
无蜂窝大规模MIMO中基于深度强化学习的无人机辅助通信与资源调度
2022-03-30 09:15:48王朝炜邓丹昊王卫东
电子与信息学报 2022年3期
王朝炜 邓丹昊 王卫东 江 帆
①(北京邮电大学电子工程学院 北京 100876)
②(泛网无线通信教育部重点实验室 北京 100876)
③(西安邮电大学通信与信息工程学院 西安 710061)
1 引言
随着超5代(Beyond fifth-Generation, B5G)和第6代(the sixth-Generation, 6G)移动通信技术的提出和发展,移动网络不再局限于地面覆盖,而是扩展到面向空天地海大尺度范围提供无处不在的无缝连接。其中,无蜂窝大规模多入多出(Multiple Input Multiple Output, MIMO)技术结合了分布式MIMO和大规模MIMO的概念,将配备大规模天线阵列的宏基站替换为仅有少量天线的大量接入点(Access Points, AP),在大幅降低网络部署成本的同时可以有效提高用户覆盖率[1,2]。然而,受地理环境和距离的影响,偏远地区、山区、海上等区域的大量用户处于无蜂窝大规模MIMO网络的边缘或者覆盖范围之外,很难得到可靠的移动通信服务。因此,无人机、卫星以及高空平台(High Altitude Platform Station, HAPS)等移动空天平台逐渐成为改善和增强无线网络覆盖的重点辅助手段[3,4];其中,无人机辅助通信具有高机动性和灵活部署的特点,可以在地面基础设施部分或者全部失效的场景下,提供更灵活和可靠的网络连接,已经得到工业界和学术界的普遍关注[5,6]。
目前,针对无蜂窝大规模MIMO技术的研究大多聚焦于地面移动通信,包括资源管理技术[7,8]、收发机设计[9]以及与其他新型无线通信技术的结合[10,11]。然而与无人机技术结合的相关研究还比较少,文献[12]提出一种无蜂窝大规模MIMO系统中基于能量采集的无人机无线能量传输(Wireless Power Transfer,WPT)技术。文献[13]将无人机视作移动用户,构建可以同时支持地面固定用户和无人机的无蜂窝大规模MIMO网络。