极高的复杂度。一方面,“桓公”“齊桓公小白”“齊桓公午”等表述存在歧义与共指;另一方面,“後三年”“十一月晦”等时间描述缺失必要的时间元素。文献[4]将时间描述划分为精确型时间描述(Precise Time Expressions,如“桓公五年”“五年”)、模糊型时间描述(如“昔者”“先日”“将来”“后代”等)以及事件触发型时间描述(“桓公立”“幽公弟沸自立,是為魏公”)等类型。Zhao和Jin等人[5]进一步将精确型时间描述划分为时间元素完备的显式时间描述(Explicit Time Expressions,如“秦穆公任好元年”“桓公五年”)和缺失时间元素的隐式时间描述(Implicit Time Expressions,如“元年”“其岁”“後三年”“十一月晦”)。可见,时间维度下的史书全文重组无法通过简单的字符串处理完成。
历史上,“东汉史学家荀悦将纪传体的《汉书》删改成编年体的《汉纪》[6]”。固然,除完成时间维度的史书全文重组外,《汉纪》还采用类举等方法为编年体史书的写作做出了卓越的贡献。然而就时间维度的史料查询层面来看,随着历史的推移和史书数量的增多,时间维度的信息离散规模也随之扩大—历代史官以纪传体写就二十五部正史(又有二十四史,二十六史之说);“《隋书·经籍志》著录史书817部”[7]……显然难以通过人工完成对所有史书的重写。数字人文的研究范式下,面对规模庞大的史籍,亟待探索一套以时间为线索重组史书全文的自动化方法。
本研究探索了以时间为线索重组史书全文的方法,并将其分解为以下两个子问题:
(1)古汉语时间描述识别与语义解析:完成时间描述识别、时间描述规范化和时间表达式链接;
(2)事件句识别与事件时间语义关联:包含事件句识别和事件时间语义关联。
最终,本文将提出的方法应用于纪传体史书《史记》与国别体史书《国语》中,检验方法的有效性。本研究采用数字手段回应人文研究中信息获取和处理的需求,旨在破除纪传体等史书体裁形成的时间信息获取壁垒,从而改善人文领域学者获取信息的方式方法。这是数字人文研究的具体实践,也是对情报学传统研究领域信息获取与处理技术的探究。
2 相关研究
以时间为主线呈现事件的发生和发展是后续对事件演化形势的研判、分析、预测的基础。然而在以自然语言组成的新闻、医疗等文本中,语言的多样性导致对时间的具体描述往往具有省略、模糊等特性,无法直接加以利用,因此对时间信息处理方法的探索引发了各国学者的关注。
英文与现代汉语领域对时间信息处理的研究已经相对比较成熟,相关研究主要涉及时间描述抽取、时间描述规范化以及时间事件关系抽取三方面:
(1)时间描述抽取(Temporal Extraction)的主要任务是识别非结构化文本中时间描述的边界及其具体类别。时间描述类别及标注规范方面,继英文领域相关规范推出并应用于后续任务之后,自动内容抽取项目(Automatic Content Extraction Program,ACE)[4]于2009年发布了中文时间标注规范,将中文时间描述划分为精确型、模糊型、事件触发型等,为后续开展现代汉语时间信息处理研究奠定了基础;时间描述识别算法与模型方面,冷启动条件下往往采用基于规则的方法[8-9]。随着中英领域相关语料库日渐成熟,机器学习和深度学习的方法受到更多关注[10-11]。
