
一种基于Chiplet集成技术的超高阶路由器设计*
2022-03-22 04:12梁崇山徐炜遐
计算机工程与科学 2022年2期
梁崇山,戴 艺,徐炜遐
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着人工智能、机器学习的快速发展和应用,百万级超大规模计算结点间的数据通信量急剧增长,且通信模式多样化,通信延迟要求越来越低。HPL(High Performance Linpack)和HPCG(High Performance Conjugate-Gradient benchmark)是常用于评估超级计算机系统性能的基准测试程序,HPL的性能比HPCG高50倍,其中HPCG部分性能的下降是由于其更高的通信强度造成的[1]。这清楚地表明,高效的互连网络有助于充分发挥系统的计算能力,连接百万级计算结点及存储设备的互连网络已成为制约高性能计算系统性能乃至成败的关键因素。相较于采用低阶路由器构建的互连网络,高阶路由器能够缩短网络直径,减少节点间通信步长,因此能够有效降低延迟,减少系统互连所需要的电缆、光缆数量,降低互连成本[2]。
高阶路由器所面临的最大挑战之一就是怎样设计可扩展的路由器微体系结构。基于Crossbar的交换结构能够实现非阻塞通信并且能够确保绝对的公平性,保证路由器有较好的性能。但是,一个阶数为N的单级Crossbar交换结构,由于内部连线资源、仲裁逻辑复杂度、消耗的缓冲区资源按照O(N2)的速度增长,仅仅扩展单级Crossbar交换结构阶数的代价将变得不可接受。层次化交叉开关的设计能够有效地克服传统交换结构的局限性[2],提高性能,并且已经得到了成功的应用[3],基于瓦片(tile)的交换结构也十分整齐,易于扩展,十分适合高阶路由器的设计,学术界也不断对基于tile结构的路由器进行新的设计[4],在不影响性能的情况下可减少总的硬件开销。
但是,路由芯片想要向更高的阶数扩展,仍然要受到当前集成电路工艺的限制。集成电路工艺制程的升级对于各种不同类型的路由芯片的性能提升和功耗优化都起着重要作用。在过去很长一段时间,集成电路的工艺进步一直都在沿着摩尔定律发展。目前,IC制造可量产工艺已达到7 nm,并向5 nm及3 nm推进。每一代工艺节点的进步,都会使芯片具有更高的集成度,I/O管脚的数量、带宽也都不断增加,使得一个路由器上可以集成更多的端口数,芯片上也能够集成更多的高速串行接口。然而,先进的集成电路工艺制程将会导致成本的急剧增加,7 nm工艺单次全掩膜流片甚至已经超过10亿元人民币。由于高昂的成本,通过集成电路工艺制程的升级带给路由芯片集成度及频率提升的性价比越来越低。此外,摩尔定律[5]以及登纳德缩放比例定律(Dennard Scaling)[6]的放缓和停滞同样加剧了这一问题。摩尔定律指出,集成电路上可以容纳的晶体管数目大约每经过18个月便会增加一倍。登纳德缩放比例定律表明,随着晶体管面积的不断缩小,其消耗的电压和电流也会以差不多相同的比例缩小。因此,提高芯片频率增加的动态功耗会和减小的静态功耗相抵消。进入21世纪以后摩尔定律开始出现了放缓的迹象,摩尔定律预测的与芯片的实际性能在2018年甚至出现了15倍的差距。登纳德缩放比例定律在2007年后出现显著的放缓,到2012年几乎失效。因此,通过单芯片集成的设计方式来扩展路由器的阶数,在未来将会变得越来越难以接受,有必要为高阶路由器设计一种新型的交换结构。
本文首先介绍高阶路由器设计的相关工作以及Chiplet技术的背景知识和采用Chiplet技术进行高阶路由器设计的研究动机;之后提出了一种基于Chiplet架构的128端口超高阶路由器,内部的Switch Die之间采用二层胖树拓扑进行互连,并通过RTL级代码对性能进行了评估;最后给出采用Chiplet技术需要考虑的问题以及今后工作的展望。
