
深度学习算法的P2P流量识别与控制
2022-03-22 12:08黄金铃
沈阳工业大学学报 2022年2期
黄金铃
(上海师范大学 信息化办公室, 上海 200234)
在对等网络(peer to peer,P2P)应用过程中,易出现网络宽带消耗量增长、信息泄露与其他安全方面问题,而P2P流量在互联网资源内所占比例超出60%,对P2P流量的管控进行研究成为当前网络管理研究的重中之重[1-2].P2P流量管控中的关键之处在于流量的识别与控制,P2P流量的精准识别是实行P2P流量有效控制的基础,通过对P2P流量控制,能够降低网络拥堵与延迟、提升网络服务与管理质量,对网络的安全运行提供有效保障[3-4].实现有效的P2P流量控制,达到网络的安全运行,需对网络流量中P2P流量予以识别[5].
当前P2P流量识别和控制的方法有很多,例如,最优ABC-SVM算法流量识别方法适用于小样本数据的分类,对于大流量数据的识别无法保障识别的准确度[6];CNN流量识别方法即卷积神经网络(convolutional neural network,CNN),通过提取数据特征运用多个窗口卷积方式对各块的部分信息实行处理识别,但该方法训练时易产生过学习现象,导致出现整体识别时间过长、识别精度不稳定等问题[7-9].
深度学习算法[10-11]能够通过训练提取到数据的特征并实现分类,具有较强的并行处理与自组织学习等能力,为了获得理想的P2P流量识别与控制效果,提出了基于深度学习算法的P2P流量识别与控制方法,在针对网络中的P2P流量实行精准识别的基础上,实现对识别P2P流量的有效控制,提升网络的管理水平与运行的安全性.
1 P2P流量识别与控制
1.1 深度学习算法的P2P流量识别
1.1.1 深度学习算法的网络流量数据聚类
深度学习算法聚类的基本过程为:将由网络应用端口所采集到的流量数据作为样本数据,其中少量流量数据作为训练样本数据,其余流量数据作为检测样本数据,以训练样本数据实现对深度学习算法的BP神经网络训练,应用训练后的BP神经网络预分类训练样本数据,以预分类结果为依据将聚类中心确准;在预分类结果所确准的聚类中心基础上,通过聚类算法对检测样本数据实行聚类,获取精准有效的识别结果.深度学习算法聚类过程如图1所示.
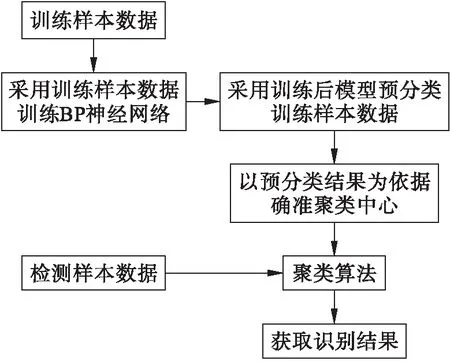
图1 深度学习算法聚类过程
深度学习算法聚类算法的实现过程为:
1) 训练样本数据为Xk=[xk1,xk2,…,xkN],k=1,2,…,M,M为样本数量;第m次迭代时,网络的实际输出为Yk(m)=[yk1(m),yk2(m),…,ykg(m)],g为输出层神经元数量;期望输出为Bk=[bk1,bk2,…,bkg],Yk为最终结果,可通过误差运算与权值修正获得.
2) 以Yk值为第k个聚类中心点.
3) 将k个聚类数据对象集合Ai与k个聚类中心Yi输出.
1.1.2 P2P流量识别
作为IP服务的P2P包通常情况下包含数据传输与消息联系两种状态,且两种状态均以较高速率实施转换[12].当前较为常见的六种IP服务流量特征对比如表1所示.通过表1能够看出,P2P的流量特征主要包括:字节数高、持续时间长以及平均传输速率由中到高,以此类特征为依据可较好地区分除FTP以外的其他服务类别,对于FTP服务类别的区分,可依据消息联系方面实现,具体为:FTP仅拥有单方面联系,无用户交互,而P2P拥有双方面消息联系,存在用户交互.

表1 不同IP服务流量特征
P2P与万维网(WWW)相对于单个流而言,二者包的大小标准差较大,但因P2P包大小转换频率较高,且P2P持续时间长,故输入特征值可选取为各流的包大小转换频率、包数目、包大小标准差、总字节数及包大小平均值五类特征值,输入层神经元数量为5.对于流量识别结果,需对是否属于P2P予以判断即可,即输出结果仅有两种,则输出层神经元数量为2.设置相应的参数:隐含层神经元数量为4,输入层神经元数量与输出层神经元数量分别为5和2,训练次数与学习速率分别为420和0.66.以深度学习算法的预分类结果为依据,运用所选取的五个特征值对流量数据中的检测样本数据进行分析,获取各种IP服务的聚类中心;以常见的IP服务类别为依据,聚类k值取为2,根据5个特征值的均值聚类各个流量获得聚类结果,实现P2P流量识别.
