
基于关联规则算法的换流站SER事件集挖掘方法
2022-03-30 08:14黄剑湘林铮骆钊禹晋云杨涛徐峰
科学技术与工程 2022年8期
黄剑湘, 林铮, 骆钊*, 禹晋云, 杨涛, 徐峰
(1. 中国南方电网有限责任公司超高压输电公司昆明局, 昆明 650217; 2.昆明理工大学电力工程学院, 昆明 650500)
随着泛在电力物联网建设的不断发展以及物理信息系统在电力系统中的深度融合,电力数据的数量呈爆炸增长的趋势[1],电力电气行业的大数据时代已经到来[2]。换流站的复杂程度与设备智能化程度逐渐升高,因此对换流站的智能化运维水平提出了更高的要求。当前换流站的运维数据主要依靠事件顺序记录(sequence events recorder, SER)系统记录庞大的一、二次设备运维日志[3]。当直流系统进行顺控操作或出现故障时,换流站SER系统生成海量异构、多态的数据[4],这些数据中蕴含着大量有价值的信息,包含了很多典型的事件集及强关联性的特征事件,对其进行数据挖掘与数据分析对提升换流站的运维管控水平有重要的意义。但中外对于换流站SER的故障数据挖掘的技术较少,缺乏对换流站故障数据日志间的关联分析。
利用数据挖掘技术分析复杂数据,近年来在电网的数据分析中得到了广泛的应用[5],且利用数据挖掘算法对电力系统的运行数据进行分析[6-8]已经逐步成为主流的方法。文献[9]引入了数据挖掘与关联分析的思想,提出了寻找二次设备的薄弱环节的混合聚类分析的网损评估方法并为分析处理电网故障提供决策支持。文献[10]提出了薄弱度的概念来量化分析电气设备的薄弱性,通过关联规则数据挖掘分析出配电网的薄弱点。但对于换流站的数据挖掘与分析文献相对较少,尤其是在换流站SER建模方面与面对海量SER事件的挖掘还处在探索阶段。
为此,提出一种基于关联规则算法的换流站SER事件集挖掘方法,同时定义SER典型事件支持组与SER典型事件置信事件的概念,通过对常见换流站典型事件历史SER事件进行关联分析,得到了典型事件支持组与典型事件置信事件,以此分析未来典型事件中的SER事件缺失情况,并及时告知换流站运维人员,避免了人工检查异常SER事件的中漏看错看,方便换流站运维人员及时发现换流站的设备异常动作。
1 数据挖掘的关联规则算法
1.1 关联规则
关联规则(association rules, AR)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于在大型数据库中挖掘出有价值的数据项之间的相关关系[11]。关联规则的强度取决于支持度和置信度。
(1) 支持度(Support):全部事件中,事件{X,Y}出现可能性,即总项目集中子项目集{X,Y}的比重,可表示为
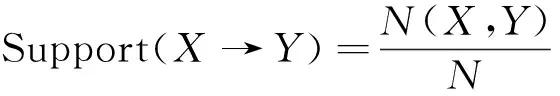
(1)
式(1)中:Support(X→Y)为子项目集X对子项目集Y的支持度;N(X,Y)为事件{X,Y}出现的次数;N为项目集的总数。
