
基于多级特征图联合上采样的实时语义分割
2022-03-16 03:36王小瑀
计算机技术与发展 2022年2期
宋 宇,王小瑀,梁 超,程 超
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
1 概 述
近年来,对于无人驾驶视觉感知系统,大多使用语义分割技术来处理感知到的物体。因此语义分割在无人驾驶领域有着极其重要的作用。由于无人驾驶的特殊性,使其不仅对语义分割网络的准确度有要求,对实时性的需求也非常迫切。
Long等人提出了最原始的语义分割网络FCN。继FCN之后应用于无人驾驶的语义分割算法总体来说可以分为两大类:第一类是基于编码器-解码器结构的网络,例如Ronneberger等人提出的Unet网络,在进行少类别分割任务时速度快、精确高。但是当分割类别增多,网络分割速度将大幅度降低;剑桥大学提出的SegNet,网络中采用最大池化索引指导上采样存在特征图稀疏问题,进而导致算法虽然达到了实时分割速度,但分割精度低;Paszke等人提出的Enet网络通过减少神经元权重数量以及网络体积使得网络可以达到实时分割的要求,但是算法的拟合能力弱导致分割精度较低。第二类是基于上下文信息的网络,例如Zhao H等人提出的PSPNet网络,通过引入更多上下文信息提高了网络的场景解析能力,但是由于多次下采样操作导致特征图丢失大部分空间信息。针对这个问题,Zhang H等人提出了EncNet,但是由于采用Resnet101网络作为主干,参数量庞大,网络实时性较差;Chen等人提出的DeepLab网络,引入了空洞卷积来保持感受野不变。并且后续又提出了DeepLab v2以及DeepLab v3+网络,其中DeepLab v3+结合了两大类网络的优点,使用DeepLab v3作为编码器并且在最终特征图的顶部采用了空洞金字塔池化模块(atrous convolution spatial pyramid pooling,ASPP),在避免下采样操作的同时获取了多感受野信息。但是网络在分割速度方面存在不足,主要是因为引入空洞卷积带来了大量的计算复杂度和内存占用。以Restnet-101为例,空洞卷积的引用使得其中23个残差模块,需要占用4倍的计算资源和内存,最后3个残差模块需要占用16倍以上的资源。
