
基于软件定义的WSNs非均匀分簇QoS路由算法*
2022-03-22 04:12苟平章
计算机工程与科学 2022年2期
苟平章,原 晨,张 芬
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
随着无线传感器网络WSNs(Wireless Sensor Networks)[1]的普及,其数据类型逐步多样化,应用场景逐步增多,网络对路由协议服务质量QoS(Quality of Service)[2]的要求也逐渐提高。但是,传统WSNs的局限性使得QoS路由也面临诸多问题,如节点能量受限的特性使得节点无法进行大量复杂的QoS指标参数计算;节点处理数据的能力和存储空间有限,导致网络QoS无法进一步提高;无法根据不同QoS需求实时动态地调整网络路由;路由协议多为分布式,通过邻居节点信息交换来计算路径,导致路由算法仅在局部能得到最优结果,进而影响网络QoS。因此,如何有效地提高网络QoS仍然是一个具有挑战性的问题。另一方面,在WSNs路由领域中,为提高能量效率,研究人员提出基于分簇原理的层次型路由。LEACH(Low Energy Adaptive Clustering Hierarchy)协议[3]是最早的分簇路由协议,能有效降低节点能耗,延长网络生命周期,但随机性的簇头选举策略导致节点能耗不均衡。为缓解能量黑洞的现象,EEUC(Energy-Efficient Uneven Clustering)协议[4]通过节点竞争半径公式将网络分为大小不同的簇,平衡各簇头间的能量消耗,但簇头算法仍然采取随机的方式,导致簇无法达到最优。CRIPSO(Clustering Routing protocol based on Improved PSO algorithm)[5]通过优化粒子群优化算法的惯性系数和学习因子,平衡算法的全局搜索与局部探索能力,选举出能量和位置合理的簇头节点。
软件定义网络SDN (Software Defined Network)[6]是一种新型网络架构,是网络虚拟化的一种实现方式。SDN通过分离控制平面和数据平面以及开放通信协议,打破了传统网络设备的封闭性[7]。其整体框架分为应用层、控制层和数据层,应用层包含各种网络业务,给用户提供实现和部署网络应用的接口;控制层通过网络状态信息,获取网络拓扑与视图,制定并下发数据转发规则;数据层负责数据的处理、转发和状态的搜集[8]。将SDN与WSNs相结合,形成的软件定义无线传感器网络SDWSN (Software Defined Wireless Sensor Network)将成为下一代WSNs技术探索的主流方向[9]。Luo等人[10]结合WSNs应用需求,提出基于SDN的Sensor OpenFlow架构,旨在对SDWSN南向接口协议进行标准化,通过启用传感器节点的可编程性,增强网络控制。Gante等人[11]提出一种新型的基于SDN的WSNs基站架构,传感器节点不必做出路由决策,而由网络管理员通过控制器提供的全网拓扑视图做出最佳决策,提高传输效率并减少节点能耗。文献[12]提出扰动粒子群优化的SDWSN路由算法tPSOEB (extremum disturbed Particle Swarm Optimization based Energy-Balanced routing protocols),采用SDN集中式的计算方式,通过引入扰动改进粒子群优化算法的搜索性能,进行簇头选举与非均匀分簇。
