
基于时空异构双流卷积网络的行为识别
2022-03-18 05:01:14丁雪琴朱轶昇朱浩华刘光灿
计算机应用与软件 2022年3期
丁雪琴 朱轶昇 朱浩华 刘光灿
(南京信息工程大学自动化学院 江苏 南京 210000)
0 引 言
行为识别是计算机视觉研究的一个热点,目标是从一个未知的视频或图像序列中自动分析其中正在进行的行为。它在视频监控、行为分析、智能家居、视频检索和人机智能交互等领域发挥着重要的作用,但由于视点变化、背景杂乱和光照条件等限制,行为识别仍然面临着重大挑战。近年来,深度卷积网络(ConvNets)[1]在图像和语音识别方面取得了巨大的突破。此后,计算机视觉的研究人员一直试图将卷积网络转移到行为识别上来应用。
与图像领域的成功相比,深度学习在基于视频的行为识别领域发展相对缓慢。主要有两个原因:(1) 与图像数据集相比,视频数据的规模和多样性是不可比拟的,因此需要建立一个用于深度网络训练的大规模标记视频数据库;(2) 与二维图像相比,视频包含更多的时序信息,引入了比图像更复杂的分析工作。
为了解决上述问题,近年来人们针对基于深度卷积网络的视频行为识别进行了许多尝试,也获得快速发展。Karpathy等[2]比较了几种用于行为识别的卷积网络体系结构,并在一个非常大的Sports-1M数据集上进行了相应的训练过程。Tran等[3]介绍了一种基于三维卷积网络的动作识别方法。Simonyan等[4]提出了一种基于双流网络的性能优化方法。虽然这些方法在一定限度上利用了视频中的时间信息,但它们只关注短期的运动变化,没有捕获视频中的长时间信息。为了解决这个问题,Wang等[5]提出了一种从视频数据中提取长时间信息的时域网络(TSN)。对于时间跨度较长的视频行为识别而言,单帧或者是单个短片段中单帧堆栈的数据量是不够的,需要采用密集时间采样的方式来获取长范围时间结构,但是这样会存在视频连续帧之间的冗余,因此要用稀疏的时间采样来代替密集的时间采样,也就是对视频做抽帧的时候采取较为稀疏的抽帧方式,这样可以去除一些冗余信息,同时降低计算量。Cho等[6]提出了一个新的时空融合网络(STFN),它集成了整个视频的外观和运动信息的时间动态,然后将捕获的时间动态信息进行融合,以获得更好的视频级表示,并通过端到端训练进行学习。