
基于深度卷积生成对抗网络的不平衡大数据监测与诊断
2022-03-24 12:16林君萍
重庆科技学院学报(自然科学版) 2022年1期
林 君 萍
(福建船政交通职业学院,福州 350000)
0 前 言
随着工业4.0时代的到来,工业大数据成为驱动工业发展和进步的核心资源之一[1]。利用不同类型的传感器采集到的工业大数据,可以实现对机械设备的实时在线监控,避免出现由于设备故障、停机等而给企业造成额外损失。由于数据采集环境、数据类型的不同,不平衡数据广泛存在于生产过程中[2]。在不平衡数据集中,一个或多个数据类别的总量往往远超过其他类别,数据类别的不均衡给故障特征提取、分类、检测等带来了较大困难[3]。传统数据监测和故障诊断算法大多依赖于故障数据均衡的假设[4],现有的少数针对不平衡工业大数据的处理算法,也都是以数据集的再平衡为前提,并未对故障数据的具体类别作出详细区分。王来等人提出了基于Boosting的不平衡工业大数据处理算法,通过引入代价矩阵平衡大数据故障样本集[5]。该算法的不足之处在于,误分类的代价过高,算法本身缺乏足够的针对性和指向性。谭志等人提出基于朴素Bayes的故障大数据分类与监测算法[6],该算法在针对规模较小的数据集时具有一定的优势,但应对大规模数据集的能力较弱,分类的准确性和精度也有待改善。针对大规模不平衡数据集的特征,本次研究以机器学习和深度学习为基础[7-8],提出一种基于深度卷积生成对抗网络的故障大数据监测和诊断算法,该算法融合了深度卷积神经网络和生成对抗网络的优势,在数据分类处理和故障诊断方面具有更高的效率。
1 深度卷积生成对抗网络模型
1.1 生成对抗网络模型的构建
