
融合汉字字形信息的文本关系抽取
2022-03-10 09:34覃俊廖立婷刘晶叶正刘璐
中南民族大学学报(自然科学版) 2022年2期
覃俊,廖立婷,刘晶,叶正,刘璐
(中南民族大学 计算机科学学院& 湖北省制造企业智能管理工程技术研究中心,武汉 430074)
关系抽取作为信息抽取的核心任务,旨在从文本中识别实体并抽取实体之间的语义关系,为构建知识图谱、自动问答系统等自然语言处理任务提供数据基础.早期应用于关系抽取的方法主要是CNN、RNN 及其改进模型.LIU 等[1]最早将CNN 运用到自然语言处理任务中来自动提取特征,代替了手工特征,但结构简单无池化层.ZENG 等[2]是首次将Position Embedding 应用到关系抽取中,使用最大池化,但提取特征单一.ZHANG 等[3]尝试使用RNN 获取更多的信息,但训练时间较长、易出现梯度消失和梯度爆炸.随着LSTM[4]、GRU[5]、BERT[6]等模型的出现,RNN的问题在一定程度上得以改进.
综合考虑关系抽取的实体之间的位置关系、句子的语义信息、以及汉字特点,提出了基于汉字字形的关系抽取方法,其主要贡献如下:
(1)根据汉字是象形字的特点,相同或相近意思的词或多或少在汉字字形上都存在相似之处,故将汉字字形拆解并融合到关系抽取的模型中,以获取更多未曾关注到的潜在信息.
(2)使用能获取更多特征信息的深度学习模型BERT 进行句子级、词级编码,并利用自注意力机制计算实体之间的语义关系.
1 相关工作
针对语料缺乏问题,MINTZ 等[7]首次提出不依赖人工标注的关系抽取——远程监督.其基于一个大胆的假设:如果两个实体在已知知识库中存在某种关系,那么当这两个实体在同一个句子中共现时,这个句子也表达这种关系.但带来两个主要问题:包含实体对的句子可能并未表达在知识库的关系;二是两个实体对可能存在多种关系,无法判断是哪一种.RIEDEL 等[8]放宽该假设:包含实体对句子中至少有一个表达这种关系.其有更好的准确性,但预测任务更为复杂.SURDEANU 等[9]提出多实例学习来缓解.LIN 等[10]引入attention 机制.XU 等[11]提出将关系抽取转换成序列标注任务,使用LSTM 缓解长距离依赖问题.BELTAGY 等[12]提出将监督学习与远程监督相结合的改进模型.YE 等[13]将注意力从bag内扩展到bag 间.随着Bert的问世,SHI等[14]提出基于Bert模型进行关系抽取.VASHISHTH 等[15]提出利用KBs中的附加边信息改进关系抽取.
中文语境的关系抽取借鉴已有的研究方法.文献[16]提出在文本特征组织方面融合位置特征、最短依存特征等多元特征.文献[17]利用文本向量和位置编码得到局部特征作为输入,通过多头注意力机制的神经网络模型,得到全局特征.文献[18]将双向GRU 模型与PCNN 模型结合起来,并加入注意力机制.文献[19]使用BiLSTM 获取更为完整的上下文特征信息.通过深度学习框架来获取文本的语义信息,忽略了数据集自身的特点.汉字,起源于记事的象形性图画,象形字是汉字体系得以形成和发展的基础.当前我们使用的虽是简化版的文字,但在一定程度上依旧保持着潜在的联系.这种潜在的信息在先前的研究工作中很少被利用.
2 语料预处理
预处理的主要目的是获取高质量的训练数据,预处理工作主要是对句子中的实体进行字形拆解.汉字属于象形文字,其字形存在丰富的内在特征.比如部首为氵的汉字(如江、海、河等)都表示一般与水有关,也存在极少数例外,如法.
模型输入是包含实体对(eh,et)的句子和该句子的上下文、实体对以及其字形.假设包含实体对(eh,et)的文本数据的集合s={x1,x2,…,xn},xi为一个输入语料,集合s的向量标记为S,表示如公式(1).

αi为xi权重,引入的注意力机制中权重越高的句子越能表示实体对的关系.其中αi的计算如公式(2).
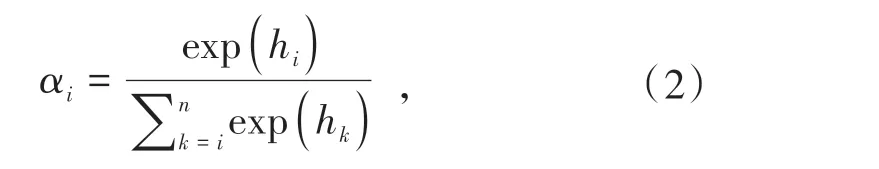
hi是实体对(eh,et)之间关系的相关性权重,在计算时考虑上下文信息对实体对关系的影响,hi的计算如公式(3).
