
全局信息引导的多尺度显著物体检测模型
2022-03-18 05:01:14陈小伟林家骏
计算机应用与软件 2022年3期
陈小伟 张 裕* 林家骏 张 晴
1(上海应用技术大学 上海 201418)2(华东理工大学 上海 200237)
0 引 言
显著物体检测的目的是模拟人的视觉感知,从杂乱背景中定位和分割出最引人注意的具有精确轮廓的物体。近年来,显著性物体检测作为一个预处理步骤被广泛应用于各种计算机视觉任务,包括视频跟踪[1]、目标识别[2]和图像编辑[3]等。
根据算法是否使用深度特征,可将显著性物体检测算法分为两大类:基于手动选择特征的传统方法[4-5]和使用深度神经网络提取语义特征的方法[6-7]。传统的显著性检测方法采用颜色、纹理、形状等图像中低层特征,并利用启发式先验条件(颜色对比度、边界、物体级信息等)进行显著性物体检测计算。虽然基于传统的方法在处理简单场景图像时取得了较好的检测效果,但由于其无法提取图像深层的语义特征,因此在面对复杂图像时,检测效果与人的视觉感知结果存在较大的差异。
近年来,卷积神经网络在计算机视觉任务中显示出了其强大的特征表征和学习能力。受此启发,研究人员将卷积神经网络应用于显著性检测任务。一些基于卷积神经网络的显著性检测算法[6,8,22]利用了图像的深度特征,取得了比传统方法更好的检测性能。随着全卷积神经网络的兴起,研究人员发现,融入中低层特征的显著性检测模型[9-10,23-24]相比仅利用深度特征的方法更进一步提高了算法性能,因为中低层特征包含丰富的结构和细节信息,对于勾勒出完整和精确的轮廓信息具有十分重要的作用。
尽管现有算法取得了令人瞩目的成果,显著性物体检测领域仍具有如下问题需要解决:(1) 基于特征金字塔网络(Feature pyramid network,FPN)[11]结构的显著检测模型,将深度信息逐层传递给浅层,在传递过程中,深度信息必然有损失,不能全部传递给最浅层;(2) 自然场景中包含各种尺度的物体,而某一固定大小的卷积核只能处理固定尺寸的目标物体,因此如何在每一层次的特征中融合多尺度信息值得进一步研究。
