
基于ADCP-TOP 的微表情识别方法*
2022-03-17 10:17唐家明宛艳萍谷佳真
计算机与数字工程 2022年2期
唐家明 宛艳萍 孟 竹 张 芳 谷佳真
(河北工业大学人工智能与数据科学学院 天津 300401)
1 引言
微表情是人在试图压抑自己情绪时,面部肌肉在不受控制情况下产生轻微幅度变化而流露出的表情[1],其更能揭示一个人的真实感情[2],因此在刑侦测谎、心理治疗、国家安防等领域有着广泛应用[3~8]。
随着微表情识别受到更多研究者的关注,近年出现了许多自动微表情识别方法。Pfister 等提出LBP-TOP(Local Binary Pattern from Three Orthogonal Planes)算法[9],是最早对自动微表情识别做出贡献的工作之一。LBP-TOP 计算简单,但存在对噪声敏感,有效信息不足的问题。Guo 等提出CBP-TOP(Centralized Binary Pattern from Three Orthogonal Planes)特征提取方法[10],通过对差值设置阈值增强编码抗噪性能以改善对噪声的敏感。Ben等提出HWP-TOP(Hot Wheel Patterns from Three Orthogonal Planes)识别方法[11],通过增加采样点并分内外两圆进行顺序编码来增加特征信息量。Li等为探究空域特征和时域特征对微表情的影响,将HOG(Histogram of Oriented Gradients)特征描述子[12]拓展到三维正交平面提取特征,指出时域特征对识别起主要作用。除基于编码方式的识别外,基于光流法的识别也是微表情研究方向之一。Liu等提出MDMO(Main Directional Mean Optical-flow)特征描述子[13]。将面部划分为36 块感兴趣区域(Regions of Interest,ROI),计算每个ROI中主要方向上的平均光流作为识别特征。Xu 等提出FDM(Facial Dynamics Map)特征描述子[14],通过稠密光流场迭代地求出每个图像分块光流的主方向进行识别。Liong 等提出Bi-WOOF(Bi-Weighted Oriented Optical Flow)特征描述子[15],将光学应变作为每个分块的权值从而获得加权光流主方向特征,并只使用起始帧,峰值帧,结束帧,三帧作为数据输入以减少噪声的影响。