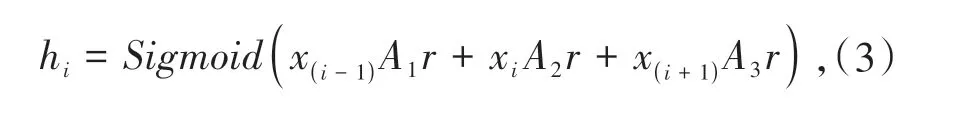
xi为包含实体对的句子,xi-1表示它的上一句,xi+1表示下一句.A是通过模型学习到的权重矩阵,r是实体对之间的关系,也是需要学习的.使用Sigmoid将句子对实体对的影响映射到[0,1]之间.
包含实体对(eh,et)句子xi=(w1,w2,…,wj,..,wk,…,wp,…,wq,…,wn),其中wi为一个汉字,实体eh=(wj,..,wk),实体et=(wp,…,wq).一个实体由多个汉字组成,一个汉字由多个部件构造而成,实体eh的字形表示为,其中表示实体第一个汉字的第一个构造部件(比如‘汉’构造部件为‘氵’和‘又’,其中为‘氵’为‘又’,n为eh的所有构造部件总和),实体et的字形表示为字形信息均从新华字典(http://tool.Httpcn.com/Zi/)中获得.
3 基于字形融合的BERT 关系抽取模型
基于深度学习BERT_BI-GRU_Glyph 关系抽取模型如图1所示,其主要部分如下:
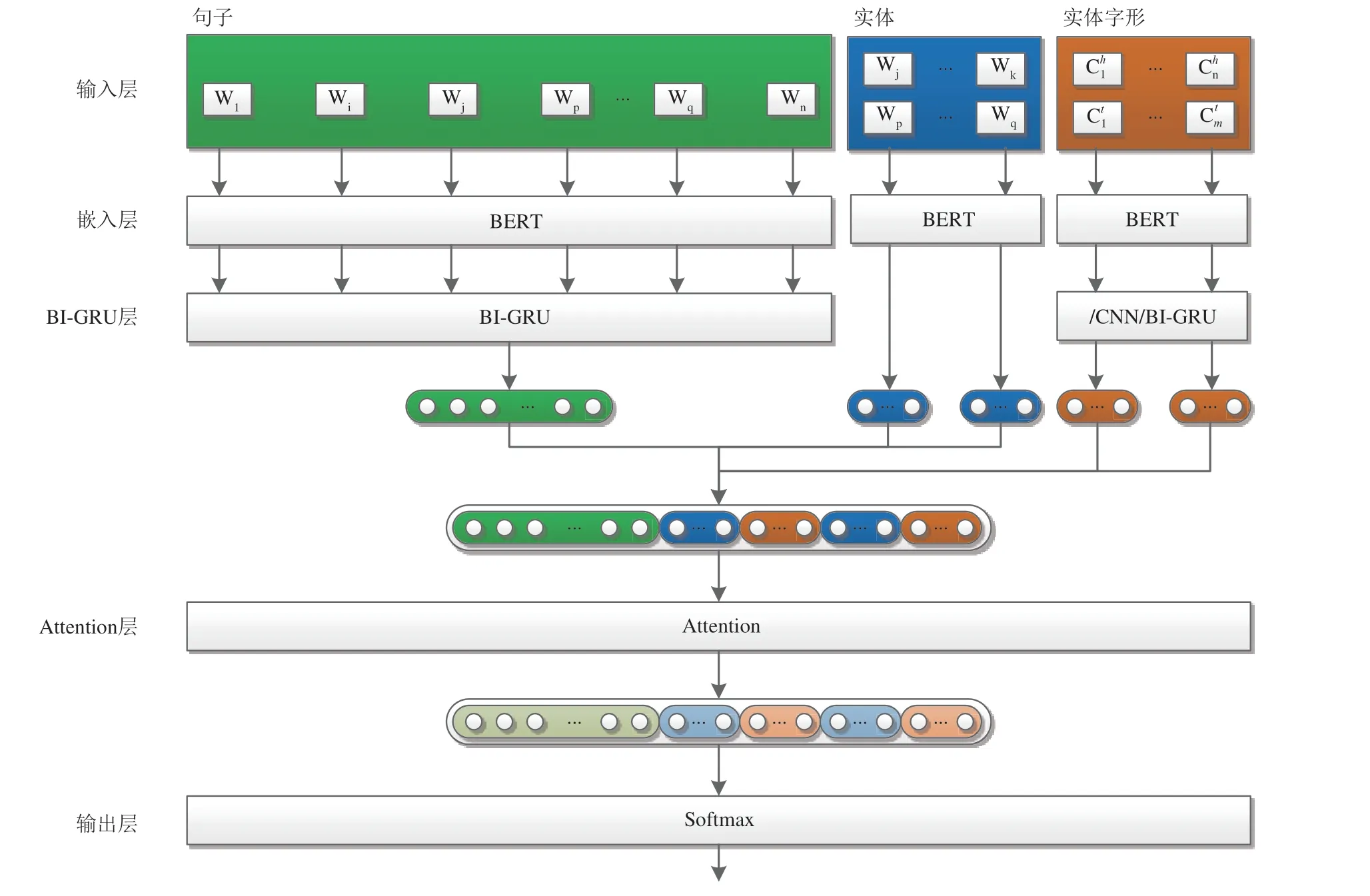
图1 融合多信息的实体关系抽取分类器Fig.1 Entity relationship extraction classifier based on multi-information fusion