(2)时间规范化(Temporal Normalization)是指利用时间描述之间的关系,将文本中的时间描述如“下周三”“某月某日”等转变为形如“年-月-日”的规范化表达。相关研究主要面向新闻文本提出上下文无关策略和上下文局部相关策略,前者将新闻文本的发布时间作为参照时间(Reference Time),后者则主要采用最邻近的上文时间作为参照时间,之后又提出了两者相融合的动态选择方法[5]。本研究分析了涉及古汉语时间的规范化问题,由于史籍成书时间对正文具体时间描述的参照价值较小,因此必须结合史书自身特点制定相应的时间规范化方法。
(3)时间事件关系抽取(Temporal Relation Extraction)包括事件与时间的关系[12](又称为事件时间对齐,Event Time Alignment)以及事件时序关系[13],前者确定事件与时间描述的关系,后者确定事件发生的先后顺序。其中,事件与时间的关联主要通过文本内容的相关性、修辞成分等特征确定,文本中所描述的事件往往与上下文中一定范围内出现的时间具有相关性,但在史书中呈现何种关联仍有待探索。
综合已有研究所涉及的语言类别及文本类别可知,过去对时间信息处理的研究主要集中在英文及现代汉语领域且主要面向新闻文本,近年来则正在朝多语言[14]、多领域[15-16]的方向发展。
相较于英文与现代汉语,古汉语文本中的时间描述更具特殊性和多样性。特殊性主要体现在纪年法的不同,多样性则表现在古汉语中除年、月、日之外还有王公名、年号等时间元素,因此古汉语时间信息处理与上述研究存在较大差异。需要指出的是,古籍的成书年代、版本年代属于外部书目信息,相关研究如王兆鹏、邵大为[17]以作品创作时间、创作地点为基础实现时间和空间维度下的古代作家资料的整理,而本研究旨在探索史籍全文在时间维度下的自动重组,因此主要关注史籍全文中所包含的时间描述信息。目前相关研究主要包括:肖怀志[18]构建了一个历史年代知识元本体,建模《三国志》所涉及的年号与帝王之间的关系,但仅在理论层面指出了古汉语时间的歧义性,且未探索时间描述自动识别与语义解析的具体方法;董慧、徐雷等[19]提出一套古汉语时间处理流程,主要包含时间表达式抽取模块及以段落为单位的时间规范化模块,但未考虑古汉语时间描述歧义的问题;徐蒙蒙[19]分析了地方志中的时间信息,并初步提出地方志时间描述规范化的方法。
总体来看,目前缺少以下两项关键研究导致无法支持以时间为线索的史书全文重组:
(1)古汉语时间描述消歧与共指消解方法,这一点正是古汉语时间处理与英文、现代汉语时间处理的核心区别,例如“桓公元年”这一时间描述虽包含了完整的时间元素,但“桓公”这一王公名存在歧义;
(2)缺少时间事件句关系识别的相关研究。对上述问题的探索,不仅能够为史书知识跨体裁自动获取与呈现奠定基础,还有利于促进古汉语时间信息处理向深层次、语义化的方向发展。
3 时间维度下的史籍全文自动重组方法
3.1 技术路线
如图1所示,系统以卷为单位(如《高祖本纪》卷)处理史书原文。经过词性标注之后,进入两个核心处理模块。一是时间描述识别与语义解析模块的处理过程,如下:
(1)识别原文中的时间描述(如“桓公五年”“二十七年”);
(2)将存在省略、共指、歧义、模糊性的时间描述统一规范化为具有包含完整元素的古汉语时间表达式;
(3)将时间表达式转化为基准统一、语义唯一(无歧义与共指)的公元时间表达式。
二是事件句识别与事件时间语义关联模块的处理过程,如下:
(1)剔除“王翦者,频阳东乡人也”等陈述客观事实而非表述事件的句子;
