
基于尺寸不变特征转换向量的图像检索精度优化
2022-03-28 07:53:48朴林
河北北方学院学报(自然科学版) 2022年3期
朴 林
(辽宁民族师范高等专科学校,辽宁 沈阳 110032)
0 引 言
对于影像局部特征的检测,传统的尺度不变特征转换(scale-invariant feature transform,SIFT)向量检索法能够通过提取图像特征并将其转化为多组128维向量的方式,在空间尺度中进行极值点的搜索,并确定其尺度、位置、旋转不变量的相关数据。该方法在亮度变化、尺度缩放、旋转角度等方面保持固定,可以在一定程度上控制噪声干扰、仿声变换和视角变化,鲁棒性很强。虽然是图像检索中最为常用的方法,但在大数据背景下其固有的缺陷也逐渐显现出来,包括需要基于训练集以人工的低效方式确定vocabulary tree的高度M;进行建树和检索时,每个128维向量都必须与某个中心点的多个分支点完成距离的检测,耗时过长、效率过低;向量到达叶子节点后所获取的结果不完全与原向量相符,但仍被提取,极大地影响了检索精度。为此,本文提出了一种基于尺寸不变特征转换向量的图像检索精度优化方法,构建了新的树节点聚类法来完成建树,从测试集中提取出SIFT特征向量来创建树模型下的倒排文件,在检索过程中基于欧氏距离信息对SIFT特征向量进行统一处理,从而有效提高了图像特征检索的效率和精度。
1 聚类方法
对于影像特征检索常用的SIFT特征向量法,其聚类方法无法将多个近似特征向量聚合到同一个叶子节点上且存在分配错误的可能,即在检索和倒排文件的过程中存在所谓的“维数灾难”,所以使算法的精度受到很大的影响[3-4]。为了尽可能消除这些分配误差,本文所提出的方法将聚类与分类两个过程结合在一起,基于类半径以及聚类中心R与目标向量P之间的距离实现最终的聚类,在设定阙值后可以获取聚类数量,具体方式为
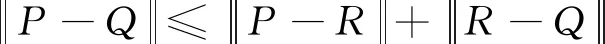
(1)
式中,Q代表从倒排文件中提取的任意向量。
匹配任意2个向量需要确定它们之间的距离,但创建倒排文件时并未将图片集中的SIFT特征向量保存于其中,所以不能直接搜索与目标向量相似的向量,需要通过式(1)保证近似向量同处某一范围之内,遍历全部被检索向量之后,包含大量相同ID号的即可判定为正确图片,由此可以获取类半径及分支节点的数量。
2 树模型建立
2.1 建树
建数是通过分类与系统聚类的方法将训练集中的全部特征向量构建成一组复杂的多维向量坐标的过程。首先,通过式(2)计算所有特征向量的平均向量:
(2)
然后以该向量坐标为聚合中心节点(具有标示符性质的根节点)求出训练集中的所有向量与它的间距:
(3)
对所有计算结果进行排序,设定合理的阙值,通过式(1)对这些向量进行分类。假设聚类数量为K,在中心点中保存与其相连的K个分支节点的数量,同时保存单个类与中心节点的最大距离,以此来大幅提高图像检索的效率。最后逐一检查单个分支节点与中心节点的间距以及与该分支节点对应的类的半径之和,如果小于某个设定的阙值,则该分支节点不再继续对这些类进行聚合,并且直接转换为叶子节点;如果大于阙值则继续迭代聚类,直到获取想要的结果。
