
Hadoop 下并行化实现文本聚类的优化算法∗
2022-03-18 06:19潘俊辉MariusPetrescu王浩畅
计算机与数字工程 2022年12期
王 辉 潘俊辉 Marius.Petrescu 王浩畅 张 强
(1.东北石油大学计算机与信息技术学院 大庆 163318)(2.普罗莱斯蒂石油天然气大学 什蒂 100680)
1 引言
目前互联网上产生了海量的数据,而单机串行处理海量数据时存在瓶颈,因此使用云计算、大数据对海量数据进行挖掘的技术不断涌现[1]。文本聚类可将相似的文本进行归类处理,提取出文本中的关键信息,该技术目前被广泛地应用在众多领域[2]。针对目前互联网上的海量数据,采用Hadoop对海量数据并行化实现文本聚类可有效地解决单机处理数据效率低的缺点。
目前,国内外的一些学者对文本聚类的算法进行了研究。国内的胥桂仙等人重点对中文文本挖掘中的特征表示及聚类方法进行了相应的研究和改进[3~4];而赵庆等利用Hadoop 云计算平台实现了K-means 聚类算法[5];还有一些学者将聚类算法移植到了MapReduce 下进行了设计和实现[6~7];国外的Yoon提出了一种使用k-均值聚类方法测量数据异常点的检测方法[8~9];为了确定K-means 算法中的K 个初始值,消除其敏感性,一些学者提出了改进的K-means 算法从而快速定位最优初始聚类数值[10]。
本文针对K-means 聚类算法存在初始中心选取不当导致运行不稳定的缺点以及单机串行编程对海量数据聚类效率低的问题,提出了一种Ha⁃doop 平台下并行化实现文本聚类的优化算法。该算法首先通过自定义的Mapper 和Reducer 任务对文本向量化过程进行了并行化的实现,然后采用基于密度和最大最小距离的算法选取初始质心作为K-means算法的初始中心,并将该优化方法应用到K-means 算法中,最后基于MapReduce 框架设计Mapper 和Reducer 各阶段实现对文本的并行聚类。文中在最后通过搭建的Hadoop 集群对数据进行测试,实验结果表明优化的文本聚类并行算法在聚类效率和聚类质量上均有较大的提高。
2 Hadoop平台及文本聚类
2.1 Hadoop平台
Hadoop 平 台 由Apache Software Foundation 公司正式引入后迅速成为大数据分析处理的领先平台。该平台具有两大核心架构,分别是底层存储系统HDFS和上层应用MapReduce编程框架[11]。
2.1.1 HDFS
HDFS是一种分布式文件系统,以分布式的形式将划分的数据块存储到多节点中。HDFS中的主节点负责分布式文件系统的命名空间,在其中保存了两个核心的数据结构FsImage 和EditLog。从节点则是HDFS 的Slaver,其主要负责数据的存储和读取[12]。
2.1.2 MapReduce
MapReduce核心是Map函数和Reduce函数[13]。Map 函数可将输入数据以
2.2 文本聚类
