
燃煤电厂大数据挖掘和关键目标寻优智能系统研究
2022-03-22 06:58:20虞仕杰蒋赢凯尹贵豪翁浩斌
浙江电力 2022年2期
虞仕杰,蒋赢凯,尹贵豪,翁浩斌
(1.浙能北仑发电有限公司,浙江 宁波 315824;2.上海鉴智软件技术有限公司,上海 201203)
0 引言
应对全球气候变化被视为21 世纪人类社会面临的巨大挑战之一[1],它关系到全人类的生存问题,更会影响到全球的经济和政治。2016 年签署的《巴黎协定》提出将全球温升控制在比工业化前水平高2 ℃的范围内[2],为达成这个目标,全球剩余碳排放空间和碳达峰时间均非常有限[3]。2020年9月22日,习总书记在第75届联合国大会提出,中国确保2030年前CO2排放达峰,力争2060年前实现碳中和,这一承诺成为推动全球气候治理转折的关键[4]。现阶段煤炭仍是中国能源消耗的主要种类,占一次能源消耗的50%以上[5],其中电力与供热用煤占煤碳消耗总量的60%[6],因此煤电行业的节能减排、降低发电标准煤耗是实现碳中和和碳达峰的不可或缺的一环。
为提高火电厂发电效率,降低发电煤耗,自20世纪70年代起中外学者就做了大量的研究。在发电厂运行在线监测研究方面,德国西门子公司研发了主要分析机组运行和燃料价格的变动对机组效率的影响的Sienergy 软件。GE(通用电气)开展的发电厂优化方案Enter,借助设备运行参数的实时测量,通过虚拟传感器进行一些必要的测点补充,为优化机组运行提供尽可能详细的技术数据,从而通过机组的运行优化调整,帮助机组实现节能减排的目的。国内的高等院校、研究所也开展了对电站运行优化系统的研究与开发。清华大学研究了锅炉变工况运行优化监控系统[7],对于变工况运行的锅炉系统具有很好的状态监测和操作指导作用。浙江大学研究开发了火电机组在线能耗分析系统[8],通过实时分析机组运行参数,给出主要运行热力参数偏离应达值对全厂发电煤耗影响的定量关系,优化机组运行。东南大学研究了火力发电厂机组优化运行系统[9],不仅对机组运行的经济性提出建议,还研究了给水泵辅机节能的方法。国内火电机组运行优化研究还处于初步发展阶段,虽然在部分发电厂实际应用中取得了一定的成效,但大多数的运行优化产品还不够成熟。软件的通用性与国外同类产品相比仍有一定的差距,需要向专业性和实用化的方向进一步发展和完善[10]。
本文通过数据库挖掘技术,研究了火电厂历史大数据有效信息挖掘的标准实现流程,通过流程生成历史标杆库,并通过在线实时对标系统给出在历史相似工况下的关键目标及运行参数的优化建议,在锅炉效率提升、辅机运行参数优化等方面均有实际应用价值。
1 研究方法
火电厂历史运行数据库中存在着海量的信息,需要通过合适的方法提取有效信息,用于优化运行。以下将分为历史数据有效信息挖掘、关键参数标杆库形成的方法研究,以及标杆库指导实时运行研究2个部分进行讨论。
1.1 历史大数据挖掘与标杆库生成
1.1.1 稳态运行工况划分
机组运行过程中可以分为稳态和非稳态2种工况。非稳态情况下,各参数处于耦合变动状态,难以从中提取有效信息,因此对历史数据挖掘应处于稳态或准稳态运行工况下进行[11]。由于火电厂各参数的动态响应时间长短不同,快的只需几秒钟,而慢的参数过渡过程可能达到半小时,因此在稳态判定时需要将进入稳态时前一段时间的过渡过程排除,使所有判稳参数都结束响应过程,最终达到稳定状态。
CP(过程能力)是一种应用于工程中的用以判断工序稳定程度的方法,源于6sigma 管理理论,此处用于判定火电机组工况的稳定程度,过程能力指数计算公式如下:

式中:CP为过程能力指数,可根据实际参数情况调节;SU和SL分别为参数允许变化的上、下限;Range为参数在工程上稳态情况允许变化范围;σ为当前工况段参数的标准差。
根据过程能力算法,在参数工程上稳态变化范围确定后,通过调节CP值求出当前参数最大允许变化的标准差。当该参数在设定的过渡时间和稳态时间之和的时间内,标准差均小于最大允许变化的标准差,则定义该参数在该段稳态时间内处于稳定状态。多个判稳参数均处于稳定状态时,判定机组处于稳态。
1.1.2 运行工况模糊聚类
分析火电厂机组运行各参数关联时,参数可分类为MV(操作变量)、CV(被控变量)和DV(扰动变量),通常需要在避免DV 影响的情况下,寻找MV与CV之间的联系。例如环境温度是一个典型的扰动变量,在进行对标和关键参数寻优时,应保证其他MV或者DV在相近条件下,这样的对标结果才是有意义的,才可以提供运行优化建议。
FCM(模糊C 聚类)算法是一种将参数通过隶属度方法进行聚类的算法,打破了经典数学“非0即1”的局限性,用[0,1]之间的实数来描述中间状态,相较于K-means的硬聚类,FCM避免了在聚类边缘的参数被硬分割的缺点,更适用于机组运行参数的大数据挖掘[10]。
FCM 算法的流程如图1 所示,在初始化样本的隶属度矩阵后,通过公式(2)计算出聚类中心。FCM算法的目标函数Jm是使各样本点与该类聚类中心的距离乘上隶属度后最小,目标函数Jm的表达式如式(3)所示。而在目标函数Jm和每个样本在各聚类中心隶属度之和为1的约束下,通过解拉格朗日二次规划问题,求出新的隶属度矩阵,隶属度矩阵U迭代计算如公式(4)所示。当前后两次迭代的隶属度矩阵差值小于阈值ε,FCM 算法迭代结束,输出最佳聚类中心和样本在各聚类中心上的隶属度。

图1 FCM算法流程
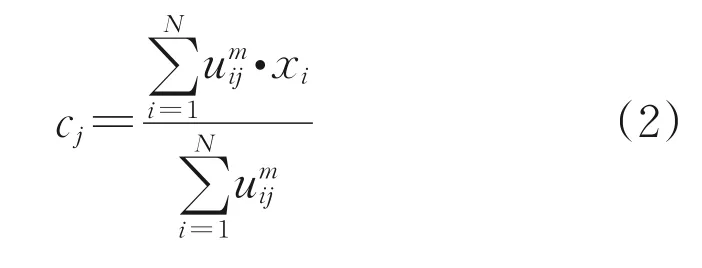
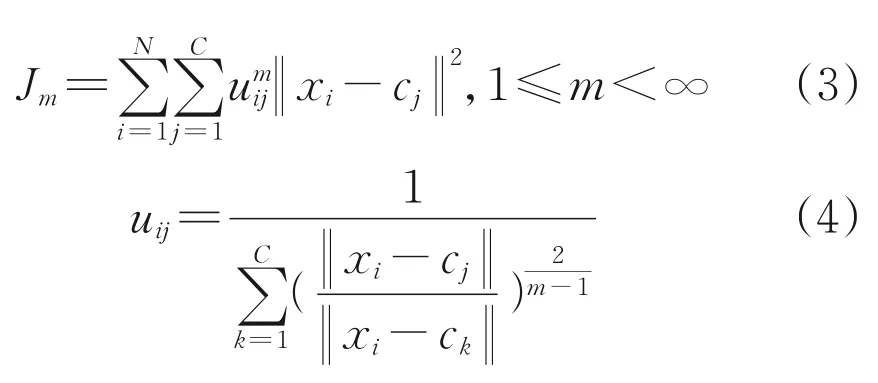
式中:m是聚类的族数;i和j是类标号;uij表示样本xi属于j类的隶属度,i表示第i个样本;x是具有d维特征的一个样本;cj是j簇的聚类中心,也具有d维度;‖*‖可以是任意表示距离的度量。
通过FCM算法,可将工况按照不同的MV和DV参数分段,对比近似工况下关键参数的值,找出影响关键参数差距的CV,从而达到优化运行、指导运行的目的。
1.1.3 运行工况模糊聚类
在完成工况判稳和工况聚类后,历史工况已经按照不同的MV和DV进行了聚类,形成一个个小的数据集,然后需要按照关键目标的优劣情况进行排序,挖掘出最优关键目标下的CV值,这些值是对于优化运行有指导意义的关键参数。
关键目标的构建有不同的方法,最简单的目标函数便是单一参数的最大/最小值,如公式(5)所示。