(1)输入层:预处理阶段通过新华字典得到实体的字形信息,句子、实体、实体字形作为模型的输入;
(2)嵌入层:通过BERT 得到句子编码、实体编码和实体字形编码,作为BI-GRU的输入;
(3)BI-GRU 层:通过BI-GRU[20]丰富句子和字形上下文信息,并融合句子信息、实体信息和实体的字形信息得到输入的向量表示;
(4)Attention 层:通过生成一个代表注意力的权重向量,对上一层的输出进行加权计算,得整体特征向量表示.
(5)输出层:将整体的特征向量输入到softmax分类器,得到其关系的分类结果.
模型是将句子输入到BERT 中得到比较丰富的语义特征向量,再将句子编码放入BI-GRU 模型中丰富句子的上下文信息,并融合实体和实体字形信息加强实体的特征表示,最后使用融合后的特征信息进行关系抽取.在本节中会介绍到句子信息编码(3.1)、实体信息编码(3.2)以及实体字形信息编码(3.3).
3.1 句子信息编码
实验的数据集是中文数据集,首先利用BERT自带的分词工具得到Tok,其中输入的文本信息有包含实体对句子的上文xi-1、包含实体对的句子xi和包含实体对句子的下文xi+1三个部分组成.经过BERT模型得到句嵌入向量如公式(4).
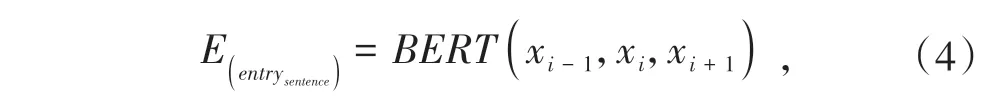
