
基于新型多尺度注意力机制的密集人群计数算法
2022-03-30 09:16:12万洪林王晓敏彭振伟白智全杨星海孙建德
电子与信息学报 2022年3期
万洪林 王晓敏 彭振伟 白智全 杨星海 孙建德
①(山东师范大学物理与电子科学学院 济南 250358)
②(山东师范大学信息科学与工程学院 济南 250358)
③(山东大学信息科学与工程学院 青岛 266237)
④(青岛科技大学信息科学技术学院 青岛 266061)
1 引言
随着庆祝活动、音乐会、体育赛事、公众游行等大型公共活动日益增多,人群大量集聚的场景不断出现,各种踩踏受伤事件也层出不穷,因此对密集人群进行有效监管非常必要。人群计数能够为大规模人群聚集的监管提供技术支持[1,2]。如果能够使用计算机视觉技术对相关场景的密集人群进行准确的人群密度估计,则会对减少危险事件的发生带来很大的帮助。目前,准确统计出在不同的场景下的人群总数仍然具有很大的难度,因此这一领域所面对的问题具有一定挑战性。早期人群计数大多采用传统的检测和回归方法,需要人为提取出图片中的低层次特征,并将其用特征框标记出来,标记框的数量即为图片中行人的数量,随着人群密度的不断提高,人与人之间的互相遮挡越来越严重,再加上密集人群分布不均、光照等因素的影响,这些问题都对密集人群计数提出了更高的挑战。近年来随着深度学习的快速发展,人群计数也更多地采用此方法。深度学习方法相对于传统的检测、回归方法,准确性和适用性要更好。通过卷积神经网络将卷积核与图像做卷积操作,通过一系列的卷积核,不断提取图像的特征,最后将提取到的高层特征进行分类生成密度图,再对密度图求和来统计人群的总体数量。但其只是将这些特征做了简单的操作,不能较好地利用这些特征。为此本文提出了一种新的基于新型多尺度注意力机制的密集人群计数方法。其网络结构分为主干网络、特征提取网络和特征融合网络。特征提取网络分为两个支路:特征支路和注意力支路。考虑到数据尺度特征的多样性,本文的两个支路都增加了新型多尺度模块,并在特征支路单独增加了Res结构,以便更好地获取不同尺度下的人群特征。