
基于预过滤结构的正则表达式硬件专用匹配引擎
2022-03-28 06:31李俊儒陈昆明
北京信息科技大学学报(自然科学版) 2022年1期
李俊儒,张 伟,2,陈昆明,徐 涛
(1.北京信息科技大学 计算机学院,北京 100101;2.北京信息科技大学 北京材料基因工程高精尖创新中心,北京 100101;3.清华大学 微处理器与片上系统技术研究中心,北京 100084)
0 引言
正则表达式具有灵活强大的表达能力,故在网络流量检测或者文本信息匹配等方面成为定义复杂特征的首要选择形式[1]。在硬件平台上实现正则表达式匹配加速,其体系结构一般分为两大类[2],一类是以硬件逻辑为中心的匹配架构,另一类是以存储为中心的匹配架构。
Scarpazza等[3]使用IBM的Cell宽带引擎,在16个并行的匹配流中,对于1 500状态数以下的小规模确定有穷自动机(DFA),性能达40 Gbit/s。Vasiliadis等[4]提出了第一个基于图形处理器(GPU)的检测模型Gnort,并在Snort规则集上进行1 000条纯字符串规则的测试,吞吐量达2.3 Gbit/s。Cascarano等[5]在GPU平台上提出基于非确定有穷自动机(NFA)的新型匹配引擎,在Snort534规则集上吞吐量为1.5 Gbit/s,在L7-filter规则集上吞吐量峰值为1.0 Gbit/s。张伟等[6]提出多正则表达式匹配硬件结构,设计了硬件四级流水线,并达到1.6~2 Gbit/s的匹配性能。麦涛涛等[7]在中低性能的FPGA(现场可编程门阵列)平台上实现了一种基于预定义类紧凑型自动机(Pre-Class CFA)的匹配系统,吞吐量为1.3 Gbit/s。高阳阳等[8]采用专用集成电路(ASIC)与FPGA的混合计算框架,同时使用软硬件协同的工作模式,匹配速度达280 Gbit/s。李玉璋等[9]在软硬件协同工作方式下,在FPGA上实现了50个通用并行匹配核,吞吐量达19.62 Gbps。Becher A等[10]在基于FPGA的Zynq SoC上实现了一个既具有匹配状态又具有不确定状态的DFA,可实现21.28 Gbit/s的正则表达式计算。
经过对硬件平台上实现正则表达式匹配加速方案的研究,发现正则表达式的硬件实现存在如下问题:第一,采用GPU、通用处理器等非专用硬件实现匹配,其系统性能无法和使用FPGA、ASIC这种专用硬件性能相比;第二,在专用硬件上采用电路逻辑描述正则表达式的方式,每次更新规则需要重新编写寄存器传输级别(RTL)代码,生成硬件电路,时间成本高,灵活度低,不适合频繁更新规则的应用场景。
为了解决上述问题,本文使用FPGA设计专用电路,并使用以存储为中心的匹配架构,更新规则库时只需要通过软件编译器重新编译规则,并通过PCIE将编译后的数据写入FPGA,规则编译时间短,理论上可实现各种规则的匹配,灵活度更高。