(2) 置信度(Confidence):在关联规则中,事件X发生的条件下,另一事件Y发生的概率,即一个项目集中同时含有X和Y的概率,可表示为
(2)
式(2)中:Confidence(X→Y)为子项目集X对子项目集Y的置信度;N(X)为事件X出现的次数。
支持度作为关联规则强度的度量之一,衡量子项目集在总项目集出现的频率。通过设置最小支持度阈值minsup,筛选出现频率较多的有意义规则,剔除出现频率较小的无意义规则。支持度大于最小支持度阈值的项集被称为频繁项集。
置信度作为关联规则强度的又一个度量,衡量频繁项集中两个事务同时出现的概率。通过设置最小置信度阈值mincon,筛选出频繁项集中两个事务同时发生的概率。置信度大于最小置信度频繁项集中的强规则。
常见的关联规则包括布尔关联规则和数值型规则,而换流站SER的数据属于布尔型数据[12]。分析SER事件集时采用布尔关联规则,并且通过调整最小支持度阈值得到合适的频繁项集作为SER故障可信组。
Apriori算法和FP-Growth算法是最常见的关联规则算法[13]。由于Apriori算法需要扫描数据库多次且操作过程中产生大量的候选集,导致时间、空间成本过高,而FP-Growth算法仅需要对数据集扫描两次,且不生产候选集,有效降低了FP-Growth算法的写入与读取次数。Apriori算法和FP-Growth算法的比较如表1所示。
综合考虑Apriori算法和FP-Growth算法的优缺点,考虑采用FP-Growth算法实现换流站发生故障时SER事件告警关联规则的挖掘。

表1 Apriori和FP-Growth的比较Table 1 Comparison of Apriori and FP-Growth
1.2 FP-Growth算法
FP-Growth算法挖掘频繁项集主要是包括两个步骤,具体如下。
步骤1建立频繁模式树(frequent pattern-tree, FP-Tree):第一次扫描目标数据集,筛选频繁项为1的项目集,并定义项目出现最少次数即最小支持度,定向删减项目支持度小于最小支持度的项目,并将目标数据集中的条目按项目支持度降序进行排列,在此基础上二次扫描目标数据集,并创建自顶向下的项头表和FP-Tree。
步骤2从FP-Tree中挖掘频繁项集:将项目按照从顶向下的顺序查找其条件模式基(conditional patten base, CPB),递归调用树结构以删除小于最小支持度的项,直至呈现单一路径的树结构。
2 换流站SER事件集关联规则挖掘
2.1 换流站SER事件特征筛选与换流站SER建模
换流站SER系统每日会产出近十万条SER事件,需从中筛选出发生故障时且有价值的特征项以方便关联规则挖掘。SER系统记录的部分SER事件如图1所示,原始SER事件记录的数据特征项如表2所示。
在原始SER事件的数据中,时间方便收集故障发生后产生的SER数据;主机方便定位故障发生位置;系统为SER系统本身相关的;等级为SER事件对当前运行下的工况,分为“正常”“轻微”“报警”“紧急”4个等级;报警组为定位产生该条事件的控制设备组或控制软件;事件为SER系统对当前运行下进行的动作带有嵌入值的事件内容描述。
