
基于信息融合的企业会计信息舞弊风险识别方法
2022-03-28 07:53刘倩倩
河北北方学院学报(自然科学版) 2022年3期
刘 倩 倩
(徽商职业学院 会计系,安徽 合肥 231299)
0 引 言
三公原则既是企业有效运行的重要原则也是经济市场规范的集中表现,该原则实施的基础是企业会计审计信息披露的规范化[1-2]。近几年,很多企业被发现存在会计审计信息作假舞弊等行为,该行为不仅违背了市场经济运行规则,使企业信誉度下降,也为企业长期发展埋下不小隐患,为此众多学者开始研究识别企业审计信息舞弊方法,其中以严良等人和杨贵军等人所研究的DE-SVM资源型财务风险识别方法[3-4]和Benford-Logistic模型风险识别方法应用最为广泛。严良等人研究方法利用成分分析方法和支持向量机方式完成企业财务数据识别,但该方法受支持向量机收敛性影响,其识别结果不佳;杨贵军等人研究的方法通过构建回归模型和风险因子,分析会计审计信息之间的关联性完成识别过程,受风险因子选取方式影响,该方法在预测准确度上不够精确。
信息融合又称数据融合,是将不同类型和不同复杂程度的信息融合后,从融合后的数据信息内识别有效信息的信息处理方式,该方式具有容错性,在交通、教育等多个领域中具有重要作用[5]。为提升企业会计信息舞弊风险识别的精确度,本文结合信息融合方式研究基于信息融合的企业会计信息舞弊风险识别方法。
1 基于信息融合的企业会计信息舞弊风险识别研究
1.1 会计审计信息融合方法
企业审计的资源环境随着当前社会发展逐渐体现出多元化异构特征,多源会计审计信息融合是企业审计环境的基本要求[6],且企业会计信息舞弊识别的基础是获取精准的会计审计信息,基于信息融合充分融合不同数据特征,并利用融合后的会计审计信息展开精准舞弊风险识别。本文利用先验分布方式实现会计审计信息融合,在融合的过程中使用K-L信息距离算法计算审计信息权重。
1.1.1 先验分布的会计审计信息融合方法
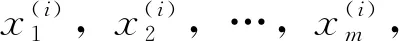
(1)
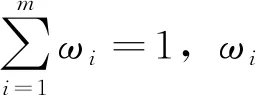
令X表示整体会计审计信息样本,则该信息样本内的现场样本由x=(x1,x2,…,xn)表示,验后的信息分布表达公式如下:
(2)
上述公式中,φ表示参数空间内随机参数。
令πi(φ|x)表示随机审计信息源i验后分布,其计算公式如下:
(3)
将公式(3)结果输入到公式(2)内,则有
(4)
假设λi表示审计信息源i分布占所有边际密度比例,该比例计算公式如下:
(5)
将审计信息源i分布占所有边际密度比例引入到验后的信息分布计算公式内,则有:
(6)
上述公式中,αi=λiωi表示后验分布加权和。
通过上述步骤,可知审计信息融合前后的加权会影响其融合权值与边际密度比例,因此合理选取融合权值是会计审计信息融合重要步骤[7-8]。
1.1.2 基于K-L信息距离的融合权重计算
K-L信息距离又称Kullback-Leibler信息距离,利用该方法可判定审计信息融合后的分布概率的接近程度[9]。
假设(Ω,F)表示度量空间,P、A为该度量空间内的概率分布,则信息距离表达公式如下:
(7)

假设先验分布为π={π1,π2,…,πn},f为审计信息子样分布,则该审计信息子样分布和第i个先验分布的信息距离由Ii(f,πi)表示,各个概率之间的差异率Di的表达公式如下:
(8)
上述公式中,差异率Di表示第i个先验分布概率和子样分布概率在整体差异内的占比,在会计审计信息融合过程中表达分布对先验和子样分布的贡献度[10],因此概率分布的融合权重表达公式如下:
(9)
上述公式中,n表示先验分布数量,将公式(9)计算结果代入到公式(1)内,获取融合后的会计审计信息分布结果[11]。
1.2 会计信息舞弊风险识别模型建立
本文利用混沌神经网络构建会计信息舞弊风险识别模型,该模型信息舞弊风险识别流程如图1所示。
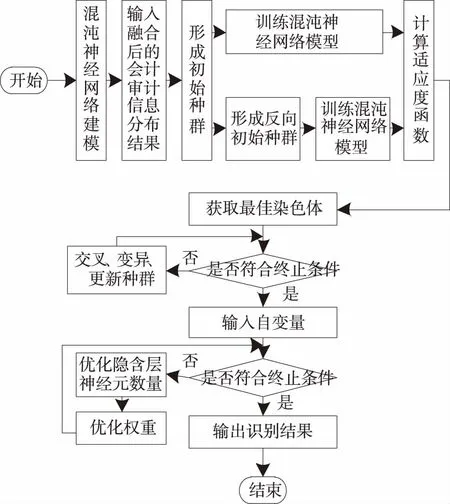
图1 会计信息舞弊风险识别模型识别流程
上述模型识别流程:将会计审计信息融合方法获取的审计信息分布结果π(φ)作为模型的输入,利用遗传算法形成初始种群后形成反向初始种群,通过迭代计算适应度函数后,选择最佳染色体,经过判断是否符合终止条件后,输出最终识别结果。具体会计信息舞弊风险识别过程如下:
第一步,种群初始化。

(10)
通过反向遗传算法计算输入数值,将搜索空间内的数据投射到编码空间内[12],且所有数据均存在一个染色体,假设n表示维度,S=(s1,s2,…,sn)表示该维度空间内的染色体,则有
si∈[ai,bi]∀i∈{1,2,…,n}
(11)
(12)
其中公式(11)为正向染色体,公式(12)为反向染色体。
第二步,计算会计舞弊信息遗传概率以及适应度。
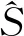
(13)
所有染色体和单独染色体以变异的方式遗传至下一代的概率如下:
(14)
上述公式中,fmax、favg表示搜索空间最大适应度数值、平均适应度数值,f表示单独适应度函数,z表示空间内随机参数。
在遗传算法原理内,适应度数值越大其遗传的概率越大[13],则适应度表达公式如下:
(15)
第三步,获取隐含层神经元数量。
为了提升会计审计信息提取效果,需计算隐含层最优神经元数量,其计算公式如下:
(16)
上述公式中,n表示输入变量数量。
第四步:更新权值。
假设β表示混沌神经网络的学习速率,学习速率数值对权值修改的作用和模型学习速度成正比,学习速率表达公式如下:
(17)
公式(17)中,βmax表示会计审计信息最大学习速率,βmin表示会计审计信息最小学习速率。tmax、t分别表示最大迭代次数和现在迭代次数。
权值更新表达公式如下:
ωij(t+1)=ωij(t)+βDjxi+[ωij(t)-ωij(t-1)]
(18)
Vj(t+1)=Vj(t)+βDjQj+[Vj(t)-Vj(t-1)]
(19)
上述公式中,ωij、Vj分别表示隐含层和输出层权值,Qj表示隐含层的输出数值。
令Qinj、Qj表示隐含层的输入和输出,Yin、Yj表示输出层的输入与输出,计算公式如下:
(20)
(21)
(22)
(23)
通过上述公式可获取混沌神经网络的输出数值,经过该网络模型数次迭代,模型最终输出会计信息舞弊风险识别信息[15]。
2 实验分析
以某上市企业2010年至2018年会计审计信息作为实验对象,使用本文方法对其展开风险识别,为更加清晰展示本文方法实际应用效果,分别使用文献[3]和文献[4]方法同时进行实验。其中文献[3]方法表示DE-SVM资源型企业财务风险识别方法,文献[4]方法表示Benford-Logistic模型企业财务风险识别方法。
