
基于ELK的运维辅助系统的设计与实现
2022-03-25 22:33:49李书达刘遵仁朱琦
青岛大学学报(工程技术版) 2022年1期
李书达 刘遵仁 朱琦




文章编号: 10069798(2022)01001806; DOI: 10.13306/j.10069798.2022.01.003
摘要: 针对分布式集群在服务出现异常情况下存在的无法快速定位到异常所在服务器,并获取报错详情的问题,本文采用技术栈(elasticsearch,ELK)捕获异常,并解析日志内容来展示详情,以实现快速定位,最终以邮件形式告知运维人员进行处理。测试结果表明,部署在A公司多台服务器上的集群出现异常后,本系统最快可在2 s内监控到异常,5 s内完成对运维人员的邮件通知,邮件内容包括问题发生时详细信息,方便运维人员快速定位问题。本系统大大缩短了运维人员处理故障时间,提升了运维效率,降低了公司损失,可以辅助运维人员实现对多服务器集群的监控,做到对异常集群的快速定位。该研究对企业分布式集群节点的异常定位具有重要意义。
关键词: ELK; 辅助运维; 大数据; 日志
中图分类号: TP311.13文献标识码: A
随着互联网飞速发展,高速网络不但增加了用户体验,也增加了企业服务器负载压力,在此情况下,分布式集群成为企业服务器应对大数据高并发场景的主流解决方案[1]。分布式集群保证机器宕机时仍有其余机器可对外提供访问,但如果代码层面出现异常,不能被及时发现并修正,也会造成严重损失,因此深入代码层面的监控对企业意义重大。日志记录了各自服务器运行时的核心信息,这对定位问题具有重要作用,所以利用好服务器日志成为关键点。近年来,为方便管理大型集群,一些团队设计了集群监控系统,但与日志相关的功能并不丰富。Zabbix是一个常用的集群监控系统,其实现了多条报警及自带画图功能,当集群出现异常时,可以执行对应的紧急预案脚本自动修复[2];Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库,其通过超文本传输协议(hypertext transfer protocol,HTTP),周期性抓取被监控组件的状态,组件只需提供对应的HTTP接口就可接入监控,不需要任何软件开发工具包或者其他集成过程[3]。上述系统主要针对服务器硬件指标(如磁盘I/O率),对日志的采集和分析功能不完善。因此,本研究通过对传统数据处理技术和当前流行的大数据日志分析技术进行融合[4],设计并实现一个基于ELK的海量日志分析系统,将其应用于服务器集群运维方面,解决无法及时发现集群异常的问题。该研究对企业分布式集群节点的异常定位提供了理论依据,具有一定的创新性。
1技术基础
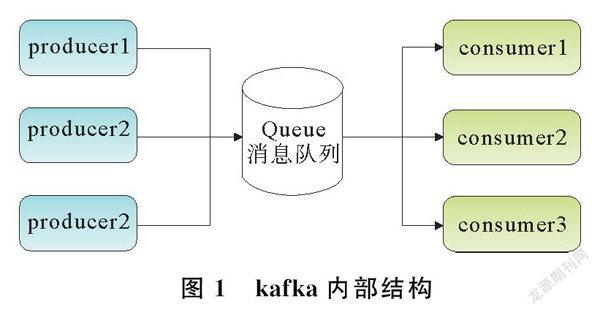
本系统所使用技术基础包括Filebeat、kafka、Logstash、ELK。Filebeat是大数据常用数据采集组件,因其体积轻,占用生产机器极少资源而被广泛用于文本采集输入端[5]。在本辅助运维系统设计中,Filebeat专门针对各个服务器日志进行捕获,输出至kafka;kafka是一个高吞吐量发布订阅模式消息队列,类似组件还有RabbitMQ和RocketMQ等,由于kafka对Hadoop的大数据生态支持较好[6],因此本辅助运维系统采用kafka作为汇集各个服务器日志数据的队列。kafka内部结构如图1所示。
