
基于CenterNet的密集场景下多苹果目标快速识别方法
2022-03-14 07:57杨福增雷小燕刘志杰
农业机械学报 2022年2期
杨福增 雷小燕 刘志杰 樊 攀 闫 彬
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100; 2.农业农村部苹果全程机械化科研基地, 陕西杨凌 712100; 3.农业农村部北方农业装备科学观测实验站, 陕西杨凌 712100)
0 引言
我国是世界上最大的苹果生产国和消费国,但苹果的采摘仍以传统的人工作业为主,人工采收不仅劳动强度大,且随着农村劳动力的减少,出现了用工荒的现象,亟需研发苹果采摘机器人以降低对人工的过度依赖[1-2]。苹果目标的准确快速识别是机器人实现自主采摘的重要前提[3-5]。在果园环境中, 密集场景(即远距离场景)指远距离拍摄的单幅图像,该图像包含大量的果实,且图像中普遍存在果实重叠、遮挡的现象[6-7]。实现密集场景下多苹果目标的准确快速识别,对提高采摘机器人的识别效率、进而实现苹果的智能化采摘至关重要。
传统的果实识别方法主要基于果实的颜色、纹理和形状特征等[8-11],这类方法对单个果实或相邻果实识别效果较好,但对果园中互相重叠或受枝条、树叶遮挡的果实识别准确率明显降低[12]。近年来卷积神经网络(Convolutional neural networks,CNN)在目标检测方面性能卓越,已经被广泛应用于果实识别[13-15]。果实识别从原理上可划分为两类:一类需要将果实的识别问题分为两步,先通过网络产生可能包含果实的候选区域,再对候选区域进行分类,这类网络的识别时间普遍较长[16-17]。另一类方法直接通过CNN给出果实的置信度和位置坐标,其特点是能提高果实的识别速度,但同样使用锚框(Anchor box)导致遮挡类果实的识别精度降低[18-19]。上述两类算法均是基于锚框的识别算法,针对不同的数据集,需要进行不同大小、多个数量的锚框设定,由于锚框尺寸固定,导致网络对不同尺寸目标识别的通用性降低,对重叠、遮挡的小目标果实可能无法匹配到锚框,从而导致漏检。在预测阶段需要通过非极大值抑制(Non-maximum suppression,NMS)删除重复的候选框,使得目标识别时间更长。
近两年,基于无锚框(Anchor free)的目标识别思路开始兴起,无锚框是基于预测目标关键点的识别算法,如CenterNet[20]、CornerNet-Lite[21]、ExtremeNet[22]等在人体姿态检测上得到成功应用。CenterNet通过预测每个目标的中心点,并预测其宽、高尺寸实现目标识别。CornerNet-Lite网络通过预测目标的左上角点和右下角点,两个关键点进行组合确定目标。ExtremeNet网络通过预测一幅图像每个目标的上、下、左、右4个极点和中心点,通过几何关系对预测的关键点进行分组实现目标识别。与CornerNet等关键点预测模型相比,CenterNet只预测目标的中心点,没有预测点的分组问题,不需要NMS抑制冗余框,是无锚框领域识别精度和速度较优的算法。
在密集场景下,图像中的苹果尺寸较小,且苹果间互相重叠遮挡、苹果被枝条和树叶遮挡等现象严重,这些因素给苹果目标的准确识别带来困难。为实现密集场景中多苹果目标的准确识别,本文通过改进基于无锚框的CenterNet模型,设计Tiny Hourglass-24轻量级骨干网络,同时优化残差模块进而提高苹果的识别速度,实现密集场景下多苹果目标的准确快速识别。