文献[14]引入无人机辅助无蜂窝网络,为蜂窝基础设施薄弱的高速公路上行驶的车辆提供覆盖。在研究无蜂窝大规模MIMO技术的同时,针对无人机辅助通信的研究也面临着诸多挑战,例如,无人机的通信范围有限,并且飞行过程受限于电池续航能力。因此无人机辅助网络的轨迹设计需要同时考虑环境适应性和能源可持续性。文献[15]假设无人机具备充足的能量供应,研究固定场景下的无人机最优位置选择,利用迭代算法求解非凸优化问题,旨在最大化用户的可达速率。文献[16]考虑无人机飞行过程的机械能消耗,假设无人机以周期模式运行,通过联合优化无人机充放电时间、3维轨迹和发射功率,实现飞行周期内的总吞吐量最大化。文献[17]聚焦于多跳无人机中继系统,基于信息转发的因果性约束,对多无人机轨迹进行联合设计,最大限度地提高端到端吞吐量,该方案适用于通信基础设施被破坏的灾区、无线网络没有覆盖的沙漠或海洋等区域。上述优化算法需要根据全局的信道状态信息(Channel State Information,CSI)进行决策,然而,系统在大多数现实情况中(如信道估计误差、通信延迟和回程链路的限制)无法获取完美的全局CSI[18]。为解决上述问题,各类机器学习算法逐渐被应用到无线资源管理研究中。
近年来,强化学习(Reinforcement Learning,RL)引起了研究人员的广泛关注。尽管RL在诸多领域都获得了应用,但它仅工作于具有完全可观测的低维状态空间[19];为此,RL利用深度神经网络(Deep Neural Network, DNN)的高维特性,合并发展成为深度强化学习(Deep Reinforcement Learning, DRL),并在无线资源管理和无人机辅助通信中得到了广泛应用。文献[20]利用深度Q网络(Deep Q-Network, DQN)选择无人机拓扑中的最优链路;文献[21]研究了基于多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)的多无人机通信网络动态资源分配问题;文献[22,23]采用深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)优化无人机的3维轨迹设计和频带分配。