
新高考改革背景下考生择校行为可视化分析
2022-03-29 21:35刘华强刘建华
教育教学论坛 2022年9期
刘华强 刘建华
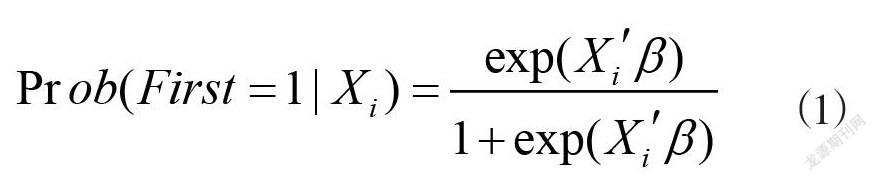


[摘 要] 新高考改革倒逼高校更加關注“用户需求”。通过采集某师范大学新生数据构建可视化模型,发现存在三类特征差异较为明显的新生“典型画像”。基于画像,可以制定不同群体的精准招生宣传措施并提供不同阶段的个性化服务。根据细分市场提供精准信息服务成为研究热点和行业共识。精准服务的前提是对细分市场用户群体特征的分析,把握潜在目标群体的择校动机,较好地回答“向谁宣传”“宣传什么”的问题。研究的创新在于探索根据新高考改革背景下择校行为的理论研究制定具体校本招生宣传政策的数据分析方法。
[关键词] 新高考;择校行为;用户画像;K-Means聚类
[基金项目] 2020年度福建省中青年教师教育科研项目(科技类)“基于K-均值聚类的高校宣传用户画像研究”(JAT200321);2020年度闽南师范大学教育教学改革研究项目“实践取向的公费师范培养项目综合改革研究”(JG202026)
[作者简介] 刘华强(1983—),男,福建寿宁人,心理学硕士,闽南师范大学学科建设与研究生工作处学科建设办公室主任,助理研究员,主要从事教育管理研究;刘建华(1978—),男,福建南靖人,经济学博士,闽南师范大学数学与统计学院副教授,商学院调查与数据研究中心主任,主要从事贝叶斯统计、模型选择研究。
[中图分类号] G644 [文献标识码] A [文章编号] 1674-9324(2022)09-0049-04 [收稿日期] 2021-09-23
新高考改革背景下,00后学生择校自由权得到释放,高校招生宣传必然由粗放型向智慧型转变。以往不区分对象、内容宽泛、单向传播的宣传方式已无法满足考生的多元化、个性化需求。当前大数据环境下的精准营销策略都与用户需求有紧密的联系,Zoratti S 等提出了利用数据挖掘事物间的关联性[1],Zhen Y 等提出通过识别不同类别客户之间的潜在特征进而提出适当的精准营销策略[2]。用户画像分析是近年来深度挖掘用户需求的重要方法,用以更好地理解用户需求,实现个性化、精准化信息服务。在高等教育领域,近年来出现多项研究,探讨了用户画像在图书馆服务、思想政治工作、学生评价、心理健康评估等场景下的应用。但该技术在招生宣传的应用研究尚不多见,也缺乏可以复制的案例。
一、研究方法
(一)用户画像的概念
最早提出用户画像的概念是交互设计之父A.Cooper,他认为用户画像是一种建立在一定数据基础上概括用户行为特征、需求和目标的模型[3]。经过用户特征属性归纳或相似度计算进行聚类,可以从海量数据中获取某产品(服务)的“典型用户”的可视化形象——群体用户画像,从而实现用户分类、市场细分等目标。相较于销售人员或产品设计人员主观归纳的用户特征,用户画像作为用户静态和动态属性特征提炼后得出的“典型用户”的概念模型,更加强调用户的主体地位,更加凸显用户的特定化需求[4]。
(二)高校新生择校行为的构成因素
用户的基本特征、需求及偏好等特征信息是构建用户画像的基础性数据单元。通常也将用户画像的属性分为两个部分:一部分包括性别、年龄等身份属性数据,另一部分为行为数据。研究中抽取这些特征信息中最具代表性的信息或者核心信息成为标签。
在高考生择校及专业选择影响属性的研究中,国内学者关注的属性主要可以概括为家庭经济社会背景、成本与收益的比较、高校特征、受教育者价值观念和高等教育信息五个方面。刘自团等开展的不同家庭经济背景子女的择校差异及影响因素调查采用谢作栩教授团队所研制的“大一新生调查问卷”,共包含16个影响因素,分别是父母、家人或其他亲属的影响或建议,中学教师及其他非亲属长辈的影响或建议,朋友、同学、学长(姐)的影响或建议,学校的声望,离家较远,离家较近,有亲朋好友在本校,校园环境、设施、设备,特殊项目(如实验班、特色班或按大类招生等),大学师资,学校知名度,学科、专业声誉,学费和生活费用因素,就业前景,学校招生分数段,大学所在地的经济发达程度等,为高校新生用户画像的构成标签提供了依据。上述属性均为较为静态的因素,本研究根据招生工作人员意见,增加对宣传工作至关重要的“搜寻院校招生信息时间”作为可变信息标签。
