
基于改进Faster RCNN 的目标检测算法∗
2022-03-18 06:20孙顺远
计算机与数字工程 2022年12期
孙顺远 杨 镇
(1.江南大学轻工过程先进控制教育部重点实验室 无锡 214122)(2.江南大学物联网工程学院 无锡 214122)
1 引言
过去很长一段时间各类识别任务都是建立在对SIFT[1](Scale Invariant Feature Transform)、HOG[2](Histogram of Oriented Gradient)等特征的使用之上的。20世纪80年代,Fukushima第一次提出一个多层神经认知机Neocognitron。1998 年,Yann LeCun提出用于识别手写字的LeNet网络[3]奠定了由卷积层、池化层、全连接层组成的现代卷积神经网络基本结构。卷积神经网络因此得以广泛使用,然而之后又随着支持向量机等手工设计特征模型的崛起而淡化。随着图形处理器GPU(Graphics Process⁃ing Unit)性能的巨幅进步以及大数据带来的历史机遇,深度卷积神经网络在2012 年迎来了重大的突破。AlexNet[4]首先把卷积神经网络的基本结构应用到很深很宽的网络中去,将LeNet 的思想发扬光大,首次在卷积神经网络中应用了非线性激活函数ReLU[5],并且通过数据增强、随机失活Dropout[6]等方法防止训练过拟合。得益于飞涨的GPU 性能和百万级的ImageNet图像数据集[7],Geoffrey Hinton和Alex Krizhevsky 凭 借AlexNet 在ILSVRC 2012(ImageNet Large Scale Visual Rec-ognition Challenge)挑战赛中夺冠。此后各类应用于图像分类的深度卷 积 神 经 网 络 如VGG 网 络[8]、Inception 网 络[9]、ResNet网络[10]等如雨后春笋般出现。
与图像分类不同,检测还要在图像中定位目标具体位置。Ross Girshick 等提出的R-CNN(region with CNN features)[11]首次将卷积神经网络运用于目标检测。R-CNN 使用选择性搜索[12]替代传统的滑窗搜索来提取候选区域。由于每张图片提取出的候选区域中有大量的重复,且都需要进行神经网络的前向传播导致检测速度过慢。鉴于此,Ross Girshick 团队借助于SPP-Net(Spatial Pyramid Pool⁃ing Network)[13]提 出 了R-CNN 的 改 进 版Fast R-CNN[14]。Fast R-CNN 直接对整张图片做特征提取,候选区域在特征图之后再做提取,不需要对所有候选区域进行单独的神经网络的前向传播,避免了特征的重复提取。采用了深度学习中常见的softmax 分类器代替SVM 分类器,通过多任务损失函数进行边框回归,一定程度上提升了模型的训练和检测速度。但由于Fast R-CNN 仍旧使用选择性搜索来提取候选框使得模型无法满足实时性检测的需求。于是任少卿等继续提出了Fast R-CNN 的改进版Faster R-CNN[15],使用区域生成网络RPN(Region Proposal Network)代替选择性搜索方法,更高效地生成候选区域。