1.2 基于自相似性的P2P流量控制
P2P流量识别是为了实现更有效的P2P流量控制,故在P2P流量识别结果的基础上,结合P2P流量特征,将所识别的P2P流量作为控制对象,提出基于自相似性的P2P流量控制机制,对识别所得的P2P流量实行有效控制.
1.2.1 基于FARIMA过程的自相似模型
分形自回归综合滑动平均(FARIMA)自相似模型为分形自回归综合移动平均线过程(p,d,q),其中,p为自回归阶次,d为差分次数,q为滑动平均阶次.对于任意时序序列{Z(n)},FARIMA(p,d,q)模型可表示为
他却很大方地给我找了个椅子,然后从开水瓶里给我倒了杯水,像个大人一样招呼我。他奶奶拄着拐杖颤颤巍巍地出来,说这孩子从小就懂事脑袋也聪明,就是命不好,两个大人都不靠谱,要我多照顾一下他。
φ(B)dZ(f)=θ(B)E(f)
(1)
式中:B为延迟算子;E(f)为白噪声序列;d为分形差分算子,其表达式为
(2)
延迟算子表达式为
BnZ(t)=Z(n-t)
(3)
φ(B)和θ(B)分别为自回归项和滑动平均项,其表达式为
φ(B)=1-φ1B-φ2B2-…-φpBp
(4)
θ(B)=1-θ1B-θ2B2-…-θqBp
(5)
1.2.2 基于FARIMA模型的P2P流量控制
P2P流量控制机制是以FARIMA的P2P流量识别结果为依据,对P2P流量进行智能控制,主要包括:FARIMA自相似模型预估、预估流量对比、以计数器为依据调整P2P流量,具体如图2所示.基于FARIMA模型的P2P流量控制步骤具体如下:
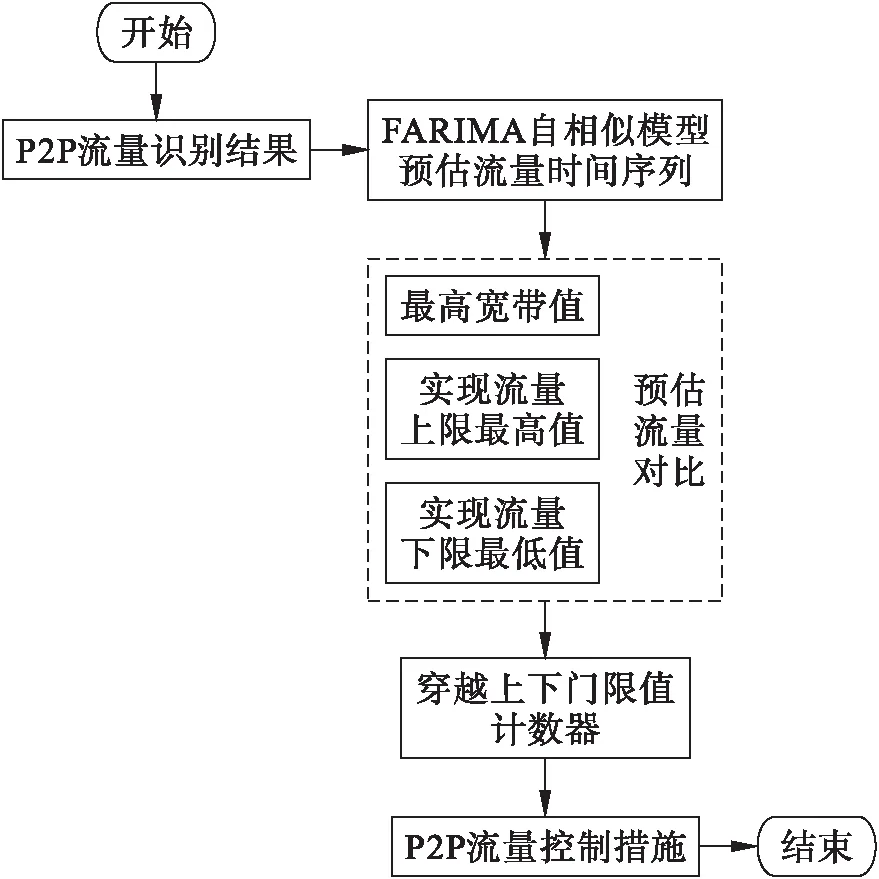
图2 P2P流量控制机制流程
1) FARIMA自相似模型程序可通过C编程实现.
2) 设用户的最高宽带值为DG、突现流量的上限最高值和下限最低值分别为hDG和cLG,穿越上下门限值计数器分别为hCount和cCount,各数值的关系为DG>hDG>cLG.
