
基于改进YOLOv4的行人检测算法
2022-03-30 08:15李挺伊力哈木亚尔买买提
科学技术与工程 2022年8期
李挺, 伊力哈木·亚尔买买提
(新疆大学电气工程学院, 乌鲁木齐 830047)
随着经济的快速发展和科技的飞速提高,行人检测在智能视频监控领域应用非常广泛,尤其在大型商场、城市街道、娱乐广场等人群密集的场所,行人检测技术与人流统计、人流跟踪、人流疏导和安全预警工作息息相关。龚露鸣等[1]针对行人误检率问题提出一种基于方向梯度直方图、混合高斯背景建模和支持向量机(support vector machines, SVM) 3种方法结合的行人检测模型,采用前景分割、特征降维、信息更新等多种操作使误检率降低到4%。胡亚洲等[2]提出了一种高点行人检测方法,将帧间差分法和背景建模结合在一起,这种方法应用于高点监控应用场景中使检测精度得到了提升,同时也减少了误检。前人在检测精度和误检率等方面做了很多研究,并且效果得到了一定的提升,但是多尺度和不同运动状态的行人产生的检测结果有很大的差异。深度学习大力发展的时代来临,涌现了很多优秀的目标检测算法,目前主要划分为2类,一类是两阶段的目标检测算法,主要有R-CNN(regions with convolutional neural network features)、Fast RCNN[3](fast regions with convolutional neural network features)、Faster RCNN[4](fast Regions with CNN features),另一类是单阶段的目标检测算法,主要有YOLO(you only look once)、SSD(single shot multibox detector)[5]、YOLOv2(you only look once version2)[6-7]、YOLOv3(you only look once version3)[8]和YOLOv4(you only look once version4)[9]。姚万业等[10]提出了一种改进Faster R-CNN 的行人检测算法,以软化非极大值抑制算法(soft non-maximum suppression,Soft-NMS)代替非极大值抑制算法(non-maximum suppression,NMS)、“Hot Anchors”代替原有的均匀采样,提升了检测速率和准确率。袁小平等[11]针对检测效果不佳的问题,提出了一种改进YOLOv3的行人车辆检测算法,用ResneXt代替Darknet-53中的残差模块,并且加入了密集连接,提高了行人检测的准确率。
