
一种改进的轻量级垃圾目标检测算法
2022-03-16 03:36:38熊卫华
计算机技术与发展 2022年2期
许 伟,熊卫华
(浙江理工大学 机械与自动控制学院,浙江 杭州 310018)
0 引 言
随着中国经济的高速增长,对资源的使用和环境的保护使得人们开始重视对垃圾的处理问题,而随着全国各大城市的生活垃圾管理条例的颁布和执行,便捷的垃圾分拣方法成为了社会的热点问题。传统分拣主要依靠人工分拣,工人的工作环境较差,且施工人员容易在施工过程中受伤。该文基于计算机视觉深度学习的方法对垃圾进行目标检测,通过对垃圾目标的定位和分类为后续的各种取件机械手分拣或其他分拣方式提供算法参考方案。
随着计算机视觉技术的成熟,越来越多的研究者陆续提出适用于垃圾目标检测的深度学习解决方案。Li等提出了FSSD算法,将SSD算法网络额外提取部分特征层作为金字塔特征融合层,但是,改进后的网络检测速度较慢。岳晓明等提出了一种基于CenterNet的垃圾分类与检测算法,将具有浅层特征层的特征与最终输出检测层进行融合,得到了改进的DLLA-34网络。该算法对其论文中自制垃圾数据集的精度达到98.2%,但是,该论文所使用的垃圾数据样本过于相似,训练集数据量不够大,背景单一,鲁棒性不高。向阳等提出了O-SSD网络,使用八度卷积算法代替传统卷积,在提高模型性能的同时减少了算力,该网络模型取得了不错的检测效果。
目前基于深度学习技术的目标检测算法分为两类,一类为以Fast R-CNN、Faster R-CNN、R-FCN为代表的双阶段目标检测算法,该类算法基于区域建议寻找可能存在目标物体的检测框;另一类是以YOLO系列、SSD系列为代表的单阶段目标检测算法,该类算法在直接生成候选框的同时进行检测框的分类和回归。这些算法模型参数量较大,不适用于计算能力较弱、成本不高的低功耗设备。