针对以上各种网络无法同时兼顾准确度以及实时性的问题,该文提出了一种实时语义分割网络,采用参数量较少的轻量卷积网络FCN8s代替DeepLab v3+中的ResNet101作为网络的主干。文中算法主干与DeepLab v3+的区别在于最后两个卷积阶段。以第四个卷积阶段(Conv4)为例。在DeepLab v3+中首先对输入图片进行卷积处理,然后再进行一系列的空洞卷积处理。不同的是,文中方法首先使用跨步卷积来处理输入的特征图,然后使用几个常规卷积来生成输出特征图。并且使用多级特征图联合上采样模块(multi-scale feature map joint pyramid upsamping,MJPU)来代替DeepLab v3+中耗时、耗内存的空洞卷积,大大减少了整个分割框架的计算时间和内存占用。最重要的是,MJPU在大幅度减少运算量的同时,不会造成性能上的损失,让算法应用在无人驾驶实时语义分割场景中变得可行。
2 文中算法
为了获得高分辨率的最终特征图,DeepLab网络中的方法是将FCN最后两个下采样操作删除,这两个操作由于扩大了特征图的感受野而带来了大量的计算复杂度以及内存占用量。该文的目标是寻找一种替代方法来近似最终的特征图。
为了实现这一目标,首先将所有被DeepLab v3+删除的跨步卷积全部复原,之后用普通的卷积层替换掉空洞卷积。如图1所示,文中方法主干与原始的FCN相同,其中五个特征图(Conv1-Conv5)的空间分辨率逐渐降低2倍。

图1 网络执行流程
为了得到与DeepLab v3+相似的特征图,提出了一个新的模块,叫做多级特征图联合上采样模块(MJPU),它以编码器最后三个特征图(Conv3-Conv5)为输入,然后使用一个改进的多尺度上下文模块(ASPP)来产生最终的预测结果。在算法执行过程中,输入图片的格式为H
×W
×3,经过文中设计的编码器网络,编码器网络由轻量级网络构成,可以减少算法在编码阶段的计算时间;其次使用MJPU模块来生成一个特征图,该特征图的作用类似于Deeplab v3+主干网络中最后一个特征图的激活作用。MJPU的使用避免了DeepLab v3+中参数量庞大的空洞金字塔池化网络与高分辨率的最终特征图做卷积运算而大幅度降低了分割速度。MJPU模块是该文可以大幅度增加实时性的重要因素。最后网络经过ASPP获取不同大小的感受野信息,增加网络对不同尺度物体的分割能力,提升算法的分割精度。下面将详细介绍替换空洞卷积的方法以及多级特征图联合上采样模块的结构。2.1 空洞卷积的替代
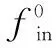
f