综上所述,以上文献在检测精度和漏检率等方面展开了研究,但是存在检测速度慢,实时性差的问题。为此,对YOLOv4算法进行改进,将Mobilenetv2作为主干网络,减少参数量,且加入Bottom-up连接,达到多尺度信息融合的目的;在特征融合网络Neck中嵌入CBAM注意力,使特征表现更加突出;将Inceptionv2结构加入检测网络的最后一层中,增加网络复杂度和减少计算量,以此实现更高的检测精度和更好的实时性。
1 相关工作
1.1 YOLOv4算法原理介绍
1.1.1 算法模型结构
YOLOv4是一种在YOLOv3算法的基础上改进的单阶段目标检测算法,检测性能比较优异。算法结构由主干特征提取网络Backbone、特征融合网络Neck、分类和回归的检测网络 Head组成。经典的YOLOv3目标检测算法,算法结构由主干特征提取网络Darknet53、特征金字塔网络FPN、检测网络YOLO-Head组成。算法主干特征提取网络CSPDarknet53将Darknet53与CSPNet[12]结合,增加网络宽度且保证检测精度;特征融合网络在YOLOv3算法中的特征金字塔网络FPN的基础上加入空间金字塔池化层SPPNet,形成特征融合网络PANet[13],增加特征的丰富性。检测网络继续使用YOLOv3的检测网络。YOLOv3和YOLOv4算法的网络组成部分如表1所示。

表1 YOLOv3和YOLOv4网络对比Table 1 Comparison of YOLOv3 and YOLOv4 networks
1.1.2 算法检测流程
步骤1将输入图片通过主干网络CSPDarkNet53中提取特征,在此过程中使用卷积核大小为3×3,步长为2的卷积层对输入依次进行5次下采样,形成3个有效特征层13×13、26×26、52×52。
步骤2将13×13的特征层通过空间金字塔池化网络(spatial pyramid pooling networks,SPPnet)进行多尺度感受野的融合,并将融合后的13×13特征层与由主干网络生成的26×26、52×52特征层一起通过特征融合网络PANet把浅层具有充分的细节特征与深层具有丰富的语义特征融合,改善了小目标检测效果差的问题,在此过程中共进行了两次上采样、两次下采样、多次卷积和拼接操作。
步骤3将经过特征融合网络后获得的特征层送入检测网络,利用分类和回归将输入图片划分为13×13、26×26、52×52的栅格图,分别检测大、中、小3种不同尺度的目标。每个网格负责预测3个边界框,每一个边界框预测目标的位置信息(含有预测框的中心坐标和宽高)和存在目标的置信度,若数据集中有k个类别,则最终输出特征图的通道数为3×(5+k)。由于研究行人检测,只有行人类别,所以输出特征图的通道数为54。YOLOv4算法与双阶段目标检测算法相比,YOLOv4算法不仅提升了检测精度,还加快了检测速度。