研究者们大多从两个角度对网络模型进行优化,一些着眼于模型的各类压缩算法,如剪枝、量化、知识蒸馏等,另一些将关注点放在优秀的网络模型设计中,如MobileNet、ShuffleNet等。该文提出一种基于改进YOLOv3的轻量级垃圾目标检测算法Ghost- YOLO,将GhostNet网络作为特征提取层代替原来的Darknet-53,并对yolo层进行一定的改进,经实验论证,该算法能有效满足实时垃圾分类检测的需求。
1 算法理论
1.1 YOLOv3算法模型
基于端到端的神经网络算法YOLO(you only look once)系列经过发展,至今已到YOLOv5版本,第四和第五版本都是在第三版本上做改进,且并未涉及到网络的轻量化工作。该文使用该系列原创作者的YOLOv3算法,并针对网络轻量化做出一些改进。
YOLOv3网络结构如图1所示。算法主干网络使用Darknet-53作为特征提取层,共74层的特征提取层由大量残差网络组成。在yolo层中,YOLOv3采用FPN多尺度特征融合的方式,通过将13×13大小富含高级语义信息的特征进行上采样操作,与富含位置信息的低层特征图进行融合,分别在32、16、8倍降采样三个尺度的特征图像上进行检测框和类别的输出与预测。依次输出由大及小的物体检测框。
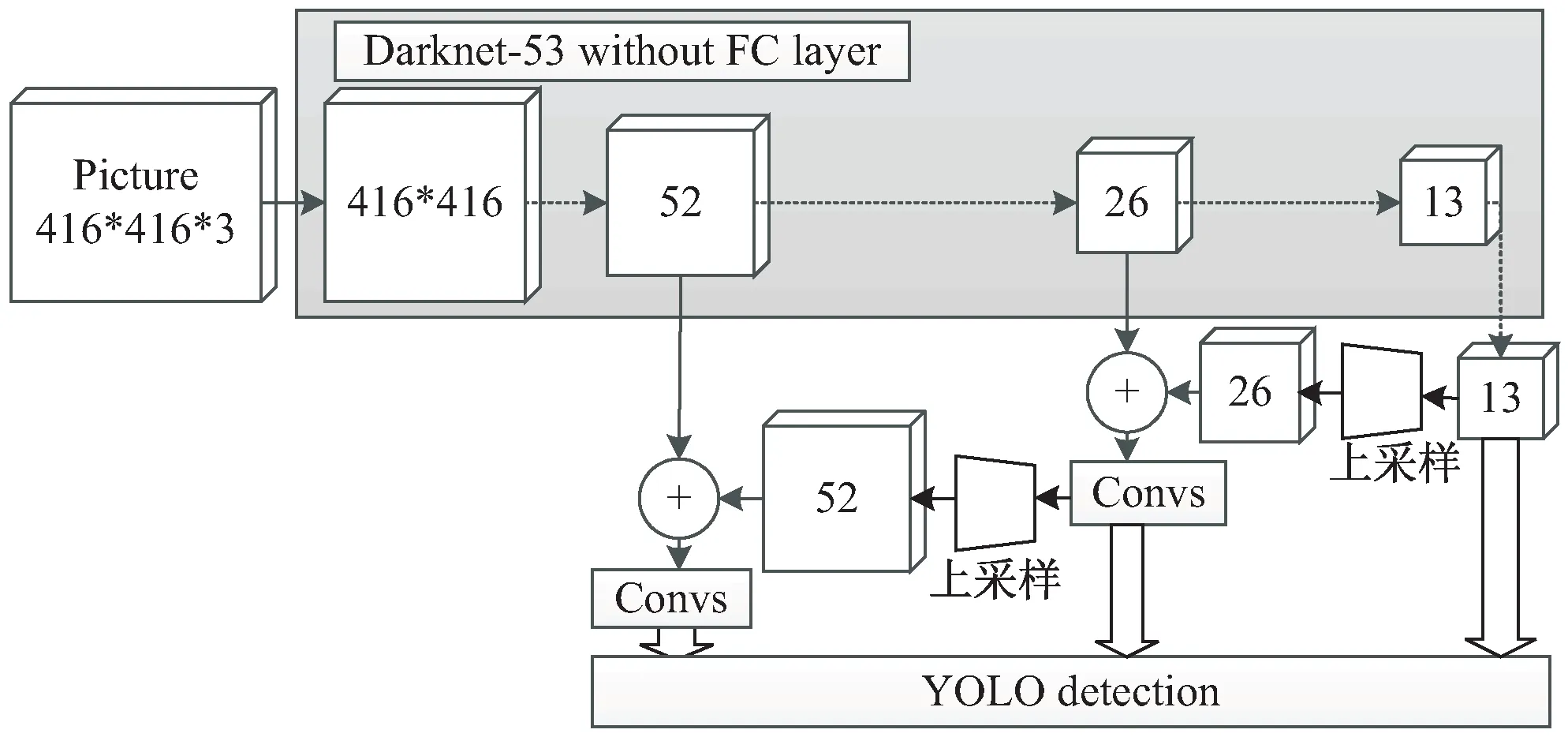
图1 YOLOv3网络结构
1.2 文中轻量化算法
如图2所示,Ghost-YOLO算法通过去除全连接层的GhostNet网络进行特征提取,其中特征提取网络中的104、52、26和13分别表示该大小特征图的最后一步卷积操作。经过灰色区域的特征提取后进入特征融合单元,其中富含语义信息的13×13大小的网络经过三次上采样分别与特征提取网络中的第13层、第7层、第5层相同大小的特征进行融合,该融合结果同时与104×104大小的特征层经过三次DSConv(depthwise separable convolution)深度可分离操作的