注意力支路用于不断加强密集人群图像中的头部特征,从而使得头部区域的密度图相较而言更加明显。在特征融合网络中,通过注意力融合模块,将注意力特征与图像特征进行有效融合,进一步提高计数精度。在公开数据集(ShanghaiTech,UCF_CC_50, Mall, UCSD)上的实验获得了比其他方法更好的参数指标。
2 相关工作
早期行人计数主要采用的是基于检测的方法,但这类方法不够准确,效率较低。随着深度学习技术的飞速发展,人们更加倾向使用卷积神经网络(Convolutional Neural Networks, CNN)实现对于密集人群的计数。Shang等人[3]提出了一种使用CNN的端到端计数估计方法,将整个图片作为输入,最后直接输出人群总数。针对图像密度、视角信息差异大的问题,Zhang等人[4]提出了MCNN方法,即通过使用多个卷积核大小不同的网络来捕捉不同尺度的目标特征信息,以增强模型的稳定性。通过估计具有任意人群密度和任意视角的图像,从而生成图像或视频中真实的人群密度图。与MCNN类似,Onoro-Rubio等人[5]提出了一种尺度感知计数模型Hydra,通过尺度放缩的思想考虑了视角差异带来的影响,即使没有任何明确的场景信息,这一模型也能估计各种各样的拥挤场景中的密度。Marsden等人[6]受到尺度感知模型的启发,提出了一种基于Resnet-18[7]架构的网络,可同时实现人群计数、暴力行为检测和人群密度等级分类的工作。Li等人[8]首先提出MCNN的劣势:训练时间长以及无效分支结构,然后提出使用空洞卷积以获得更大的感受域并提取更深层次的特征。Sam等人[9]提出了选择卷积神经网络(Switch-CNN)来提升人群计数的精确度,首先由几个卷积核大小不同的CNN作为密度图预测的回归器,然后再由一个选择分类器来为每一张输入图像选取最优回归器,将其得到结果作为最终结果。此外,Wang等人[10]提出了一种数据收集器和贴标机,它可以生成合成人群场景,不需要任何人力就可以对图片进行注释。在此基础上,作者还构建了一个大规模、多样化的合成数据集。Li等人[11]提出了一种针对可自由移动人体在单个摄像机场景下估计深度密度图的方法。