1.2 轻量级网络MobileNetv2
Mobilenetv2[14]是在Mobilenetv1的基础上改进而来的,广泛应用在移动端和嵌入式设备中。Mobilenetv2是一种用来减少参数量的轻量级网络,不仅使用了深度可分离卷积,还运用了倒残差块,还能使网络保持特征的提取能力。深度可分离卷积对于标准卷积而言,其先进行深度卷积,然后在进行标准卷积。
给定特征图A,其维度为(DF,D′F,M),使用N个尺寸大小为(DK,D′K,M)的卷积核对特征图A进行普通卷积,得到维度为(DF,D′F,N)的特征图B,其中M为特征图A的通道数,DF、D′F分别为特征图的长度和宽度,DK、D′K分别为卷积核的长度和宽度,N为特征图C的通道数,所需计算量为
OS=DKD′KMNDFD′F
(1)
式(1)中:OS为普通卷积所需的计算量。
给定特征图A,其维度为(DF,D′F,M),使用M个尺寸大小为(DK,D′K,1)对特征图A进行深度卷积,得到特征图B,B的尺寸大小为(DF,D′F,M);然后使用N个1×1的卷积核对B进行普通卷积,得到维度为(DF,D′F,N)特征图C,其中M为特征图A的通道数,N为特征图C的通道数,所需计算量为
OS1=DKD′KMDFD′F+MNDFD′F
(2)
式(2)中:OS1为深度可分离卷积所需的计算量。
将OS1除以OS可得:深度可分离卷积相对于标准卷积在很大程度上减少了计算量。
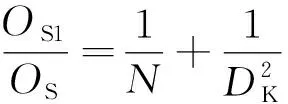
(3)
Mobilenetv2中的倒残差结构首先用1×1的卷积升维,增强了模型的表达能力;然后用3×3的深度可分离卷积提取特征,最后用1×1的卷积降维,使其与输入特征图通道数相同。倒残差结构如图1所示。
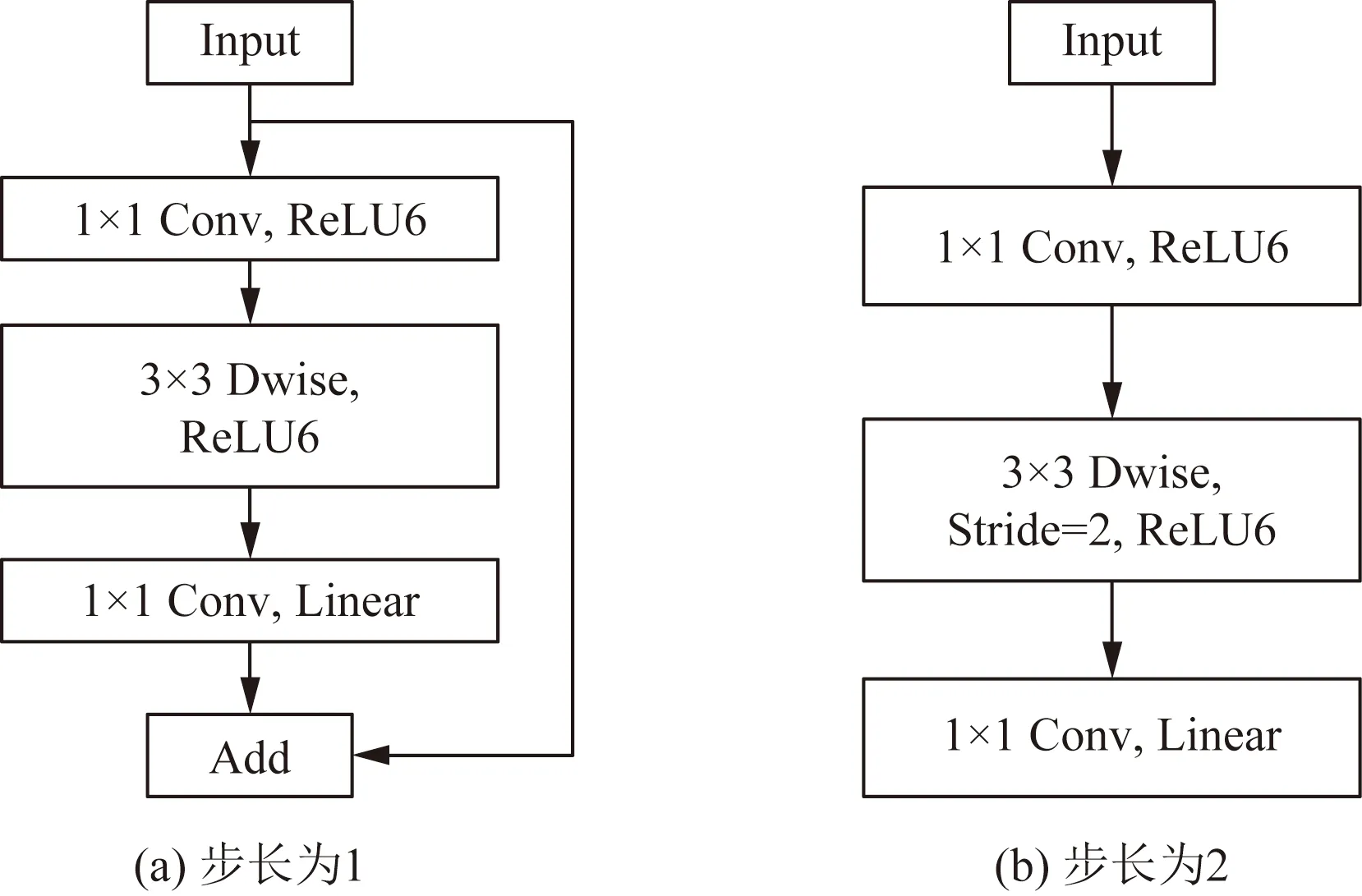
Input为输入;Conv为普通卷积;ReLU6为激活函数;Dwise为深度卷积;Stride为步长;Linear为线性激活函数;Add为加权操作图1 倒残差模型结构Fig.1 Inverted residual model structure
图1(a)为步长为1的倒残差结构,一个分支是经过升维、提取特征、降维操作,另一个分支是残差边部分,输入和输出直接相连。图1(b)为步长为2的倒残差结构,只经过升维、提取特征、降维操作,而没有残差边部分。
1.3 CBAM注意力机制