而机组运行时各参数往往是互相制约的,即一个上升一个下降需要取平衡,如主汽温度和减温水量;或者是有些参数有边界条件限制,如锅炉出口NOX浓度、主汽温度等,当求解这些边界条件下的关键目标寻优时,需要构建更为复杂的目标函数,如公式(6)所示。此时,为了避免求解二次规划问题,引入罚函数的方法,通过惩罚因子构建新的目标函数,求解新的目标函数下的最优值,新的目标函数如公式(7)所示。

式中:f(x)为目标函数;gi(x)代表边界约束条件;σ为惩罚因子,通常为一个较大的正实数;F(x,σ)为构造出的带有惩罚因子的目标函数。
通过关键目标寻优排序,找到在相近MV 和DV工况下最优目标值以及相关运行CV参数,建立历史数据标杆库,为后续实时运行指导提供知识储备。
1.2 实时关键目标对标与运行优化指导
在1.1中的历史数据挖掘通过自动程序计算出的历史标杆库,需要通过实时的对标来给运行提供优化指导建议,从而实现历史数据挖掘的价值。在线实时对标流程如图2所示,实时程序通过滚动对标,当实时运行达到稳态工况时,通过判断当前工况的MV和CV属于哪个聚类中心,找到历史标杆库中的相近工况,从而找到当前工况下最优关键目标值及相应CV值,提供运行指导。

图2 实时关键目标对标流程
整个历史数据挖掘与关键目标寻优智能系统的架构如图3所示,系统分为数据采集系统、离线寻优系统和在线对标系统。通过这一套系统的相互配合,不仅可以从庞大的历史数据库中挖掘出有用的信息,还可以将现场实验调整参数、运行人员发掘出的优秀运行参数一并记录,不断迭代标杆库知识,以达到更智能、更有效指导运行的目标。

图3 智能化系统框架
2 结果与分析
以智能系统在锅炉效率参数寻优方面的实际工程应用为例,讨论、分析系统在各关键步骤中的结果,及最后对于优化运行的指导作用。
2.1 锅炉稳态工况划分
根据以往研究结果及理论经验,锅炉稳态工况的判稳参数选择实时负荷、总给煤量、主蒸汽压力、总风量,在定义好各参数在稳态工程意义上的最大变化范围后,通过调节CP值寻找最优锅炉稳态工况的划分方法。
如图4 和图5 所示,当主蒸汽压力CP值设为0.6 时比设为1.1 时多划分了3 段稳态工况(如图4中红圈所示)。在这些工况中发现其他判稳参数处于相对稳态或较小波动情况,但主蒸汽压力波动较大,特别是图4 中从左往右第三个红圈的工况,证明主蒸汽压力CP值设定太宽松。因此提高CP值为1.1,更改后的稳态工况划分明显更为合理。