不平衡数据集通常具有高维、复杂的数据分布特征[9],对少部分数据集特征提取的难度较大。生成对抗网络模型作为一种高效的无监督数据处理算法,无需大量样本标准和训练就能够学习到少量数据集的深度表征。生成对抗网络模型包含生成思想和对抗思想,其中,生成模型中的生成器G根据输入数据的特征建立与之匹配的模型,并随机产生与输入数据分布近似的分布数据,校正数据集的不平衡性。判别器D则基于已有的数据进行建模,学习输入数据的分布并判定输入数据的概率分布。生成对抗网络模型的基本结构如图1所示。

图1 生成对抗网络模型的基本结构
深度学习过程模型参数的设置通过对输入数据或构造数据的学习而完成[10]。数据训练中核心参数的选择必然存在偏差,用损失函数评价模型的理论参数与实际参数之间的差距。对于判别器D而言,输出参数部分损失函数的确定较为容易;而对于生成器G而言,模拟样本的构建过程较为复杂,定义损失函数的难度较大。鉴于生成模型损失函数参数选择的特点,生成对抗网络是针对对抗模型来处理前端模型的信息反馈,再由判别模型判别数据类型,利用判别结果指导前端模型参数的生成与选择。通过生成模型和判别模型之间不断的对抗、调整与优化,得到最优的对抗模型。在生成对抗网络模型中,先验分布为P(z),其中z为输入模型的噪声数据;生成器G的概率分布为PG(x),x为输入判别器D的待判定数据;PD(x)为输入判别器D的真实数据概率分布。生成对抗网络模型的目的是得到一个经过数据对抗的优化生成器G′:
(1)
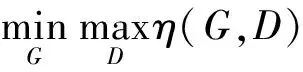
EPD(x){lg[1-D(G(z))]}
(2)
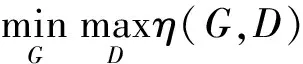
(3)

PG(G(x))]