(2)大量事件句中不包含时间描述,因此需要通过对史书文本的分析制定方法,建立事件句与时间描述之间的语义关联。
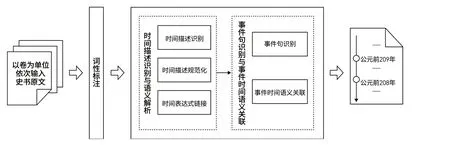
图1 ᅠ时间维度下的史籍全文自动重组技术路线Fig.1 Technology Roadmap of Automatic Reorganization of Historical Records from Time Dimension
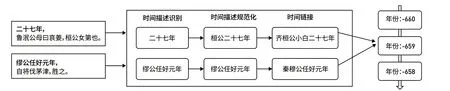
图2 ᅠ时间描述识别与语义解析示例Fig. 2 Examples of Ancient Chinese Temporal Expression Recognition and Semantic Parsing
两个核心模块分别实现了事件句与时间描述以及时间描述与公元时间轴的两层语义关联,从而使史书中的事件句得以定位于基准统一的时间轴上,实现时间维度下的史籍全文自动重组。两个核心模块的进一步描述与其各个子模块的具体实现方法分别在3.2和3.3节中进行阐述。
3.2 时间描述识别与语义解析
如图2所示,时间描述识别与语义解析包含三部分,即时间描述识别、时间描述规范化和时间表达式链接。
3.2.1 时间描述识别
与时间词不同,时间描述指文献中描述时间的完整表述。如“秦侯(NB1)立(VH1)十(S)年(NA5)……”中包含时间词“年”以及时间描述“秦侯立十年”;又如句子“竫公(NB1)子(NA1)立(VH1),是(NH)為(VG)寧公(NB1)”不含时间词,但包含事件触发型时间描述“寧公立”。本研究采用规则匹配的方法识别史书中时间描述的边界及其所属类别,具体规则见脚注①https://github.com/strawberrylunar/ancient-chinese-time-expression中的说明,识别结果示例如表1所示。
对于同一个句子中存在多个时间描述情况,借鉴文献[11]采用优先权值的方法选择时间表达式,本文结合史书时间描述的特点进一步根据不同的情景确定时间描述的优先权值,最终保留优先权值最高的时间描述,其余的时间描述均去除,保证一个句子只有一个时间表达式。如图3所示,以句子“<繆侯七年>,而<魯隱公元年>也”为例,该句包含两个时间描述,由于前文包含显式时间描述,因此进一步判断句子中是否包含王公转换触发词。由于不包含王公转换触发词,因此根据各个时间描述在句子中的位置确定两个时间描述的优先权值,“繆侯七年”的位置为[1,4](即句子“繆侯七年,而魯隱公元年也”的第一个字至第四个字),而“魯隱公元年”的位置为[7,11],前者位置更靠前,因此最终保留“繆侯七年”。
3.2.2 时间描述规范化
时间描述规范化的目的是将上一节从原文中识别到的时间描述转化为包含王公(或年号)、年份、月份等时间元素的时间表达式。本研究根据不同时间描述类型的特点,分别制定了不同的时间规范化方法。

表1 ᅠ时间描述识别结果示例Table 1 Examples of Time Expression Recognition Results
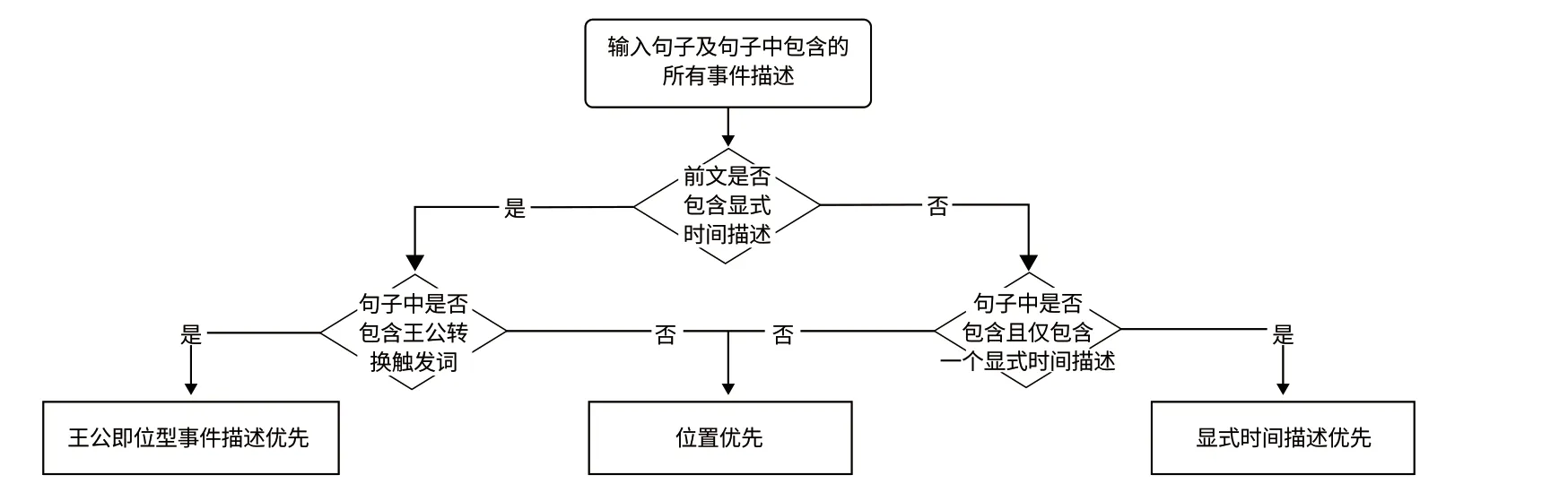
图3 ᅠ基于具体语境的时间描述优先权确定方法Fig.3 Method of Determining the Priority of Time Expression According to Specific Context