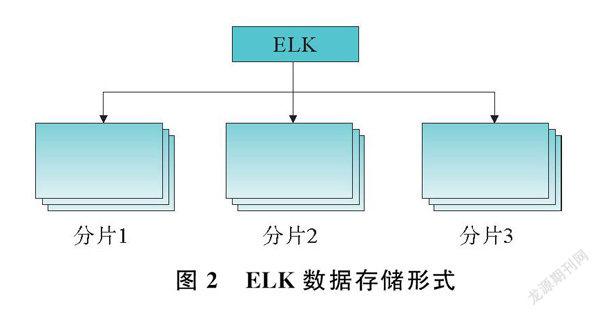
Logstash作为数据处理引擎,在本系统中负责实时拉取kafka中原始日志数据[7],将解析完的数据输出到ELK中,以作为最终持久化存储及检索。ELK是目前最受欢迎的企业搜索引擎之一,同级别搜索引擎还有Solr,由于在持续性动态插入数据时,Slor的查询效率较ELK会明显降低,因此本系统采用的检索引擎为ELK,作为最终的数据存储和检索[8]。ELK数据存储形式如图2所示。
2系统设计
2.1节点规划与组件版本
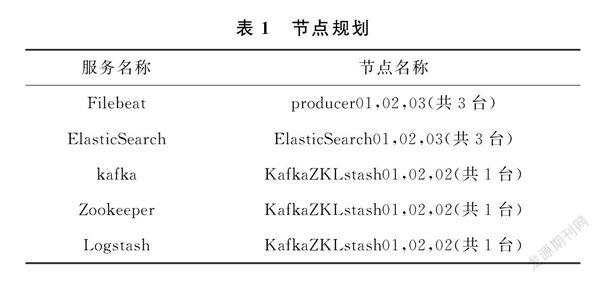
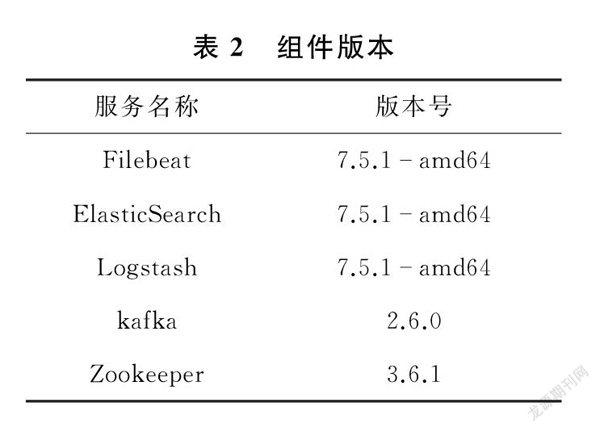
本辅助运维系统的安装部署以及最终测试效果基于如下环境,FileBeat作为日志采集输入层,kafka、Zookeeper、Logstash作为中间队列及数据处理层,ELK作为数仓层。表1中所列服务是必须的,但节点数量可以大于此表所列数量,节点规划如表1所示。不同组件的其他版本会有不兼容的情况,本系统所使用的组件版本号参照组件版本表,组件版本如表2所示。
2.2架构设计
本系统为集群环境设计,基于节点规划表所列的节点,设计系统架构图,系统架构图如图3所示。公司生产系统部署在Producer01,02,03上,3台服务器形成小型集群,服务器实时产生的log日志中,包括info、Warn、Error类型日志数据[9]。系统原始数据采集输入端——Filebeat监控指定日志文件,并将捕获到的日志数据发往kafka。Filebeat是轻量级,可以在每台服务器上安装部署,不会影响机器性能,当服务器过多时,可通过脚本或者Xshell工具,实现“一次操作所有部署”,缩短工作量[10]。系统中间数据缓存解析端——kafka,实时接收Filebeat发来的数据,并进行缓存存储。在辅助系统开发中,kafka应当独立于生产系统的集群,因为外界组件不应该与生产系统竞争CPU和内存资源,否则影响生产系统的性能,辅助系统就丧失了辅助的意义[11]。
本系统选擇将Zookeeper和kafka安装在同一集群,Zookeeper只起到kafka注册中心作用,功能单一。而与kafka同一集群,方便kafka与Zookeeper之间数据交互[12]。由于kafka消耗服务器的磁盘I/O性能和内存资源,CPU和部分内存还未被充分利用,可以将Logstash与kafka安装在一个集群。Logstash解析kafka中每条日志数据,并插入ELK,需要消耗服务器CPU性能,与kafka搭配使用,可将集群资源利用率达到最大[13]。另外,此部署方式避免了跨集群网络传输,Logstash可以更快速的读取本地kafka数据,大大减少网络延迟,增加处理效率。系统的存储及检索端——ELK,负责存储Logstash解析后的数据,并在用户(运维人员)请求时返回查询到的数据。由于数据量较大,上百万量级数据的检索对Mysql具有挑战性[14],因此系统最终选择ELK作为最终存储端。