2 研究背景
随着摩尔定律和登纳德缩放比例定律的放缓与停滞,半导体制程工艺越来越接近物理极限,目前已经实现了7 nm制程,三星公司与台积电甚至都已攻克了3 nm,正在研究1 nm先进工艺制程。但是,工艺制程提升的代价也越来越高,采用5 nm制程的芯片,从芯片的设计到流片,成本约为4.36亿美元,3 nm制程的芯片成本甚至会达到6.5亿美元,先进节点工艺技术变得更加复杂和昂贵。为了抵消这一影响,许多芯片正在变得越来越大,以继续在功能和性能方面进行新一代的改进,例如NVIDIA公司的“Volta” GPU芯片[7]面积达到了815 mm2。但是,增大芯片的面积会导致芯片的良率下降,功耗增加,大大增加芯片设计的难度,也无法获得较好的应用。为了缓解半导体工艺不断接近物理极限带来的问题,近几年来,工业界和学术界都在研究基于“Chiplet”概念的片上系统SoC(System on Chip)设计,即将一个面积较大的单片SoC分解成多个面积更小、产量和成本效益更高的小芯片,使用特定的高级封装技术进行重新整合。当前已经出现了成功利用Chiplet设计的芯片,例如NVIDIA公司的MCM-GPU[8],Marvel公司的MoChiTM(Modular Chip)架构[9],美国国防部高级研究计划局DARPA(Defense Advanced Research Projects Agency)也在2017年推出了聚焦Chiplet关键技术的CHIPS(Generic Heterogeneous Integration and IP Reuse Strategy)项目[10]。
Chiplet技术站在系统重组的角度,在对系统复杂功能予以逐一分解的基础上,以特定功能开发为目标,对系统的计算、数据流管理、数据存储和信号处理等功能进行了更为细致性的分类开发,将一个大型片上系统分解成多个具有特定功能的芯片裸片(Die),这些Die可以是相同的,也可以是不同的,在多个Die集成的形式下形成芯片网络。这种做法能够在系统功能聚集的基础上,最大程度简化芯片元件的复杂程度,能够打造出更具紧凑性、功能性的新型计算机系统结构,而所采用的Die相较于一块大的芯片,由于面积较小,良率会更高,并且都是经过验证的已知合格裸片KGD(Known Good Die),采用这种多Die集成的芯片设计方式,能够缩短芯片的研发周期,降低芯片生产成本[11]。
同时,采用Chiplet技术也能够暂时缓解芯片设计面临的“卡脖子”问题。在晶圆厂设备受限,很难做到最先进的工艺,并且无法获得先进工艺技术的情况下,利用已有的芯片技术进行迭代开发,设计出新一代的芯片,将会成为芯片设计的必然趋势。因此,Chiplet技术为突破工艺的限制,采用已有的路由芯片进行迭代开发,设计新一代更高阶数的路由芯片,提供了一种新的思路。
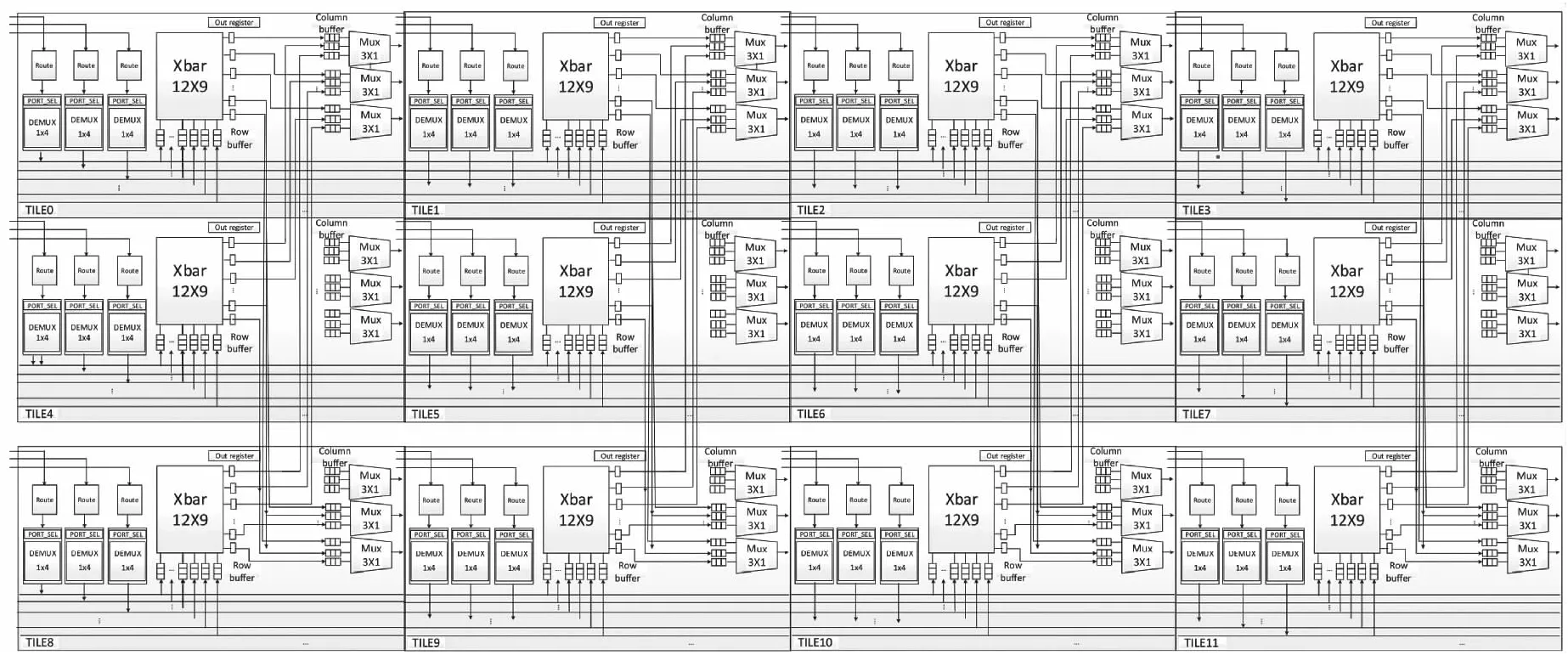
Figure 1 Microarchitecturel of MBTR router 图1 MBTR 微体系结构图
3 高阶路由器面临的挑战
传统的大规模互连网络是由端口数较少的低阶路由器构建的,但半导体工艺的进步使得芯片集成度越来越高,集成了更多的I/O管脚数,带宽也不断提高[12],这使得路由器向更高阶扩展成为可能。同时,由于信号速率的增长速度快于网络协议中所发送数据包大小的增长速度,每个路由芯片上多个窄通道的性能会好于数量较少的宽通道的性能[13]。当今的大规模互连网络大部分都是由具有更多端口数、较低端口带宽的高阶路由器构建的,学术界和工业界也都提出和设计了许多高性能的高阶路由器。