本文提出一种简单有效的基于全卷积神经网络的显著性物体检测模型,结合图像的多层次特征,探索多尺度特征的表示和融合,并且将全局信息直接与每一层的特征进行融合,指导多层次特征的提取,从而提高模型的检测性能。
本文工作主要贡献如下:(1) 提出了一种新的全局信息引导的多尺度特征卷积神经网络用于显著物体检测,将全局信息直接与多层次局部特征相结合。该模型能更好利用全局信息,从而提高检测性能。(2) 设计了多尺度卷积模块,利用同一侧输出的不同尺度特征融合,提高网络各层次特征的表达和学习能力。(3) 根据常用的评价指标,在ECSSD、DUT-OMRON、PASCAL-S和DUTS-TE数据上进行算法性能比较与分析,从而说明本文算法的有效性和鲁棒性。
1 相关工作
显著性检测方法可以分为基于眼动点的显著性预测和具有精确物体轮廓信息的显著性物体检测,本文主要关注显著性物体检测。
1.1 基于手动选择特征的方法
大部分传统的显著性物体检测方法先将图像进行超像素分割,然后采用手动选择图像的中低层特征进行显著性计算。基于局部的方法[12]使用每个超像素的对比度或独特性等先验信息来捕获局部显著区域。而基于全局的方法[13-14]通过使用整个图像的整体信息来计算每个超像素的显著度。由于基于手动选择特征的方法不能有效利用图像蕴含的语义信息,因此无法从复杂图像中精确检测和分割显著性物体。
1.2 基于深度特征的方法
近年来,基于卷积神经网络的显著性物体检测方法[19]明显提高了检测性能。Wang等[6]提出一个深度神经网络,首先计算局部上下文中每个像素的显著性得分,然后用另一个网络在全局视图上重新评估每个对象的显著性得分。Li等[8]利用深度神经网络提取图像的多尺度特征,通过融合这些特征计算显著性值。Zhao等[15]通过整合全局和局部信息预测显著性图。然而,上述检测方法将图像区域视为基本的计算单元,网络必须运行多次得到整个图像的显著性值。