卷积模块的注意力机制模块(convolirtional block attention module, CBAM)[15]模块融合了通道和空间注意力,首先在通道和空间两个维度上对特征图分配注意力权重,然后将注意力权重和原特征图相乘,这样使神经网络在学习特征的时候更加关注重要像素区域而忽略无关紧要的区域。CBAM模块的总体结构如图2所示。可以看出,通道注意力过程为:输入特征图为F,首先从空间维度上分别进行一次全局平均池化和最大池化,得到两个通道描述子;然后将这两个通道描述子传入一个共享神经网络中,再将生成的两个特征图相加后通过sigmoid激活函数得到权重系数MC;最后将F和MC相乘得到新特征图F1,可表示为
F1=MC(F)⊗F
(4)
式(4)中:MC(F)为特征图F通过通道注意力后生成的权重;F1为F通过通道注意力加权后的新特征图;⊗表示对应元素相乘。
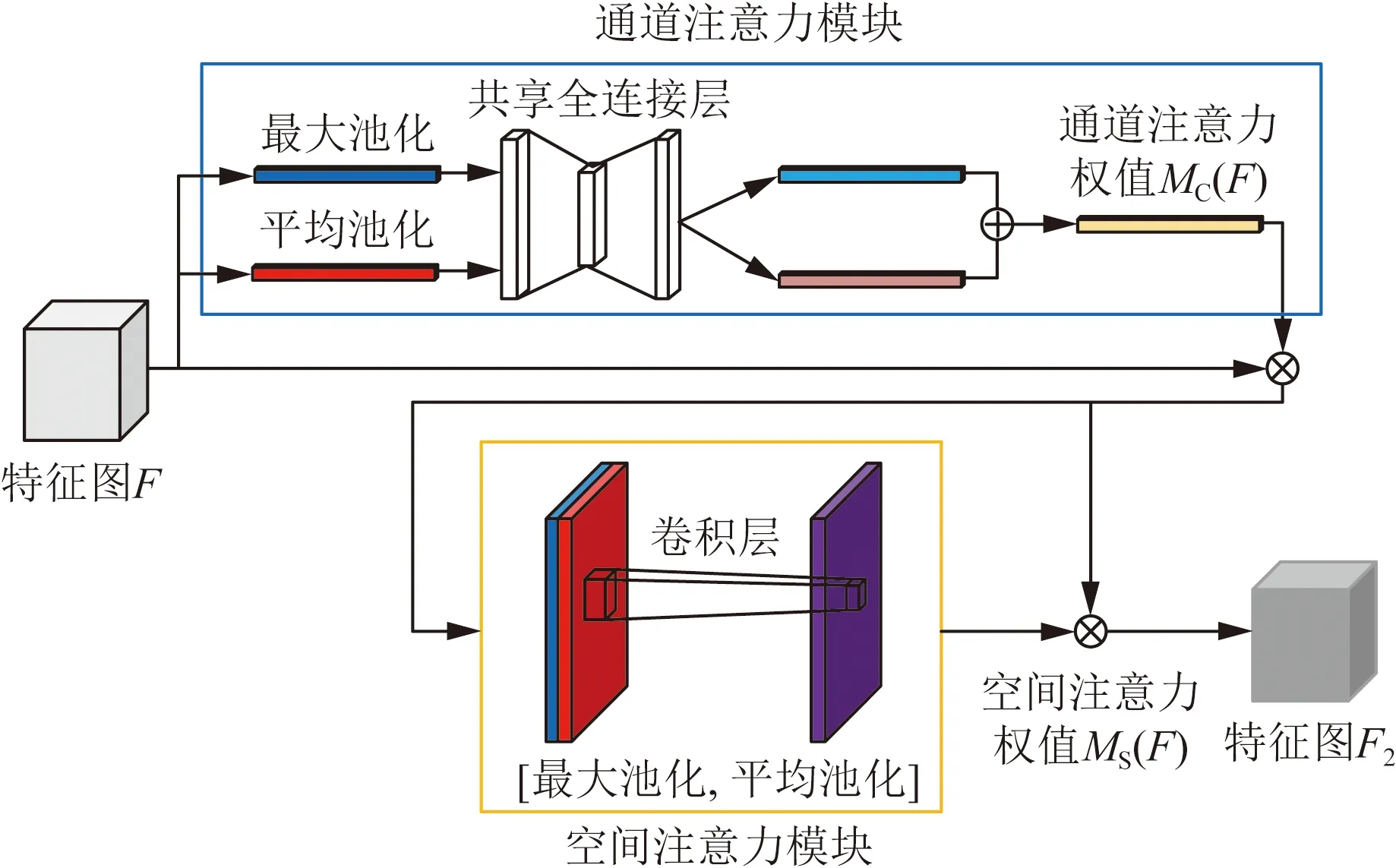
图2 CBAM模块总体结构Fig.2 Overall structure of CBAM module
由图2所示,空间注意力过程为:首先将经过通道注意力生成特征图F1从通道维度上分别进行一次全局平均池化和最大池化,得到两个空间描述子;然后把这两个空间描述子按通道拼接后经过一个7×7的卷积层,再由sigmoid激活函数得到权重系数MS;最后将F1和MS相乘得到新特征图F2,可表示为
F2=MS(F1)⊗F1
(5)
式(5)中:MS(F)为F1通过空间注意力后生成的权重;F2为F1通过空间注意力加权后的新特征图;⊗表示对应元素相乘。
1.4 Inceptionv2结构
Inceptionv2[16]模型的核心思想是先运用多种不同尺度的卷积核在特征图上进行卷积,然后再把得到的结果按照通道进行拼接融合。在使用多种不同尺度的卷积之前,运用了1×1的卷积减少特征图的通道数,从而减少参数量。多种不同尺度的卷积可以使得到的特征信息越来越丰富。Inceptionv2模型还有一个最大的特点:将一个特定的卷积可以使用多个宽和高不一的卷积替代,这样使得网络结构更加复杂,计算量变得更少,Inceptionv2网络结构如图3所示。
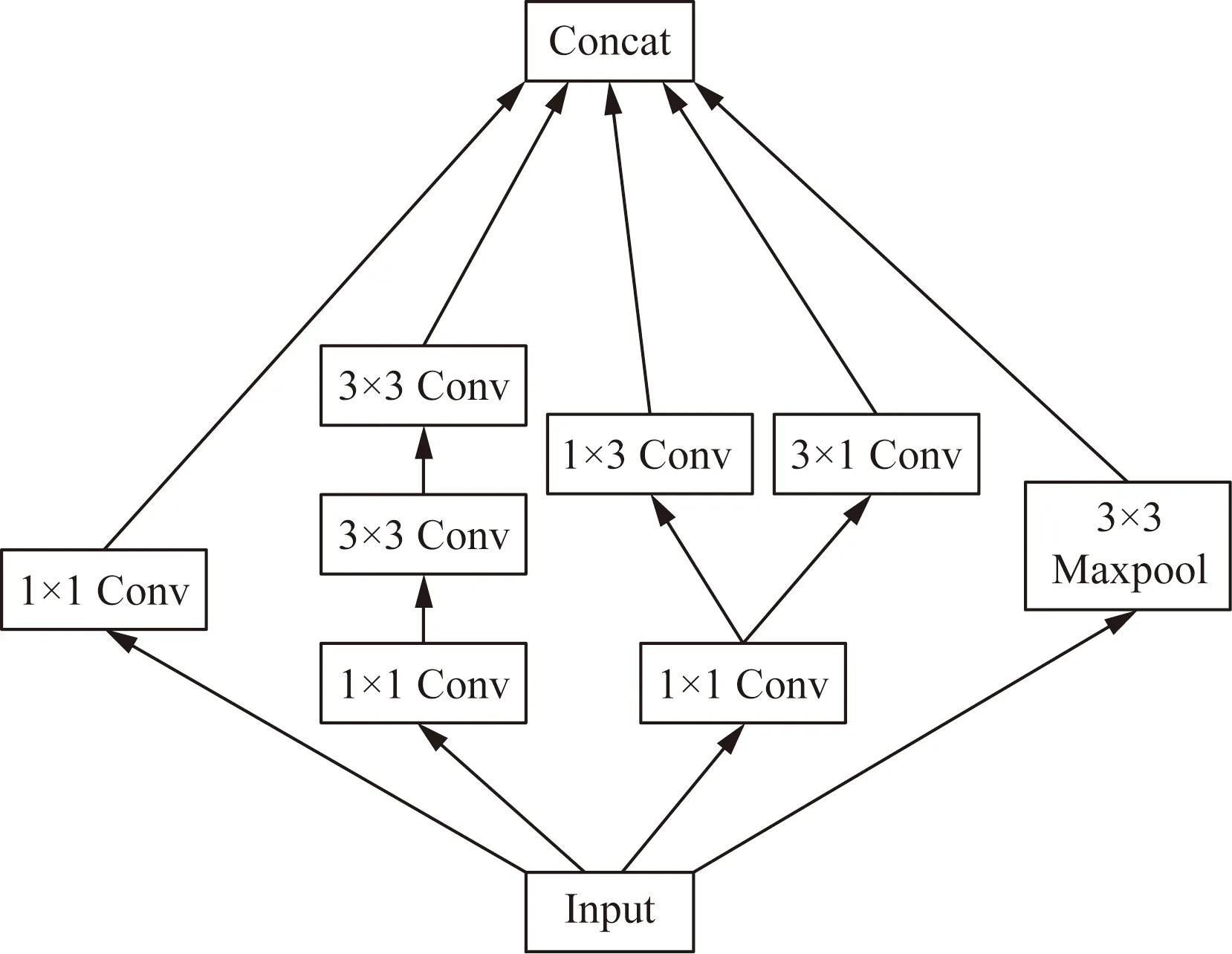
Maxpool为最大池化;Concat为按通道拼接图3 Inceptionv2网络结构Fig.3 Inceptionv2 network structure
2 改进YOLOv4的行人检测算法
2.1 改进主干网络
由于YOLOv4算法采用CSPDarknet53作为主干网络,虽然能提取有效的特征信息,但是网络结构相当复杂,造成参数量过大,在实用性上很不理想。所以本文将Mobilenetv2作为YOLOv4算法中的主干网络,可以在保证其精度的同时减少参数量,形成YOLOv4-Mobilenetv2算法。YOLOv4-Mobilenetv2算法通过Mobileetv2提取到3个有效特征层,分别为52×52、26×26、13×13。由于在提取特征的过程中,13×13的特征图中的细节信息逐渐丢失,因此在52×52的特征上使用卷积核大小为3×3,步长为4的卷积进行下采样后与13×13的特征图进行融合,形成Bottom-up连接。