精确型时间描述包含显式时间描述与隐式时间描述。显式时间描述的规范化无需依靠参照时间,直接在时间描述实例内部提取相应时间元素分别填充对应槽位即可。隐式时间描述规范化则需要结合参照时间、偏移粒度、偏移量,将时间描述(如“元年”)解析为包含完整时间元素的时间表达式(如“王公:齊桓公;年份:元年”和“年号:元鼎;年份:三年”)。不同的文本类型在参照时间的选择方法上有所差异,一般分为上下文无关策略和上下文局部相关策略。与新闻、临床报告等文本不同,史书对历史事件的时间描述较少以成书时间为基准,而往往以上文时间描述为参照,因此本研究采用上文局部相关策略规范化隐式时间描述。其中,“二十七年”“元年”等省略型时间直接从参照时间中提取缺失的信息;“是歲”“後六年”等方位型时间描述则首先获取偏移方向、偏移粒度以及偏移量,完成后再进行规范化处理。值得注意的是,若方位型时间前为模糊型时间,其参照时间不应继续向前追溯。
事件触发型时间描述通过特殊事件指出具体时间,本文主要考虑了如“幽公弟沸自立,是為魏公”等王公即位型时间描述,即通过王位更替这一特殊事件指明时间。值得注意的是,各诸侯国在王位的更替衔接中在何年为元年的问题上具有不同的取向。根据陈美东[21]对西周共和之后纪年法进行系统探究所得出的结论可知,大部分诸侯国采用次年王公纪年法,而晋、宋、卫采用当年王公纪年法。因此,将涉及晋、宋、卫三国的王公即位型时间描述的年份设为“元年”,其他国家王公的时间描述均设为“零年”(元年的前一年)。
模糊型时间描述无法准确定位在时间轴上,且转换后的结果将直接影响后续时间描述规范化的准确性,因此仅做识别但不进行规范化处理。
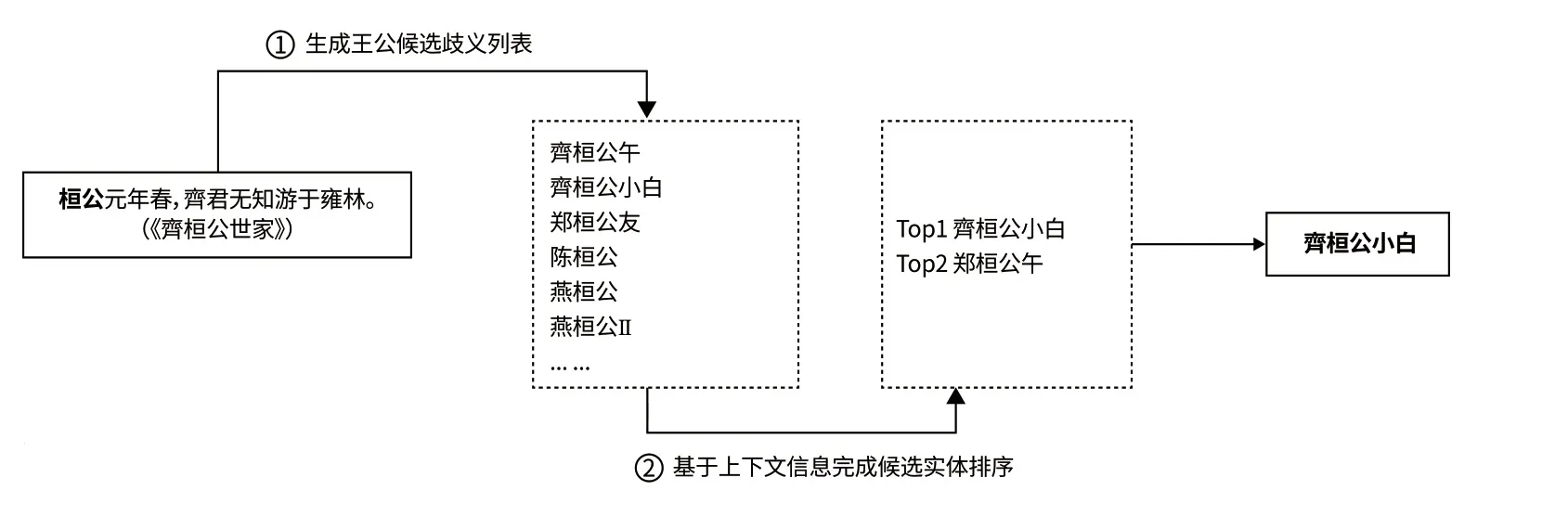
图4 ᅠ王公实体消歧实例Fig.4 Example of Emperor Entities' Disambiguation
3.2.3 时间表达式链接
{王公:桓公,年份:二十七年}、{王公:缪公,年份:元年}等时间表达式具有完整时间元素,但无法直接通过计算定位在同一条时间轴上,必须解决的问题包括时间元素层面的歧义、共指,以及时间表达式整体层面的共指。
(1)时间元素消歧与共指消解
古汉语时间元素的歧义主要在于王公名(或年号)存在歧义,例如,仅春秋战国时期谥号为“桓公”的王公多达十一位。为此,本研究探索了作为时间元素的王公实体的自动消歧方法。如图4所示,首先生成候选实体列表(Candidate Entity Generation),继而结合上下文信息进行置信度排序从而完成消歧(Entity Disambiguation)。
① 生成王公候选歧义列表与王公别名列表
若王公名Mi存在歧义,则其具有候选王公候选歧义列表Ci=(ei1,...,eij)。本研究构建王公候选歧义列表的方法如下:首先,编写正则表达式匹配史书年表中形如“齊桓公小白”“齊桓公午”等王公主称谓。其次,将其进行分解从而得到王公的多个别名,并通过史书引得进一步补充王公别名,形成王公别名表,如表2所示。最后,对王公别名表进行纵向对比,若两个或多个王公实体具有相同别名,则将相同别名放入王公歧义列表,同时将其对应的所有王公主称谓放入该歧义王公名的候选歧义列表。例如,“齊桓公”具有歧义,其对应的王公候选歧义列表包括“齊桓公小白”与“齊桓公午”等。