为了解决该问题,研究人员引入全卷积网络,采用图像到图像的方式进行显著性检测[7]。利用全卷积网络的各个侧边输出的多层次特征,采用类似U-Net结构,进行显著性检测信息的编码和解码。网络的低层侧边输出的特征富含低层特征,但缺乏图像的整体语义信息;而网络的深层侧边输出的特征含有丰富的语义信息,但缺乏图像的结构细节。因此,结合网络的不同侧边输出的多层次特征有助于进一步提高显著性预测的准确性。
Luo等[16]通过一个多分辨的4×5网格结构融合图像的局部和全局信息,并采用Mumford-Shah函数进行边界优化。文献[17]采用反注意力图引导特征选择。文献[18]采用跳层连接方式将深层特征融入各浅层侧输出,从而进行显著性计算。Zhang等[10]利用注意力机制,逐层引导各侧边输出整合多层次特征。Zhang等[20]提出采用双向信息传递模型整合多层次特征。
虽然这些基于深度学习的方法已经取得了明显的成效,但是仍有很大的进步空间,使其可以在复杂场景中均匀突出整个显著目标并且准确判断边界,同时有效抑制背景噪声。
2 模型设计
2.1 模型整体结构
为了一致高亮显著区域,同时抑制无关背景噪声,本文提出一种新的全局信息引导的多特征网络(GCMF-Net)用于显著物体检测,探索利用全局信息引导多层次特征提取方法及多尺度特征的检测和融合策略。
GCMF-Net的整体结构如图1所示,主要包含多尺度特征提升模块(MFEM)和全局信息引导模块(GCGM)。其中,全局信息引导模块GCGM由空洞空间卷积池化金字塔(ASPP)模块[30]和全局特征融合模块(GFFM)构成。本文使用基于VGG-16的全卷积网络结构作为主干网络模型,采用PFN结构,以由粗至细的方式更新显著性图。利用主干网络提取图像的多层次特征;利用MFEM模块提取不同层次的多尺度特征,并将这些特征进行融合;利用ASPP模块获取多尺度的全局语义特征;利用GFFM模块融合不同层次的多尺度特征与全局特征,从而准确捕获多层次多尺度的显著区域特征。
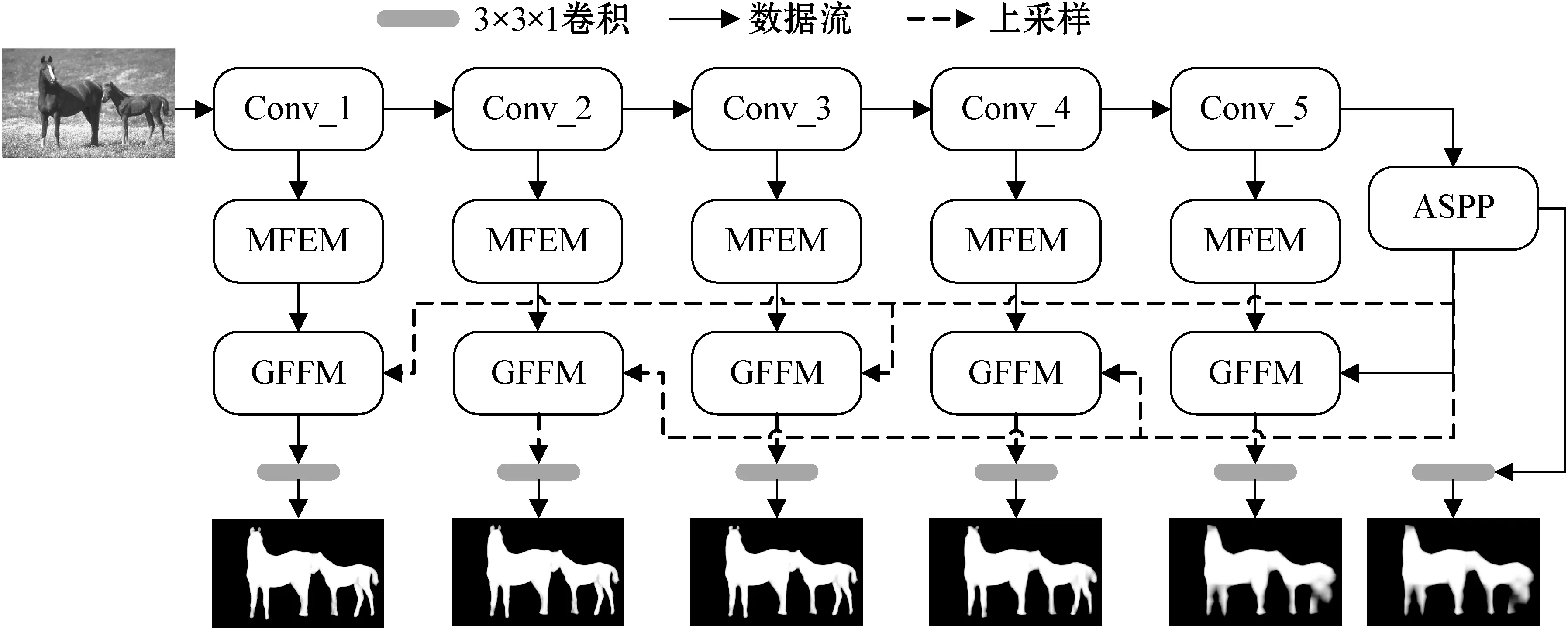
图1 GCMF-Net整体结构
2.2 主干网络
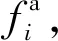
2.3 多尺度特征提升模块