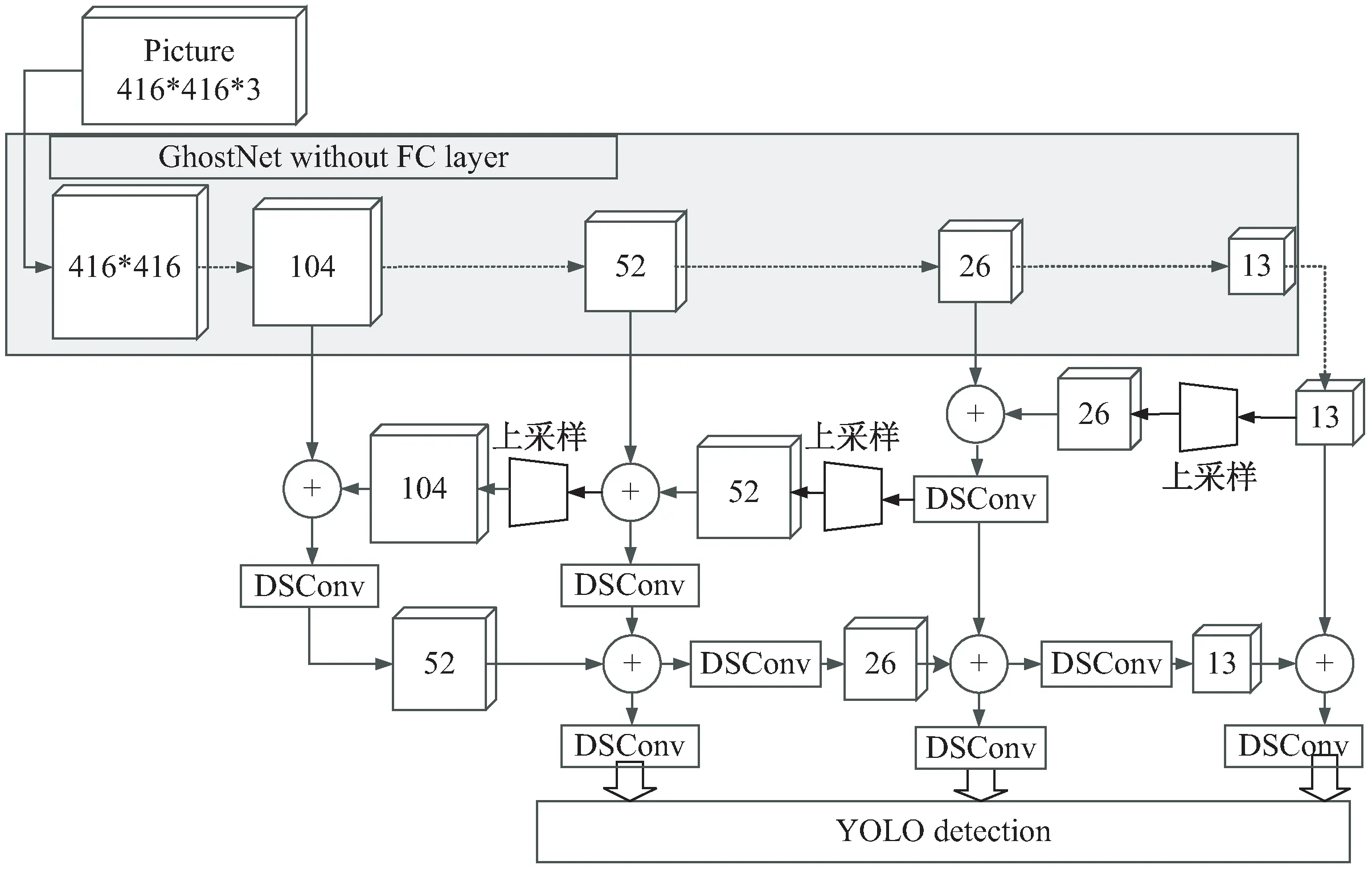
图2 Ghost-YOLO网络结构
特征相融合,获得更为丰富的底层特征的位置信息。通过最后输出的52×52,26×26和13×13大小的特征图进行垃圾目标检测。
1.2.1 改进的特征提取网络
考虑到垃圾分类使用场所大多是成本较为低廉的嵌入式设备,为降低运算复杂度,需要对算法进行轻量化。该文使用华为在2020年CVPR上提出的GhostNet网络结构,将YOLOv3算法中的特征提取网络部分由Darknet53改为GhostNet网络结构,并将其进行迁移学习。Han K发现经过普通卷积后的特征图有相当一部分高度相似,图3为文中数据集中某张图片第7层卷积层52×52大小的特征图可视化,可以发现该层存在许多近似的冗余特征图。

图3 Ghost-YOLO网络结构
这些冗余特征图虽然同样对网络训练有一定帮助,但生成这些特征图的计算成本过高,为降低计算量,只通过普通卷积得到部分特征,其余特征层通过逐层卷积获得。
通常的卷积如图4(a)所示,对输入数据X
使用n
个滤波器得到卷积后的特征,而Ghost module则分两步来获得与普通卷积相同数量的特征图。如图4(b),第一步是少量卷积,对输入数据X
使用m
(m
=n
/2)个滤波器,内核大小为k
×k
的卷积核f
跟原始特征图X
进行卷积运算,得到输出特征图Y
=X
*f
;第二步是cheap operations,如图中的φ
所示,文中使用的具体方法是对输出的m
个特征图逐个进行3×3卷积(depth-wise convolutional)得到另外的n
/2个特征图。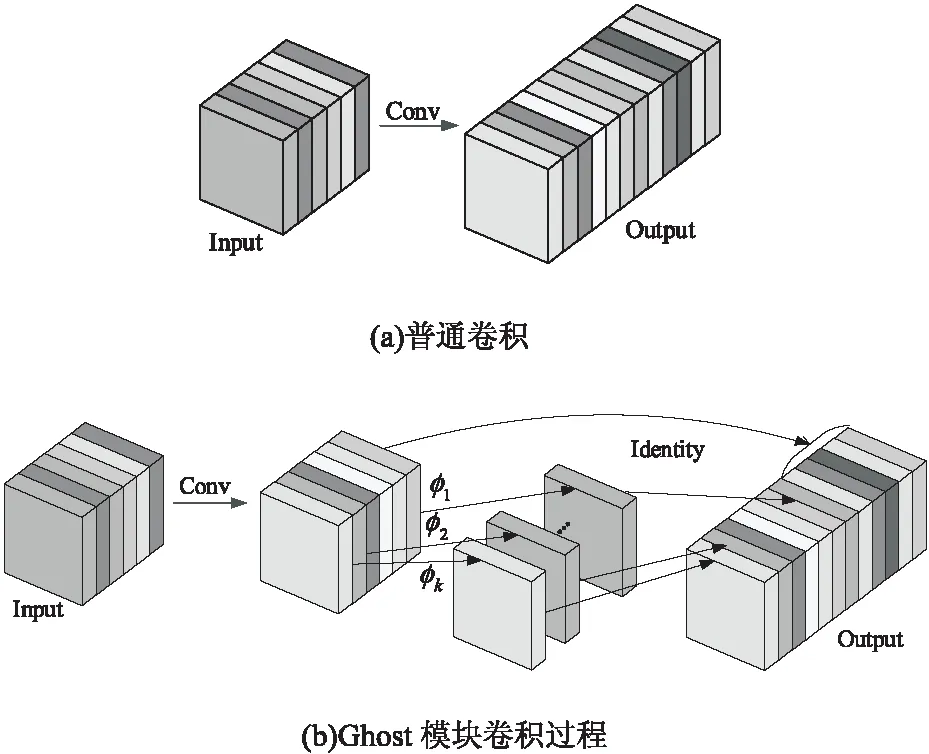
图4 普通卷积与Ghost模块的卷积过程
