
基于调度下令的录音自动识别方法及关键技术研究
2022-03-28 08:31季铮铮周红杰谈叶月
自动化与仪表 2022年3期
傅 靖,季铮铮,周红杰,谈叶月
(1.国网南通供电公司,南通226006;2.江苏电力信息技术有限公司,南京210000)
近年来大数据技术的出现,更多的公司企业适应企业资源计划系统,实现了企业信息的整合,产生了数据共享服务,通过汇总的信息进行业务流程的分类[1]。同时语音识别技术在企业中的应用场景更加广泛,能够将声音转换为其它形式,为数字化办公提供了便利。然而当前企业工作中仍需要个人的主观判断和多种软件的交互,工作环境存在的大量噪声声音嘈杂,单一模式下的语音识别不能满足办公需求[2]。
针对上述存在的问题,文献[3]系统提出应用DNN 和HMM 结合的方法,在大词汇量连续语音识别的性能得到了进步,能够获取更长的音频时序信息,且降低了计算量;文献[4]系统使用双向LSTM 建模,考虑到前向与反向时序信息的影响,使系统具有更好的鲁棒性。但网络结构更加复杂,对具有长依赖关系的语音信号识别效果不好;文献[5]系统中采用长短时记忆网络建立语音模型,能够对有上下文联系的音频信息更好地建模,提高了语音识别能力。
1 基于RPA 接口的录音自动识别调度下令系统
本研究系统应用机器人流程自动化技术(robotic process automation,RPA),利用和融合现有各种技术,实现企业业务流程自动化,并且可以与多个系统进行交互,执行非常规任务[6]。系统使用的主流的RPA开发工具(poupular RPA development tools,PRDT)为UiPath,其中UiPath 是一种基于流程图的可视化流程工具,提供标准或自定义的工作组件。UiPath可以操作VMware 等虚拟机,也可以操作本地计算机。系统架构如图1所示。

图1 基于RPA 接口的录音自动识别调度下令系统架构Fig.1 System architecture of recording automatic identification and dispatch ordering based on RPA interface
本研究系统分为开发层、RPA 服务层和应用层。开发层主要负责程序的设计;RPA 服务层主要负责license 代理、日志收集和程序执行等任务;应用层主要完成调度下令、用户授权管理、工作流授权管理、语音识别等功能[7]。UiPath 开发平台提供了便捷的调度模块,执行任务前使用调试工具设置断点,逐步监视项目的执行步骤、数据参数和运行状态,并且能够调整调试速度,通过日志查看相关的项目执行情况。应用层使用Orchestator 服务器,具有特定的管理界面,能够对RPA 服务层进行机器人的添加、删除和监控,并且管理用户、进程和令牌,有效进行监控和读写log日志文件等操作,在schedule 计划任务中设定时间和执行次数控制机器人执行自动化过程。RPA 服务层具有ServiceHost,Executor 和Agent三个组件[8-9],设置每个监视器的DPI,Agent 能够在系统窗口显示机器人所在环境中的执行工程包。
2 关键技术分析
2.1 基于注意力机制的AVSR 双模态语音识别模型
传统的语音识别模型不能记录时间周期较长的相关信息,处理音频的长度有限,目标词只与前面N个词相关,目标词的增加将带来数据量的急速增长。本研究提出一种基于注意力AVSR 机制的模型,使用注意力机制对特征进行前期和后期融合,解决了音频速率不匹配和信息长度不相同带来的融合问题。对原始的音频信号先要进行预处理再输入到AVSR 双模态语音识别模型中[10],语音信号预处理流程如图2所示。
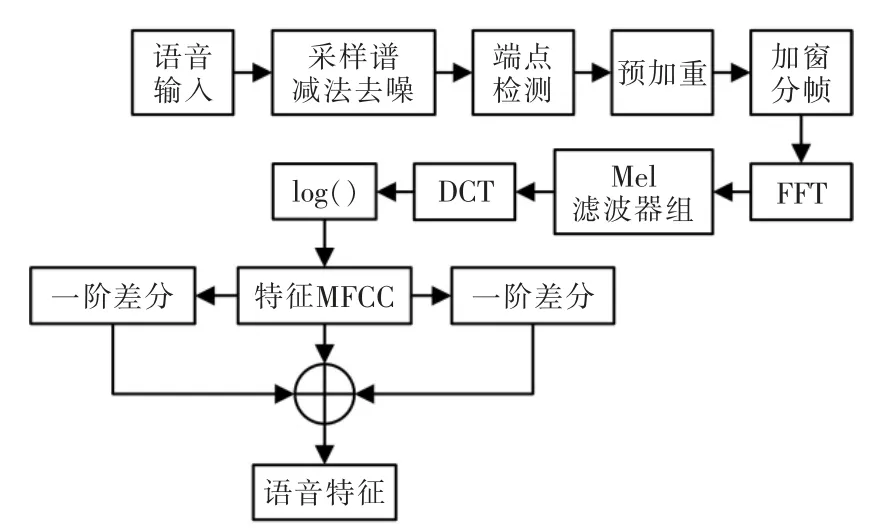
图2 语音信号预处理流程Fig.2 Voice signal preprocessing flow chart
原始音频信号首先进行采样,得到符合需求的数据,然后进行谱减法去噪。原始语音谱减去噪声谱,再变换到时域,就得到了去噪后的语音,可表示为
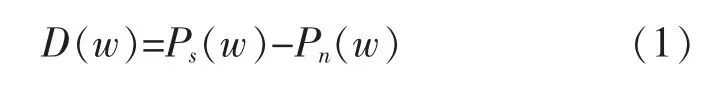
式中:Ps(w)表示原语音频谱;Pn(w)表示噪声频谱;D(w)表示差值频谱[11]。当实际噪声大于估计噪声时进行减法操作,会出现残余噪声。本研究对谱减法进行了改进,可表示为
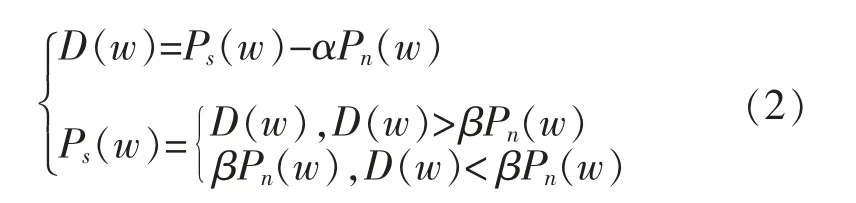
式中:α 表示减法因子;β 表示阈值参数。改进后的谱减法能够去除原始音频信号中的更多噪声,残留噪声减少[12]。引入阈值参数,将小于βPn(w)的数都统一设置为这个阈值,减小了残余噪声峰值差距。然后进行音频信号的编解码操作,音频编解码模型结构如图3所示。