为了解决高阶路由器复杂度日益增长和高阶输入队列交换机性能低的问题,学术界提出了层次化交叉开关结构(Hiera)[2],随后被应用于Cray公司研发的YARC(Yet Another Router Chip)芯片中[3],这是早期高阶路由器设计中运用模块化设计的一个成功案例。采用基于瓦片(tile)结构的64端口交换结构,将阶数为64的高阶路由器分解为64个瓦片,由瓦片作为基本单元进行模块化设计。报文仲裁被分解为多级分布式的异步仲裁,降低了仲裁的复杂度;同时,每个瓦片的结构相同,使得路由器内部的结构非常规整。
但是,由于较高的存储资源需求以及更为复杂的全局布线,当路由器的阶数不断增加时,每个tile的仲裁逻辑、存储资源和全局布线复杂度都会线性地增加,YARC结构不具有较好的可扩展性。一种基于tile结构的聚合端口路由器MBTR(Multiport Binding Tile-based Router)[4]通过在每个tile内绑定多个物理端口,减少tile的数量,从而降低硬件开销。一个阶数为64的MBTR路由器,相较于同阶数的Hiera结构路由器,在性能相同的情况下,能够降低50%~75%的存储开销和布线资源。阶数为36的MBTR路由器结构图如图1所示。
虽然基于tile结构的高阶路由器能够提供较高的性能,但是布线和中间缓冲区资源的开销都十分高昂,学术界也探索了高阶路由器交换结构网络化的方法,提出将高阶路由器的交换结构利用构建网络的思想来实现[14]。通过由多个低阶Switch互连组成的网络来实现高阶路由器内部的交换功能,这种方法能够使高阶路由器具有更好的可扩展性,并且能够大幅度降低布线的复杂度及缓存资源。
但是,上述路由器微体系结构都是针对单芯片集成的方式设计的。随着芯片制程的不断发展,单个芯片所能集成的串行器/解串器SerDes(Serializer/Deserializer)高速差分I/O引脚数目并没有显著提升,这意味着通过制程的提高来增加SerDes数目的方式将变得越来越难,若要在芯片中集成更多的端口就势必要牺牲每个端口的带宽。而Chiplet技术则为路由器微体系结构的设计提供了新的方法,例如,路由芯片往往需要提供高密度的高速串行接口,传统的交换芯片是将交换逻辑与高速接口逻辑在一个芯片内实现,采用Chiplet技术,可以将SerDes集成为I/O Die,通过Switch Die和多个I/O Die的集成使得芯片带宽不局限于SerDes集成数目,具有更好的可扩展性。交换逻辑作为芯片中最重要的功能部分,用最先进的工艺来实现能够获得较大的收益,而I/O接口则可以使用较为成熟的工艺实现。Intel公司利用Chiplet的思想,将交换逻辑(7 nm工艺)与多个高速SerDes 集成的I/O接口(12 nm工艺)分成不同的Die实现,再通过特定的高级封装技术整合在一起,设计出了具有12.8 Tb/s高带宽的Tofino2[15]路由芯片。
Chiplet技术为芯片交换能力的提升和灵活配置提供了一种全新的思路,同时也使路由器不断向更高阶数扩展成为可能。由于工艺的限制,未来采用单片集成的方式在路由芯片中集成更多的管脚数和更高的单引脚带宽将会变得越来越难,芯片的总体带宽难以持续增加,增加路由器的阶数将以减小每个端口的带宽为代价。
采用Chiplet架构,可以将基于tile的交换结构与网络化交换结构的方法相结合,利用多个已知合格芯片,例如MBTR,通过高效的高阶拓扑实现阶数的灵活扩展,既克服了基于tile的交换结构向更高阶数扩展时所面临的缓冲区资源和布线复杂度不断增加的问题,又能够保证较高的性能,同时也克服了单芯片带宽所受到的SerDes集成数目的限制。并且,由于采用的Switch Die是已经经过验证的合格裸片,在芯片的设计过程中能够简化验证过程,缩短研发周期,实现利用已有的路由芯片进行高效的迭代开发,构造新一代更高阶数的路由器。