1 试验数据
1.1 图像采集
图像采集地点为陕西省乾县农业科技试验示范基地的标准化现代果园,采集设备为索尼FDR-AX45型相机。相机与树冠距离为0.5~2 m,选择多个角度和距离进行拍摄,采集时间为白天,包括树叶遮挡、枝条遮挡、果实间重叠遮挡、顺光和逆光等环境下的图像,最终采集苹果图像1 852幅。部分采集图像如图1所示,可以看到在密集场景中(图1b~1d),果园苹果呈多簇密集生长的情况,存在大量重叠、遮挡的现象,导致密集场景下的苹果目标识别存在较大难度。

图1 果园环境下的苹果图像Fig.1 Images of apples in an orchard environment
1.2 数据集制作
利用LabelImg标注软件绘制苹果矩形框,标注后生成相对应的xml文件,其中标注信息包含每个苹果目标真实的左上角点和右下角点像素坐标,数据集保存为PASCAL VOC格式。为了验证在密集场景下算法的识别性能,将标注后随机选择的852幅测试集分为2类,其中测试集A为近距离场景下的苹果,共397幅图像,包含3 542个苹果,平均一幅图像包含8.92个苹果目标。测试集B为摄像机远距离拍摄的密集场景下的图像,共455幅图像,包含11 578个苹果,平均每幅图像有25.45个苹果目标,其果实在图像中的尺寸较小,遮挡现象较为普遍,两类测试集上均包含不同光照情况下的图像。
由于深度学习需要大量数据集提升网络的识别性能,对剩余的1 000幅图像进行亮度、锐度、色度的增强和减弱,加入0.01的高斯噪声、进行图像翻转等数据增强方式来丰富数据集,最终共生成图像28 020幅用于网络训练。
2 目标快速识别方法
2.1 CenterNet网络
CenterNet网络比基于锚框的识别算法更简单,更快且更准确[20]。CenterNet采用 “点即是目标”的思路,通过寻找待识别物体的中心点以及宽、高来确定目标。CenterNet网络首先对输入图像预处理,4倍下采样降低图像分辨率;然后通过骨干网络Hourglass-104进行特征提取,产生一组关键点、目标宽高尺寸以及中心点误差;最后用最大池化(Max pooling)筛选保留的关键点,在关键点附近产生预测框。CenterNet网络识别流程如图2所示。网络总的输出通道数为C+4,C为识别目标的类别数,4为通道数,表示目标的宽、高尺寸以及目标中心点的横向和纵向坐标误差。
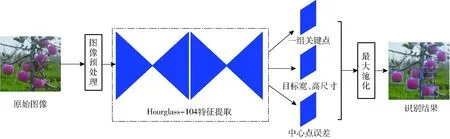
图2 CenterNet网络识别流程Fig.2 Progress of CenterNet recognition
2.2 苹果中心点预测
CenterNet预测苹果目标中心点的过程分为3步:首先根据标注保存的xml文件内的像素坐标信息,求取每个苹果真实的中心点坐标,将真实中心点位置的得分置为1;其次,考虑到苹果真实中心点附近的区域也近似代表苹果目标,通过高斯核函数Yxyc在真实中心点附近生成一个二维的正态分布,使真实的苹果中心点附近的区域值为0~1之间的数;最后,通过网络训练预测出一组苹果可能的中心点,预测的中心点得分xyc在0~1之间,预测的中心点和真实中心点之间的最小误差为Lk,误差函数采用改进的Focal loss[23],即