通过这一方法,聚类过程不再受到vocabulary tree层数M与分支节点数量K的限制,所有训练集中的特征向量直接转化为任意高度和分支数量的树,由此在很大程度上消除了维数过多所引起的检索误差,有效避免了SIFT向量的“维数灾难”。
2.2 创建倒排文件
构建分层多维向量坐标后,将测试集中的所有特征向量作为叶子节点,即可完成倒排文件的创建。由树节点所构建的向量坐标具有一定的指向性,当前节点的一个SIFT向量运动到某一个分支节点后,进行一次欧式距离的计算即可选择下一个目标分支节点,最终停留在叶子节点。由此每个向量都被单独分配了一条按照节点指向从中心节点到达叶子节点的路径,这条路径的距离是最短的。到达叶子节点后,向量计算其与叶子节点中心向量之间的间距,如果大于设定的阙值,则直接舍弃该节点,不再将其列入移动目标分支节点的范围。此外,阙值需要结合训练集的具体情况来确定。
在使用该方法对海量图片模型进行检索时,并不保存到达叶子节点的向量,而是保存其ID编号,以便节省存储空间,如此一来叶子节点中便存在一个维数与测试集包含的图片数量相等的数组,图片向量终点即为叶子节点的向量数量,通过其中一个维度来表示,具体形式如图1所示。
图1中的Ii,j为包含在第i个叶子节点中的第j张图片的特征向量的数量。倒排文件的整体排列形式如图2所示。
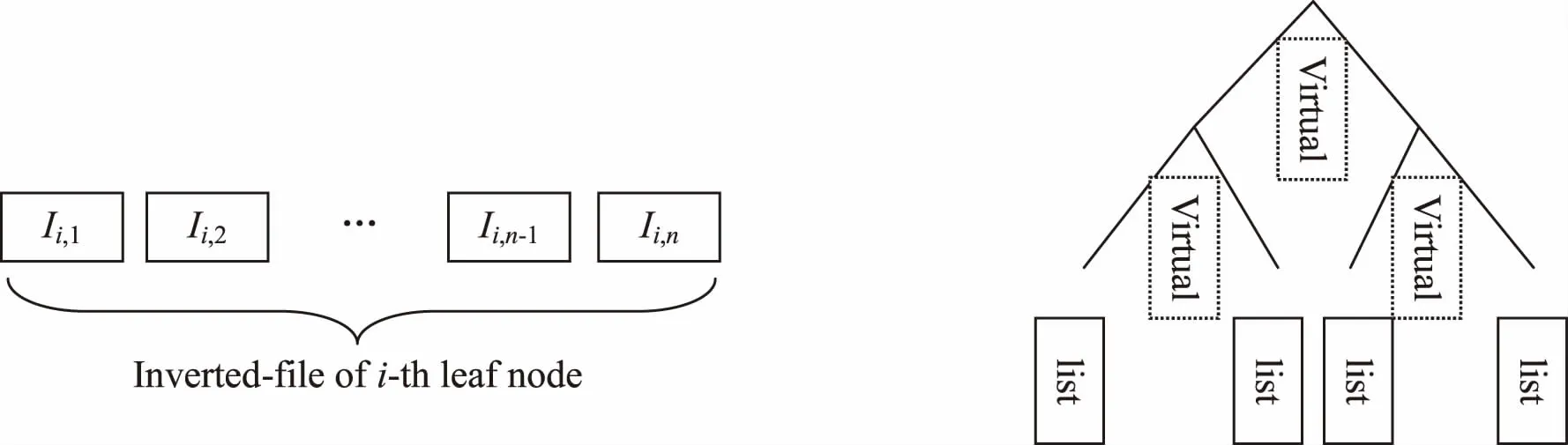
图1 倒排文件的具体形式 图2 通过建树所得到的倒排文件
为了得到更高的检索精度,本文在进行图像检索的过程中借鉴了文本检索中的TF-IDF(term frequency inverse document frequency)检索机制。由于图片到SIFT特征向量的转换,使图像检索的过程变换为在规模庞大的向量集中搜索与目标向量近似的那些向量,即利用向量来检索向量,这本来属于文本检索的范畴,通过这种方式能够实现检索结果明显得到改善。引入TF-IDF检索机制能够赋予叶子节点一个权值,如果某个叶子节点包含对应图片库中全部图片的向量,那么它就不适合参与图片的区分,因为在这种情况下每个节点都能够与这个叶子节点产生联系,所以检索过程中无法获取足够的图像匹配信息。反之,如果某个叶子节点仅包含一个或少数几个近似的图片向量,则当向量取最短路径达到该叶子节点时,就代表该向量所对应的图片与其所到达叶子节点内倒排文件所对应的图片符合匹配的条件,也就是说这个叶子节点能够在检索过程中用以表示特定的一张或几张近似的图片。同时,取最短路径到达节点的向量仅存在于近似图片之中,所以可以为该叶子节点赋予一个较大的权值,如此就能使该叶子节点的作用充分发挥出来。
图像检索是一个特殊的检索过程,对倒排文件的检索也需要满足一些特殊条件,仅通过TF-IDF机制是无法实现检索的,其对文本进行检索的方式为
w=T×I
(4)
式中,w代表叶子节点被赋予的权值,T代表特定单词在某篇文章中的词频TF,I代表特定单词在所有文章中出现的情况IDF。本文通过式(5)为叶子节点赋予权值:
w=I
(5)
理论上,叶子节点中所包含向量能够对应的图片id越多,其被赋予的权值越小,假设:
(6)
式中,N代表测试集中所包含的图片总数,m代表倒排文件向量中所包含的数组的维数,Ii,j代表包含在第i个叶子节点中的第j张图片的SIFT特征向量的数量,函数f(Ii,j)的取值方式为
(7)
这是一个在倒排文件数组中搜索通过该叶子节点可能发现的图片的过程。利用式(5)、(6)、(7)能够获取叶子节点的权值,由此通过该权值与向量中的数组即可构建倒排文件。
3 图像检索
将特定的图片转换为SIFT特征向量后,就可以在树中搜索相似度最高的向量来判断图片之间的匹配程度。取该图片中所有特征向量与中心节点的距离,节点中保存有其与所有分支节点的距离信息,所以可以在最短路径中找到下一个节点,即树中的某个分支节点,这是本文提出的提高搜索效率的基本方法原理。树的高度为M,平均分支数量为K,计算2个向量间欧式距离所需的时间为t,传统算法的检索时间为
T=M×(K-1)×t
(8)
而本算法消耗时间为T=Mt,这就意味着,通过本文提出的方法进行图像检索所消耗的时长仅为传统方法的1/(K-1),而利用节省的时间可以在其它方面进一步提高检索的精度。
在每个向量均已获取到达叶子节点最短路径的条件下,从倒排文件中提取信息用以构造检索图片向量和测试集中图片的向量,检索图片向量的具体形式为
S=(w1×n1,w2×n2,…,wn×nn)
(9)
由式(9)可见图片向量的终点为叶子节点的数量与其各自权值的乘积。测试图片向量的具体形式为
Dj=(w1×I1,j,w2×I2,j,…,wn×In,j)
(10)
传统算法基于向量的单一化来计算图片的匹配度,即
(11)
根据实际的使用经验,在该算法下,由于不同的图像包含不同数目的信息量,包含信息量较多的图片会经历多次检索,这在很大程度上影响了算法的精度,所以本文对算法进行了优化,即
(12)
式中,N代表检索图片中包含的特征向量的总数。由此可按照匹配度对获取的图片进行排序。
4 实验与结果分析
从Ukbench数据集中选取2 500组不同的图像,每4张拍摄相同事物的图片为一个图像组,但每张图片的角度、光线、分辨率和背景噪音各不相同,因此互为相似图片。用本文提出的方法对与目标图片相似的图片进行检索。图片的检索精度由式(13)进行计算:
(13)
式(13)表示检索结果中排名靠前的10张图片中,存在ni张相似图片。从图片库中任意选取不同数量的图片组建测试集,分别用L1-norm、L2-norm和本文方法在统一化的unit-norm标准下进行测试,具体结果如图3所示。
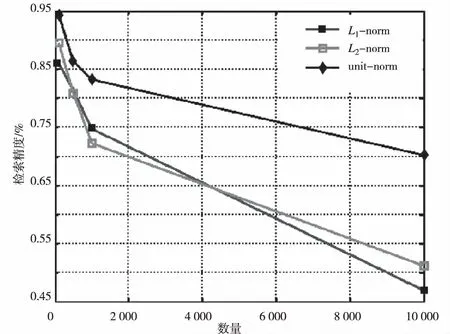
图3 不同标准下的测试结果
图3中的横轴为每次测试选取的图片数量,纵轴为检索精度,显而易见,在本文所提出算法的统一化标准下能够获得更高的图片检索精度。
同时,在unit-norm标准下,通过舍弃与叶子节点间距最大的SIFT向量的方法进行检索,得到的检索精度如图4所示。
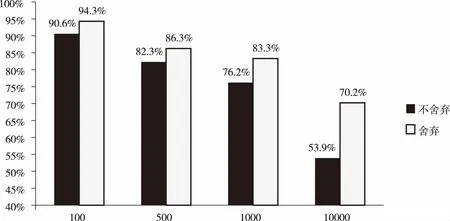
