
基于改进YOLOv3的高铁异物入侵检测算法
2022-03-16 03:36王等准莫光健谢本亮
计算机技术与发展 2022年2期
张 剑,王等准,莫光健,谢本亮*
(1.贵州大学 大数据与信息工程学院 半导体功率器件可靠性教育部工程研究中心 微纳电子与软件技术重点实验室,贵州 贵阳 550025;2.成都铁路公安局贵阳公安处,贵州 贵阳 550025)
0 引 言
高速铁路的运行速度很快,一旦在运行的过程中发生碰撞,必然导致严重的铁路事故,造成巨大的生命财产损失。针对这一问题,中国已在高铁沿线搭建了一套综合视频检测系统,通过沿线安装防护网,设置各种传感器检测装置配合沿路监控摄像头对高铁线路进行监控。这种传统的“防护网+视频监控”的方法能够较大地提升高铁行驶时的安全性,但是其主体仍是依靠人工进行监控和巡查。这种检测方式耗费了大量的人力资源且效果欠佳,不符合当前智慧交通的理念。
近年来,深度学习模型由于使用多个处理层来学习原始数据的多级抽象表示,在图像识别、语音识别等领域取得了重大进展。不少学者也将深度学习应用在铁路检测中。同时在目标检测算法方面新的算法不断涌现,如RCNN、Fast-RCNN、Faster-RCNN、YOLO、SDD等算法在检测目标时都取得了较好的效果。目标检测主要分为两类算法:两阶段检测算法,如Faster-RCNN、DCNv2、M2Det等,首先产生目标候选区域,然后对候选区域进行分类和回归。该类算法在检测速度上较慢,达不到实时检测需求;单阶段算法,如SSD、DSSD、RetinaNet、FCOS等,则是直接对目标的种类和位置进行预测,故检测速度较快,但是精度与两阶段检测算法相比较低。
为满足高铁异物检测的实时性需求,该文以单阶段检测网络中的YOLOv3网络为主网络,提出一种改进的YOLOv3网络来实现高铁线路异物的检测。首先使用可切换空洞卷积替换原YOLOv3特征提取网络中的前四个3×3卷积,SAC以不同的膨胀率对输入进行卷积,自适应选择更有效的卷积结果。其次,将Darknet-53中第二次下采样得到的特征图,与Darknet-53中第三个尺度得到的特征图上采样后的特征层进行融合,然后输入到检测层,输出尺度为104×104的预测特征层,加上原来的三个预测特征层,共输出四个尺度的预测结果。最后使用自制的数据集对不同改进的网络进行对比。
1 YOLOv3算法