② 基于上下文信息相关度排序完成王公实体消歧
通过对包含歧义王公名的文本内容及逻辑结构进行分析,发现以下特征:
(a)歧义王公名中被省略的“国家”元素在上文出现频率较高;(b)史书篇章内部的时间记叙多为顺序。因此,分别计算了候选王公所属诸侯国上文出现频率、候选王公与上文王公实体的时间连贯性,将两者转化为权重值相加,得分最高的候选实体作为消歧结果,具体实现方法如下:
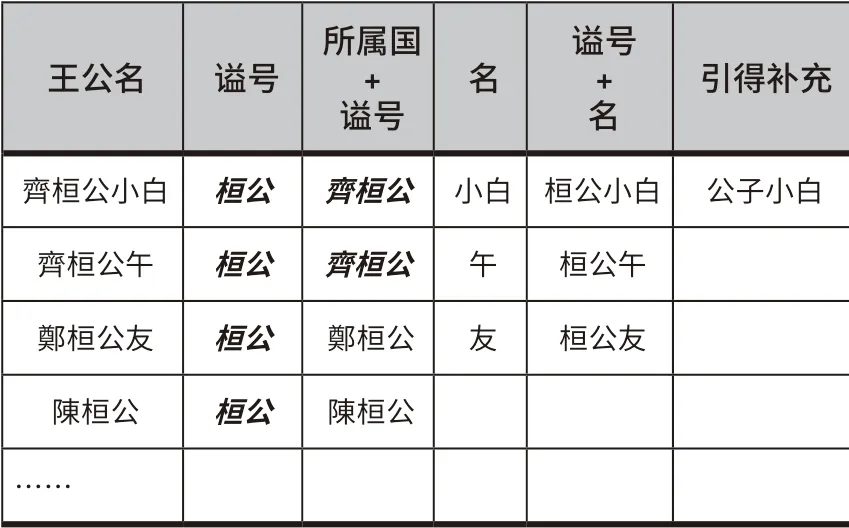
表2 ᅠ王公别名列表与歧义列表生成示例Table 2 Examples of Generating Alias List and Ambiguity List
首先,统计歧义王公上文中各诸侯国的出现频次。由于“齊桓公小白”等王公正式称谓均包含其所属国家(诸侯国),因此若判定歧义王公所属国家,便可大范围缩小链接范围。统计歧义实体的上文(Preceding Text)中各候选王公实体所属国家ekij的出现频次Npre(ekij),频次越高,候选王公实体的权重也越高,如公式1所示。
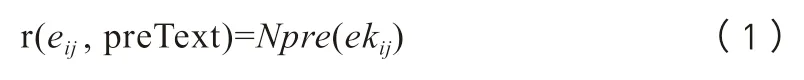
然后,量化候选王公与上文王公实体的时间连贯性。与前文最相邻时间描述所对应的公元时间进行大小比较,大于前文时间且时间距离越近则时间连贯性越强,如公式2所示。
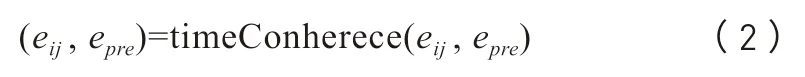
最终,将上述两项转化为权重值相加(公式3),得到歧义王公与候选王公列表中各个实体的相关度权重。将相关度权重排序,将权重最高的ei作为消歧结果输出,如公式4所示。
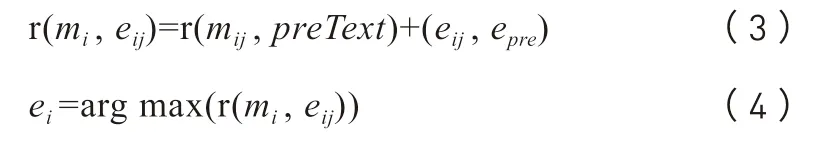
③ 借助王公别名列表完成王公实体的共指消解
如表2所示,在生成王公候选歧义列表的过程中,也生成了王公别名列表(如“齊桓公小白”的别名有:“齊桓公”“小白”“小白”“桓公小白”“公子小白”)。在前文完成王公实体消歧的基础上,以该别名列表为依据,通过映射完成王公实体的共指消解。
(2)时间表达式整体共指消解
对于“王公:秦缪公任好,年份:元年”“齊桓公小白,年份:二十七年”等时间表达式整体层面的共指问题,由于以《春秋》等史书采用一国纪年作为基准的方式难以串联所有的历史时期,本文以近代史学家所制定的中西历对照表为基准,以公元纪年为标准统一所有时间描述。经过上述规范化处理与消歧、共指消解处理,史书原文中的“二十七年”等时间描述被解析为具有完整时间元素的古汉语时间表达式与公元时间表达式。
3.3 事件句识别与事件时间语义关联
为实现史书原文句子以时间为线索的重组,必须确定句子与时间描述之间的关系。然而,一方面,并非所有句子都具有事件属性,例如“二十七年,鲁泯公母曰哀姜,桓公女弟也”虽包含时间描述,但其仅表述客观事实,因此不具有事件属性,不应定位于时间轴上;另一方面,大量事件句自身不包含时间描述,如“桓公召哀姜,杀之”。本研究首先识别事件句,然后将事件句关联至时间描述,如图5所示。
3.3.1 事件句识别
事件句表示一个具有实际终点的、叙述完整且独立的句子[22],自然语言处理领域多借助动词、介词短语等标注事件句[23-24]。本文结合词性标记识别事件句,以台湾“中央研究院”所提供的标注集为例,该数据集将动词分为动作类动词(动作不及物动词、动作类单宾动词等6种,标记为VA-VF)、状态类动词(状态不及物动词、状态句宾动词等5种,标记为VH-VL)以及分类动词(VG)三类[25]。本文将包含动作类动词及状态类动词的句子视为事件句,识别结果示例如表3所示。
