
进化算法优化GBDT的带钢卷取温度预测
2022-03-14 08:58:40皮理想崔桂梅
华南师范大学学报(自然科学版) 2022年1期
皮理想, 崔桂梅
(内蒙古科技大学信息工程学院, 包头 014010)
热轧后带钢的冷却控制是热轧生产的重要环节,层流冷却过程温度和卷取温度的控制精度将直接影响带钢的组织性能和力学性能,同时也是带钢能否顺利卷取、安全下线的决定因素[1-2]。热轧带钢卷取温度预报是带钢质量控制的重要基础,准确的温度预报模型为卷取温度的前馈补偿控制提供可靠的参考数据,对提高卷取温度的控制精度具有重要意义[3]。
目前的层流冷却控制系统主要通过经典数学模型对卷取温度进行预测,但是冷却过程是一个非常复杂的时变非线性过程,在目标卷取温度允许公差范围内,机理预测模型的命中率往往并不理想。随着人工智能技术的发展,有学者将BP神经网络应用于卷取温度方面,以提高其预测精度,如:马丽坤等[4]利用BP神经网络预测数学模型中的综合换热因子,大幅提高了卷取温度的预测精度;石孝武和申群太[5]将遗传算法与BP神经网络相结合,建立了遗传神经网络卷取温度预测模型,具有较好的应用前景;郭强等[6]建立人工鱼群神经网络预测模型,利用鱼群算法训练BP网络权值,建立了人工鱼群神经网络预测模型,具有较强的自适应能力。然而,基于BP神经网络建立的预测模型虽然取得了较好的预测精度,但由于BP神经网络自身结构的局限性,导致在有限的训练样本下泛化性能较差,容易陷入局部最优,限制了BP神经网络模型在卷取温度方面的应用。
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)作为集成学习[7]中一个的重要算法,具有防止过拟合和泛化能力较强等优点,在回归预测方面具有广泛应用。如:王伟等[8]利用GBDT对热镀锌刚力学性能预报,模型具有较高的预测精度;谷云东等[9]将梯度提升决策树应用于电力负荷预测,其预测误差明显低于传统神经网络的。 针对B钢厂层流冷却系统卷取温度预报精度低且人工调参过程具有经验性和不确定性的问题,本文探索将集成学习中的梯度提升决策树算法应用于带钢卷取温度预测,利用差分进化(Differential Evolution,DE)算法的全局寻优能力获取模型最优参数,建立基于差分进化优化梯度提升决策树的卷取温度预测模型(DE-GBDT)。同时,与3个基础预测模型(梯度提升决策树(GBDT)[10]、支持向量机(SVM)[11]、小波神经网络(WNN)[12])以及差分进化优化后的支持向量机(DE-SVM)、小波神经网络(DE-WNN)预测模型进行对比实验,以验证DE-GBDT预测模型的有效性,拟为前馈补偿控制提供准确的参考数据,为进一步提高卷取温度的控制精度提供新方法。
1 DE-GBDT预测模型
1.1 数据的标准化处理
根据钢厂实际历史生产数据,通过对带钢层流冷却段的生产工艺特点和历史数据分析,确定以下生产过程中的关键因素作为模型训练的数据特征:目标卷取温度、终轧温度、带钢厚度、带钢速度、冷却水温度和实测卷取温度。由于上述不同特征量纲差别较大,如带钢厚度为2~6 mm,而带钢温度区间为600~800 ℃,需根据下式对数据进行标准化处理,以消除量纲:
(1)
其中,z为标准化后的数据,x为原始数据,μ为样本均值,σ为样本标准差。经数据标准化处理后,可以提高模型精度及收敛速度。
1.2 GBDT预测模型的建模过程