随着SDWSN理论逐渐成熟,针对网络QoS的路由策略也逐渐应用其中。文献[13]提出一种软件定义的WSNs控制器实现方式,采用基于模糊逻辑算法和贝叶斯推理的方案,确定WSNs中合适的端到端QoS路径。Dio等人[14]为了提高网络QoS,通过对节点拥塞状态和数据等级的划分设置不同的丢包率,提升了网络性能,但未涉及到路由协议。为了解决SDWSN中的路由节能问题,文献[15]提出一种集中式路由算法IA-EERA(Interference-Aware Energy-Efficient Routing Algorithm),同时考虑链路QoS和负载平衡问题,以延长网络生命周期。文献[16]提出一种QoS路径选择和资源关联方案Q-PSR (QoS Path Selection and Resource-associating),用于自适应负载平衡和智能资源控制,实现最佳网络性能。
在上述研究基础上,本文提出一种基于软件定义的无线传感器网络非均匀分簇QoS路由算法SDNUCQS(Software-Defined Non-Uniform Clustering QoS routing algorithm)。初始阶段,控制器执行全网拓扑发现及信息收集过程,建立网络拓扑图,获取所需的网络信息。分簇阶段,控制器以节点能量、节点间距离、传输时延和传输丢失率为指标,采用熵权法竞选出针对QoS的高质量簇头,根据竞争半径公式将网络分成大小不同的簇。簇间路由阶段,利用交叉分类法将所要传输的数据以时延和丢失率为参数分为不同种类。对于有QoS需求的数据,采用Dijkstra算法计算最佳路径;对于无QoS需求的普通数据,先计算节点负载度,并以此为参数,采用Dijkstra算法计算最佳路径,达到网络负载均衡的目的。
2 系统模型
2.1 SDWSN体系结构
SDWSN中控制器部署方式有3种,分别为单控制器部署、水平多控制器部署和层次化多控制器部署。本文采用水平多控制器部署方式中的SDN-WISE(Software Defined Networking solution for WIreless SEnsor networks)[17]体系结构实现WSNs的SDN化。SDN-WISE体系结构如图1所示。
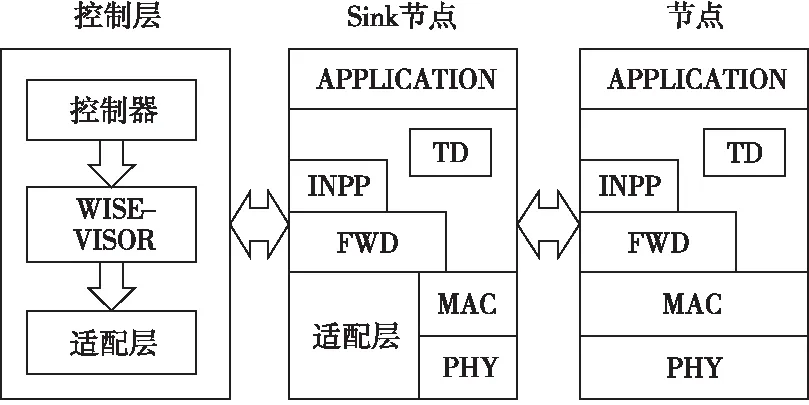
Figure 1 SDN-WISE architecture 图1 SDN-WISE体系结构
图1的SDN-WISE体系中,基于IEEE 802.15.4和MAC(Multiple Access Channel)层构建传感器节点,Sink节点与控制器之间设计有适配器,用来格式化传输的数据。FWD(ForWarDing)为转发层,按照WISE流表中的指示处理匹配成功的数据包。网内数据包处理层INPP (In-Network Packet Processing)用于进行数据融合或处理数据包。TD(Topology Discovery)层用来维护邻居节点列表,辅助控制器进行拓扑发现。控制层中,WISE-VISOR受控制器管理,用于提取网络资源,以便不同管理策略或逻辑网络可在同一物理设备上执行。控制器和WISE-VISOR共同决定网络逻辑。节点根据流表匹配结果进行数据包转发。流表由3部分组成:用于数据包匹配的匹配域(Matching Rule)、用于统计匹配数据包个数的统计域(Statistics)和用于展示匹配数据包处理方式的操作域(Action)。节点流表图如图2所示。