Wang等人[12]设计了一个包含结构特征编码器、空间上下文学习解码器以及密度回归模块在内的网络结构。这一网络从频道维度和空间维度两个维度来获取空间上下文信息,以此来提高网络性能。Chen等人[13]提出了相关区域预测方法,即统计密度图中的像素之和代表输入图像中落入相应局部区域的数量。这一方法丢弃了详细的空间信息,使网络更加关注计数而不是对具体每个人进行定位,从而相应地提高计数的准确性。多列结构在一定程度上解决了人群计数存在的尺度变化问题,但不同CNN学习到的多尺度人群特征如何在保证信息不丢失的情况下充分融合利用,提高输出密度图质量,仍是多列结构没有解决的难题。为此孟月波等人[14]提出了一种编码-解码结构的多尺度卷积神经网络来进行人群计数,提升了密度图的输出质量。编码器采集更加丰富的尺度信息,解码器对编码器的输出进行上采样,实现了高层语义信息和前端低层特征信息的融合。左静等人[15]提出了一种多尺度融合的深度人群计数算法,以膨胀卷积理论为基础,构建多尺度特征提取模块,以此实现上下文特征信息提取。最后经过特征融合得到更高质量的密度图。Zou等人[16]提出了自适应容量多尺度卷积神经网络(ACM-CNN),它可以为输入的不同部分分配不同的容量。该模型以输入图像的重要区域为中心,在满足人群密集度的前提下,优化其容量分配。尽管取得了很大进展,但由于密集人群计数场景下人群分布不均、光照、遮挡等因素带来的影响,上述方法仍然存在改进空间。
3 网络结构
针对当前密集人群计数存在的问题,本文提出了基于新型多尺度注意力机制的密集人群计数算法。其基本思想,一是通过双通道特征提取网络取代传统的单通道网络结构,将人头定位与密度图结合,实现更丰富的特征提取;二是引入新型多尺度模块,增强网络对不同尺度特征的适应性;三是引入空间注意力机制,进一步丰富特征形态,从而为高质量的密度图生成奠定基础。
本文提出的网络结构分为3部分,即主干网络、特征提取网络和特征融合模块(如图1所示)。
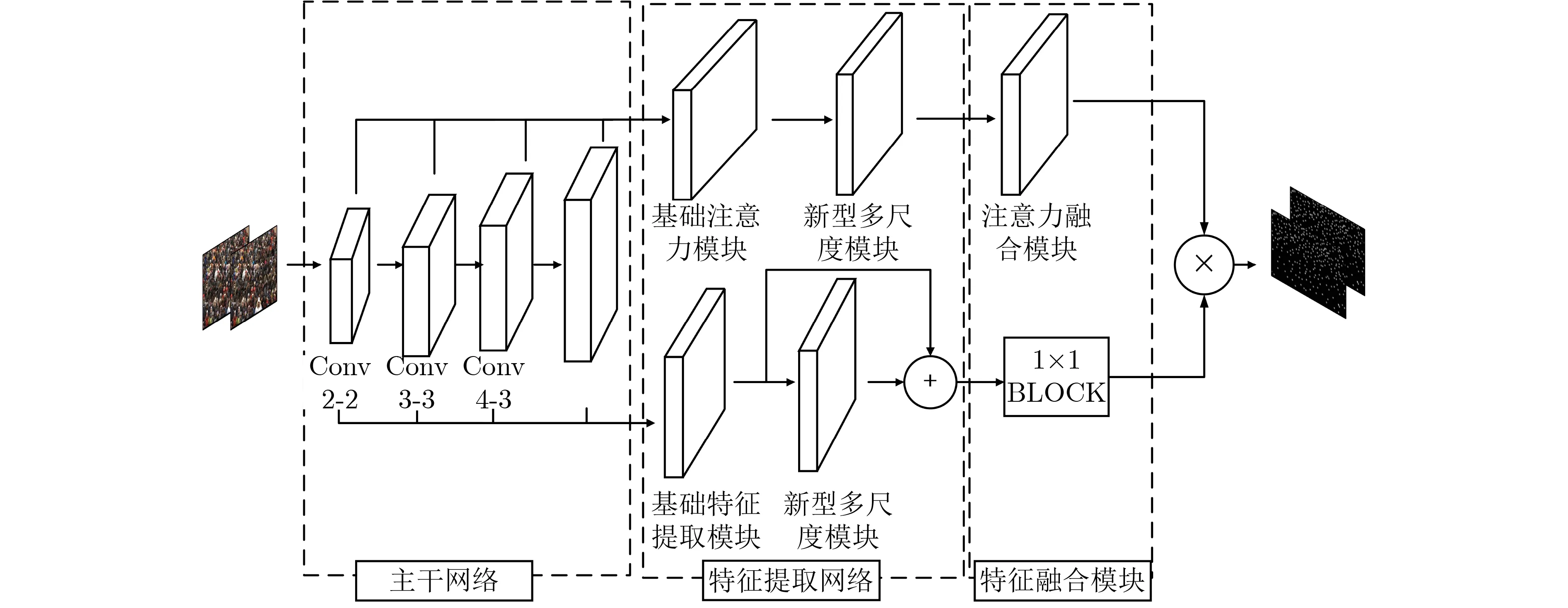