以上这些网络模型都需要先生成一系列的候选区域,再通过卷积神经网络进行分类。Joseph Redmon 等提出的YOLO(You Only Look Once)[16]网络模型取消了区域生成网络,直接回归目标的类别概率和位置坐标值,牺牲了一定的精度但大大提高了模型的速度。刘伟等提出了融合了Faster R-CNN 锚框思想整体仍然采用一步法架构的SSD(Single Shot Detector)[17]网络,既考虑到了模型的精度又照顾了模型的速度,使实时高精度的目标检测成为可能。
2 Faster R-CNN网络结构描述
Faster R-CNN 分别使用了ZF 模型(Zeiler and Fergus model)[18]和VGG16 模 型(Simonyan and Zisserman model)作为基础骨干网络,如图1所示为使用VGG16 作为骨干网络的Faster R-CNN 网络整体结构。整个网络首先使用一组基础的卷积神经网络来提取输入图像的特征图,该特征图被用于后续 的RPN 层 和RoI Pooling(region of interest pool⁃ing)层。RPN 层通过Softmax 函数先判别生成的锚框(anchor)属于正样本或负样本,再利用边框回归(bounding box regressin)修正锚框的位置,从而获得精确的基于原图的区域提案(region proposals)。RoI Pooling 层综合RPN 层输出的区域提案和CNN层输出的特征图后,提取出基于特征图的区域提案(feature map proposals)。最后利用基于特征图的区域提案计算proposal 的类别,同时使用bbox-reg获得检测框的最终精确位置。
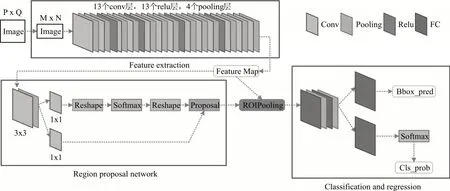
图1 Faster R-CNN网络框架
3 改进的Faster RCNN算法
为了提高算法性能,同时兼顾模型的运算速度,进行了如下几点的改进。用DIoU(Distance In⁃tersection over Union)[19]作为评价预测框和目标框的距离指标,并将其作为损失函数,使得边框回归更加收敛。将区域特征聚集方式从候选区域池化RoI Pooling 改进为效果更好的候选区域校准RoI Align[20],减小了误差,使得检测结果中的预测框位置 更 加 精 确。 使 用Soft-NMS[21]替 换NMS(Non-Maximum Suppression),提高了锚框的检测率,从而有效地提升目标检测的精度而又不影响速度。
3.1 损失函数
损失函数是用于目标检测任务中评价模型性能的常用指标,Faster R-CNN 中采用的IoU Loss 就是最为常用的损失函数。相较于Fast RCNN 中的Smooth L1 Loss,它解决了4点坐标不具有一定相关性的问题和相同大小Loss 的检测框IoU 差异过大的问题。但是它也带来了相应的问题:只是降低了相同大小Loss 的检测框IoU 过大的差异,实际上差异仍然存在;如图2 所示,它无法反映两个检测框之间的实际距离,不能反映两个检测框是如何相交的;当真实框与预测框重合,此时IoU 为0,损失函数不可导,模型无法优化进行有效训练。
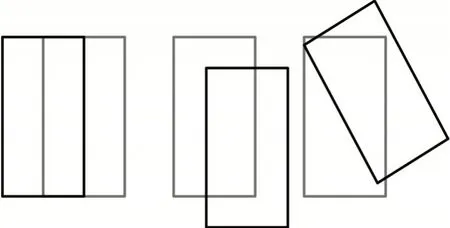
图2 相同IoU的位置效果
基于此,提出使用DIoU 改进原算法。DIoU 定义如下:
式(1)中:A代表预测框的面积,B代表目标框的面积。如图3 所示,作为惩罚项的式(2)中:b是预测框的中心点位置,bgt是目标框的中心点位置,ρ是预测框和目标框中心点的欧氏距离。c是能够同时包含预测框和目标框的最小闭包区域的对角距离。