由于微表情数据库样本数量限制,目前基于深度学习方法的微表情识别率不高[16]。本文针对传统编码方法存在有效信息不足、噪声敏感的问题,提出基于相邻双交叉二值模式(Adjacent Double Crossover Local Binary Pattern from Three Orthogonal Planes,ADCP-TOP)的微表情识别算法。传统LBP-TOP 算法只考虑周围像素与中心像素关系而忽略了周围像素之间的联系,ADCP-TOP将采样点邻域之间顺序编码以增加更多信息量,并对奇偶采样点分开编码,在增强鲁棒性的同时融入方向信息。进一步通过获取细粒度感兴趣区域(FROI)从而提取更精细的ADCP-TOP特征,最后将特征送入SVM分类器进行分类。
2 相邻双交叉局部二值模式
基于ADCP-TOP 微表情识别的系统框图如图1 所示。首先利用Dlib 人脸检测工具[17]提取人脸关键点,然后以关键点为坐标,根据面部动作单元AUs[18]划分人脸粗粒度感兴趣区域(CROI),并通过再次划分CROI 取细粒度感兴趣区域(FROI)。随后在FROI内利用ADCP-TOP提取特征获得特征直方图,最后使用SVM分类器进行微表情识别。
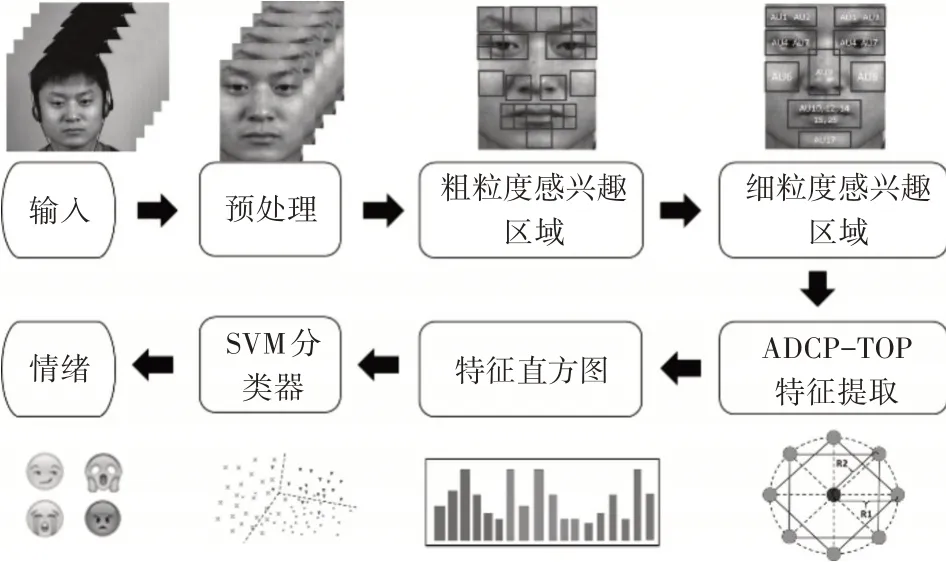
图1 ADCP-TOP微表情识别方法系统框图
2.1 特征提取
本文对传统LBP-TOP 算法改进,针对LBPTOP 算法提取有效信息不足,对噪声敏感的问题,提出ADCP-TOP时空特征描述子。