2.2 加入CBAM注意力
YOLOv4算法的特征融合网络位于主干网络之后,将主干网络提取得到的3个有效的特征层进行进一步的卷积融合,得到更具有代表性的特征。在此过程中,由于特征在特征图通道和空间两个维度上表现力是一样的,造成了提取到的特征冗余,使模型的识别效果变差。所以在YOLOv4的特征融合网络拼接后的5次卷积中加入CBAM注意力机制,构建CBC模块。这样能使网络在训练过程中关注更加重要的特征,忽略冗余的特征,提升检测精度,CBC模块如图4所示。
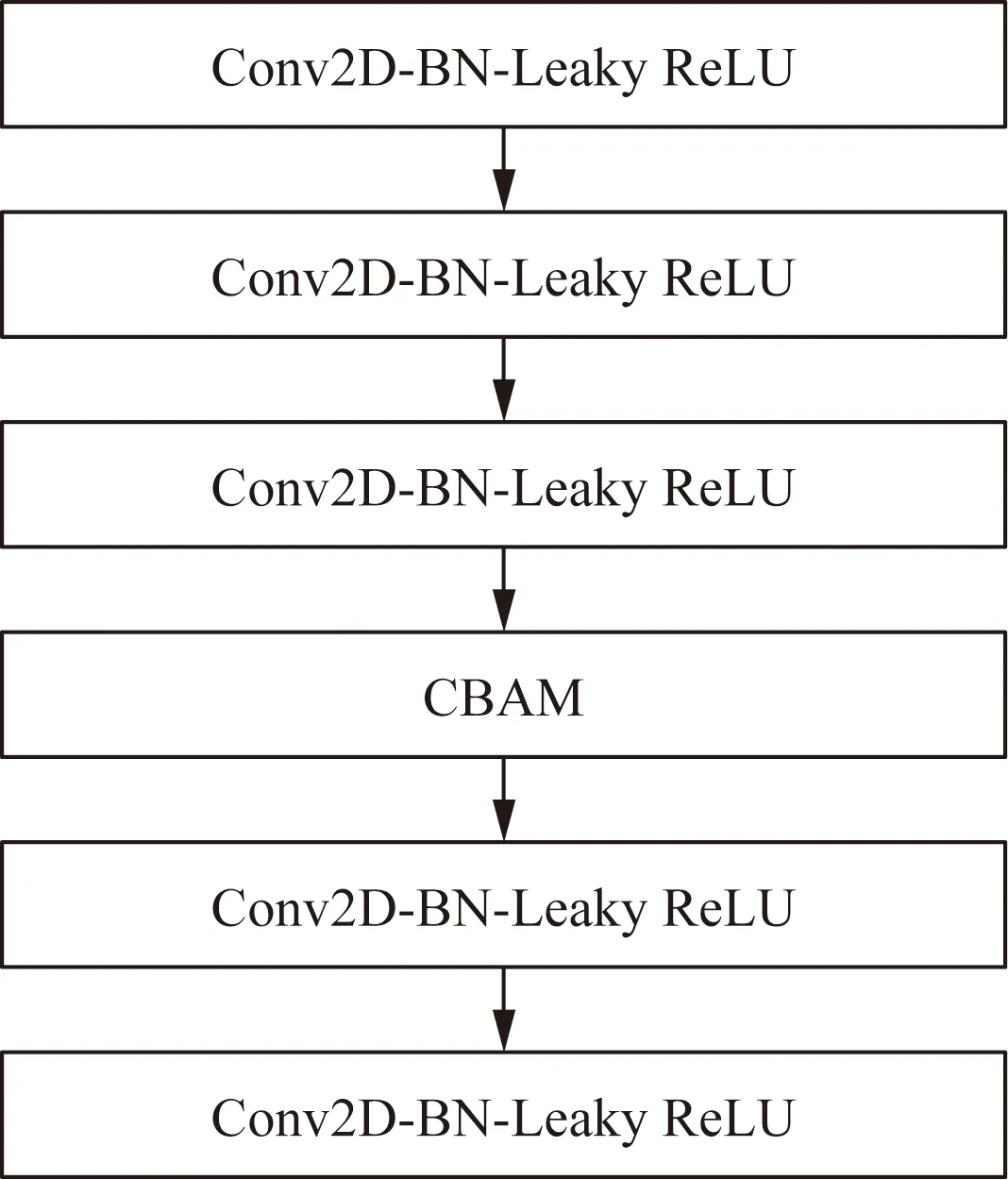
Conv2D为普通卷积;BN为归一化处理;Leaky ReLU为激活函数;Conv2D-BN-Leaky ReLU表示先进行普通卷积,再经过归一化处理,最后通过激活函数输出;CBAM为注意力机制模块图4 CBC模块Fig.4 CBC module
2.3 加入Inceptionv2结构
由于YOLOv4算法的检测网络只使用3×3的卷积核对特征图进行特征整合,这使整合的特征信息较弱,且整合过程需要的参数量较大,若将1×3和3×1的一维卷积替换3×3卷积,可增加模型的非线性表达,同时也可减少参数量。借鉴Inceptionv2模型结构,将YOLOv4算法最后一层中的3×3卷积改为Inception3×3结构,构建成ICP模块:首先使用3个并行1×1的卷积减少通道数,然后将原来的3×3卷积换为1×3的卷积和3×1的卷积,再将其加在其中一个1×1卷积后,最后进行融合,这样在减少参数量的同时加深网络的深度,提高网络的性能,Inception3×3结构如图5所示。由改进点可得改进算法的总网络结构(图6)。
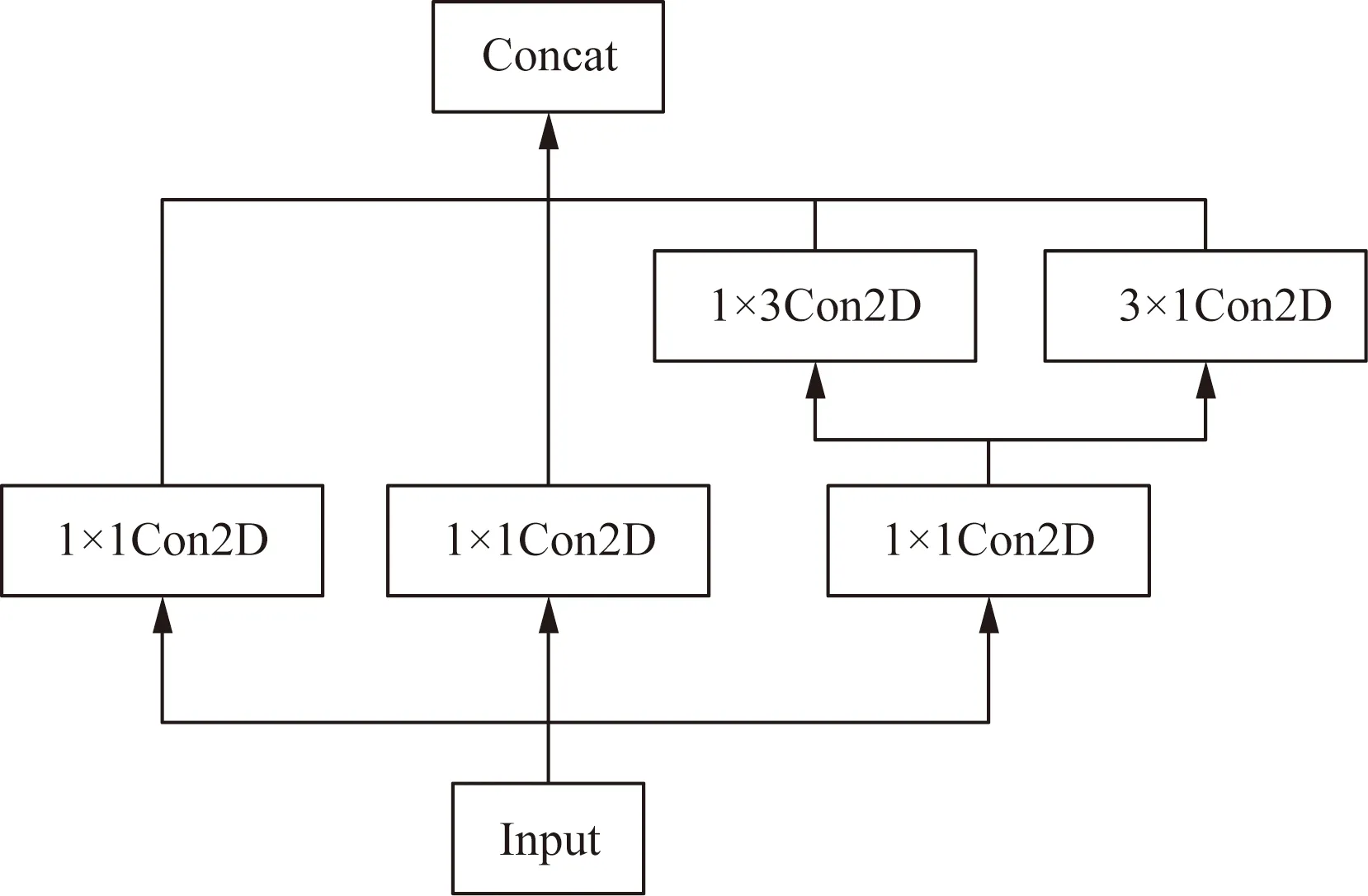
Con2D为二维普通卷积图5 Inception3×3结构Fig.5 Inception3×3 structure
3 实验及结果分析
3.1 实验平台
实验在Win10操作系统上完成的。在CPU为i5 9300;内存为16 G、GPU为GTX 1660T的训练环境下进行训练,再将训练好模型在CPU为i7 10750;内存为12 G;GPU为RTX 2060的环境下进行测试。实验使用的框架为Pytorch,同时采用了很多第三方库保证代码的正常运行。
3.2 实验数据集