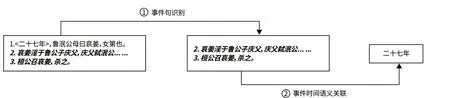
图5 ᅠ事件句识别与事件时间语义关联实例Fig 5 Examples of Event Sentence Recognition and Event-time Relation Extraction

表3 ᅠ事件句识别结果示例Table 3 Examples of Event Sentence Recognition Results
3.3.2 事件时间语义关联
由于史书写作具有很强的逻辑性,文本中所记载的事件往往与其在一定距离范围内的时间描述相关联,因此本文采用了前向邻近时间焦点保留的方法,并考虑了时间焦点转移的情况,从而完成事件句与时间描述的语义关联。具体处理过程如下:按文本叙述先后顺序输入所有事件句,若事件句中含有时间描述,直接将其与事件句关联;若事件句中不含时间描述,则首先判断时间焦点是否发生转移。在时间焦点未发生转移的情况下(见表4),链接至上文最邻近时间描述;若时间焦点转移,则时间置为空,直至出现下一个时间描述。
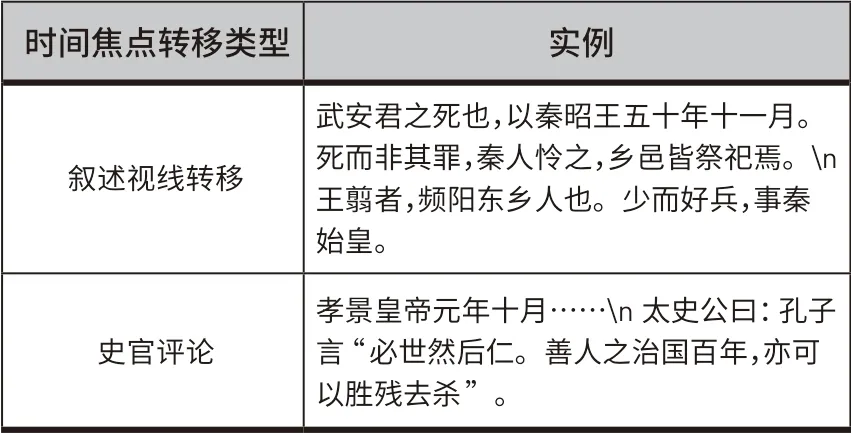
表4 ᅠ时间焦点转移类型Table 4 Types of Time Focus Shift
4 时间维度下的《国语》《史记》重组
本章将上文提出的方法应用至体裁不同的史书,从而验证其有效性。鉴于中国古代由史官写就的正史均采用纪传体,因此选取我国第一部纪传体史书《史记》,另外选取了与《史记》所涉时代有重叠的另一部国别体史书《国语》。下文首先介绍语料的获取与预处理过程,然后对系统标注结果进行评价与分析。
4.1 语料来源与预处理
本文分别基于台湾“中央研究院”上古汉语语料库[26]与中国哲学电子书电子计划[27]中获取两册史书的两种电子化语料,前者包含领域专家所添加的分词与词性标记、特征标记;后者具有段落信息,且包含已添加公元年份的史书年表,整合之后得到本研究所采用的语料,语料基础信息在表5中给出。在此基础上,将每卷语料按句进行分割,并为其中每个句子添加由“段落号-句子编号”组成的唯一标识。
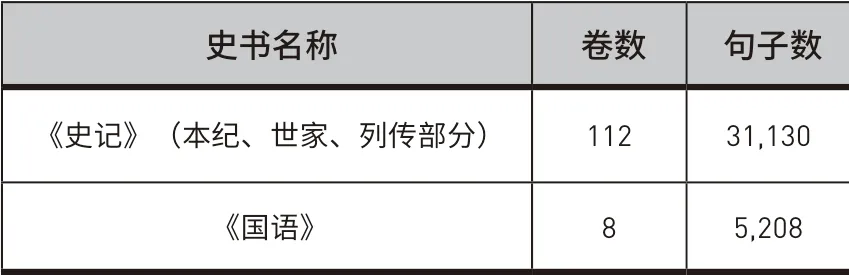
表5 ᅠ实验语料基础信息Table 5 Basic Information of Experimental Corpus
王公名消歧与共指消解所采用的王公同名词典与王公别名词典的具体获取方式已在上文给出。此处针对《史记》与《国语》的抽取结果如下:共获得具有歧义的王公名233个(如“桓公”),共涉及1,012位王公(如“齊桓公小白”“齊桓公午”等);共获得具有别名的王公963位(如“齊桓公小白”),共涉及2,255个王公名(如“公子小白”“桓公小白”“小白”“桓公”“齊桓公”),平均每个王公有2.34个别名。
中西历时间映射词典获取自经人工补齐公元年份的《史记》年表[27]。编写正则表达式提取王公主称谓(若缺少王公所属国,根据表头自动补齐)及其在位元年所对应的公元年份,共获取441条记录,词典样例如表6所示。
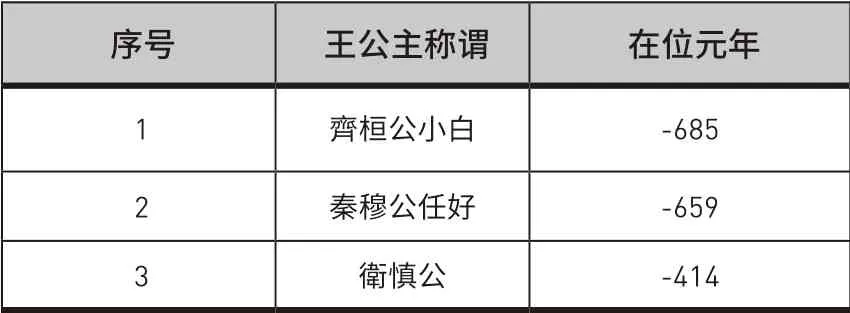