Lk=
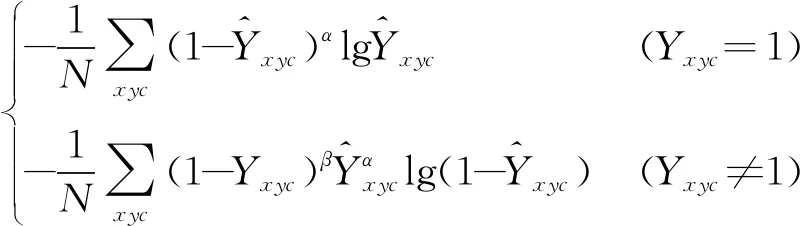
(1)

(2)
式中N——单幅图像中目标的数量
x、y——4倍下采样后目标真实的中心点坐标
c——识别目标的类别,c取1
α、β——每个点贡献的超参数,α取2,β取4

σp——自适应苹果目标的标准差
在进入骨干网络训练之前,首先对图像进行4倍下采样预处理,真实的中心点坐标在缩小4倍后会产生量化误差,因此需要对每一个中心点预测中心点偏移量P,偏移损失Loff计算公式为
(3)
其中
P=(δip,δip)
(4)
(5)
式中x1、y1——苹果目标左上角点像素坐标
x2、y2——苹果目标右下角点像素坐标
p——目标真实的中心点
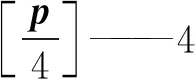
在预测阶段,对输出的特征图用3×3 最大池化提取特征图上的中心点,选出特征图上大于或等于周围8个相邻值的点,作为初步预测的中心点,对预测的点按照置信度由高到低进行排序,选取前50个点作为预测的中心点,保留置信度大于0.3的点作为最终预测的中心点。
2.3 苹果宽、高尺寸预测
网络除了要预测苹果的中心点,也要预测每个中心点对应的宽和高。CenterNet计算出图像中苹果的真实宽度和高度s,通过网络训练预测出苹果目标的宽、高尺寸。尺寸误差Lsize的计算公式为
(6)
其中
s=(x2-x1,y2-y1)
(7)
训练的损失函数由3部分构成,分别是预测的关键点损失Lk、预测框的尺寸损失Lsize以及中心点的偏移损失Loff,总体目标损失函数Ldet的公式为
Ldet=Lk+αoffLoff+βsizeLsize
(8)
式中αoff——偏移损失权重,取为1
βsize——尺寸损失权重,取为0.1
2.4 CenterNet网络的改进设计
骨干网络是一个卷积神经网络的重要组成部分,其主要对目标的特征进行提取。CenterNet原型使用了Hourglass-104骨干网络进行特征提取,Hourglass最先提出用于复杂的人体姿态估计[23],该网络由一个或多个沙漏模块组成,每个沙漏模块通过下采样和上采样的方式对输入图像进行特征提取,上、下采样过程均采用多个残差(Residual)模块,网络深度为104层,其结构复杂庞大,且受巨大参数量制约,需要多块高性能显卡带动训练,网络运行速度很慢。
鉴于本研究的识别为单一的苹果类别,浅层网络也可以实现苹果目标的特征提取[19],因此本文改进设计了轻量化的CenterNet骨干网络,以提高苹果的识别速度。考虑到密集场景下苹果多为小目标,特征图分辨率过小可能丢失小目标苹果的信息,因此在骨干网络中,本文对图像仅进行3倍下采样降低特征图分辨率,再通过3倍上采样恢复特征图的分辨率。为了降低网络参数量,提升苹果目标识别的速度,对Hourglass-104的单个Residual模块进行了优化,将原有Residual模块第1层的3×3卷积的通道数压缩2倍,将第2层的3×3卷积替换为1×1的分组卷积[24],改进后的G-Residual模块改进设计如图3所示。图3中n为Residual模块的通道数量。
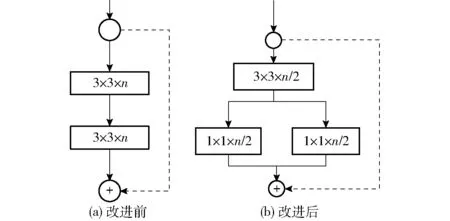
