
面向用户的共享单车预测
2022-03-31 06:27曾友董世权黄闽江夏莉丽徐则中
常州工学院学报 2022年1期
曾友,董世权,黄闽江,夏莉丽,徐则中
(常州工学院计算机科学与技术学院,江苏 常州 213032)
0 引言
作为一种新型的短途通勤方式,无桩共享单车有效缓解了城市交通拥堵的情况。虽然在许多城市大规模部署了共享单车,但由于空间、时间等各种外部因素,造成了共享单车供需的严重失衡[1-2],在高峰时段找车难的问题仍然存在。为此,本文研究了共享单车需求预测方法[3-4],预测未来某时间段内某个地点对共享单车的需求量,提前对各站点的共享单车进行优化配置和调度,以缓解共享单车的供需矛盾。用于站点需求预测的模型主要有:神经网络模型、LSTM线性回归模型、Logit模型,随机森林和时空聚类模型、SVM模型[5-9]等。
然而,这些共享单车的需求预测是为运营商自己服务的,并没有考虑用户的预测需求,为用户提供的查询服务并不能满足用户需求,比如:当用户查询显示前方有共享单车,正当自己前往时,车辆被他人骑走。在现实中,用户的需求是:当找不到共享单车时,用户需要了解附近地点未来一段时间内的单车汇集趋势,从而朝着未来一段时间单车汇聚的地点去找共享单车。所以,从用户的角度出发,对用户周围未来一段时间内共享单车汇集情况进行预测就非常有必要。但是,这种面向用户需求,预测用户周围未来一段时间内的单车汇集趋势,尚未发现相关研究。
1 设计原理
1.1 预测算法流程
运用理论分析、算法设计、实验校验相结合的方法,构建预测模型,运用共享单车大数据对模型进行训练。运用模型预测用户周围未来一段时间内的单车汇集趋势。将程序划分为4个模块,分别为大数据分析与处理、预测模型构建与训练、单车汇集趋势预测、结果可视化。预测流程见图1。

图1 预测算法流程图
大数据分析处理的任务主要为数据清洗。构建随机森林回归模型作为预测模型,并对模型进行训练。获取用户的时间地点信息,运用模型进行预测。可视化部分主要通过热力图形式反映给用户。
1.2 大数据分析与处理
首先对数据集进行数据清洗,去掉节假日的特殊情况,检查数据的完整性、合法性与一致性。然后对数据进行转换,将时间转化为对应的以3 min为一个时间段的数,提取时间,运用Geohash算法解析地理位置。
为了预测附近地点的单车汇集情况,将开始时间、经纬度作为一个三元组存入列表中,统计列表中相同时间、位置的三元组个数作为新字段numbers的值,存入以三元组为键,值为numbers的字典中。在此基础上,写入驶出数据,如果遇到时间地点相同的情况,将前面csv中sum的对应值减去numbers;没遇到时间地点相同的情况时,将字典值的相反数写入到csv中,此csv即可反映单车的汇集情况。
1.3 模型构建与训练
构建随机森林回归模型,运用共享单车大数据对预测模型进行训练,如图2所示。训练生成的模型权重保存到相应的文件中,步骤如下:

图2 模型训练
1)对处理过的共享单车数据集进行行列随机抽样。
2)使用CART算法计算,不进行剪枝操作,让每棵树最大程度生长。
3)基于各个决策树模型的最大投标,得到预测结果。
从共享单车大数据集中,将数据集的80%的数据记录作为训练集,20%的数据记录作为验证集,以验证模型的准确率。
1.4 单车汇集趋势预测
为了预测用户周围未来一段时间内的单车汇集趋势,先获取用户的时间位置信息,根据时间位置数据进行预测。
用户时间提取:每3 min为一个计时单位。
用户位置提取:运用Geohash算法解析地理位置,将经纬度保留两位小数。先将得到的Base32码进行解码,得到二进制数,根据奇位、偶位对应取出纬度、经度的二进制数。得到经纬度的区间,取中间值(0代表左区间,1代表右区间),即可得到经纬度。
把时间、位置数据(y,z)输入随机森林预测模型,对用户周围地点未来t时刻的单车汇集趋势进行预测。
1.5 预测结果可视化
将预测结果进行可视化显示,如图3所示。
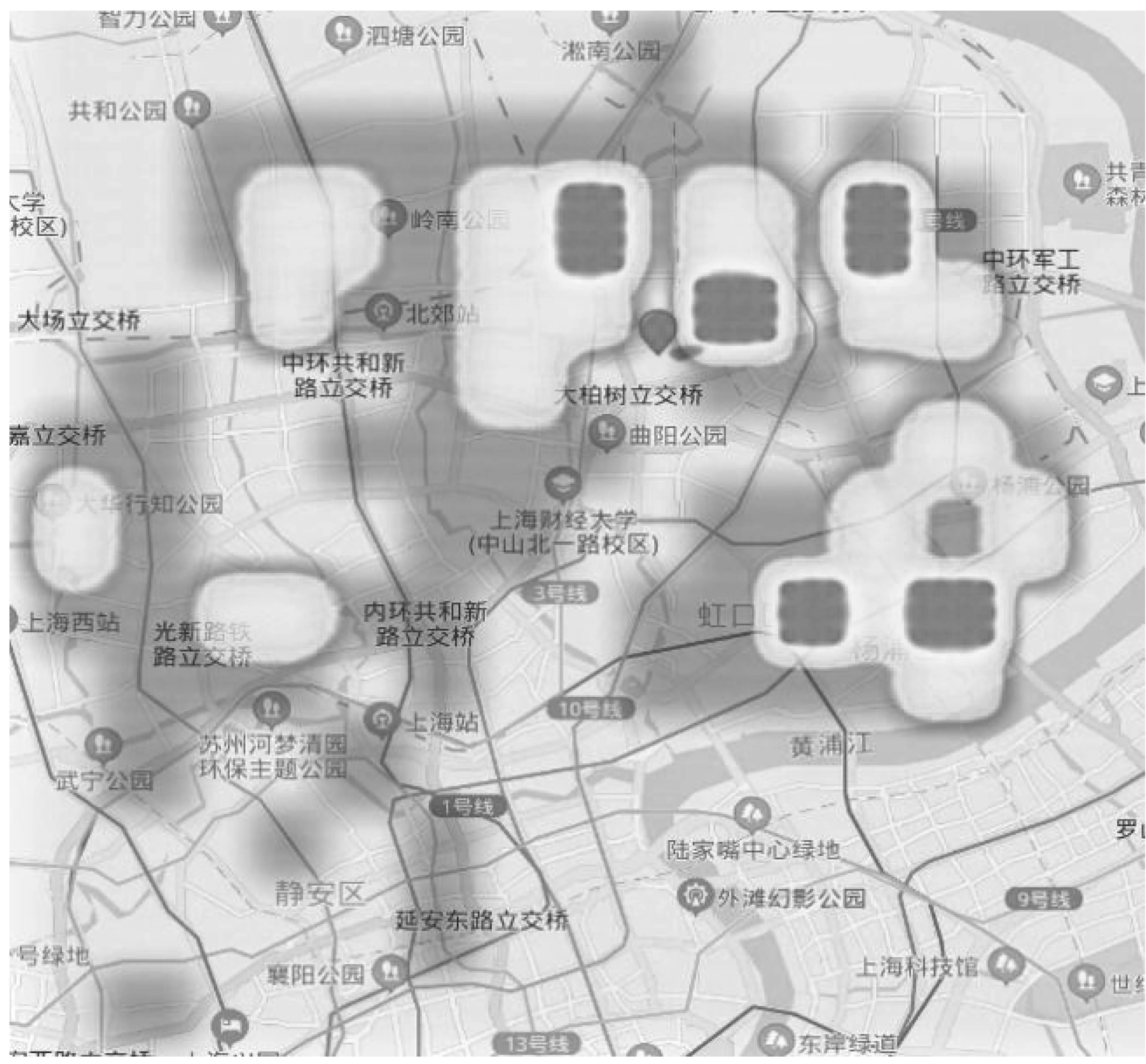
图3 单车汇集趋势
图中灰度值越高的区域代表着未来该地有更多的车辆汇集于此。基于预测结果,引导用户去车辆汇集较多的地方,提高找到单车的可能性。
2 实验结果
根据摩拜单车官方提供的数据集,运用不同的预测模型进行对比分析,选用随机森林模型对共享单车的汇集趋势进行预测,并对预测结果进行分析。
2.1 数据源
本数据集来自上海地区摩拜单车发布的数据,已经过脱敏处理,开放给研究人员使用。该数据集共有102 361条数据记录。
每条原始数据记录包含:订单号、车辆编号、用户编号、出发时间、出发经度、出发纬度、结束时间、结束经度、结束纬度、轨迹等。在本文的预测模型中用到的数据字段有:结束时间、结束经度、结束纬度、开始时间、开始经度、开始纬度。
2.2 预测结果对比分析
为了评判预测模型的准确率,选用均方根误差对预测模型进行评价。随机森林预测模型的预测值与实际值如图4所示。
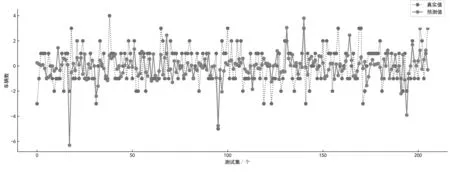
图4 随机森林模型预测值与实际值对比图
另外,本文也构建了多元回归模型、knn近邻回归模型,通过验证集数据,对模型进行预测值与实际值误差计算,计算每种预测模型的准确率。 各个模型之间的均方根误差对比如表1所示。

表1 模型均方根误差对比
从表1的均方根误差数值可以看出,随机森林模型的预测结果最为理想。
3 结语
从用户的角度出发,运用大数据技术,构建了随机森林回归预测模型,对用户周围各地点未来一段时间内的单车汇集趋势进行预测,以热力图
形式对预测结果进行可视化显示,从而引导用户到最可能找到共享单车的地点去寻找共享单车,帮助用户找到单车,提高用户租车体验。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
意林彩版(2022年1期)2022-05-03
师道·教研(2022年1期)2022-03-12
海洋信息技术与应用(2020年1期)2020-06-11
读友·少年文学(清雅版)(2020年1期)2020-05-20
传媒评论(2019年4期)2019-07-13
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