经过对提升正则表达式匹配性能方案的研究可知,预过滤是一种常用的提升匹配性能的方式。预过滤是根据规则中的特有模式串,迅速定位文本中数据的有效位置。如Snort和Suricata均使用AC算法对字符串进行精确检测[11-13];SpliteScreen使用FFBF的方式进行过滤,并使用FFBF-VERIFY验证FFBF结果[14];Hyperscan使用FDR高效多字符串匹配器,最后验证结果[11]。
但正则表达式的预过滤需存储规则中相关过滤信息,要占用额外存储空间;过滤后仍需对过滤结果进行验证,增加了整个预过滤时间。
为了解决上述问题,本文在FPGA平台上对预过滤结构进行存储优化,并将字符串匹配与自动机匹配结合,组成新型正则表达式匹配引擎,提升正则表达式匹配性能。
1 预过滤设计分析
提取正则表达式中的模式串是预过滤的前提。Intel的Hyperscan就提供了一种图分解方式,来提取不同表达中的模式串[9],并针对模式串对文本进行过滤,快速定位文本有效位置。图分解算法将正则表达式分解成了一系列不相交的字符串和有限自动机(FA)子集,在分解时对正则表达式的NFA状态图进行严格的结构分析,并识别出其中的字符串成分,Hyperscan的图分解算法能够保证提取出的字符串是正则表达式匹配的前提条件[9]。
对于任意一个正则表达式,都可表示为“字符串1+状态机1+字符串2+状态机2+……+字符串n+状态机n”的基本格式,即:
Regex→STR1+FA1+…+STRn+FAn
(1)
本文将(STR1&…& STRn)==NULL形式的正则表达式,称为“不带有字符串”的正则表达式(null_regex,NR);将能提取出字符串的正则表达式(string_regex,SR)分为两种,一种是STR1!=NULL,称为带有“前缀字符串”的正则表达式(prefix_regex,PR),另一种是STR1==NULL,称为带有“中缀字符串”的正则表达式(infix_regex,IR)。
SR中,采用组(G)来描述不同位置的字符串集合:Gn表示式(1)中STRn位置处字符串集合。各组间存在优先级:G1>G2>…>Gn,即对数据进行预过滤时必须满足Gn中模式串检测,才能进行Gn+1中模式串检测,且Gn模式串命中位置应处于Gn+1模式串命中位置之前。
按照上述定义,对Snort-PCREs中563条规则以及Hyperscan提供的2 483个合成有限复杂度规则进行测试,字符串组数分布如图1所示,前中缀字符串分布如图2所示,在以上测试集中字符串提取率为100%,故正则表达式中字符串的多组分类预过滤是必要的。
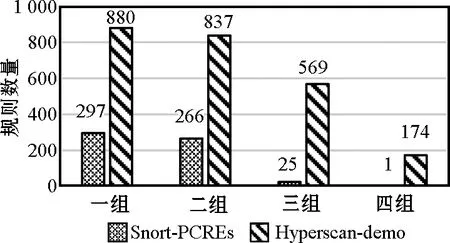
图1 字符串组数分布

图2 前中缀字符串分布