(4)
式中:κ为生成对抗网络相对熵值;PG(G(x))为生成器函数的先验分布。
当PD(x)与PG(G(x))相等并将判别器D视为二元分类器时,可以得到经过优化的生成器G′,并获取最小化的lg(1-D(x))。
1.2 基于深度卷积生成对抗网络模型的数据监测与诊断
生成对抗网络模型的生成器与判别器要交替优化,在不平衡数据的实际应用中难以实现纳什均衡,生成器网络和判别器网络的数据无法较好地实现同步。例如,生成器经过多次训练,才完成一次更新。经典的生成对抗网络无法增加相关的辅助信息,模型的稳定性不足,这将会导致生成器G的数据样本缺乏多样性、损失函数值无法准确确定。为了解决目前存在的不足,用深度卷积网络中的转置卷积层替换所有池化层,并在更深的卷积网络中去除全连接层,将步幅卷积应用于生成对抗网络当中,以提升数据训练的稳定性。基于深度卷积生成对抗网络模型如图2所示。
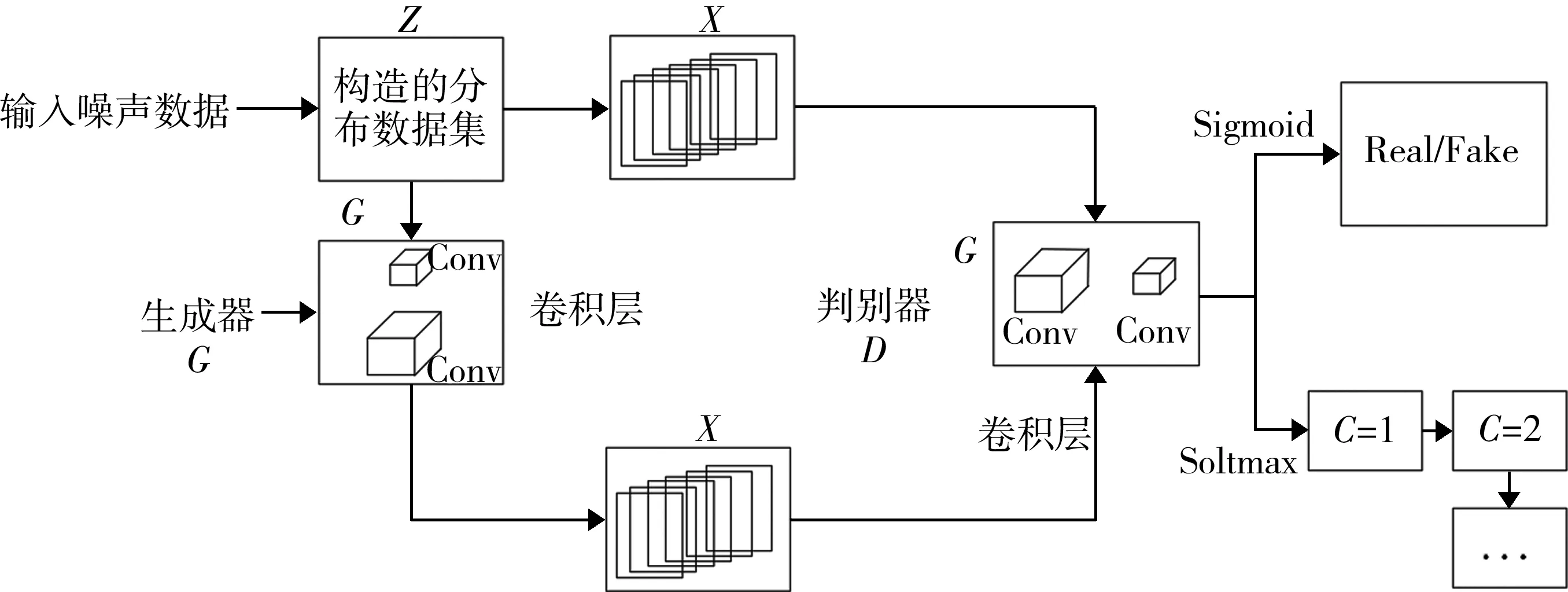
图2 基于深度卷积生成对抗网络模型
将转置卷积层所提取的特征作为判别器网络的输入项,经过优化的生成对抗网络判别层选择Sigmoid作为激励函数,而输出层则选择Relu作为激活函数。判别器的输出数据处理为均值为0、标准差为1的分布,增强数据的一致性和模型的稳定性能解决深度卷积网络模型中梯度溢出的问题。选用Sigmoid函数作为模型的激励函数,生成对抗网络是通过生成器与判别器的交替优化和训练,选取最优的训练参数以达到优化整个网络数据处理性能的目的。输入模型的噪声数据为z,通过生成器前项预测得到与输入数据相关的输出数据为z′,在生成器模型中训练过的z′与z合并,在叠加后作为判别器的输入项。