图3 音频编解码模型结构Fig.3 Audio codec model structure
模型输入的是音频特征序列{a1,a2,a3,…,an},经过多次激活函数的操作后,数据分布可能更加分散,并且发布范围越来越大,导致收敛缓慢。在激活函数之前减少分散性,可表示为

式中:xi表示输入的一批数据;φ,β 表示网络学习参数,用来进行尺度变换和平移,保持网络的非线性能力。对音频编码中输入序列经过两层GRU 的非线性变换,得到每个时刻维数相同的状态向量组成一个集合,可表示为
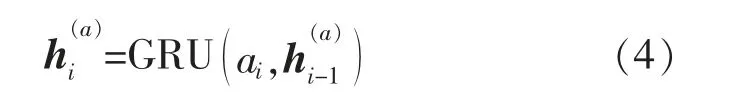
式中:ai表示输入特征序列;表示状态向量。得到集合后,每一时刻的音频状态向量进行一个注意机制计算来更新状态向量,更新过程可表示为

式中:T 表示向量的转置;u表示归一化参数。通过注意机制,实现了音频信号特征的前期融合,在音频缺失和噪声污染严重的情况下辅助修正音频特征。音频双模态语音识别框架如图4所示。
在模型的解码阶段使用两个独立的注意力机制,用于视修正后的音频特征,经过注意力机制后再进行特征向量的拼接融合,实现后期融合共同决定最终的结果。对语音识别模型进行优化,可表示为

式中:θ 表示模型的权重和偏差;η 表示学习率;y表示实际值;y¯表示模型的预测值;J表示目标函数。将AVSR 双模态语音识别模型的网络结构设定为2 层大小为128 的GRU 编码和单层128 单元的GRU解码,在测试解码时使用集束搜索。首先对音频质量评估音频信号的信噪比SNR,可表示为
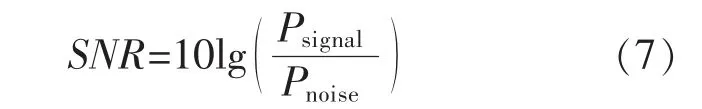
式中:Psignal表示信号功率;Pnoise表示噪声功率。SNR越大说明音频信号中的噪声越少,音频信号的质量越高,选择SNR<10 dB 的音频信号进行信号特征的前期融合。
2.2 基于雾计算动态优先级的实时任务调度下令方法
本研究系统使用雾计算在网络边缘提供分布式基础架构,实现低延迟访问和应用程序的请求快速响应。基于动态优先级的任务调度下令时序图如图5所示。