3) 以FARIMA自相似模型为依据,将识别得到的P2P流量下个Δt时刻的流量值PΔt预估得出.
4) 计时器在预估出第一个Δt时刻的P2P流量值时开启计时.
5) 若预估流量值PΔt>hDG,则hCount=hCount+1;反之则cCount=cCount-1.
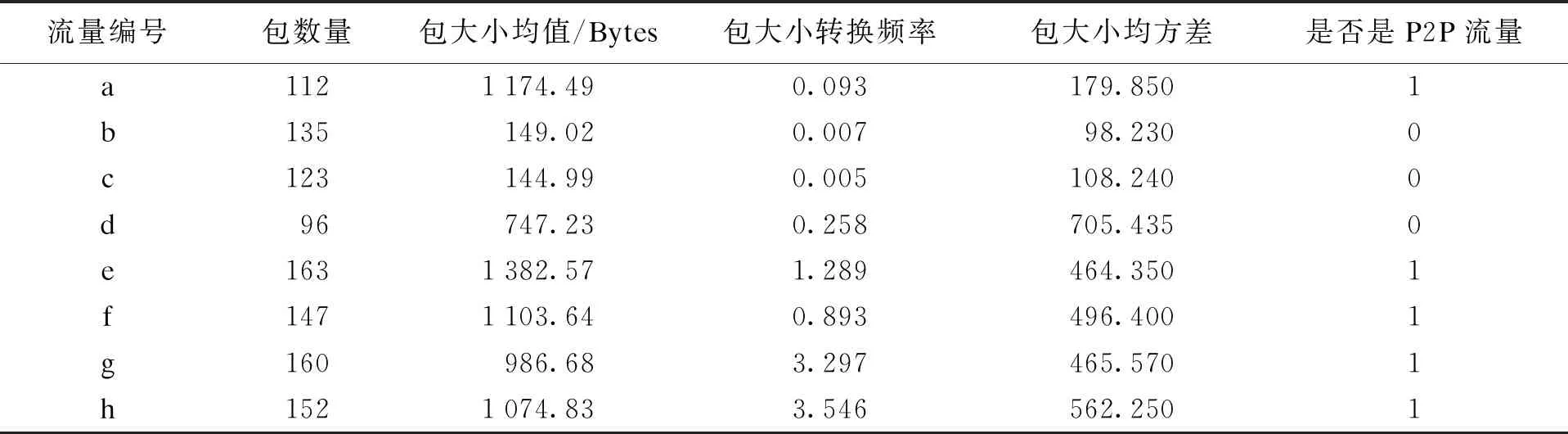
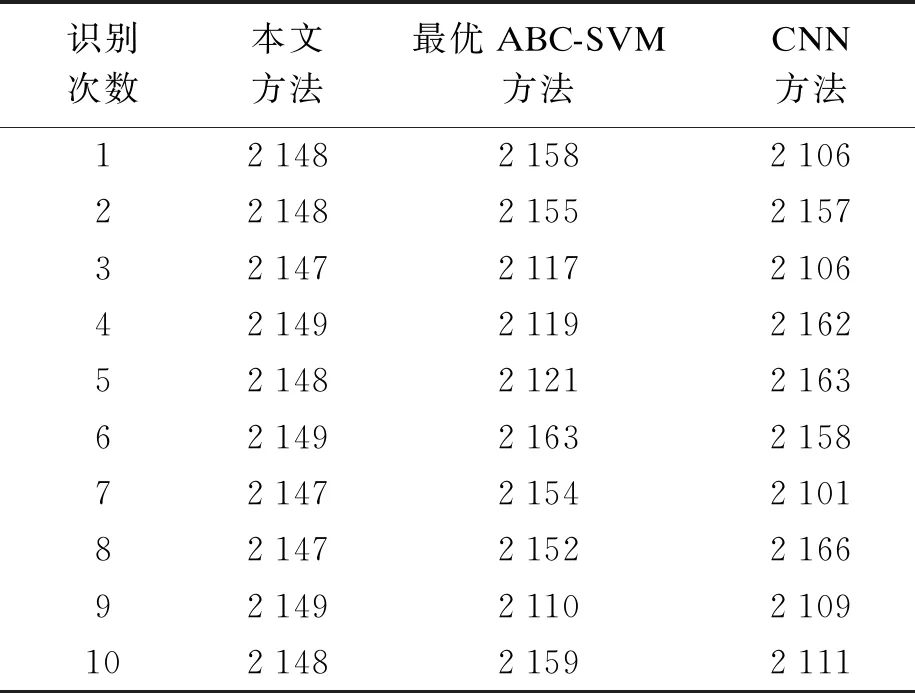
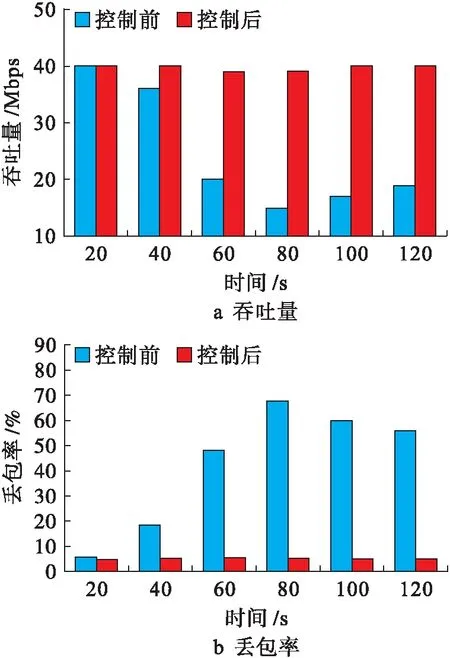
6) 在l个Δt时刻内,若cCount 实验中在某高校校园网中的计算机终端上安装网络嗅探软件wireshark,通过被动监听的方式抓取网络流量数据包,抓取流量数据包的时间段为2019年3~7月,运行ftp、www、eMule与BitTorrent等应用.校园网计算机的配置为:Intel 2.85 GHz 4核CPU,8 GB内存,操作系统为Windows XP,通过抓取采集到各应用的字节数、包数量、转换频率、包大小等流量样本数据共4 500条.从每种应用中各随机抽出1/3数据作为本文方法的训练样本数据,剩余数据为检测样本数据. 2.1.1 稳定性分析 通过本文方法对1 500条训练样本数据实行预分类,获取到训练样本数据的预分类结果,包含P2P流与非P2P流,随机从预分类结果中选取出两类流量数据各4条,每条流量样本数据的特征值如表2所示.表2中,“1”表示P2P流,“0”表示非P2P流.通过本文方法预分类后获得的聚类中心值(各个特征值的平均值)如表3所示. 表2 流量样本数据的特征值 表3 聚类中心值 以预分类得到的训练样本数据聚类中心值为依据,采用本文方法对剩余3 000条检测样本数据实行10次聚类,获得10次流量识别结果;再分别采用最优ABC-SVM和CNN流量识别方法进行10次对比实验,P2P流量识别结果如表4所示.通过表4可以看出,本文方法的10次P2P流量识别结果更加稳定,识别结果波动幅度小,表明本文方法可以得到较稳定的P2P流量识别结果. 表4 不同流量识别结果 2.1.2 精度分析 将3 000条检测样本数据进行预处理,去掉一些无用数据,得到有效的P2P流量数量为2 136条,统计三种方法的P2P流量识别精度,得到P2P流量识别误差,结果如图3所示.