图1 本文提出的网络结构
3.1 主干网络
主干网络主要用于图像特征的提取,本文采用的骨干网络为VGG-16,其中有4层特征作为主干网络的输出特征,分别是conv2_2,conv3_3,conv4_3和conv5_3(如图2所示)。
3.2 特征提取网络
本文提出的网络模型中,特征提取网络采用新型注意力机制。它包括两个支路:特征支路与注意力支路。特征支路用来提取图像中的人群分布特征;注意力支路则用于准确估计人头位置,对得到的人群密度图进行修正,得到较高质量的人群密度估计图。
特征支路包括基础特征提取模块(如图2所示)、新型多尺度模块和辅助结构。基础特征提取模块主要用于将低分辨率特征恢复为高分辨率特征,为密集人群计数的密度图估计提供更丰富的空间分布信息。注意力支路包括基础注意力模块和新型多尺度模块。在本文中,基础注意力模块的结构与基础特征模块相同,作用是将低分辨率特征恢复为高分辨率特征,有利于人头位置的精准定位。
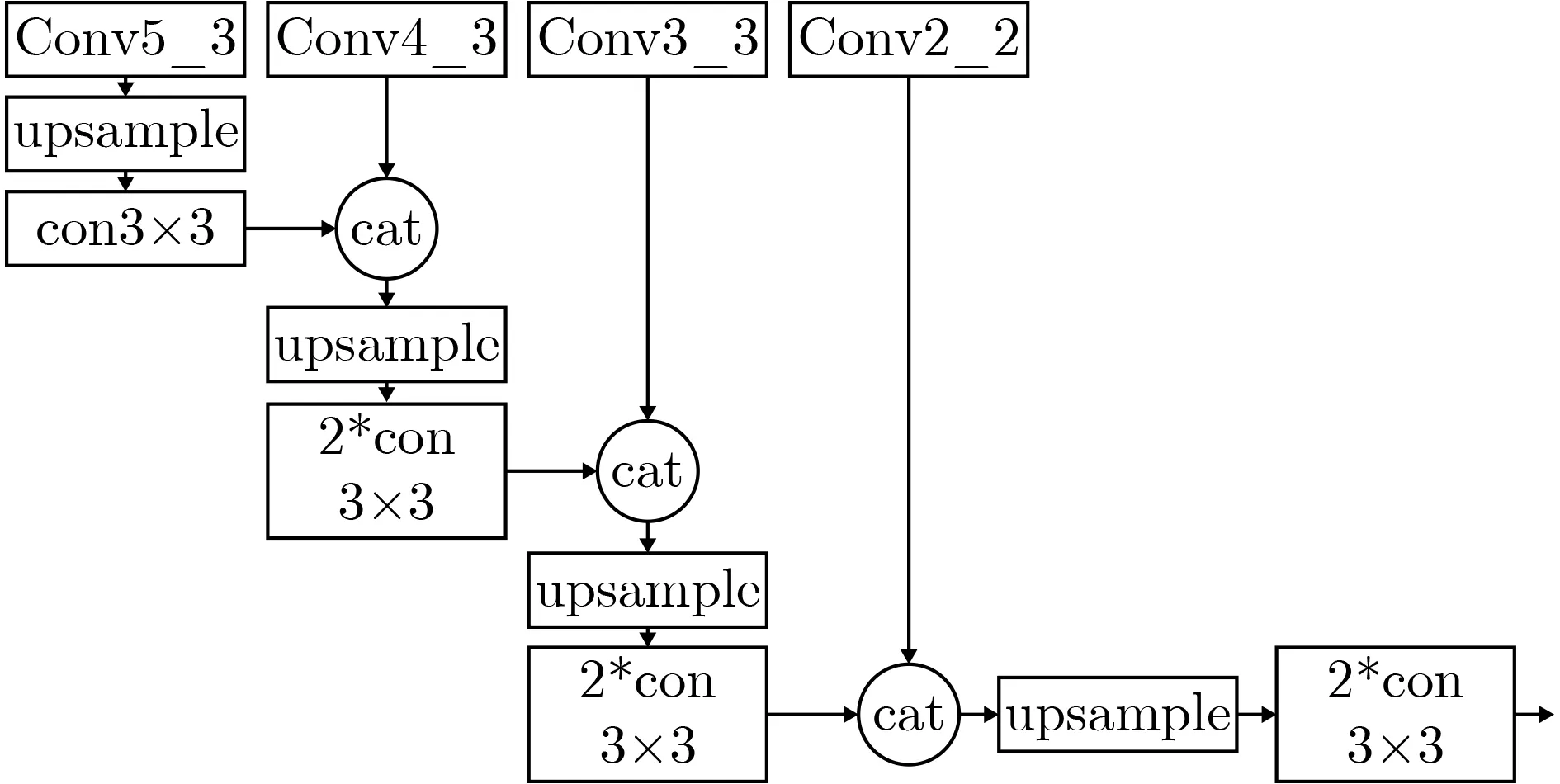
图2 基础特征提取模块,在本文亦被采用为基础注意力模块
针对特征提取网络,本文提出了新型多尺度模块,用于改善两个支路的输出特征,提高计算效率。随着神经网络深度的不断增加,网络参数体量越来越大,而其中大量参数的权值趋于零,冗余度高,浪费计算资源。解决此问题的一种方法就是引入稀疏滤波器。由此Szegedy提出了inception结构。经典的inception是由1×1,3×3,5×5卷积层和一个池化层(pooling)组成的并行结构(如图3所示)。卷积核的大小直接决定了对不同目标的感知能力。本文考虑到密集人群图像中人的大小的变化范围,为提取图像中的大尺度人群特征,我们将inception结构中的池化层,替换为7×7卷积层(如图4所示)。
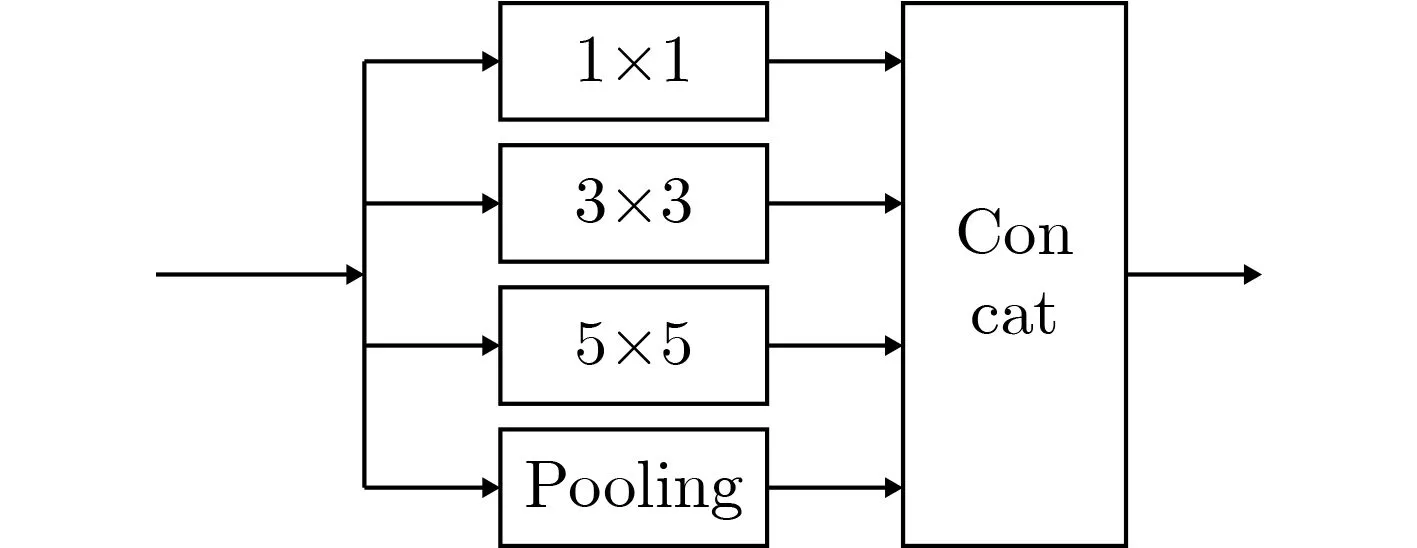
图3 传统Inception结构
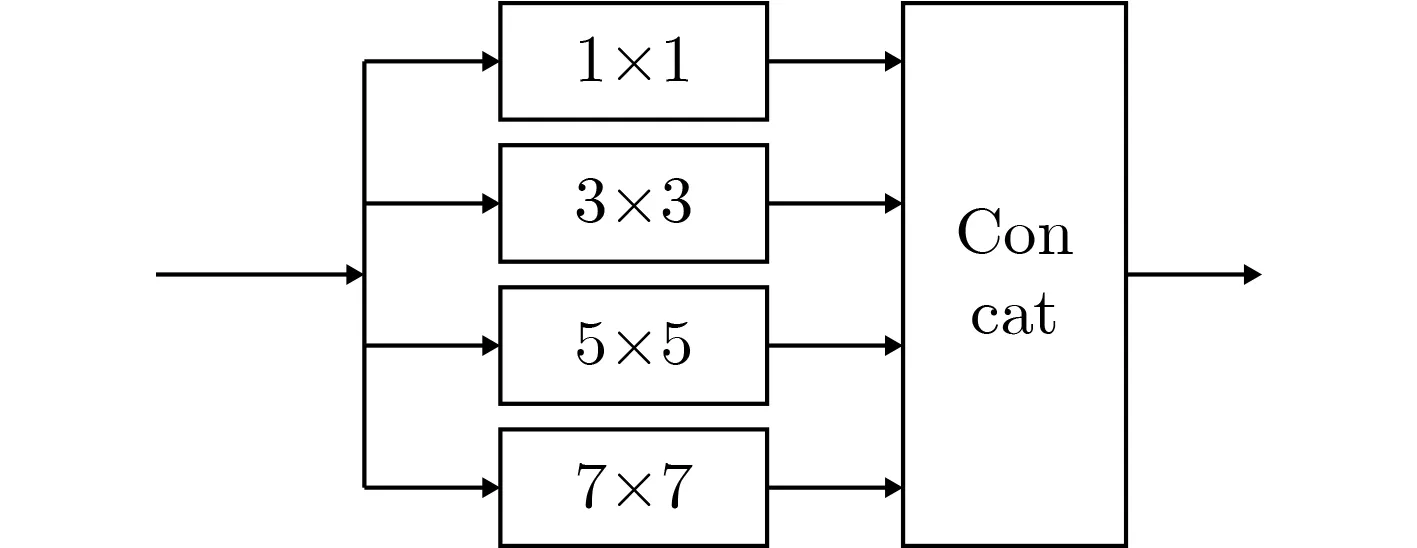
图4 改进Inception结构