Figure 2 Structure of flow table 图2 流表结构
2.2 网络模型
本文WSNs模型由传感器控制服务器、Sink节点,以及随机分布在M×M大小的检测区域中的N个传感器节点组成。相关网络模型约束为:
假设1所有传感器节点随机分配在检测区域内,并且其位置在整个生命周期中不会发生改变,与Sink节点和控制器的关系位置同样也是固定的。
假设2所有传感器节点具有相同的初始能量,每个节点拥有唯一的ID标识,均有机会充当簇头。
假设3节点的发射功率能够根据传输距离自动调整。
假设4传感器控制服务器仅有一个且能量不做限制。
2.3 能耗模型
能耗模型采用经典的无线传输能量消耗模型[18],如图3所示,当传输kbit数据时,发送端的能耗为传输电路消耗和信号放大电路消耗;接收端能耗为信号接收电路能耗。
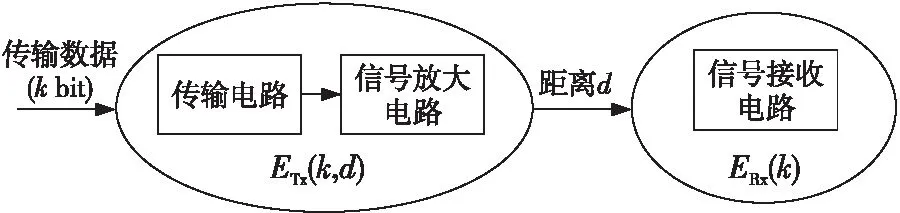
Figure 3 Energy consumption model图3 能量消耗模型
根据发送节点和接收节点之间的距离,采用自由空间和多路径衰减模型,节点发送kbit数据到距离为d的节点消耗的能量如式(1)所示:
(1)
其中,Eelec表示接收或发送数据时的电路功率消耗系数,εfs为自由空间模型的放大倍数,εmp为多路径传输模型的放大倍数,d为节点间距离,d0为通信距离分界值,其计算如式(2)所示:
(2)
节点接收kbit数据消耗的能量如式(3)所示:
ERx(k)=kEelec
(3)
3 SDNUCQS路由算法
SDNUCQS算法包括拓扑发现阶段、簇的形成阶段、簇间路由建立和数据传输4个阶段。拓扑发现阶段,控制器获取网络拓扑图及其他所需信息。簇的形成阶段,采用熵权法,结合QoS指标,竞选出针对网络QoS的高质量簇头,并进行非均匀分簇。簇间路由阶段,控制器根据时延和丢失率将数据分类,对不同数据有针对性地制定最佳传输路径,并下发流表。数据传输阶段,簇头收集簇内节点数据并按照流表规则进行数据传输。
3.1 拓扑发现及信息收集
在网络初始化阶段,控制器需要进行拓扑发现和信息收集流程,其目的在于获取网络数据平面拓扑图及其他信息(网络QoS指标、节点剩余能量)。控制器通过Sink节点下发拓扑发现包(TD),TD信息包括节点剩余能量,与Sink节点间的距离,以及端到端QoS参数(包括时延和数据丢失率)信息等。
图4所示为拓扑发现过程,节点A广播TD(A),节点B接收到TD(A)后,首先将A的剩余能量、QoS参数等信息保存起来,并将A加入至其邻居节点列表中;其次比较A和B到Sink节点的跳数大小,若A到Sink节点的跳数大于B的,则B到Sink节点的跳数为A的加一,并规定B到Sink节点的下一跳为A;最后B广播TD(B)。通过此流程直至全网节点皆完成广播,将所有数据发送至Sink节点,最终Sink节点将数据发送至控制器。控制器得到数据后,建立全网拓扑图并拥有节点剩余能量、节点间距离、邻居节点列表和QoS参数。
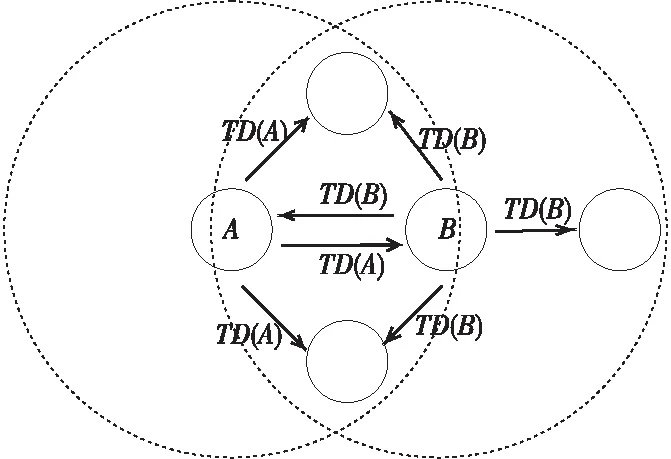