由于主干网络的卷积层组采用固定大小的卷积核得到侧边输出特征,因此各侧边输出特征均对固定尺寸的显著物体具有较好的响应值。然而,自然场景中包含各种尺度的物体,多尺度特征检测和融合模块的研究可以提高模型处理多尺度目标的能力,从而提升整个网络的显著物体检测性能。
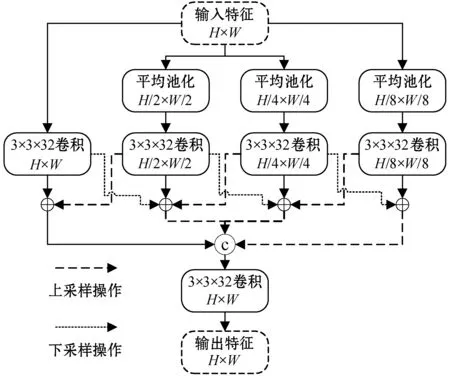
图2 MFEM结构
2.4 全局信息引导模块
本文利用空洞空间卷积池化金字塔ASPP模块捕获多尺度的全局语义信息,从而生成包含显著物体位置的全局特征。实验将ASPP的三个空洞卷积层膨胀分别率分别设置为4、6和8。
卷积神经网络产生的高层特征包含图像丰富的语义信息,而卷积神经网络低层侧边输出特征包含更多的颜色、纹理和形状等中低层图像特征,因此融合各个侧边输出的不同层次特征,能提高整个网络的特征表达和学习能力。
现有模型一般采用FPN结构,将高层语义特征逐渐与低层特征相融合,采用由粗到细的方式逐渐更新显著性图,提高检测质量。但是这种逐层更新的方式在一定程度上削弱了高层语义信息对低层特征提取和更新的引导作用。因此,本文提出将全局语义信息直接与各个侧边输出的多尺度融合特征相结合,利用高层语义信息直接引导侧边输出的中低层特征集中于有效目标区域的特征表征与学习。
在本文提出的全局特征融合模块中,将侧边输出、深层的显著特征图、ASPP模块生成的全局语义特征图进行维度方向的连接,再使用32维的3×3卷积核进行特征融合,可表示为:
(1)
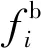
3 实 验
3.1 基准数据集
为评价算法性能,在四个公开的基准数据集上进行了一系列定性和定量评价实验。数据集包括ECSSD、DUT-OMRON、PASCAL-S和DUTS-TE,各数据集的图像数如表1所示。

表1 基准数据集信息
3.2 评价指标
本文采用常用的准确率-召回率(PR)曲线、F测度(Fβ)、平均F测度(avgFβ)、加权F测度(wFβ)和平均绝对误差(MAE)作为算法性能评价的量化指标。