同时考虑到为了提高网络计算效率,我们进一步将上述5×5卷积层,替换为2个级联的3×3卷积层,将7×7卷积层替换为3个级联的3×3卷积层。替换前后其感受野范围不会改变[17]。
由此我们提出了新型多尺度模块(如图5所示)。
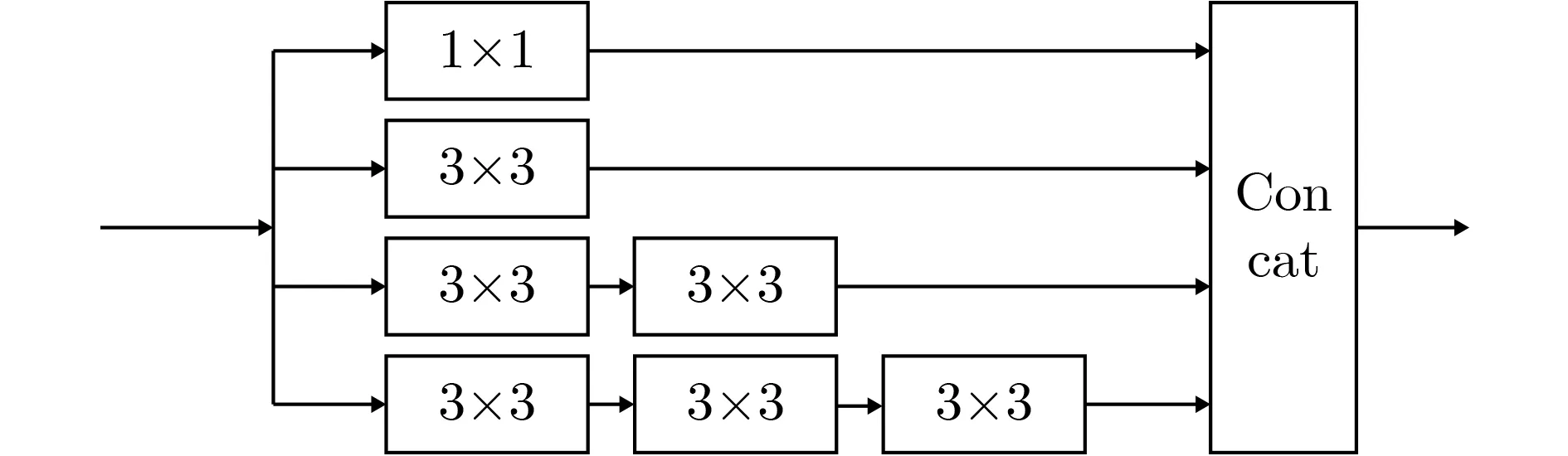
图5 新型多尺度模块
新型多尺度模块增强了特征支路中人群密度特征的集中度,进一步扩大了感受野,使得每一层输出的特征图上的像素点在输入图片上映射的区域增大。同时新型多尺度模块也能够在注意力支路中增强人头位置信息。
3.3 特征融合模块
特征融合模块的作用是将注意力支路的输出特征作用于特征支路的输出特征,通过相乘的方式实现两者融合,得到更高质量的人群密度图。其中起关键作用的是注意力融合模块,其结构如图6所示。
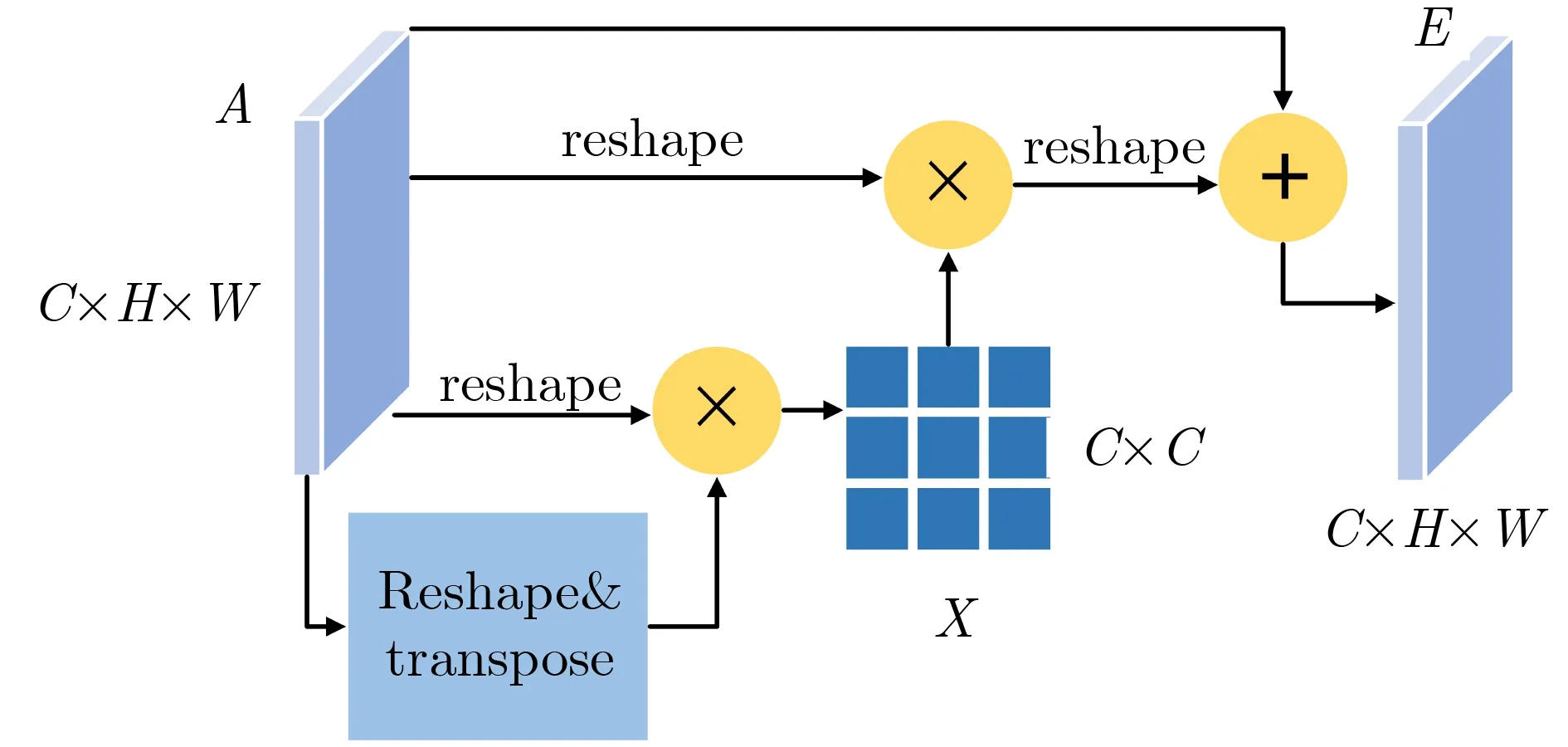
图6 注意力融合模块
在高层次特征中,丰富而抽象的特征信息,对网络的特征辨识能力提出了更高的要求。在注意力融合模块中,通过矩阵变换及其组合,特征维度或元素位置发生变化,即通道信息发生改变,从而实现了特征重组。这些重组后的特征能够进一步丰富密集人群密度图的特征描述,提高网络辨识能力。本文中注意力定义为

3.4 损失函数
本文选取欧氏距离作为网络模型的损失函数,将网络输出的人群密度估计图回归到 ground truth的密度图。损失函数定义为

4 实验结果
本文实验的硬件配置为: CPU Xeon-E5,GPU Quadro P5000 / 16GB和128GB内存;软件环境是Ubuntu 16.04和Pytorch 1.0。
4.1 评估指标
现有的传统人群计数方法均采用平均绝对误差(Mean Average Error, MAE)和均方误差(Mean Square Error, MSE)两种误差来评估模型的性能。本文亦采用MAE以及MSE两项指标来评价密集人群技术网络的性能,其定义为
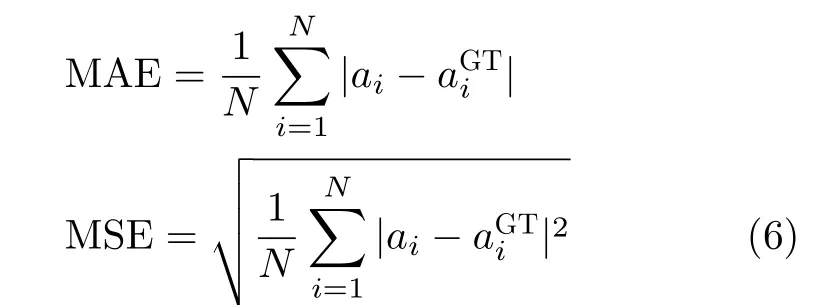

4.2 数据集