通过换流站SER事件特征筛选,可以降低SER事件模型维度,故需从原始SER事件特征选取有效特征,从原始SER数据中利用时间和等级作为索引,主机、报警组和事件作为特征来进行建模。其次,在时间的处理中,直流输电系统状态转换操作及保护出口后相关设备动作将在0~120 s内完成,故设置关联事件最大时间差为120 s,即考虑换流站保护动作后120 s内SER事件组。换流站SER事件模型M|system可表示为
M|system=[I(I1,I2,I3),P(P1,P2)]
(3)
式(3)中:下标system为采用的冗余系统;I为索引维度特征的集合;I1为时间维度;I2为位置维度;I3为等级维度;P为时间特征的集合:P1为报警组;P2为事件。
2.2 换流站SER典型事件支持组挖掘
通过分类换流站中的典型事件,分析换流站出现典型事件时SER事件的关联规则,得出不同典型事件时出现的SER事件集合。利用SER数据清洗与建模,并对典型事件的分类结果进行FP-Growth关联分析,取支持度最大的频繁项集作为换流站SER典型事件支持组,其表征在相似的典型事件下,该类SER事件组发生概率极大,视其为必然发生,其挖掘流程如图2所示。
2.3 换流站SER典型事件置信事件挖掘
在得出换流站SER典型事件支持组后,利用挖掘结果中的置信值,将非SER典型事件支持组但相对于SER典型事件支持组置信度大于0.6的SER事件作为换流站SER典型事件置信事件,其表征在针对相似但不同的典型事件下,该SER事件发生概率大于60%,即在大多数相似典型事件下会出现,但需要运维人员根据实际情况进行辅助判断,其挖掘流程如图3所示。
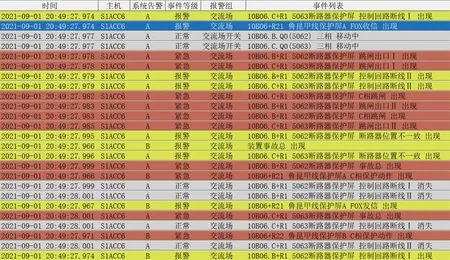
图1 SER系统记录部分SER事件Fig.1 SER system records some SER events

表2 原始SER事件特征Table 2 Characteristics in primary SER log
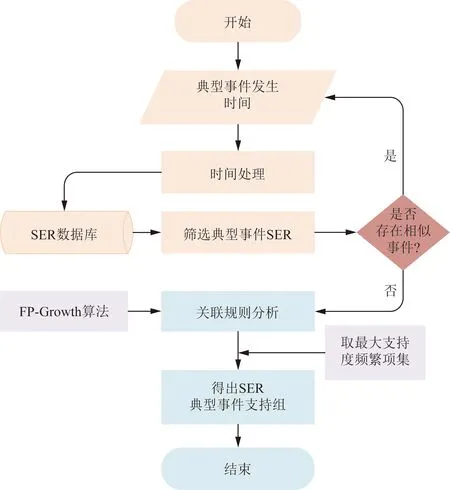
图2 SER典型事件支持组流程图Fig.2 Flow chart of SER class event support group
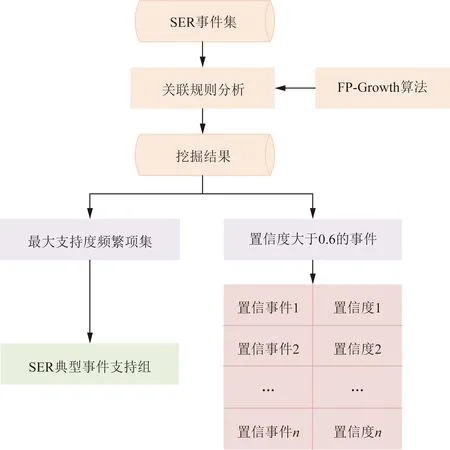
图3 换流站SER典型事件置信事件挖掘流程图Fig.3 Flow chart of confidence events mining for typical SER class events in converter station
2.4 基于典型事件支持组与置信事件的SER事件集分析