在PR中,可通过字符串匹配算法迅速定位字符串位置,再启动资源消耗更大的正则表达式匹配结构;而在IR中,无法定位有效文本位置,最简单的方式是从文本起始位置开始进行匹配,这种方式在正则表达式匹配结构中的处理时间消耗并未减少,但在一定程度上减少了正则表达式匹配结构启动次数。
为优化IR中匹配模块工作效率,有研究将中缀之后的文本顺序送入正向工作的子状态机,中缀之前的文本倒序送入逆向工作的子状态机;还有一些过滤方式关注规则的后缀字符串,通过定位后缀字符串,将文本倒序送入逆向状态机中进行匹配。
本文将PR和IR的处理流程统一化,只存储一套状态机转移信息,但是由于IR只能从文本起始位置开始匹配,这将会损失匹配性能。为提升IR匹配效率,本文引入首个自动机(式(1)中FA1)深度的概念,大幅度提升了IR的匹配性能。
一般来说,预过滤结构要保证结果的准确性,需要存储字符串精确信息。本文为减少存储开销,基于布隆分类器(Bloom filter,BF)实现预过滤结构,只存储BF中定长向量表,但这种做法会损失预过滤结果的准确性。为了解决这个问题,本文在匹配流程中设计了预过滤容错机制,保证了整体功能的正确性。
2 预过滤结构设计
2.1 Bloom filter结构原理
BF是一个基于哈希(Hash)函数的字符串匹配算法,采用一个位串表示并支持集合内元素的Hash查找,自1970年BF首次被提出,就被广泛应用于大数据集的表达和查找[15-16]。
BF的工作原理是定义一个m位的向量M,通过k个Hash函数对模式串集合P内的每个元素进行运算,得到k个值域为[0,m-1]的哈希值,将k个哈希值与M中的对应位置设置为1,若该位置已置1,则不做处理,这样就完成了对模式串集合P的初始化。查询时需要将字符串和k个哈希函数进行运算,若k个结果所对应M中的位置均为1,则表明在一定误判率的情况下,该字符串是属于模式串集合P的。
BF的优点是不需要进行字符串原数据的存储,只需要存储Hash值,故存储空间占用少,且不会出现漏判现象。但使用Hash函数运算将数据进行压缩存储,会出现字符串的误报,对于集合P中的n条字符串,误报率为
P=(1-e(-kn/m))k
(2)
2.2 k路并行多组向量表
由于正则表达式中提取出的多组模式串只存在逻辑上的先后关系,故本文提出使用多组向量表来存储Hash结果。多组向量表结构如图3所示。

图3 多组向量表结构
每组空间为mbit,模式串组数为g,那么空间占用(MEM)为m×gbit,每组发生误判的概率为pg=(1-e-kng/m)k。每组随机存取存储器(RAM)读写分两种方式:
1)深度为mbit、宽度为1 bit的RAM,读写时只能按照k个对应的地址逐个读写。
2)深度为1 bit、宽度为mbit的RAM,查询时可一次读取数据进行对比,但写入时需要读取RAM内原始数据,用Hash值与RAM内原数据进行按位或后写入RAM内。
但以上两种方式均不能做到并行读写。为提升初始化与查询的效率,本文提出k路并行的多组向量表存储结构,按Hash函数分组,每组对应独立的存储空间,实现k个Hash值并行读写,结构如图4所示。

