
基于大数据的西藏非物质文化遗产知识图谱构建研究*
2022-03-16 06:01雒伟群党红恩刘炜高屹
西藏科技 2022年1期
雒伟群 党红恩 刘炜 高屹
(西藏民族大学信息工程学院,陕西 咸阳 712082)
0 引言
西藏自治区非遗资源丰富,是中华民族优秀传统文化宝库的重要组成部分。截止2020年,西藏自治区级非物质文化遗产项目中的藏戏、格萨尔、藏医药浴法等入选世界非遗名录,96 项入选国家级项目名录。利用先进的大数据、知识图谱等信息技术对西藏非遗进行保护,可以传承和发扬藏民族先辈文明。
随着移动设备的广泛使用,人们的社交行为、购物习惯、所处位置等数据都能得到有效地存储,并且存储已开始以PB(1PB=1024TB)为单位,我们已经进入大数据时代[1-3]。大数据环境下数据信息庞杂巨量,但也面临知识严重缺失问题。传统知识搜索引擎按网页文档进行超链接,但这些超链接都是独立的,没有相互依赖关系,搜索失败时不能推荐相关内容[4]。知识搜索引擎通过整合多源信息,产生知识信息,有效实现了知识利用和共享。
谷歌的知识图谱[5]与百度的知心等为通用知识图谱,在地理信息和企业等领域已经构建了领域知识图谱。知识图谱的构建方式有人工构建、机器自动构建等多种方式,人工构建方式准确度高,但费时费力;机器自动构建速度快,但准确度不高。所以构建领域知识图谱时,最好采用半自动化方式,即采用人工+机器自动化方式,在准确度和效率两方面取得平衡。
知识图谱的构建主要工作包括本体知识表示、语义标注、实体识别和关系抽取等环节。本体形式化定义了领域中的概念和关系,其定义必须得到大家一致认可。领域本体知识表示应该在领域专家指导下进行[6],人工构建本体质量比较高。自动构建本体速度快,从数据资源中自动获得本体知识,但获得的本体并不良好[7]。在大多数领域,自动构建与用户指导是一个切实可行的方法。语义标注就是对原始数据标记语义信息,可以通过人工方式对标注文档标记语义信息;半自动标注需要标注人员在客户端软件中完成手工指定网页,再选择合适的本体概念,最后生成可存储的标注结果;自动标注通过软件自动产生语义信息,虽改善了标注速度,但降低了标注质量。实体识别在文本中识别实体,关系抽取在文本中抽取出实体之间的关系,建立实体联系。
大数据处理、知识搜索与信息可视化等新技术在电子商务、社交平台等领域的应用成果突出,但这些IT 新技术在西藏非遗领域的研究应用却极少,这是因为西藏非遗文化体系庞杂、文化资源海量等因素造成的。所以利用大数据处理技术整理西藏非遗文化体系,构建本体模型,建立知识图谱,将为促进西藏非遗数字化保护的发展具有一定的实际意义。
1 西藏非遗知识图谱构建过程
自顶向下与自底向上是建立知识图谱最常用的两种方法[8]。自顶向下方法借助于行业领域数据和百科类网站知识建立知识图谱中的本体知识,然后在知识库中存储这些本体知识与模式信息;自底向上方法从最低实体层中归纳组织实体,然后人工审核整理出的新模式,最后存储到知识库中。本研究构建知识图谱时采用自顶向下方法构建本体库。