Martinez等[7]利用细粒度识别方面的进展来改进行为识别的模型,将重点放在如何提高网络的表示能力,也就是改进网络的最后一层,在这一层中变化对计算成本的影响很小。Torpey等[8]使用三维卷积神经网络从视频采样片段中分别提取局部外观和运动特征,将局部特征连接起来形成全局表示,然后用全局表示训练一个线性支持向量机来执行行为分类。
基于以上方法,本文提出一种基于行为识别的双流卷积网络结构。在原双流网络结构中,时间网络和空间网络具有相同的结构,但人们对表观和运动的理解是两个截然不同的过程,因此空间和时间网络应该是不一样的。为了解决这一难题,本文提出了一种基于时空异双流网络的行为识别方法。此外,为了从视频序列中提取长时间信息,将视频分段[5]的思想引入到提出的时空异构网络中。实验结果表明,本文时空异构双流网络的性能优于时空同构网络。
1 时空异构双流卷积网络模型
本文基于双流卷积网络,提出了时空异构的双流网络结构,在此基础上,将BN-Inception和ResNet引入作为时空异构双流网络的基本网络,最后引入视频分段的思想,建立了视频分段的时空异构双流卷积网络模型,整体框架如图1所示。
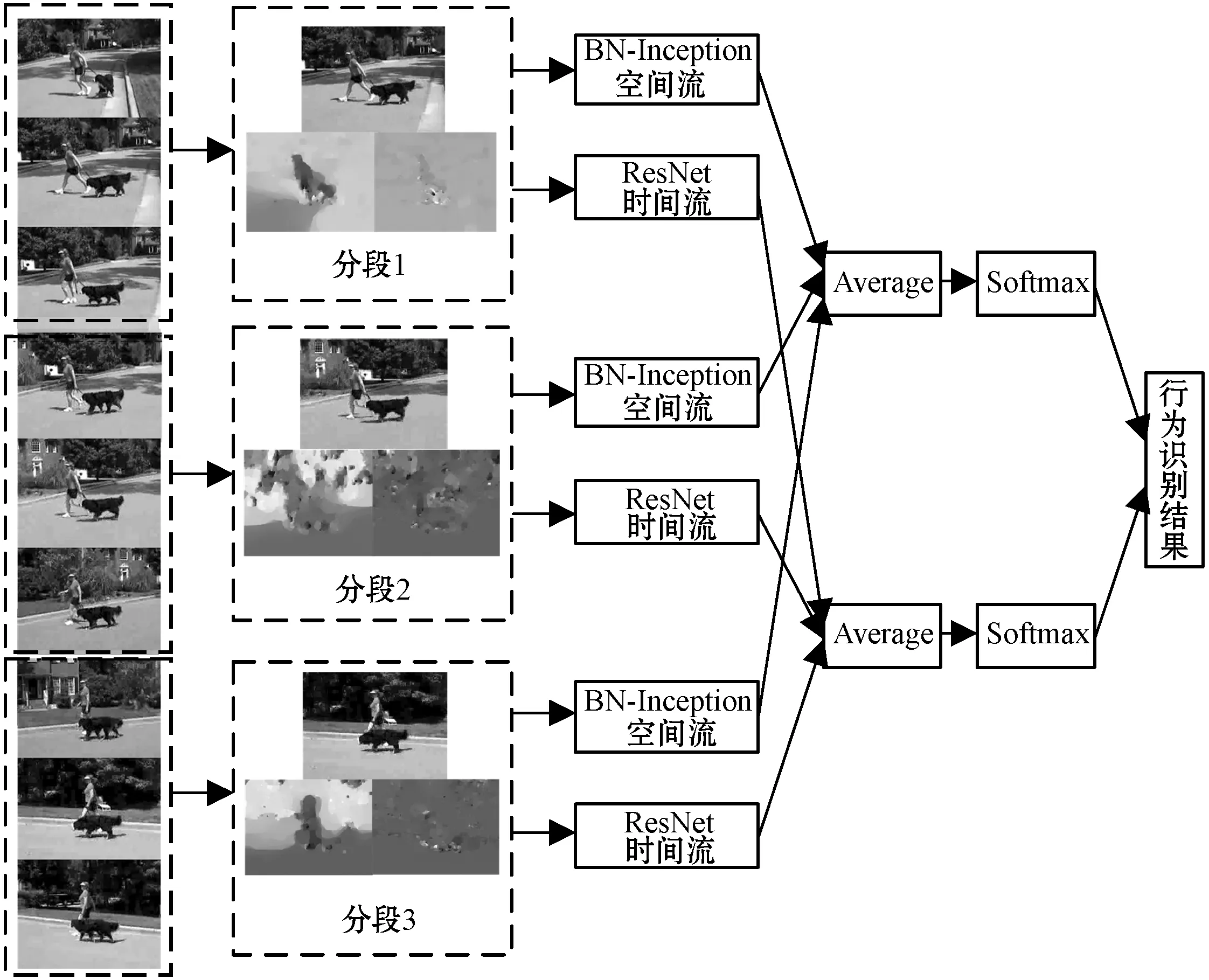
图1 整体框架
1.1 时空异构双流网络
时空异构双流网络结构如图2所示,其采用了不同的网络结构。可以看出,设计时空异构双流网络有两个动机:(1) 当双流网络中的时空网络具有相同的结构即时空同构时,双流合并时会产生大量的冗余信息;(2) 由于人对表观和运动的理解是两个截然不同的过程,所以时空的网络结构应该是不一样的。
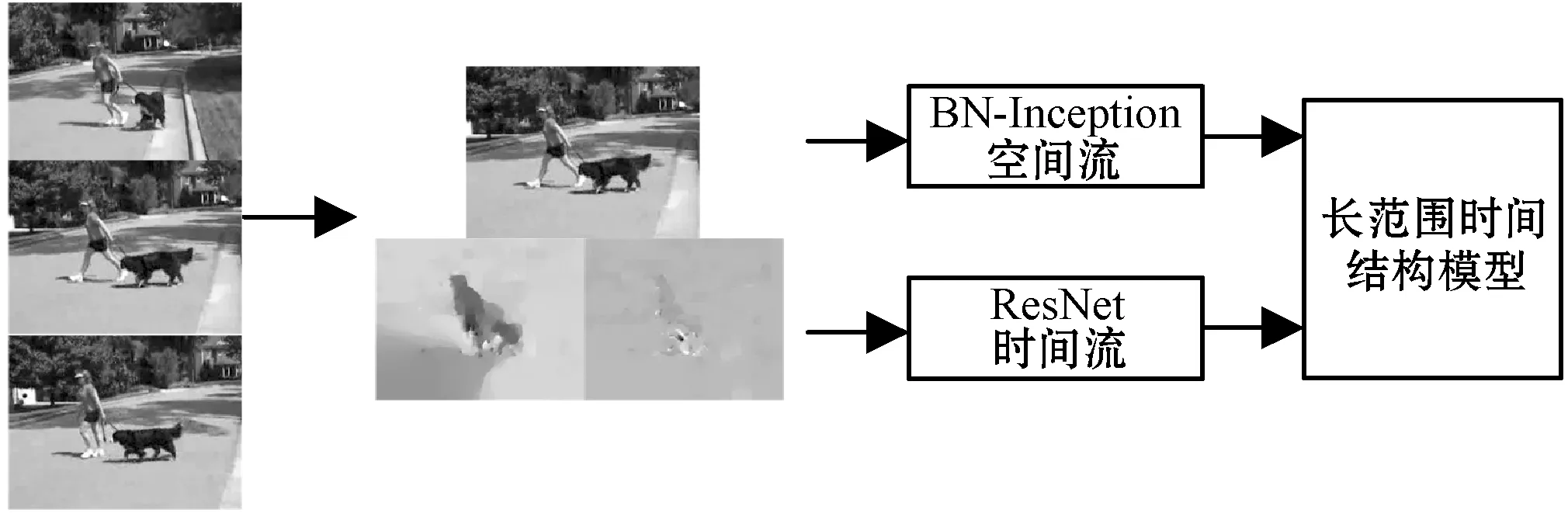
图2 时空异构双流结构
输入数据的形式是RGB图像和光流场,如图3所示。单个RGB图像是对视频的中的某一帧的静态外观进行编码,光流场是视频的光流信息用来获取运动信息。与原始的双流卷积神经网络[1]一样,空间卷积神经网络对单个RGB图像进行操作,而时间卷积神经网络以一组连续的光流场作为输入。

图3 输入数据形式
1.2 网络架构