本实验所选择的数据集为PASCAL VOC数据集,使用VOC2007 trainvalid与VOC2012 trainvalid数据集进行训练,在VOC2007 test数据集上进行测试。主要研究行人检测,因此将总训练数据经过数据清洗,只保留Person类,得到训练数据6 182张,测试数据共2 097张。
3.3 目标框聚类
本实验利用K-means算法对训练数据集进行聚类分析,得到适应于数据集的候选框尺寸,其避免了手动选取的候选框过于主观,不具客观性和代表性。本实验选取k=9时产生的Anchor box(k为Anchor的个数),在保证预测结果的精度同时防止选取过多的Anchor box带来巨大的计算量,选取的Anchor box尺寸如表2所示。
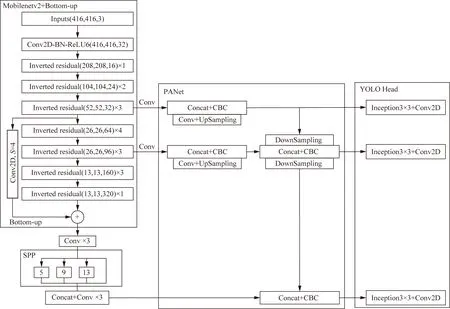
Conv2D-BN-ReLU6表示先进行二维普通卷积,再经过归一化处理,最后由ReLU6激活函数激活输出;Inverted residual为倒残差结构;Conv2D为二维普通卷积;S为步长;CBC为加入CBAM注意力机制的模块;UpSampling为上采样;DownSampling为下采样;Inception3×3表示加入Inceptionv2的模块;Mobilenetv2为轻量级主干网络;Bottom-up为加权连接;SPP为空间金字塔层;PANet为特征融合网络;YOLO Head为检测头图6 改进算法的网络结构Fig.6 The network structure of the improved algorithm
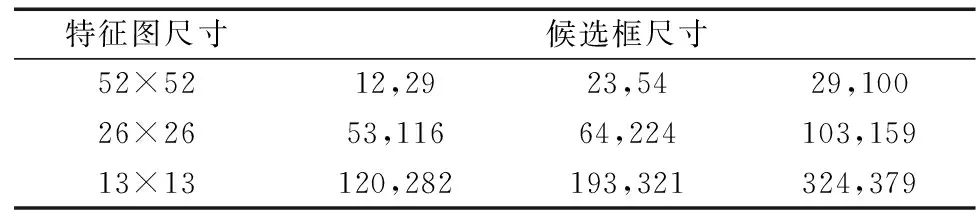
表2 聚类生成的候选框尺寸Table 2 Candidate frame size generated by clustering
3.4 网络训练
训练模型时,将图片设置为416×416,最初始的学习率设置为0.001,经过30个epoch训练后,再将学习率缩小10倍。优化器为Adam,Batchsize设置为16,采用学习率余弦退火衰减、Mosaic数据增强和标签平滑技巧辅助训练,训练过程中损失变化如图7所示。可以看出,前400个epoch,总的损失和验证损失下降得比较明显,从400个epoch开始,loss曲线慢慢趋于稳定,到825个epoch模型已经完全收敛了。
3.5 性能对比
采用目标检测中常用的评价指标,利用准确率平均精确率AP、模型大小Model Size以及每秒检测帧数FPS性能指标对目标检测模型进行评估,并将本文算法与YOLOv3、YOLOv4-Tiny、YOLOv4进行对比。
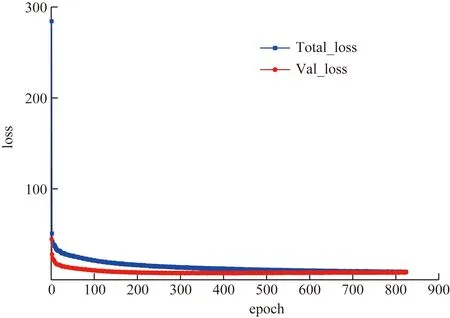
