
基于深度可分离卷积的卫星影像检测技术研究
2022-03-15 09:45张曼,叶曦,李杰,沈霁
计算机仿真 2022年2期
张 曼,叶 曦,李 杰,沈 霁
(上海航天电子技术研究所,上海 201109)
1 引言
卫星影像中目标自动检测是遥感图像智能分析领域的重要研究方向[1],它要求对包含多目标卫星影像自动定位标记,并判别该目标所属类别,对船只、飞机、油罐等军事目标信息采集具有重要作用[2]。
传统卫星影像目标检测算法主要利用滑动窗口搜索策略切割整幅遥感图像,然后依据目标固有特征(如几何、纹理、颜色等)定位标记[3-5]。这种方法无法同时对多种类别目标同时定位区分,且易受光照、拍摄角度等外界环境变化,鲁棒性差。自2012年AlexNet[6]在ImageNet竞赛[7]上大获成功,卷积神经网络技术在目标检测领域获得广泛应用。2014年Ross B.Girshick提出RCNN[8]算法,检测图像通过选择性搜索法(selective search)[9]进行图像分块,分割后的候选区域通过多层卷积网络提取特征,最后进行分类与位置回归。该算法中候选区域的大量重合导致运算速度低,检测过程中需保存大量特征信息,内存消耗大。针对这一情况,Ross B.Girshick一年后提出了Fast-RCNN[10]算法,算法通过对整张图像卷积得到特征图像,利用分类与边框回归结合的多任务损失函数迭代优化,由于候选区域提取同样依赖selective search方法,检测速度较慢。2015年提出的Faster-RCNN[11]算法舍弃以往候选区域提取策略,候选区域由可训练优化的RPN网络提取,有效减少候选区域数量,提高了检测效率。由此可见,基于区域建议框的R-CNN系列算法检测过程主要分为两步:第一步提取候选区域,第二步检测分类,具有网络结构复杂、检测效率低、工程实现困难等缺陷。2016年,端对端检测策略的YOLO[12]被提出,该算法将目标定位检测问题转化为回归问题处理,通过一个卷积神经网络直接所有候选区域进行回归,对其预测相应的类别的概率,解决候选区域重叠问题,实现实时目标检测。2017年提出YOLO-V2[13]算法,在YOLO的基础上进行多方面改进,进一步提高定位精度。Tiny-Yolo-V2为YOLO-V2算法的简化版本,通过减少卷积层数,提高检测效率,便于工程实现。