一个好的视频网络结构应该提取更多不同的时空信息。为了最大限度地挖掘时空异构双流网络的潜力,本文在时空异构双流网络中引入ResNet和BN-Inception网络作为提取时空特征的网络结构。
1.2.1残差网络

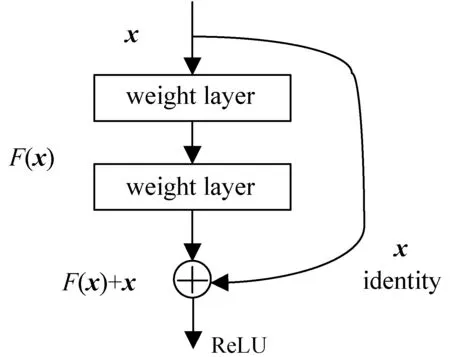
图4 残差单元结构
残差单元被定义为[9]:
xl+1=σ(xl+F(xl;wl))
(1)
式中:xl和xl+1分别为第l层的输入和输出;F(xl;wl)是非线性残差映射;σ(·)表示ReLU函数[10]。残差单元的主要优势是跨层连接的方式可以从第一层直接传播到网络中的任何层,避免了梯度爆炸和消失的问题。同时,跨层连接不会引入额外的参数和计算复杂度,而且可以加快网络的收敛速度。
1.2.2BN-Inception
BN-Inception[11]用一个非常有效的正则化方法,使大型卷积网络的训练速度加快,同时收敛后的分类准确率也得到大幅提高。它不再依赖于具有技巧性的参数初始化点,可以使用更大的学习率加快训练过程,另外其正则化手段可以有效缓解Sigmoid或tanh等激活函数的梯度消失问题,同时在一定程度上也降低了对Dropout等手段的依赖。
由于ResNet能够通过增加相当的深度来提高准确率,BN-Inception网络用一个非常有效的正则化方法,让大型卷积网络的训练速度加快,同时收敛后的分类准确率也得到大幅提高。因此本文将ResNet和BN-Inception网络作为基本网络,构建了一个更深层次的时空异构双流网络。与双流网络使用的VGG网络相比,ResNet具有更少的滤波器和更低的计算复杂度。虽然增加了ResNet的深度,但ResNet- 50(38亿次)和ResNet-101(76亿次)的计算复杂度仍然低于VGG-16(153亿次)和VGG-19(196亿次)。
1.3 建模长范围时间结构
视频中的长时间信息对行为识别也起着非常重要的作用。从TSN[5]中得到引导,通过视频分段来提取视频序列中长时间的时间信息来提高时空异构双流网络的性能。根据时间的长短,将视频分成K个等长片段{S1,S2,…,SK},基于分段的空时异构双流卷积网络Y对行为的识别可以表示为:
Y(T1,T2,…,TK)=H(g(F(T1;W),F(T2;W),…,
F(TK;W)))
(2)
式中:(T1,T2,…,TK)是一个片段序列,每个代码片段TK从其对应的片段SK中随机采样,在空间网络对应的是RGB帧图像,时间网络是光流;F(TK;W)是一个带有参数W的卷积神经网络函数,该函数对代码片段TK进行操作,生成所有类的类分数;分段融合函数g(·)将多个短片段的输出融合,得到空间网络或时间网络的特征。利用输出函数H(·)对识别结果进行分类,利用Softmax函数得到各行为类别的概率值。
分段融合的最终损失函数定义为:
(3)
式中:C表示动作类别的数量;yi表示关于类别i的基准标签;Gi=g(F(T1;W),F(T2;W),…,F(TK;W))是类i的类得分,通过对K个片段的同一类别的得分进行平均得到。本文利用多个片段,用标准的反向传播算法联合优化模型参数W。反向传播过程中,W的梯度对时空异构双流网络行为识别损失值L可以推导出如下公式:
(4)
然后,通过小批量随机梯度下降法得到相关的模型参数。从式(4)可以看出,使用K个小片段的类别融合G来更新参数。使用此类优化方式,能学习到视频级的模型参数,进而获得长期的时间信息。
2 实 验
2.1 数据集
本文在UCF101[12]和HMDB51[13]两大数据集上验证方法的有效性。UCF101数据集包含101个动作类和13 320个视频剪辑。HMDB51由51个动作类别的6 766个视频剪辑组成。对于这两个数据集,本文遵循THUMOS13挑战机制[14]的评估方案,在训练和测试过程中,将每个数据集分为三组,以三组数据的平均准确性作为评价模型效果的指标。
2.2 基本参数设置
本次实验是基于PyTorch 0.3.0深度学习框架。采用MBGD来学习网络参数,批量参数为256,动量参数为0.9,使用来自ImageNet的预训练模型初来始化网络权重。在实验中设置了一个较小的学习率。对于空间网络,初始化学习率为0.001,每2 000次迭代减少到它的1/10次。整个训练过程在4 500次迭代停止。对于时间网络,设置初始化学习率为0.005,经过12 000和18 000次迭代后,学习率降低到它的1/10,最大迭代设置为20 000。