做普通卷积,得到中间特征f
;(2)删除索引为奇数的元素,得到f
。
图2 一维空洞卷积与跨步卷积示意图
形式上,给定输入特征图的x
,DeepLab v3+网络中得到输出特征图的y
如下:
(1)
而在文中方法中,生成的输出特征图y
如下: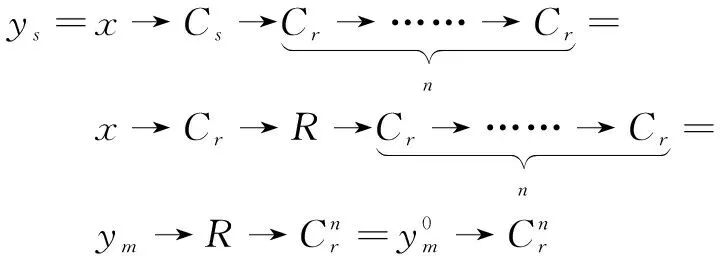
(2)
其中,C
代表普通卷积,C
代表空洞卷积,C
代表跨步卷积。S
、M
、R
分别代表图2中的分离、合并、删除操作。相邻的S
和M
操作是可以相互抵消的。为了简单起见,上述两个方程中的卷积是一维的,对于二维卷积可以得到类似的结果。2.2 多级特征图联合上采样模块
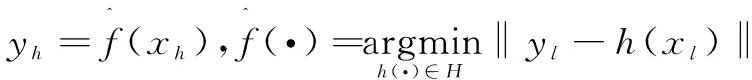
(3)
其中,H
是所有可能的变换函数集合,‖.‖是一个给定的距离度量。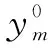

(4)
根据上述分析,设计了如图3所示的MJPU模块。
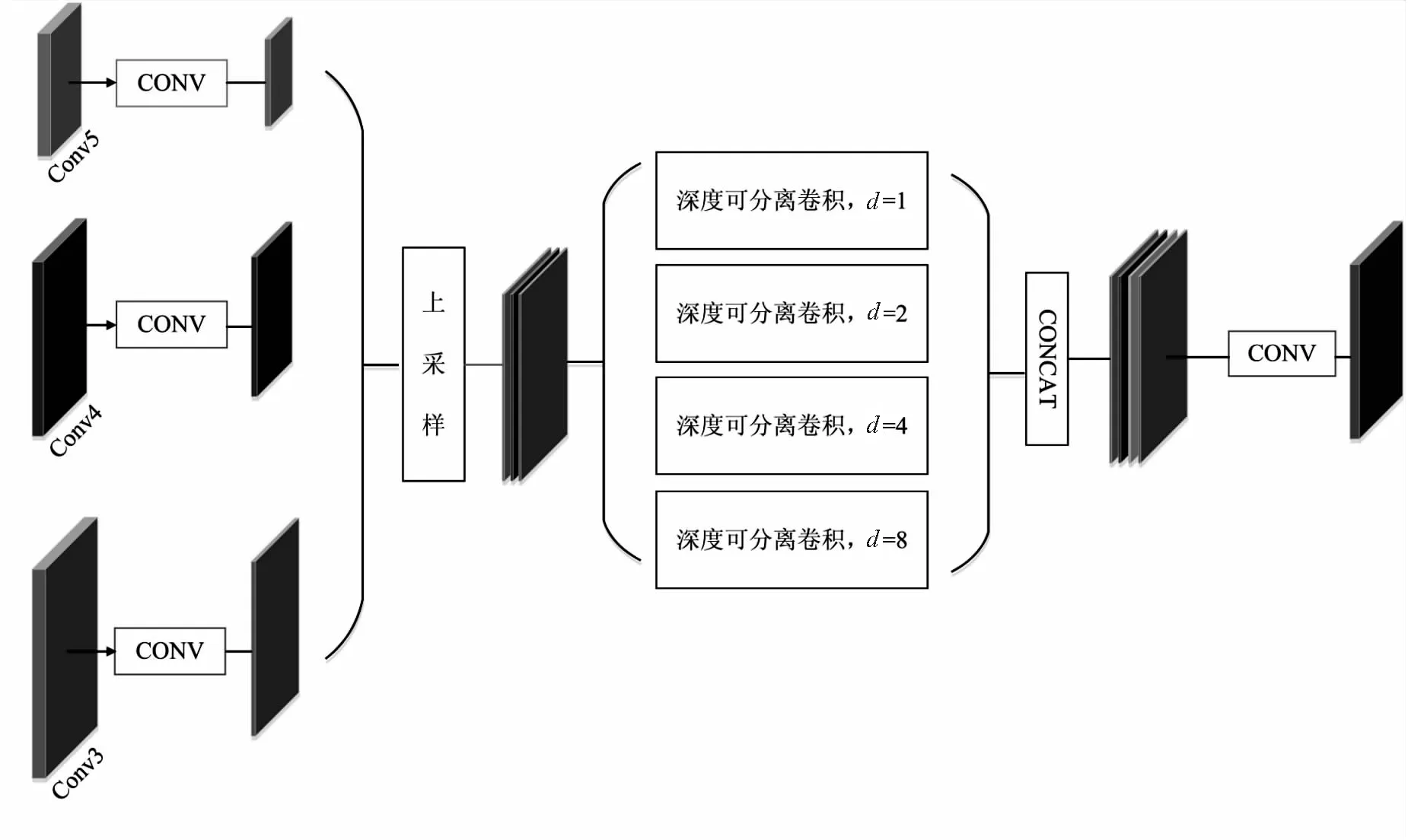
图3 MJPU模块
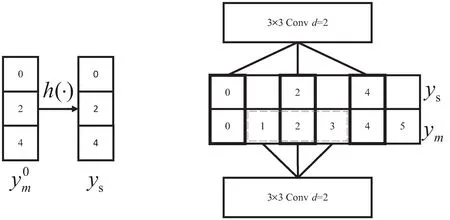
图4 深度可分率卷积作用示意图
3 实验与分析
3.1 评价指标
实验主要是在准确率以及速度两方面对网络进行了评价。在准确率方面使用的是像素精度(PixAcc)以及平均交并比(mIoU)作为评价指标。在速度方面则使用的是每秒处理帧数(FPS)作为评价指标。
PixAcc是语义分割中正确分割像素占全部像素的比值,而mIoU指的是真实分割与预测分割之间重合的比例,其计算公式如下:

(5)
式中,k
表示类别数量,文中为34类。TP
表示正类判断为正类的数量,FP
表示负类判断为正类的数量,FN
表示正类判断为负类的数量。FPS作为常见的测量网络速度的评价指标,计算公式如下:
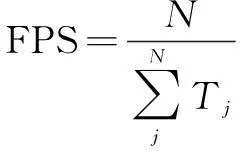
(6)
其中,N
表示处理图像数量,T
表示处理第j
张图像所用的时间。3.2 实验环境
语义分割模型使用TensorFlow2.0深度学习网络框架搭建,在训练和测试阶段的服务器配置均具有英特尔 Core i9-9900K 5.0 GHz的CPU、32 G DDR4 2 666 MHz的内存和RTX-2080TI(具有11 GB显存)的GPU,并且基于Window10的操作系统,在CUDA10.0架构平台上进行并行计算,并调用CuDNN7.6.5进行加速运算。