图4 k路并行多组向量表
将每组空间k等分,等分后每组空间为m′=m/kbit,单个Hash_RAM空间为m′×gbit,每组的误报率为pg′=(1-e(-ng/m′))k,由于m′=m/k,故pg=pg′,即采用k路并行的多组向量表存储Hash值误报率不变。
以<字符串,组号>(
2.3 面向不定长模式串的共享内存过滤器组
传统设计中每个BF只能对单一长度的模式串进行识别,在进行多长度模式串匹配时,一般将不同长度BF组合成过滤器组来实现多种长度的模式串过滤。组内每个过滤器单独对应一个向量空间,故只能对相应长度的模式串进行过滤。由于正则表达式中模式串提取数量、长度等均不固定,而硬件电路固定后,每组存储资源是固定的,无法进行动态分配,当长度单一但数量较多的模式串组出现时,将导致硬件资源利用率下降,且过滤器性能变差。
为了解决上述问题,使得硬件结构能面对不同长度的模式串,本文提出使用共享内存的方式,对不同长度模式串的Hash结果进行存储。
在共享内存的过滤器组中,不同长度BF的计算结果不再单独存储,每个过滤器组对应一个向量表,组内所有长度过滤器均可以对该向量表进行操作,结构如图5所示。
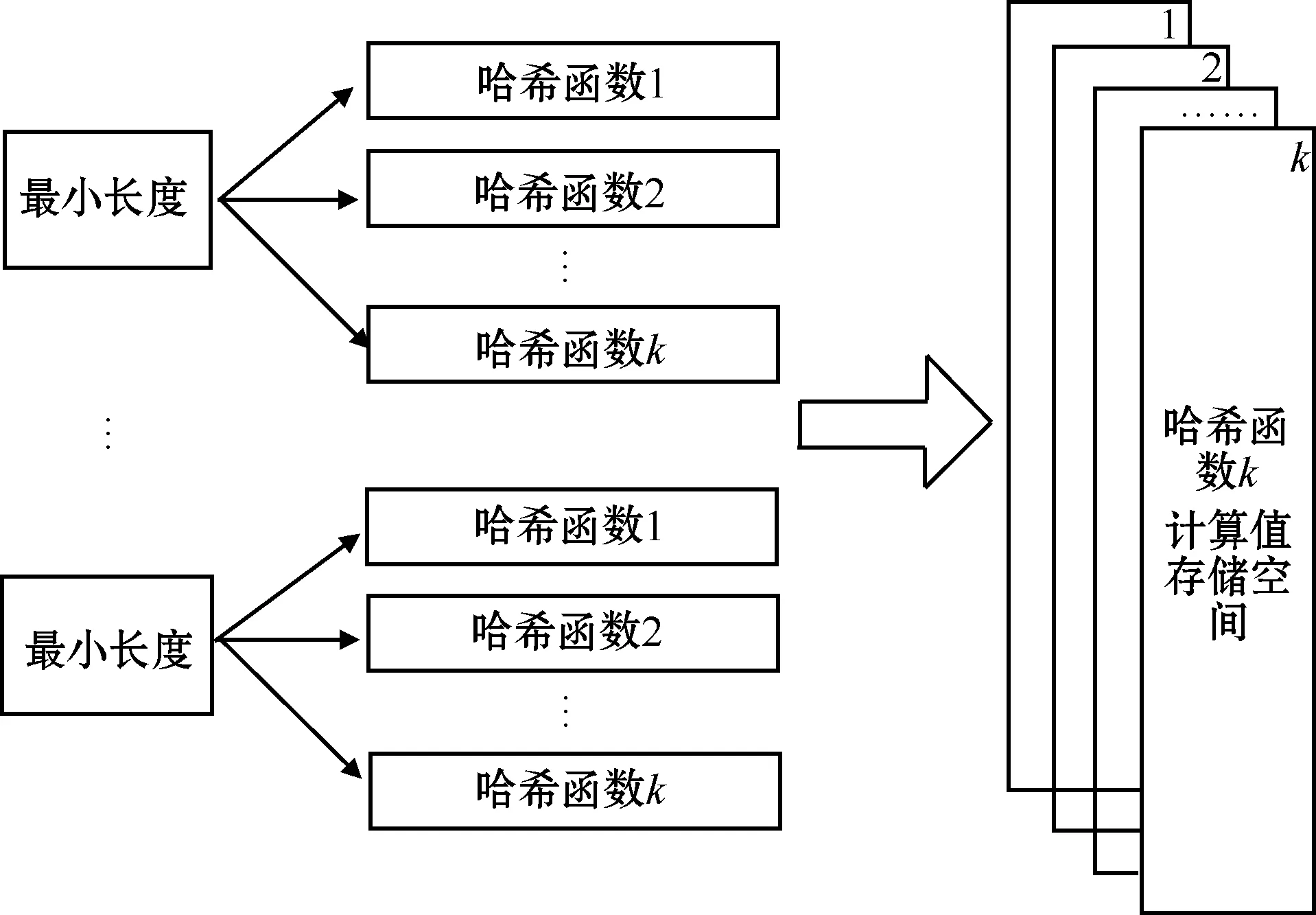
图5 共享内存的k路并行向量表
过滤器组使用时,以<字符串,组号,长度>(
优化后,查询时可以做到组内不同长度BF并行计算,理论上误报率为p=(1-e(-n/m))k。
预过滤时,过滤器组每次移动1字节进行检测窗口滑动,如图6所示。通过组内结果位图,可以准确得到命中字符串长度l,记录滑动窗口位置,得到字符串的命中位置(position_start,Ps)。命中字符串的结束位置(position_end,Pe)可由计算得到:
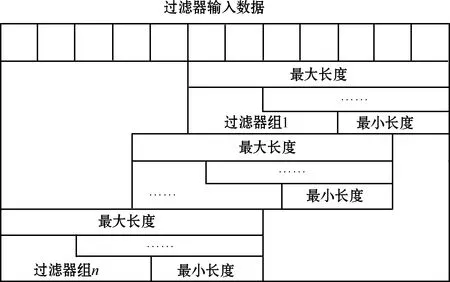
图6 n路过滤器组
Pe=Ps+l-1
(3)
本文设计充分利用FPGA并行的优势,可以实现n路过滤器组并行检测。
2.4 预过滤结构流水线优化设计
BF进行初始化时,共分为3个阶段:1)模式串信息获取阶段;2)Hash计算阶段;3)写入阶段。3个阶段共需3个时钟周期,即每个模式串写入均需3个周期,若等一个模式串写入完成后再执行下个模式串的写入,初始化阶段将耗费3n个时钟周期,其中n为模式串个数。
为提升初始化效率,设计初始化流水线[8]。优化后n个模式串的初始化总耗时为n+2个时钟周期,在模式串个数较多的场景下,初始化性能为非流水线方式的3倍。
BF进行模式串查询时,共分为4个阶段:1)数据处理阶段;2)Hash计算阶段;3)查询阶段;4)结果计算阶段。4个阶段通过RTL代码逻辑优化,可实现5个时钟周期完成一次查询。设计中BF一次并发处理的数据规模为32字节,在200 MHz时钟频率下,过滤器吞吐量可达10.24 Gbit/s。