BERT 中文模型只支持字级别的编码方式,不会根据时态等情况进行分词,忽略掉句子具有序列结构的特征.故融合BI-GRU[20]以获取其上下文信息.其BI-GRU[20]的编码方式如图2.GRU[5]是RNN 网络的一种,其思想和LSTM[4]相似.通过“门机制”来克服短时记忆的影响和梯度爆炸梯度消失问题.其中LSTM[4]和GRU[5]元 结 构 对 比 如 图3.相 比LSTM,GRU 只包含重置门和更新门,GRU 结构简单,参数少,训练容易.
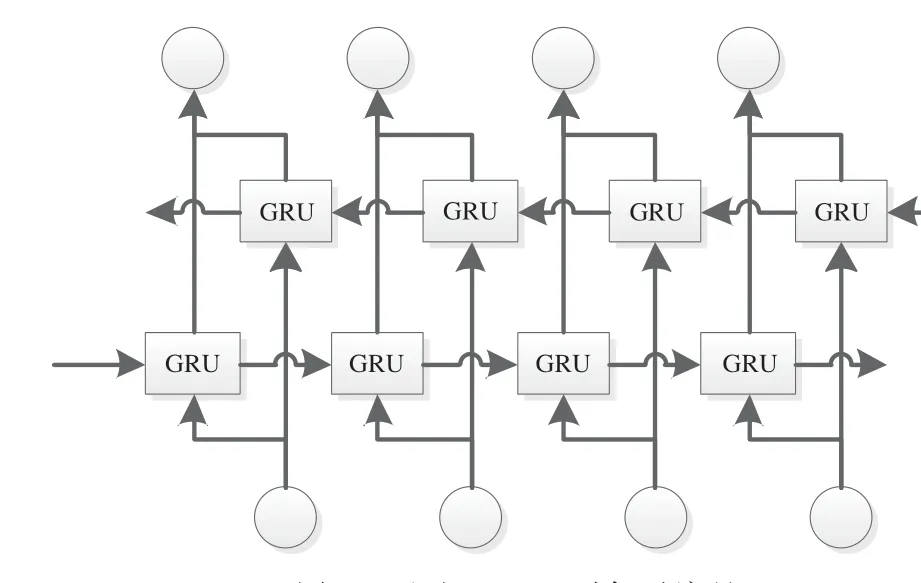
图2 通过BI-GRU对句子编码Fig.2 The sentence is encoded by Bi-GRU
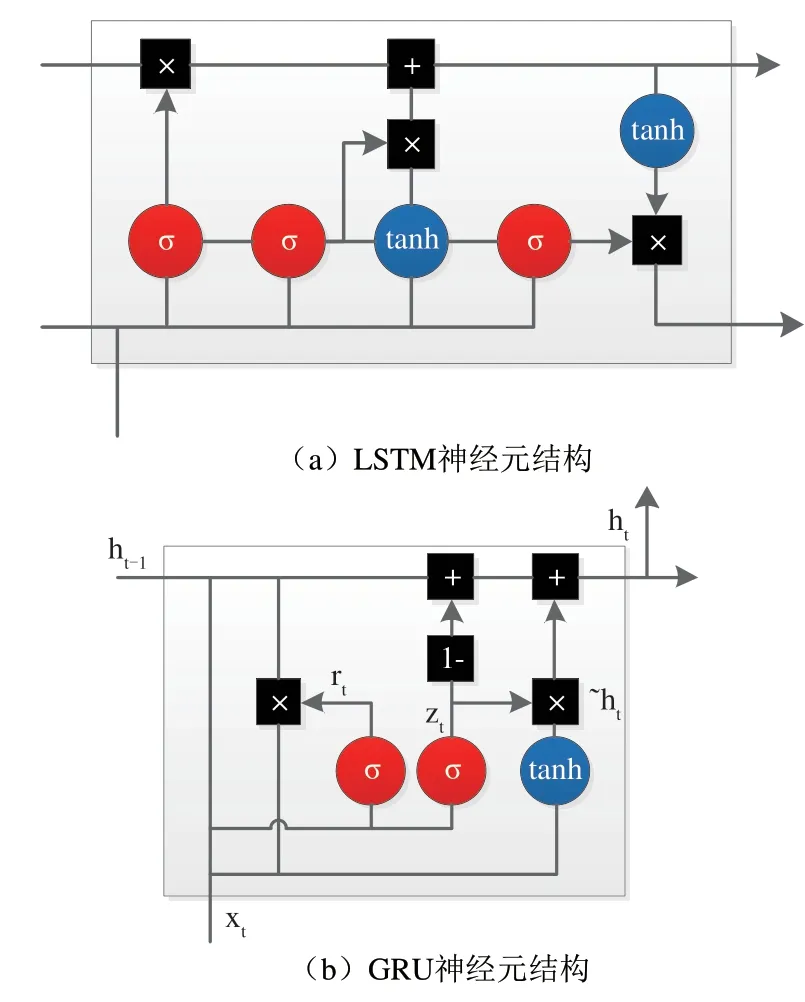
图3 GRU和LSTM内部结构Fig.3 GRU and LSTM internal structure
在图3(b)中,xt为输入,ht为GRU 神经元的输出,rt、zt分别为t时刻的重置门和更新门,共同控制上一层的隐藏状态和这一层的输入来计算当前时刻的隐藏状态ht.计算如公式(5~8):
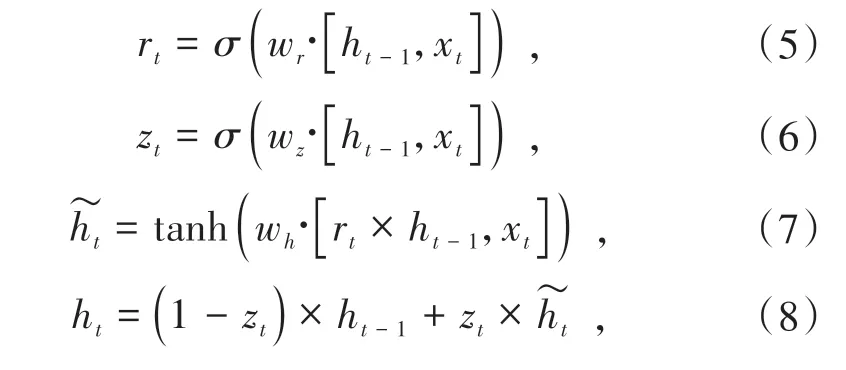
σ为Sigmoid函数,wr、wz、wh分别为重置门、更新门和候选隐藏状态~ht的权重矩阵.
BI-GRU 中包含了正向传播和反向传播的隐藏层,两个方向的隐藏层都会传递到输出层,因此输出信息既包含了正向信息也包含了反向信息.