图3 Residual模块改进结果Fig.3 Residual module improvement result
重新设计的沙漏模块命名为Tiny Hourglass,由多个G-Residual组成,单个Tiny Hourglass模块由下采样层、上采样层、跳跃连接层构成,每层均使用1个G-Residual模块。下采样层对特征图进行3倍下采样提取不同尺度下的特征,3倍下采样后特征图的分辨率降为16像素×16像素,再通过上采样层3倍上采样进行特征提取,恢复图像的分辨率。输出特征图的分辨率为128像素×128像素,大分辨率的特征图有利于目标的准确识别。在每个下采样层和上采样层之间,添加跳跃连接层弥补下采样丢失的目标信息。改进的骨干网络由2个相同的Tiny Hourglass模块堆叠而成,整个骨干网络为全卷积网络,网络深度为24层,2个Tiny Hourglass模块采用中间监督[23](Intermediate supervision)方式,将第1个Tiny Hourglass模块输出的特征图和输入特征图作为第2个Tiny Hourglass模块的输入,基于Tiny Hourglass-24骨干网络的CenterNet网络结构如图4所示,图4中A、B、C为跳跃连接层。
3 网络训练
3.1 试验运行平台
本试验所运行的硬件平台为T7920塔式工作站,处理器为Intel(R) Xeon(R) 5118 CPU,2.30、2.29 GHz (双处理器),32 GB运行内存,显卡为Nvidia RTX2080TI-11G。在Windows 10操作系统上运行,借助Pytorch1.2框架、CUDA 10.0、CUDNN 7.3软件工具搭建运行环境。

图4 基于Tiny Hourglass-24的CenterNet网络结构Fig.4 CenterNet network structure based on Tiny Hourglass-24
3.2 网络训练
网络训练的批处理量为68,初始学习率为0.000 25,网络训练共迭代100轮,学习率在60轮和90轮时分别下降10倍。训练前对图像进行标准化和归一化处理,使用整个网络最后一层的特征图来进行预测。网络训练的损失值如图5所示。由图5可知,网络在前20轮训练时,损失值快速下降,80轮之后,损失值基本趋于稳定。

图5 网络训练损失曲线Fig.5 Network training loss curve
3.3 评价指标
为验证本文所提网络的识别性能,利用F1值和平均精度来对网络的识别性能进行评价。
4 结果与分析
4.1 不同深度Tiny Hourglass网络识别结果对比
网络深度对识别性能有很大影响,浅层网络会导致其特征提取能力不强,加深网络层数会提取更加复杂的深层特征,但会导致识别速度降低。为了在不降低识别精度的同时提升网络的识别速度,在确定骨干网络深度之前,本试验设计了3种不同深度的Tiny Hourglass网络进行性能对比,设置深度分别为32、24、12层,网络在测试集A、B下的识别结果如表2所示。
由表2可知,随着网络深度的降低,网络识别的F1值下降,且网络在测试集B上的平均精度和F1值降低较为严重。当骨干网络深度为24层时,在测试集A上识别的平均精度和F1值分别为98.90%和96.39%;在测试集B上识别的平均精度和F1值