使用流水线结构进行优化,无需等待数据过滤结果,直接进行下一次数据的过滤,命中后,停止流水线。基于流水线的查询设计,在200 MHz时钟频率下,吞吐量可达51.2 Gbit/s,查询性能为非流水线设计方式的5倍。
3 匹配引擎工作流程
3.1 带有“前缀字符串”的正则表达式
面对带有“前缀字符串”的正则表达式,本文设计的匹配引擎算法流程如下所示。
1)BF向量表清零。
2)初始化BF。
3)进行G1内模式串检测。若命中,执行步骤4);若过滤至文本结束仍未命中,返回匹配失败信息,匹配流程结束。
4)记录命中位置Ps,并计算结束位置Pe。
5)判断多组模式串是否均已过滤完成。若仍有未匹配的模式串组,且文本未过滤至结束位置,执行流程6);若文本全部过滤,直接返回匹配失败,匹配流程结束;若所有模式串组均已匹配完成,进入步骤9)。
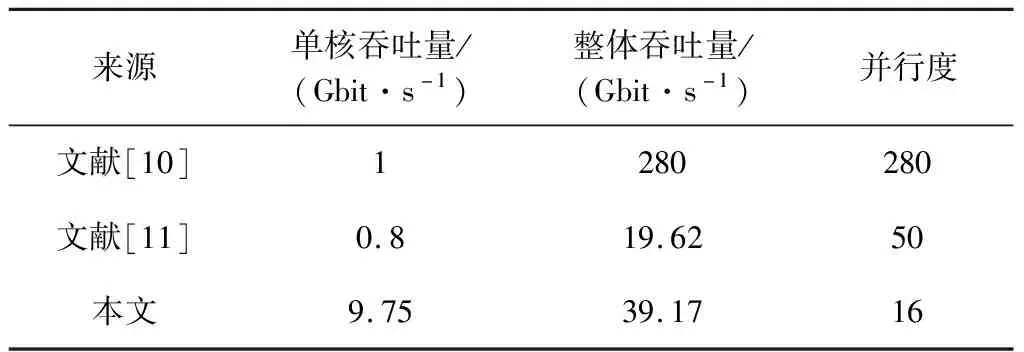
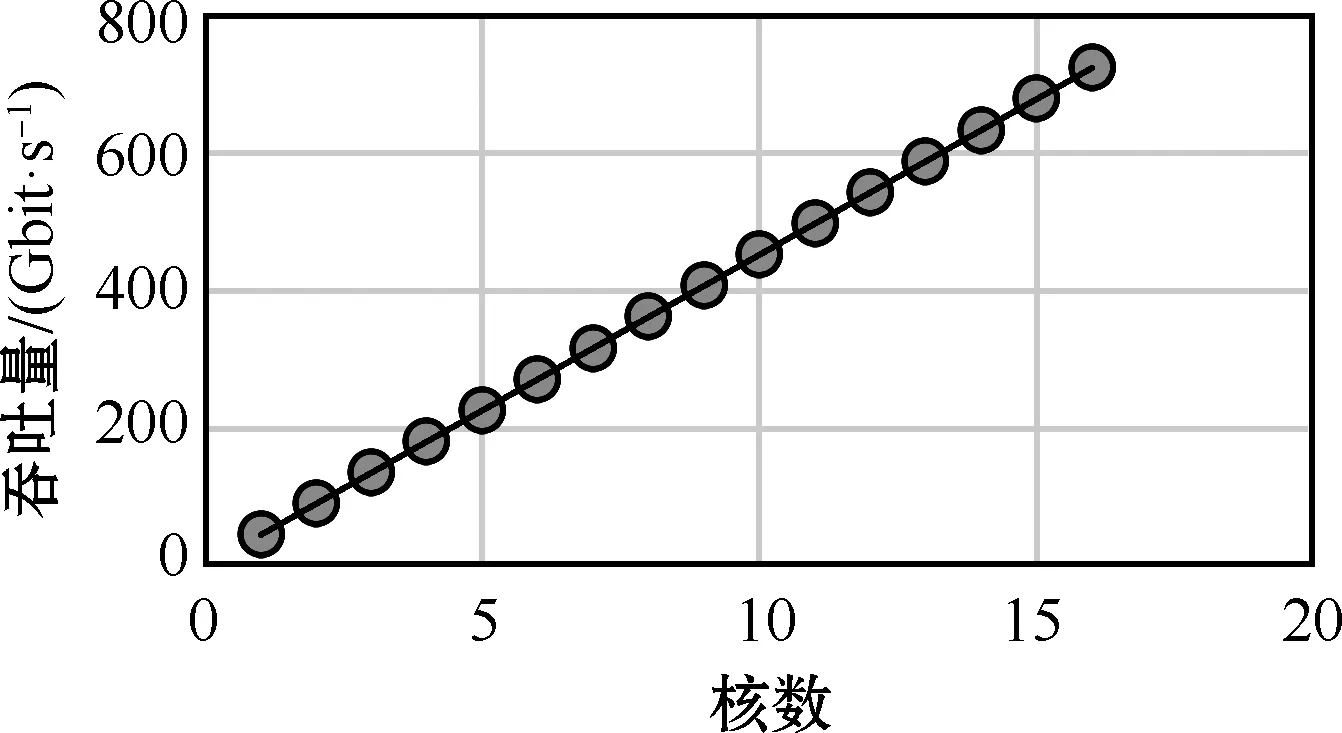
6)为避免Pe(i) data=inputdata&mask (4) mask={(Pe+1){0}(n-Pe-1){1}} (5) 7)若再次命中,计算Pe并更新,Ps保持不变。 8)重复步骤5)~7)。 9)根据Ps,计算进入正则表达式匹配引擎的文本位置(position_dfa,Pd)。 Pd=Ps (6) 10)从Pd开始,以输入字符char和状态转移表作为驱动条件启动匹配引擎。 11)正则表达式匹配引擎输出匹配成功,或出现失配需重启过滤器。 12)重新启动过滤器,根据失配位置(position_mis,Pmis),处理数据算法如下: data=inputdata&mask (7) mask={(Pmis+1){0}(n-Pmis-1){1}} (8) 13)重复流程,直至匹配成功,或是匹配失败,并结束匹配流程。 例如正则表达式“Host:w+httpw+”,其类型为prefix_regex,匹配文本为“abcHost:efg123httpabc”。该规则提取出的模式串组为G1={“Host:”},G2={“http”},length(Host:)为5,length(http)为4。BF使用32路并行的过滤器组进行过滤,以G1为模式串过滤,得到并行结构的结果位图result_bitmap 为0001000…000(32 bit),对应了并行时数据过滤的32个起始位置,此时Ps=3,表示在第4个字符处命中,根据过滤器组返回的组内位图match_bitmap为00001,命中字符串长度为5,并得到Pe=Ps+L-1=7,其中L为长度length。在Pe之后开始以G2为模式串过滤,为避免Pe(1) 数据将从字符“e”开始以G2为模式串进行过滤。