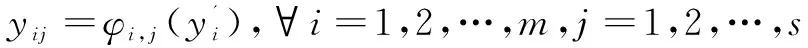
(1)
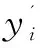
Y
=[y
,y
,…,y
]=[y
,y
,…,y
1,…,y
1,y
2,…,y
](2)
由于通过逐层卷积生成的特征图数量比例越大,网络的准确率会下降得越明显,所以该文通过普通卷积得到一半特征图,另一半特征图使用计算量较低的逐层卷积得到,即s
=2。Ghostnet网络结构将Mobilenetv3中的bottleneck模块改为Ghost bottleneck。其主要由两个堆叠的Ghost模块组成,通过第一个Ghost Module起到增加通道数的作用,并且用来指定输出通道数的膨胀比;第二个Ghost Module将通道数降低到与输入通道数一致。该模块根据步长的不同分为两种,如下图右图所示Stride=2的G-bneck,使用DWConv深度可分离卷积,该结构会进行两倍的降采样。
该文将其应用在垃圾目标检测任务中,由于垃圾目标会包含类似电池等小物体,为了使小物体在特征提取的过程中信息不易丢失,将图片统一缩放至416×416大小。
1.2.2 轻量化的特征融合网络
原YOLOv3网络由特征提取网络Darknet-53和目标检测特征融合yolo层组成,yolo层采用FPN特征金字塔结构将深层语义特征与浅层位置特征进行特征融合,该结构充分利用了特征层级,自上而下的路径增强以及侧向连接,为检测提供了更加丰富有利的特征。原yolo层输出检测框的特征图大小分别为13×13、26×26和52×52。由于考虑到原FPN结构在上采样融合的过程中并未对13×13大小的检测框进行融合,且特征经过多层的传递位置信息丢失较多,浅层网络特征未得到充分利用。为了能够充分利用网络浅层丰富的位置信息,同时增强网络对小尺寸目标的检测能力,添加一个自底而上的二次融合通道,进一步增强整个网络结构的特征提取定位能力,如图5中下方的虚线箭头所示。