SER数据接入后,在换流站开展同类顺控操作或发生相似故障时,利用历史数据挖掘的SER故障支持组与置信事件,判断是否满足换流站SER支持组与置信事件,若满足SER故障支持组则继续判断置信事件,若不满足SER故障支持组则直接向控制中心报告异常情况;在满足SER故障支持组的条件下,将未出现的故障置信事件及其置信值发至控制中心,辅助运维人员进行下一步处理,具体流程如图4所示。
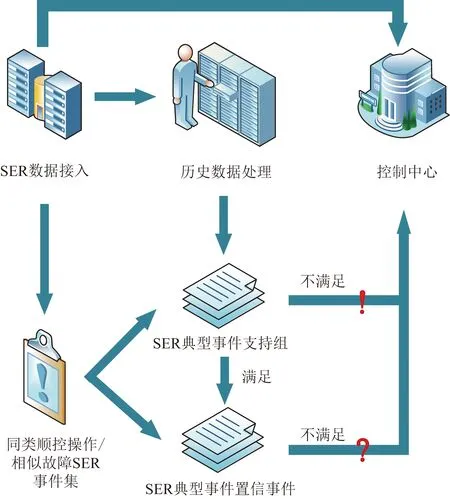
图4 SER事件集分析方法Fig.4 Method of SER event set analysis
3 算例分析
3.1 实验环境与数据来源
采用操作系统为Windows 10、内存为8 GB、CPU为Intel(R) Core(TM) i3-9100F CPU@3.60 GHz、GPU为NVIDIA GeForce GTX 1650的实验环境,使用Python3.8语言开发,实验软件平台为Anacaoda3,编写数据清理、建模程序及FP-Growth算法程序。
数据来源于昆柳龙直流系统2020年5月20日—2020年12月20日调试期间换流站记录的事件/报警信息,由控制保护系统主机及其I/O系统自身产生,经由站LAN网发送到SCADA系统,由SCADA系统处理后保存到实时数据库和历史数据库中。同时为建立典型事件集,分类了常见的昆柳龙换流站典型事件集:直流系统典型顺控操作和典型故障,如表3所示。

表3 昆柳龙换流站典型事件Table 3 Typical events in Kun-Liu-Long converter station
3.2 昆柳龙换流站SER典型事件支持组与置信事件挖掘
考虑到昆柳龙直流换流站调试期间数据量较小,单次事件的事件集数据不完善,故设置FP-Growth的最小支持度为0.5,最小置信度为0.6。以换流器闭锁转解锁为例,SER系统记录了14次换流器闭锁转解锁及相似操作,挖掘得到换流器闭锁转解锁相似事件的所用满足的SER事件集,得到14次换流器闭锁转解锁的FP-Growth数据挖掘结果,如图5所示。
可以看出,事件集1为挖掘结果的最大支持度,故将集合1作为换流器闭锁转解锁典型事件的支持组,其具体事件如表4所示。同时,通过最小置信度得到相对于置信度大于0.6的SER事件,将其作为换流器闭锁转解锁典型事件的置信事件,如表5所示。典型事件极区送端侧故障(极母线接地、中性母线接地)的换流站SER典型事件支持组与置信事件挖掘结果表6所示,其他部分典型事件关联挖掘结果如表7所示。
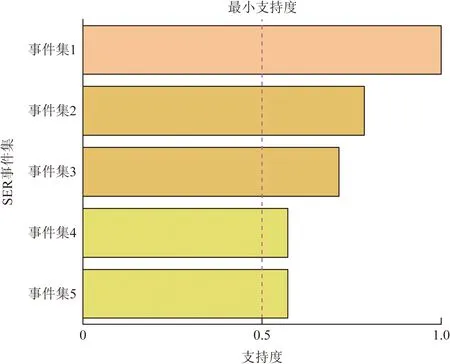
图5 SER事件集支持度Fig.5 SER log event set support

表4 换流器闭锁转解锁支持组Table 4 Support group of inverter lock-to-unlock
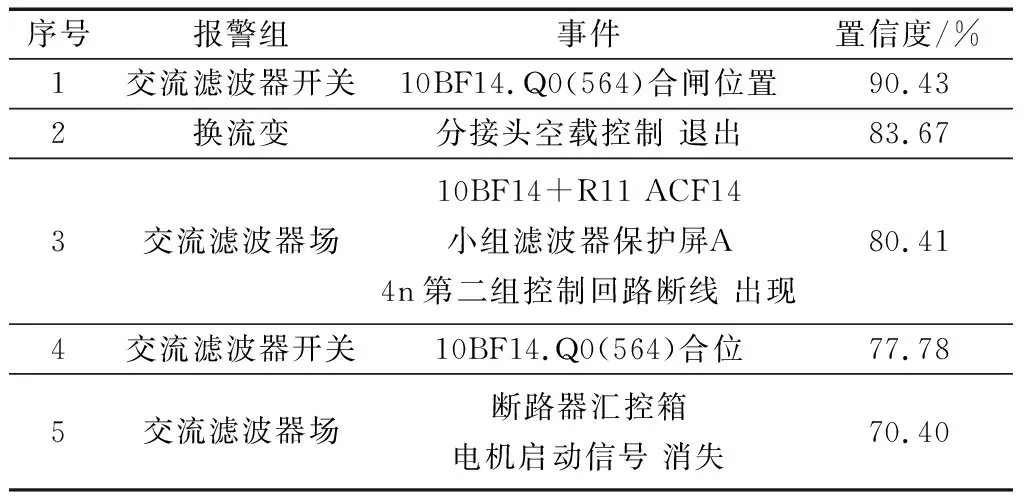
表5 换流器闭锁转解锁典型事件的置信事件Table 5 Confidence events of inverter lock-to-unlock
