
融合知识图谱与深度学习的羊病诊断方法∗
2022-03-18 06:21翟增林王天一
计算机与数字工程 2022年12期
翟增林 王天一
(贵州大学大数据与信息工程学院 贵阳 550025)
1 引言
近年来随着人工智能的快速发展,深度学习已经在疾病诊断领域取得较好的成果,然而深度学习以数据为驱动,其自动特征提取的方法虽然提高了效率,但往往缺乏专家经验和知识,无法发掘疾病与症状间隐含的关联关系。而知识图谱技术能够以结构化的形式表示人类知识,通过知识表示和知识推理技术,可以给人工智能系统提供可处理的先验知识[3]。因此,可以利用知识图谱中潜在的信息指导神经网络模型的学习,模拟羊病专家的诊断过程,实现对羊主要疾病的诊断。
基于以上研究现状,本文提出融合知识图谱与深度学习的羊病诊断方法。首先根据羊病专家知识构建知识图谱,再利用图神经网络融合知识图谱信息将症状描述文本转化为词向量,最后使用LSTM 学习症状描述文本的单个汉字特征,强化模型文本语义表示能力。实验表明本文通过羊病知识图谱嵌入为LSTM 提供先验知识,使得模型在训练时能够更全面的学习症状文本特征,从而提升诊断效果,并能够实现羊病的初步诊断。
2 羊病知识图谱构建
知识图谱(Knowledge Graph,KG)通过“实体-关系-实体”三元组信息表示现实世界中的抽象概念,实体之间通过关系相互连接构成网状结构,通过三元组的形式可将物理世界中的每一条知识描述为KG=
领域知识图谱可以解决特定领域的知识推理问题。针对羊病领域没有开源知识图谱的问题,本文首先通过爬虫爬取羊养殖百科、论坛等网站中羊病领域的相关数据。针对养殖百科中的结构化数据,通过设计关系抽取模板将结构化数据转化为三元组的形式;对于从论坛中获取到的非结构化数据,通过中文分词工具jieba[8],中文命名实体识别工具LTP[9]和中文知识图谱关系抽取工具DeepKE从非结构化文本中自动抽取三元组知识。
经过以上处理共得到3854 组三元组信息,其中包含2626 个节点,涉及疾病-症状、疾病-病因、疾病-别称、疾病-含义、疾病-治疗等12种关系,部分三元组表示结果如表1 所示,最后将所有三元组信息存入neo4j图数据库中,得到羊病知识图谱,部分知识图谱可视化结果如图1所示。
对两组临床相关指标(手术时间、术中出血量、骨愈合时间、髋关节功能Harris评分、住院时间)、骨折复位丢失率、并发症发生率实行观察和记录。