大多数基于DRL的无线资源分配方案假设信道是高斯或块衰落的,文献[24]考虑到无线环境的时变特性,采用了一种更具现实意义的有限状态马尔可夫信道(Finite-State Markov Channel,FSMC),但所提出的算法仍然需要当前的全局CSI来表征状态。
本文针对无蜂窝大规模MIMO传输场景下的偏远地区通信,研究多架无人机组成的辅助通信网络,提出了由第1跳无人机调度和第2跳用户调度组成的两跳协作机制。首先,将第1跳中的AP功率分配和无人机服务区选择建模为双动作马尔可夫决策过程(Double-Action Markov Decision Process,DAMDP),采用基于卷积神经网络(Convolutional Neural Networks, CNN)的DQN算法实现最优策略;然后将第2跳中的用户调度方案建模为0-1优化问题,通过分解为独立的子问题进行求解。
2 系统模型
本文设计的无蜂窝大规模MIMO网络中无人机辅助通信系统如图1所示,该系统包括1个AP、L个无人机和K个移动用户。用户与AP间不存在直连链路,需要借助无人机充当中继来转发信号。同时,考虑无人机飞行过程中的能耗问题,无人机需围绕地面充电站飞行以保证能量供应。因此,无人机轨迹被限定在以各个充电站为中心,以r为半径的服务区内。根据地理位置,将服务区划分为L个区域,第l个区域内存在Ml个服务区、Kl个移动用户,其中第m个服务区和第k个用户分别表征为[m,l], [k,l],每个区域分配1架无人机负责该区用户的通信服务。
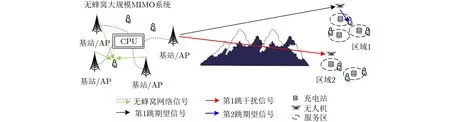
图1 无蜂窝大规模MIMO网络中无人机辅助通信