YOLO(you only look once)是由Redmon等在2016年提出的一种目标检测算法。YOLO系列算法将目标检测重新定义为回归问题,检测时首先将图像划分为大小不同的网格,当物体的中心落在网格内,这个网格便负责这个物体的检测。2018年Joseph等人为改善YOLO算法中的缺陷提出YOLOv3目标检测算法。为获得更好的检测效果,其骨干网络由YOLOv2的Darknet-19替换为Darknet-53,包含53个卷积层。主要特点是在网络中添加了残差网络Residual,残差网络内部的残差块使用跳跃链接,能够有效缓解深度神经网络中由于增加深度带来的梯度消失问题。同时,Darknet-53中每一个卷积使用DarknetConv2D结构,在每次卷积时进行L2正则化,卷积完成后进行标准化和激活函数(leaky ReLU)激活。卷积、标准化和激活函数构成了YOLOv3骨干网络中的最小网络单元DBL。在特征利用方面,YOLOv3共提取三个特征层,分别位于Darknet-53中间层,中下层和底层。中间层提取的特征图感受野较小,主要负责小目标的检测。而中下层和底层得到的特征图感受野较大,主要负责大目标的检测。三个特征层在经过采样和张量拼接后最终输出13×13,26×26,52×52三种尺度的预测结果。YOLOv3网络框架如图1所示。
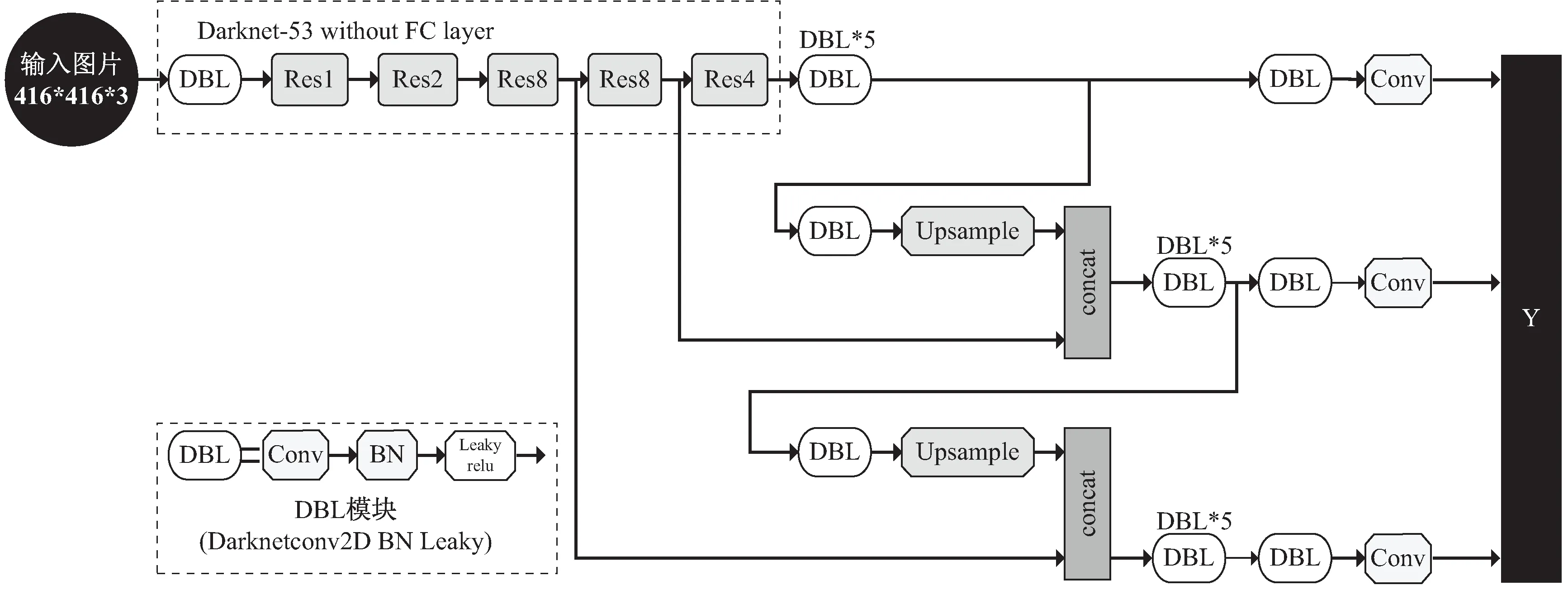
图1 YOLOv3网络模型及DBL模块
由于YOLOv3网络检测速度快,对于不同尺度的目标都能有效检测,故该文将YOLOv3网络应用于高铁异物入侵检测场景。
2 基于改进的YOLOv3的高铁异物入侵检测算法
2.1 先验框参数的优化
YOLOv3网络中,预测层分为三个特征层,对应每个特征层有大、中、小三个不同的先验框。先验框由数据集聚类而来,能够加快检测模型的收敛速度。而YOLOv3模型原始先验框是由coco数据集聚类得到,并不适合高铁异物检测数据集。因此,该文使用k-means聚类算法对高铁异物数据集进行聚类分析,重新调整先验框的宽和高。在目标检测任务中,当先验框(anchor box)与真实框(ground truth)的交并比IOU越大时,模型收敛速度越快,因此以交并比IOU为度量标准,定义下面的距离函数:
d
(box,centroid)=1-IOU(box,centroid)(1)
式中,box表示先验框的坐标,centroid表示聚类的中心点。最终得到适用于文中数据集的先验框,针对输入尺寸为416×416的图片设置宽和高[8×31,17×66,23×23,51×47,65×135,112×90,153×210,275×280]。
2.2 用SAC替换骨干网络中的3×3卷积