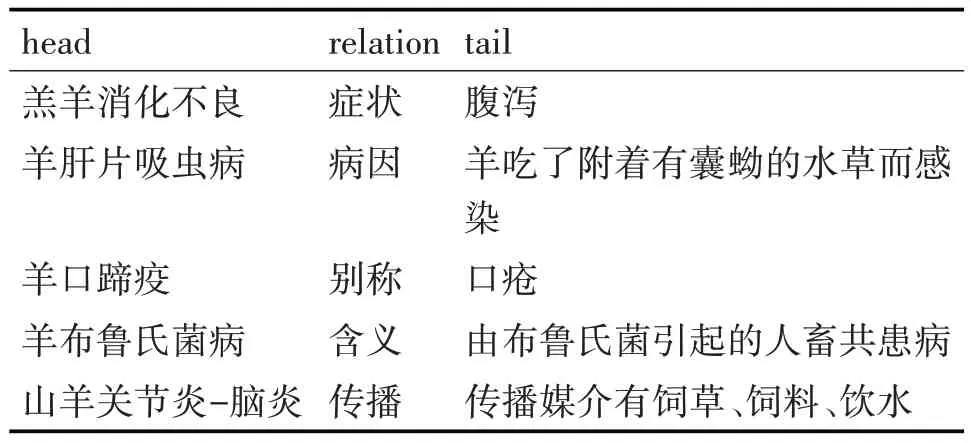
表1 部分三元组表示

图1 知识图谱可视化结果
3 羊病诊断模型
融合知识图谱与深度学习的羊病诊断模型主要由症状文本处理模块、羊病知识图谱嵌入模块、长短期记忆网络(Long Short Term Memory,LSTM)特征提取模块和输出模块四部分组成,其模型结构如图2 所示。其中,症状文本处理模块包括Word2vec 字级别编码和症状文本词特征编码,羊病知识图谱嵌入模块包括羊病知识图谱特征提取与融合的GCN(Graph convolution neural network,GCN)编码模块,双向LSTM 模块提取Word2vec 编码后的症状字特征,单向LSTM 提取GCN 编码后的症状词与羊病知识图谱融合特征,最后将两部分特征进行拼接,使用Softmax 分类器计算诊断结果的概率分布,完成基于症状的疾病诊断。
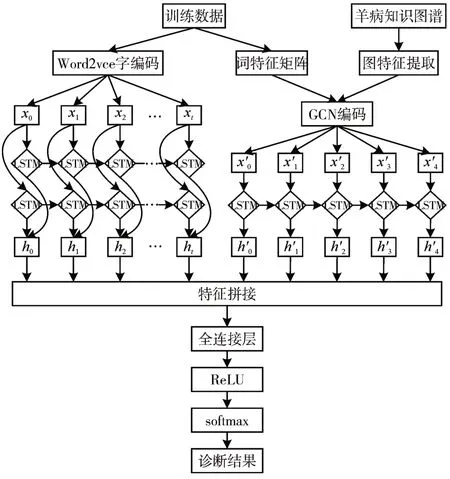
图2 融合知识图谱与深度学习的羊病诊断模型
3.1 症状文本处理模块
症状是描述病羊因患有某种疾病而表现出的异常状态,这些状态容易被饲养人员观察到并以文本的形式记录。为了从多个维度学习这些文本的特征,本文分别从字与词两个角度出发,对于疾病症状文本当中的单个汉字,使用Word2vec 的Skip-gram 模型[10],将汉字表示成连续稠密的字向量,通过这种方式得到的字向量能够蕴含文本中各个汉字之间的语义关系。对于疾病症状文本中的词,它与羊病知识图谱当中的节点相同,因此可以与知识图谱中图结构特征进行融合,通过设计字表,将词语中出现该汉字的位置标标记1,未出现该汉字的位置标记为0,得到疾节点特征矩阵,可以作为GCN 的输入,假设字表为Ω={发,腹,口,泻,疮,热},则“发热”可以表示为{1,0,0,0,0,1}。
3.2 羊病知识图谱嵌入模块