在无蜂窝大规模MIMO网络中,资源的有效调度需要考虑全局的CSI,而本文所针对的偏远地区反馈信道资源有限,特别是对于包含大量即时用户信息的第2跳反馈。因此,本文提出一种基于AP决策和局部决策的两跳协作框架,前者利用第1跳的CSI动态调度AP发射功率和无人机服务区,并通过反馈方式调整调度方案;后者检测每个无人机的本地第2跳CSI,并制定相应用户调度方案。该框架的优点在于无人机可以自主选择服务用户,并且AP决策不需要反馈第2跳的CSI,从而降低系统的反馈链路负载。
2.1 AP决策
在AP传输信号至无人机的第1跳中,AP决策负责制定其自身功率分配和无人机服务区选择方案,假设功率和服务区的调度周期包含T个单位时隙。无人机l的可达频谱利用率Rl可以表示为
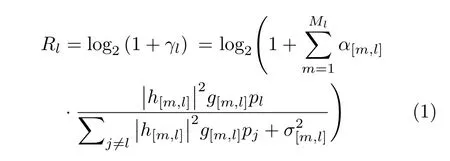

其中,λ为发送信号波长;d[m,l]表示服务区[m,l]到AP的距离,假设无人机服务区比整个通信区域小得多,可以认为服务区内的信道增益是等同的,且服务区到AP的距离被定义为服务区的中心点与AP之间的距离。
AP决策过程需满足以下约束
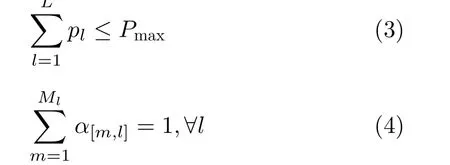
其中,约束式(3)保证AP的总分配功率小于最大功率;而约束式(4)表示在每个区域内,无人机1次只能选择1个服务区。
需要指出的是,资源调度的目标是最大限度地提高用户的总频谱利用率Rsum而非无人机的。因此,AP决策过程同时依赖第1跳的CSI和第2跳反馈的Rsum来调整功率分配和服务区选择方案

2.2 局部决策
在无人机转发信号至用户的第2跳,局部决策确定每个无人机的用户调度方案。假设每架无人机在选定的服务区内遵循固定的螺旋轨迹[25],由于无人机的发射功率有限并且各区域间相隔较远,本文忽略区域间干扰。用户[k,l]在时隙n的接收信号干扰噪声比(Signal to Interference plus Noise Ratio,SINR)为

3 基于DQN的AP决策方案
3.1 RL概述
RL可用于解决马尔可夫决策过程(Markov Decision Process, MDP)问题,该问题由3部分组成:环境出现的状态s,智能体执行的动作a和指导策略π;系统的下一状态s(t+1)仅取决于当前状态s(t)和动作a(t);在转入新的状态s(t+1)后,系统会得到即时的奖励值r(t) =r(s(t),a(t))。RL的目的是寻找最佳状态-动作策略,该策略可以根据当前状态做出最优动作决策。为了得到最佳的长期回报,RL利用值函数V π(s)表示状态s在策略π下的未来潜在价值