Figure 4 Process of topology discovery 图4 拓扑发现过程
3.2 基于熵权法的簇头选举
熵权法是一种客观赋权法,依赖于数据本身的离散程度。传统分簇路由的簇头选举多为多指标加权和的形式,人为确定各数据指标的权重大小,使数据所占比重缺乏客观性,导致理论上选举出的簇头与实际最优簇头存在偏差。本文结合QoS指标,采用熵权法进行簇头选举,对数据进行客观度量。簇头选举流程包括数据指标分析、节点评估、簇头确定和分簇4个阶段。
3.2.1 数据指标分析
通过剩余能量、平均向心距离、平均向心链路连通度和平均向心端到端时延4个数据指标对节点进行评估。
假设节点竞争半径范围内有n个节点,而每个节点有4个指标,则第i个节点的第m个指标可描述为xim(i=1,2,…,n;m=1,2,3,4)。
(1) 节点剩余能量。剩余能量越高,越容易成为簇头。设竞争半径内第i个节点的剩余能量为xi1=Ere(i),Ere(i)为第i个节点的剩余能量。
(2) 平均向心距离指竞争半径内其他节点与该节点之间距离的平均值。该值越小,越容易成为簇头。第i个节点的平均向心距离如式(4)所示:
(4)
其中,d(i,j)表示第i个节点和第j个节点间的距离。
(3) 平均向心链路连通度表示竞争半径内其他节点向该节点传输数据完整率的平均值。平均值越高,该节点越容易成为簇头。竞争半径内第i个节点的平均向心链路连通度如式(5)所示:
(5)
其中,s(j,i)和f(j,i)分别为第j个节点向第i个节点发送数据包成功到达的大小和发送数据包的大小。
(4) 平均向心端到端时延指节点竞争半径内其他节点向该节点传输数据端到端时延平均值。该值越低,节点越容易成为簇头。竞争半径内第i个节点单位数据传输时延如式(6)所示:
(6)
其中,t(j,i)表示第j个节点向第i个节点发送1 bit数据所用时间。
3.2.2 节点评估
使用熵权法对节点指标进行计算,得到节点综合实力。具体步骤如下所示:
步骤1指标归一化处理。指标分为正向指标和负向指标,正向指标数值越高越好,负向指标数值越低越好,因此,对于正向指标和负向指标需要采用不同的算法进行数据标准化处理。
剩余能量和平均向心链路连通度是正向指标,正向指标归一化公式如式(7)所示:
(7)
平均向心距离和单位数据传输时延为负向指标,负向指标归一化公式如式(8)所示:
(8)
其中,x′im表示经过归一化处理后第i个节点的第m个指标值,xim为第i个节点的第m个指标,min(xim)和max(xim)分别为指标函数最小值和最大值。
步骤2计算各个指标下,每个样本的数据分析指标占总指标的比重。竞争半径内第i个节点的第m个指标所占总指标比重如式(9)所示:
i=1,2,…,n;m=1,2,3,4
(9)
步骤3计算各个指标的熵值。第m项指标的熵值如式(10)所示:
(10)
步骤4计算各指标信息熵冗余度,如式(11)所示:
Dm=1-Em,m=1,2,3,4
(11)
步骤5计算各指标的权重,如式(12)所示:
(12)
步骤6通过指标数值及权重,计算各节点的综合实力S。竞争半径内第i个节点的综合实力Si如式(13)所示:
(13)
3.2.3 簇头确定及分簇
在SDWSN中分簇流程由控制服务器完成,极大地节省了节点能耗,具体流程如下所示:
步骤1节点竞争半径的确定。为缓解网络“热区”问题,本文采用文献[4]的节点竞争半径计算公式,如式(14)所示:
(14)
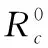
控制器按照式(14)计算每个节点的竞争半径,并为其维护一个邻居列表NL(Neighboor List),用来保存竞争半径内的节点ID。
步骤2节点评估。控制器通过上述熵权法流程依次计算每个竞争半径内所有节点的综合实力S,并计算各个节点成为簇头的优先级,如式(15)所示:
(15)
其中,pri(i)表示节点si的优先级,NLi为节点si邻居列表,n(NLi)表示节点si邻居节点个数,S(i)表示节点si通过熵权法计算后的节点综合实力。
步骤3簇头确定。控制器根据计算得到的节点优先级从大到小排序,得到簇头竞选列表CHC(Cluster Head Competition list),并建立簇头列表CH(Cluster Head list),依次将CHC中节点ID放入CH中,每放进去一个,则删除存在于CHC中的邻居节点,直到CHC为空。对于同时属于多个簇的节点,则选择距离最近的簇头加入该簇,最后所有节点有且仅有一个归属簇,至此分簇完成。
步骤4下发分簇规则。控制器计算得到簇头及簇成员集合后,将簇成员信息发送到对应簇头,簇头收到信息后生成对应流表项,并生成簇成员通知信息,发送到簇内各节点。
3.3 簇间路由
簇间路由阶段,根据时延和丢失率将数据分类,控制器针对不同类型数据制定路由策略。
3.3.1 数据分类
利用交叉分类法,依据传输时延和丢失率,将数据分为4类,如表1所示,其中前3类为QoS需求数据,第4类是普通数据。表1中0代表不敏感,1代表敏感。
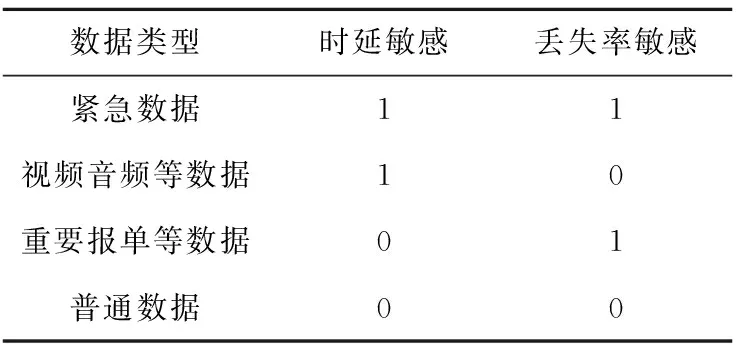
Table 1 Data classification
3.3.2 有QoS需求数据的路由
由表1可知QoS数据分为3类:时延敏感型数据、丢失率敏感型数据、时延和丢失率均敏感型数据。
对于时延敏感型数据,控制器根据簇头信息建立网络拓扑结构,结合链路信息得到每条链路的端到端时延,以时延为链路权值,通过Dijkstra算法计算每个簇头节点到Sink节点的最佳路径,如式(16)所示:
rtime(i,e)=argsmin∑r(h,j)∈rs(i,e)T(r(h,j))
(16)
其中,rtime(i,e)表示节点si到Snik节点时延敏感型数据传输的最佳路径,rs(i,e)表示节点si至Sink节点的路径集合,r(h,j)表示相邻节点sh和sj的路径,T()表示链路时延。
对于丢失率敏感型数据,控制器同样建立网络拓扑结构,并得到每条链路的传输丢失率,但由于丢失率为乘性系数,应先取对数后再采用Dijkstra算法计算路径,如式(17)所示:
rloss(i,e)=argsmin∑r(h,j)∈rs(i,e)lnL(r(h,j))
(17)
其中,rloss(i,e)表示节点si至Sink节点丢失率敏感型数据的最佳路径,L()表示链路传输丢失率。
对于时延和丢失率均敏感型数据,为了对链路的时延和丢失率分配客观权重,控制器首先使用熵权法,以链路端到端时延和传输丢失率作为数据指标,计算出网络中每条链路的综合得分;其次以链路得分为度量,采用Dijkstra算法计算出节点到达Sink节点的最佳路径。