会计信息舞弊风险识别的权重选择是舞弊风险识别关键所在,以适应度作为衡量权重选取优劣的指标,以该企业9 000个会计审计信息作为实验对象,测试3种方法风险识别权重选取能力,结果如图2所示。
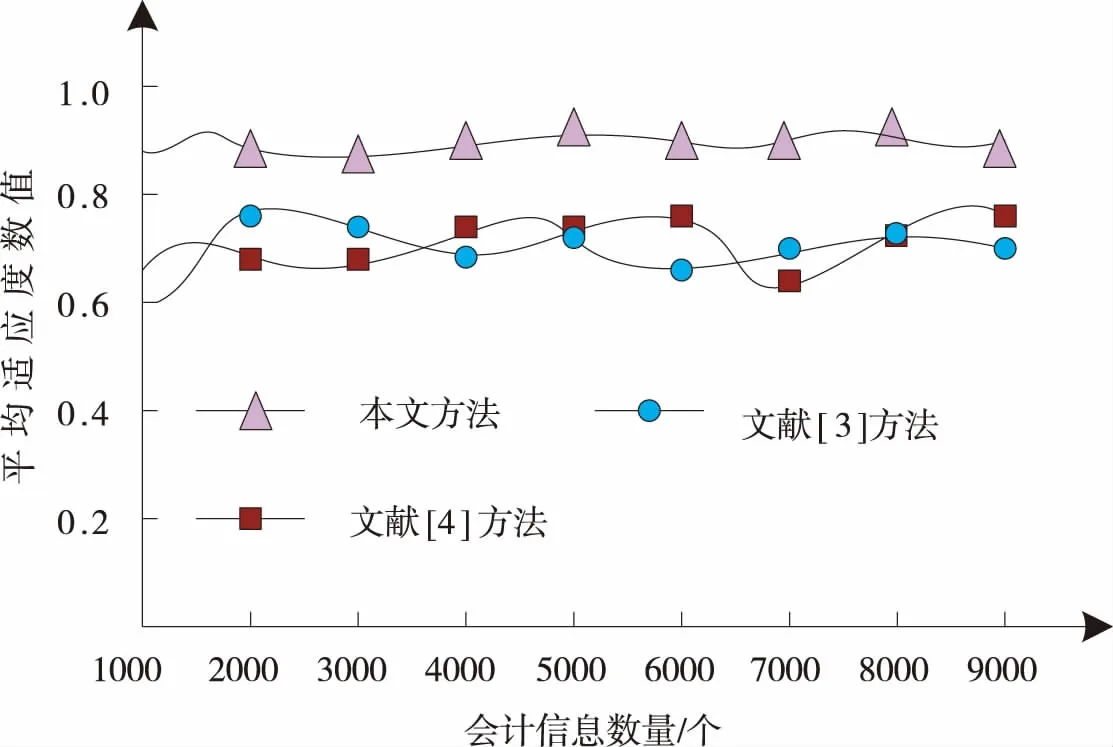
图2 3种方法选取权重能力测试结果
分析图2可知,随着会计信息数量的增加,3种方法选取权重的平均适应度整体呈现平缓趋势,当数据量在1 000~2 000个时,3种方法的平均适应度数值均出现上升波动趋势,其原因在于计算过程中如果迭代次数少就无法获取其平均适应度,经过多次迭代,平均适应度数值逐渐趋于稳定,随着会计信息数量的增加,本文方法的平均适应度数值始终保持在0.8~0.9,而文献[3]和文献[4]方法的平均适应度数值始终在0.6~0.8波动,表明二者方法选取的识别权重不够准确,综合分析可知,本文方法识别的平均适应度数值较高,且稳定,选取权重能力较好。
以该企业2010年至2018年企业会计信息作为实验对象,使用1~5标注法对识别结果进行标注,1~5分别表示风险极高、风险较高、风险一般、较安全、安全,测试3种方法的舞弊风险识别能力,结果见表1。

表1 3种方法舞弊风险识别能力结果
分析表1可知,文献[3]和文献[4]方法在识别该企业会计信息是否存在舞弊风险过程中,均存在2次错误,实际风险标注数值为3,表明此时该企业存在的会计信息舞弊的风险为一般。但文献[3]方法和文献[4]方法所识别的风险等级为安全,当该企业会计信息舞弊的实际风险为风险极高时,文献[4]方法所识别的风险为风险较高,可知上述两种方法风险识别能力较差,无法诠释企业会计信息现状,造成企业风险意识较低,无法保障企业长期发展安全。而本文方法识别的企业风险与实际数值相同,可见本文方法风险识别能力卓越。
通过计算3种方法的假正率、真正率并绘制ROC曲线,测试3种方法的泛化性能,结果如图3所示。
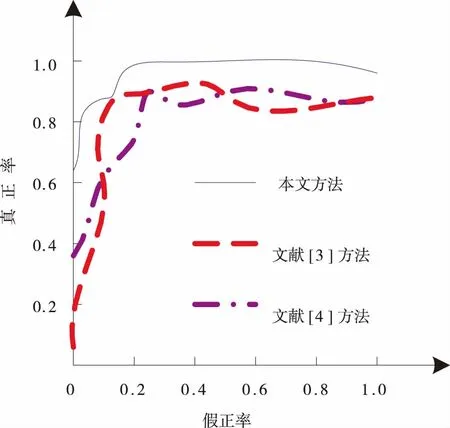
图3 三种方法泛化性能
分析图3可知,本文方法的ROC曲线下面积较大且真正率、假正率趋近于1,而文献[3]方法和文献[4]方法的ROC曲线波动较大,其下面积较本文方法少,由此可知,本文方法的识别泛化能力较高。
4 结 论
本文利用信息融合方法对企业会计信息舞弊风险识别进行研究。该方法通过融合企业会计信息并构建识别模型完成企业会计信息舞弊风险识别,经过多次验证,本文方法的适应度数值始终保持在0.8~0.9,权重选取能力较强;风险识别等级与实际等级相同,识别能力卓越;ROC曲线下面积较大,泛化能力强。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
大众投资指南(2021年23期)2021-12-06
中国市场(2021年34期)2021-08-29
活力(2021年6期)2021-08-05
现代商贸工业(2020年24期)2020-11-26
消费导刊(2017年24期)2018-01-31
当代旅游(2016年10期)2017-04-17
现代商贸工业(2016年35期)2016-04-09
人间(2015年19期)2016-01-04
财经理论与实践(2015年2期)2015-04-16