图神经网络(Graph Neural Network,GNN)由戈里(Gori)等[11]提出,是一种处理图结构数据的神经网络模型,而知识图谱本身就是一种图结构数据,因此可以采用图构建知识和数据之间的关联。图卷积神经网络[12]是卷积神经网络(Convolutional Neural Network,CNN)在非欧式空间的一种拓展[13],它能很好地对知识图谱中图结构信息进行融合,通过加入GCN 可以增加模型对自然语言文本中词语间关联性的学习能力,提高特征向量的稠密度。本文利用GCN 编码的功能,通过聚合羊病知识图谱中疾病与症状之间的节点特征与结构特征信息,学习知识图谱疾病与症状的节点嵌入表示。
图神经网络的核心是消息传递,通过聚合邻居节点的信息完成当前节点特征的更新。例如在图3所示的疾病-症状子图中,疾病Xi作为中心节点,其特征通过聚合周围一阶邻居节点特征即症状的特征进行更新。
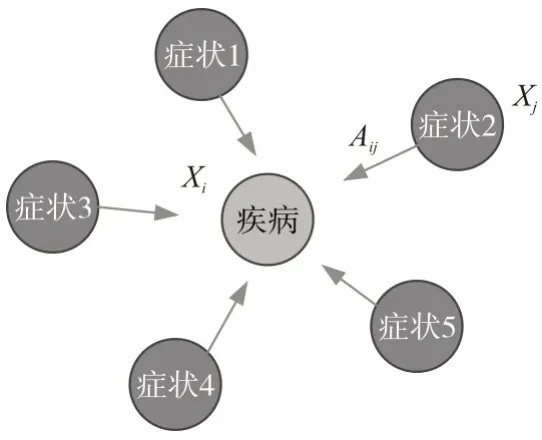
图3 疾病-症状子图
其中,Aij表示消息传递系数,可由邻接矩阵得到,Xj表示症状的特征,通过节点特征矩阵得到。节点的更新不仅要考虑邻居节点的特征,还需要考虑自身的特征,可以通过自身特征矩阵与一个单位矩阵相加,实现自连接的作用,将自身特征添加进来。
其中,͂表示带有自连接的邻接矩阵。在实际情况中,节点间关系连接的数量并不相同,因此需要根据不同节点与其他节点连接的密切程度设定不同的权重来限制每一个节点信息传输。GCN 巧妙的利用度矩阵解决了这个问题,通过自连接度矩阵对带有自连接的邻接矩阵͂进行特征归一化后再进行消息聚合。
通过这种方式得到的节点特征能够根据邻居节点的数量进行有选择的特征提取。将单次次节点聚合后与权重矩阵W相乘,再经过一个非线性激活函数Sigmoid,得到下一层的节点特征。
通过GCN 可以得到聚合了知识图谱中图特征信息的疾病症状节点表示。
3.3 LSTM特征提取模块
LSTM是一种时间递归神经网络[14],它可以选择性的保留或遗忘某些输入信息,防止模型训练时可能产生的梯度消失的问题,获得更长的记忆。对于羊病诊断问题,LSTM 可以按照时间先后顺序记住用户输入的症状,之后通过神经网络的训练赋予每种症状不同的权重,从而完成羊病诊断。LSTM单元结构图如图4所示。
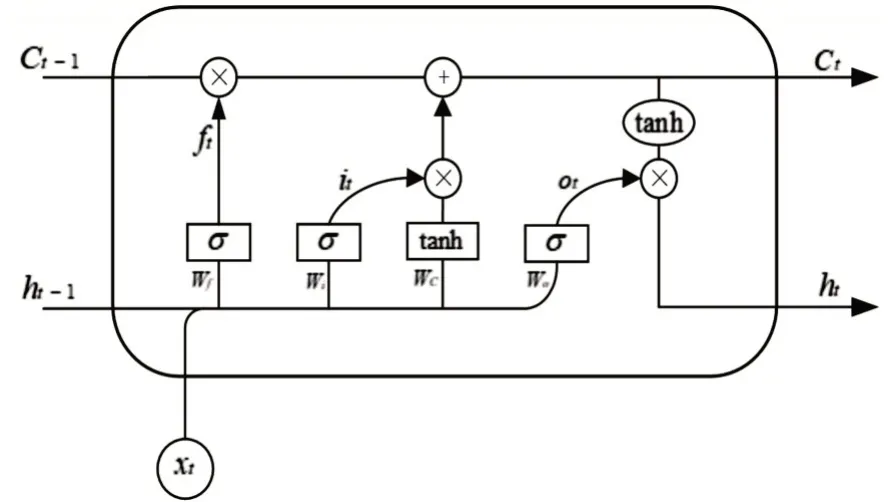
图4 LSTM单元结构图
LSTM 单元包括输入门、输出门和遗忘门三个主要部分。输入门会根据上一时刻LSTM 的隐藏状态ht-1和当前时刻的输入xt,通过学习参数矩阵Wi计算来决定有多少信息更新到细胞状态Ct中。