Total_loss为总的损失;Val_loss为验证损失图7 本算法训练情况Fig.7 Training situation of this algorithm
3.5.1 AP对比
实验利用准确率P、召回率R计算出平均精确率AP对目标检测模型进行评估。精确度计算公式为
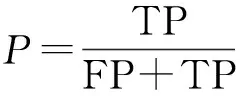
(6)
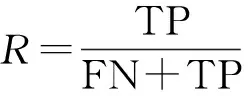
(7)

(8)
式中:TP为检测正确的目标数;FP为检测错误的目标数;FN为漏检的目标数;P为准确率;R为召回率。
为了验证算法的有效性,实验在VOC测试集上进行测试,并参考式(6)~式(8)可得到本文算法和其他对比算法的AP值,结果如表3所示。
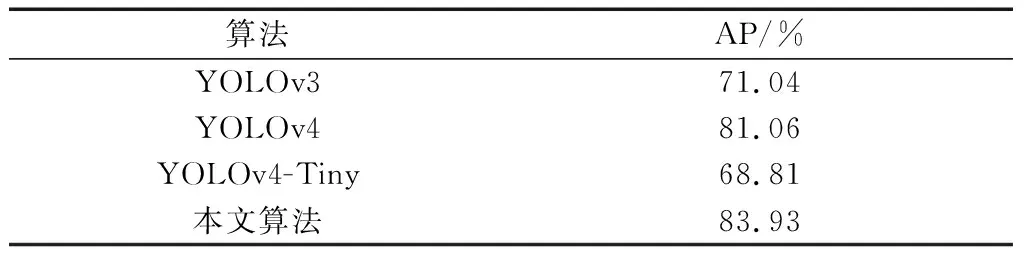
表3 网络模型在VOC测试集上AP值Table 3 AP value of the network model on the VOC test set
可以看出,YOLOv3算法精度为71.04%,比本文算法低12.98%;YOLOv4算法的精度为81.06%;YOLOv4-Tiny算法是YOLOv4算法的简化版,使用CSPDarknet53-Tiny作为主干网络,采用两个尺度的特征层进行分类与回归,精度仅获得68.81%,比YOLOv4算法降低了12.25%;本文算法由于使用CBAM注意力机制和Bottom-up连接,同时还采用Inceptionv2优化结构,AP为83.93%,较与YOLOv4算法提高了2.87%,具有更好的检测精度。
3.5.2 模型大小和FPS对比
实验采用权重大小和FPS对4种目标检测模型进行评估,其中模型权重越小,所需的参数量就越小;FPS是描述模型检测速率的指标,表示每秒钟处理的图片帧数。评估的结果如表4所示。
可以看出,YOLOv3、YOLOv4算法采用了Darknet-53、CSPDarknet-53结构导致了模型参数量较大,模型大小都达到了200 MB以上,占用系统较大的内存;YOLOv4-Tiny算法减轻了YOLOv4算法的网络结构,模型大小比YOLOv4缩小91%;本文算法采用Mobilenetv2的网络结构作为网络结构,并采用Inceptionv2减少参数总量,使模型大小较与YOLOv4缩小81%。就处理图片速度而言,YOLOv3算法最差为每秒18.38帧,YOLOv4算法每秒钟处理29.15帧,本文算法处理速度为每秒58.67帧,虽然不如YOLOv4-Tiny算法的每秒70.91帧,但是与相比YOLOv4算法每秒提升了29.52帧,有更好的实时性,更易于移植到移动端平台上。

表4 网络模型大小和FPS对比Table 4 Comparison of network model size and FPS