3.2 实体信息编码
中文分词中对于边界模糊的词常存在错误传播问题,故将实体信息进行编码加强句子中实体的表示.在编码时,使用BERT 进行预训练.给定实体eh=(wj,..,wk),实体et=(wp,…,wq)作为输入,则其对应的实体eh和et信息表示分别为Eh=(ej,..,ek)和Et=(ep,..,eq),其中ej+i表示实体eh的第i 个汉字.ei∈Rdc,dc为输出维度.
3.3 实体字形信息编码
数据预处理是通过新华字典(http://tool.Httpcn.com/Zi/)获取实体的字形信息.在进行实体字形信息编码时,采用BERT进行预训练.在形式上,给定实体eh字形 信 息,实 体et字 形 信 息作为输入,则其对应的实体字形信息表示分别为和其中i表示实体的第i个字形,表示如图4.为输出维度.将实体的信息和实体字形信息拼接融合表示实体信息,则输出如公式(9~10).
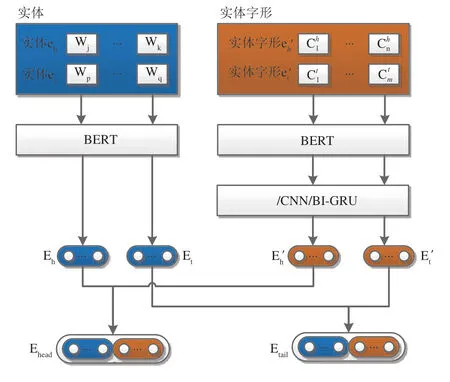
图4 实体信息融合表示Fig. 4 Entity information fusion representation
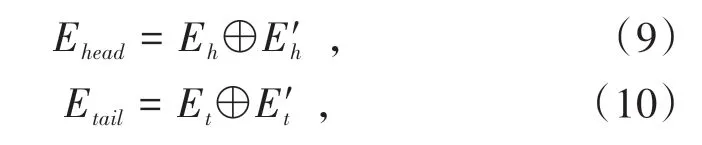
3.4 注意力层
模型中引入注意力机制,对句子中的词语添加权重,使神经网络更加注重句子中的重要词语.对于BI-GRU 输出的词向量H=(h1,h2,…,hn),其中n表示输入的句子文本的长度,首先通过tanh函数将原始的矩阵变换到[-1,1]之间,然后通过Softmax函数计算得到注意力权值α,最后用α对词向量矩阵进行加权得到示例向量N,输出如公式(11~13).
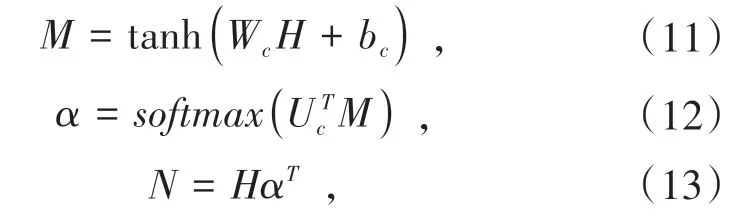
Wc、Uc、bc参数均是通过训练模型得到的.
输出层使用Softmax对句子、实体融合特征进行分类,Softmax函数将会计算出对每类别的倾向概率,取最大值作为该句子的预测类别.表示如公式(13).
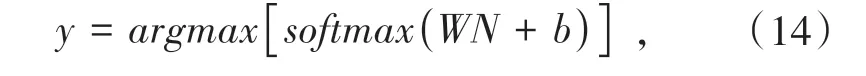
W和b分别为权重参数与偏置参数.
4 实验设计
4.1 数据集与评判标准
数据集是中国科学院软件研究所刘焕勇[21]和GUAN[22]发布的人物关系语料库.其中刘焕勇发布的数据集中包含12类人物关系,其人物关系对数量如表1.由于数据集未进行训练集和测试划分,所以以8∶2 划分训练集和测试集.Guan 发布的数据集中包含12类人物关系,其人物关系对数量如表2.采用评测指标为准确率.