对于候选信息,可以通过将上一时刻LSTM的隐藏状态ht-1和当前时刻的输入xt进行拼接后再与可学习的参数矩阵Wc相乘,最后经过非线性激活函数tanh 后得到。
遗忘门控制上一层细胞状态Ct-1中的需要丢弃的信息。其输出结果ft与上一时刻LSTM 的隐藏状态ht-1和当前输入xt有关,通过学习参数矩阵Wf来决定需要保留和舍弃的信息。
经过上述过程的计算,LSTM 单元既能够通过输入门向细胞状态Ct-1中添加新的信息,又能利用遗忘门取出过往信息中心不重要的部分,完成细胞状态Ct的更新。
输出门用于输出当前细胞状态Ct有多少作为当前输出,通过可学习的矩阵Wo,计算出输出门ot控制细胞状态的输出。
最后,隐藏状态ht可表述为
双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)[15]是LSTM 的扩展,其结构如图5 所示,它不仅能捕获文本序列的正向信息,也可以学习反向信息。例如对于输入文本“共济失调”,正向网络LSTML会依次输入“共”,“济”,“失”,“调”得到四个状态向量{hL0,hL1,hL2,hL3},而反向网络LSTMR会依次输入“调”,“失”,“济”,“共”得到四个状态向量{hR0,hR1,hR2,hR3}。最后将两部分状态向量进行拼接得到习得上下文症状的字特征{[hL0,hR3],[hL1,hR2],[hL2,hR1],[hL3,hR0]}。
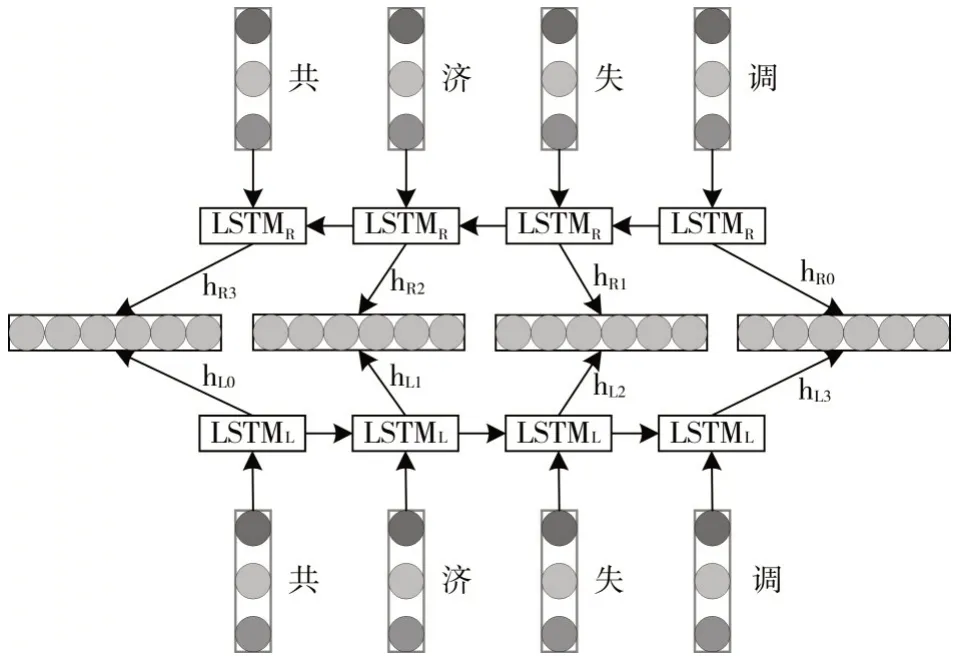
图5 Bi-LSTM结构图
3.4 输出模块
该模块的任务是输出每条症状文本最有可能对应的K种疾病,并给出每种疾病出现的概率。将LSTM特征提取模块得到的症状文本特征与知识图谱特征进行拼接后,再经过线性变换并输入到激活函数ReLU 中得到特征表示。
式中o1,o2表示由特征提取模块得到的向量,W表示维度为d×c的权重矩阵,d为o1,o2拼接后的特征维度,c为疾病的总数。最后使用Softmax预测每种症状的概率,并对结果做归一化处理。
4 实验过程与结果分析
4.1 羊病诊断数据集生成
羊病诊断的关键点在于从具体症状到疾病的推理,本文首先利用neo4j 提供的Cypher 查询语句提取羊病知识图中所有头尾实体分别为疾病与症状的三元组数据,构成由152 种疾病和861 种症状组成的疾病-症状子图,再根据子图中每种疾病连接的症状,使用python编程语言编写代码生成症状文本数据。本文假设羊只不会同时患有多种疾病,数据集实现步骤如下:
Step1.通过Cypher查询语句获得疾病-症状子图KGsub=
Step2.分别提取152种疾病及其相连的所有症状,构成152 个集合Qi={hi,t1,t2,…,tk},再对集合中的症状t按照个数为1~5,比例为1∶3∶3∶2∶1进行100 次随机采样,模拟真实情况下羊只可观测到的症状的数量。
Step3. 将采样得到的症状信息与疾病进行组合得到训练所需的文本数据,并去除重复的数据。
通过上述处理,最终得到11724 组症状疾病数据,并按照7∶1∶2 划分训练集、验证集、测试集。部分样本数据如表2 所示:症状为0 表示采样得到的症状数量不足5个时用0填充。

表2 部分样本数据展示
4.2 实验环境
实验所用的硬件配置为:AMD(R)Ry⁃zen5-5600X CPU@3.70 GHz,32 GB 内存,GPU 为NVIDIA(R)GeForce RTX 3060Ti;实验所用软件环境 为 Windows10 操 作 系 统,Python3.8,Py⁃torch1.10.0,Cuda11.3。
4.3 评价指标
本次实验采用TopK 推荐常用指标精确率(Precisiond@K)和召回率(Recalld@K)来衡量模型的性能,计算公式分别如下。
其中predsd是模型预测的疾病列表,posd为症状文本记录中各症状在羊病知识图谱中相邻疾病节点所构成集合的交集,negd表示症状文本记录中各症状在羊病知识图谱中相邻疾病节点所构成集合的并集再减去posd得到的集合。精确率也叫查准率,即让模型的预测结果尽可能不出错的概率,可以作为Top1 推荐的指标来判断模型的好坏。召回率也叫查全率,高召回率意味着模型会尽力找到每一个可能被找到的对象,在羊病诊断中可以作为评价诊断广度的指标。
4.4 实验结果分析
为了分析加入知识图谱特征对神经网络的影响,本文分别与自然语言处理中常用的递归神经网络DeepRNN[16]、LSTM 与Bi-LSTM 进行对比,计算四种模型在测试集中Top1,Top2,Top3 精确率与召回率,实验结果如表3 所示。可以看出,本文的方法通过将文本特征和知识图谱特征进行融合后得到的各项评价指标均优于其他模型的结果,表明该方法能够在羊只疾病诊断中取得不错的效果。