4 基于Chiplet的超高阶可扩展路由器设计
在了解了Chiplet的相关设计思想,并研究了高阶路由器所面临的挑战之后,本文提出了一种基于Chiplet的超高阶可扩展路由器设计,利用已有的36端口MBTR路由芯片作为Switch Die,模拟采用二层胖树拓扑实现Switch Die之间的互连,构造了实际端口数为128的更高阶数的路由器。
4.1 Switch Die间互连拓扑
胖树拓扑是超级计算机最常用的拓扑结构之一,Cray公司早期的计算机XD1就是利用低阶路由器搭建的胖树拓扑结构实现的,而后Cray公司又使用阶数为64的YARC结构路由器搭建胖树拓扑,应用于BlackWidow计算机中。国防科技大学自主研制的天河系列超级计算机也一直沿用的是高阶胖树拓扑结构。胖树拓扑结构最大的优势在于当网络规模增大时,网络的等分带宽也能同程度地增加,网络的性能较好,通过增加更多的路由芯片进行报文转发,有效避免了网络路径唯一性和负载不均衡的缺点。
该高阶路由器内部的Switch Die互连拓扑结构如图2所示,内部是一个2层胖树网络,共由12个Switch Die构成,其中8个组成胖树的第1级结构,每个Switch Die中16个端口用于与终端结点相连接,总共能连接128个终端节点,16个端口分别用于与第2级的4个Switch Die之间进行互连,第1级与第2级的每2个Switch Die之间通过4个端口实现互连。对于每个36端口的MBTR Switch Die,构建2层胖树拓扑只需要其中的32个端口,有4个端口未被使用。而所采用的36端口MBTR Switch Die是已经得到成熟验证和应用的路由芯片,能够简化路由芯片的设计与开发,并且能实现高吞吐率及低延迟,Switch Die的阶数与构建拓扑的实际需求相差不大,因此无需重新设计32端口的芯片。

Figure 2 Fat tree topology for Switch Die interconnection图2 用于Switch Die间互连的胖树拓扑
在该拓扑中,任意2个终端结点之间报文的传输最多只需要2跳,路由器的有效阶数可扩展为128。
4.2 报文仲裁过程
报文在由多个Switch Die构成的高阶路由器内的传输过程,其实就是报文在Switch Die构成的网络中的传输过程。
MBTR结构将一个N×N的交换结构,用(N/A)个tile按照R×C的矩阵排列实现,每个tile内的子交叉开关的规模为m×n,其中,A为一个tile内聚合的物理端口数,R和C分别为每行和每列的tile数量,m和n分别为子交叉开关行缓冲和列缓冲的数量。对于构成该胖树拓扑的36端口的MBTR Switch Die,是由12个tile按照3×4的矩阵构成,一个tile内聚合了3个物理端口。
由于第1级与第2级的每2个Switch Die之间通过4个端口实现互连,因此路由表的配置需要考虑多路径路由和负载均衡。对于每个Switch Die,配置了不同的路由表,而单个Switch Die中每个输入端口都集成了相同的路由表。对于第1级Switch Die的路由表配置,每个Switch Die需要对去往128个目的端口的流量进行负载均衡,由于有16个目的端口位于本地Switch Die,因此只需要将去往位于其它Switch Die的112个目的端口的流量按照16个上行端口进行负载均衡的配置,即每条上行链路分别对去往非本地Switch Die的7个目的端口的上行流量进行传输;而对于第2级的4个Switch Die,由于只负责流量的转发,路由表的配置则按照与第1级Switch Die的互连方式进行配置,即去往某个第1级Switch Die 16个目的端口的下行流量,由4条下行链路分别进行传输,每条下行链路分别传输去往4个不同端口的流量。