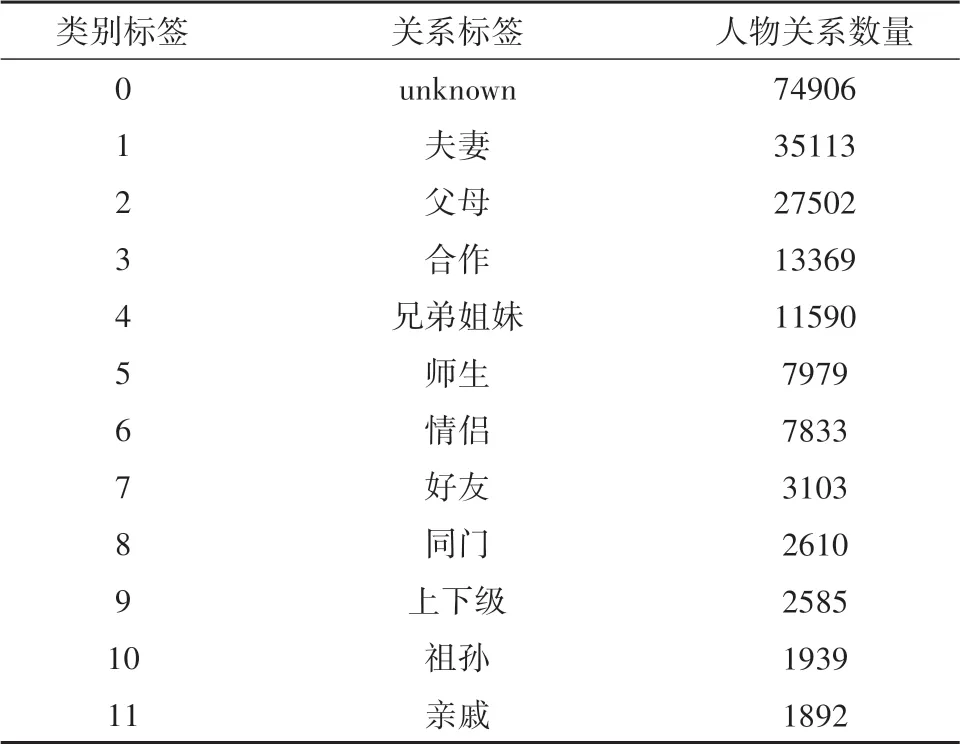
表1 数据集中的人物关系对数量Tab.1 The number of relationship pairs in the data set
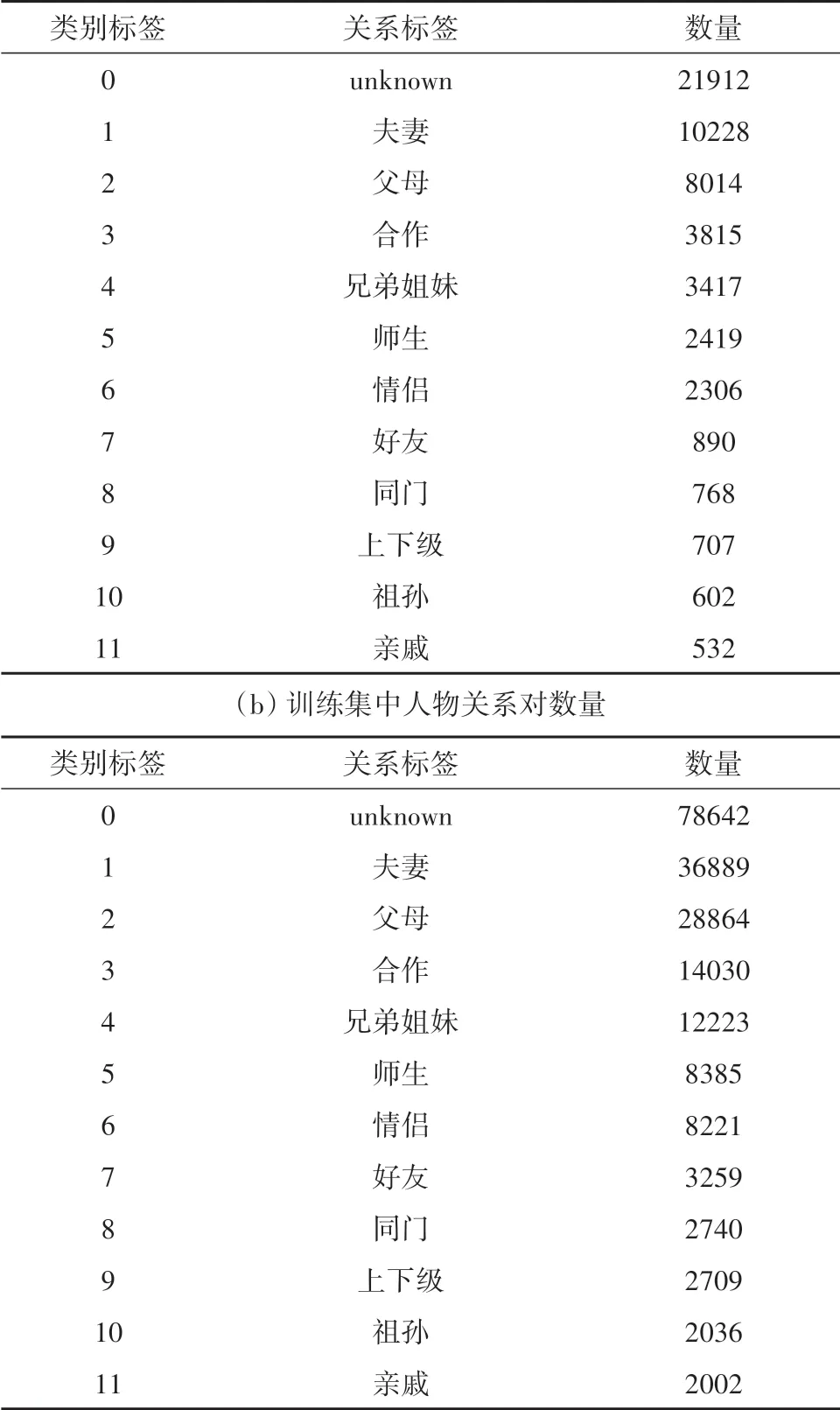
表2 数据集中的人物关系对数量Tab.2 The number of relationship pairs in the data set(a)测试集中人物关系对数量
4.2 实验环境及参数设置
实验中使用的语言是python 3.6,BERT 中文预训练模型使用的是Chinese_L-12_H-768_A-12,深度学习框架tensorflow1.15.句子的最大长度设为128,训练时的batch_size 设为30,学习率为0.001,epochs 设为30.为了获得更好的泛化性能,防止过拟合,在训练时加入了early stopping 机制,还在模型中多处中加入了dropout,其中dropout rate 为0.2,最后通过Adma优化器进行训练.
4.3 实验结果分析