本文实验数据集包括S h a n g h a i T e c h[4],UCF_CC_50[18],Mall[19]和UCSD[20]。
上海数据集包含了1198个图像以及330165个注释头文件,它分为A和B两部分。其中A部分由300张训练图片和182张测试图片组成,B部分由400张训练图片和316张测试图片组成。上海数据集是具有不同场景和不同密度级别的数据集,非常具有挑战性,也是最有代表性的数据集。
UCF_CC_50是包括各种密度和视角的不同场景。为了捕捉场景类型的多样性,作者收集了不同的图像,像音乐会、抗议、体育馆和马拉松等场景。它包含了50个不同分辨率的图像,每个图像平均有1280人,整个数据集中共标记了63075个人。个数从94到4543不等,图像之间存在很大差异。
Mall数据集是一个具有不同光照条件以及人群密度的数据集,是使用安装在购物中心的监视摄像机收集的数据集。除了具有各种密度水平外,它还具有不同的活动模式。另外,数据集中的场景还具有严重的透视畸变,导致对象的大小和外观大的变化,该数据集还呈现了由场景对象引起的严重遮挡的挑战。数据集中的视频序列由2000帧大小为320×240的帧组成,其中标记为行人的6000个实例。前800帧用于训练,剩余的1200帧用于评估。
UCSD数据集是为人数统计创建的第1批数据集。数据集是从人行道的摄像机收集的。该数据集由来自视频的2000帧大小为238×158 以及每5个帧中每个行人的地面实况(Ground Truth)注释组成。此数据集共包含49885个行人实例,我们将601到1400作为训练集,剩余的1200张图片用来测试。
4.3 实验结果
我们评估了本文模型在主要人群数据集ShanghaiTech,UCF_CC_50,Mall和UCSD上的计数性能。并与其他人群计数模型的MAE和MSE指标进行比较。表1—表4列出了在4个数据集上不同模型的实验结果,可以看出本文的模型要优于其他方法。
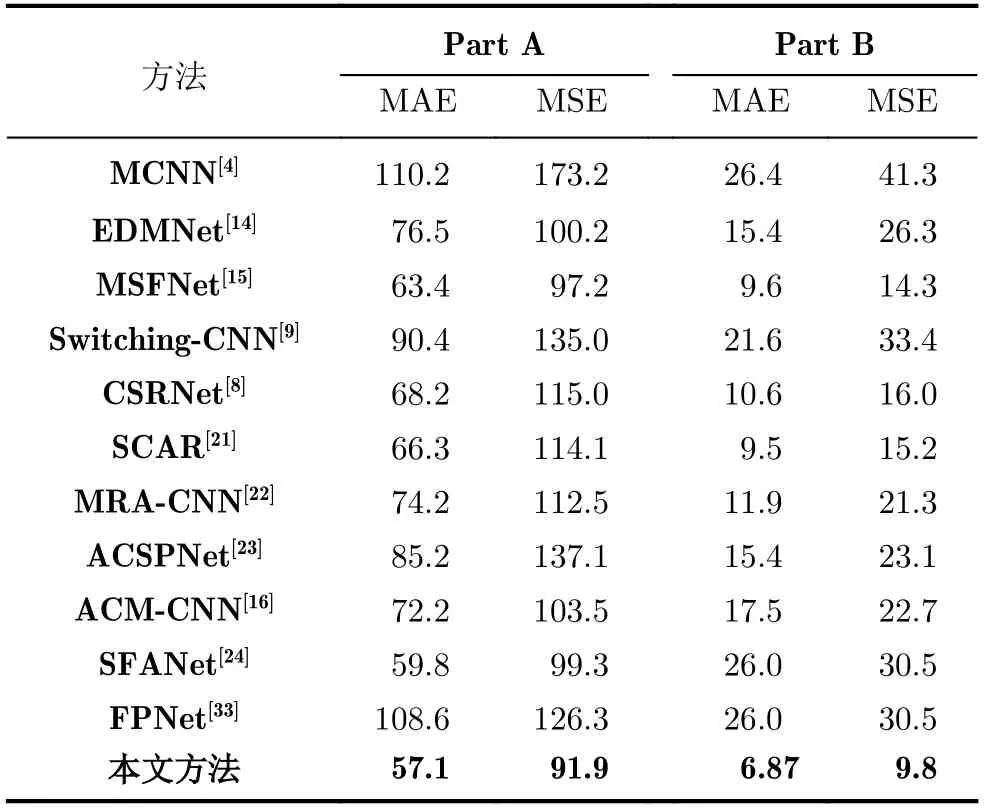
表1 ShanghaiTech数据集实验结果
4.3.1 ShanghaiTech