图4 主蒸汽压力CP=0.6时稳态工况划分
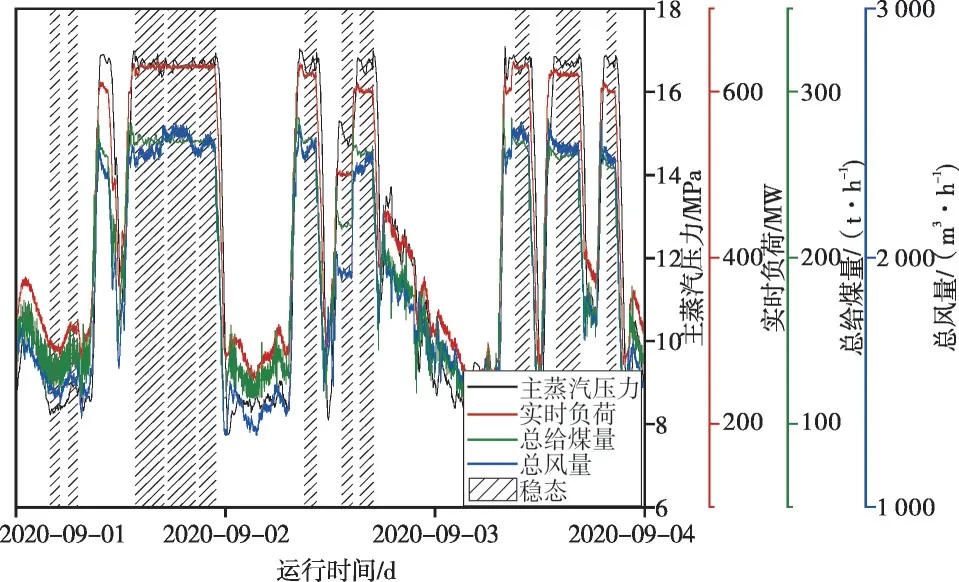
图5 主蒸汽压力CP=1.1时稳态工况划分
2.2 锅炉运行重要参数聚类
影响锅炉运行效率的MV 有负荷、锅炉总给煤量等,DV 有环境温度、煤质低位发热量等,CV有锅炉烟气含氧量、过热器和再热器减温水流量等,需要对MV和DV参数进行历史数据聚类。
根据经验,分别将负荷、总给煤量、环境温度、煤质低位发热量分别划分为10 类、3 类、3类、3 类,如图6 所示。图6 中不同颜色代表样本点位隶属度最大的类别颜色,且可以看出FCM算法优于K-Means 硬分类算法之处在于:每一类别并非在数据尺度上等宽度,而是在数据样本数量上近似,这样的划分结果更加合理。

图6 锅炉效率影响参数聚类结果
2.3 锅炉效率实时对标及运行优化指导
在完成锅炉稳定工况划分和参数聚类后,需要对每一聚类样本按照关键目标的优劣进行排序,此处关键目标选择锅炉效率最大值为单一目标,来构造历史标杆库。
形成历史标杆库的最终目标是,通过实时对标能够为运行指导提供优化操作建议,实时对标的过程如图2所示。先对当前实时工况进行稳态判定,若为稳态则进入聚类过程,若非稳态则等待下一时间的对标发起。聚类时计算当前工况各参数的中位数与历史标杆库中参数聚类中心的距离,
3 结语
本文研究并开发了火电厂大数据挖掘和关键目标寻优智能化系统,通过判稳、聚类、寻优形成历史标杆库、实时对标、提供运行优化建议的流程,为火电厂机组实时运行提供优化建议。以锅炉效率作为关键目标,比较了实时对标成功后系统所挖掘出的历史标杆库与实时工况间工况参数的差异,发掘出在当前实时工况下,锅炉氧量从而计算出隶属度矩阵。根据隶属度矩阵最大值形成相似工况代码,从历史标杆库中根据相似工况代码查询出历史最优关键目标值及相关CV值并显示出来,从而达到实时提供运行优化建议的目的。
图7为实时对标过程中由智能系统对标后提供的优化建议。在相近的MV和DV参数情况下,实时工况炉效为92.13%,而历史标杆工况炉效为93.34%,分析可见由于蓝线烟气含氧量的差别,设定值可由5.5%降低至4%,在当前工况下也可以平稳运行。即在当前实时运行工况下,锅炉总风量还有进一步降低的空间,以此可以提高锅炉效率,达到优化运行的目的。设定值有减小空间,可以提高锅炉运行效率的操作建议。

图7 实时对标挖掘出的历史和标杆工况分析
该系统除了可以用于锅炉效率关键目标寻优外,还可应用于关键辅机参数寻优(如给煤机一次风温设定值)、炉效和NOX排放浓度综合寻优等场景,通过研究提出了火电厂历史数据挖掘的标准流程,为进一步优化运行、实现闭环控制奠定基础。
猜你喜欢
大电机技术(2022年3期)2022-08-06 07:48:24
核科学与工程(2021年4期)2022-01-12 06:30:04
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
煤气与热力(2021年4期)2021-06-09 06:16:54
公民与法治(2020年22期)2020-12-14 07:56:54
中华建设(2020年5期)2020-07-24 08:55:10
中华戏曲(2020年1期)2020-02-12 02:28:18
汽车观察(2018年12期)2018-12-26 01:05:40
NBA特刊(2014年7期)2014-04-29 00:44:03
计算机与网络(2014年9期)2014-03-25 10:57:13