空洞卷积(atrous convolution)是在标准卷积中以添加空洞的方式来有效提高卷积的感受野,DR(dilation rate)膨胀率是控制空洞卷积中空洞数量的超参数。但是特征图中不同的位置可能需要不同的DR从而获得合适感受野来完成检测任务,可切换空洞卷积,通过训练一个转换函数,自适应输出具有合适感受野的卷积结果,从而提升检测精度。SAC结构如图2所示。
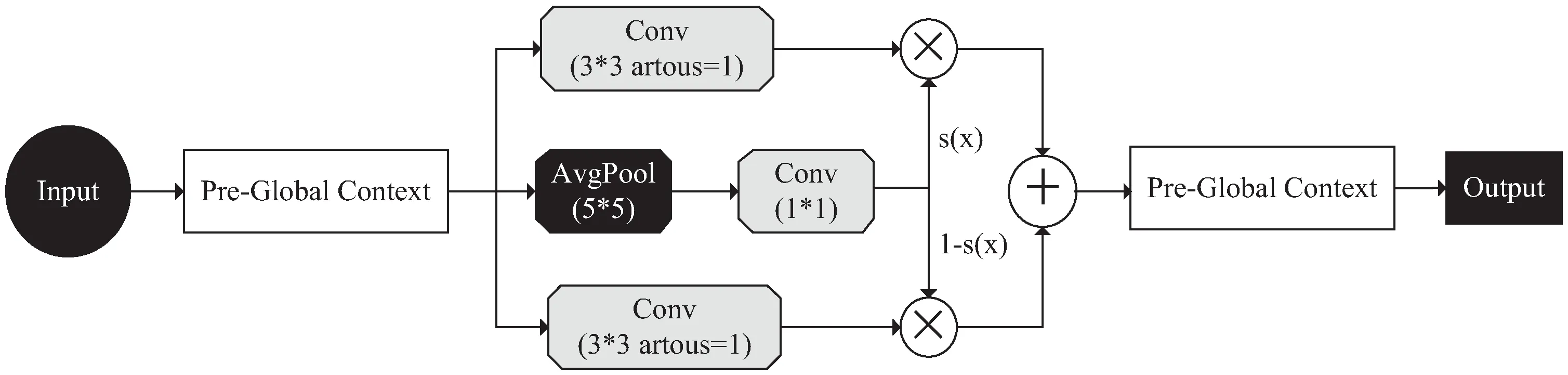
图2 可切换卷积SAC
SAC由上下文全局模块和核心SAC组件组成,将输入定义为x
,输出定义为y
,SAC运算表示为: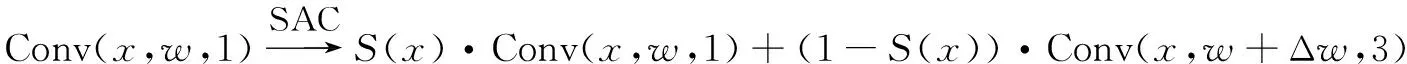
(2)
其中,Δw
为可训练的权重,S
(x
)为转换函数,由一个5×5内核的平均池化层和一个1×1的卷积组成。输入x
首先通过全局平均池化,再送到SAC中进行DR分别为1和3的空洞卷积,并与转换函数相乘,最后再经过一个全局平均池化进行输出。该文采用SAC来替代YOLOv3骨干网络中前四个3×3卷积,通过对转换函数进行训练,SAC能够输出特征图不同位置自适应的空洞卷积结果,特征图每个位置都获得了合适的感受野,从而有效提升了检测模型的性能。2.3 改进的YOLOv3网络结构
文中高铁异物检测数据集由高铁路线沿路高清摄像头拍摄视频得来,包含行人、车辆和动物多种小目标。为充分利用YOLOv3骨干网络中浅层所包含的小目标信息,提升对小目标检测的精度,将Darknet-53中第二次下采样得到的特征图,与Darknet-53中第三个尺度得到的特征图上采样后的特征层进行融合,输出第四个尺度为104×104的预测特征层。
原YOLOv3网络中输出大、中、小三个预测特征层,其尺寸分别为13×13,26×26,52×52,其中52×52的特征层用来预测图片中的小目标。YOLOv3模型输入图片尺寸为416×416,当图片划分为52×52个网格时,每个网格单元的尺寸为8×8。而高铁沿路摄像头往往高架于铁路两边的高杆上,当有行人、动物和车辆侵入高铁线路时,拍摄于摄像头内往往尺寸小于8×8。同时浅层骨干网络中由于没有经过更多的下采样,往往包含很多未被利用的小目标信息,于是利用Darknet-53中第二次下采样得到的特征图,与原52×52尺度的特征图进行融合,输出尺寸104×104尺度的预测特征层。此特征层包含更多小目标信息,对小目标有更好的检测效果。改进后的YOLOv3网络结构如图3所示。
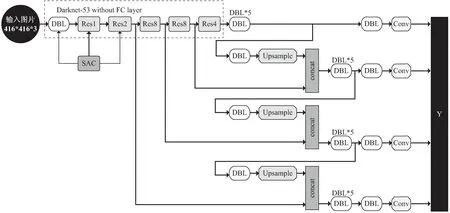