1.1 数据源
用于构建西藏非遗知识图谱的本体库数据源主要分为三类:一是百科类网站的开放链接数据集;二是CNKI等文献类网站;三是民族非物质遗产网站、非物质遗产大辞典、从事藏区非遗的科研机构或者政府部门渠道。使用Python 编写爬虫代码进行资源采集,资源采集列表为国家级非物质文化遗产名录(第一、二、三、四批)和西藏自治区级、地市级、县级非遗目录(第一、二、三、四、五批)中的非遗项目,合计2590 项,其中包含96 个国家非遗项目、460 个自治区非遗项目、480 个地市级代表性项目、1554 个县级代表性项目。表1是我们整理的西藏传统技艺知识图谱语料来源部门项目。
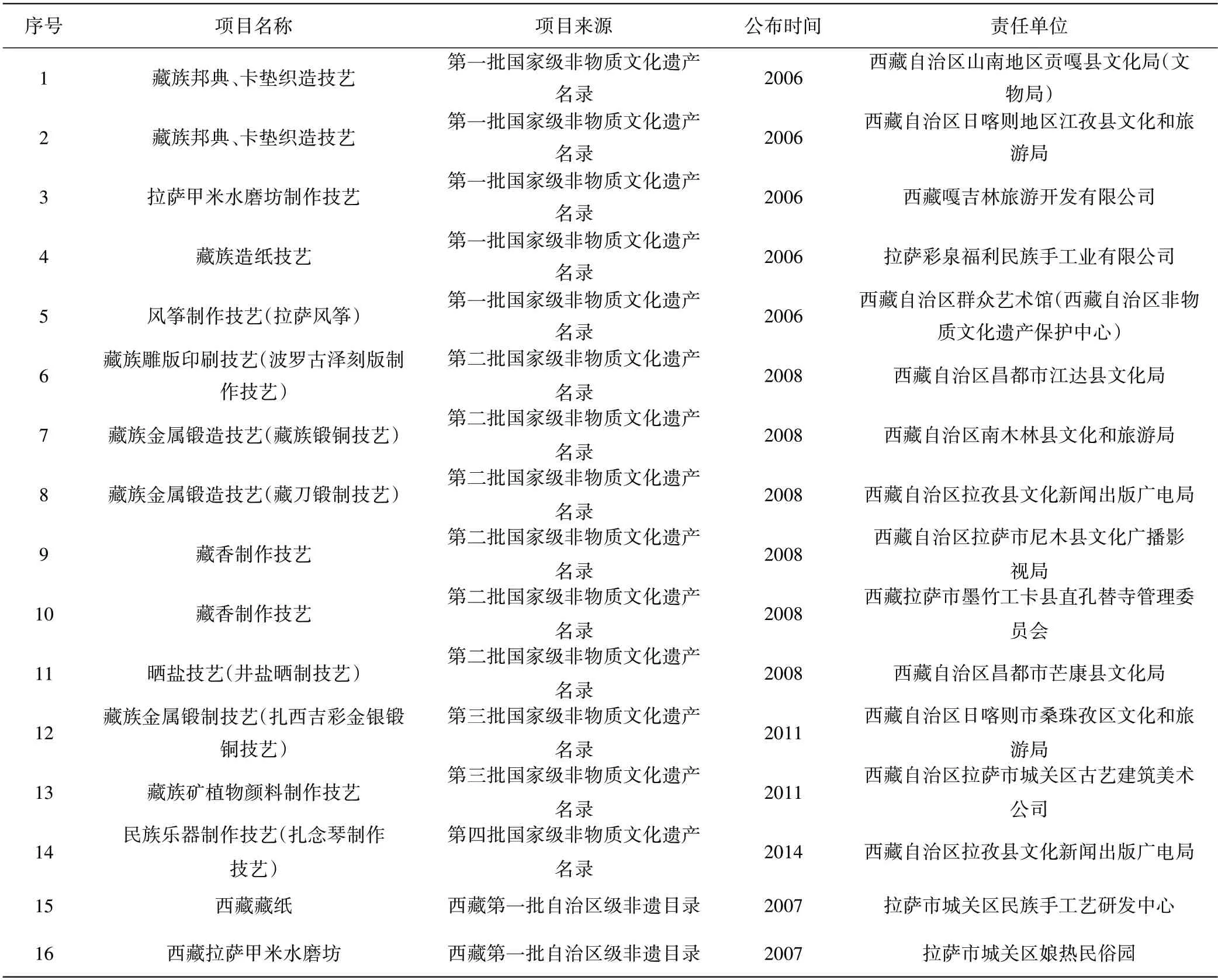
表1 西藏传统技艺知识图谱语料来源部分项目

表1(续)
结构化数据主要包括非遗项目名称、项目介绍的部分字段等,具有一定的专业性,在知识图谱构建时可以直接使用;半结构化数据主要包括文化遗产外在形式统计信息、文化遗产物理信息统计数据、介绍网页中爬取到的社评信息等。具有一定的结构但不同的项目或不同的类目间结构不完全一致,有待进一步抽取后使用。非结构化数据主要包括用户描述、分析进展,通过外部调研得到的隐含特征行为等。缺乏明确的表达方式和具体结构,需要人工参与补充及完善知识。
1.2 本体知识表示
本体是对领域中的概念、实例和关系等进行形式化的、明确且详细的一种说明,本体知识表示就是要发现概念实体及概念实体间关系,概念实体就是领域中的概念或实例,所以构建(概念实体,关系,概念实体)三元组成为本体知识表示的关键。我们用概念描述本体的实体类别,比如:传统技艺名称“藏族金属锻造技艺”是概念;具体的实例描述概念实例,比如:藏族金属锻造技艺中的“藏刀锻制技艺”;概念或实例之间的关系通过属性揭示,比如“藏族金属锻造技艺”有一种“藏刀锻制技艺”类别,也就是说“藏族金属锻造技艺”概念的属性为“类别”,该属性取值概念实例“藏刀锻制技艺”,也就是三元组(藏族金属锻造技艺,类别,藏刀锻制技艺)。领域知识表示就是要构建领域本体,挖掘数据集中所有概念及概念关系,并表示成三元组形式。
一般使用数据驱动方法建立领域本体,由于领域特性使得数据资料获取非常有限,建立的领域语料库规模普遍偏小,造成本体构建效果不佳。为解决这个问题,我们引入bootstrapping 方法。该方法目的是从搜索引擎中尽可能多地获取领域数据资料。比如:我们在搜索引擎中搜索词汇“藏刀”,返回结果有300条,搜索结果中的领域数据太少了,如何才能搜索出更多的语料数据?使用查询扩展方法。常规查询扩展为了提高准确率,在搜索引擎中获得了更多与查询相关的文档。我们使用查询扩展为了提高召回率,在搜索引擎获取更多的文档。