文本聚类是指将无序的对象作为输入,使用相似性度量函数计算未知类别文本的相似性,输出则为相似性文本组成的簇集[15]。其聚类过程采用数学形式表示为设文本数据集:D={d1,d2,…di,…,dn},di为数据集中的文本,n 为总文本数,聚类之后得到的簇集为E={e1,e2,…,ej…,ek},ej为相似文本聚成的簇,k为聚类个数。当满足条件∀di(di∊D),∃ej(ej∊E),di∊ej,将语料库D分为k个簇,使其满足如下公式:,且ei∩ej=ϕ。
文本聚类的过程包括四个步骤,第一步采用分词、去噪的方法对文本进行预处理;第二步依据频率选取文本中的关键词完成对文本特征的提取;第三步将文本由自然语言文字进行文本向量化;最后一步使用聚类算法进行文本的相似度计算最终实现聚类。
3 Hadoop 平台下并行化实现文本聚类的优化算法
3.1 文本向量化并行设计
网页文本经预处理后,通过对得到的特征赋予权值,可建立以特征和权值为基础的多维空间坐标系,在多维空间中,对网页文本进行的操作可转换为对向量进行的运算。当数据量较大时,会随着文本向量的建立而增加向量空间的维度,进而导致计算量增加严重时造成机器跌宕。因此针对MapRe⁃duce并行处理大数据的优势,可在进行文本聚类时将聚类中的每个步骤基于MapReduce并行计算,即将文本向量化的过程分成四个MapReduce任务,分别用来实现文本预处理、特征的选取、特征的TF-IDF值的计算和建立文本向量。
本节主要介绍如何对文本向量化过程进行并行化的设计,从而得到所需的文本向量,图1 给出了文本向量化过程的实现框架。计算特征的TF-IDF 值需计算四个参数:count(dj) 、count(ti,dj)、N和count(ti_in_dj)。N是文本数,其余三个参数需通过三个MapReduce Job计算。
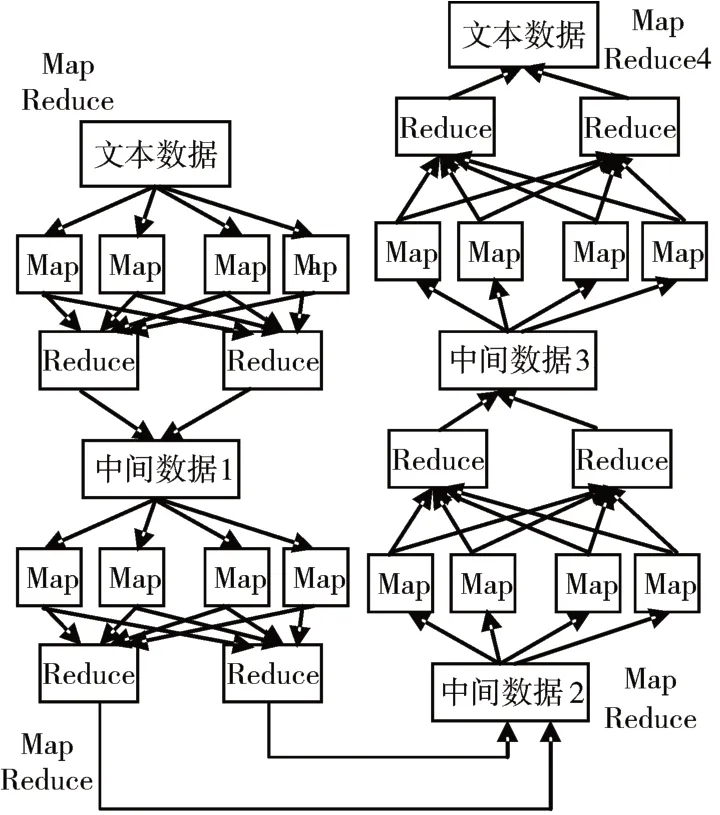
图1 文本向量化过程的实现框架
框架图中的MapReduce Job1 的工作是基于MapReduce 使用分词器对文本进行分词和去停用词等文本的预处理,并计算特征在文本中出现的次数。它的Mapper 阶段,map 函数会以
MapReduce Job2 的工作是计算特征的TF。Mapper 阶段,map 函数会以
MapReduce Job3 的工作是并行计算出每个特征的TF-IDF 值。Mpper 阶段以Job2 的输出
前述三个MapReduce Job 完成后,接下来就是并行实现文本向量化。文本向量化由MapReduce Job4 通过将MapReduce Job3 的输出转换为向量实现。Mpper 阶段的map 函数会以Job3 的输出
3.2 优化K-means并行算法
3.1 节通过四个MapReduce Job 并行实现将文本转换为文本向量后,本节的工作就是对3.1 节得到的文本向量采用优化算法并行进行文本聚类。本节为满足聚类算法有较好的效率和准确率分别从并行随机采样、并行合并数据对象和数据对象聚类并行化三个方面对K-means算法进行了优化,最后将优化的算法基于Hadoop 进行了并行实现。图2给出了优化K-means算法的MapReduce并行框架图。

图2 改进K-means算法的MapReduce框架图
3.2.1 并行随机采样