3.2 DAMDP模型
在传统的RL算法中,MDP依赖单一的状态和动作,而AP决策过程包含功率和服务区双动作,因此将MDP模型扩展为DAMDP。基于2.1节的系统模型,DAMDP的状态、动作和奖励定义如下:
状态:总状态s(t)由两个子状态sp(t)和sd(t)共同决定,并由当前的RSRP集合{RSRP(t)}表示。具体的状态表征与DQN算法输入层网络的选择有关,因此详细的函数表示将在3.3节给出。
动作:当前动作集合包括AP向每架无人机的发射功率ap(t)=[p1(t),...,pl(t),...,pL(t)],以及服务区的选择ad(t)=[d1(t),...,dl(t),...,dL(t)]。应该注意的是,由于发射功率的随机组合,部分动作集合违反了约束式(4),需要被赋予负值奖励来规避。
奖励:智能体根据奖励来辨别不同动作的优劣。奖励函数定义为
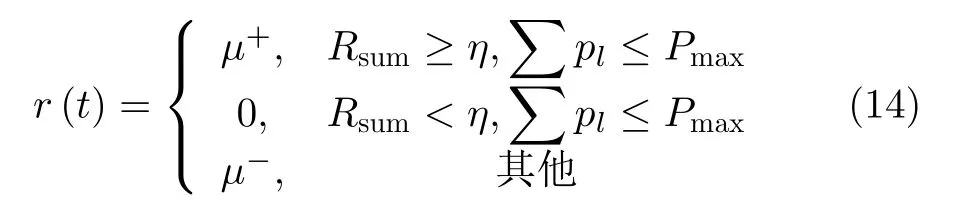

3.3 基于CNN的Q学习算法



神经网络属于监督学习模型,训练样本必须是独立同分布的,为此,DQN利用经验回放机制来打破序列样本之间的相关性。具体来说,DQN从

4 局部决策方案
用户调度在不同时间段上和不同区域上是不相关的,因此,局部决策问题可以被分解为T×L个独立的子问题。例如,第n. l个子问题可以表示为
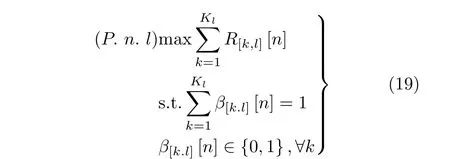
所有T×L个 子问题都属于0-1规划问题[29],本文采用假设法进行求解,最优的用户调为
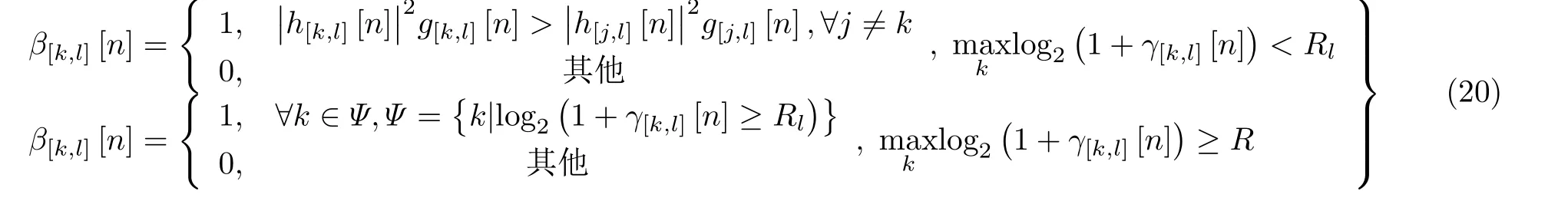

表1 DQN算法框架
5 仿真结果与分析
5.1 系统环境和仿真参数设置

5.2 收敛性与复杂度