在航天对地观测领域,卫星影像分辨率随技术的发展不断提升,地物目标信息的也逐渐丰富,采用深度学习技术进行目标检测成为研究趋势。端对端类型的Tiny-Yolo-V2算法通在保证一定检测精度的情况下,具有模型规模小、检测效率高的优势,节约了计算资源,便于硬件部署。本文提出的基于深度可分离卷积神经网络卫星影像检测算法基于Tiny-Yolo-V2算法进行优化,利用深度可分离卷积方法优化Tiny-Yolo-V2卷积层,减小算法计算量,提高检测效率,同时针对卫星影像地物目标大小差异较大问题,结合特征金字塔(FPN)[14]思想,利用多种尺度特征图融合技术,提高目标检测精度。
2 深度可分离卷积
卷积层的主要作用是特征提取。标准卷积将输入特征图通过卷积核卷积过程中,需要同时学习空间特征与通道特征,而于2017年Andrew G.Howard提出的深度可分离卷积[15]通过将卷积层空间相关性与通道相关性解藕,在标准卷积过程中添加一层过渡层,将其分解为深度卷积(depthwise convolution)与逐点卷积(pointwise convolution),分别考虑空间相关性与通道相关性。相对标准卷积,深度可分离卷积可以在保证精度损失不多情况下,大幅降低参数量与计算量[16]。
假设输入为DF×DF×M的特征图,与DK×DK×M×N大小的卷积核卷积,标准卷积操作过程如图1所示,每张输入特征图分别与N类中M个DK×DK卷积核卷积后求和加上偏置得到一个输出,最后输出为DF×DF×N大小。深度可分离操作过程如图2所示,图2(a)为深度卷积过程,图2(b)为逐点卷积过程。深度卷积时,每张输入特征图只与对应卷积核卷积加偏置,输出大小为DF×DF×M。逐点卷积时,DF×DF×M的特征图与N个1×1的卷积核做标准卷积,改变通道个数,最后输出特征图大小为DF×DF×N。