根据从0到255的阈值,将显著图二值化,并与真值图进行比较来计算准确率和召回率。PR曲线显示了在某一数据集上不同阈值下的显著图的平均准确率和召回率。
Fβ用于综合考虑准确率和召回率:
(2)
式中:p和r分别代表准确率和召回率;β是衡量准确率和召回率的平衡参数,与文献[18]参数选取一致,本文实验将β2设为0.3。
wFβ使用加权准确率pw和加权召回率rw进行计算:
(3)
MAE用来评价显著图和真值图之间的平均像素误差:
(4)
式中:S表示最终显著图;G表示真值图;h和w分别表示图像的高度和宽度,i和j表示像素点的位置。
3.3 实施细节
所提模型的训练和测试是在具有Intel i7- 7700k CPU(4.2 GHz)、32 GB RAM和一块英伟达GTX TITAN GPU的台式计算机上,使用Python实现。
所提出的网络基于公开的Pytorch框架。本文模型使用DUTS-TR作为训练集。DUTS-TR包含10 553幅训练图像。为了提高模型的鲁棒性,本文通过随机水平翻转进行训练集增强。所有的训练图像的分辨率均320×320,每次只加载一个图像。学习率设置为5e- 5,使用Adam作为优化算子,权重衰减为5e- 4,一共训练25期。
为了进一步提高边缘像素的检测精度,使用CRF[29]对本文模型输出的预测结果进行显著图优化。
3.4 算法性能对比
将本文方法与8种近三年发表的具有代表性的方法进行了比较,包括PAGR[10]、RAS[17]、BDMP[20]、R3Net[28]、RADF[25]、ASNet[26]、RFCN[7]和AFNet[27]。为了比较的公平性,所有对比算法的显著图均使用作者提供的实现方法获取或作者公开的显著预测图。
3.4.1定量比较
本文提出的GCMF-Net模型与具有代表性的8种主流方法的PR曲线图如图3所示。由图3可知,GCMF-Net在ECSSD、DUTS-TE和DUT-OMRON这3个基准数据集上,较现有的代表性算法具有竞争力,只在PASCAL-S数据集上略逊于ASNet和AFNet。

(a) ECSSD数据集