图3 改进YOLOv3网络模型
3 实验设计及结果分析
为验证提出的改进YOLOv3高铁异物入侵检测算法的正确性与有效性,利用自制的高铁异物检测数据集进行两个实验,一是对不同改进策略的YOLOv3算法进行对比;二是使用其他目标检测算法与文中改进算法进行对比。
3.1 实验平台
算法于深度学习服务器上进行训练和测试,训练和测试环境见表1。

表1 网络模型训练与测试环境
3.2 高铁异物检测数据集
为保证改进YOLOv3高铁异物入侵检测算法的有效性,利用贵阳高铁监控视频为素材,使用Labelimg标注工具按照YOLO网络所需格式进行标注,得到2 774张异物入侵检测图片。由于高铁异物侵限视频资料较少,于是挑选UA-DETRAC,Animals-10数据集中的合适图片对数据集进行补充,其中Animals-10数据集1 500张,UA-DETRAC数据集800张,最终获得的数据集包含人、车、火车、狗、牛、羊,共5 074张图片,其中3 552张图片用于训练,1 522张图片用于测试。
3.3 模型训练及评价标准
对不同改进策略的YOLOv3算法及其他目标检测算法,均使用相同的训练设置进行训练。设置初始学习率为0.001,batch_size为8,迭代次数最大为300 epoch。当迭代次数达到75 epoch,150 epoch,225 epoch时衰减为上一学习率的十分之一。训练过程中采用翻转、平移变化等方法对输入图片进行数据增强。
目标检测中通常使用每秒检测帧数(FPS)、平均检测精度(mAP)作为评价标准。其中mAP的计算需要计算精确度(precision)和召回率(recall),利用这两个参数构建准确率-召回率曲线,从而计算出mAP,mAP越大表示整体检测精度越高。精确度与召回率的计算公式分别为:
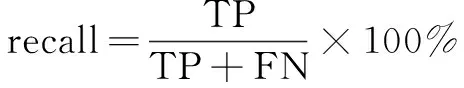
(3)
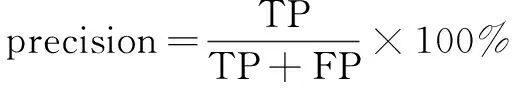
(4)
式中,TP为检测网络分类正确的正样本,FP为分类错误的正样本,FN为分类错误的负样本。
3.4 实验结果与分析
3.4.1 改进YOLOv3网络对比实验
分别对使用SAC替换骨干网络中前四个3×3卷积的YOLOv3网络(命名YOLOv3-1),改进FPN结构的YOLOv3网络(YOLOv3-2),及同时加入以上两个改进的YOLOv3网络(YOLOv3-3),在图片尺寸416×416的高铁异物检测数据集上进行训练和测试,与YOLOv3原网络训练结果进行对比,实验结果如表2所示。