GBDT 是以分类回归树(Classification and Regression Tree,CART)为基模型的集成学习算法,该算法基于Boosting 迭代的思想,利用原始训练集获取第一棵决策树,此后每一轮迭代中的目标都是拟合上一轮弱学习器的残差。GBDT建模过程以当前学习器的损失函数最小为目标,损失函数选用平方损失函数,通过多次迭代以减小训练残差,最后将所有训练好的回归树的结果进行求和,从而获得最终的预测结果[13-15]。本文将带钢目标卷取温度、冷却水温度以及带钢在精轧出口实时的厚度、速度、温度等条件属性作为GBDT预测模型的输入特征,将带钢实测卷取温度作为输出特征:输入为训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi(xiX⊆n)为影响带钢实测卷取温度的条件属性,X为输入样本空间;yi(yiY⊆)为带钢实测卷取温度,Y为输出样本空间;损失函数为L(yi,f(xi)),输出为回归树fM(xi)。GBDT预测模型的建模过程如下:
(1)初始化:估计使损失函数极小化的常数值c,f0(x)是只有1个根节点的树:
(2)
(2)对建立的M棵回归树:
① 对i=1,2,…,N,计算第m(m=1,2,…,M)棵树对应的损失函数的负梯度,即伪残差:
(3)
② 利用CART回归时拟合数据(xi,rmi),从而得到第m棵回归树,其对应叶子节点区域为Rmj,其中j=1,2,…,J,J为第m(m=1,2,…,M)棵回归树叶子节点的个数;
③ 对于j(j=1,2,…,J)个叶子节点区域,计算最佳拟合值:
(4)
④ 更新学习器fm(x):
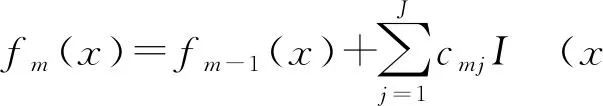
(5)
(3)得到回归树fM(x):

(6)
1.3 DE-GBDT预测模型的建模过程
在GBDT算法模型中,模型参数较多,人工调参需耗费大量时间且存在不确定性,目前关于如何选择和调节模型参数理论尚未建立,因此,本文利用DE算法的全局寻优能力获取模型最优参数。
DE算法[16]是基于群体差异的启发式并行搜索方法,主要包括种群初始化、变异、交叉和选择等操作。主要的控制参数包括:种群规模NP、缩放因子F和交叉概率CR,其中,NP主要影响种群多样性以及收敛速度,F主要影响搜索步长,CR主要影响进化信息的调整权重[17-18]。差分进化算法主要操作如下:
(1)初始化操作:本文采用实数编码方式(RI)构建种群,个体维数D由寻优模型参数个数决定。个体定义如下:
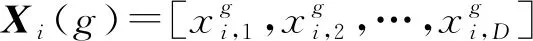
(i=1,2,…,NP;g=0,1,…,G),
(7)
其中,Xi(g)为第g代迭代的第i个个体,G为种群最大迭代次数。设定好控制参数,由下式即可随机生成满足约束条件的0代种群(即初始种群):
(8)

(2)变异操作:首先,从第g代种群中随机选取3个个体Xr1(g)、Xr2(g)、Xr3(g),选择其中2个个体Xr1(g)、Xr2(g)进行差分操作;然后进行加权,再与另一个体Xr3(g)进行求和,从而生成变异个体。计算公式如下:
V(g)=Xr3(g)+F·(Xr1(g)-Xr2(g))。
(9)

(10)
其中,rand(j)[0,1]为第j维分量对应的随机数。
(4)选择操作:对个体Ui(g)、Xi(g)进行适应度评价,f(·)为适应度函数,对中间个体和当代个体对应的适应度值进行比较,选择适应度值更优的个体进入下一代,计算公式如下:
(11)
依次执行以上操作,可以获得新一代种群Xi(g+1)。通过不断对新种群Xi(g+1)执行变异、交叉和选择等操作,可以不断更新种群,直至达到最大种群迭代次数G,算法结束。
GBDT模型主要考虑弱学习器的最大迭代次数、弱学习器的权重缩减系数、子采样比例和决策树最大深度。其中,最大迭代次数和权重缩减系数相互影响:若最大迭代次数(即弱学习器的个数)太小则容易欠拟合,太大则容易过拟合;对于同样的训练集拟合效果,较小的权重缩减系数(即步长)表明需要的最大迭代次数更多;子采样比例小于1可以防止过拟合,但是会增加样本拟合的偏差;决策树最大深度太小则可能会简单地过拟合训练数据,太大则会使决策树结构过于复杂,容易过拟合,导致测试误差增大。
针对上述模型的参数特性,GBDT预测模型的参数范围设置如下:最大迭代次数、权重缩减系数、子采样比例、决策树最大深度的取值区间分别为[10,1 000]、[0.001,0.1]、[0.1,1]、[1,100]。然后,根据这些区间初始化种群,通过个体参数训练GBDT模型。其次,计算每个个体的适应度,并根据当前种群迭代次数和种群收敛情况判断是否满足终止条件:若不满足,则根据交叉、变异和选择等操作更新种群,重新训练GBDT模型;若满足,则根据当前种群最优个体获取模型最优参数组合。最后,根据此最优参数组合训练GBDT模型,从而建立DE-GBDT预测模型(图1)。
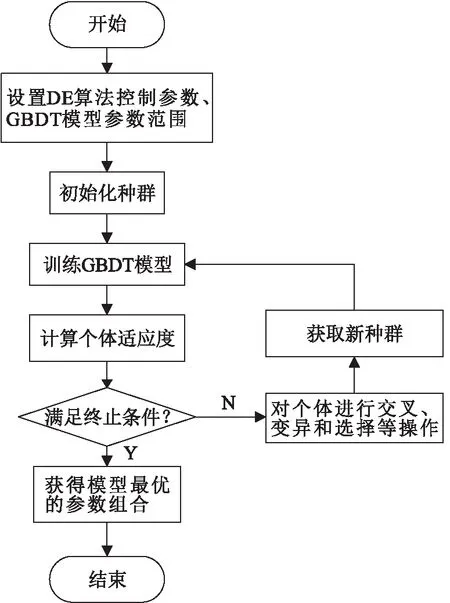
图1 DE-GBDT预测模型的建模流程
2 仿真实验
利用B钢厂2020年8月份历史数据进行建模,训练并验证卷取温度预测模型。模型输入特征包括带钢厚度、带钢速度、带钢温度、冷却水温度和目标卷取温度,输出特征为实际卷取温度,实验仿真工具为Python。实验共采集了190卷带钢数据,依样本段提取带钢数据并经数据处理后,共获取11 000组高质量数据,其中10 000组数据构成训练集,1 000组数据构成测试集。由于目前钢厂中有70%的带钢是以相对误差在20 ℃范围内计算预测命中率,其余带钢以相对误差在15 ℃范围内计算命中率,因此,实验以15 ℃的相对误差计算模型预测命中率。模型预测误差评价指标采用均方误差(MSE)、均方根误差(RMSE),计算公式如下:
(12)
其中,n为样本数,ytrue,i、ypre,i分别为带钢卷取温度实际值、预测模型输出值。
2.1 差分进化算法参数选择
在GBDT模型中,针对DE算法中的种群规模NP和最大迭代次数G进行超参数选取实验,将G初始化为20,NP分别设置为10、30、50、70,分析不同的参数设置对模型预测效果的影响。
由实验结果(表1)可知:当种群最大迭代次数G为20、种群规模NP为50时,效果最佳。此时的GBDT模型的最优参数取值如下:弱学习器的最大迭代次数为906,权重缩减系数为0.019,子采样比例为0.776,决策树最大深度为16。同时为后续对比实验做准备,利用该进化算法参数设计分别对小波神经网络模型中的学习率、最大训练次数和支持向量机模型中的惩罚系数C、核函数参数γ进行参数寻优,得到模型的最优参数:学习率为0.1、最大训练次数为17 703,C为234.092 8,γ为2.699 7。
2.2 3个优化后模型的效果对比