本文为提高随机采样的效率,设计了基于Ma⁃pReduce 进行随机采样的方法。基于MapReduce的并行随机采样通过两个阶段实现。
并行随机采样的第一个阶段多次对样本集进行并行采样。Mapper 的map 会以
3.2.2 并行合并数据对象
经过并行随机采样得到候选聚类中心后,由于从整体上来说,这些候选的聚类中心可能存在距离较近的对象,因此应从候选聚类中心找出高密度邻域内的对象并进行合并。并行合并候选聚类中心则由该过程中的MapReduce Job2具体实现。
MapReduce Job2 的Mapper 阶段,会以并行随机采样得到的输出
将M中的分量依次与半径R进行比较,若大于R,值为1,否则值为0。然后计算各对象的密度参数并按照从大到小的顺序排序,遍历矩阵M,合并对象,直到所有对象归入到不同簇内,最后得到MapReduce Job2 的Reduce 的 输 出 为
3.2.3 数据对象聚类并行化
通过并行随机采样和并行合并数据对象操作后,会得到初始聚类中心,得到的初始中心不再由K-means 随机选取。图2 中的MapReduce Job3 的工作就是计算文本集中其他文本向量到已经选择的聚类中心的距离,然后根据计算选择距离聚类中心最小的文本向量归类到所在的簇中,同时计算簇均值,得到新的聚类中心。
MapReduce Job3 的Mapper 的map 函数的输入为MapReduce Job2 的输出
3.3 优化K-means聚类算法并行实现
基于Hadoop 的优化K-means 聚类算法的具体实现过程如下:
Step 1:对于在3.1节中MapReduce Job4计算得到的文本向量集D={di|di∊Rp,i=1,2,…,n},通过采用等概率抽样的方法对D多次进行采样,得到样本集表示为S1,S2,…,Sn。
Step 2:随机从Si中选择文本向量dj,把dj看作第一聚类中心e1。计算D中其他的向量到dj的欧式距离,选择最远距离所对应的向量dk作为第二聚类中心e2。
Step 3:分别计算D中剩余向量di和e1、e2之间的距离,分别记做di1和di2,从中找出最小值min(di1,di2)。
Step 4:比较di1和di2,找出较大者max(min(di1,di2)),对应向量用dm表示。
Step 5:如果max(min(di1,di2))≥t|e1,e2|,t的范围为,这时取dm作为第三个聚类中心。
Step 6:当选取Si中的第n+1 个向量作为聚类中心时,计算并找到剩余向量到已知聚类中心的距离max(min(di1,di2,…,dim))所对应的向量,如果满足公式,则对应的向量作为第n+1个聚类中心。
Step 7:为获得其他聚类中心,重复执行Step2到Step6。
Step 8:依据密度参数进行升序排列。
Step 9:合并具有最大密度参数对应向量的半径R内的所有向量为簇,将访问过的向量标记好,然后重复步骤选择密度参数最大的向量,直到所有向量均被处理,得到各个簇的平均值,作为最终初始聚类中心。
Step 10:将Step 9 计算得到的聚类中心作为K-means的初始中心并运行该算法。
最后将优化的算法基于Hadoop 进行具体的实现。
4 实验结果