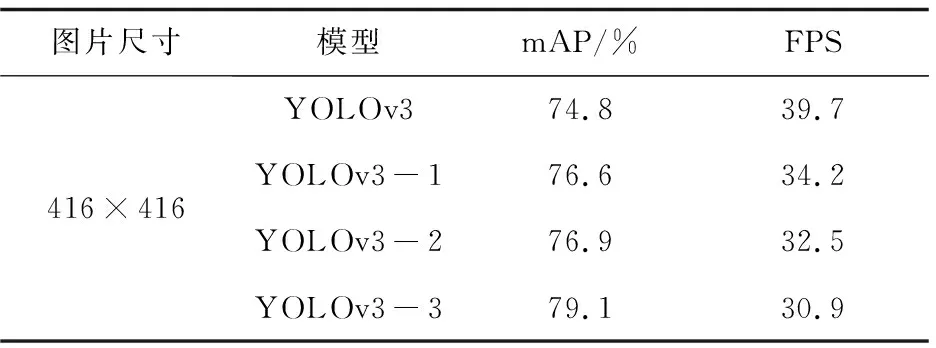
表2 改进YOLOv3和YOLOv3检测结果
如表2所示,改进的YOLOv3网络相比于原YOLOv3网络提升了检测效果。其中YOLOv3-1网络相比于未改进的YOLOv3网络mAP有所提升,表明通过将可切换空洞卷积替换原骨干网络中的前四个3×3卷积能够有效地提升卷积时的感受野,从而提高检测精度。而YOLOv3-2网络相比于原YOLOv3网络mAP提升更多,表明改进的FPN结构由于融合了来自浅层网络生成的特征层,获得了更多的小目标信息,通过对这些信息的利用,使得网络对小目标的检测精度有所提升。最后,加入两种改进的YOLOv3-3网络平均检测精度达到79.1%,相较于原YOLOv3网络mAP增加了4.3%。同时可以看到,三种改进网络的FPS相较于原YOLOv3网络都有所下降,分别下降5.5 FPS,7.2 FPS和8.8 FPS。这是由于改进网络在原网络上添加了额外的参数,从而导致检测速度的下降,但是达到最高精度的YOLOv3-3网络仍有30.9 FPS的检测速度,能够满足实时性的需求。
3.4.2 不同尺度检测结果分析
为进一步体现改进YOLOv3网络中可切换空洞卷积SAC和改进FPN结构在提升检测精度中的作用,挑选大、中、小三种尺度目标train、car、person的AP值进行对比分析,如图4所示。

图4 不同尺度目标检测精度对比
其中A代表未改进的YOLOv3网络,而B、C、D分别代表YOLOv3-1网络、YOLOv3-2网络和YOLOv3-3网络。通过对比可以看出,B网络相较于A网络在train和car上的检测精度均有提升,表明SAC由于能够自适应扩大卷积的感受野,可提高网络对大、中型目标的检测精度。C网络与A网络相比,三种尺度目标的检测精度均有提升,对小尺度目标person尤为明显,AP值增加了14%。表明改进FPN结构的YOLOV3网络更能够利用网络中的小目标信息,极大地提升对小目标的检测效果。而最后加入两种改进的D网络相比于A网络,对大、中、小三种尺度的目标检测精度均有较大提升,证明了改进YOLOv3的高铁异物检测网络的有效性。
3.4.3 改进YOLOv3算法与其他算法对比
为验证改进YOLOv3算法的有效性,在相同的实验环境下利用高铁异物检测数据集对DSSD、Faster-RCNN、RetinaNet和CornerNet四种目标检测算法进行训练、测试。实验结果对比如表3所示。
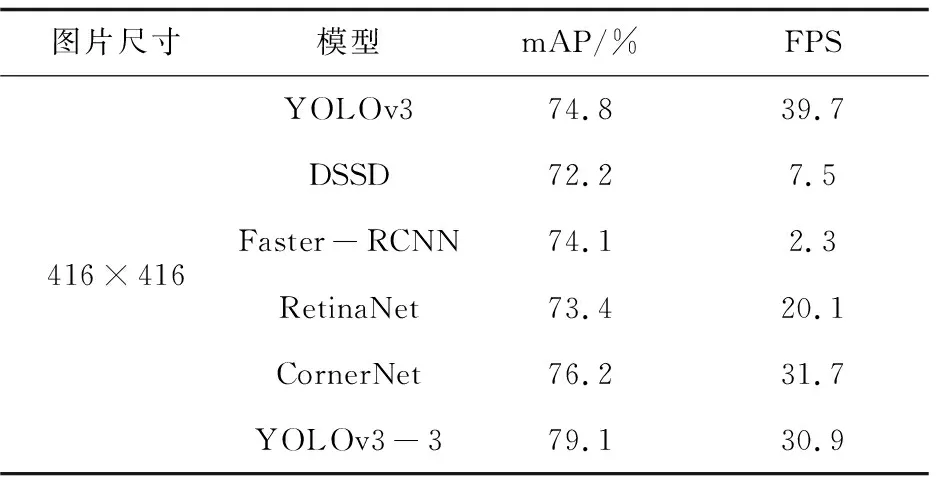