由于该正则表达式一共提取出两组模式串,在G2命中后,BF的预过滤工作完成,令Pd=Ps,对于上述数据,数据将从字符“H”处开始进行正则表达式匹配。匹配引擎在接收到字符串“http”之后的字符“a”后,状态机跳转至可接受状态,返回匹配成功信息,匹配结束。 对于带有“中缀字符串”的正则表达式,匹配流程与prefix_regex区别在于以下几点: 1)因规则在G1内模式串之前仍有FA,为了保证字节码匹配引擎功能正常,应将整个文本送入匹配引擎中进行匹配。 Pd=0 (9) 2)匹配引擎出现失配再次进入匹配引擎时,应在上次匹配引擎失配位置处开始匹配。 Pd=Pmis+1 (10) 如规则“w+Host:w+httpw+”,属于infix_regex,文本为“abcHost:ef&g123Host:abchttpabc”,过滤完成后,数据将从起始位置开始正则表达式匹配,即Pd=0。在匹配引擎中遇到字符“&”,失配并记录位置Pmis=10;再次启动BF,过滤完成后,令Pd=Pmis+1=11,文本从字符“g”处再次匹配。 按照上述方式对infix_regex进行处理,若数据量较大,Pe位置较为靠后,匹配引擎仍要从位置0开始匹配,对于FA来说,若Pe前大部分为无效数据,则匹配效率并未得到提升。 分析上述规则,FA1为“w+”,其含义是匹配集合{0-9,a-z,A-Z,_}内字符一次或多次,即在字符串“Host:”之前,文本中至少需要包含一个上述集合中的字符。如规则“W{5}abc”,FA1为“W{5}”,“W”表达的含义是“[^w]”,匹配字符不在集合{0-9,a-z,A-Z,_}中,“{5}”表示循环5次,即文本若要符合该规则,在字符串“abc”前至少需要连续5个字符满足“W”要求。 本文在设计infix_regex时中引入FA1深度(FA_depth,Fd)的概念,Fd用来辅助infix_regex确定进入匹配引擎时的文本位置,以及辅助BF更快速地判断文本是否符合规则要求。 引入Fd后,关于infix_regex的匹配流程,需要做出以下修改: 1)BF首次完成G1内模式串检测后,若Fd>Ps,应处理数据,并再次进行G1内模式串检测。 2)BF完成预过滤后 Pd=Ps-Fd (11) 3)匹配引擎失配后,再次启动BF,完成G1内模式串检测后,若Fd>Ps-Pmis,同1)。 对于表达式“w+Host:w+httpw+”,其Fd=1。文本不变,BF在G1模式串检测时Ps=3,符合要求,继续进行G2模式串检测。BF完成过滤首次进入正则表达式匹配引擎时Pd=Ps-Fd=2。匹配引擎失配后Pmis=10,再次启动BF进行G1模式串检测,Ps=15,符合Ps-Pmis>Fd要求,继续进行G2模式串检测。BF完成过滤,再次进入匹配引擎时Pd=Ps-Fd=14。 引入Fd后,基于上述例子中的规则、文本,可节省10个时钟周期。经测试,在大数据量的场景下,性能与prefix_regex相当,性能提升2.5倍。 