LBP-TOP 主要提取图像的局部信息,首先在XY 面中计算LBP 编码,再以相同的编码方式拓展到XT 面和YT 面。以XY 面为例,如图2 所示,在一个3×3 的像素块中,将中心像素值与其邻域像素值作差,差值大于0 则编码为1,否则编码为0。计算得到一组八位二进制编码,将其转换为十进制后替换中心像素值,并通过统计得到XY 面的特征直方图。接着,以相同的计算方式拓展到XT 面、YT面。最后通过级联三个面的特征直方图得到LBP-TOP 特征。此外,不限于八邻域,LBP-TOP 算子可以设置R 为半径,P 为采样点个数,计算每个采样点与中心像素关系后,得到p位二进制编码。
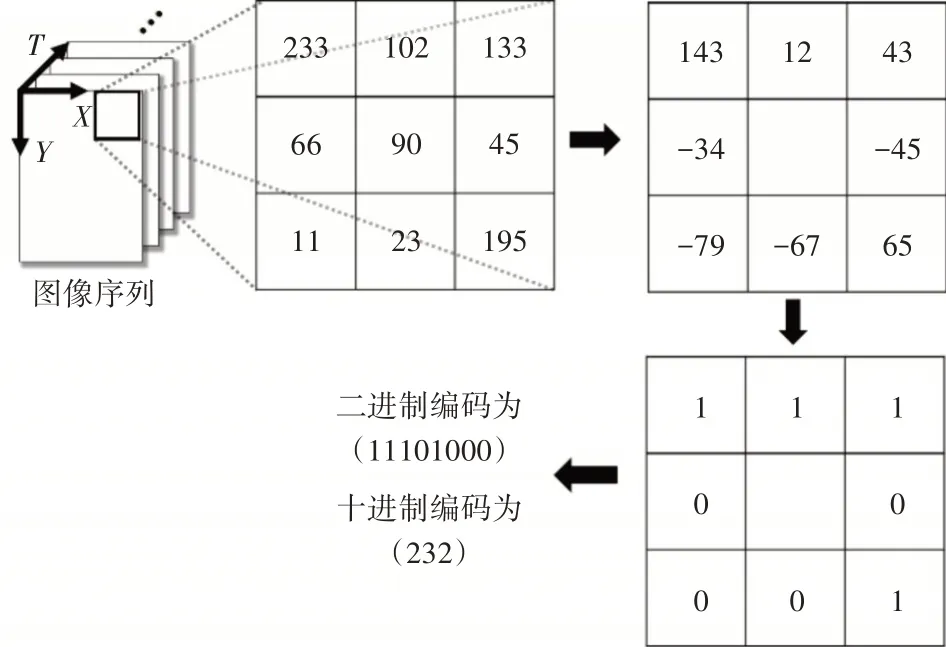
图2 LBP-TOP在八邻域中的二进制编码
LBP-TOP 只考虑到周围像素与中心像点像素的关系,而忽略了相邻像素点之间的关系;同时也将水平竖直方向和对角线方向同等对待,缺少了方向上的信息。
针对以上问题,本文提出ADCP-TOP时空特征描述符。以某一像素作为圆心,以R 为半径,在圆周的水平方向、垂直方向、对角线方向上取p 个采样点,以p=8 为例,得到A0-A7八个采样点,如图3(a)所示。为将结构信息量化,每个方向上的采样点设定唯一编码,定义如公式(1)所示。

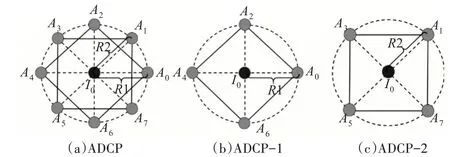
图3 ADCP-TOP时空特征描述符
最终,ADCP 编码特征直方图由两个交叉编码ADCP-1 和ADCP-2 串联得到。ADCP 可以描述二维图像中每个像素邻域之间的信息,但是对于图像序列或是视频序列,单一的ADCP 描述符会忽略时序信息。为表示相邻帧之间的信息,将ADCP 编码拓展到三维正交平面XY、XT、YT 面中,最终获得ADCP-TOP时空特征描述符。
ADCP-TOP 时空特征描述符将邻域像素点之间的关系考虑进来,使得能够更加准确提取图像的深层信息,与LBP-TOP 相比,该方法提取的特征会包含更多结构信息,提升了特征判别度。其次,ADCP-TOP 将水平竖直方向与对角线方向分成两个编码,融入方向信息,并将结构信息更细化区分,增强鲁棒性的同时降低了维度。
2.2 获取细粒度感兴趣区域(FROI)
ADCP-TOP特征属于统计特征,需要对图像分块以区分不同位置表达的信息。本文依据面部编码系统(Facial Action Coding System,FACS)[18],划分感兴趣区域(ROI)。