首先,利用存在于浅层特征更丰富的定位信息,建立自下而上的特征信息路径,增加了104×104大小的特征图进行降采样实现特征的二次融合,将相同大小的特征图与上采样结构的特征图进行融合,最后取52×52、26×26和13×13大小的特征图生成最终的三种大小的检测框进行目标检测。
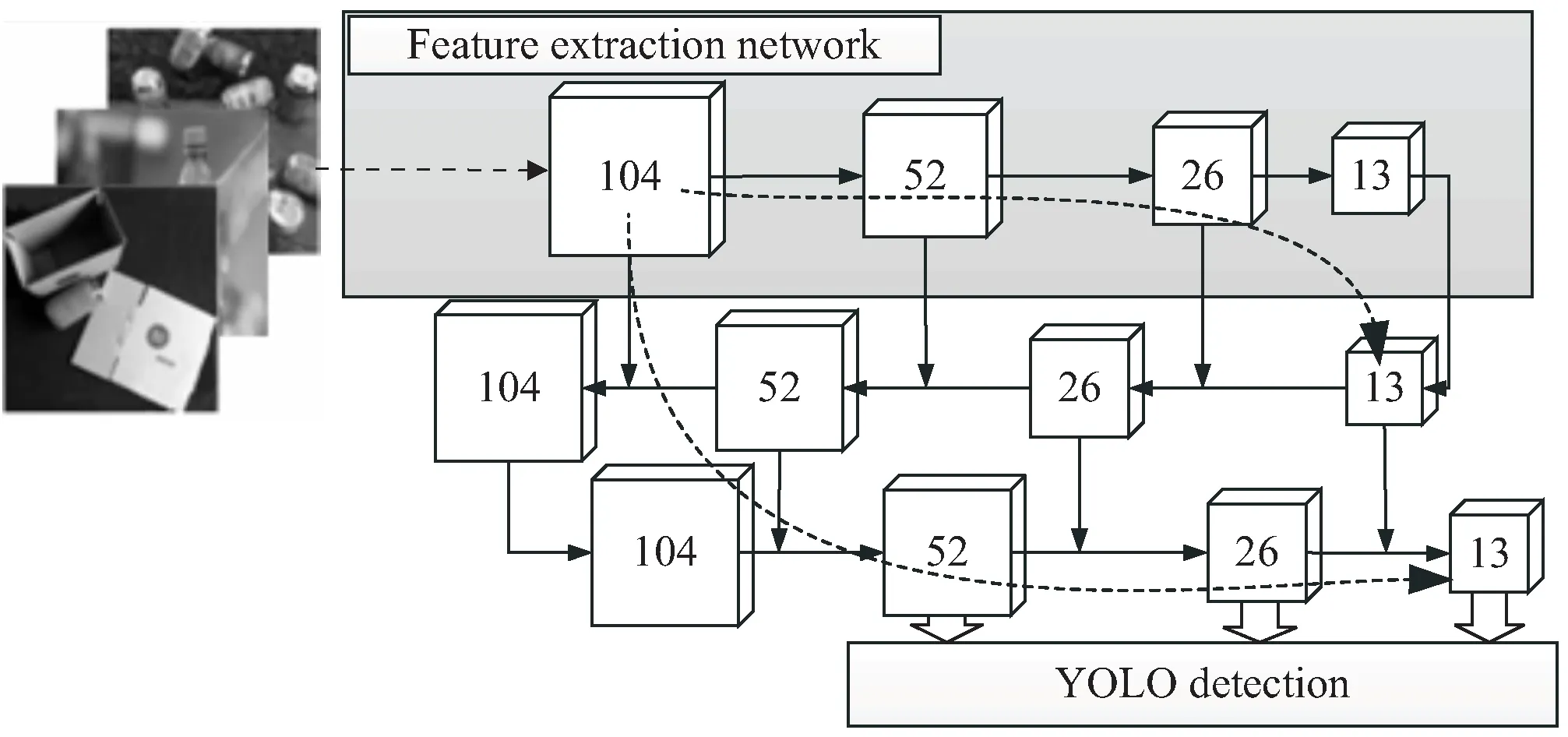
图5 改进的YOLO特征融合层
为降低特征融合层的参数量,在特征融合层中的所有卷积操作都使用DWConv深度可分离卷积操作代替传统卷积操作。具体操作在上述网络结构图中已经展示。相比于原始结构的上采样过程与特征提取网络的特征进行一次融合后卷积,文中的特征融合网络会增加一路从特征提取网络中的stride=2的深度可分离卷积构成的降采样链路,进行两次的特征融合,相当于将原本富含位置信息的低层特征层信息进行了二次传输。使用深度可分离卷积既保证了信息的有效传输,又使得整个改进后的网络结构轻量化。为表述方便,在下文中使用improved yolo代表本节的特征融合算法方案。
2 数据集的制作
由于目前并未有专门针对垃圾目标检测的数据集,所以笔者制作了较为通用的垃圾检测数据集。考虑到人力和时间成本,设置了6类常见垃圾种类,分别为瓦楞纸(cardboard)、塑料瓶(bottle)、纺织物品(cloth)、金属罐头(metal can)、玻璃材料(glass)和废弃电池(battery)。通过网络爬虫技术在各大网站上下载了约2万4千张图片,每种4千张,经过对图片进行分辨率、目标占比以及清晰度的筛选,每个种类筛选出800张左右。另外通过手机拍摄生活垃圾照片作为数据集的补充,总数据集每类约1 000张,部分图片会出现多种垃圾,总训练集5 899张。将上述数据集通过LabelImg完成图片标注工作,存储为xml格式文件。图6为数据集中的部分图片。