在测试过程中按照双流网络结构[4]的测试方法。在相同的时间间隔内,从动作视频中采样25帧RGB帧或光流堆栈。对于每个采样帧,通过裁剪4个角、1个中心和其水平翻转来获得网络的10个输入。本文融合时空网络采用的是加权平均,设置空间网络和时间网络的权值比为1 ∶1.5。以下所有的实验都是在UCF101第一组数据集上进行。
2.3 不同分段数目性能分析
将视频分为K个等长的片段来对长范围时间视频进行建模。当视频段数较少时,会导致行为信息提取不足,训练模型过于简单;当视频段数较多时,将导致数据冗余,增加计算量。表1显示了使用ResNet50/101网络时,不同视频段下时间网络的识别性能。结果表明,将视频分成三段时有较好的识别性能。因此在以下实验中,视频片段的数目都设置为3。
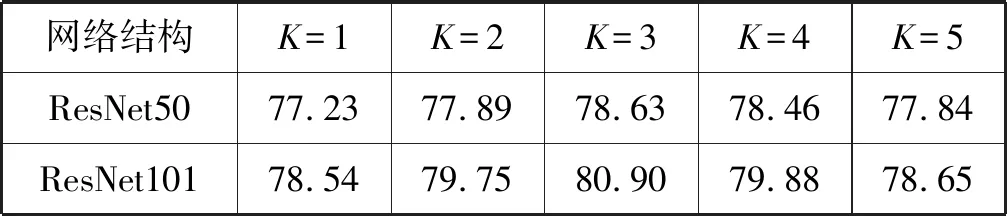
表1 时间网络中不同视频段数的行为识别准确率对比(%)
2.4 不同分段融合函数性能分析
在式(2)中,分段融合函数由函数g(·)定义。本文评估了最大池化、平均池化和加权平均池化三个融合方案来作为融合函数的形式。实验结果见表2。可以看出,平均池化函数可以获得最佳性能,最大池化的方式整体性能较差,可能是由于视频分段中内容不同会导致判别误差比较大。因此在以下实验中,本文选择平均池化作为默认的分段融合函数。
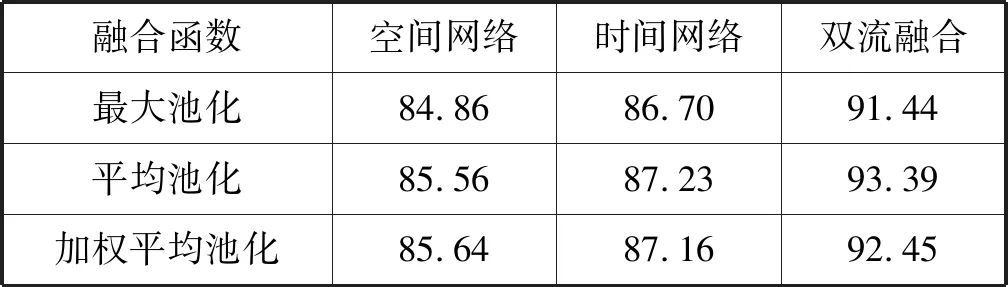
表2 基于BN-Inception结构下不同融合方式准确率对比(%)
2.5 时空异构和时空同构网络分析
本节中的所有实验都是在UCF101的第一组数据上进行的。本文将时空异构网络分为同一类型的不同深度的网络和不同类型的网络。测试使用了ResNet-50、ResNet-101和BN-Inception[11]。比较了三种不同网络结构的性能,分别为:(1) 具有相同结构的时空网络;(2) 深度不同但结构相同的时空网络;(3) 具有不同网络结构的时空网络。在实验中可以发现结构相同但深度不同的时空网络的性能要优于时空同构网络,实验结果见表3。从双流融合的结果来看,ResNet-101是时间网络的最佳选择。选择ResNet-101作为时间网络,选择不同结构的BN-Inception作为空间网络时,其对UCF101的第一组数据的准确率为92.24%。实验表明,时空异构网络的性能优于时空同构网络。