FACS 的基础是动作单元(Action Units,AUs),微表情是由多个特定AUS 共同作用而形成。每个AU有自己的发生区域。图4(a)总结了参与微表情运动的AUs,并以人脸关键点为坐标,划分9个AUS主要作用的区域,即粗粒度感兴趣区域(CROI)。ROI的大小会影响提取信息的细节程度,因此继续对CROI 进一步划分,获取细粒度感兴趣区域(FROI)。FROI的划分原则是不能过于稠密也不能过于稀疏,过于稠密会使得信息冗余,而过于稀疏则会造成信息提取遗漏。鉴于微表情发生时牵扯到的唇部区域主要集中在嘴角,眼部区域主要发生在眼角,所以对嘴角和眼角两处进行更细致的划分,划分结果图4(b)所示。其中大块尺寸为50×50,小块尺寸为25×25,图像分辨率大小240×280。
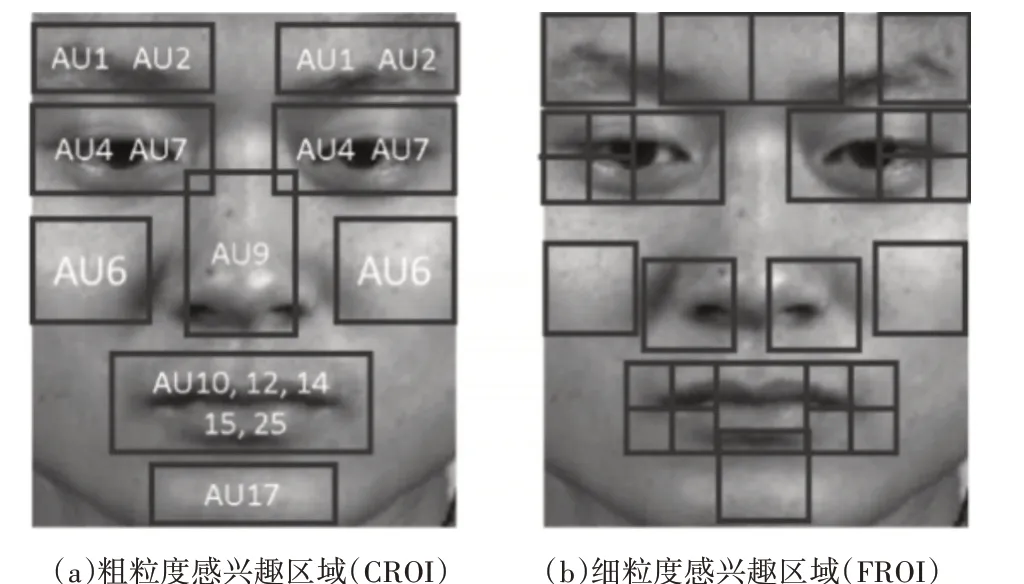
图4 根据面部动作单元划分的ROI示意图
3 实验验证与结果分析
3.1 微表情数据库
1)SMIC数据库
SMIC[19]是第一个公开的自发微表情数据库,SMIC 具有三个子集,其中SMIC-HS 子集样本最多,因此采用该子集作为实验样本。 SMIC-HS 包含16 个受试者的164 个自发的微表情样本,帧率为100 fps,分为三个类别:积极(51 个样本),消极(70个样本)和惊奇(43个样本)。
2)CASME2 数据库
CASME2[20]由中科院傅小兰团队发布,帧率达到200fps,数据库包含来自26 个受试者的247 个样本。实验中将其分为5类,高兴(32个样本)、惊讶(25个样本)、厌恶(64个样本)、压抑(27个样本)其他(99个样本)。
3.2 实验结果与实验细节
为验证提出的ADCP-TOP方法的有效性,在两个数据库SMIC 和CASME 中,进行了十倍交叉验证和LOSO交叉验证(Leave-One-Subject-Out)[21]。。