3.3 SER事件集分析
以某次换流器闭锁转解锁为例,SER系统记录SER事件集,利用上节换流器闭锁转解锁SER典型事件支持组与置信事件挖掘结果,分析SER事件集如表8所示。可见在SER事件集中通过昆柳龙换流站SER典型事件支持组与置信事件挖掘结果分析当前直流系统典型顺控操作和典型故障的SER事件集,为运维人员快速查看SER事件集中典型SER事件的缺失及时提供指导作用。

表6 极区送端侧故障的关联挖掘结果Table 6 Association mining results of faults on the transmission side of the DC pole area
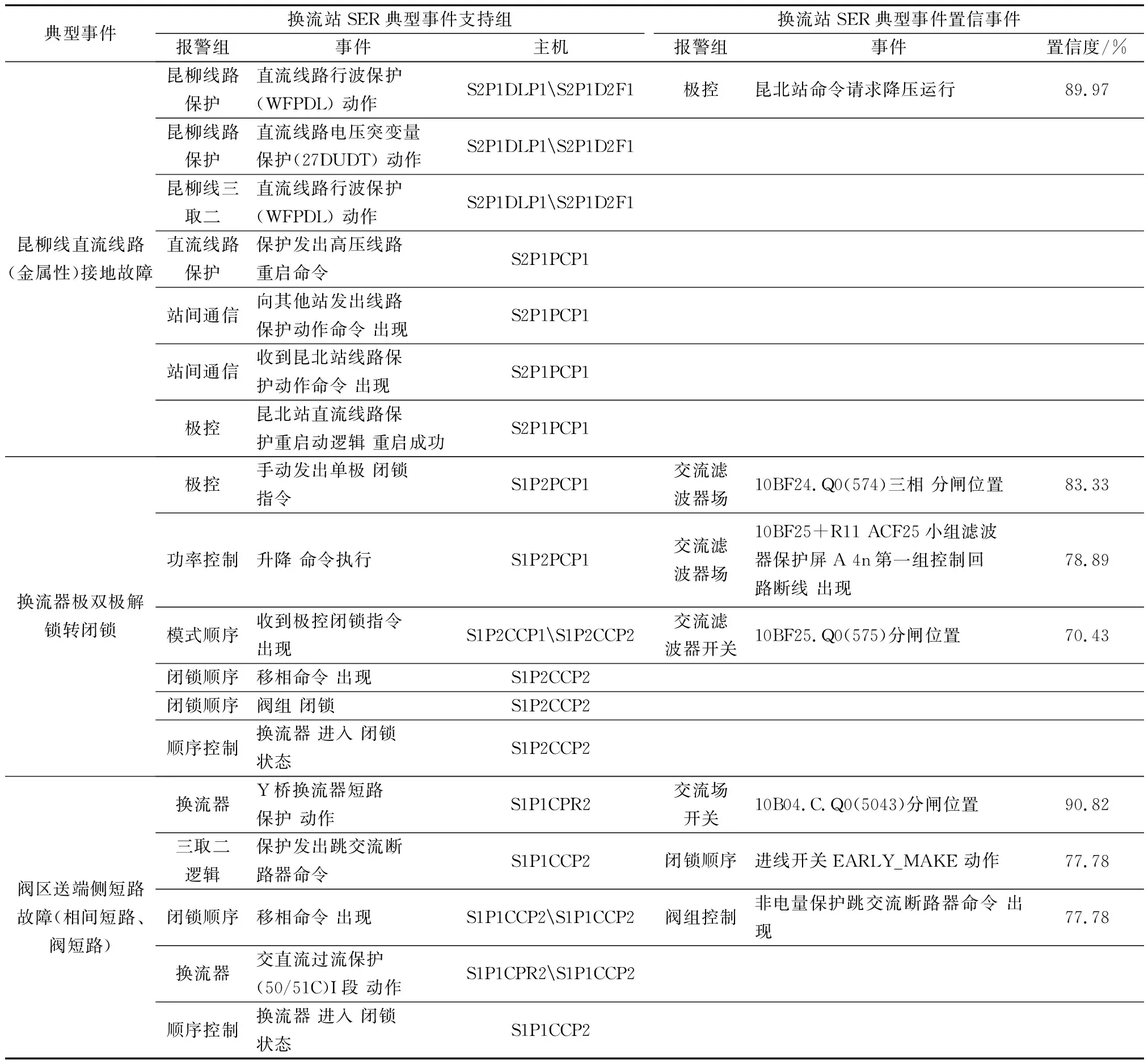
表7 部分典型事件挖掘结果Table 7 Association mining results of some other typical events

表8 换流器闭锁转解锁SER事件集Table 8 Association mining results of faults on the transmission side of the DC pole area

续表8
4 结论
提出一种基于关联规则算法的换流站SER事件集挖掘方法,得出以下结论。
(1) 在分析了换流站SER事件的数据特点基础上,设计了包含时间、地点、等级维度特征和报警组、事件关联数据挖掘特征的SER事件模型。利用了FP-Growth算法进行换流站典型事件产生的SER事件集的数据挖掘与分析。引入了SER典型事件支持组与置信事件概念分析SER事件的异常情况。
(2) 挖掘结果表明,利用FP-Growth算法可以从海量SER事件中高效地提取关键SER事件;有效地挖掘出换流站发生故障时最大SER典型事件支持组和置信事件。
(3) 目前针对换流站SER事件的关联挖掘方法较少,通过文中提出的方法可以有效协助运维人员发现SER事件异常。随着事件的推移,SER系统将积累更多的事件数据,下一步的工作主要考虑自动提取出故障发生的SER事件数据并利用Hadoop大数据平台并行挖掘关联SER事件数据,逐步提高最小支持度与置信度阈值以达到精确挖掘,自动判断SER事件异常问题并直接应用于昆柳龙直流工程,同时可为未来白鹤滩-江苏±800 kV特高压直流输电工程换流站高效运维提供参考。
猜你喜欢
粘接(2022年12期)2023-01-05
电力设备管理(2022年4期)2022-11-25
电工技术学报(2022年20期)2022-10-29
电工技术学报(2022年19期)2022-10-14
哈尔滨工业大学学报(2022年5期)2022-04-19
现代电子技术(2022年1期)2022-01-25
陶瓷学报(2021年2期)2021-07-21
电子制作(2019年22期)2020-01-14
电子制作(2019年11期)2019-07-04
通信电源技术(2018年3期)2018-06-26