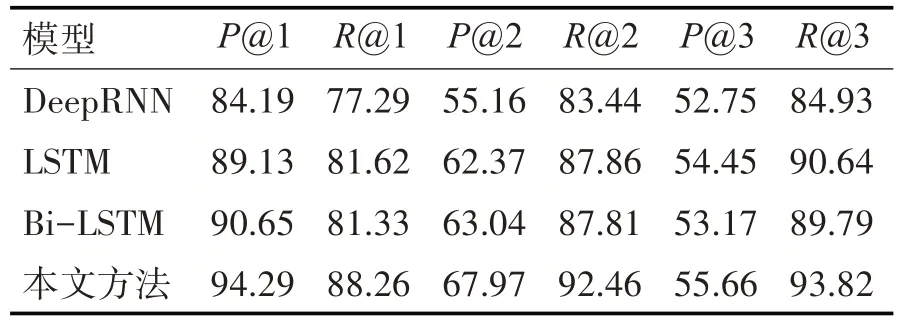
表3 四种方法对比结果
此外,本文分别对测试集中不同症状数量的文本信息预测出的结果进行Top1,Top3,Top5 的精确率与召回率的计算,实验结果如表4 所示。对于羊病诊断问题,随着输入症状数量的增加,其Top1 诊断精确率也会增加。

表4 不同症状数量测试结果
在实际生产实践中,本文所提出的模型能够在给出3 个以上症状时的Top1 精确率接近100%,由于本文假设羊只不会同时患有多种疾病,即羊只可确诊患有某种疾病。当输入症状只有1 个时,本文模型虽然不能准确地预测羊只所患疾病,但较高的召回率仍可以给养殖人员提供候选疾病以及每种疾病可能出现的概率。输入症状小于3 个时使用Top3 推荐,输入症状大于等于3 个时采用Top1 推荐,部分诊断结果如表5所示。
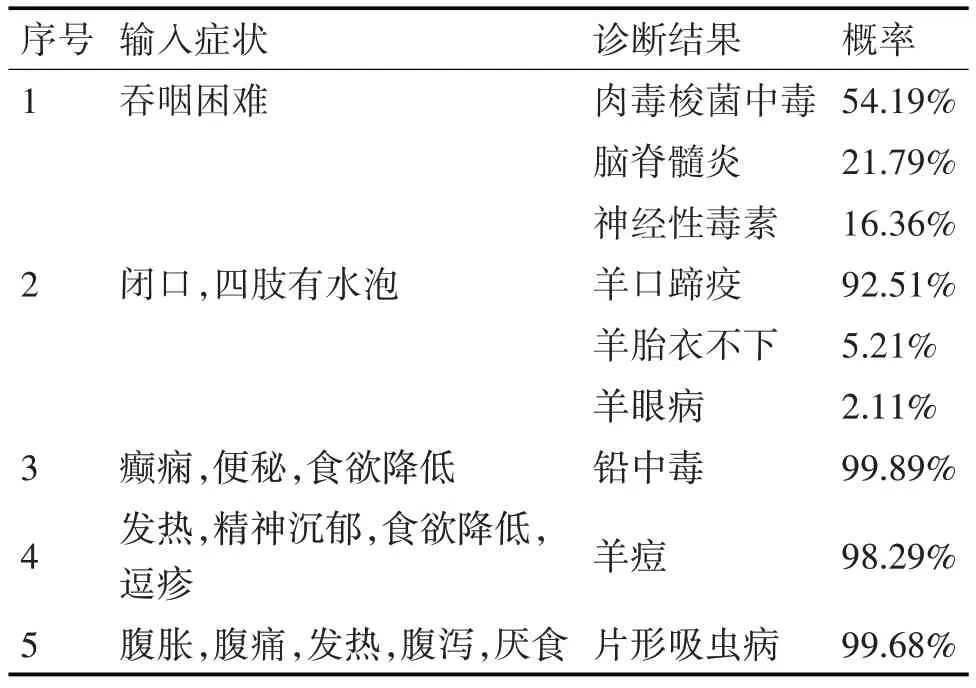
表5 部分诊断结果
5 结语
本文提出了一种融合羊病知识图谱和症状文本特征的羊病诊断模型,首先根据专家知识构建羊病知识图谱,使用GCN 聚合知识图谱与症状描述文本的词语特征,提高了模型获取高层文本特征的能力。然后使用LSTM 学习症状描述文本的单个汉字特征,强化了模型文本语义表示能力,提高对不同类型疾病的诊断准确率。该模型与其他仅基于文本特征的诊断模型相比,在精确率与召回率上均有的提升,在输入症状不足的情况下也有较好的召回率。本文所提出模型能够根据症状有效判断出羊只可能患有的疾病及其概率,有助于减少因羊患病造成的经济损失。
猜你喜欢
今日农业(2022年15期)2022-09-20
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
今日农业(2020年20期)2020-11-26
五邑大学学报(自然科学版)(2019年3期)2019-09-06
兽医导刊(2019年14期)2019-02-12
计算机技术与发展(2018年12期)2018-12-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
中国农业信息(2016年13期)2016-02-07