利用差分进化算法分别对SVM、WNN预测模型的模型参数进行寻优,从而得到DE-SVM、DE-WNN预测模型,并与DE-GBDT预测模型进行效果对比。由对比结果(图2)可知:DE-WNN预测模型在740~800 ℃范围内的数据点预测偏差较大,DE-GBDT、DE-SVM预测模型的误差基本都分布在±15 ℃误差带范围内,且DE-GBDT预测模型的离群点最少。
同时,由3个预测模型的评价指标(表2)可知: DE-GBDT预测模型的预测命中率最高,且DE-GBDT预测模型的各项评价指标均最小(MSE为18.232、RMSE为4.269),表明DE-GBDT预测模型在带钢卷取温度预测方面的应用效果最好。
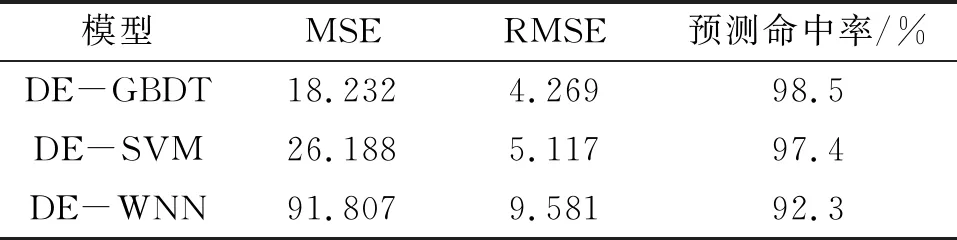
表2 3个优化后的预测模型的评价指标
随机选取一卷带钢数据,利用DE-GBDT预测模型对该钢卷样本点的卷取温度进行预测。由预测效果(图3)可知:DE-GBDT预测模型的预测值与实际值高度拟合,符合实际工艺要求。
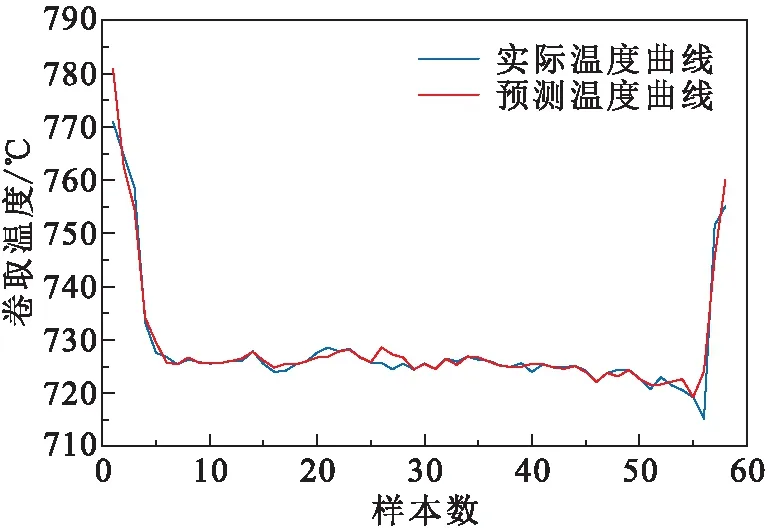
图3 DE-GBDT预测模型的卷取温度拟合效果
2.3 DE-GBDT预测模型与3个基础预测模型的效果对比
将DE-GBDT预测模型与3个基础预测模型(GBDT、SVM、WNN)进行对比。由4个模型预测误差分布(图2A、图4)可知:3个基础预测模型的预测误差较大,DE-GBDT预测模型的离群点明显少于3个基础预测模型。

图4 3个基础预测模型的误差分布
由4个预测模型的评价指标结果(表2,表3)可知:DE-GBDT预测模型的各项误差指标均最小,预测命中率最高,其中,与GBDT预测模型对比,DE-GBDT预测模型的MSE、RMSE分别降低了40.294、3.388,预测命中率提高了2.9%,说明差分进化算法能明显提升模型性能。
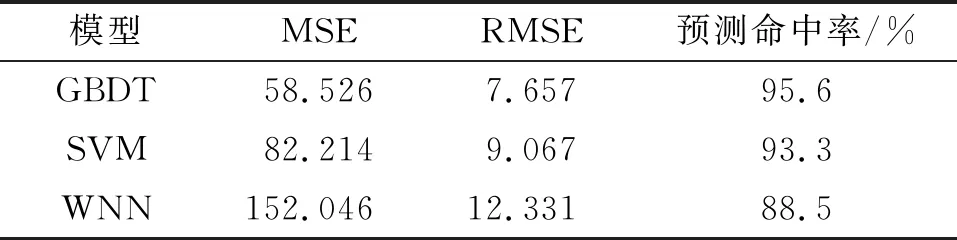
表3 3个基础预测模型的评价指标
3 结论
本文以B钢厂2 250 mm热轧生产线实际生产数据,结合差分进化算法的全局寻优能力和梯度提升决策树的鲁棒性优点,建立基于差分进化算法优化梯度提升决策树的卷取温度预测模型(DE-GBDT)。与DE-SVM、DE-WNN、GBDT、SVM、WNN预测模型的对比仿真结果表明:
(1)DE-GBDT预测模型的各项误差指标均小于DE-SVM、DE-WNN预测模型的,说明DE-GBDT预测模型在卷取温度预测方面泛化性能更好,能为层流冷却前馈控制系统提供更可靠的参考数据。
(2)DE-GBDT预测模型的离群点明显少于3个基础预测模型(GBDT、SVM、WNN)的,各项误差指标均最小,预测命中率最高。其中,与GBDT预测模型对比,DE-GBDT预测模型的MSE、RMSE分别降低了40.294、3.388,预测命中率提高了2.9%,说明差分进化算法能明显提升模型性能。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
红土地(2018年7期)2018-09-26 03:07:38
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息安全研究(2015年3期)2015-02-28 20:17:57
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
太空探索(2014年1期)2014-07-10 13:41:50
四川生理科学杂志(2014年2期)2014-02-28 14:09:20