为了验证融合了字形级特征的实体表示的效果,实验采用未融合的模型BERT_BI-GRU,融合的模型BERT_BI-GRU_Glyph.其次考虑到实体的字形表示也存在空间联系的、位置顺序关系,选取CNN对BERT编码后的向量进行信息增强BERT_BI-GRU_Glyph(CNN),选取BI-GRU 丰富字形的上下文信息BERT_BI-GRU_Glyph(GRU).实验结果如表3(其中ALL 表示数据集全部数据).
从表3中可以看到,对比实验2和实验4以及实验3和实验4,可以发现在模型中加入了BI-GRU后,关系抽取的准确率也有提升,在一定程度上弥补了Bert 官方的中文模型上的不足.对比基线模型(BERT_BI-GRU),使用实体字形信息的模型在不同量级的数据集上的所有关系抽取的准确率指标上都有一定的提高.在数据量级相对较少的情况下,其提升值最大;在量级相对较高的情况下,其准确率的基数也相对较高,其提高的度相对于小量级的稍低.通过使用不同的模型处理实体以及实体字形信息,通过实验发现,实体信息中不仅存在先前工作中忽略掉的字形信息,而且字形信息在排列上也存在隐藏联系.
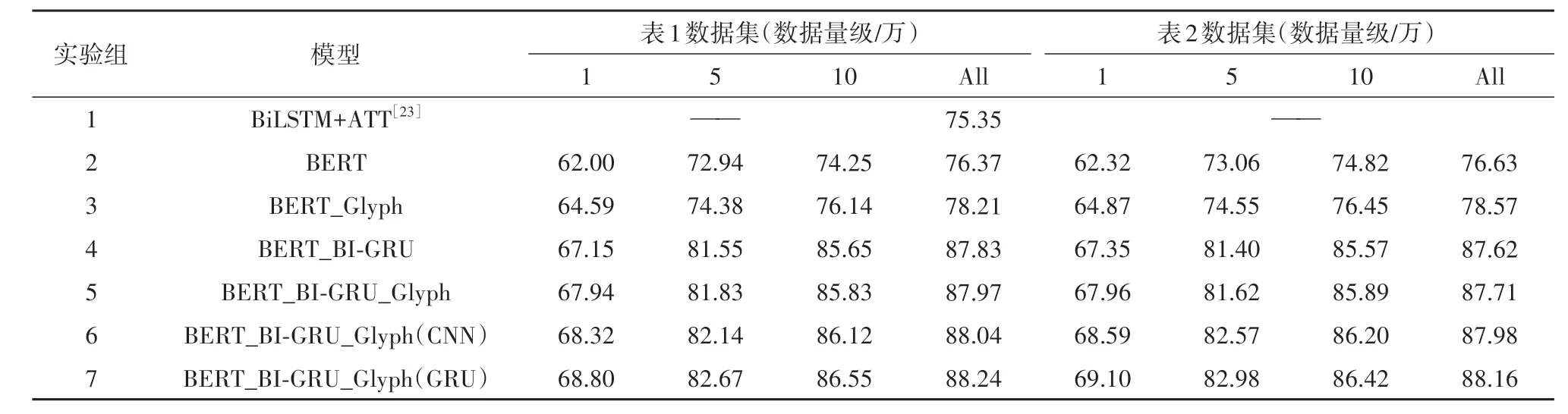
表3 模型在不同量级的数据集上的准确率(%)Tab.3 Accuracy of models on different magnitudes of data sets
实验中在数据集量级为5 万的情况下,对关系类别上进行对比,如表4.
