
神经网络在解决某企业供应链牛鞭效应问题中的应用
2022-03-18 05:01杨光陈佳徐斌
计算机应用与软件 2022年3期
杨 光 陈 佳 徐 斌
(大连海事大学航运经济与管理学院 辽宁 大连 116026)
0 引 言
在供应链运营管理中,经常会出现需求信息从供应链末端传递到首端的过程中扭曲变异的现象,此种现象表现为需求波动的放大,称之为牛鞭效应。牛鞭效应的存在使得整个供应链效率降低、成本增加、效益下降,是供应链研究中的重点问题。Forrester[1]首先发现了牛鞭效应现象,并提出了解决牛鞭效应的办法就是要将供应链看作一个整体加以研究。Sterman[2]通过对“啤酒分销游戏”的验证,从理论上证明其确实存在,对牛鞭效应进行了量化的分析。在此基础上,Lee等[3]从供应链运行的角度出发,归纳总结出了引发牛鞭效应的四个主要原因:(1) 在供应链上的每个企业都对需求信息进行了加工处理;(2) 供货短缺;(3) 零售商分批订货方式;(4) 生产商品的价格波动[3]。2000年,Frank等学者在Lee的研究上,构建了一个只含有一个供应商和一个零售商的二级供应链模型,将牛鞭效应的量化公式定义为供应商与零售商之间的需求波动比,以此为衡量牛鞭效应程度的依据,此公式较为科学地体现了需求的不确定性[4]。经过海内外学者的多年探讨,已经有很多有关牛鞭效应的研究理论出现,同时,也对牛鞭效应的测量过程和方法进行了不同程度的研究,比如如何减少需求波动和选取合适的工具模型降低预测偏差。近年来,随着制造业整体发展,这一课题成为了供应链牛鞭效应问题研究的重点。
在企业的采购预测中,最常见的方法为移动平均法,这种预测方法既粗糙又风险大。近几年在预测中自回归模型(AR)、移动平均模型(MA)等时间序列模型也被广泛应用,通过控制模型中的参数来减少预测的差值以提高预测精度。但是在实际供应链运行中,情况往往更加复杂,单纯的线性预测难以适应多变的环境,这时出现神经网络、支持向量机、贝叶斯网络这些非线性预测模型,使得预测效果更加准确[5]。
尽管有多种模型可用于预测,但这些模型往往被单独使用,虽然各有优势,但是很难有效地捕捉到样本数据的所有复合特征,所以组合预测应运而生,将某几种单一预测以不同的方式组合使用,使得模型之间进行优势互补得到更好的预测效果。本文构建ARIMA-BP组合预测法,ARIMA是时序分析中常用的模型,在线性部分的预测结果良好,但是对于非线性部分的处理上有一定的不足。而神经网络作为自学习方法,对处理非线性数据有很强的能力。ARIMA-BP组合预测方式很好地结合了两种预测模型的优点,选取该模型能够提高需求预测的精准度,对抑制牛鞭效应有更好的效果。
1 牛鞭效应
1.1 供应链特点
牛鞭效应是客观存在的,是必要的。在实际生产环境下,制造商每月需求数据由物料计划部门的相关人员定制,需求预测的方法通常为在去年同期实际数据的基础上增加一定的百分比,具体数值由物料计划人员根据自己对生产的熟悉程度及相关经验来制定。 实际需求比预测数量高时,存在着缺货的风险,影响客户满意度;实际需求比预测数量低时,企业很容易出现大量库存积压,库存成本出现不必要的浪费,造成资金损失。比较两种情况,企业更担心缺货的风险,一旦发生缺货,会对流水线的正常生产以及客户订单的准时完成造成严重负面影响。所以为了减少缺货的风险,企业通常会对物料设置安全库存,尤其对于需求不确定性高风险性极大的物料,会设置更高的安全库存。当供应链上每一级节点企业的物料计划人员设置安全库存时,牛鞭效应由此产生。牛鞭效应是企业为了降低缺货风险的主动选择,不能完全地消除,增加了库存风险,导致供应链整体效率低下和资金浪费。针对这个问题,本文通过提高预测的准确度来降低安全库存数值,使缺货和滞货的风险能够相对平衡,达到缓解牛鞭效应的目的。
根据实际调研,企业通常按照定期订货模型来制定生产计划。定期订货模型是企业生产中常见的订货模型,节点企业在每个固定时间周期对库存物料的储备量进行盘点,将盘点结果与目标库存水平比较,按照差额批量订购。由于需求是随机变动的,每周期盘点的库存量是不同的,为达到目标库存水平而需要补充的数量也是不同的[6-7]。
1.2 问题描述
本文首先基于实际生产环境搭建供应链模型,模型简化后如图1所示(其中P表示产品),需求信息从下游批发商向上传递直到供应商部分,在此过程中需求变异放大。一般来说,批发商按照自己对市场需求的评估向制造商订货,制造商收到下游订单后再转换为主生产计划向供应商订货。由于订货提前期的存在,每一级节点企业在考虑到平均需求的基础上,都会增加安全库存,这样使得每一层的需求变动性都要比上一级更大。所以,尽管最后产品的客户需求较为稳定,但是批发商、制造商、供应商这些中上游企业的订购量波动却越来越大如图2所示。