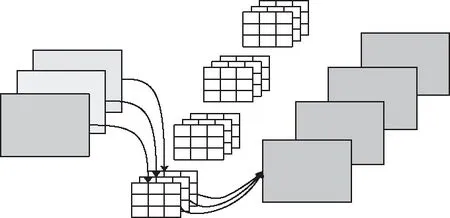
图1 标准卷积操作示意图
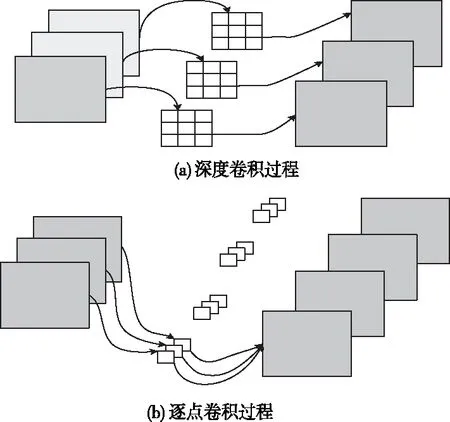
图2 深度可分离卷积操作示意图
标准卷积卷积过程计算量如下式所示
DF×DF×M×N×DK×DK
(1)
深度可分离卷积中,深度卷积过程计算量如下式所示
DF×DF×M×DK×DK
(2)
逐点卷积过程计算量如下式所示
DF×DF×M×N
(3)
深度可分离卷积相当于标准卷积的n倍,n的表达式如下所示
(4)
3 基于深度可分离卷积的卫星影像检测算法
3.1 基于特征金字塔的目标检测网络结构
深度学习算法Tiny-Yolo-V2是一种端到端的目标检测算法,算法的网络结构简单,参数量少,工程化实现相对容易,本论文选择此算法为基础算法进行优化。Tiny-Yolo-V2算法具体网络结构参数如表1所示,包括9个卷积层和6个池化层。卷积层使用3×3大小的卷积核操作,最后1层卷积层卷积核大小为1×1,池化层为最大池化方式,池化大小为2×2,步长为2。每次池化操作相当于做一次下采样,特征图缩小1倍。前12层,卷积层后做池化操作,池化后,卷积层卷积核个数扩增1倍,卷积层提取特征,池化层做特征压缩。除最后1层卷积层外,每层卷积层引入BatchNormal算法稳定训练过程,加快收敛。
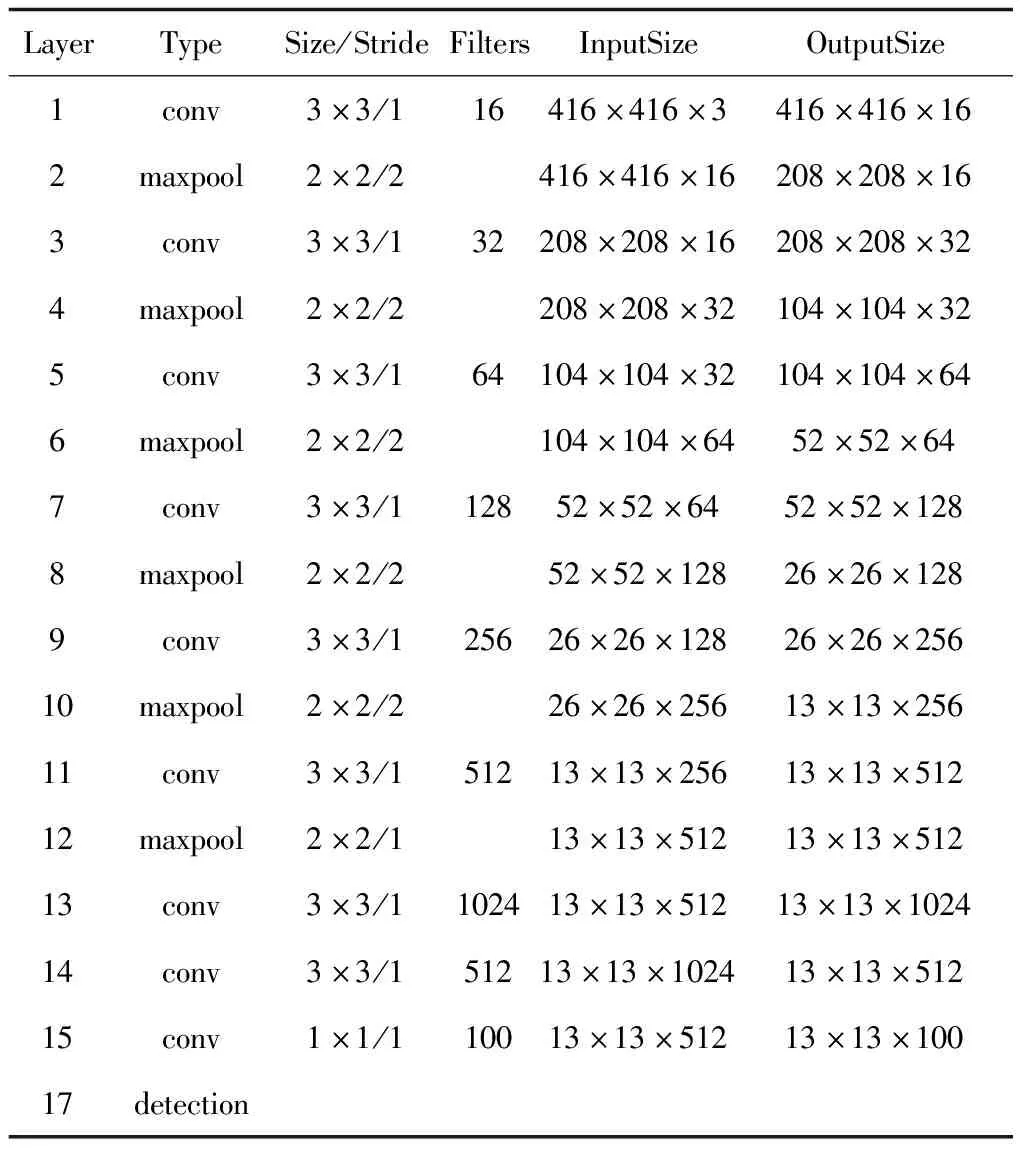
表1 Tiny-Yolo-V2算法网络结构参数
卫星影像中地物信息丰富,能同时存在车辆、飞机、港口等差异较大的地物目标,单一尺度的目标检测算法无法很好地对不同类别不同大小的目标进行预测,本文希望通过添加一个维度的尺度特征图预测,改善这一问题。在深度学习领域,增加预测尺度方式有多种,本论文结合特征金字塔(FPN)结构进行优化。