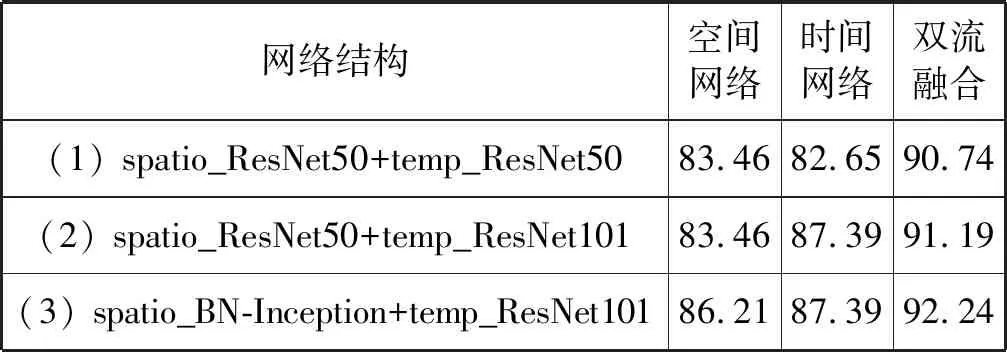
表3 时空异构和时空同构网络的准确率比较(%)
2.6 与现有方法对比
表4将本文方法与现有方法进行比较,如基于稠密轨迹编码方式的DT[15]和iDT[16]表示方法、基于深度学习方法的3D卷积网络(C3D)[17]、双流卷积网络(Two Stream)[4]、空间时间分解卷积网络(FSTCN)[18]和长期卷积网络(LTC)[21]。从表4中UCF 101和HMDB51数据集可以看出,本文方法优于其他方法。与双流方法(Two Stream)[4]相比,其准确率分别提高了4.3百分点和3.1百分点。验证了时空异构双流网络在基于长时间结构上的建模是效果显著的,相比于时空同构双流网络,时空异构双流网络的性能有一定的提高。
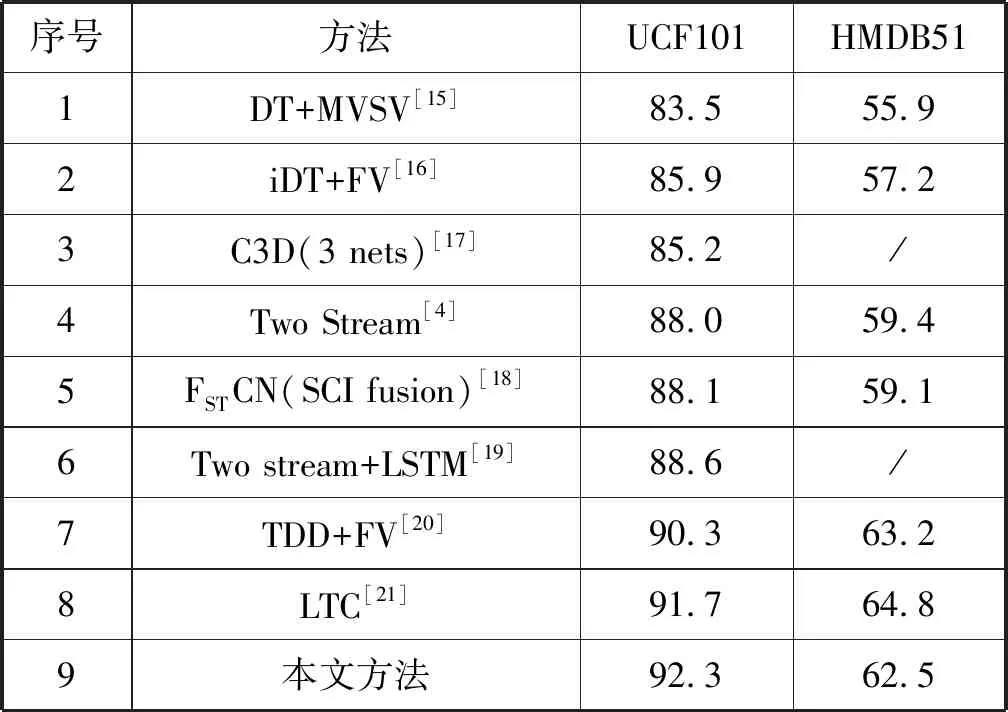
表4 本文方法与其他方法的准确率比较(%)
3 结 语
本文提出了一种用于人体行为识别的时空异构双流网络。由于人类对表象和运动的认识和理解是两个完全不同的过程,本文改进了现有的方法,设计了不同的网络结构来提取时空信息。通过实验研究在性能上对时空异构双流网络和时空同构双流网络进行比较,从结果可见时空异构双流网络的性能更好。同时为了发掘时空异构网络的最大潜力,以ResNets和BN-Inception作为基本网络来提取更多的表观和运动特征。在此基础上,建立了视频的长时间时间信息提取结构。通过端到端培训,该网络在HMDB51和UCF101数据集上的性能显著提高。
猜你喜欢
中小学校长(2022年7期)2022-08-19 01:36:36
小学教学研究(2022年5期)2022-04-28 21:29:36
冶金设备(2020年2期)2020-12-28 00:15:22
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