叠加的故障数据并非是完全真实的数据,包含一部分真值为0的负样本y和真值为1的正样本y′。经过优化的生成对抗网络,能够区分生成的故障数据和真实的故障数据,且无需反复确定模型的参数。转置卷积层的加入,一方面提升了模型应对大规模数据集的能力,另一方面也可调整神经元的数量,降低计算代价。在生成器的训练过程中,将叠加输入的故障数据设定为1,并通过对抗调整和优化模型的参数使输出结果尽量接近真实,降低损失值以达到优化生成器的目的。
生成器损失函数的设计是提升模型对故障数据监测与诊断的关键,对进入判别器的正样本进行y′训练,设LGAN(D)为判别器输入结果与真实值的交叉熵:
LGAN(D)=Ez[lg(1-D(z,z′))]
(5)
式中:Ez是z所对应的能量函数;利用y和y′的L1范数作为生成器的损失函数,衡量真实值与生成值之间的差距:
(6)
模型的训练初期,基于深度卷积网络的转置卷积层提取的故障数据特征更加稳定。局部特征训练过程中,采用迁移学习的策略调整数据集,训练的补偿和时间都会减少,数据处理的效率得到提升。
2 实验结果与分析
2.1 平台搭建与数据集选择
在Hadoop环境下搭建不平衡数据监测实验平台,平台基于Java语言开发,具有良好的开放性和兼容性。平台由4个实验主机构成,其中主机1设定为NameNode,主机2—主机4设定为DateNote,实验中使用的Hadoop版本为2.7.1,JDK版本为jdk1.8.3-53。将全部主机连接在同一局域网络范围内,虚拟服务器选择VirtualBox。各数据监测主机的参数配置如表1所示。

表1 实验平台主机的参数配置
从UCI数据库中选择10组不平衡的数据集样本,数据集的范围涵盖特征维度、样本规模、数据集比例等不同的信息(见表2)。