在目标检测算法中,由于池化层进行了特征压缩,网络中不同卷积层输出特征图尺寸不同。浅层输出的特征图尺寸更大,保留更多的细节信息,更有利于目标位置信息的预测,同时由于经过的卷积层数少,提取的信息不够精炼,不利于进行目标类别的预测。深层的特征图尺寸小,在多次卷积后,特征图提取的信息更加抽象,进行目标分类准确度更高,相对地,多次卷积池化信息提炼过程中丢失了很多细节信息,易出现目标位置信息预测不精准现象。特征金字塔结构将深层特征与浅层特征结合,提高目标检测算法预测的类别正确率和定位准确度。
改进算法是基于Tiny-Yolo-V2算法进行优化实现的,记为FD-Tiny-Yolo-V2算法,在原有13×13大小的预测尺度上,增加26×26大小的预测尺度,提高小目标、多目标的检测精度。FD-Tiny-Yolo-V2算法网络结构如图3所示,包括7个卷积层、5个深度可分离卷积层、6个池化层、1个上采样层和1个特征融合层。输入图像尺寸为3通道416×416的卫星影像,经过4个卷积层与4个池化层特征提取与压缩后,得到128维26×26大小特诊图。得到的特征度经历两种操作最后得到不同尺度的预测信息。26×26大小特诊图通过图中上通道一系列卷积层、深度卷积层和池化层作用,最后得到的特征图大小为13×13,是第一种预测尺度。输入图像经过5个卷积层、5个池化层与2个深度可分离卷积层操作后,得到256维13×13大小特征图,这256维13×13大小特征图包含高维特征信息,上采样后与上述128维26×26大小特征图相融合,得到的384维26×26大小特征图,经过卷积层操作后得到特征图大小为26×26,是第二种预测尺度。FD-Tiny-Yolo-V2将高语义信息的深层特征与高细节信息的浅层特征相互融合的方式,课得到多种尺度的信息,提高目标检测的定位精度于类别预测正确率。卷积层操作如图3中模块1所示,包括标准卷积、批量归一化(BN)和非线性变换三种操作,深度可分离卷积层包括3×3深度卷积、BN、非线性变换、1×1标准卷积、BN和非线性变换六种操作。

图3 FD-Tiny-Yolo-V2算的的多尺度网络结构
FD-Tiny-Yolo-V2算法最后做两种尺度预测,分别为13×13和26×26。假设每个珊格预测B个框,训练图像包含C个类别,最后特征图输出结果为