BF无法避免出现误报,一般会使用专用验证结构,将误报的元素排除。而这种做法需要额外周期进行验证,且需提供规则中各模式串组准确信息,占用额外的存储资源。本文为减少额外存储开销,设计了预过滤容错机制,下面是针对不同误报场景下容错机制的设计: 1)G1模式串检查得到命中位置Ps1,计算得到Pe1,将位置[0,Pe1]内数据清零,若G2命中位置Ps2 2)若匹配引擎失配后,再次启动BF对G1中模式串进行检测,出现Ps 3)若Pmis≤Pe,说明BF出现误报,不响应此时的失配信号,继续在匹配引擎中进行匹配,直至Pmis>Pe,可响应失配信号,跳出匹配引擎,启动BF。 4)若BF完成过滤后,Pe大于eod,直接返回匹配失败,结束匹配流程。 以上几种场景,包括了预过滤中可能出现的误报问题,对应场景下容错机制的设计,可以保证系统功能的正确性。 实验所用FPGA板卡参数如表1所示。 表1 FPGA板卡参数 在200 MHz时钟频率上实现了基于预过滤结构的正则表达式专用匹配引擎。预过滤结构中,使用5路并行的多组向量表来实现,规则中模式串最大提取组数设定为4组,每组向量表为32 bit,即向量表存储空间MEM为640 bit,过滤器的误报率为0.73%,预过滤在32路并行的流水线设计下吞吐量达到51.2 Gbit/s。 基于vivado系统的综合布线表明单个正则表达式匹配引擎对FPGA片上资源利用率不高。为充分利用FPGA片上资源、更好地提升性能,在200 MHz时钟频率上完成了16个基于预过滤匹配引擎的实现,理论性能提升16倍,且多个匹配核对DFA的“状态爆炸”问题有一定的缓解作用。16核独立匹配引擎的显示查找表(look-up-table,LUT)资源为39%,BRAM(block RAM)资源为35%,这为更多匹配引擎的实现提供了可能。后续若要提升匹配核数量,瓶颈不在资源上,而是体现在时序上。在现阶段的优化中,200 MHz时钟下完成16核结构的实现,可符合加速卡结构时序要求,但增加更多的匹配引擎,带来的是整体布线上的复杂度增加,信号传递上的延迟等,需对关键路径上的时序进行更好的优化,这也是未来的优化方向之一。 性能从两个方面进行分析:一个是在软硬件协同工作结构下多核匹配性能,体现的是现阶段整体匹配性能;另一个是纯硬件多核匹配性能,体现的是加速卡的性能极限,在之后软硬件数据接口优化后,性能可提升的最大限度。根据实际需求,测试文本使用多个小数据包进行测试,实验过程为: 1)对规则进行编译,记录编译时间Tcom。 2)发送正则表达式字节码到FPGA,记录字节码传输时间Tcoe。 3)发送数据包,记录数据包传输时间tdata。 4)开始进行匹配,记录匹配时间tmatch。 5)重复3)、4)两步,直至所有数据包完成匹配。 实验中,将系统吞吐量C作为考察目标。 (12) 式中:Dsize为单个数据包大小;Tdata为n包数据传输总时间,Tmatch为n包数据匹配总时间。 