具体流程如下所示:
步骤1控制器建立有向连通图,得到全网中簇头节点间的b条链路,将各链路端到端时延和传输丢失率作为数据指标,设第a条链路的端到端时延和传输丢失率分别表示为xa1和xa2。
步骤2对指标进行归一化处理。时延和丢失率均为负向指标,使用式(9)处理指标数据。设归一化后,第a条链路的时延和丢失率分别为x′a1和x′a2。
步骤3通过熵权法计算,第a条链路综合得分通过式(18)计算得到,综合得分越高,链路越适合传输数据。
SCa=x′a1W1+x′a2W2,a=1,2,…,b
(18)
其中,W1表示熵权法计算出的时延权重,W2表示丢失率权重。
为了表达清晰,将式(18)重新定义为节点sz向节点su传输数据的链路得分:
SC(z,u)=W1t(z,u)+W2l(z,u)
(19)
其中,t(z,u)和l(z,u)分别表示归一化处理后节点sz和su之间的链路时延和丢失率指标值。
步骤4路径计算。因为链路得分越高,越适合作为传输路径,因此控制器以链路得分的倒数为度量,采用Dijkstra算法计算,路径公式如式(20)所示:
(20)
其中,rQoS(i,e)表示对时延和丢失率均敏感型数据的节点si至Sink节点的最佳路径,p(i,e)表示节点si和Sink节点间路径上的节点集合,SC(z,u)表示相邻节点sz和su的链路得分。
3.3.3 无QoS需求普通数据的路由
对于无QoS需求的普通节点,为了使全网节点能耗均衡,延长网络生命周期,通过式(21)计算节点负载度。节点负载度表示数据传输时接收节点相对于发送节点的工作负载大小,负载越大,则该接收节点越不适合作为下一跳节点。
(21)
其中,Cj(o)为节点sj相对于节点so的节点负载度;d(o,j)为节点so与节点sj之间的距离;dave表示网络中邻居簇头节点间距离的平均值,2节点距离越大,发送节点传输数据需要消耗的能量就越多,接收节点相对于发送节点来说负担就越重,负载度就越高;Ej表示节点sj当前能量,Eave表示整个网络中簇头节点的平均能量;Ase和Are分别表示过去的t时间内节点sj发送和接收的数据量;α、β、γ分别表示3个影响因素的权重大小且α+β+γ=1。
控制器根据网络拓扑,建立有向连通图,采用Dijkstra算法,以节点负载度为链路权值,计算每个簇头节点的最优传输路径。路径公式如式(22)所示:
rcom(i,e)=argpmin∑si,sj∈p(i,e)Cj(i)
(22)
其中,rcom(i,e)表示针对普通数据的节点si至Sink节点的最佳路径,节点so与节点sj为相邻节点。
3.4 数据传输
控制器进行路由计算后,下发流表至所有簇头节点,流表中包含了针对不同类型数据在传输时下一跳节点的地址等。当感知节点有数据需要传输时,首先将数据包发送到自己的簇头节点;然后簇头节点对接收到的数据包进行匹配,确定该数据包的类型后,根据流表规则向下一跳簇头节点发送该数据包,直至到达Sink节点;最后Sink节点将数据打包后统一发送至控制器。
3.5 SDNUCQS算法流程
本文算法通过上述4个阶段周期性进行,但为了避免频繁分簇,SDNUCQS在每一轮全局分簇后进行轮局部簇头更新。首先,在分簇阶段完成后,控制器通过3.2节中的熵权法计算各个簇内每个节点相对于该簇所有节点的综合实力S,如果节点综合实力大于δ倍的当前簇头节点综合实力,则该节点可作为预备簇头。一个簇内预备簇头的个数即该簇局部簇头更新的次数。全网簇头更新次数是所有簇的簇头更新次数的平均值,如式(23)所示:
(23)
其中,kj为第j个簇的簇头更新次数,num为全网中簇的总数。
SDNUCQS算法流程图如图5所示。
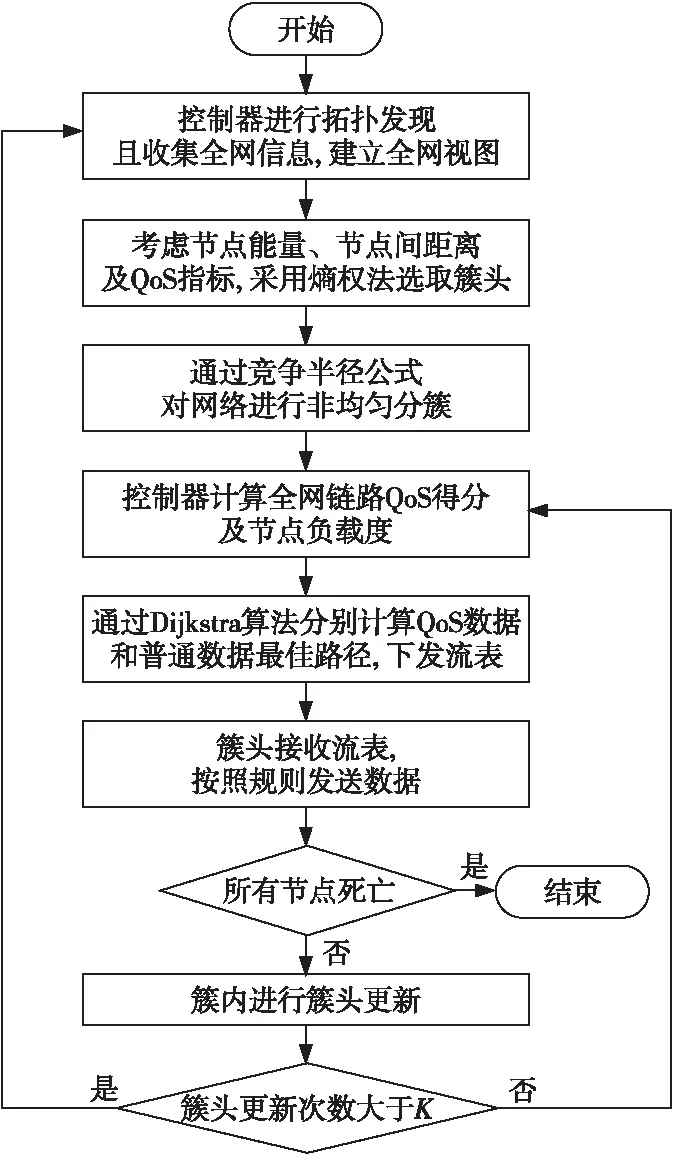
Figure 5 Flow chart of SDNUCQS algorithm 图5 算法流程图
4 仿真实验与结果分析
本文从全网簇头能耗、端到端平均时延、平均传输丢失率和网络生命周期4个方面进行仿真,以验证SDNUCQS算法的性能,参数如表2所示。
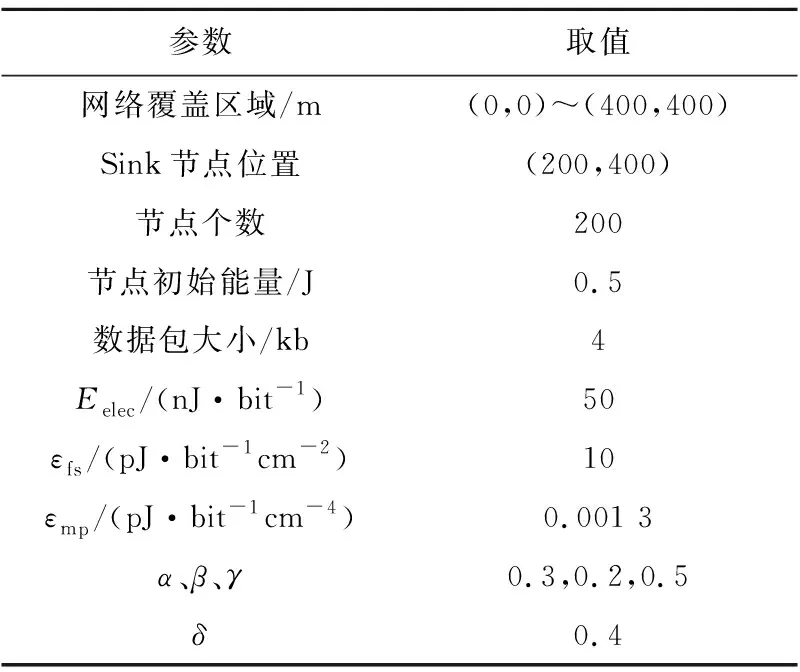
Table 2 Simulation parameter
4.1 簇头形成数量
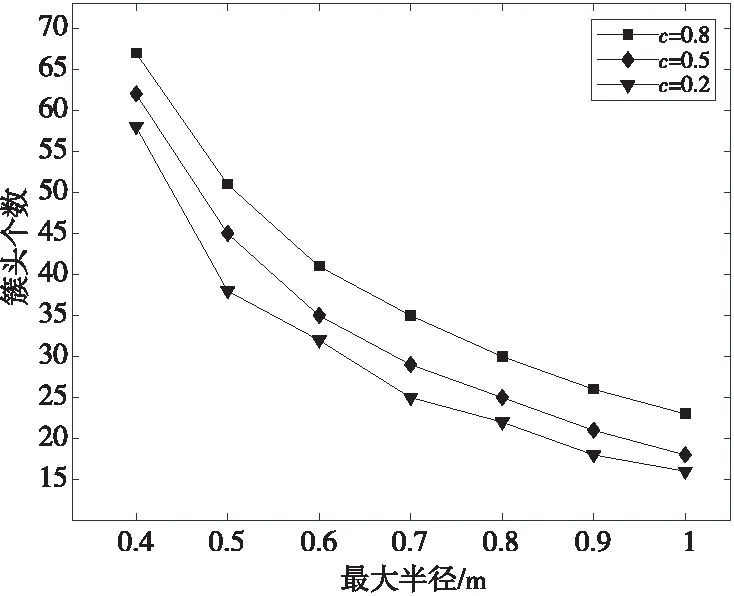
Figure 6 Number of cluster heads formed图6 簇头形成数量
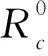
4.2 簇头能耗对比
为了验证基于熵权法的簇头选举和非均匀分簇的有效性,选取若干轮,统计分簇结束后至下一轮分簇前,簇头平均能耗,将SDNUCQS同LEACH、EEUC、CRIPSO和tPSOEB进行比较,仿真结果如图7所示。
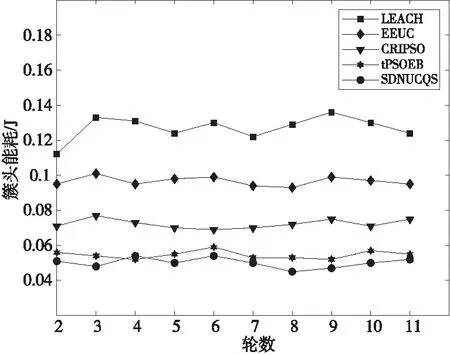
Figure 7 Cluster head energy consumption图7 簇头能耗
EEUC、CRIPSO、tPSOEB和SDNUCQS同LEACH相比较,因其采用多跳路由且非均匀分簇,簇头能耗明显降低,且波动较小。EEUC采用节点竞争半径公式实现非均匀分簇,避免能量空洞,平衡且降低簇头能耗。CRIPSO通过粒子群优化算法选举出能量和位置更加合理的簇头节点,簇头能耗相比于EEUC进一步降低了。而tPSOEB同样采用基于粒子群优化算法的簇头选举策略,但其采用SDN框架,簇头无需路由计算等能量消耗,相比CRIPSO进一步降低了能耗。本文的SDNUCQS基于SDN框架,采用熵权法进行簇头选举并进行非均匀分簇,簇头能耗大小与tPSOEB较为接近且偏低。
4.3 时延对比
图8为SDNUCQS的不同路由算法时延情况。rout1、rout2、rout3和rout4分别为时延敏感型数据、丢失率敏感型数据、时延和丢失率均敏感型数据和普通数据的路由。
Figure 8 End-to-end delay图8 端到端时延
所有路由算法时延均随运行时间而增加。rout1和rout3传输的数据均对时延敏感,其路由计算中时延低于其他2个的;由于rout3以时延和丢失率共同作为参数,因此时延略高于rout1的。而rout2和rout4路由计算不考虑时延,则时延较高,但由于rout4为普通数据路由,以节点负载度为参数计算路径,节点负载度低,间接性导致时延低,因此rout4时延略低于rout2的。rout1相较于rout2和rout4,传输时延平均降低29.62%和26.44%,rout3相较于rout2和rout4,传输时延平均降低25.57%和22.21%,由此可知SDNUCQS针对时延敏感型数据,能够显著降低端到端时延,提高网络QoS。