此外,GCMF-Net模型与8种主流方法在四个公开基准数据集上就Fβ、avgFβ、wFβ和MAE指标进行了定量比较,结果如表2和表3所示,“/”表示原文作者没有提供该数据集上的显著性图。
由表2和表3可知:(1) GCMF-Net在PASCAL-S数据集上的avgFβ指标略逊于AFNet,而MAE指标位居第四;(2) GCMF-Net在ECSSD、DUT-OMRON和DUTS-TE数据上,均具有最佳表现。
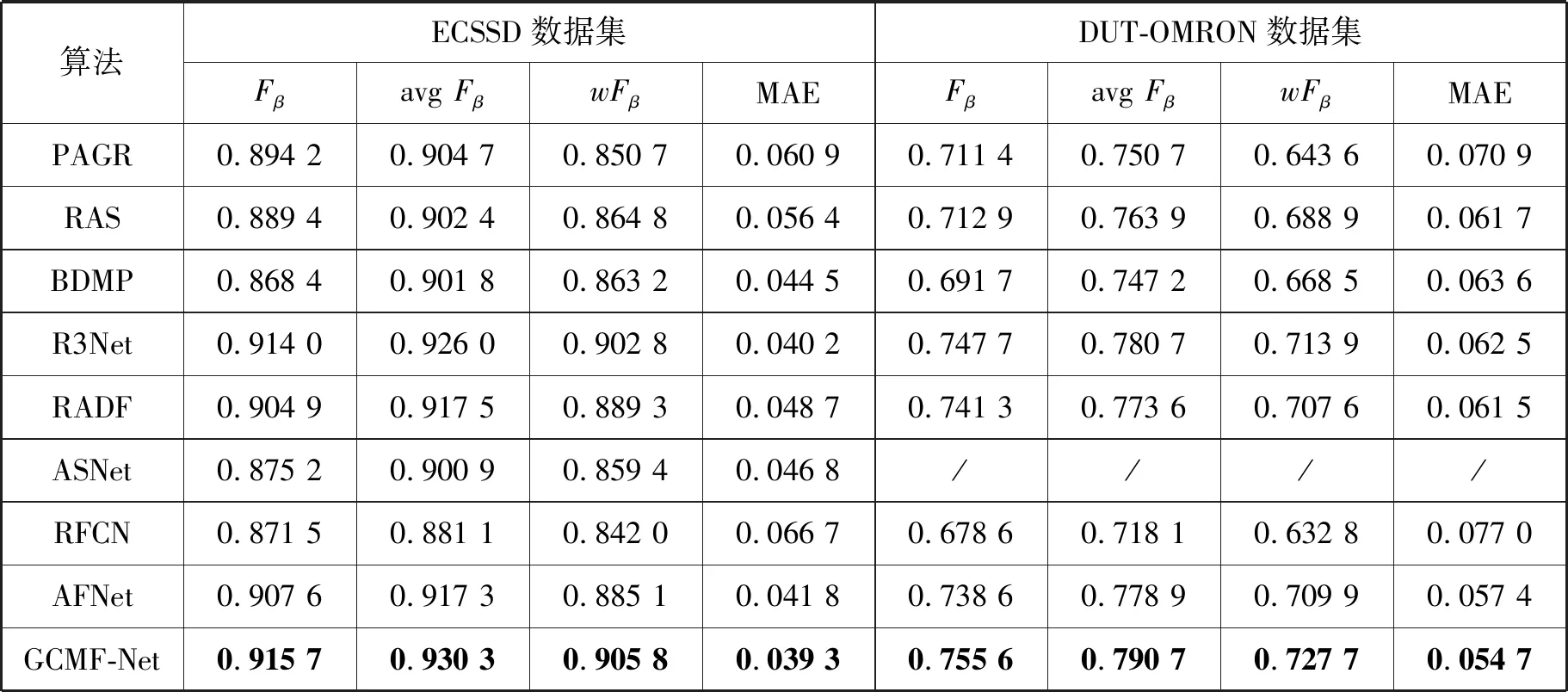
表2 不同方法在ECSSD和DUT-OMRON基准数据集上的性能比较
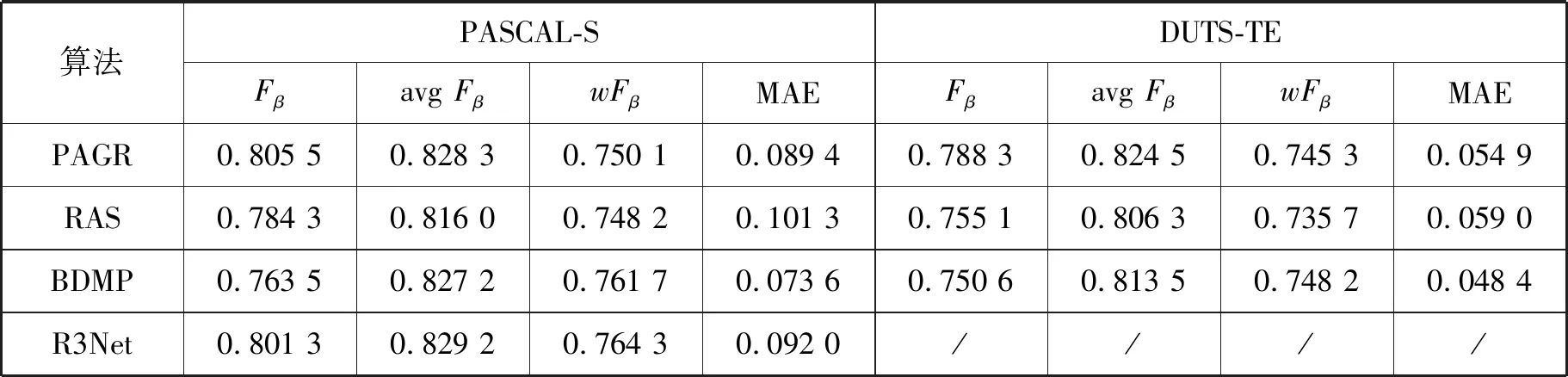
表3 不同方法在PASCAL-S和DUTS-TE基准数据集上的性能比较
综合本文方法在四个基准数据集上的PR曲线、Fβ、avgFβ、wFβ和MAE评价结果,GCMF-Net较近年的主流方法具有一定的优越性。
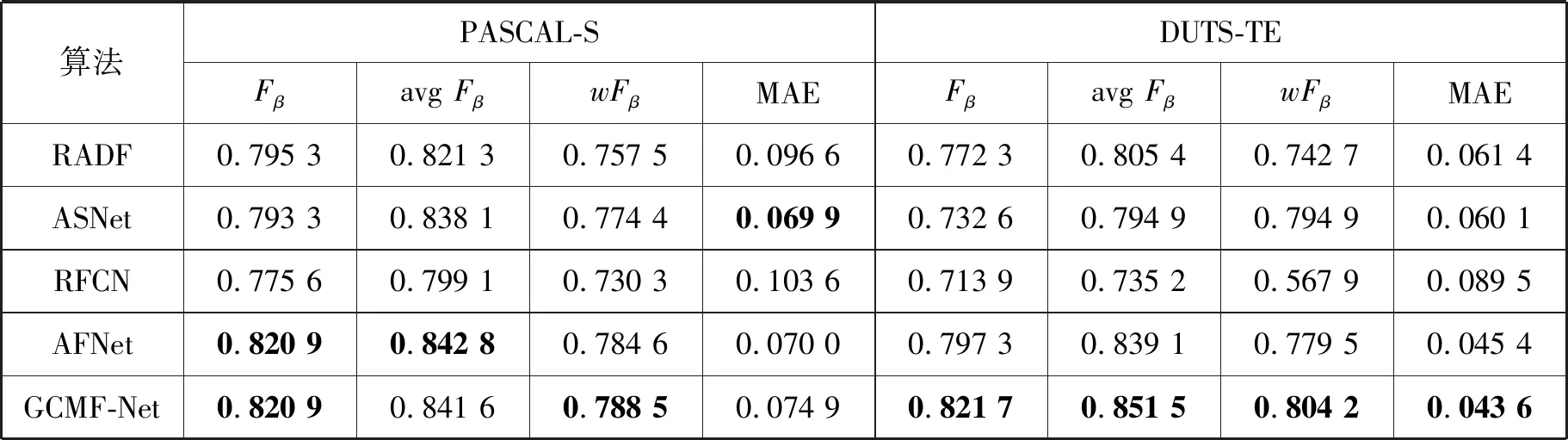
续表3
3.4.2定性比较
图4显示了GCMF-Net模型与不同算法在四个公开数据集上生成显著性图的视觉比较。由图4可知,本文提出的GCMF-Net方法在各种复杂场景(例如多目标、复杂背景、大目标、小目标、目标接触边界、复杂目标等)中表现良好,一致高亮了显著区域,并有效抑制了背景噪声。

(a) 输入 (b) 真值 (c) PAGR (d) RAS (e) BAMP (f) R3Net (g) RADF (h) ASNet (i) RFCN (j) AFNet (k) 本文图4 不同方法生成显著图的视觉比较
3.5 本文模型分析
3.5.1不同侧输出的预测结果分析
本文对GCMF-Net模型的各个侧边得到的显著性图,在ECSSD基准数据集上的进行检测性能比较,结果如表4所示。可以看出,最浅层的侧边得到的显著性图性能最佳,这表明了所提模型采用由粗至细的逐层更新策略是有效的。
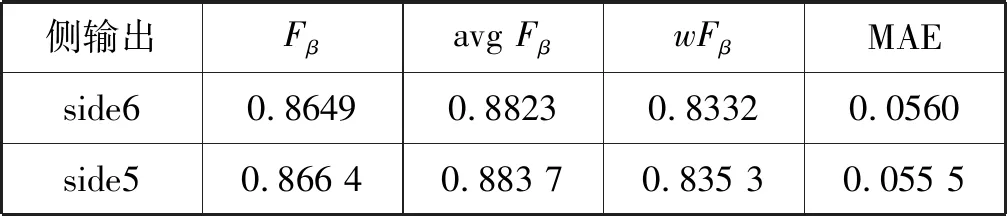
表4 不同侧输出的性能比较