表6 ᅠ中西历映射词典样例Table 6 Examples of Chinese and Western Calendar Mapping Dictionary
4.2 实验结果
融合《国语》《史记》两部史书的历史事件时间轴示例如图6所示,《史记·周本纪》《史记·秦本纪》以及《周语·国语上》等不同史书或不同卷册中的历史事件被定位至同一时间轴上。可见本研究提出的方法能够有效地将《史记》等非编年体史书中的历史事件以时间为脉络重组,便于以时间为索引获取同一史书以及不同史书中的相关信息。
为了对处理效果进行定量评价,表7给出了《史记》《国语》的处理结果。最终《史记》中有19,868个事件句定位于时间轴上,《国语》中则有715个事件句定位于时间轴上。需要进一步说明的是,部分直接从原文中获取的时间描述及其所对应的事件句未能链接至公元时间轴,主要原因如下:
(1)时间描述规范化过程中,与新闻文本中前文缺乏局部参照时间时可转而采用参照发布时间不同,若前文缺乏可参照时间,隐式时间描述无法进行规范化;

图6 ᅠ历史事件时间轴生成结果示例Fig. 6 Examples of Historical Events' Timeline Generation Results
(2)时间表达式链接过程中,部分规范化之后的时间表达式因目前无法考证其具体所指公元年份,无法链接至公元时间,如“帝颛顼元年”“周文王元年”;
(3)实验所采用中西历映射表缺乏相关信息从而导致的时间表达式链接失败,如“軍臣單于”的在位元年在年表中未给出,之后将进一步扩大中西历映射表覆盖范围。
为了进一步评价系统准确率,在《史记》本纪、世家、列传中各随机选取一卷,在《国语》中选取包含时间描述最多的《晉語四》,人工校验各处理阶段系统的准确率,结果在表8中给出。
如表8所示,总体来看系统达到了较高的准确率,其中《史记》三卷的准确率均达到89%以上,《晉語四》的准确率则为77.33%,可见本研究在减少人工标注的前提下,达到了较高的准确率,取得了较好的应用效果。
为了开展进一步的相关研究,下面主要对系统实现方法存在的不足做分析,提出未来在方法层面改进的可能方向。从系统不同模块的处理效果来看,时间描述识别、时间表达式链接、事件句识别均已达到了较高的准确率,因此重点分析时间描述规范化、事件时间语义关联方法等存在的缺陷以及今后的提升方向。
时间描述规范化模块存在的主要问题是不同史书效果的差异。人工检验发现,《国语》中大量隐式时间在上下文并无可参照时间。未来一方面可以进一步探讨特殊情况下时间描述规范化的方法;另一方面可以引入异文句,借助描述相同事件句子所包含的时间信息加以修正。
事件时间语义关联则可从以下两方面出发展开进一步探索:
(1)部分事件句无法关联至上下文中的任何时间描述,例如《田敬仲完世家》有以下描述:“……<立他,為厲公>。厲公既立,娶蔡女。蔡女淫於蔡人,數歸,厲公亦數如蔡。桓公之少子林怨厲公殺其父與兄,乃令蔡人誘厲公而殺之。”最后一个句子“桓公之少子林怨厲公殺……”被错误关联至前文最邻近时间描述“立他,為厲公”,但参照《陳杞世家》“七年,厲公所殺桓公太子免之三弟,……與蔡人共殺厲公而立躍,是為利公”可知陳厲公被杀一事发生于陳厲公七年。发生这一错误的原因在于《田敬仲完世家》的描述主体非陈国,因此对陈国事件未逐年详写。此外,插叙而具体描述中缺乏明显的指引词也会导致相同的结果,例如“是歲,管仲、隰朋皆卒。管仲病,桓公問曰:「群臣誰可相者?」”中“管仲病”为插叙。对于上述情况,同样可以在完成异文句对齐的基础上对前者的时间进行修正。