S×S×B×(5+C)
(5)
此处,5表示每个预测边框的坐标信息(边框中心点坐标与边框长宽共4个值)加预测表框置信度信息。这里选择的数据集包括15个类别,根据K-means[17]聚类算法可知,当一个珊格预测5个边框时。因此,最后两种特诊图输出为13×13×100与26×26×100大小。
3.2 算法训练框架
卫星影像开源数据量少,宽幅影像无法直接用于深度学习目标检测算法处理,因此,训练前需进行数据集増广与切块操作。如图4所示为FD-Tiny-Yolo-V2算法训练框架,具体分为三步,第一步増广数据集,第二步进行数据集切块,第三步开展模型训练工作。数据集増广时,采用旋转、颜色抖动、模糊处理及缩放操作扩充卫星影像与对应标签。数据集切块时,利用滑动窗口将大小不一的卫星影像切块处理,对应标签随之变化,切块后剔除不包含目标信息的图像切块与标签。网络模型训练过程中,将训练图像分批次输入FD-Tiny-Yolo-V2网络模型中,将模型输出的预测值与实际标签比较,利用二值的误差值优化模型参数,多次迭代后,保存网络模型。训练过程中,误差为预测坐标误差、预测类别误差与预测置信度误差之和,具体计算公式如下式所示
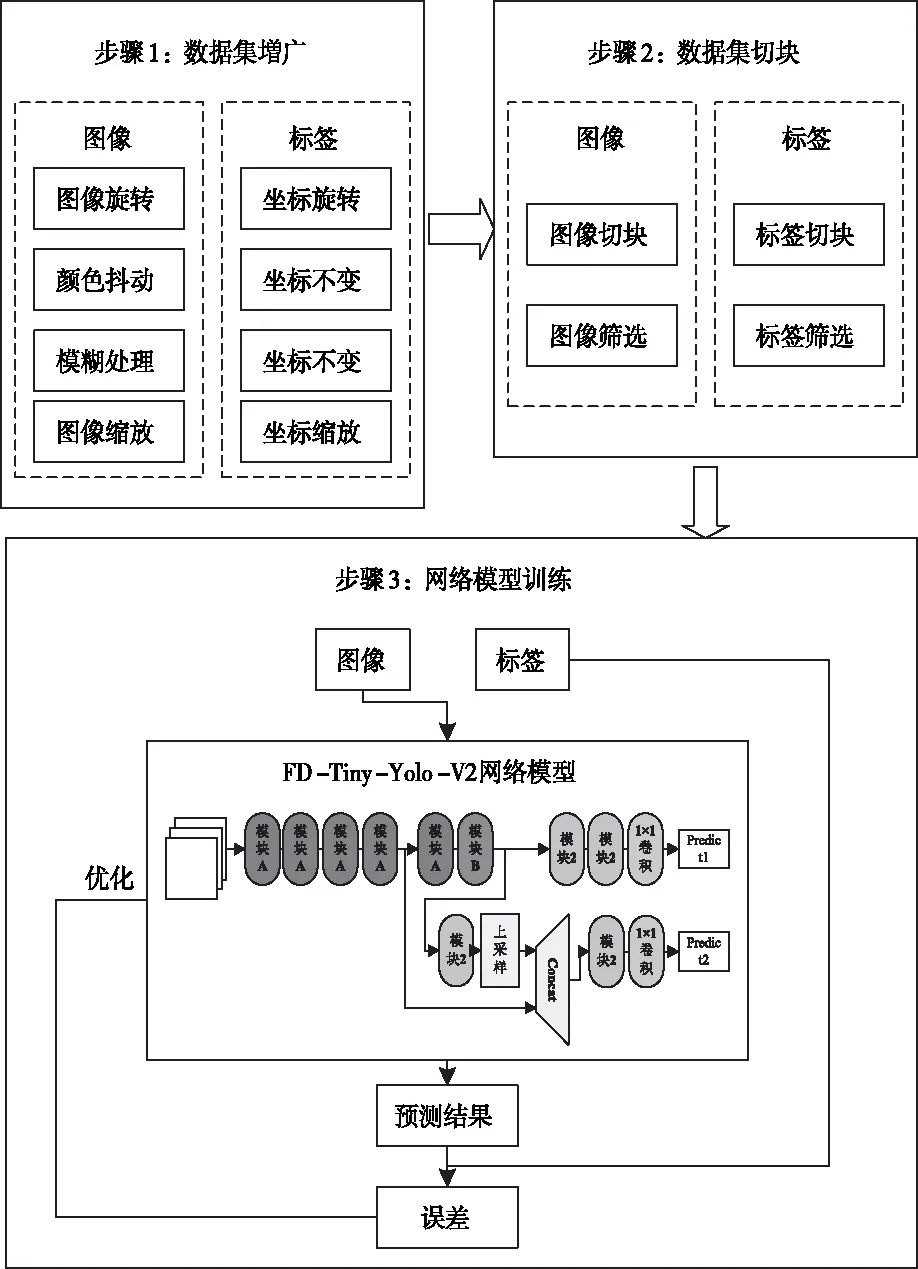
图4 算法训练框架
(6)
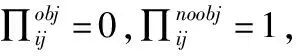
4 实验结果与分析
4.1 数据集及评价指标
本文实验采用DOTA[18]作为实验的数据集。卫星影像数据集DOTA是由武汉大学和华中科技大学联合团队标注完成的,共标注了包含飞机、船只、小轿车、油罐等在内的15种目标类别,图像大部分来自谷歌地球。DOTA数据集中尺寸不一的宽幅卫星影像数据集经过滑动窗口切块与数据集増广操作后,得到160000张图像切块,做训练测试使用的数据集,具体数据集示例如图5所示。

图5 数据集示例