我们的方案是:在构建领域语料库时,在搜索引擎中引入bootstrapping 方法,将初始主题作为种子,生成查询query,在搜索引擎中获得搜索出的文档集合,然后通过查询扩展和迭代过程不断地进行搜索,获得的扩展查询词相关于原主题,最终获得的领域语料库规模将达到本项目研究需要,如图1所示。
扩展查询不断迭代,与初始主题相关的领域语料库规模不断扩大,通过3次迭代扩展,获得了15738 条数据,对于构建本体来说,数据量已经能够满足基本需求。
1.3 语义标注
本体定义完成后,我们就可以在领域数据集上进行标注概念实例了,另外利用属性可以标注实例关系,对可能的三元组添加提示信息。标注一般采用人工方法,对领域数据文本进行分词,对每个单词标注,进而标注概念实例和实例关系。
领域数据集处理的一项重要工作是领域分词,一般借助于分词工具+领域词表可以取得很好的分词效果。常用的分词工具有ansj、hanlp 和jieba 等,这些工具都能提供多种分词方式,但ansj 自定义领域词典后,领域词汇分词效果还是不理想;hanlp 可个性化分词,但在加载自定义词典时用时较长;jieba 也可进行个性化分词,并且可以较快地加载自定义词典。因此,构建领域词表是领域分词重要一环。
我们使用分词器jiaba 工具对领域数据集中的每个句子进行分词,西藏非遗领域的特有词汇,一般也会出现在期刊论文文献的关键词部分,比如藏刀、锻铜技艺、金属锻造等领域词汇,我们搜索学术期刊论文电子资源库,搜索出的论文中的关键词添加到领域词表中。
本体文本标注时,我们要定义好概念和关系的模板,然后采用基于种子的模板辅助人工标注方法。例如:文本中有一个句子“藏族金属锻造技艺分为藏族锻铜技艺和藏刀锻制技艺”等,该句中说明了藏族金属锻造技艺的一种上下位关系,它的模板可定义为:<C >分为<C1>和<C2>等。其中,概念C 是父类,C1 和C2 是其子类,即C1 和C2 的上位关系是C,C的下位关系是C1 和C2。模板识别方法简单易实现,准确率高,但是模板事先需要先定义好,非常耗时耗力,导致不能大规模展开。
基于种子的模板辅助人工标注方法,属于无监督方法,首先给定关系和两个种子实体对,然后从领域语料库中抽出句子集合。从这些句子中进一步得到给定关系的描述模式,再通过投票机制挑选给定关系的最佳模板。应用这些合适模板,在预料库中进行迭代,可匹配出更多句子,抽取出新的实例对,发现新的模式。持续迭代下去,最终实现给定关系全部实例对的抽取。在算法的辅助下,我们文本的实例标注就会省时省力,便于开展大规模语料库的概念提取和关系识别。
1.4 知识抽取
实体识别,通过命名实体名称在文本中识别出领域实体。基于规则和词表的实体识别在半结构化数据中具有天然的优势。对于非结构化数据一般采用规则+统计学习的方式进行抽取,经典模型如HMM、CRF,以及预训练模型BERT等。