3.5.3 算法改进前后检测结果对比
将训练好的YOLOv4和本文模型权重在VOC测试集上进行检测,可得到部分检测结果如图8所示。可以看出,YOLOv4算法出现漏检,而改进算法检测出YOLOv4算法没有检测到的目标,具有更好的检测性能。
综合以上对比实验,本文算法在平均精确率AP、模型大小和处理速度FPS上均有不错的效果,改进的算法比原算法检测效果更佳,实时性更好。

图8 改进模型在VOC测试集上的检测结果对比Fig.8 Comparison of the detection results of the improved model on the VOC test set
3.6 实际场景中的应用
为了验证本文算法的泛化能力,从新疆大学校园篮球场、足球场、2号教学楼采集500张行人图片,使用Labelimg对图片进行标注,转化为检测所需的VOC格式,形成真实场景下的测试数据集。调用VOC训练集上训练好的权重对真实场景下构建的测试数据进行测试,可得到不同算法的AP对比,如表5所示。
从表5可知,改进的算法比原始算法在真实场景下表现得更好,其精度提升了2.13%,且与其他对比算法有更好的检测性能。改进算法和YOLOv4在真实场景下的检测结果如图9所示。
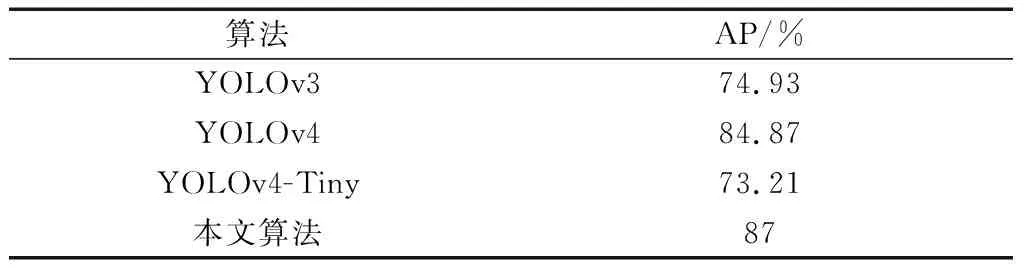
表5 网络模型在真实场景下构建的测试集上AP值Table 5 AP values on the test set constructed by the network model in real scenarios
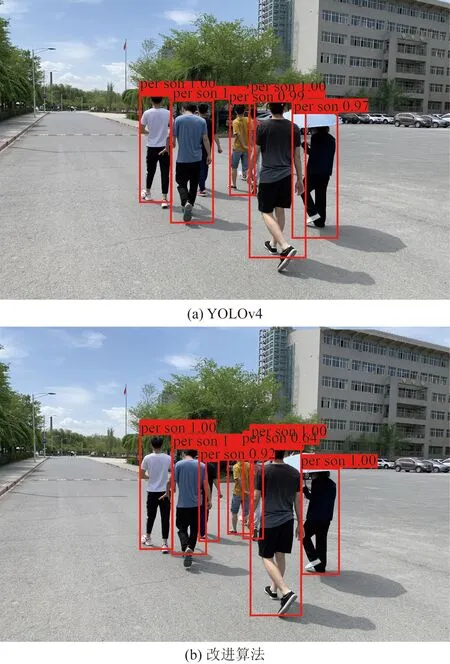
图9 改进模型在真实场景下的检测结果对比Fig.9 Comparison of the detection results of the improved model in the real scene
4 结论
(1)本文算法将CSPDarknet53替换为Mobilenetv2替换,在保证其特征提取能力同时提高了检测速度,同时在Mobilenetv2中加入Bottom-up连接,加强了多尺度特征图的信息融合;将CBAM模块加入特征融合网络,增加特征的表现力;在检测网络最后一层加入Inceptionv2结构,进一步减少计算量和增加网络复杂度。本文算法比原始算法拥有更好的实时性和检测精度。
(2)在进一步的研究中,将在丰富数据集的多样性的同时优化所提行人检测模型,使其更好地完成行人检测任务,更高效地应用在行人计数、行人跟踪中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