图1 简化后的供应链模型

图2 牛鞭效应效果图
基于以上描述,假设搭建的供应链模型由一个批发商、一个制造商、一个供应商组成,在此模式下,供应链上的节点企业遵循以下规则:
每隔固定周期t,批发商对客户需求做出估计,即实际市场需求Dt,然后进行库存盘点,向制造商发出订单Oret。
供应链之间不存在订单延迟,制造商在t时刻得到批发商订单Oret后配送产品至批发商,进行库存盘点后向批发商发出订单Odis。
批发商和制造商遵循同样的订货顺序,通过固定间隔进行补货。
批发商根据自己的库存策略向制造商进行订购,理论上该企业的订货量为:
(1)
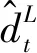
同样,制造商向供应商发起的订单量为:
(2)
(3)
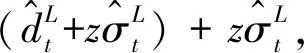

2 核心算法
2.1 ARIMA(p,d,q)模型
ARIMA(p,d,q)模型,即自回归求和滑动平均模型是非平稳的时间序列模型,为使它平稳后便于计算需要进行d阶差分,所得结果就是ARMA模型。
(1) ARMA(p,q)模型,即自回归移动平均模型,是AR(p)模型(p阶自回归模型)与MA(q)模型(q阶滑动平均模型)的结合,其中,AR(p)表示时间序列{Xt}本身某一时刻与前p个时刻互相之间依存的线性关系;MA(q)表示每个时间序列都是过去q个周期随机扰动项的加权平均。表达式分别如下:
AR(p):Xt=φ0+φ1Xt-1+φ2Xt-2+…+φpXp-1+εt
MA(q):Xt=εt-θ1εt-1-θ2εt-2-…-θqεt-q+μ
ARMA(p,q):Xt=(φ0+φ1Xt-1+φ2Xt-2+…+
φpXt-p)+εt-θ1εt-1-θ2εt-2-…-θqεt-q
式中:φ1,φ2,…,φp是自回归模型参数;θ1,θ2,…,θq是滑动平均模型的参数;εt为白噪声序列,反映了所有其他随机因素对序列的干扰。满足白噪声序列的条件为:如果ε0,ε1,…,εt是一系列独立随机变量,并且其期望、方差、协方差满足E(εt)=0、Var(et)=σ2、Cov(et,et+k)=0,k≠0。
(2) ARIMA(p,d,q)模型。上述三种模型都是针对平稳时间序列,在实际生产中并不常见,更多的是非平稳的序列。对于非平稳时间序列,常用的模型为自回归求和滑动平均模型,简称ARIMA(p,d,q)模型。序列在时刻t的值Xt与它之前时刻的响应值和t时的干扰有关;而与前期的干扰无关,所以有一般形式如下:
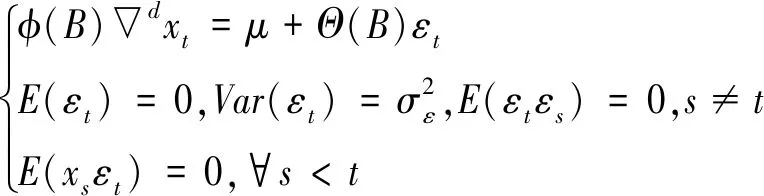
(4)
式中:B表示延迟算子(滞后算子),当前序列乘以一个延迟算子,相当于向回拨p时刻,Xt-p=BpXt;▽d=(1-B)d,为高阶差分;φ(B)=1-φ1B-φ2B2…-φpBp,为ARMA(p,q)模型的自回归系数多项式;Θ(B)=1-θ1B-θ2B2-…-θqBq,为ARMA(p,q)模型的移动平滑系数多项式。可简记为:
(5)
式中:εt是白噪声序列;μ是时间序列xt的均值。
2.2 神经网络模型
BP神经网络是一种常见的无反馈前向网络,由输入层、隐含层和输出层构成,其特征为信号前向传递,误差反向传递,其中:输入层和输出层各占一层;而隐藏层可以为多层[8]。BP模型的结构简单、原理清晰,在实际的生产计划中易于理解和使用。基本步骤为:在输入层设定R个神经元,将获取的输入样本数据x=(x1,x2,…,xn),通过传递函数传到隐含层,神经元的连接权值为wi(i=1,2,…,n),再以同样的方式进入输出层,得到向量y=(y1,y2,…,yn)。将结果值与期望值进行比较,如果误差过高则转向反向传播,沿原路调整模型中的权值和阈值,直到误差达到期望范围,使得预测输出不断地接近期望值[9]。x和y的计算如式(6)所示。
(6)
2.3 模型搭建流程
在实际应用中,该制造商产品需求既包含了线性特征,又包含非线性特征,对于线性部分可以用时间序列模型ARIMA很好地捕获其特征,而对于非线性部分,神经网络表现良好。所以本文首先利用ARIMA模型预测需求量,得到数据的线性趋势后,将自回归的阶数作为神经网络输入节点的参考,再提取序列的非线性特征,通过灰色关联度分析这些因素对于预测值的影响,同样作为BP神经网络模型的的输入神经元,得到更加准确的生产需求预测结果,搭建流程如图3所示。