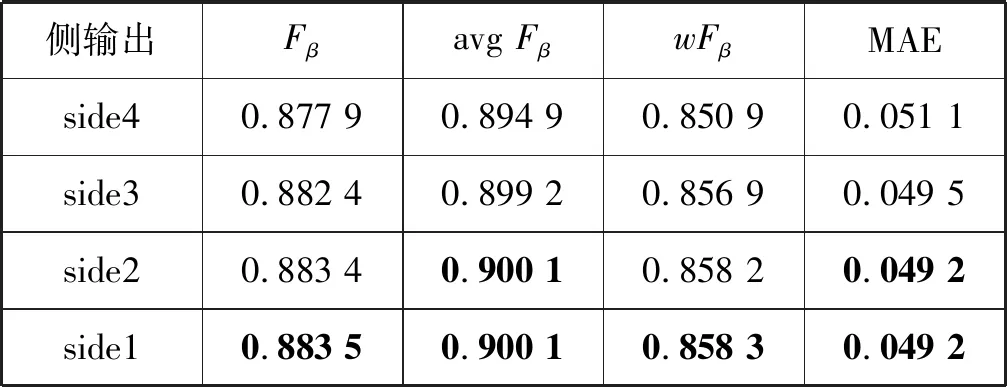
续表4
3.5.2不同模块性能分析
为了验证本文方法的可靠性和有效性,从本文模型中分别移除不同的模块和结构,并且测试这些新的网络模型在ECSSD和PASCAL-S数据集上的检测性能。
采用Fβ、avgFβ、wFβ和MAE对未采用CRF进行显著图优化的结果进行评价,如表5所示,本文方法中的各个模块能有效提高检测性能。其中:Ourswo_MFEM表示移除多尺度特征提取的特征优化模块,Ourswo_GCGM表示移除整个全局信息引导模块,Ourswo_GFFM表示保留全局信息引导模块中的全局特征提取部分,移除全局特征与其他侧输出的局部特征进行融合部分,Ourswo_ASPP表示移除全局信息引导模块中的全局特征提取部分。

表5 不同模块的性能比较
4 结 语
本文提出了一种利用多尺度和多层次特征进行显著性目标检测的方法。针对主干网络的每个侧输出进行多尺度特征的提取和融合;利用从最深层侧输出提取的全局语义特征引导侧输出的多尺度特征聚焦于主要区域的特征表达和学习;采用类似于FPN的网络结构,逐渐更新预测显著性图;采用深监督方式进行网络训练,从而得到预测显著性图。在测试阶段,为了进一步获得具有精确轮廓和均匀一致内部区域的显著物体检测结果,使用基于全连接的CRF进行显著性图更新。在四个公开的基准数据集上的实验结果表明,本文方法较8种近年发表的主流算法具有优越性。未来研究将考虑引入显著性物体的轮廓信息以获得更清晰的目标边界。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
金桥(2018年4期)2018-09-26 02:24:54
太空探索(2016年5期)2016-07-12 15:17:55
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
中国卫生(2014年5期)2014-11-10 02:11:26
时代英语·高三(2014年5期)2014-08-26 17:01:17