在训练过程中网络采用Adam优化器,初始学习率是0.001,学习率策略为逆时间衰减策略,权重衰减使用L2正则化。其中decay_steps=74 300、decay_rate=0.5,代表每过100个epoch,学习率衰减为原来的三分之二。图5是网络应用此种学习策略的loss值衰减曲线。可以清楚看出逆时间衰减策略可以使模型在较少的epoch次数内达到全局最优。

图5 网络训练过程中loss值展示
3.3 数据集
文中选择的无人驾驶数据集为国际公开的由奔驰公司推动发布的数据集Cityscapes。Cityscapes是在无人驾驶环境语义分割中使用最广泛的一个数据集。它包含了50个城市的不同场景、背景、季节的街景图片,具有5 000张精细标注的图像、20 000张粗标注的图像。在实验过程中,文中只使用了5 000张精细标注的图像,将其划分为训练集、验证集和测试集。分别2 975张、500张、1 525张图像,并且使用了全部34类物体作为分割对象。由于原有图像分辨率为2 048×1 024,分辨率过高导致硬件无法进行大批量训练,因此对图像进行缩放并裁剪成512×512大小。
3.4 实验结果分析
为了验证该网络的分割性能,选取了六种网络与文中算法做对比,选取的网络分别为Unet、SegNet、ENet、PSPNet、EncNet、DeepLab v3+。算法性能对比见表1。
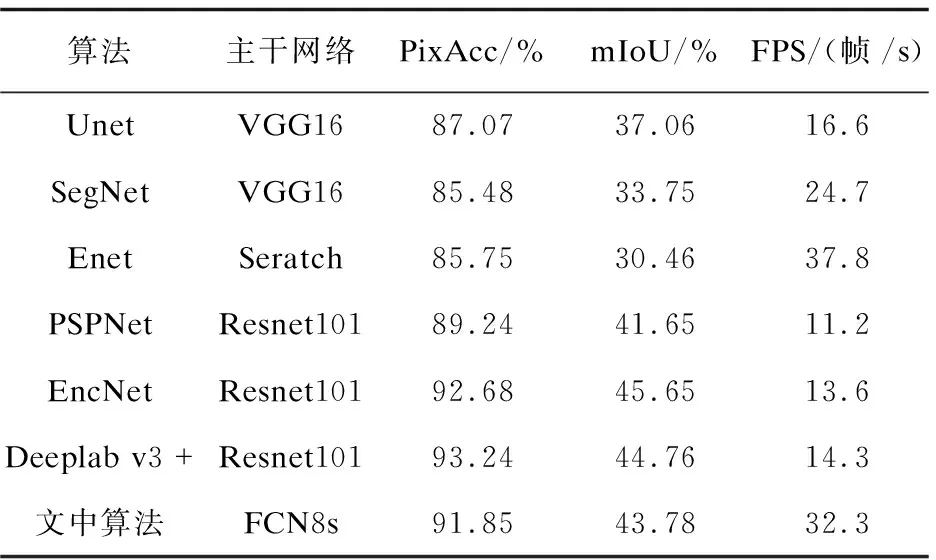
表1 各算法在Cityscapes数据集(val)上的不同评估指标对比
首先与表1中的前三种轻量级网络进行对比,文中网络的mIoU分别高出6.72%、10.03%和13.32%,PixAcc也有平均5%以上的提升。在网络实时性方面虽然略低于Enet,但这是由于Enet通过减少神经元权重数量的结果,虽然Enet的实时性较好但是算法严重非线性,网络分割精度较低。而对比以分割精度为主要指标的PSPNet、EnecNet和DeepLab v3+,由于文中主干网络采用的是轻量级网络,导致网络精确度略微落后,但是在分割速度方面最多高出200%。
图6展示了不同算法的分割结果。从图6中可以看出,文中算法对楼房、道路、树、汽车、天空等都具有较好的分割效果,对于这些大物体该网络均未产生分类错误区域;从图中还可以看出该网络对路灯等杆状物体以及远处车辆等小目标分割效果良好,这主要受益于所提出的MJPU模块结合了多层特征图的语义信息。