本文选择精准率、召回率和平均精准率(Average Precision,AP)为目标检测算法评价指标。精准率为预测正确边框数量与所有预测边框数量之比,召回率为预测正确边框数量与标注为该类别边框数量之比,AP值为精确率随召回率变化曲线在从0到1上的积分。精准率、召回率与AP值越大,代表检测效果越好。
4.2 实验平台与参数设置
实验由CPU为i8、内存为32G、GPU为2片NVIDIA的1080Ti 的台式计算机完成。程序设计平台为Visual Studio2015,操作系统为ubuntu16.0.4。
训练时,最大迭代次数为50020次,每次训练8个批次,每个批次训练32张图片,初始学习率为0.0001。训练时IOU阈值为0.3,测试时IOU阈值为0.5。
4.3 实验结果分析
本文算法是基于Tiny-Yolo-V2进行优化改进的,表2为两种算法性能评估结果表。可以发现,大体来说,FD-Tiny-Yolo-V2算法在精准率、召回率与AP值上优于Tiny-Yolo-V2算法。对于篮球场、田径场、足球场、游泳池等中型、大型目标,两种算法精准率、召回率与AP值差别不大;对于小汽车、桥梁等小型目标来说,本文提出的FD-Tiny-Yolo-V2算法目标检测评估结果更好。说明FD-Tiny-Yolo-V2算法通过增加预测尺度,达到了提高小目标检测的精准率效果,验证了结合特征金字塔优化Tiny-Yolo-V2方案的有效性。
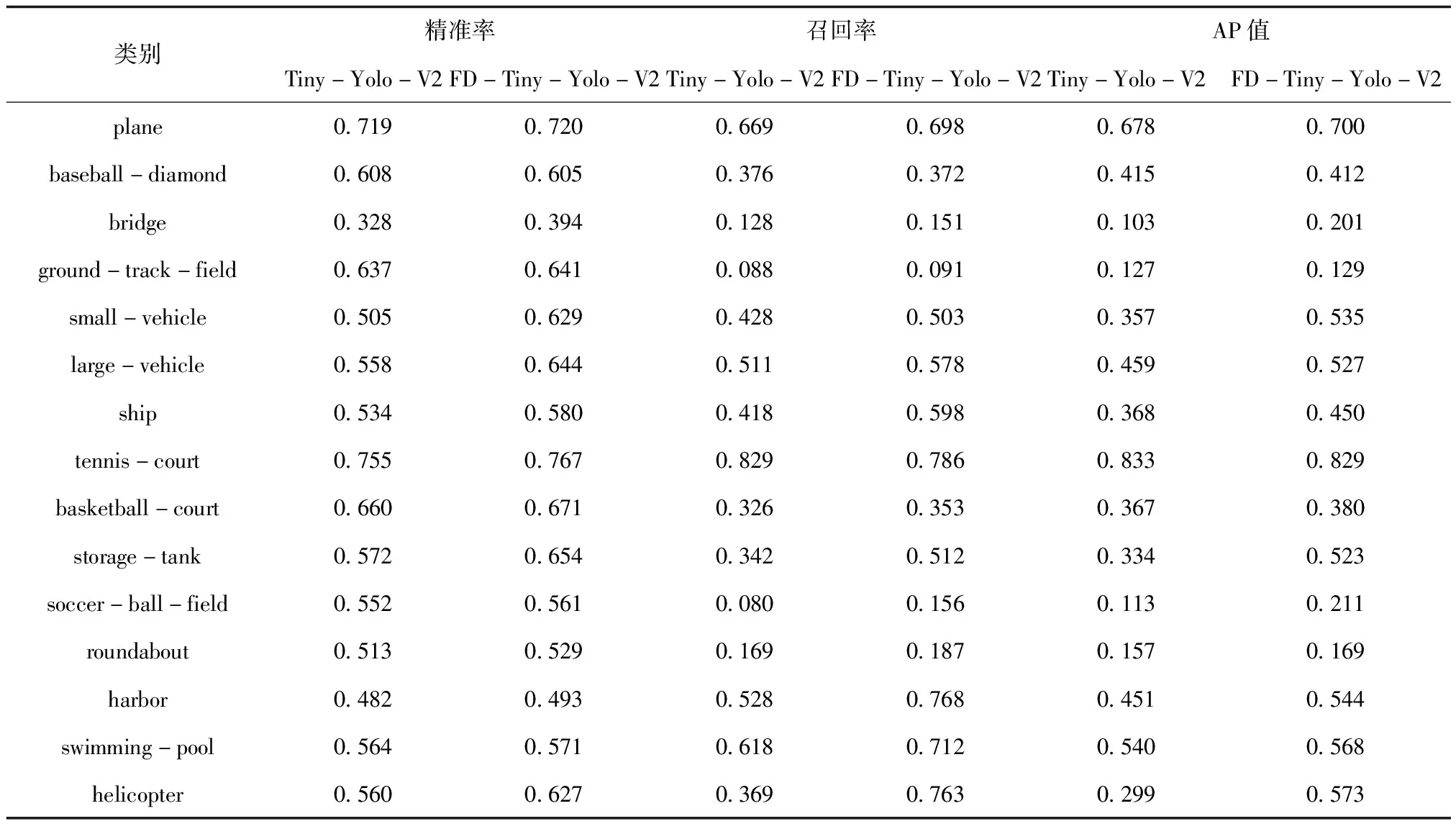
表2 目标检测算法性能评估结果
表3为YOLO-V1、YOLO-V2、Tiny-Yolo-V2与本文提出的FD-Tiny-Yolo-V2四种不同目标检测算法性能对比表,mAP为AP的平均值。可以发现,本文提出的FD-Tiny-Yolo-V2算法mAP值为0.427,比Tiny-Yolo-V2算法高了0.084,排四种算法的第三位置。FD-Tiny-Yolo-V2算法在检测时间与参数量方面表现更好,一张图像切块仅需1.44ms,参数量为21.5M,排四种算法中第一位置。验证了结合深度可分离卷积优化检测算法方案的有效性。本文提出算法工程化实现更容易。