图2为本文所提基于DQN的资源调度方案与基于Q-learning的资源调度方案在收敛性能方面的对比,其中,DQN方案用损失函数和总频谱利用率的变化情况来说明其收敛性能。仿真结果显示,随着训练的进行,所提方案的损失函数曲线逐渐收敛到较小的损失值,且总频谱利用率也稳定收敛到最佳性能。而Q-learning方案在60000步训练过程中仅获得了0.08 bps/Hz的性能增益,当训练步数增加到120000步时,Q-learning方案的性能增益也仅仅扩大为0.14 bps/Hz,并且随着训练的进行,该方案的性能增益还将持续上升。因此,相比于Q-learning方案,本文所提基于DQN的方案具有更好的收敛性能。
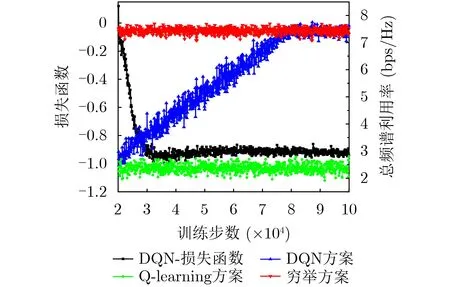
图2 不同算法的收敛性
图3展示在不同的服务区数量下,不同算法的复杂度对比。仿真结果显示,所提方案相比于Q-learning方案具有显著降低的复杂度,且复杂度不随训练步数的增加而增长。对于Q-learning方案,Q-table会随着训练步数的增加而扩展,导致Q-learning算法更难找到与当前状态相匹配的Q-table元素,对应的复杂度也增加。而所提DQN方案在不同的训练步数下,面对的是相同的神经网络结构,时间消耗相对稳定。同时,服务区数量的增加使得系统的状态-动作对呈指数增长,两种方案的复杂度都会相应提升。但由于所提方案受状态空间维度而非状态总数的影响,复杂度的增幅明显慢于Q-learning方案。
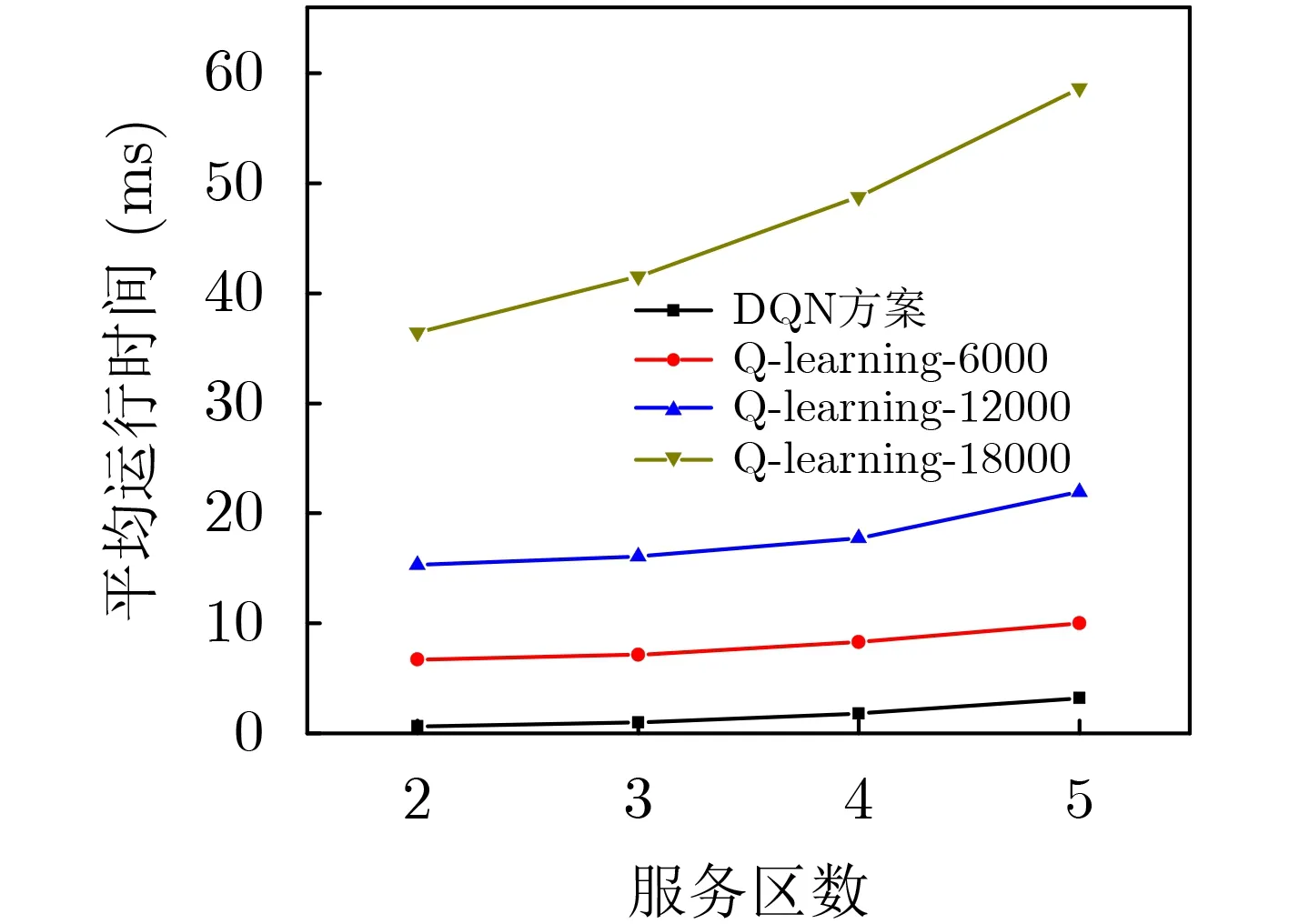
图3 不同算法的复杂度
5.3 学习率与网络框架
图4展示了不同学习率对所提方案性能的影响,错误率表示所提方案与穷举法的频谱利用率差值大于某阈值的概率。具体来说,错误率05、错误率1.0和错误率3.0分别表示频谱利用率差异大于0.05,0.1和0.3 bps/Hz的概率。可以看出,过高或者过低的学习率都会导致高错误率。当学习率过高时,损失函数会在最小值附近波动,甚至无法收敛;当学习率过低时,算法收敛速度慢,在相同的训练步数下,可能无法学习到最优策略。同时,过低的学习率使得梯度下降的步长过小,可能导致神经网络收敛到局部最优。