图3 目标真实位置与预测位置效果示意图(绿色为预测框,黑色为真实框,灰色为两者的最小闭包矩形框)
和IoU Loss 相比,DIoU Loss 具有尺度不变性;考虑了重叠面积和中心点距离,对模型精度更加有利;通过直接最小化预测框和目标框之间的归一化距离,使模型更加收敛。
3.2 RoI Pooling
RoI Pooling是用于将RPN提取的Proposal结合特征图进一步提取得到统一大小的特征图。由于RPN 网络提取到的RoI 坐标是针对输入图像大小的,所以第一步就是将RoI 坐标缩放到输出特征对应的大小,第二步将取整后的RoI 划分为h*w个小区域,最后采用最大池化处理每个小区域,最终输出h*w大小的RoI 特征。通过以上步骤可以发现,整个RoI Pooling中包含两次取整量化,又由于缩放操作,导致两次量化的误差进一步放大。
针对两次量化操作引起的误差,提出取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,这样就将特征聚集过程变成了一个连续的操作,这样有效地避免了由于取整量化操作带来的误差。如图4 所示,假设采样点数为4,对于每个小区域平分四份,每份取采用双线性插值法计算出的中心点位置,取四个像素中最大值为这块区域的像素值,重复操作,这样就能够得到固定维度的特征输出。

图4 RoI Align的反向传播
3.3 NMS
目标检测过程中在同一位置会产生大量的候选框,这些候选框之间会相互重叠,这时就需要利用NMS 找到最佳的目标边界框。非极大值抑制(Non-Maximum Suppression)就是对检测后的结果进行去冗余操作,通过搜索局部最大值,抑制极大值。通常的做法是将候选框按照对应的分类划分为不同的集合;然后在每个集合内根据得分高低降序排列,将得分最高的候选框和剩下的其他候选框进行交并比计算,若大于一个人为设定的阈值则剔除,最终保留该得分最高的候选框并从集合中取出;将原得分第二的候选框即现得分第一的候选框重复按照上述步骤迭代操作,直至集合中所有候选框都完成筛选;最后对每个集合中的候选框重复上述步骤,直至所有集合都完成筛选。NMS算法直接粗暴地将计算后的IoU 值大于阈值的候选框直接删除,特别是当两个目标物体靠近或者部分重叠时,分数较低的候选框就会因为和分数较高的候选框的重叠面积过大而被优化删除,这导致了对该物体的检测失败,并且降低了算法的平均检测率。
基于这样的问题,提出使用Soft-NMS 改进原有算法。如式(4)所示:
Si代表了每个候选框的得分,M为当前得分最高的候选框,bi为剩余待处理的候选框的某一个,Nt为人为设定的阈值。可以看出当IoU 大于设定的阈值时,该候选框得分直接置零,候选框被舍弃,无法参加后续的迭代,从而可能造成目标的漏检。如式(5)所示:
改进的NMS 算法的得分重置函数采用线性加权形式,这是一种较二值化得分重置函数更为稳定、连续的改进形式。它不是直接粗暴地对候选框得分置零删除候选框,而是降低当前候选框的得分,使得它能进入到下一轮的迭代,这能够有效地提升目标检测的精度,而又不会影响运算的速度。
4 实验结果对比分析
4.1 训练方法
本文实验环境为Ubuntu 16.04 稳定版、CUDA v10.1、cuDNN v7.5、NVIDIA GeForce GTX1080 显卡,深度学习框架使用Pytorch,具体版本为torch v1.3.1、python v3.7。