(三)建立高校新生用户画像的模型与方法
为了从大量数据中获取“典型用户”的可视化形象,需要将用户分类为不同的组群。K-means聚类分析以算法快速简单、适合挖掘大规模数据集的优势成为建立分类的常用方法之一,其数学思想是将n个对象的数据分成k个簇(k≤n),簇中对象的“距离”较小,不同簇中对象的“距离”较大。通过K-means聚类分析,能够将一批样本数据(或变量)按照它们在性质上的亲疏程度在没有先验知识的情况下自动进行分类,达到“物以类聚”的目的。傅振南利用K-means算法对录取学生所在学校进行细分,得出了不同学校簇(用户)中学生的报考倾向,提供了“招生问题的描述和聚类分析的目标—招生相关源数据收集—数据预处理—聚类分析—结果可视化和解释”的研究范式。参考傅振南的研究,结合孙吉贵提出的典型的聚类过程,本研究将生成高校新生用户画像的步骤分为数据预处理与特征提取、择校行为的模型选择、聚类结果可视化解释三个步骤。
二、高校新生用户画像构建的数据处理
(一)数据预处理与特征提取
使用网络平台采集福建省某省属高校(以下简称M校)2019级、2020级新生近一万人在高考填报志愿中院校及专业选择的行为特征。调查数据用网络平台上填答电子问卷的方式收集并匹配学生中学档案数据和高考志愿填报数据获得。调查在每年新生入学后一个月内进行,共收到调查问卷9761份,其中有效问卷9400份,有效率为96.31%。本问卷调查对同一IP地址、同一手机/电脑的用户填写的问卷数进行了严格设置,并且不允许断点续答,从而保证每份问卷均回答完整有效。部分学生利用不同手机、电脑进行重复作答,经审核后予以剔除。本调查报告的所有统计数据均由网络平台后端数据统计生成。
(二)择校行为的模型选择
可能影响学生志愿填报行为的因素众多,部分因素由于存在多个类别,需要引入多个虚拟变量进行刻画。为刻画学生志愿填报行为,需要从众多的影响因素中选择显著的变量(或变量组),同时又要从存在多个类别的因素(即变量组)中选择显著的虚拟变量。因此采用了基于压缩估计的双层变量选择方法对学生志愿填报行为进行统计建模分析,第一层选择显著组,第二层选择组内显著单个变量。
根据前文研究方法部分高校新生用户画像的标签选择的讨论,结合M校特色,本研究以填报志愿时M院校是否排在第一愿志学校作为填报行为的度量,变量代码为First,作为因变量。选择的可能影响因变量First的因素包括:性别Sex,生源地SYD、应往届YWJ、中学所在地Location、文理科WLK、省份Prov、家庭经济水平Eco、父母最高学历Edu、父母职业是否与学生就读专业相关Occupation、大学目标规划Plan,以及搜寻院校招生信息的时间Search。其中,Location有三个类别,引入了两个虚拟变量——Location1和Location2;大学目标规划也分成三个类别,引入两个虚拟变量——Plan1和Plan2。这些自变量中家庭经济水平Eco和父母最高学历Edu为顺序型变量,搜寻招生信息时间为数值型变量,其余变量均为分类变量。
由于因变量为0-1的二分类变量,因此建立logistic回归模型:
(1)
其中X为所有的自变量,β为回归系数。采用基于压缩估计的双层变量选择方法进行变量选择,最终得到表1中的回归结果。
表1的全样本回归结果表明,女生比男生更倾向于报考M校,她们在填报志愿时把M校列为第一志愿院校的概率比男生高。类似的,农村生源地的学生、理科学生、福建考生、要报考师范类的学生,以及搜寻招生院校信息时间较短的学生,在填报志愿时均更倾向于把M校列为第一志愿院校。其余几个因素均不影响学生填报志愿的行为。