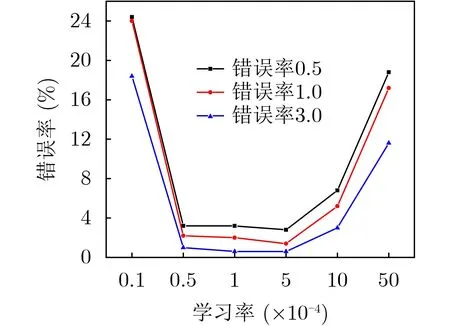
图4 不同学习率下的错误率
图5展示了本文所提基于CNN的DQN方案与原有基于DNN的DQN方案在决策错误率上的对比。其中,基于DNN的方案包括两种:第1种DNN方案包含6×1的输入向量,每个元素表示对应服务区[m,l]的当前状态;第2种DNN方案包含24×1的输入向量,该向量仅将CNN方案的输入矩阵按行展开。仿真图显示,经过80000步训练,6输入DNN方案的错误率要比所提出的CNN方案大得多。虽然DNN方案的错误率会随着输入神经元数和训练步数的增加而降低,但本文所提出的CNN方案显然更优。
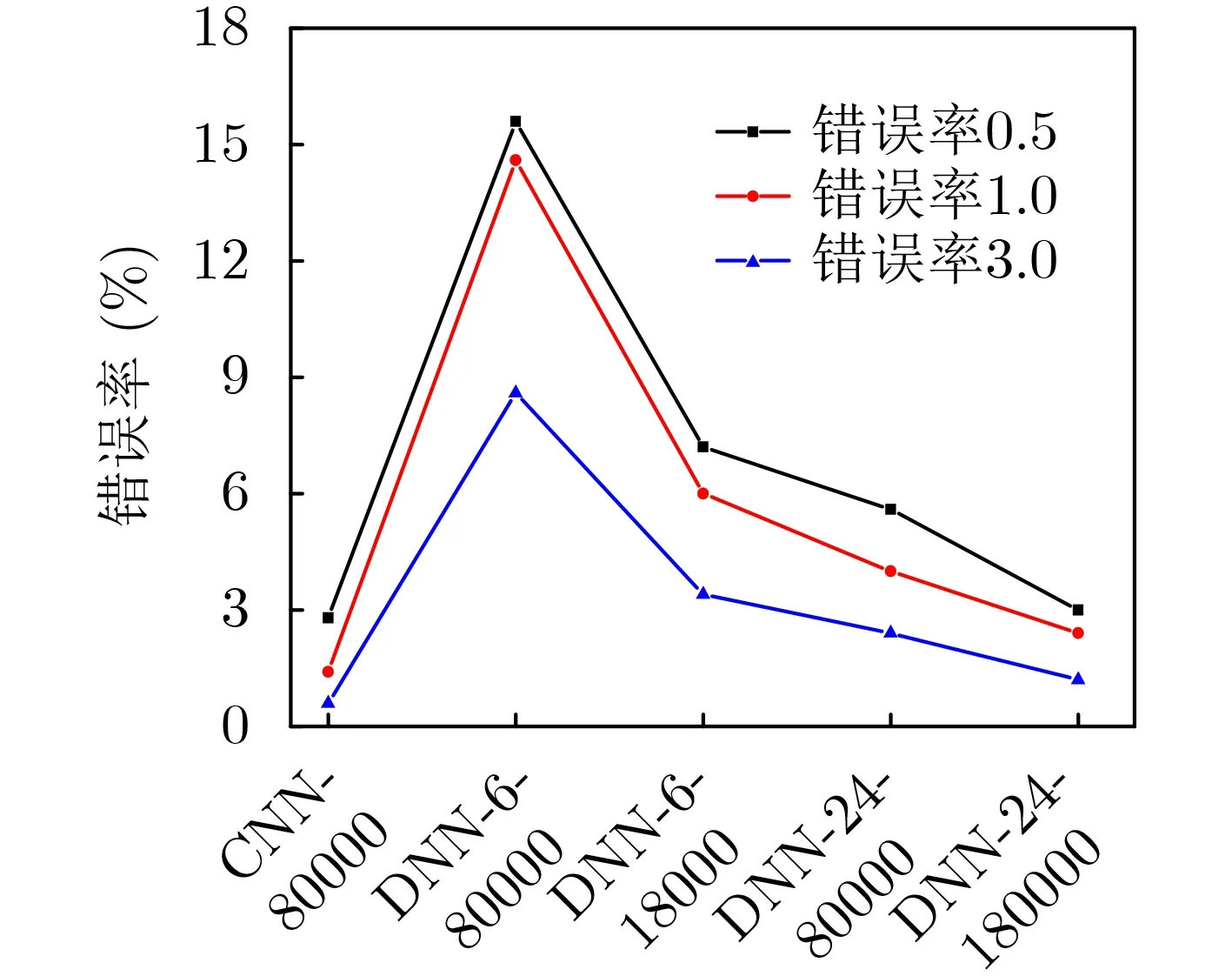
图5 不同网络框架下的错误率
5.4 系统频谱利用率
图6展示在不同的最小距离Lmin下,不同方案的频谱利用率对比。本文所提方案与以下5种基准方案作对比:穷举法、Q-learning方案、随机分配、最大距离模式和最小距离模式。其中,最大距离模式是指所有无人机选择距离AP最远的服务区,而最小距离模式是指所有无人机选择距离AP最近的服务区,此两种模式的功率分配策略与所提方案相同。从仿真结果可以看出,本文提出的基于DQN的方案接近穷举法性能,明显优于其他方案。此外,所提方案与最小距离模式的性能差异随着Lmin的增大而增大,而与最大距离模式的性能差异则相反。当Lmin=1000 m时,最近的服务区具有较低的路径损失,因此更容易被选择。随着Lmin的增大,最近服务区和最远服务区之间的路径损失差距逐渐减小,信道增益更高的服务区成为首选。
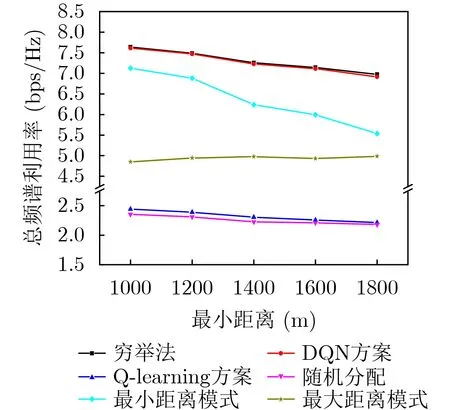
图6 不同最小距离下的频谱利用率(DQN和Q-learning方案经历60000步训练)