图6 数据集样本
3 实验结果分析
3.1 训 练
文中所使用的深度学习框架为Pytorch1.1.1,实验设备为win10系统,GPU为GTX1080ti,主机内存为32 G,所使用的神经网络加速库为CUDNN7.3,CUDA10.0。
由于2019年华为云举办过基于ModelArt平台的垃圾分类竞赛,公开了经过筛选的垃圾分类数据集,共计19 459张43个类别,文中的特征提取网络使用迁移学习,在该分类数据集上进行预训练,使用预训练后的权重文件初始化特征提取网络。使用自制的垃圾目标检测数据集,将85%的数据集作为训练集以batchsize为8进行训练,另5%作为测试集,10%作为验证集。训练初始学习率为0.000 1,到第90个训练周期学习率降为0.000 05,在第150个epoch终止训练,模型在140个周期左右测试集的平均精度均值达到峰值。
3.2 评估参数
评价指标使用目标检测的通用评价指标平均精度均值mAP(mean average precision),该指标表示多个类别的平均精度的均值,即所有AP的平均值。AP指单个垃圾类别的平均精度,文中使用的AP默认为AP,即预测框与ground truth的IOU在大于50%前提下的单类别平均精度。
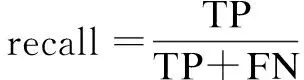
(3)
公式(3)表示召回率的计算方式,其中TP表示模型将垃圾目标检测为正确的类别,FP表示模型将非垃圾目标检测成垃圾目标,FN表示误把垃圾目标检测为错误类别或未检测到垃圾目标的情况。
3.3 结果分析