图6 不同算法在Cityscapes数据集上语义分割效果
3.5 网络结构分析
为了进一步验证MJPU的有效性,该文将其与经典的双线性插值上采样和特征金字塔网络(FPN)进行了对比实验。使用FPS作为评价指标,在GPU上以512×512图像作为输入进行测量。结果如表2和表3所示。对于ResNet-50,文中方法的测试速度大约是Encoding结构(EncNet)的两倍。当主干更改为ResNet101时,文中方法的检测速度比Encoding结构的快三倍以上。并且可以由图看出文中方法的检测速度可以和FPN相媲美。但是对于FPN来讲,MJPU模块可以获得更好的性能。因此对于DeepLabv3+(ASPP)和PSP,文中提出的模块可以在提高性能的同时,对网络进行一定程度的加速。
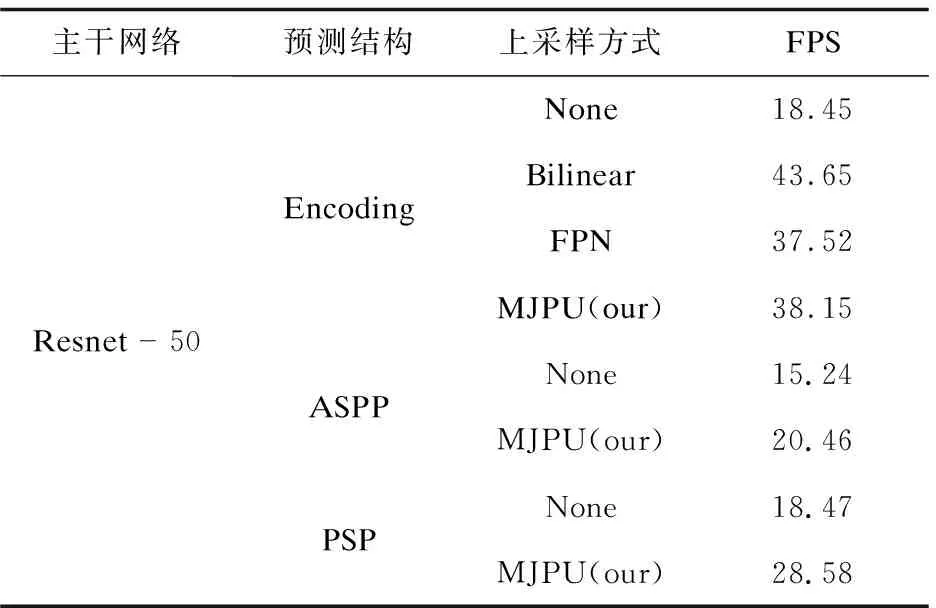
表2 Resnet-50中不同上采样方式计算复杂度对比

表3 Resnet-101中不同上采样方式计算复杂度对比
4 结束语
为了使语义分割网络更加满足无人驾驶实时分割任务的需求,提出了一种新的实时语义分割网络。首先,采用了一种轻量级的卷积神经网络作为编码器。并且分析了空洞卷积和跨步卷积的区别和联系,使用跨步卷积和普通卷积的组合代替了耗时、耗内存的空洞卷积。在此基础上,将高分辨率特征图的提取问题转化为一种联合上采样问题,提出了一种新的多级特征图联合上采样模块,通过该模块可以在获得近似与DeepLab v3+相似的特征图的前提下,将网络计算复杂度最多降低三倍以上。通过在Cityscapes数据集上的实验表明(mIou=43.78%,FPS=32.3),所提出的实时分割算法在大幅度降低计算复杂度的同时,取得了较好的分割效果。从而使该网络更加适合应用于无人驾驶场景当中。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
科学24小时(2020年6期)2020-07-18
上海师范大学学报·自然科学版(2019年5期)2019-12-13
价值工程(2017年28期)2018-01-23
中国新通信(2017年9期)2017-05-27
科技与创新(2017年5期)2017-03-28
故事作文·高年级(2017年2期)2017-03-01
漫画月刊·哈版(2009年10期)2009-03-26