细分来看,对于师范类学生,影响学生是否将M校列为第一志愿院校的因素与全样本相同,且系数符号也完全一致,但在系数的绝对数值上均比全样本的回归系数更大,表明对师范类学生来说,女生、农村生源学生、理科生、福建生源学生及搜寻院校信息更短的学生更倾向于以第一志愿院校报考M校师范类。与全样本和师范类样本的回归结果不同,对非师范类学生而言,性别Sex和搜寻院校信息时间Search这两个变量则并不影响学生填报志愿时是否把M校列为第一志愿院校,其余的影响因素均与全样本和师范类样本回归的影响因素相同且符号一致,但在回归系数的绝对数值上要更小一些,这表明虽然生源地SYD、文理科WLK、省份Prov是重要的影响因素,但影响程度并不如对师范类学生那么大。
(三)聚类结果可视化解释
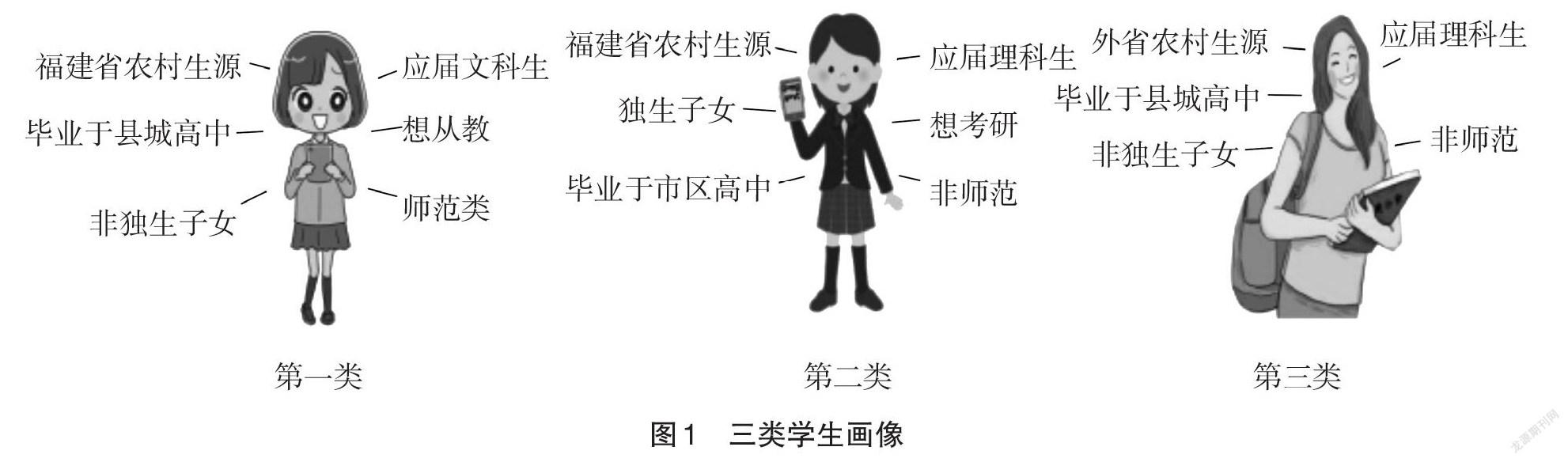
采用K-Means聚类方法,最终得到了如图1所示的三类学生画像。
第一类:福建省+农村生源+在县城中学就读+文科+非独生子女+想从教的女生,其家庭经济状况介于较低和中等之间,且偏向于中等,父母的最高学历略高于初中水平,她们约在考前1个月开始搜索院校招生信息。
第二类:福建省+城镇生源+在市区中学就读+理科+独生子女+想考研的女生,其家庭经济状况略低于中等水平,父母最高学历略高于高中/中专水平,她们在考前半个月左右开始搜寻院校招生信息。
第三类:省外+农村生源+在县城中学就读+理科+非独生子女+不考研不从教(即想毕业后直接就业)的女生,其家庭经济水平介于较低和中等之间,父母最高学历为初中水平,他们在高考结束后填报志愿前才开始关注院校招生信息。
三、分析与建议
过去在招生宣传期学校一般采取“广撒网+轰炸”策略,造成了数据爆炸和信息环境污染等问题,导致考生信息检索成本高而院校宣传效果差的资源错配。在上述背景下,不同的高校如何从全国一万多所高中找出适合本校的目标高中,成为高校招生宣传工作的重要问题。
本研究通过构建“用户画像”,用数据重构潜在新生群体的主要需求、偏好、动机特征,以考生为中心,通过目标群体细分形成某特定院校精准线上线下宣传方案。例如,本研究的案例学校显现出在县城中学就读学生更偏爱师范类、城镇生源偏爱考研的特点,这就要求根据不同性质的中学设计不同的宣讲策略,见表2。
在填报期,学生根据高考成绩选择学校和专业的意向已相对清晰,关注点更加集中在个性化需求。根据用户画像进行用户需求预测,精准推送细化到专业、知名教师团队、教学科研平台、社团、竞赛等招生宣传“点”信息,减少“信息冗余”噪音。以用户画像为依据将学生引导到细分的同类考生交流微信群或者QQ群,增加社群的情感黏性、认同感和归属感。
通过用户画像,学生工作教师可以较为便捷地发现报考大致动机及其录取专业出入较大的学生,进行有针对性的生涯辅导。
四、优化建议和研究展望
用戶画像的优势依赖大数据,本研究只基于调查收集一所学校新生的数据,数据来源及数量具有较大的限制。后续研究可以跨院校跨机构、多平台特别是网络社交平台开展数据收集,实现地域和跨领域的数据融合,为教育主管部门、高校、中学师生及第三方平台提供更丰富的数据服务,更好地满足考生多样化需求,让考生家长收获更多新高考改革“红利”。
参考文献
[1]秦仲篪,庄穆妮,管慧,等.大数据视角下欧莱雅(中国)的用户画像分析[J].长沙大学学报,2018,32(5):44-49+55.
[2]ZHEN Y, SI Y, ZHANG D et al. A decision-making framework for precision marketing [J].Expert systems with applications,2015(7):3357-3367.
[3]王麗,谭凯波,黄云.用户画像在图书馆个性化服务应用中的问题及对策[J].数字图书馆论坛,2021(10):66-72.
[4]刘海鸥.国内外用户画像研究综述[J].情报理论与实践,2018(11):155-160.
Visual Analysis of Students’ School Choice Behavior under the Background of the New College Entrance Examination Reform: Taking M University as an Example