表2 实验数据集样本的相关信息
2.2 实验结果与分析
首先,验证深度卷积生成对抗网络模型的数据训练性能。基于T-SNE算法将故障样本降维,并确保其在二维空间内的可视性,以数据集5和数据集10为例,150轮训练后,不平衡数据集样本中的数据分布情况见图3、图4(基于Matlab仿真得到)。仿真结果显示,两类不平衡数据间有明显的界限,证明生成对抗网络在优化后,生成对抗网络模型获得了良好的训练结果,数据训练性能得到提升。
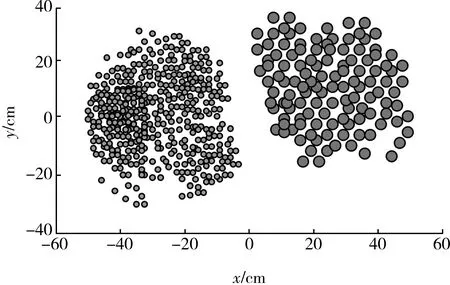
图3 数据集样本5的数据分布情况
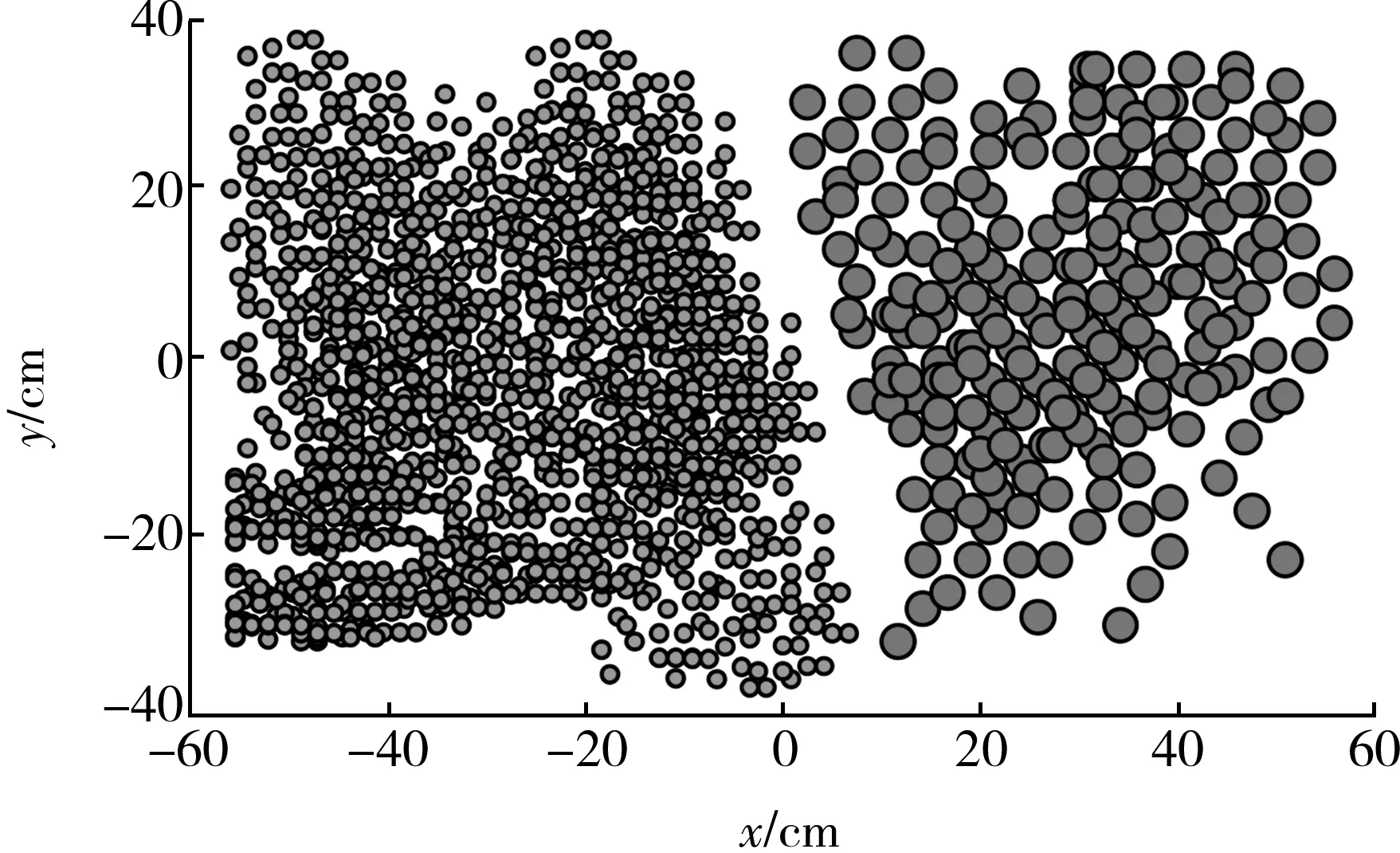
图4 数据集样本10的数据分布情况
其次,检验深度卷积生成对抗网络模型针对不平衡数据集的分类性能,提升数据分类准确率是保证故障数据诊断准确率的基础。为保证实验结果的直观性,实验过程引入Boosting算法和Bayes算法进行对比,10组不平衡数据集样本准确率统计结果见表3。

表3 不平衡数据集样本分类准确率统计
统计结果显示,针对小规模样本的故障数据分类,3种算法模型均有较高的准确率,而当样本规模较大时,Boosting算法和Bayes算法的分类准确率降低。为了评估算法模型的性能,引入评价指标F(Measure)和G(Mean)。F(Measure)是一种用于指标评价的统计量,将准确率(Precision)和召回率(Recall)进行加权、调和与评价;G(Mean)是一种用于综合指标评价的统计量,能够综合评价Recall与误判率(Misjudgment rate)等指标,可以避免单一指标评价时出现的数值波动。
(7)
(8)