当报文到达第1级Switch Die的输入端口时,首先被储存在输入缓冲区中,通过路由计算单元计算出目的端口所在tile的行号、列号和输出端口号,如果该报文的目的端口位于当前Switch Die,则报文在路由器内部的传输过程就是在当前Switch Die内的传输过程:虚通道VC(Virtual Channel)仲裁器按照轮询的方式从缓冲区中选择一个报文,通过一个1×4的多路分配器,根据行号进入该输入端口对应的行缓冲;子交叉开关设置有2级仲裁,每个VC仲裁器从多个VC的报文请求中选择一个报文,端口仲裁器将会从VC仲裁器选出的报文中,根据列号和输出端口号,将报文传输到对应的列缓冲中;当报文到达列缓冲的队列头部时,报文将会通过一个3×1的多路选择器发送到输出链路;如果该报文的目的端口位于其它的Switch Die,那么还需要通过上行链路发送到对应的第2级Switch Die,之后,通过相同的仲裁过程和下行链路最终到达目的端口所在的第1级Switch Die的输出端口,由终端结点接收或者进入其它的路由器。
5 实验与结果分析
5.1 性能评测
为了测试基于Chiplet的超高阶路由器的性能,本文使用真实工程中的RTL代码进行实验仿真,搭建了由12个Switch Die构成的2层胖树网络,其中第1级8个Switch Die的16个端口用于连接终端结点,16个端口用于Die间的互连,第2级的4个Switch Die的32个端口全部用于Die间的互连。同时构造了128个终端结点,分别用于与第1级8个Switch Die的16个注入端口连接,用于产生流量,模拟链路层行为,例如基于信用的流控机制、随机的物理错误等等,因此该基于Chiplet的超高阶路由器实际阶数为128。本文测试了在均衡流量模式和非均衡流量模式下,系统的延迟和吞吐率性能。一个报文的延迟按照报文的第1个flit到达某个输入端口开始,直到报文的最后1个flit离开某个输出端口来计算。在热点流量模式下,每个终端结点产生报文的目的端口集中于前三分之一的端口,在指数流量模式和泊松分布流量模式下,报文的目的端口分别呈指数分布和泊松分布。
图3显示的是不同流量模式下,该高阶路由器的系统吞吐率,并与单个MBTR路由器的性能进行了对比。可以看到,该128端口的基于Chiplet的超高阶路由器,在均衡流量模式的满负载情况下,系统吞吐率能够达到98%,与MBTR相同,但是在指数流量模式和泊松流量模式下,吞吐率分别降低了27%和72%。这是由于所有目的输出端口的不同报文存储在同一个缓冲区里造成的,目的端口分布不均匀将会导致头堵塞(Head-of-Line Blocking),对性能产生较大的影响,当报文需要在多个Switch Die间传输时,性能会进一步下降。
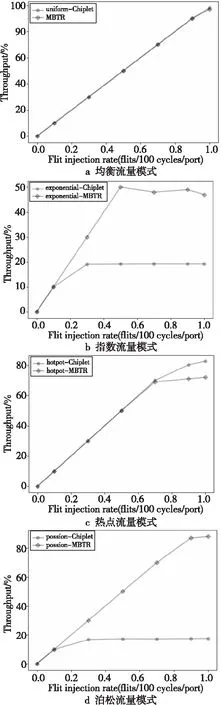
Figure 3 Throughput comparison of two routers under different traffic models图3 不同流量模式下2种路由器吞吐率对比
报文的延迟性能有着类似的结果,由于基于Chiplet的路由器报文的传输需要经过多个Switch Die,相较于单个MBTR路由器延迟必然更高。不同流量模式下Chiplet结构路由器的报文延迟如图4所示,在均衡流量模式下,flit的平均延迟较低并且在负载较高的情况下比较稳定,而在目的端口分布不均匀时,同样会出现由于队列头阻塞导致的性能下降问题,flit的平均延迟较高。