在实体抽取方面,我们还研究了基于深度学习的实体识别,我们采用词典+规则+BIGRU_CRF 方案,该方案出于对性能和效果的综合考虑,识别准确率达到90%以上。如图2 所示,该模型使用了BIGRU 与CRF相结合进行命名实体识别,该模型自底向上分别是Embedding 层、双向GRU 层和CRF 层。首先使用词向量表示每一个句子,并作为双向GRU 的输入,正向GRU 与反向GRU 分别计算每个词左侧和右侧词对应的向量,输出的词向量是两个向量的连接;最后将双向GRU 输出的向量输入给CRF 层,经过CRF 算法处理后就会标注出句子中的实体序列。
实体消岐方面,我们采用规则+BERT+实体嵌入方案,这一方案对于短文本实体消岐具有较好的适应性。
术语抽取是指从语料中发现多个单词组成的相关术语,这类属于通常具有高度的专业性,识别效果与领域高度相关,通常需要大量的专业标记语料才能达到较好的效果,技术手段与实体识别类似。
实体识别及术语抽取之后,我们就可以进行关系抽取,将文本中的知识关系也就是实体间的关联关系抽取出来。主要包括基于弱监督的实体关系抽取、基于自举式学习的实体关系抽取和基于规则的实体关系抽取。对语料进行关系标注,并结合关系特征选择得到关系特征向量,经过相应的机器学习模型训练后可得到关系分类器,能够从领域语料中抽取出更多的关系实例,采用基于关系词字典构建与关系规则自动学习的实体关系抽取方法,将这两种研究思路进行整合,利用机器学习的方法实现关系词字典的自动构建,基于模式匹配的关系规则自动学习,可以自动高效地抽取出关系实例。
2 知识图谱可视化
知识图谱就是三元组形式的实体关系对,通过上面环节我们构建了西藏非遗知识图谱。知识图谱可视化可以借助与Neo4j 图数据库自动产生,也可以使用pyechart通过编程实现。我们的做法是先将西藏非遗知识图谱存储在Excel 表中,再利用ECharts 可视化技术进行知识图谱展示。ECharts 是一种可视化插件,底层通过Canvas 类库中的ZRender 图表库可以提供个性化的数据可视化展示。图3是我们生成的一张西藏非遗知识图谱截图。
从图3我们看到西藏传统技艺知识图谱中有关藏族金属锻造技艺方面的概念,揭示了藏族金属锻造技艺中各个概念节点的关系。藏族金属锻造技艺活动中所涉及到相关联的一些实体和属性有藏族锻铁技艺、藏刀锻制技艺、波密易贡藏刀锻制技艺、林芝市波密县易贡乡等。
3 结论
西藏非遗体系完整,包含数据量较大,通过网络爬虫技术可以自动产生大数据的语料库,从语料库文本中进行实体识别和关系抽取,就会构建三元组形式的西藏非遗知识图谱。通过知识图谱可视化,可以直观看到实体和实体之间的潜在知识关系。现阶段领域知识图谱的构建在知识抽取算法方面还有待改善和发展。
猜你喜欢
吉林大学学报(信息科学版)(2021年5期)2021-10-26
校园英语·月末(2021年13期)2021-03-15
哈哈画报(2021年10期)2021-02-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
中学生英语·外语教学与研究(2008年4期)2008-03-18