本文网络估计的人群密度图与ground truth的对比如图7所示。

图7 密度估计图、ground truth以及原始图像
4.3.2 UCF_CC_50
考虑到UCF_CC_50图像数量少,该数据集发布者定义了一种交叉验证协议,以此实现样本容量的扩增。我们也采用了相同的5次交叉验证策略,即将整个数据集样本均分为5份,每次训练取其中4份样本作为训练集,剩余的1份作为测试集,一共进行5次训练和测试。最后计算5次实验的MAE和MSE的均值作为测试结果。表2为本文方法对UCF_CC_50数据集的实验结果与其他方法的对比(batch size=8),可以看出本文方法取得了更优的实验结果。
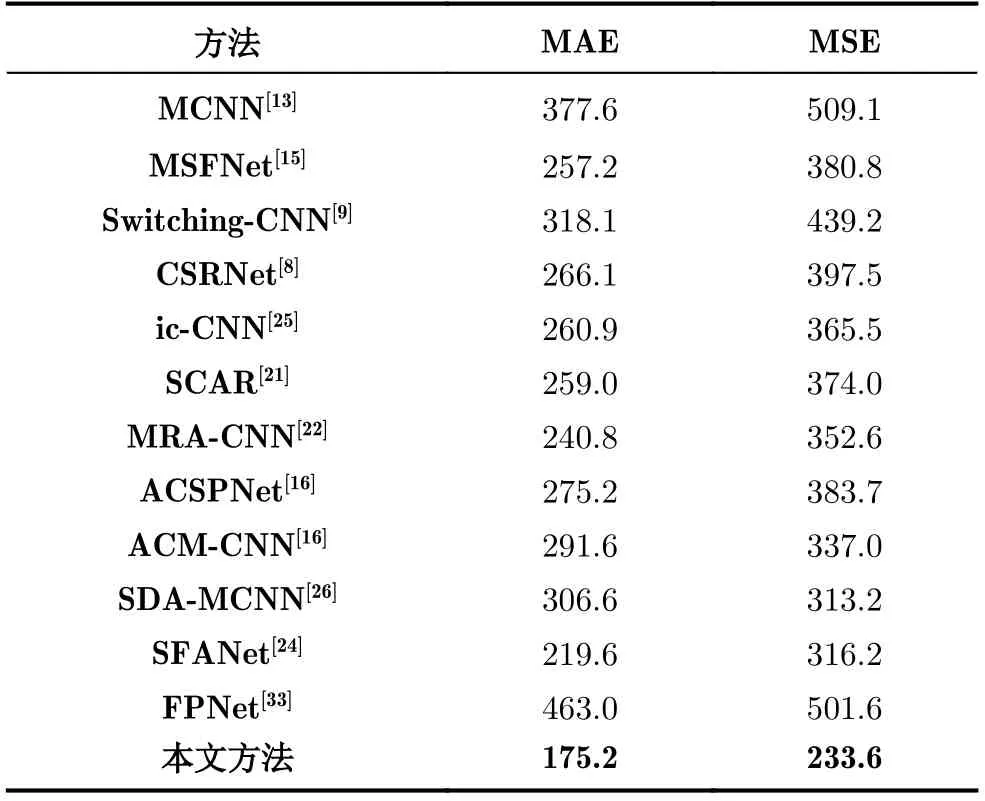
表2 UCF_CC_50实验结果
在表2中可以看到与之前最好的方法相比,本文方法的平均绝对误差(MAE)结果是175.2比最好的方法要低44.4,均方误差(MSE)也有明显的降低。
4.3.3 Mall数据集
表3为本文方法对Mall数据集实验的实验结果(batch size=8 ),可以看到与之前最好的方法相比,MAE结果是1.57,比之前最好的方法要好0.23,MSE结果是2.03,比之前最好的方法要好1.07。
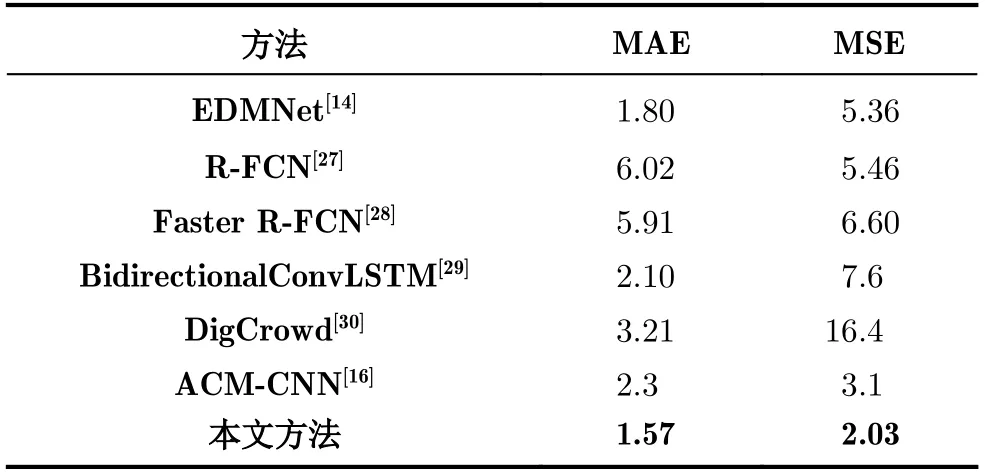
表3 Mall实验结果
4.3.4 UCSD数据集
网络在多次降采样后输出特征过于模糊,影响了计数精度。因此,本文通过双线性插值将UCSD的分辨率扩大为960×640,其ground truth也进行相同比例的插值。提升分辨率能够提高人群密度估计的精度,适于注意力机制的作用发挥。由表4看出,本文方法取得了更优的实验结果(batch size=8)。
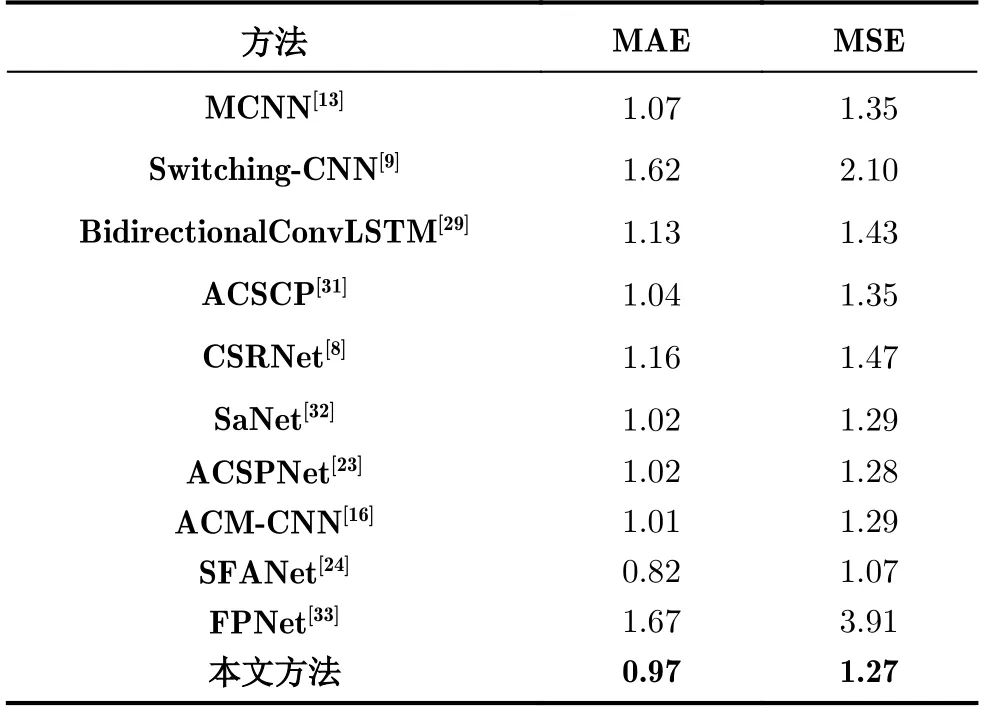
表4 UCSD实验结果
4.4 消融实验