4.4 丢失率对比
图9为SDNUCQS不同路由数据丢失率情况,指标设置同图8。
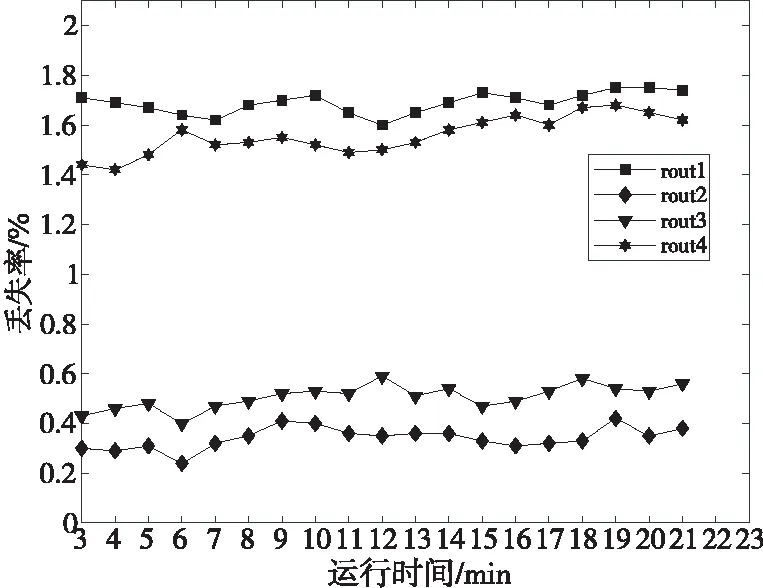
Figure 9 Loss rate图9 丢失率
rout2和rout3丢失率明显低于rout1和rout4的,因为其路由计算均以丢失率为参数,得到传输丢失率最低的路径,而rout3同时考虑时延参数,丢失率略高于rout2的。rout1仅考虑时延参数,所以传输丢失率高,rout4为普通数据路由,以节点负载度为参数,丢失率和rout1的接近。rout2与rout3传输丢失率区间分别为[0.24%,0.42%]和[0.43%,0.58%],而rout1和rout4传输丢失率区间分别为[1.60%,1.75%]和[1.42%,1.68%],可知SDNUCQS针对丢失率敏感型数据,能够显著降低传输丢失率。
4.5 网络生命周期对比
图10为SDNUCQS针对普通数据的路由以及LEACH、EEUC、CRIPSO和tPSOEB的网络存活节点数量变化情况,从中可以比较网络生命周期。
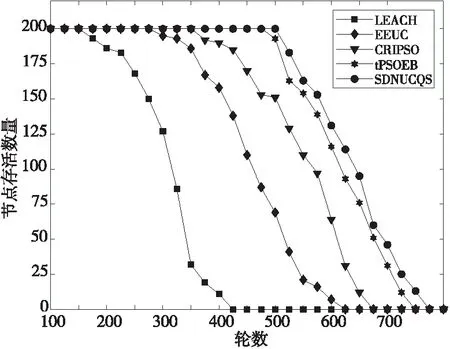
Figure 10 Network life cycle图10 网络生命周期
LEACH的存活节点数下降最快,在425轮左右节点全部死亡,EEUC采用非均匀分簇缓解网络“热区”问题,有效延长了网络生命周期;CRIPSO利用粒子群优化算法选择更加合理的簇头节点,平衡簇头能耗,延长生命周期;而tPSOEB和SDNUCQS利用SDN框架,节点无需路由计算,进一步降低了簇头能耗,SDNUCQS根据节点负载度计算路径,均衡节点能耗,延长网络生命周期。SDNUCQS相比于LEACH、EEUC、CRIPSO和tPSOEB网络生命周期分别延长了50.58%,21.28%,13.70%和5.54%,由此可知SDNUCQS能够平衡节点能耗,极大延长网络生命周期。
5 结束语
本文提出一种基于软件定义的无线传感器网络非均匀分簇QoS路由算法SDNUCQS。簇头选举采用熵权法,结合QoS指标,竞选出针对网络QoS的高质量簇头。为缓解网络热区问题,对网络进行非均匀分簇,平衡簇头节点能耗。路由阶段,首先按照时延和丢失率对数据分类,然后控制器针对不同数据计算路由。仿真结果表明,SDNUCQS在分簇方面能有效提高簇头质量,降低簇头能耗;在路由方面能够显著提高网络QoS并且延长网络生命周期。虽然本文算法在仿真中具有较好的性能,但应用于大规模网络中的效果有待考量,下一步将进一步改进算法,使其在大规模网络环境中也能发挥优势。
猜你喜欢
移动通信(2021年5期)2021-10-25
空间科学学报(2020年3期)2020-07-24
通信电源技术(2020年8期)2020-07-21
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年20期)2019-12-04
太原科技大学学报(2019年3期)2019-08-05
电子制作(2019年23期)2019-02-23
科技与创新(2018年1期)2018-12-23
科技创新导报(2016年27期)2017-03-14
现代防御技术(2016年1期)2016-06-01