单类别平均精度AP数值如图7所示:平均精度最高的类别为bottle,在文中的数据集下达到97.7%,其余从高到低依次为cardboard(95.4%),battery(89.1%),metal can(87.9%),cloth(82.7%),glass(81.3%)。将Ghost-YOLO网络与原YOLOv3以及YOLOv2网络进行比较,这两个网络的主干网络均使用同样的方式在垃圾分类数据集下进行预训练。文中网络对每类垃圾的平均精度均值均优于原YOLOv3网络,YOLOv3的mAP为86.2%, YOLOv2的mAP为81.1%,文中网络的mAP为89.02%。
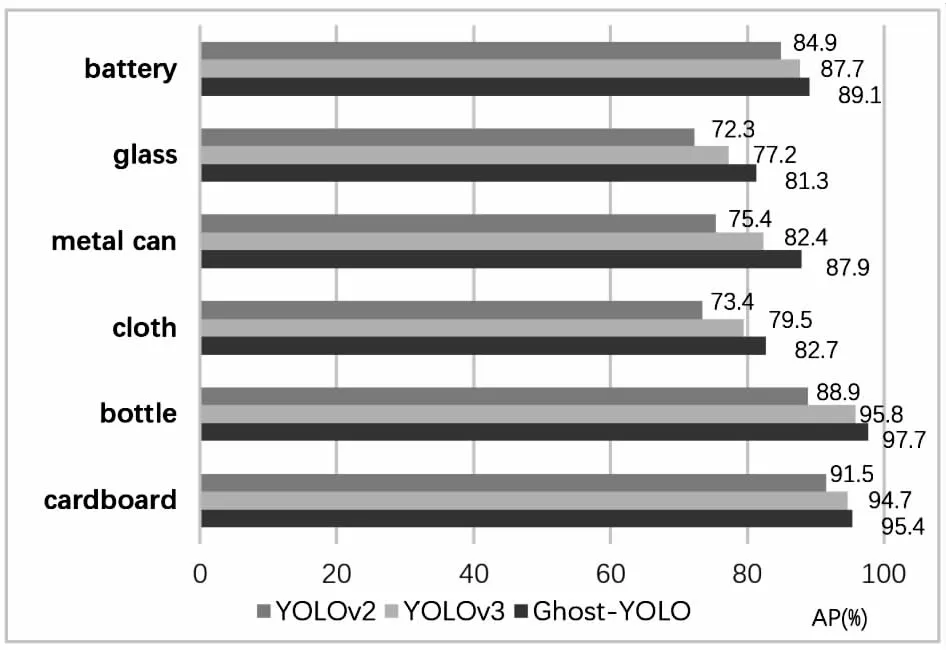
图7 不同网络模型各类别垃圾检测结果对比
图8为上述三种网络的检测效果对比,通过对特征融合层的改进,增加了底层特征信息的二次融合,使得检测层的位置信息更加丰富,改进后的网络检测框的回归更加精确。另外对小物体的检测也更加准确,YOLOv2算法对于所占像素较少的小目标检测性能较差,文中网络可以较好地检测到复杂背景下的小物体。

图8 不同网络检测效果比较
由于文中的垃圾目标检测数据集是自制的,将Ghost-YOLO算法与目前公认的目标检测算法进行网络性能的对比。
表1为YOLO系列算法与更换了不同特征提取网络以及改进YOLO层在同一训练条件下对文中Garbage数据集进行训练的结果对比。实验中各特征提取网络的权重初始化方式均为在同一垃圾分类数据集下的预训练权重。表中的网络结构MobilenetV3也是将图片resize到416×416大小。
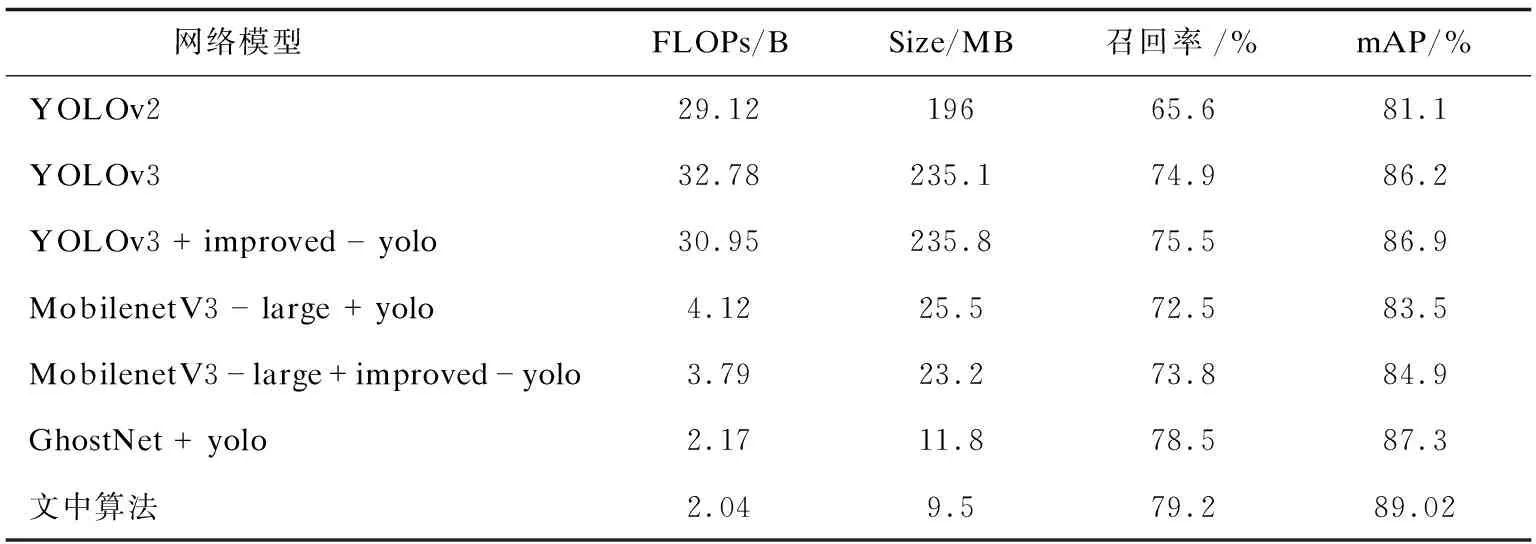
表1 不同主干网络下检测模型与改进yolo层网络结构性能对比
由表1可见,Ghost-YOLO垃圾检测算法在文中数据集上的mAP达到89.02%,高于YOLO-v3的86.20%和其他网络。召回率达到79.02%,模型大小为9.5 MB,远小于YOLOv3的235.1 MB。由于Ghost Model所使用的cheap operations,计算量仅为原YOLOv3的7.14%。同时,文中改进的improved yolo提升了1%~2%左右的mAP。