表3 不同算法检测结果对比
由表3可知,在检测精度方面,提出的改进YOLOv3高铁异物检测网络模型最高为79.1%。而在检测速度方面,与其他目标检测网络相比,YOLOv3-3网络同样有优秀的表现。综上所述,改进YOLOv3高铁异物检测网络模型拥有更好的检测精度,虽然检测速度相对原YOLOv3网络有所降低,但是仍达到了30.9 FPS,可以满足实时性检测的需求。
3.4.4 图片检测结果
从数据集中随机抽取一张图片验证改进YOLOv3高铁异物检测网络的有效性,检测效果如图5所示。

图5 改进YOLOv3网络检测效果
图5中(a)、(b)、(c)、(d)分别表示原YOLOv3网络、YOLOv3-1网络、YOLOv3-2网络及YOLOv3-3网络对同一输入图片的检测结果。其中图5(a)中误将右下角的目标train识别为目标dog。图5(b)相较于图5(a),三个大目标train的种类预测及位置预测都更为准确,但是对于小目标person的位置预测却有偏差,体现了SAC增大卷积感受野从而提升检测性能。图5(c)中对小目标person的检测精度较图5(a)更准确,表明改进FPN提升了对小目标的检测性能。图5(d)中对四种目标的种类及位置都预测很准确,证明了改进YOLOv3高铁异物检测网络模型的正确性和有效性。
4 结束语
该文提出一种基于YOLOv3网络的改进高铁异物入侵检测算法,利用可切换空洞卷积替换骨干网络中的前四个3×3卷积,自适应增加卷积的感受野,提高了对中、大型目标的检测精度。同时改进FPN结构,利用浅网络层中的小目标信息,融合输出尺度为104×104的小尺度预测,提高了小目标的检测精度。改进YOLOv3高铁异物检测网络在满足实时性检测的要求下,平均检测精度有较大提升,如何提升检测速度将是后续研究的方向。同时高铁异物侵限相关数据缺乏也阻碍了高铁异物入侵检测的发展,加快相关数据集的建立,也将有效提升目标检测算法对于高铁异物入侵的检测效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2021年6期)2021-08-18
上海师范大学学报·自然科学版(2019年5期)2019-12-13
文萃报·周二版(2018年22期)2018-09-18
中国新通信(2017年9期)2017-05-27
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
中华急诊医学杂志(2006年10期)2006-10-24