图3 组合模型搭建流程
3 实验仿真与结果分析
3.1 ARIMA模型预测
(1) 观察节点企业的历史订单量的变化趋势,做出时序图,经过ADF单位根检验其平稳性,如果不平稳则对数据进行差分平稳化处理。
(2) 经过差分计算得到,当d=1时序列平稳。
(3) 对模型进行识别和定阶,即确定p和q的值。p由样本的自相关图决定,q由偏自相关图决定。根据图4判断,自相关图为2阶截尾,偏自相关呈1阶截尾,可以初步设定p=2或者p=3,q=1或者q=1。

图4 AC图和PAC图
图4中,AC表示自相关系数;PAC表示偏自相关系数;Q-Stat为Q统计量,Prob为Q统计量的P值。
根据AIC、SC定则准确定阶,在所有通过检验的模型中使得AIC、SC函数达到最小的模型为相对最优模型,其中模型的AIC、SC的信息验证值如表1所示,通过对比,选取ARIMA(2,1,2)模型。
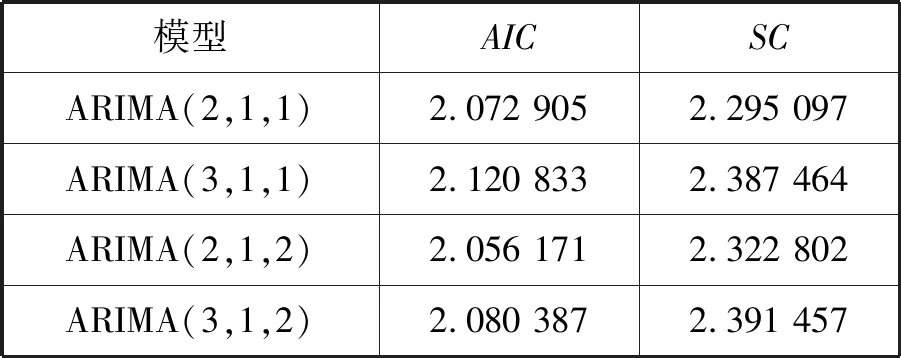
表1 各模型的AIC SC
模型的检验。通过Prob值判断残差的相关性,大于0.05代表不存在自相关性。ARIMA(2,1,2)的Prob的值为0.787,即残差为白噪声,满足模型要求。
3.2 神经网络预测
3.2.1影响因素的选取
在制造商企业中,外部有市场因素的影响,需求变化快,然而内部的产能稳定,导致企业在决策时对于各产品制定的生产计划不同,所以各产品种类在整个产品系列中比例关系并不是一成不变的。本文基于对历史数据的分析和对企业的调研,总结出以下三种较为重要的影响因素:
(1) 价格因素。价格的区间决定产品的定位,价格起伏会影响客户的购买行为和趋势,导致产品需求变化。
(2) 季节性因素。以月份划分,从产品的历史数据中可以看到每年的下半年需求量相比于上半年要偏高。
(3) 同系列产品中存在竞争。当企业大力促销某系列中的一种产品时,其他种类产品的需求数量就会相反地变动。
对以上选取的因素进行灰色关联度分析,判断是否可用。灰色关联度分析是一种多因素统计分析的方法,即在一个灰色系统中,某一个指标可能与其他哪几个因素相对来说更有关系,与哪些因素相对关系弱一点,通过计算得到一个分析结果用于统计。将以上影响因素经过归一化处理,减少因素之间的量级差别,再计算灰色关联度系数,计算公式为:

(7)
式中:xi(k)表示第i个因素的第k个数值;ρ作为控制关联系数区分度的可调节参数,取值范围为(0,1),ρ越小时,区分度越大,通常情况下取ρ=0.5较为合适。经过MATLAB代码实现,各影响因素的关联度数值如下,影响程度上促销力度>价格>季节因素。
ζ价格=0.727 2ζ季节性=0.569 4ζ促销力度=0.880 3
3.2.2组合预测结果
理论证明,任意从输入到输出的非线性映射都可以由一个具有无限隐层节点的三层BP网络实现[10]。参考文献中的研究经验,可以按照以下公式对隐含层节点数进行设计:
(8)
式中:n、ni、n0分别为隐含层节点数、输入节点数、输出节点数;a为1到10之间的常数。因此,在本文中,隐含层节点数取9。
所以,本文构建的预测模型共3层,输入层为4个神经元,分别为前p个月的需求dt-p,dt-(p-1),…,dt-1(t为当前月份,d为实际需求量),季度因素,价格定位区间,产品促销力度。通过对数据的归一化处理,使数据序列转化为[0,1]之间的数,取消各维度数据间量级差异,减少系统误差。
BP神经网络模型的搭建分为两个部分,首先需要获取需要输入的样本数据值,通过预先构建好的网络模型计算输出,再与实际输出相比较得到误差变化值,判断误差是否达到期望值。如果没有达到,需要进行反向传播,通过网络将误差信息沿之前的连接通路返回,同时对各层神经元的权值及阈值进行修改,依照误差最小的原则进行修正。这两个阶段反复交替进行,直到误差达到期望值。具体步骤如下。
设置网络训练参数,选取4个输入神经元,选取线性传递函数purelin作为传递函数;设1层隐含层,节点数为9,传递函数为S型函数logsig;输出层有1个神经元对应实际订购量,传递函数同样为purelin。对神经网络的参数进行设置,学习速率设置为0.001,网络迭代次数为1 000,误差控制在10-3。图5为神经网络模型的结构。

图5 网络结构
图6中,Output是经网络预测后得出的值;Target是训练的目标值;Fit实线为实际网络输出值;虚线为目标值;R为回归值,用来测量输出和目标之间的相关性。可以看出,整体回归效果达到99.061%,拟合程度较高。证明了该网络模型训练效果良好,精准度高,可以实现生产管理中对产品需求较为精准的预测。除去个别样本的影响,该模型可以解释99%左右的数据样本,整体效果在期望达到的范围内。

图6 模型拟合
通过表2的预测结果对比可知,平均绝对误差项中,ARIMA(2,1,2)对应值为60.5,ARIMA-BP组合模型对应值为35;平均误差绝对率项中,ARIMA(2,1,2)的平均误差百分比为19.16%,ARIMA-BP组合模型为10.02%;两个观测值对比发现,组合模型对应值都远低于ARIMA(2,1,2)模型。由此可见,ARIMA-BP组合模型对原始数据的预测效果确实优于ARIMA模型。