图5 基于动态优先级的任务调度下令时序图Fig.5 Sequence diagram of task scheduling order based on dynamic priority
任务调度下令模型中任务的向量可表示为
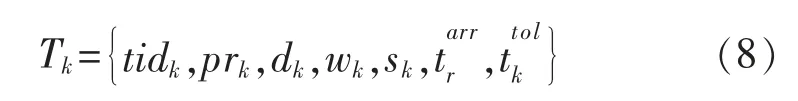
式中:tidk表示唯一标识;prk表示任务的固定优先级;dk表示任务数据量;wk表示任务需要的CPU 周期;sk表示任务需要的存储空间;表示任务到达雾计算的时间;表示最大容忍时延。雾计算层中的雾节点的集合为{Fog1,Fog2,Fog3,…,Fogn},雾节点Fogn的向量可表示为
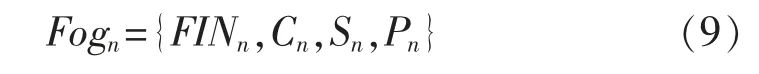
式中:FINn表示雾节点的唯一标识;Cn表示计算频率;Sn表示可用存储容量;Pn表示传输发射功率。为提高任务的执行完成率,将时间属性作为任务优先级的指标,任务在雾节点Fogn中的执行紧迫度可表示为

式中:p,q表示权重参数;prmax表示任务的最高优先级。任务处理流程如图6所示。
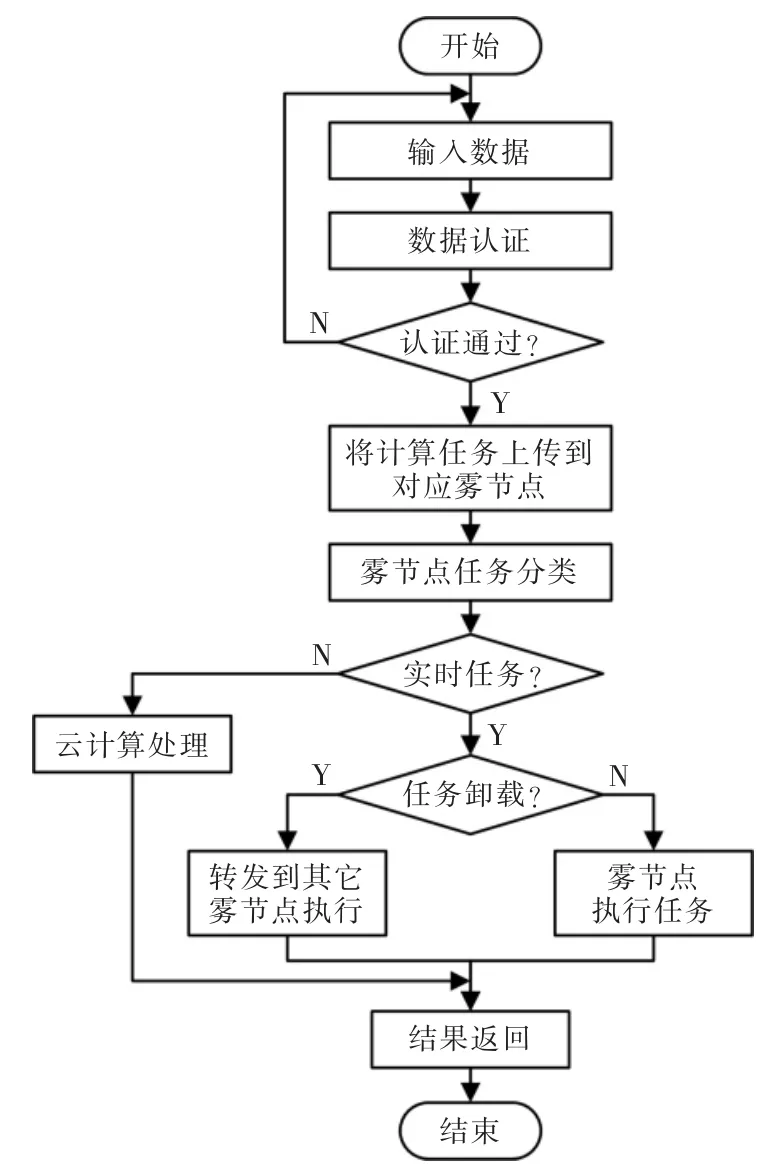
图6 任务处理流程Fig.6 Task processing flow chart
设置任务卸载策略的执行间隔I,根据任务规模动态调整I,在执行第α 个任务卸载时,所有任务节点的等待队列中共有K个任务{T1,T2,T3,…,TK},每个任务所在的雾节点为{l1,l2,l3,…,lK},任务Tk在等待队列中的等待时间为。当雾节点接收到卸载决策后,会根据卸载决策将其等待任务进行重新分配。
3 应用测试
3.1 实验环境
为验证本研究录音自动识别调度下令系统的性能,分别使用文献[3]系统、文献[4]系统和本研究系统进行实验,对比3 种系统的调度下令完成时间和语音识别效果。实验环境在基于雾计算的网络架构下,设置6 台服务器作为雾节点。实验环境参数如表1所示。