Figure 4 Average flit delay of Chiplet router under different traffic models图4 不同流量模式下Chiplet路由器平均flit延迟
5.2 未来工作
本文针对采用Chiplet技术设计超高阶可扩展路由器时,根据胖树拓扑性能较好的特点,提出了一种可行的Switch Die间互连拓扑方案。在实际的Chiplet架构设计中,还需要结合具体的封装技术以及Die间互连接口。
目前,采用基板的封装技术应用较为广泛,成本较低,在许多的Chiplet系统中都得到了成功的应用[16,17]。但是,由于基板主要采用的是引线键合或倒装技术,I/O引脚的密度较低,芯片的大部分引脚被电源占用,因此用于数据传输的引脚十分稀少,Die间的互连必须要采用超短距离的高速SerDes。
采用硅中介层的封装技术,是2.5D封装技术的主要形式,所谓的2.5D封装,是在基板上放置硅中介层,再将多个Die放置在硅中介层上,通过微凸点以及硅通孔技术,能够实现更小的凸点间距和走线距离。相对于基于基板的封装,基于硅中介层的封装可以实现更高的I/O密度,因此Die间的互连接口主要采用并行接口。
因此,在未来将会考虑具体的封装技术。对于不同的封装技术,所适用的Die间互连接口也不相同。基于基板的封装常采用串行接口,虽然传输速率较高,对I/O引脚的需求较低,但当数据传输速率较高时,需要适合的前向纠错机制来确保数据传输的准确性,因此会引入较高的数据传输延迟。而以硅中介层封装技术为代表的2.5D封装技术和3D堆叠技术,具有较高的I/O引脚密度,虽然封装成本较高,但可以采用传输速率较低但准确性较高的并行接口,例如Intel的高级接口总线AIB(Advanced Interface Bus)[18]和台积电的LIPINCON[19],能够实现较低的数据传输延迟。对于基于Chiplet的高阶路由器设计,为了实现Switch Die间的高效通信,除了设计高效的Die间互连拓扑之外,不同的封装技术以及Die间互连接口的选择对Chiplet系统的整体成本及性能有着不同的影响,需要在各种影响因素之间进行权衡,同时也会搭建其它的主流高阶拓扑进行对比评测,结合拓扑、互连接口和封装技术等因素,在多种方案中选取最优的设计方案。
6 结束语
本文针对目前高阶路由器设计在可扩展性、成本及功耗方面面临的挑战,结合Chiplet设计思想,设计和模拟实现了一种基于Switch Die间互连的超高阶路由器体系结构。采用2层胖树拓扑实现了12个可重用Switch Die间的互连通信,并将路由器阶数扩展至128。分别在均衡流量模式和非均衡流量模式下测试了该体系结构吞吐率和延迟随负载变化的情况,在最常见的均衡流量模式下,该Switch Die互连拓扑能够实现较好的性能。未来也会搭建其它的主流高阶拓扑进行评估,选择最优方案。
猜你喜欢
汽车电器(2022年9期)2022-11-07
科教新报(2022年24期)2022-07-08
作文小学中年级(2021年10期)2021-12-26
科教新报(2021年23期)2021-07-21
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
空间科学学报(2021年6期)2021-03-09
哈尔滨轴承(2020年1期)2020-11-03
铁道通信信号(2020年4期)2020-09-21
北京航空航天大学学报(2019年9期)2019-10-26
中国外汇(2019年11期)2019-08-27