在实验最后本文进行了消融实验,以确认本文包含的各个网络结构带来的影响。本文将1×1,3×3,5×5,7×7的基础特征提取网络简称为D,将新型多尺度密度图估计模块称为ND,将1×1,3×3,5×5,7×7的多尺度注意力模块称为M,将新型多尺度注意力模块称为NM,将注意力融合模块称为C。消融实验对最具代表性的同时也是具备相当难度ShanghaiTech-PartA数据集进行。实验结果(表5)证明了本文网络的不同部分对结果的改善程度。从表5可以看出,以Backbone + D +M为原型,在增加了注意力融合模块C后,网络Backbone+ D+M+C的MAE和MSE分别减少了0.8和3.9。将D替换为ND、将M替换为NM后,网络Backbone + ND + NM+C的MAE和MSE继续分别减少了0.7和0.8。这充分证明了新型多尺度模块和注意力模块对网络性能的改进作用。
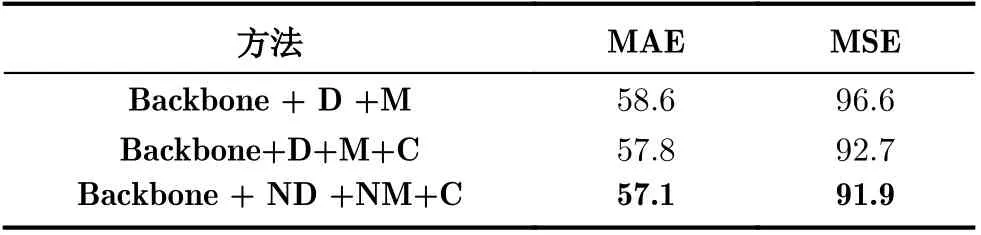
表5 消融实验结果
5 结论
本文提出了一种新型卷积神经网络结构,用于密集人群计数。该网络利用新型多尺度注意力模块对语义丰富的深层特征进行处理,以获得更加丰富的语义信息;利用注意力机制对深层多尺度特征进行处理以抑制非头部区域,使头部区域的信号更加明显。同时,本文引入的新型多尺度模块能够使深层特征的空间集中度变高,扩大感受野,得到更高质量的人群密度图。在深层的特征中,通过注意力融合模块提高特征辨别度,以此来提高网络的性能。实验结果证明了本文方法的有效性。
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
能源工程(2020年6期)2021-01-26 00:55:22
中等数学(2020年8期)2020-11-26 08:05:58
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
太空探索(2016年5期)2016-07-12 15:17:55
电信科学(2016年9期)2016-06-15 20:27:30
电测与仪表(2016年13期)2016-04-11 11:21:20
电工技术学报(2014年7期)2014-11-15 05:53:48