2.3功能实现
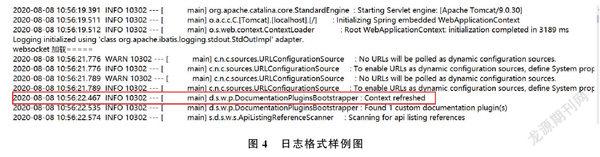
1)采集输入端。Filebeat默认一行一行读取文件,在开发过程中,考虑Error报错不止一行,而是由多行信息一起组成一个Error块。当分析日式数据格式后,使用Filebeat的multiline.pattern自动识别日志格式。日志格式样例图如图4所示。
multiline.pattern是Filebeat自身功能,需要配置正则表达式来匹配捕获到的每一行日志信息[15],如果捕获的日志数据起始为“yyyyMMdd”格式,会立即判断接下来一行日志数据是否为“yyyyMMdd”格式。如下一条也符合,则将本行单独作为一行日志进行输出,如果不是,则认为已经进入到Error块中,直到某一行捕获到“yyyyMMdd”格式為止,将期间所有数据均作为Error一整块进行输出。本系统Filebeat使用multiline.pattern,multiline.pattern: ′^[09][09]′,multiline.negate: true,multiline.match: after。
2)缓存及解析端。因为本系统设计部署3台kafka,所以在创建kafka主题——topic时,应该充分利用集群资源需要指定topic分区数为集群节点同等数量。当Logstash读取kafka数据时,会从topic设置的各个分区节点同时读取,可以大大增加并行度,提高处理效率,防止kafka数据积压[16]。
Logstash的数据解析同样依靠grok正则匹配功能[17],在grok中定义正则表达式后,当Logstash读取kafka数据会依次剪切形成各个字段,并存储到ELK中。Logstash的grok正则匹配规则设置如下:
3)存储及索引端。ELK相当于整个系统的数据库,在本系统中设置了如下几个重要字段,logHost、logLevel、logMessage、logServer和logTime。
logHost是日志来源节点名称,通过该关键字判断异常发生在生产集群的哪一台机器。logLevel是异常等级,一般包括Info、Warn、Error。其中,Warn、Error级别会在辅助运维系统UI界面展示,Error级别日志则会立即以邮件形式通知所有运维人员。logMessage是异常信息,是日志文件的基本内容,通过邮件[18]展示给运维人员。logServer是日志所属服务,微服务的每一个模块都有自己的名称,比如用户登录服务、浏览商品服务、订单服务等,通过该字段,更精确定位异常发生位置,能够第一时间评估对公司造出的影响。logTime是每一条日志产生时间。
4)推荐方案。当Error日志产生时,需要尽可能降低运维人员工作量,本系统设计了推荐方案功能,运维人员每次解决方案都会记录在系统中,当新的一条Error产生,会通过ELK与历史记录对比,当相似度超过95%时,将该历史解决记录推荐给运维人员[19]。
