
基于自监督的人脸面部动作单元检测
2022-03-09 07:25范耀文
科学技术创新 2022年5期
范耀文
(广东工业大学自动化学院,广东 广州 510006)
人脸表情对于人际沟通至关重要,而一般对表情的六种分类并不足以概括人类所有各类丰富的面部表情,因此相关学者提出了面部动作编码系统FACS (Facial Action Coding System)[1],将面部各个肌肉群的运动进行分类。随着自监督学习在机器视觉任务上的应用不断发展,使用自监督方法实现面部动作单元检测也就成为了一个十分重要的研究课题。
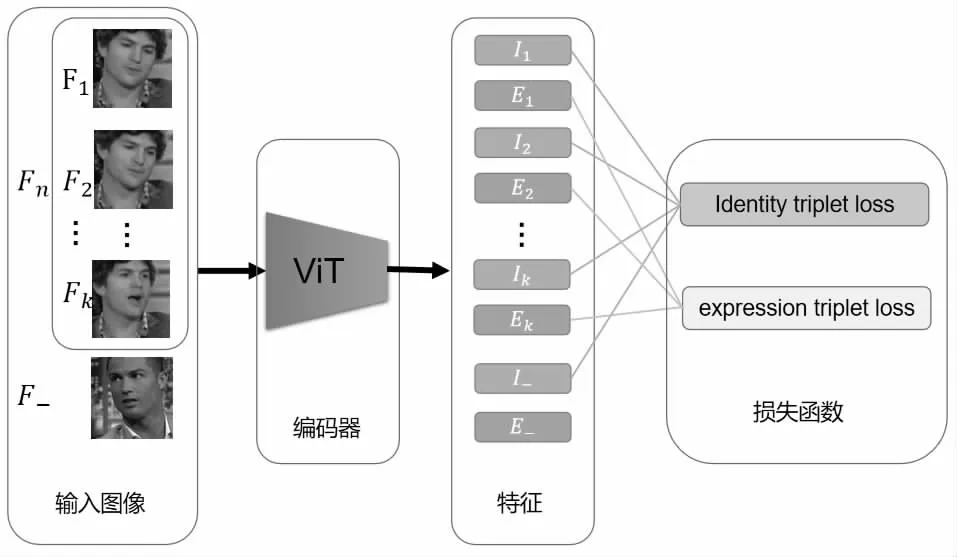
图1 本文网络结构
由于面部动作单元(AU, Facial Action Unit)的标注很困难,消耗大量人力,因此很多使用无标注图像的自监督方法在近年来被不断提出。FAb-Net[2]从无标注的人脸视频序列中提取图像帧,通过编码器对每帧图像进行特征提取,然后使用解码器由两帧图像的特征解码得到两帧图像之间的光流,由此可以通过图像对中一张图像生成得到另一张图像,目标是使生成图像与输入的另一张原始图像尽可能的相同,以此实现该自编码器网络结构的自监督训练。TCAE[3]则在此基础上进行改进,将两张图像帧之间的光流解耦为大幅度整体的头部姿态移动和小幅度局部的面部表情变化。Lu 等人[4]提出的方法则不使用光流以及图像重建,直接利用人脸面部动作变化的时域连续性,按照时间顺序对从每一帧图像提取的特征构造三元组损失函数,以此实现自监督训练,由于不需要解码器,该网络结构简洁,而且有着很好的扩展性。上述工作共同的不足之处在于,未能将个体信息以及背景信息去除,即对编码器提取特征的解耦不够充分,仍然含有大量无关信息,不利于后续下游任务阶段的训练,影响最终所得到检测器的性能。同时,这些工作中的解码器骨架都为最基本的卷积网络或尺寸较小的ResNet,而后续被提出的ViT(Vision Transformer)[5]利用自注意力机制,在很多机器视觉任务上有着出色的表现,这启发了我们将ViT 应用在人脸特征提取任务中。
针对上述问题,本文在Lu 等[4]工作的基础上,将编码器改为ViT 结构,该网络能够更好地提取特征,从而提升下游任务的性能。并将特征解耦为个体特征以及表情特征,由于面部动作单元检测等任务是与个体无关的,因此将不含个体信息的表情特征提取出来,更有利于面部动作单元检测这个下游任务的训练和表现。基于这些改进,本文提出的方法在同等实验条件下,在BP4D 数据集[6]上取得了超过其他已有最先进方法的结果。
1 本文方法
1.1 整体结构


1.2 特征解耦
为了给后续面部动作单元检测等下游任务提供含更少干扰信息的面部动作特征,对提取出的特征进行解耦,将其分为两组:个体特征和表情特征。其中个体特征包含人物个体的脸型、头发、服装、图像背景、光照环境等与面部表情无关的信息,而表情特征则是剔除掉上述干扰信息后较为纯净的只包含描述人脸表情和面部肌肉动作的特征。
为了实现该目的,本文方法利用了无标注人脸视频序列中天然存在的个体特征一致性,即在同一视频片段中,人物个体相同,且拍摄的背景以及其他因素的变化基本不变,而表情则不断地发生变化,由此我们可以限制同一视频序列中不同帧的个体特征之间的差异。然而根据对比学习的理论经验,此时编码器只需要输出与输入无关的恒定输出,即可保证不同帧的个体特征完全相同,而并没有提取人脸图像中的信息,因此需要额外加入其他来自其他个体的人脸图像作为负例,要求来自不同个体的人脸图像帧的个体特征之间的差异尽可能的大。通过以上设计,能够将人脸视频序列中不变的个体信息提取为个体特征,而将不断变化的表情信息用表情特征进行提取,实现了特征的解耦。
1.3 三元组损失函数
本文方法的损失函数由个体特征的三元组损失函数及表情特征的三元组损失函数两部分组成,见图2。三元组损失函数的基本构造为:

图2 个体特征及表情特征的三元组损失函数

其中d 代表两个输入之间的距离函数,δ 为一避免负例差异总大于正例差异而设置的常数。三元组损失函数能够同时限制使基准与正例距离最小,而与负例之间的距离最大,这一特性十分适合本文所利用的自监督信号。
对于个体特征,来自同一视频序列的不同帧之间应该尽可能相似,而来自不同视频序列的帧之间差异应该尽可能大,并且由于本文方法以k 帧的视频序列作为输入,因此选定第一帧为基准、其他个体的图像作为负例后,能将剩余k-1 帧分别作为正例,可以构造出个体特征的三元组损失函数:

Lu 等[4]的工作中使用了基于时域顺序的三元组损失函数,将视频序列第一帧作为基准,取之后的两帧图像,由于人脸表情的变化是连续的,因此可以认为在时间上更接近基准帧的图像应该与基准帧更接近,与之相比,时间上距离更远的图像则应有更大的差异。对于连续变化的表情信息,可以对本文方法中的表情特征构造出以下三元组损失函数:

该损失函数利用了人脸表情在时域上的连续性,能够驱使网络提取人脸相关信息,实现网络的自监督训练。
2 实验分析
2.1 数据集与评价指标
训练集使用VoxCeleb1/2[7],该数据集含有超过6 千位名人明星接受采访的约十五万个视频,涵盖了大幅度的头部姿态、低光、不同程度的镜头失焦模糊等极端情况。我们使用该数据集提供的已裁剪的人脸区域图像,并使用数据集已有的按照人物个体不同而划分的训练集和验证集。人脸图像帧作为输入给编码器前,会与先前工作一样,先进行中央裁剪和尺寸归一化。
评估数据集为BP4D[6],该数据集含有23 位女性和18 位男性总共41 人的人脸视频数据,其中有接近15 万帧二维人脸图像带有AU 标注。为了证明本文方法的有效性,我们使用和先前方法同样的数据集和处理流程进行训练和评估,考虑到评估数据集分布上存在的不均衡,都使用F1-score 作为评价指标。
2.2 结果分析
本文方法和其他已有自监督方法的F1 结果在表1 中列出,其中FAb-Net[2]和TCAE[3]的结果取自Lu 等[4]论文中进行的复现结果。可以看出本文方法取得了最优的平均F1 分数,相比Lu 等提升了2%,证明了本文方法的有效性。

表1 各方法在BP4D 数据集上的F1 结果
本文方法在大多数AU 项都取得了最高的F1,然而和Lu 等的方法一样,其中AU17 的检测效果不如先前其他方法。AU17 是一个下巴向上收缩挤压嘴唇的面部动作,该面部动作在外观上呈现为下巴部分区域向上平移,因此先前一些基于光流的工作可能更适合该类AU。但AU23 抿嘴和AU24紧咬牙关两项都有着加大的提升,合理的推测是因为本文方法中的特征解耦起了作用,特征解耦去除了干扰表情表征的个体信息,因此这两个在颜色梯度上不明显的面部动作能够被更好地检测。
2.3 消融实验分析
本文通过消融实验证明了两个改进的有效性,比较了单独替换ViT[5]作为编码器,单独解耦个体特征和表情特征,以及同时应用两者的结果,详见表2。

表2 消融实验结果
由表中数据可知,单独替换编码器为ViT 可稍微提升性能,而单独进行特征解耦则的性能提升幅度比前者更大,同时应用两种改进,则最终f1-score 指标结果有2%左右的提升。特征解耦的结构设计能够得到更少无关干扰信息的表情特征,能够使ViT 编码器更好地进行人脸特征提取,从而提升最终整体面部动作单元检测器的性能。
3 结论
本文提出了基于自监督的面部动作单元检测方法,进一步提升了面部动作单元检测器的性能。该方法利用ViT 的出色性能,得以更好地提取包含面部信息的特征。同时,对个体信息和表情信息进行解耦,去除了表情特征中原版含有的和人物个体相关的信息,从而使面部动作单元检测等下游任务能够得到具有更少干扰的面部表情特征。由于ViT 的自注意力机制需要较大的运算量,因此后续的工作主要会降低编码器部分的复杂度,转而在网络的整体架构以及损失函数上进行优化和改进。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
山西大学学报(自然科学版)(2021年1期)2021-04-21
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
动漫星空(2018年9期)2018-10-26
探测与控制学报(2015年4期)2015-12-15