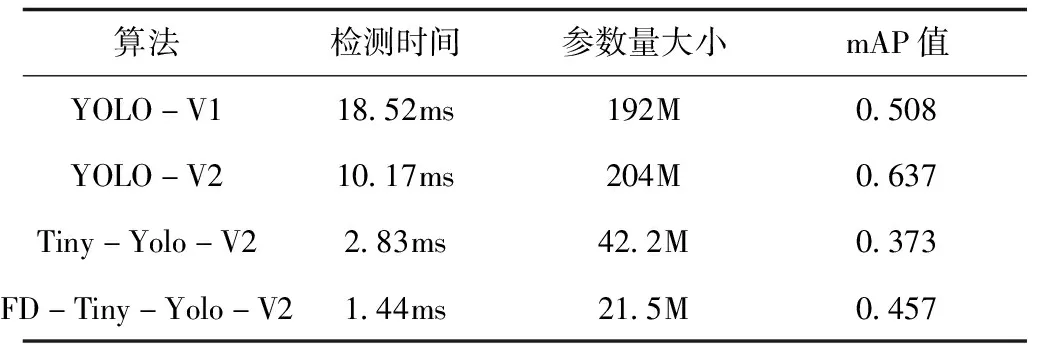
表3 目标检测算法检测性能对比
图6为FD-Tiny-Yolo-V2算法在宽幅卫星影像上的检测结果。图6(a)图像主要为飞机目标,图6(b)图像主要为车辆目标。可以发现FD-Tiny-Yolo-V2算法在不同卫星影像种,目标基本检出,检测效果良好。

图6 宽幅卫星影像检测结果
图7为Tiny-Yolo-V2和FD-Tiny-Yolo-V2两种算法在同一张宽幅卫星影像上的检测结果。上幅为Tiny-Yolo-V2算法目标检测结果,下幅为FD-Tiny-Yolo-V2检测结果,右边图像为图中边框内细节放大图。可以发现,Tiny-Yolo-V2算法小型目标更容易漏检,FD-Tiny-Yolo-V2算法目标基本检出。如图中所示车辆目标中FD-Tiny-Yolo-V2算法检测效果更好。

图7 图像切块检测结果
5 结束语
本文提出一种基于Tiny-Yolo-V2的优化算法用于卫星影像目标的自动定位与检测。针对Tiny-Yolo-V2算法目标检测精准度低问题,本文提出的FD-Tiny-Yolo-V2算法结合特征金字塔概念,在单一13×13预测尺度基础上增加了26×26尺度进行预测,融合深层语义特征与浅层细节特征,提高目标检测精度。同时,利用深度可分离卷积思想,优化标准卷积层,减小模型参数量,提升算法检测效率。在卫星影像数据集DOTA上验证了两种优化策略的有效性。相对Tiny-Yolo-V2算法,mAP值提高了0.084,模型参数量减小了49%,检测效率提高了48%。下一步将探究深度学习模型量化、剪纸等优化方法,进一步提升算法检测效率,为工程化部署做铺垫。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
科学家(2019年3期)2019-08-18
福建基础教育研究(2019年6期)2019-05-28
科学与财富(2016年28期)2016-10-14
新东方英语(2014年1期)2014-01-07
棋艺(2001年21期)2001-01-06