2.4前后端页面展示
本系统前端WEB UI界面采用VUE+Element框架,后端使用SpringBoot框架[20]实现前后端分离。后端主要负责通过RestLowLevel Client API与ELK集群做系统查询交互,并将ELK返回的数据处理封装后,返回给前端渲染到页面上展示。前端VUE+Element框架帮助快速搭建一个前端页面,供实时展示。
3最终结果
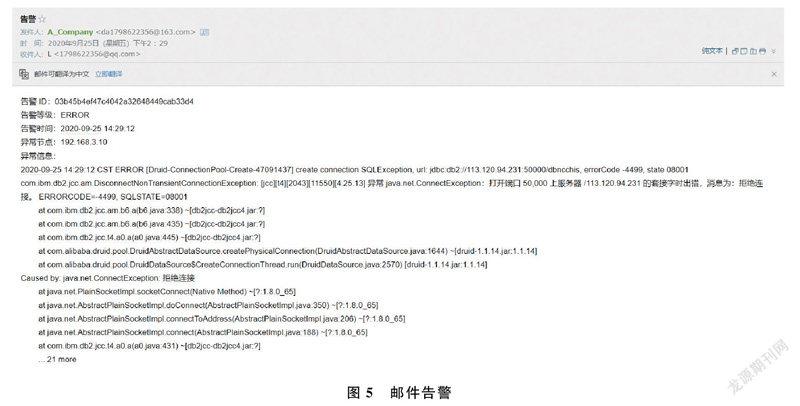
各组件及前后端服务正常启动后,开始监控生产系统集群,服务器出现异常,可迅速收到运维监控系统发出的邮件告警,邮件告警如图5所示。
运维人员在Web端查看异常数据,页面查看日志信息如图6所示。由图6可以看出,通过邮件内的信息或Web端信息,运维人员可快速定位到问题服务器,并进行处理。
4结束语
本文主要对基于ELK的运维辅助系统进行设计。基于ELK集群,并结合大数据技术,深入到代码层面进行分析,同时依据企业需求定制处理逻辑。测试结果表明,本文设计的ELK运维辅助系统,监控异常最快可达2 s,5 s内完成对运维人员的邮件通知,与其他集群监控系统相比,反应迅速,数据处理效率较高,对日志数据解析灵活,减轻了运维工作量。与现有监控系统相比,使用灵活,且分析效率高,具有一定的创新性。下一步将考虑系统末端增加推荐算法功能,推荐合适的处理方案给运维人员,可减少运维人员独立判断时间,增加排查问题准确度。
参考文献:
[1]李宁, 张轶昀. 一种分布式微服务架构系统缓存解决方案[J]. 电脑知识与技术, 2020, 16(36): 7374.
[2]王宝云, 卢兴来, 黄晓龙, 等. 基于ZABBIX的新一代天气雷达ROSE系统监控平台[J]. 气象科技, 2021, 49(5): 730737.
[3]王召选. 基于Prometheus的GPU服务器运维监控系统[J]. 信息与电脑(理论版), 2021, 33(9): 131133.
[4]王兴宏. 大数据应用及新时期所面临的挑战研究[J]. 青岛大学学报(自然科学版), 2020, 33(3): 2227.
[5]翟雅荣, 于金刚. 基于Filebeat自动收集Kubernetes日志的分析系统[J]. 计算机系统应用, 2018, 27(9): 8186.
[6]HASSAN F, SHAHEEN M E, SAHAL R. Realtime healthcare monitoring system using online machina learning and spark streaming[J]. International Journal of Advanced Computer Science and Applications, 2020, 11(9): 650658.
[7]陈东辉, 高峰, 刘娜, 等. 气象台站历史沿革信息检索可视化系统设计与实现[J]. 计算机应用, 2021, 41(S1): 119124.