表7 ᅠ《史记》、《国语》处理结果Table 7 Processing Results of Shi Ji and Guo Yu
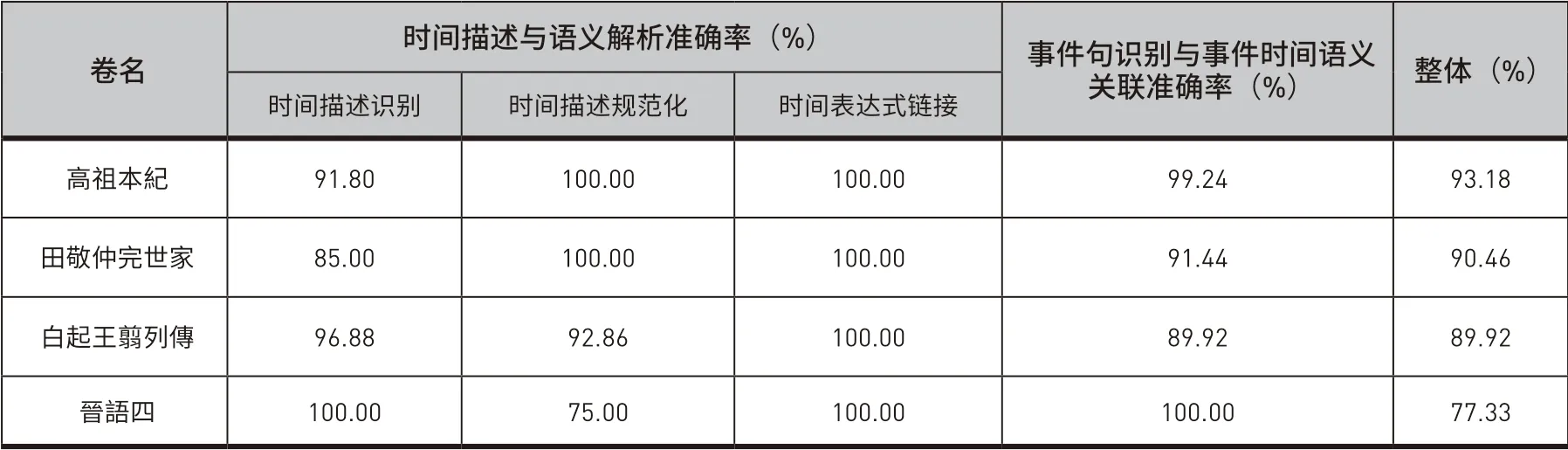
表8 ᅠ各阶段准确率评价结果Table 8 Evaluation Results of Precision Rate at Each Stage
(2)由于史书中具体到月的时间描述极少,因此本文仅定位至以年为粒度的时间轴上,同一年内的事件句无法通过时间描述排序,而需通过词法、句法、语义特征、推理规则判断事件时序关系。但目前缺乏古文方面的整理与归纳,未来可以在对相应特征及推理规则进行系统整理的基础上展开进一步探索。
5 总结与展望
从上世纪八十年代开始,英文、现代汉语时间信息处理领域历经三十多年的探究发展,对时间描述信息的处理已经比较成熟。然而古汉语时间描述的特殊性导致目前的相关研究较少,且大多停留在理论分析上。本研究提出了一套以时间为线索重组史书全文的具体方法,并设计了一套完整的方法流程对其进行了实现。首先,通过古汉语时间描述识别与语义解析,完成时间描述识别、时间描述规范化和时间表达式链接,从而使史书中的时间描述关联至基准统一的公元时间轴;然后,通过事件识别与事件时间语义关联,实现事件句关联至文中的时间描述。通过上述两层语义关联,事件句得以在时间轴上定位,从而完成以时间为序的史料重排。最后,通过实验证明系统达到了较高的准确率,能够有效减少人工标注,便于大规模推广。
同时,本研究也存在一定局限。首先,本研究目前主要对先秦两汉时期史书进行了验证,方法的实用性有待通过扩大语料规模与规则集之后得到进一步证实。其次,本研究在时间描述识别与语义解析的基础上通过史书事件时间对齐将非编年体史书中的事件句定位到以年为单位上的公元时间轴上。由于史书中具体到月、日的时间描述相对较少,同一年及少量同一时期的事件句之间时序的排列将借助事件时序关系识别进一步确定。未来,我们将在本研究的基础上展开进一步探索。
作者贡献说明
王东波,黄水清:提出研究思路;
王东波,张琪,李斌,孟凯:设计研究方案;
王东波,张琪:采集、清洗和分析数据,进行实验,起草论文;
邓三鸿,张琪:论文最终版本修订。
支撑数据
支撑数据由作者自存储,Email:db.wang@njua.edu.cn。
1、王东波,张琪.Pos_taged_shishu.json.史书词性标注结果.
2、王东波,张琪.Dict.json.同名词典与歧义词典.
3、王东波,张琪.Shishu_time_processed_result.json. 史书时间处理结果.
猜你喜欢
暨南学报(哲学社会科学版)(2020年5期)2020-05-15
语文教学与研究(综合天地)(2018年10期)2018-12-24
小学阅读指南·低年级版(2017年11期)2017-12-06
散文百家·下旬刊(2016年9期)2016-11-23
作文周刊·七年级读写版(2016年20期)2016-08-12
戏剧之家(2016年9期)2016-06-04
校园英语·下旬(2016年3期)2016-04-18
戏剧之家(2016年2期)2016-03-03
闽台文化研究(2015年2期)2015-04-17
读与写·下旬刊(2014年6期)2014-08-07