表1 出示了ADCP-TOP 方法在SMIC 数据库与CAME2 数据库中的十倍交叉实验的实验结果,并复现LBP-TOP 方法作为实验对比的基准。在SMIC数据库下,ADCP-TOP的识别率为67.09%,对比LBP-TOP 识别率提升27.92%。在CAME2 数据库下,ADCP-TOP 的识别率为70.47% ,对比LBP-TOP 识别率提升27.57%。SMIC 数据库只分三类情绪,而CASME2 数据库分五类情绪,但在CASME2 数据库下的识别率比在SMIC 数据库下的识别率高,原因是因为CASME2数据库的空间分辨率和时间分辨率都比SMIC 数据库的质量高,说明时域信息和空域的细节信息是影响微表情识别率的关键,对比LBP-TOP,ADCP-TOP 捕获细节信息的能力更强,因此实验结果有较大的提升。
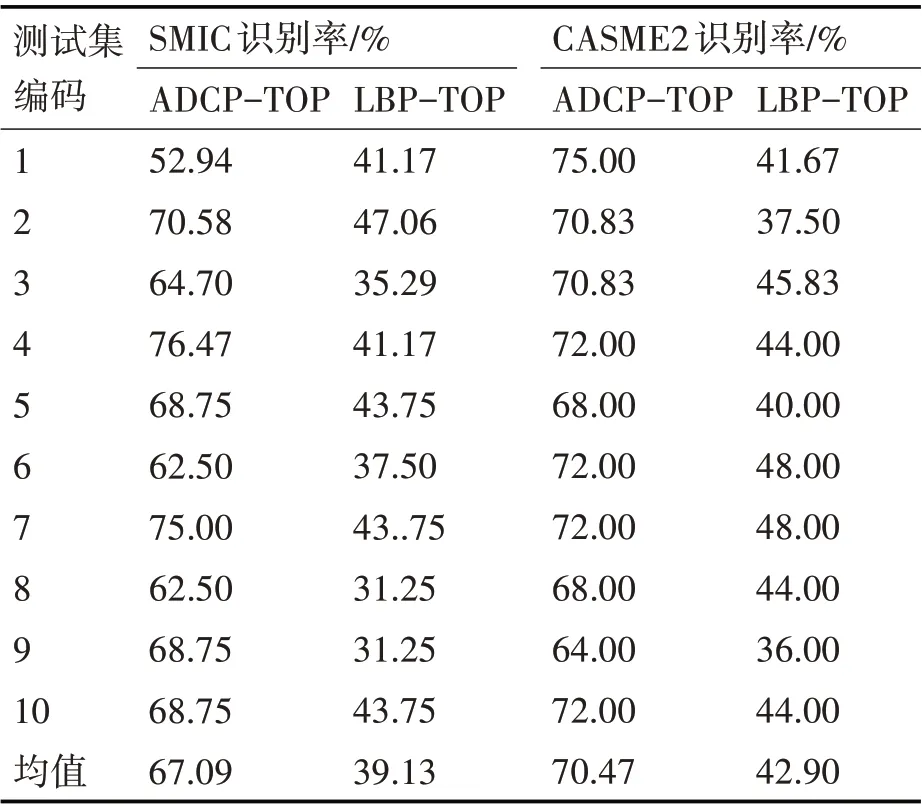
表1 ADCP-TOP在SMIC与CASME2数据库下十倍交叉验证的识别率
进一步计算混淆矩阵以分析系统的稳定性,如图5 所示。SMIC 数据库下,积极的分类表现并不是很好,消极和惊奇的分类效果较好,原因是二者的变化幅度相对更大,变化信息更容易被捕捉。CASME2 数据库下,随着样本的质量和数量提升后,对积极的分类效果有显著提高。分五类情绪下,生气、抑制、其他,这三类情绪不容易被区分开,因为这三类情绪的AUs存在共同之处,所以较难判断。尽管如此,ADCP-TOP还是具有较强的判别能力。
为验证FROI有效性,进行分块方式对比试验,如表2 所示。SMIC 数据库下,6×6 的分块方式识别效果最好,识别率为65.14%,CASME2数据库下,8×8 的分块效果最好,识别率为67.31%。两个数据库的最好分块方式并不相同,主要由图像的质量不同所导致。CROI没有比最佳的等分方式识别率高,原因为虽然去掉了面部轮廓等区域的噪声,但CROI 的单独ROI 的区域较大。ADCP-TOP 提取的特征属于统计特征,需要通过分块以提供位置信息,ROI 分割的越细,特征包含的位置信息和细节信息越精确,但噪声的影响也会增大。通过对CROI 进一步的划分得到的FROI,在SMIC h 和CASME2数据库下识别率分别为67.09%和70.47%。