表1 实验环境参数Tab.1 Experimental environment parameters
雾节点的计算能力设置为2 GHz~4 GHz 之间,可用莻空间在10 GB~20 GB 范围内,雾节点之间的传输速率为20 Mbps~40 Mbps。实验数据如表2所示。
表2 实验数据Tab.2 Experimental data
3.2 任务调度实验
本研究实验模拟一次系统计算任务调度下令,使用Matlab 作为实验平台,记录所有雾节点处理完成任务的时间。实验任务数设定为50~80,使用3 种系统进行人物调度,得到的任务调度完成时间如表3所示。

表3 任务调度完成时间Tab.3 Task scheduling completion time
为了更加直观地对比3 种系统的任务调度完成时间,将表3 中数据绘制成图像,如图7所示。

图7 任务调度完成时间Fig.7 Task scheduling completion time
由图7 可以看出,本研究系统充分利用了雾节点的性能参数和待卸载任务参数,充分考虑到了雾节点之间的性能差异,在任务数量较多的情况下仍能够保持较低的完成时间,任务数量高达80 时,任务调度完成时间为3086 ms;文献[3]系统的任务调度时间变化幅度较大,任务完成时间受限于处理最慢的雾节点完成所有任务的总时间,任务数较大时的调度完成时间小于任务数量较小时的调度完成时间,系统的最大调度完成时间可达到4372 ms;文献[4]系统的任务调度时间初始值较大,任务节点的处理实验高于其它系统,任务调度完成时间最高达到4410 ms。
3.3 语音识别实验
为验证3 种系统的语音识别模型的识别效果,使用MFCC 作为音频,再加入一阶差分作为音频特征添加语音的动态信息。并在音频特征信息汇总加入均值为0,方差为0.1 的高斯噪声,设置模型的训练次数为50~200 次,使用3 种系统对加入噪声的语音信号进行识别,得到3 种系统的识别率如图8所示,具体数据如表4所示。

表4 系统的语音信号识别率Tab.4 Speech signal recognition rate of system

图8 语音信号识别率Fig.8 Speech signal recognition rate
本研究系统对加入噪声后的语音信号的识别率达到于90%以上,训练次数在50 次时系统的识别率就高达90.7%,随着训练次数的增加,识别结果越来越准确,训练次数达到200 次时识别率高达99%;文献[3]系统的语音信号识别率最低为81.6%,训练次数达到170 次时识别率为88.2%,仍处于90%以下,达不到本研究系统训练50 次时的识别率;文献[4]系统训练50 次时的语音识别率为78.2%,训练次数达到200 次时的识别率为92%。
4 结语
本研究使用UiPath 开发,提出一种基于注意力机制的AVSR 双模态语音识别模型,通过注意力机制实现音频信号特征的前期融合,利用特征向量进行拼接融合解决音频速率不匹配问题,提高了模型的音频信号识别能力。提出一种基于动态优先级的任务调度下令方法,根据每个雾节点的计算能力和存储容量,将所有等待队列中的任务充分分配,并进行任务卸载。本研究仍存在一些不足之处还需进一步改进,非结构化的数据没有概念数据模型形式的限制,系统对于非结构化的数据处理能力不足,还需对系统的数据处理计算框架进行优化。
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
计算机测量与控制(2022年2期)2022-03-30
家庭影院技术(2021年1期)2021-03-19
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
人间(2015年8期)2016-01-09