表2 预测模型对比
3.3 结果讨论
为了对比牛鞭效应的强弱,本节根据前文提出的牛鞭效应量化公式得出不同模型下的具体数值如表3所示,企业采取传统的移动平均预测下的牛鞭效应值远大于组合预测模型下的牛鞭效应值。可以得出结论,当需求误差越小时,需求信息的波动越小,供应链牛鞭效应作用越弱。因此,提高需求预测的精度对牛鞭效应的缓解有重要意义。
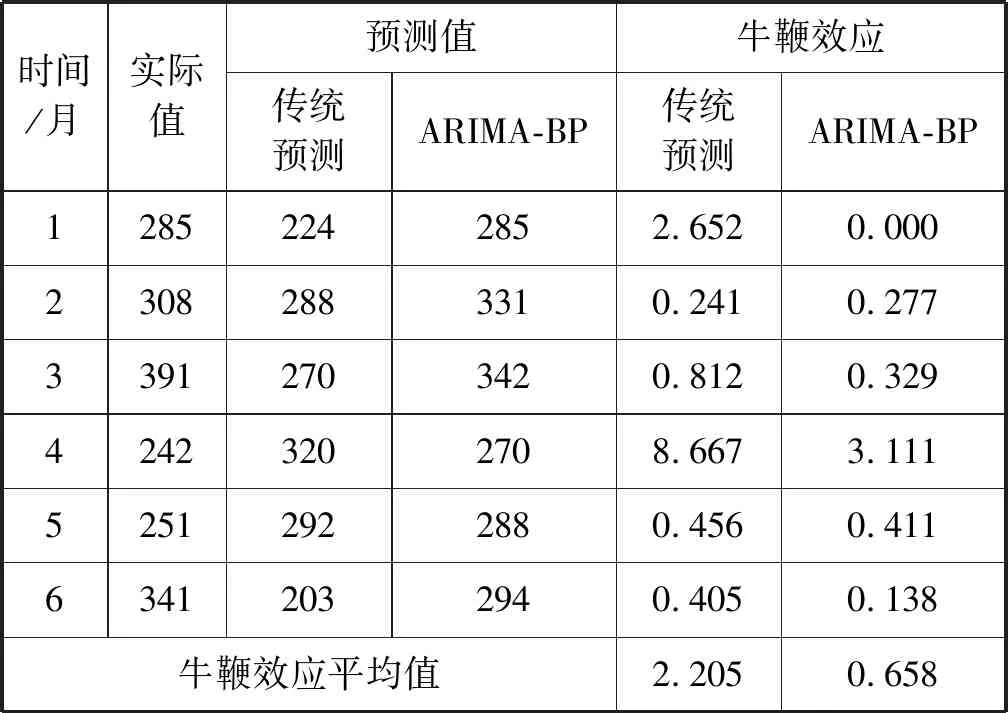
表3 牛鞭效应对比
4 结 语
时序模型预测是实际生产中常用的预测方法,它基于数理统计和微积分等数学概念,结构简单,在线性预测中有良好的拟合效果,但是面对复杂的供应链环境有一定的局限性。而BP神经网络作为一种典型的黑箱工具,具有自学习、自组织等特点,利用网络拓扑结构来处理不确定的系统,进而充分模拟非线性管理环境,更符合实际生产环境。所以本文建立ARIMA-BP模型。通过仿真分析发现,在模型的输入样本结构中,每一周期的需求量都会受到之前周期的总需求量影响,但主要受到哪段时期的影响需要具体讨论,一般来说,距离本周期越近的数据越有参考价值。同时要考虑某些产品的明显季节性波动趋势。而商品的促销力度和价格定位很大程度上都取决于企业当月的决策,非线性特征明显,神经网络的作用更大。ARIMA-BP模型综合了时序分析和神经网络各自的优点,经过比较,组合模型在预测方面相比于单一模型更好。
本文通过数据证明了在二级供应链模型中,利用ARIMA-BP模型能够提高精准度从而降低安全库存、减少库存成本,以此类推到多级供应链模型的短期预测中,减少由牛鞭效应带来的负面影响。此研究结果可用于制造业中短期内对需求量的把握。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
现代电子技术(2022年4期)2022-02-21
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
意林·全彩Color(2018年9期)2018-11-13
软件(2017年6期)2017-09-23
中学物理·高中(2016年12期)2017-04-22
小樱桃·童年阅读(2014年11期)2014-12-01
职业·下旬(2009年7期)2009-01-20