不同系统性能对比如表2所示。从表2可以看出,多核系统性能约为单核系统的4倍,这是上位机性能导致的,实验所用测试机配置不能支持16核同时调用,4核以下同时调用时,性能几乎为线性增长。理论上16核性能为单核的16倍,但这个性能也将受限于所用PCIE的总线带宽。忽略总线带宽以及测试机性能限制,多核系统的性能理论值为156 Gbit/s。 表2 系统性能对比 (Gbit·s-1) 文献[10]、文献[11]均使用基于FPGA的正则表达式匹配算法,本文与文献中两种结构的性能对比如表3所示。由表3可知,在单核吞吐量方面,本文结构性能明显优于文献中两种结构,但在并行度上有劣势,且受限于测试机性能,并行度并不能达到理论的16核,只能达到4核性能。 表3 正则表达式匹配硬件结构比较 在硬件逻辑中加入计数器,用来统计硬件匹配开始工作到结束所用周期数,将忽略上位机的处理时间,更加直观地反应出硬件匹配引擎的性能,纯硬件单核以及多核结构的性能对比如表4所示。 表4 纯硬件性能统计 (Gbit·s-1) 从一个匹配核到16个匹配核的性能变化如图7所示。 图7 多核性能变化 由图7可知,多个匹配核完全独立、并行工作,多核结构性能呈线性增长。时钟频率在200 MHz下,匹配引擎性能达722.88 Gbit/s。 为了提升正则表达式匹配性能,本文专注于最消耗计算的资源匹配操作,设计了基于预过滤结构的正则表达式硬件专用匹配引擎,在FPGA平台上对预过滤结构存储空间进行优化,减少占用空间的同时提升并发度。 实验表明在单核模式下,本文设计的匹配引擎系统性能为纯软件方案Hyperscan的4.85倍,匹配性能为Hyperscan的22.48倍。与文献[11]中同类型结构相比,单核性能为其20倍,但本文结构并行度现阶段不如文献[11]中50核结构。与文献[10]中硬件结构相比,处理单个正则表达式的性能为其9倍左右,但文献[10]中实现了同时匹配280个正则表达式。现阶段的设计中,在200 MHz的时钟频率下实现了16个并行的匹配引擎,后续可在例化更多匹配引擎以及软硬件通讯方面做出进一步优化。3.2 带有“中缀字符串”的正则表达式
3.3 预过滤结构误报处理
4 实验结果


5 结束语
猜你喜欢
共产党员·下(2022年4期)2022-05-17党的生活(黑龙江)(2022年4期)2022-04-25人民交通(2020年4期)2020-04-16科学与技术(2018年16期)2018-05-16儿童故事画报·发现号趣味百科(2017年4期)2017-06-30数字技术与应用(2017年3期)2017-05-17发明与创新·大科技(2017年5期)2017-05-16计算机应用(2016年10期)2017-05-12科教导刊·电子版(2016年30期)2016-12-26中国新通信(2016年17期)2016-11-17