本文对Hadoop 平台下优化的文本聚类算法进行了实现。实验通过采用6 台虚拟机作为Hadoop集群的六个节点,用1 台虚拟机作为集群中的Mas⁃ter 节点,剩下的5 台虚拟机则用来作为Slaver 节点。实验分别从聚类效率、聚类质量两个方面进行了测试。
4.1 聚类效率实验
对数据集S1、S2分别在1、3、6个节点构建的集群上进行了基于Hadoop 的文本向量化和基于Ha⁃doop 的优化K-means 文本聚类实验,表1 和表2 分别给出了数据集S1、S2 在不同节点个数上文本聚类运行的时间。
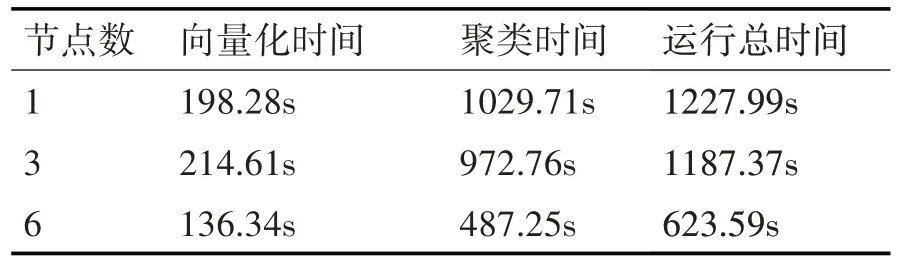
表1 S1在不同节点进行文本聚类时的运行时间
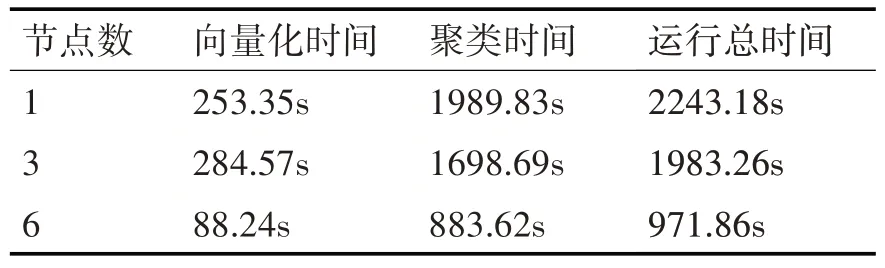
表2 S2在不同节点进行文本聚类时的运行时间
由表1 和表2 可见,对S1、S2 进行操作时,Ha⁃doop集群节点个数越多,程序无论在文本向量化还是在聚类上运行所需时间均在减少,节点个数增加越多,程序运行所需时间越少,并且随着数据集规模增加,算法运行时消耗的时间减少的也越多,由此表明基于Hadoop 的多节点的集群更适合处理大数据集,特别在节点个数达到6 个时,算法运行效率大大提高。
4.2 聚类质量实验
为了测试优化的K-means 并行算法的聚类质量,本实验分别对文本向量集S1 和S2 在K-means聚类算法和优化K-means聚类算法上进行了聚类,表3和表4分别给出两种不同聚类算法对S1和S2在五个类别上的查准率(Precision)和查全率(Recall)。

表3 数据集S1的Precision和Recall

表4 数据集S2的Precision和Recall
由表3 和表4 可见,优化K-means 并行算法在查准率和查全率上都比传统K-means 聚类算法要高。由于数据集S2 的规模大于数据集S1,因此在S2 上的查准率和查全率无论在哪个算法上都比在S1 上的查准率和查全率要小,但在减小幅度上,优化的K-means要比K-means减小的少,由此说明优化的K-means并行算法相对更稳定。
5 结语
本文首先介绍了文本聚类和Hadoop 开源云平台中的相关知识,针对传统K-means聚类算法存在初始中心选取随意而导致运行不稳定及单机串行编程对海量数据聚类效率低的缺点,提出并设计一种Hadoop 平台下并行化实现文本聚类的优化算法,然后详细地介绍了算法具体设计和实现的过程,文中在最后通过搭建的Hadoop 集群对数据进行测试,实验结果表明优化的文本聚类并行算法在聚类效率和聚类质量上均有较大的提高。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
科学与社会(2022年1期)2022-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
莫愁(2019年36期)2019-11-13
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
新高考·高二数学(2015年11期)2015-12-23