表2 ADCP-TOP在SMIC与CASME2数据库下不同分块方式的识别率对比
为验证对采样点按奇偶位置分开编码的有效性,以LBP-TOP 为例进行实验,如表3 所示,其中LBP-TOP 半径为1,采样点个数为8。OLBP-TOP为按奇数位置编码方式,ELBP-TOP 为按偶数位置编码方式,两种编码方式在CASNE2 的识别率分别为33.59%和33.43%。识别率没有传统LBP-TOP高,原因是采样点个数减少为原来的一半,包含信息量减少。OELBP-TOP 是将OLBP-TOP 和ELBPTOP 的特征直方图级联,对比LBP-TOP 在CASM2上的识别率提升7.2%,实验证明奇偶位置分开编码的方式可以提升特征的辨识性,偶数编码位蕴藏着中心像素与周围像素垂直和水平的运动关系,奇数编码位蕴藏着中心像素与周围像素斜角的运动关系,分开编码可以增强这种潜在方向信息和特征的鲁棒性。此外,ADCP-TOP加入了邻域像素之间的编码,如若不分奇偶方式编码,维度为216,导致维度爆炸。奇偶位分开编码使得ADCP-TOP 在融入更多信息时维度下降,同时也具备奇偶编码的自身优势。
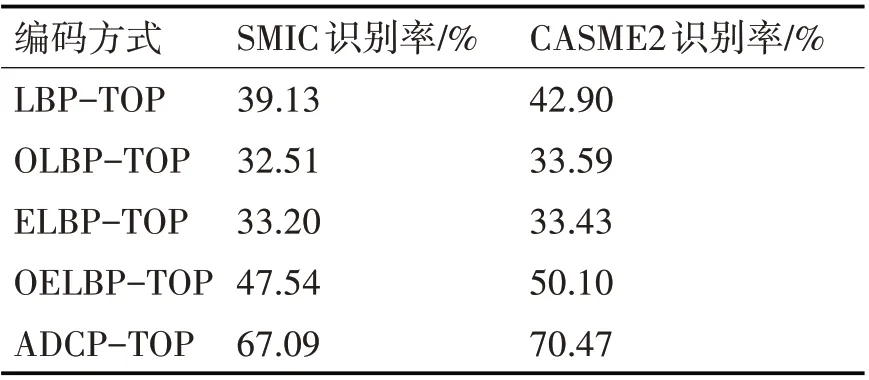
表3 在SMIC与CASME2数据库下不同编码方式的识别率对比
同LBP-TOP 一样,我们也对ADCP-TOP 算子设计了半径R 和采样点P。如图6 所示,共有三种方式,R1代表索引为偶数采样点半径,R2为奇数采样点半径。
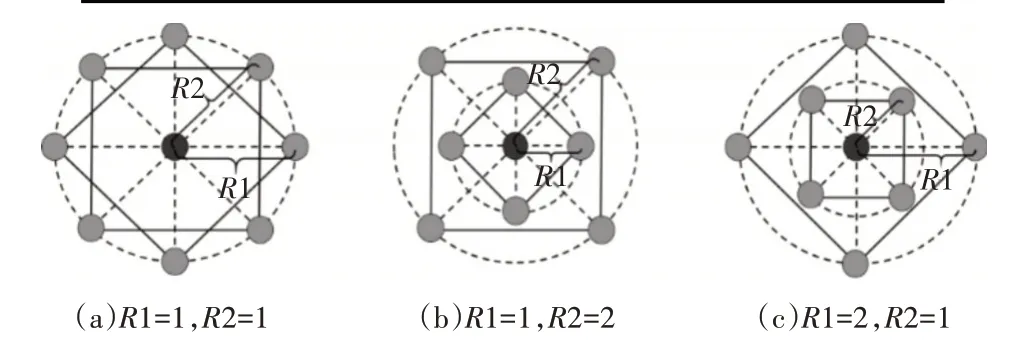
图6 ADCP-TOP 八采样点不同半径对比
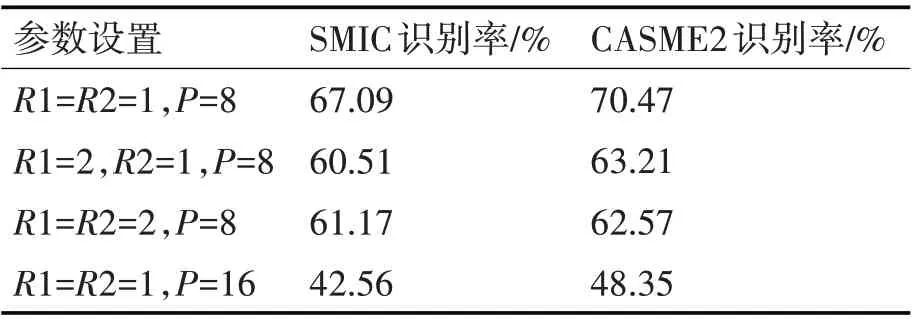
表4 在SMIC与CASME2数据库中ADCP-TOP不同参数设置下的识别率对比
3.3 算法对比