图4 舍弃最大间距SIFT向量的检索精度
为了验证本文方法的优越性,选用文献[6]的方法进行检索精度比对,比对结果如下:
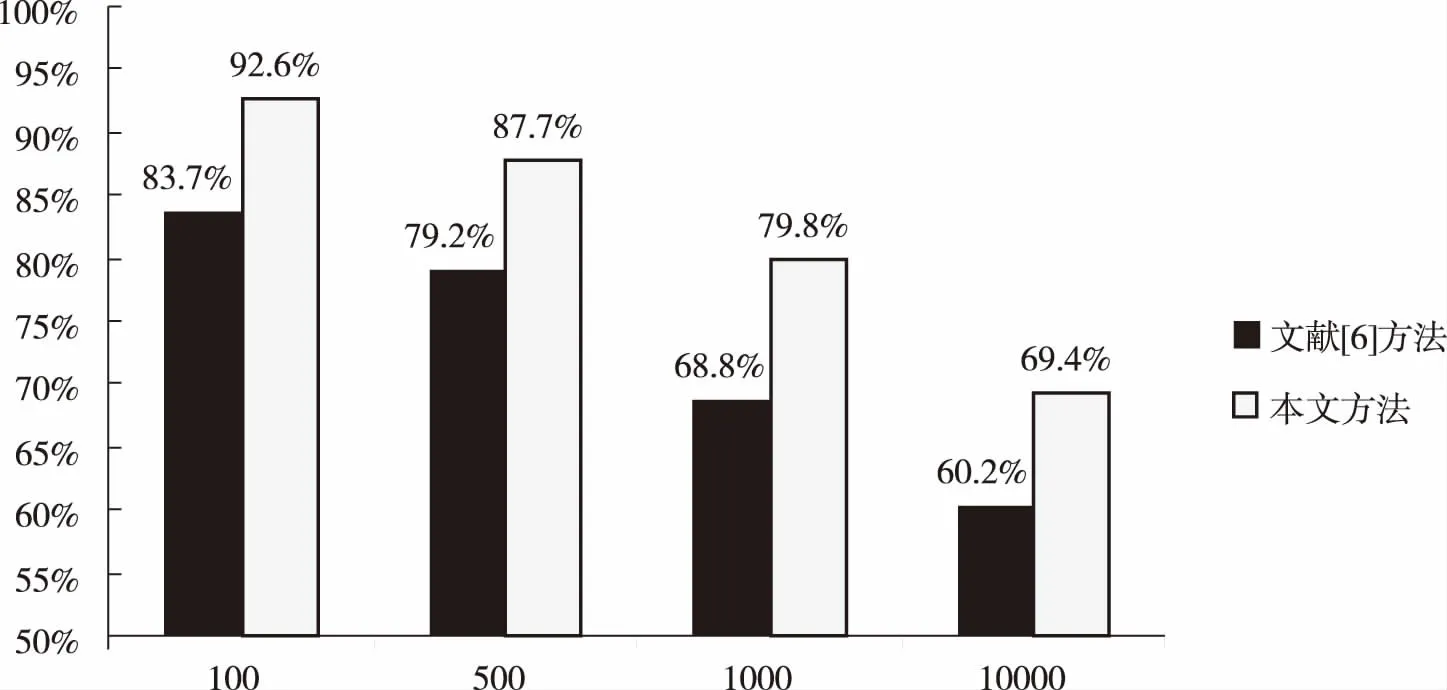
图5 检索精度对比
对以上3项测试所进行分析,可以得到以下结果:
1)在由图片转换为SIFT向量的过程中会产生一定的误差,在图片数量足够多的情况下这种误差不易被发现,由于SIFT向量的规模过于庞大,可能导致错误的分配结果,使向量误入非设定路径上的分支节点,由这种情况所引起的误差本文提出的方法已通过欧式距离的计算最大限度地进行控制;
2)图片生成地SIFT向量数量会对检索精度产生一定的影响,虽然SIFT向量过少也可能导致误差的产生,但统一化方法有效消除了海量SIFT向量引起的误差,两者相比本文提出方法的误差要小很多,所以该方法对最终检索结果的误差控制是相对有效的;
3)相对于常用的文献基于图像色彩特征的检索方法而言,本文方法的检索精度更高。
5 结 论
为了解决海量图片数据检索过程中存在的精度较低的问题,本文提出了一种基于尺寸不变特征转换向量的图像检索精度优化方法,在传统SIFT特征向量检索方法的基础上,通过聚、分类的结合设计了更为合理的聚类方式,利用计算得到的欧式距离对SIFT特征向量进行统一化的处理,最终采取倒排文件的方式有效控制了图片检索的误差。通过以上图像检索的优化方式,形成以下结论:
1)适当解除对vocabulary tree的高度M和分支数量K的限制,同时依据训练集的具体情况自行决定分类的数量,能够明显提高图像检索的效率与精度;
2)可以根据目标向量与叶子节点中心向量的间距有选择性地剔除一部分已经产生偏差的SIFT特征向量;
3)可以采用新的匹配机制对向量所对应的图片与叶子节点所对应的图片进行相似度匹配,以此来大幅降低大数据条件下的SIFT误差。
测试结果表明,本文所提出的方法具有较高的检索效率和精度,适用于图片局部特征的检索。但是,由于研究时间较短、理论研究不够透彻等原因,本次研究还存在一些不足之处,例如尚未完全解决vocabulary tree分支数量会产生干扰的问题,仍需以人工的方式进行确定。在今后的研究中,将继续探索自动确定分支数量的合理方法,以进一步提高图像检索的精度。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
学生天地(2019年28期)2019-08-25 08:50:54
小学生导刊(2018年34期)2018-12-18 01:53:26
小学生优秀作文(趣味阅读)(2018年6期)2018-09-19 06:37:38
许昌学院学报(2018年4期)2018-05-02 12:27:37
数学物理学报(2018年1期)2018-03-26 08:16:36
中华建设(2017年1期)2017-06-07 02:56:14
海峡姐妹(2016年1期)2016-02-27 15:15:13
小学生时代·大嘴英语(2015年10期)2015-11-26 09:29:42