表2为同一主干网络在添加了不同策略在文中数据集上的消融实验。

表2 不同模块的性能对比实验
由表2可知,若只使用迁移学习的Ghostnet加原yolo特征融合网络,算法mAP只有82.32%。若使用迁移学习可以使网络mAP提高到87.3%。若使用improved yolo检测准确率可以提高至88.73%。将两个策略同时使用将得到89.02%的mAP。因此,提出的Ghost-yolo算法在Garbage数据集上可以在一定程度上提高算法的平均精度均值。
另外对比YOLOv3网络和Ghost-yolo网络的图片处理速度,在GPU:GTX1080Ti的硬件条件下,文中算法达到26 f/s,相比于YOLOv3的20 f/s稍快。在CPU: i7-4790的硬件条件下,文中算法达到3.2 f/s,较快于YOLOv3的2 f/s,处理速度基本可以满足实时检测的需求。
4 结束语
基于YOLOv3算法提出了一种Ghost-yolo垃圾分类目标检测算法,通过Ghost Model使得冗余特征图以更低的计算量获得,大大降低了算法的参数量并保持较高的准确率。通过改进的yolo层能够较好地增强网络对小目标物体的检测以及检测框的回归精确度,mAP达到89.02%。该结构充分利用了特征层级,使用自上而下的路径增强以及侧向连接,为垃圾目标的检测提供了更加丰富有利的特征,且网络所占用内存空间较小,计算量较小,适合在低功耗边缘设备上运行。后续工作需要进一步扩充数据集,使其能够检测更多类别的垃圾目标,并优化算法,进一步提升检测的准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
噪声与振动控制(2015年4期)2015-01-01 07:08:21