在对比实验中,采用LOSO 交叉验证。我们复现了四种编码方法LBP-TOP、3DHOG、CBP-TOP、HWP-TOP,另外对比三种基于光流场的微表情识别方法,并直接引用所在论文中的识别率,如表5所示。在CASME2 数据库下,ADCP-TOP 对比基线LBP-TOP 方法识别率提升31.16%。3DHOG 通过梯度计算方向获取运动方向信息,CBP-TOP 通过设置阈值提升抗噪性能,但二者提取的特征包含信息较少,细节提取能力不强,ADCP-TOP 改善了这一问题,对比两种方法的识别率分别提升19.14%和6.83%。HWP-TOP 尽管与我们的算法维度相同,但HWP-TOP 没有考虑邻域像素之间的关系。且ADCP-TOP将采样点按奇偶分开编码,增加了潜在方向信息和系统鲁棒性,识别率相比HWP-TOP提高3.47%。对比基于光流法的三种方法,ADCP-TOP 不仅具有捕捉时域信息的能力,同时也具有捕捉空间信息的能力,最终在SMIC 和CASME2数据库下,实验结果均有较好的提升。
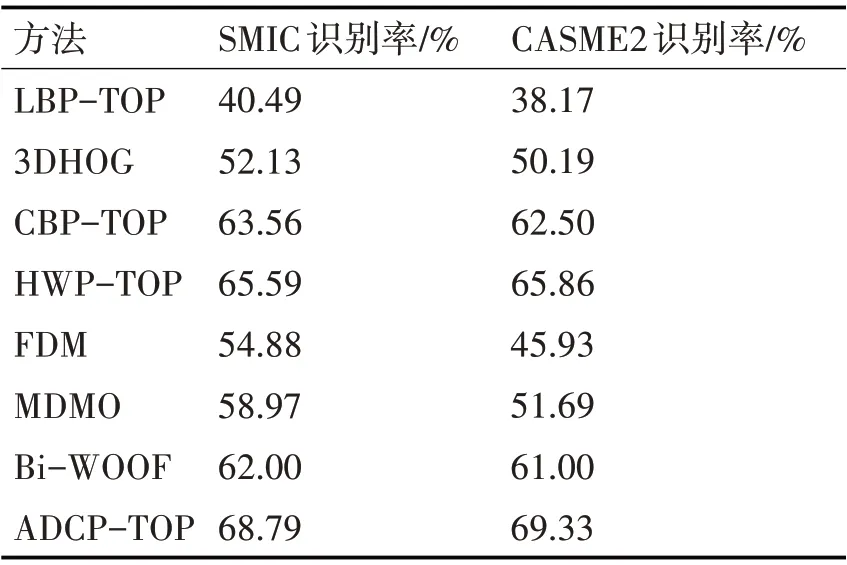
表5 在SMIC与CASME2数据库中采用LOSO交叉验证时各算法的识别率比较
4 结语
本文提出了一种新的基于相邻双交叉局部二值模式(ADCP-TOP)的微表情识别方法。ADCP-TOP 将邻域像素之间关系引入改善了原有编码有效信息不足的问题,通过对奇偶位置的采样点分开编码增加潜在方向信息和鲁棒性,对微表情有着更强的捕捉有效信息的能力和更高的识别准确度。对于未来的工作,深度学习是由网络自行寻找对分类有效特征,具有一定的优势,但需要大样本训练。因此今后将重点考虑如何利用传统方法去引导深度学习从而减小微表情数据库样本数量较小的影响。
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
房地产导刊(2022年4期)2022-04-19
航天返回与遥感(2022年1期)2022-03-09
新生代·下半月(2019年5期)2019-09-10
计算机应用(2016年10期)2017-05-12
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
科教导刊(2016年27期)2016-11-15
电脑知识与技术(2016年24期)2016-11-14