式中:η为随着数据集规模增长的动态参数,取值范围为(0,1],当取值为1时,即为F1值;κ为不平衡数据集的故障诊断准确率;τ为召回率;ζ为误判率。
深度卷积生成网络算法、Boosting算法和Bayes算法模型的F(Measure)、G(Mean)评价指标结果统计见表4、表5。
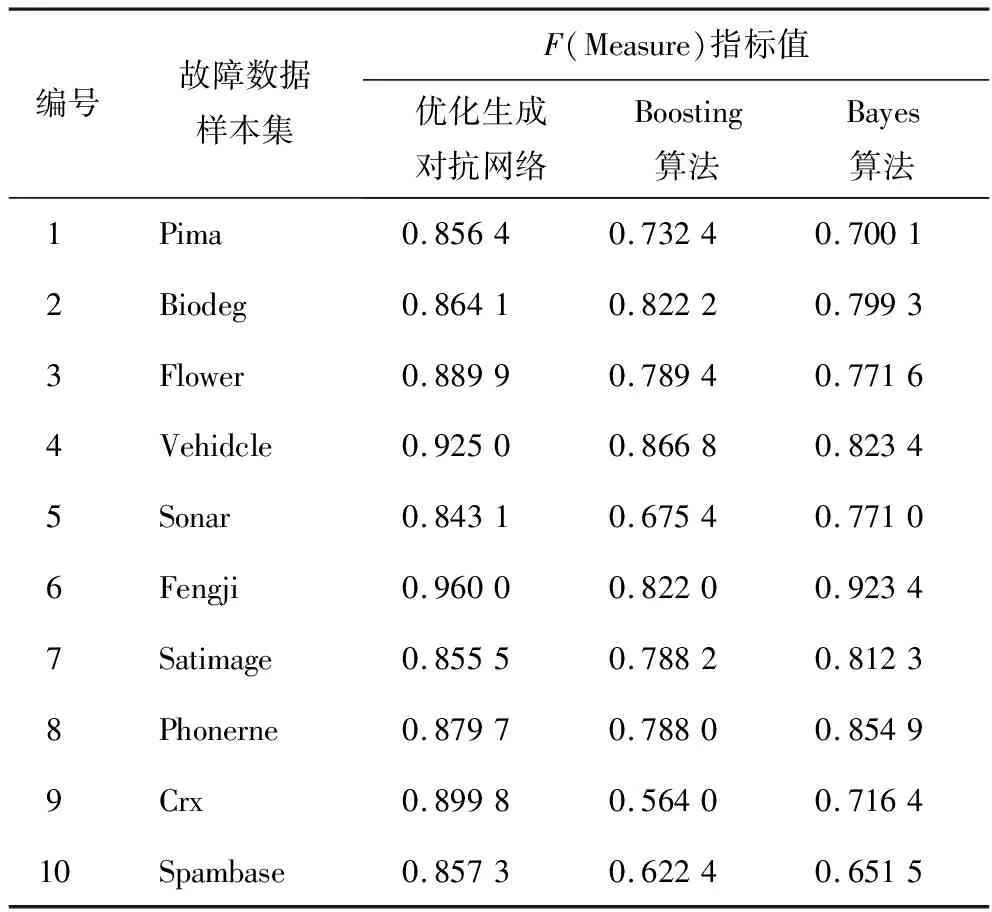
表4 F(Measure)评价指标的统计结果
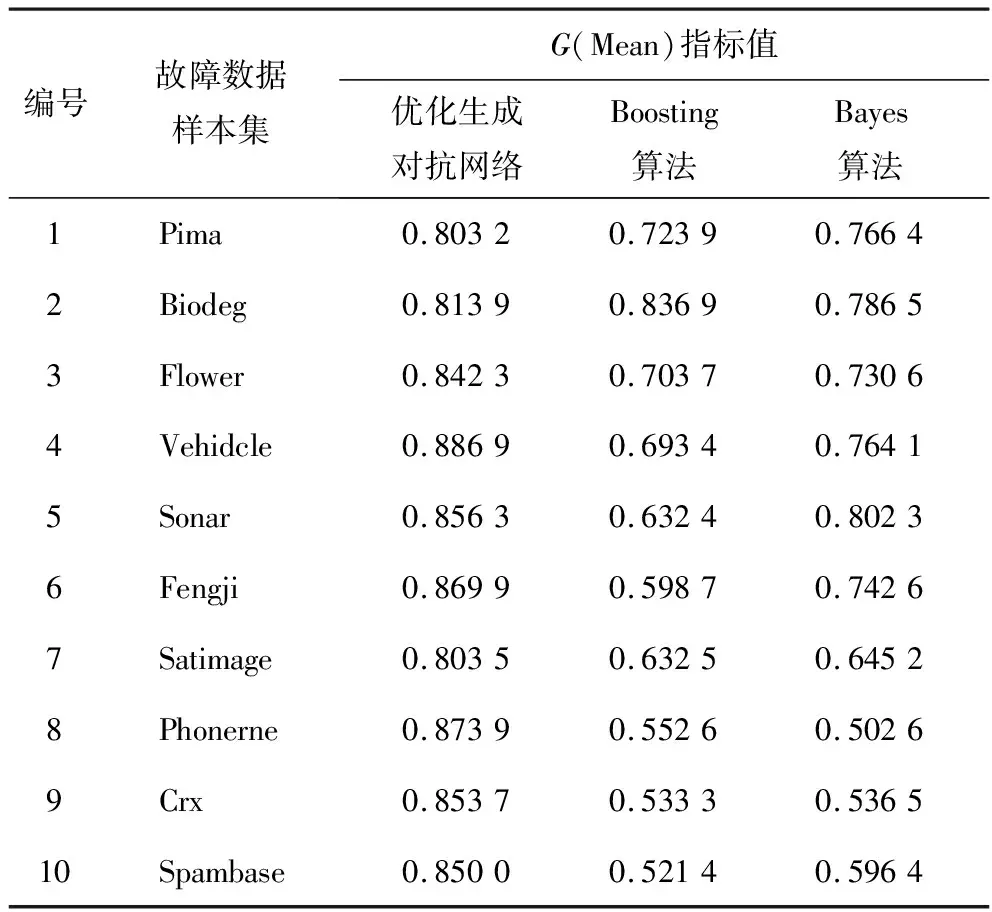
表5 G(Mean)评价指标的统计结果
F(Measure)评价指标结果显示,深度卷积生成网络算法模型对各数据集的F(Measure)值均高于Boosting、Bayes算法,尤其是当不平衡比例较高和数据集规模较大时,深度卷积生成网络算法的优势更加明显。
G(Mean)评价指标结果显示,深度卷积生成网络算法模型的指标值稳定性更好,尤其应对不平衡比例较高的数据集时,能够确保故障数据的诊断结果稳定、准确、持续地输出。
3 结 语
不平衡大数据在学习、训练和分类处理时的难度更大,为此,本次研究对经典的生成对抗网络模型进行优化,利用转置卷积层提升对故障数据训练的能力,并且降低参数调整和优化等方面的复杂度。实验结果表明,深度卷积生成对抗网络模型具有良好的故障数据训练性能,同时在数据分类性能和故障诊断性能方面也有一定优势。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
福建基础教育研究(2019年6期)2019-05-28
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