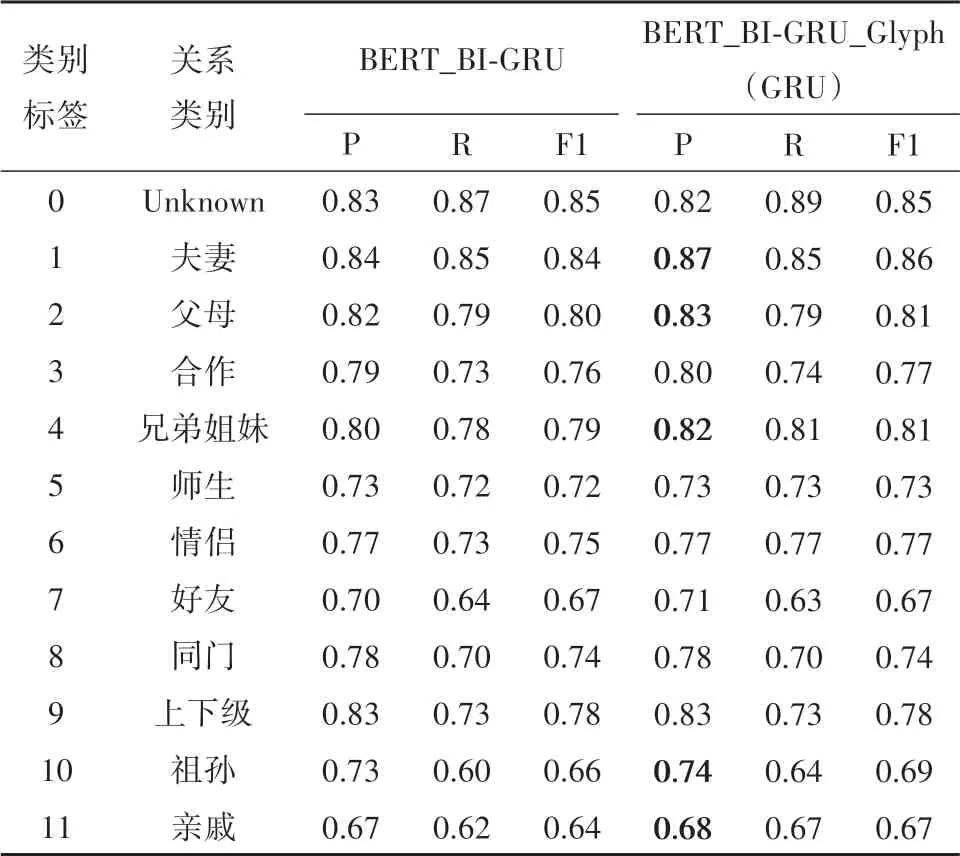
表4 各关系类型上的准确性Tab.4 Accuracy of each relationship type
如表4 所示,BERT_BI-GRU_Glyph(GRU)在大多关系上的准确率都有提高.但在有血缘关系的关系类型上相对明显,在这类关系中,实体的字形信息更加的突出,比如在红楼梦中贾母的三个儿女分别是贾赦、贾政和贾敏,他们三人在名字中都含有“攵”偏旁,其实在日常生活中也常常存在这样的现象.在农业领域、医学领域等,其字形的特征更为突出,融合字形的实体表示更能发挥潜在的价值.
5 总结与展望
针对中文关系抽取任务,本文提出了BERT_BI-GRU_Glyph 模型,基于汉字是象形字的特点,实体表示融合了字符级嵌入和字形级嵌入,丰富了语义信息.实验表明,字形级嵌入在关系抽取中有效性.目前,只涉及到人物关系抽取人物,但农业领域、医学领域等特定领域,其字形的特征更为突出.此外,在关系抽取任务中还可以融入多方面的外部信息,如实体说明,实体类型等.在未来的工作中,将尝试将其应用到特定领域的关系抽取中以及扩展实体的表示.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
计算机系统应用(2021年11期)2022-01-06
小学生学习指导(中年级)(2021年12期)2021-12-30
小读者(2021年17期)2021-10-20
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
小学阅读指南·低年级版(2016年5期)2016-05-14
初中生之友·中旬刊(2015年5期)2015-06-15
现代出版(2014年6期)2014-03-20