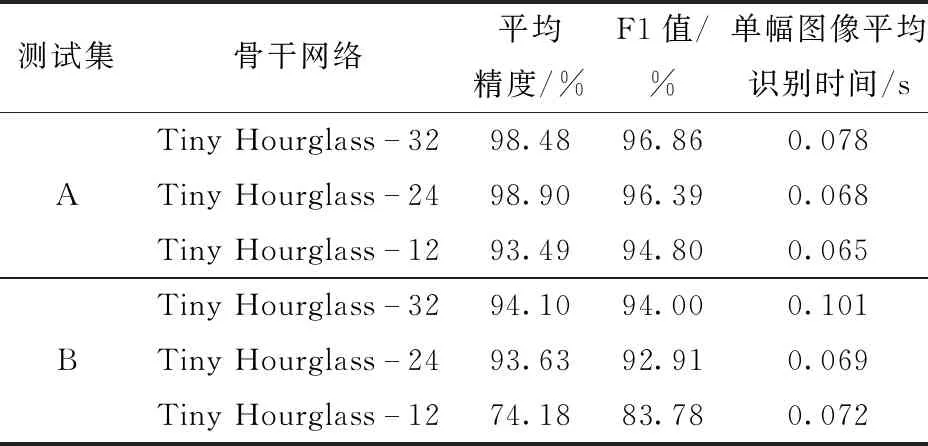
表2 不同深度骨干网络识别结果Tab.2 Backbone network identification results of different depths
为93.63%和92.91%,单幅图像的平均识别时间为0.069 s,在两类测试集上的识别精度和速度均较好。网络深度在32层时,在测试集B识别的平均精度和F1值与24层时基本相当,但Tiny Hourglass-24网络识别一幅图像的时间比Tiny Hourglass-32减少0.032 s。当网络降为12层时,在测试集B上,识别的平均精度和F1值相较于24层分别下降了19.45个百分点和9.13个百分点,可见,12层的浅层网络对密集场景果实识别效果较差。由于在测试集B上,单幅图像苹果数目增多,果实在图像中的尺寸变小,苹果间互相重叠遮挡、苹果被枝条遮挡严重,12层骨干网络提取特征能力有限,对复杂场景下多目标的识别效果较差。 综上,Tiny Hourglass-24在识别速度和识别精度上均可以取得较好的结果,最终选择深度为24层的Tiny Hourglass网络作为骨干网络。
4.2 不同骨干网络识别结果对比
为了验证Tiny Hourglass-24网络对苹果目标的识别性能,本文将Tiny Hourglass-24网络与另外两类骨干网络DLA-34、ResNet-18进行比较,在两类测试集下的识别结果见表3。

表3 不同骨干网络的识别结果Tab.3 Detection results of different backbone networks
由表3可知,Tiny Hourglass-24在识别精度和识别速度上性能最优。DLA-34骨干网络在测试集B上平均精度为91.16%,比Tiny Hourglass-24低2.47个百分点,此外,DLA-34网络模型较大、运行时间更长,在识别速度上,Tiny Hourglass-24在测试集B上对单幅图像的识别时间比DLA-34减少0.034 s。ResNet-18骨干网络相较于Tiny Hourglass-24和DLA-34更加轻量化,在识别速度上优于前两种骨干网络,但由于网络较浅,特征提取能力有限,在密集场景的测试集B上识别性能明显降低,其F1值和平均精度相较于Tiny Hourglass-24分别下降了4.63个百分点和12.33个百分点。Tiny Hourglass-24骨干网络通过3倍下采样和上采样的方式使特征图的分辨率较高,有利于小目标的特征提取;结合跳跃连接层弥补下采样丢失的信息,增加了网络特征提取能力,更适用于密集场景下多目标的识别。
图6为基于Tiny Hourglass-24的CenterNet识别结果,其中紫色框为网络识别到的苹果,红色框为漏识别苹果。由图6可以看出,网络在测试集A上对阴天和晴天逆光、顺光条件下的识别效果较好,对遮挡面积严重的苹果也可以准确识别。在测试集B中,网络在阴天环境下识别效果较好,且对重叠和遮挡的苹果识别效果较好。在逆光情况下,苹果表面颜色较暗,网络在苹果被枝干重度遮挡的情况下存在少量漏识别;在顺光情况下,苹果表面亮度增强,部分表面颜色特征变为白色,导致对遮挡苹果存在个别漏检。