[8]谢磊, 张冰, 杨猛. 基于ELK的日志分析系统研究与实践[J]. 科技经济市场, 2020(10): 1718.
[9]李英, 李劲华. 基于用户会话Web应用程序测试的新方法[J]. 青岛大学学报(自然科学版), 2015, 28(4): 6165.
[10]刘晓文. 基于脚本批量管理交换机[J]. 网络安全和信息化, 2017(11): 5657.
[11]车思阳. 基于Kafka的大容量实时预警数据汇集分发技术研究[D]. 成都: 电子科技大学, 2021.
[12]韦疆臣. 基于ELK的大数据平台运维管理应用研究[D]. 西安: 西安电子科技大学, 2019.
[13]任安, 冯佳, 朱玉立. 基于Zookeeper服务的数据库同步研究与实现[J]. 信息系统工程, 2020(7): 116117.
[14]李庆宇, 王松波, 林伟伟. 面向时序大数据的数据库性能研究\[J\]. 广州大学学报(自然科学版), 2021, 20(3): 6979.
[15]赵书慧. Android日志过滤器中正则表达式的应用[J]. 电子测试, 2021(2): 8485.
[16]刘邦, 余华平. Kafka分布式消息队列的高性能研究[J]. 电脑知识与技术, 2019, 15(32): 46.
[17]常征, 吕勇. 基于正则表达式的海量数据清洗系统[J]. 计算机应用, 2019, 39(10): 29422947.
[18]杨澎涛, 范永合, 孙友凯, 等. 基于Zabbix的告警推送技術[J]. 电子技术与软件工程, 2019(18): 5961.
[19]袁文光, 田娜. 基于大数据的教师信息技术应用能力测评路径研究[J]. 青岛大学学报(自然科学版): 2018, 31(S1): 5961.
[20]吴昌政. 基于前后端分离技术的web开发框架设计[D]. 南京: 南京邮电大学, 2020.
Design and Realization of Operation and Maintenance Auxiliary
System Based on ELKLI Shuda LIU Zunren ZHU Qi
(College of Computer Science & Technology, Qingdao University, Qingdao 266071, China)Abstract: In view of the problem that the distributed cluster cannot quickly locate the server where the exception is located when the service is abnormal, and obtain the details of the error, this article uses the technology stack (elasticsearch, ELK) to capture the exception, and parse the log content to display the details, so as to achieve fast positioning, and finally inform the operation and maintenance personnel to deal with it in the form of email. The test results show that after an abnormality occurs in the cluster deployed on multiple servers of company A, the system can monitor the abnormality within 2 seconds at the earliest, and complete the email notification to the operation and maintenance personnel within 5 seconds. The content of the email includes the details of when the problem occurred. It facilitates operation and maintenance personnel to quickly locate problems. This system greatly shortens the time for operation and maintenance personnel to deal with failures, improves operation and maintenance efficiency, and reduces company losses. It can assist operation and maintenance personnel to monitor multiserver clusters and quickly locate abnormal clusters. This research is of great significance to the abnormal location of enterprise distributed cluster nodes.
Key words: ELK; auxiliary operation and maintenance; big data; log
收稿日期: 收稿日期: 20210830; 修回日期: 20211125
基金项目: 国家自然科学基金青年基金资助项目(61503208)
作者简介: 李书达(1998),男,硕士研究生,主要研究方向为大数据及智能计算。
通信作者: 刘遵仁(1963),男,博士,教授,主要研究方向为大数据及智能计算。Email: lzr@qdu.edu.cn
猜你喜欢
心声歌刊(2020年4期)2020-09-07 06:37:14
思维与智慧·上半月(2018年10期)2018-11-30 07:29:48
思维与智慧·上半月(2018年9期)2018-09-22 00:00:00
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
中国交通信息化(2015年8期)2015-06-06 06:32:58
电子设计工程(2014年19期)2014-02-27 12:00:42