由图3可知,相对于对比方法,本文方法的10次流量识别误差变化更加平稳,平均误差值为0.56%,最优ABC-SVM和CNN流量识别方法的平均误差值分别为0.95%和1.25%,本文方法的P2P流量识别精度高于对比方法,这是因为本文方法是依据流量特征实现的流量识别,不仅可用于普通P2P流量识别,还可以对加密及未知的P2P流量实现高精度识别,具有较好的自适应性. 图3 各方法识别误差对比 为了验证本文方法的P2P流量控制效果,采用吞吐量与丢包率作为检测指标,流量丢包率的计算方法为 (6) 式中,O和K分别为P2P流量的流出值与初始值.P2P流量的丢包率越低,P2P流量控制效果越理想,测试结果如图4所示.从图4可以看出,在应用本文方法控制前,P2P流量间竞争宽带十分激烈,使得流量吞吐量快速下降,网络资源没有得到充分利用,出现丢包率过高问题;采用本文方法对P2P流量控制后,P2P流量传输顺畅,宽带分配合理,吞吐量变化十分平稳,使得流量丢包率降低.对比结果表明,本文方法能够保持P2P流量稳定传输,减少流量传输时的丢包率,获得了理想的P2P流量控制效果. 图4 吞吐量与丢包率对比 本文提出了深度学习的P2P流量识别与控制方法,通过结合深度学习算法与聚类算法,完成对所采集流量数据的聚类,获取P2P流量识别结果,并基于FARIMA自相似模型创建P2P流量控制机制,实现对所识别P2P流量的有效控制,以某高校校园网中所采集的各流量数据为例,通过本文方法识别与控制后,验证了本文方法识别结果的精准稳定与显著有效的控制性能.2 实例分析
2.1 识别结果分析


2.2 控制效果分析
3 结 论
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
科技创新与应用(2020年6期)2020-02-29
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
课程教育研究·新教师教学(2016年18期)2017-04-12
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
互联网天地(2016年1期)2016-05-04