图7展示服务区数量对不同方案下频谱利用率的影响。该图表明,本文提出的基于DQN的方案优于其他方案,并接近于遍历最优值。更多的服务区带来更多的状态和动作,而更多的动作增加了实现更高频谱利用率的可能性,因此系统总频谱利用率随着服务区的增加呈上升趋势;但同时更多的状态和动作也增加了网络的训练难度,使得网络收敛速度变慢,决策错误率变高。此外,Q-learning方案的频谱利用率与随机分配方案相似,这是因为大量的状态会导致维度灾难,并且未收敛的Q-table无法根据当前状态获得准确的决策。随着服务区数量的增加,Q-learning方案的性能表现甚至不如随机分配方案。
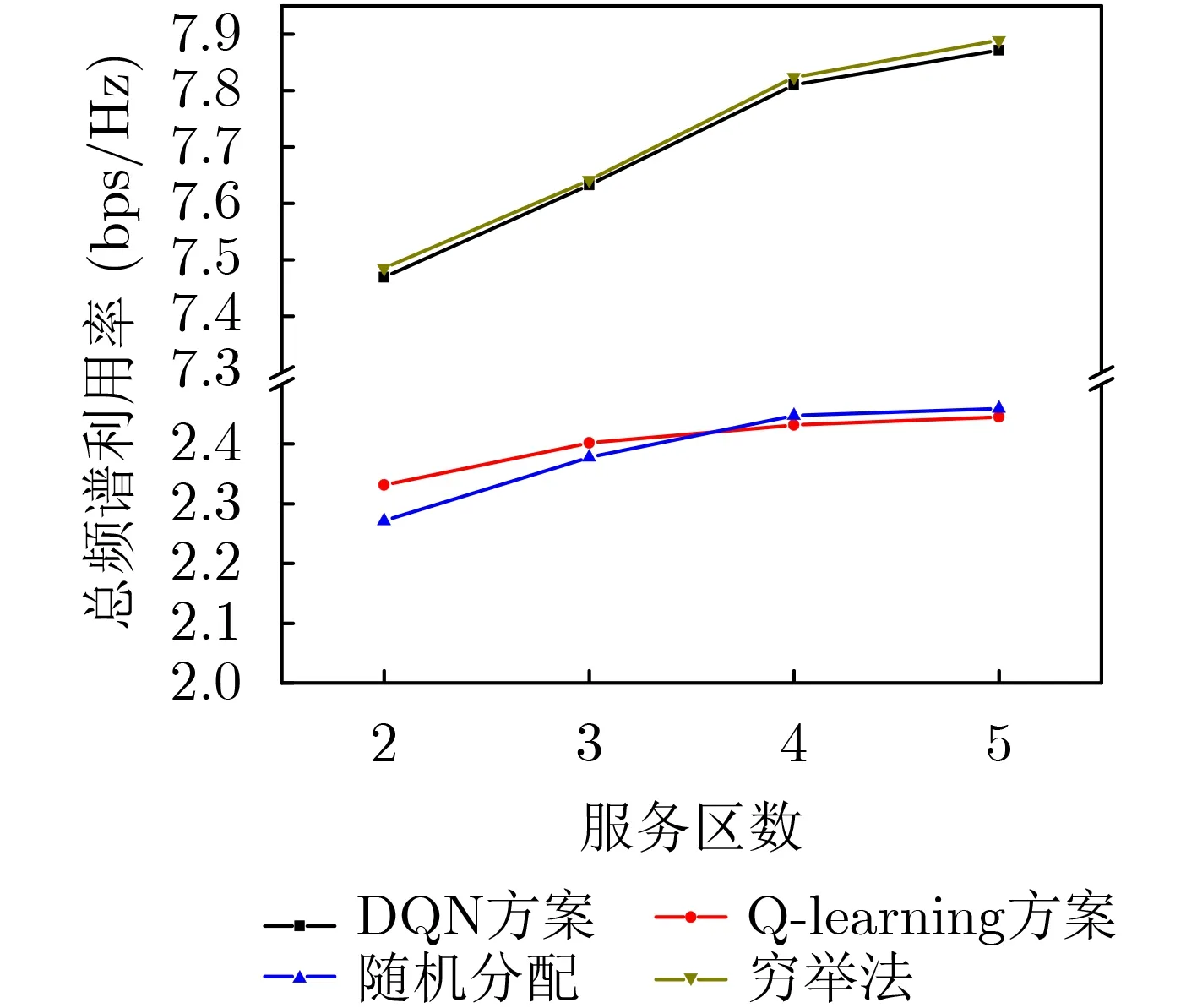
图7 不同服务区数量下的频谱利用率(DQN和Q-learning方案经历60000步训练)
6 结束语
本文针对无人机辅助通信系统,提出了一种基于AP决策和局部决策的两跳协作机制,在降低反馈链路负载的同时,研究联合设计AP功率分配、无人机服务区选择和用户调度方案。本文将功率和服务区调度策略建模为DAMDP问题,采用具有多维输入的DQN算法来求解。仿真结果显示,基于CNN的网络框架能够减少决策错误率,提升训练效果,使得所提方案在提升系统频谱利用率的同时,有效提高收敛速度、降低计算复杂度。在未来的工作中,我们将进一步研究无人机位置变化频率和资源消耗之间的平衡关系。
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
中国交通信息化(2023年1期)2023-03-18 02:01:40
中国交通信息化(2020年4期)2021-01-14 01:30:40
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
消费导刊(2017年24期)2018-01-31 01:29:29
中国公路(2017年5期)2017-06-01 12:10:10
教师·中(2017年3期)2017-04-20 21:49:49
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
印制电路信息(2015年6期)2015-12-30 12:57:48