图6 基于Tiny Hourglass-24的CenterNet识别结果Fig.6 Detection results of CenterNet based on Tiny Hourglass-24
4.3 不同算法识别结果对比
为了进一步验证基于无锚框的CenterNet算法对苹果目标的识别性能,本文将改进的CenterNet与YOLO v3、CornerNet-Lite算法在两类测试集上进行了对比,以平均精度作为评价指标。YOLO v3网络属于经典的基于锚框的识别思想,CornerNet-Lite网络是另外一种基于无锚框的识别方法,它通过预测物体的左上角点和右下角点,将预测的关键点进行匹配实现目标识别,网络识别结果如表4所示。
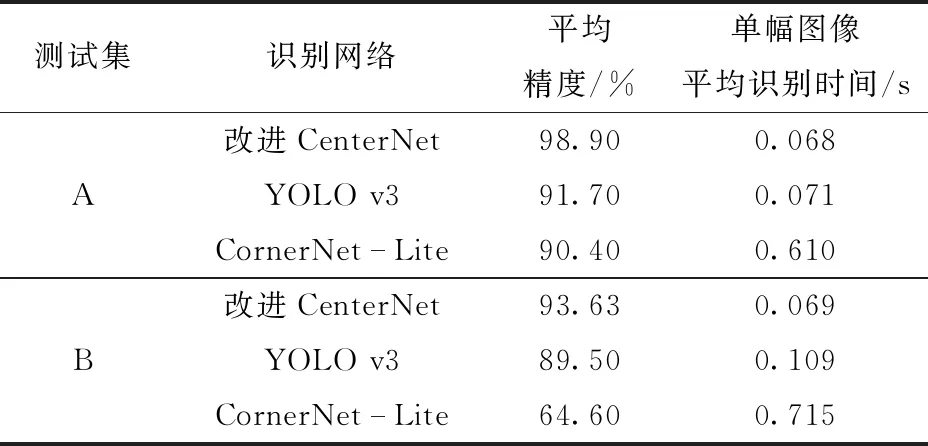
表4 不同网络识别结果Tab.4 Different network detection results
由表4可知,本文提出的基于Tiny Hourglass-24的CenterNet网络在测试集A和测试集B上的平均精度均最高。在测试集A上,改进CenterNet网络的平均精度比YOLO v3和CornerNet-Lite分别高7.20、8.50个百分点。在测试集B上,改进CenterNet网络的平均精度高于YOLO v3网络4.13个百分点,高于CornerNet-Lite 29.03个百分点。图7为基于Tiny Hourglass-24的CenterNet网络在近距离场景和密集场景下中心点识别结果,可以看出,在树枝遮挡、果实互相重叠遮挡的情况下,网络均可以准确识别到苹果的中心点。

图7 改进CenterNet网络预测的中心点结果Fig.7 Results of improved CenterNet network prediction center
3种网络的识别结果如图8所示,其中左图为在测试集A上的识别结果,右图为在测试集B上的识别结果。由图8a可知,改进CenterNet在近距离场景的识别效果较好,在果实被树干遮挡和果实之间互相重叠遮挡的情况,均能取得良好的识别结果。在密集场景的测试集上,网络在树叶遮挡、果实之间重度遮挡的情况下,均可以准确识别到苹果。由图8b可知,当果实被树干遮挡以及果实被树叶遮挡时,YOLO v3存在漏识别的现象,这是由于YOLO v3是基于锚框的多尺度预测模型,由于锚框参数需要设置,无法灵活适应苹果目标的尺寸,在密集场景下遮挡严重,容易丢失苹果的特征,使得YOLO v3对小尺度遮挡类的苹果存在漏检。

图8 3种模型在两类测试集中的识别结果Fig.8 Detection results of three models under two test sets
由表4和图8c可知,基于CornerNet-Lite网络的识别结果在近距离场景测试集上的性能远优于其在密集场景测试集。在近距离场景和密集场景中,网络识别均存在较大的误检框,这是由于CornerNet-Lite网络对每个目标预测出两个关键点,在预测出苹果的左上角和右下角两个关键点后,在关键点匹配阶段,存在部分不同苹果目标的关键点被错误组合为一个苹果,导致了网络的错检。在密集场景中,由于图像中苹果目标较小,果实与果实之间距离更加紧密,存在较大的误检框,降低了在密集场景下的识别精度。因此,基于多个关键点分组的思路并不适用于密集场景下的小目标识别,而基于Tiny Hourglass-24骨干网络的CenterNet网络,只预测一个目标中心的关键点,没有预测点的分组问题,也不需要NMS删除重复框,更适合密集环境下的小目标苹果识别。