LIU Hua-qianga, LIU Jian-huab
(a.Department of Discipline Construction and Postgraduate Work, b. School of Mathematics and Statistics, Minnan Normal University, Zhangzhou, Fujian 363000, China)
Abstract: The new college entrance examination reform has forced universities to pay more attention to “users’ needs”. By collecting the data of the freshmen in a normal university, this study builds a visual model and finds that there are three kinds of “typical portraits” of freshmen with obvious differences in characteristics. Based on the “portraits”, we can formulate accurate recruitment and publicity measures for different groups and provide personalized services at different stages. To provide accurate information services according to the characteristics of the users has become a research hot subject and a consensus of the industry. The premise of accurate service is to analyze the characteristics of user groups in the market segments, grasp the motivation of school choice of the potential target groups, and better answer the questions of “who to publicize” and “what to publicize”. The innovation of the research lies in exploring the data analysis method for formulating specific school-based enrollment publicity policies based on the theoretical research on school choice behavior under the background of the new college entrance examination reform.
Key words: new college entrance examination reform; college-choice behavior; user profile; K-Means cluster
猜你喜欢
现代情报(2016年10期)2016-12-15
考试周刊(2016年84期)2016-11-11
现代经济信息(2016年24期)2016-11-09
课程教育研究·学法教法研究(2016年19期)2016-09-07
考试周刊(2016年54期)2016-07-18
电脑知识与技术(2016年7期)2016-05-19
课程教育研究·学法教法研究(2016年7期)2016-04-26
求知导刊(2016年8期)2016-04-21
化学教学(2015年11期)2015-12-19