评估指标使用平均精度均值mAP(mean Aver⁃age Precision)。测试集使用PASCAL VOC 2007,训练集使用PASCAL VOC 2007、2012 和MS COCO 数据集[22]以及它们的联合数据集。本文使用ImageN⁃et预训练的模型初始化网络的权值,采用交替优化训练的方式,在VGG16、ZF 两种训练模型下进行了训练。交替优化训练步骤如下:首先网络使用Ima⁃geNet 的预训练模型进行RPN 网络的初始化,通过反向传播和随机梯度下降SGD(stochastic gradient descent)训练。对于60k 的小批量数据使用0.001的学习率,对于20k 的小批量数据使用0.0001 的学习率,权重衰减设置为0.0005。并针对区域提议任务进行微调。接着使用由上一步RPN 网络生成的候选建议框由卷积神经网络训练单独的检测网络。然后使用检测网络来初始化RPN 网络的训练,但是只修正共享的卷积层,且只针对RPN 特有层进行微调。这样这两个网络就共享了卷积层。最后对卷积神经网络的特有层进行微调,这样两个单独的子网络就共享了相同的卷积层,构成了统一的网络。
4.2 对比分析
从表1 中可以看出,不管是选择ZF 还是VGG作为基础骨干网络,RPN 方法都较SS 方法的mAP更高。在使用VGG 模型和RPN 方法的系统下也即是Faster R-CNN 网络下,单独添加每项改进,可以发现检测结果有1%~3%的微小提升。组合各项改进后的系统的检测结果较Faster R-CNN提升近6%效果明显,而且运行速度较原算法也有提升。从表1 中还可发现,在使用相同系统的情况下,使用VOC2007 和VOC2012 的联合训练集的效果比单独使用VOC2007 数据集的效果更好,说明更大的训练集对于网络的训练是有利的。考虑到MS COCO数据集在类别上是PASCAL VOC 数据集类别的超类,实验中忽略掉COCO 数据集专有的类别,soft⁃max 层只在VOC 数据集专有的类别上执行,从表1中可以发现,在COCO 和VOC2007、2012 联合数据集地训练之下,改进后的Faster R-CNN 算法在VOC2007测试集上的mAP达81.3%,检测精度高。
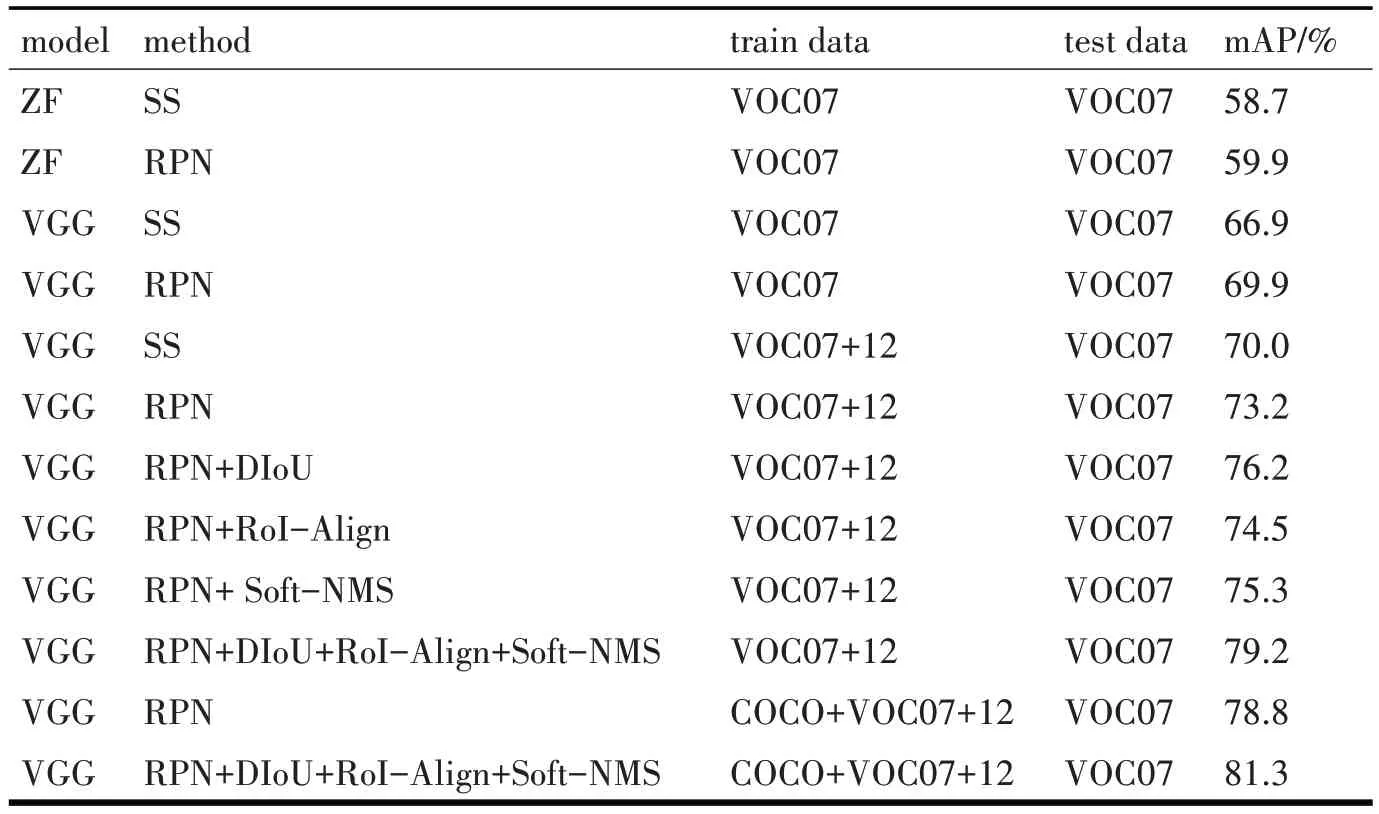
表1 PASCAL VOC2007测试集下的检测结果
5 结语
本文提出一种改进的Faster R-CNN 算法,引入DIoU 评价指标,关注了预测框和目标框的距离而不单单关注预测框和目标框的重叠面积;将候选区域池化方法改进为一种区域特征聚集方式,规避了区域池化方法带来的量化误差;使用Soft-NMS替代原有的非极大值抑制,有效地提升了目标检测精度。实验结果表明,改进后的Faster R-CNN 算法检测结果很好,基于一种联合数据集训练后在VOC2007 测试集上的检测结果达81.3mAP。后续将针对算法检测速度相对较慢的缺陷继续优化模型,提高整个系统的运行与检测速度。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
北京航空航天大学学报(2021年9期)2021-11-02
计算机技术与发展(2020年2期)2020-04-15
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
火力与指挥控制(2018年3期)2018-04-19