4.4 性能验证
为了验证本文方法的识别性能,分别与Faster R-CNN[25]、R-FCN[26]、改进YOLO v3[19]的研究结果进行了比较,结果见表5。
由表5可以看出,Faster R-CNN、 R-FCN、改进YOLO v3算法在单幅图像苹果数约为13个的情况下,F1值分别为89.8%、90.2%、75.15%,而本文方法在单幅图像平均25.45个苹果的测试集上识别的F1值为92.91%,比Faster R-CNN、 R-FCN、改进YOLO v3分别高3.11、2.71、17.76个百分点。
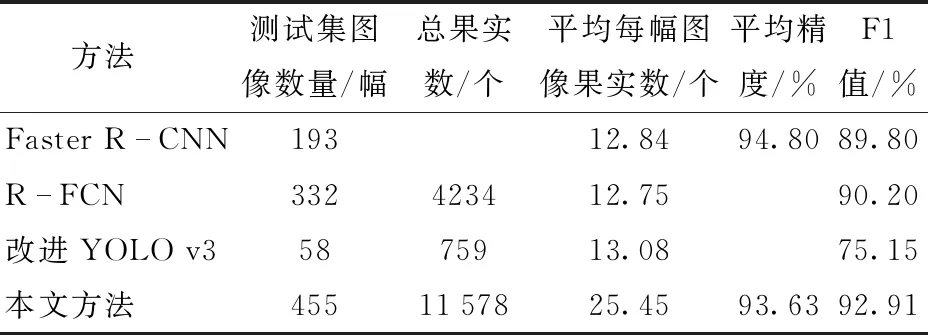
表5 不同方法比较结果Tab.5 Comparison of results of different methods
这3类算法由于锚框的限制,导致对遮挡类目标识别精度不高,锚框的设计不仅增加了网络参数量,且容易丢失小目标苹果的信息,不利于密集场景下多苹果目标的识别。本文提出的密集场景下多苹果目标的快速识别方法,采用无锚框的设计使其能更好地适用遮挡类的多目标苹果识别,不需要使用NMS操作,节省了大量时间。本文方法在密集场景测试集上识别的平均精度为93.63%,F1值为92.91%,可以实现密集场景下多苹果目标的准确识别。
5 结论
(1)提出了一种密集场景下多苹果目标的快速识别方法。借鉴“点即是目标”的思路,直接预测苹果的中心点和宽、高尺寸来识别苹果。设计了基于Tiny Hourglass-24骨干网络的CenterNet模型,并进一步优化Hourglass网络的残差结构来提高识别速度。该模型在近距离场景测试集下识别的平均精度为98.90%,F1值为96.39%;在密集场景测试集下识别的平均精度和F1值分别为93.63%和92.91%,单幅图像平均识别时间为0.069 s。
(2)通过将改进CenterNet与YOLO v3、CornerNet-Lite网络在两类测试集上进行对比验证,试验结果表明,改进CenterNet网络在测试集B上的平均精度比YOLO v3提高4.13个百分点,比CornerNet-Lite高29.03个百分点。基于Tiny Hourglass-24的CenterNet通过预测目标中心点的方法,比基于锚框的识别方法、基于多个关键点进行匹配的识别方法更具优势,整个识别过程不使用锚框和NMS后处理,减少了网络参数,更适用于密集场景下多苹果目标的识别。
猜你喜欢
英语文摘(2021年2期)2021-07-22
当代陕西(2020年16期)2020-09-11
电脑报(2020年12期)2020-06-30
长江丛刊(2019年29期)2019-11-14
山西教育·招考(2019年9期)2019-09-10
电脑报(2019年4期)2019-09-10
湛江文学(2019年7期)2019-08-30
新课程·小学(2019年1期)2019-03-18
汉语世界(The World of Chinese)(2018年6期)2018-01-22
BOSS臻品(2015年1期)2015-09-10
