
基于结构内容特征的裁判文书自动推荐研究
2022-03-07 08:29梁柱沈思叶文豪王东波
情报学报 2022年2期
梁柱,沈思,叶文豪,王东波
(1.南京农业大学信息管理学院,南京 210095;2.南京理工大学经济管理学院,南京 210094;3.南京大学信息管理学院,南京 210023)
1 引言
互联网时代,信息的快速传播导致了新闻爆发式的涌现。与此同时,关于案件类新闻的讨论也在微博、微信、知乎等各大社交平台上展开。虽然新媒体上法律案件类新闻层出不穷,但是,这类新闻信息缺乏专业的法律层面的解读。因此,越来越多的学者关注到了法律领域信息搜寻的研究必要性。
2016年10月1日,《最高人民法院关于人民法院在互联网公布裁判文书的规定》正式实施。截至2020年8月30日,裁判文书相关检索网站就有中国裁判文书网、北大法宝网等,各大地方法院均有相应的官方网站可进行文书查询。仅中国裁判文书网站,裁判文书总上传量就已突破1亿篇。自此,这类裁判文书检索系统为用户提供了大量法律研究案例,为基本的法律案例检索提供了数据保障。裁判文书记载人民法院审理的过程和结果,它是诉讼活动结果的载体,里面包括了公诉机关、被告人、原告人、辩护人、审判机构、证据信息、法院判定依据以及参考的法律条例。在现有的大数据背景下,裁判文书的应用前景表现在:规范性、结构性的裁判文书能被实现自动化信息处理,其丰富的法律案例信息,能成为用户潜在的知识获取对象,但也需要法律领域大数据挖掘能力研究的提升;裁判文书的实用价值表现在裁判文书被审核多次,用词谨慎,语言规范性好,案件解释详细,可以为非专业用户提供相关案件推送的定制化服务。具体来说,用户根据特有的案例情况,可以获取到相关的裁判文书文档。
目前,裁判文书检索系统的不足之处主要在于数据资源更新缓慢,以及缺乏对裁判文书横向和纵向资源的检索展示。中国裁判文书网提供了基于裁判文书的结构化数据和全文数据的关键词检索,北大法宝等网站对裁判文书进行如案例焦点、核心术语等细粒度知识元标引,并提供对应检索功能。这类裁判文书检索系统对用户专业背景知识要求高,仅能满足法律研究者和法律实践者的检索需求。针对这类问题,本文根据新闻、事件等事实性文本内容特征,提出一种裁判文书自动推荐技术。
本文将类新闻的事实性文本作为查询式,以结构规范的裁判文书作为全文语料库,对裁判文书的传统检索方法进行改进;利用裁判文书结构内容特征将专业性的检索系统一般化,满足缺乏法律知识的非专业用户的检索需求;提出“新闻-文书”自动推荐系统框架,该框架可以实现为类新闻的事实性文本推荐相关裁判文书文档。
2 相关研究
裁判文书作为规范化的文本数据,具有特定的文本结构。目前传统的关键词检索技术和传统分类体系受限于裁判文书的数据情况,对用户领域知识要求高,限制了检索系统的用户范围。但是,人工智能等新兴的研究技术已经对法律领域文本数据开展了研究,法律类信息抽取等研究领域已经能逐渐满足信息检索技术发展的需要。在信息检索领域,特殊领域知识的信息检索技术已经有所突破,但缺少面向案件、新闻等一般化数据的研究内容。
2.1 裁判文书特点
李振宇[1]总结了法律文献特有的规范化的特征,规范化不仅反映在法律文书内容的规范,也反映在法律文书的程式上,即文书的特定结构特征。裁判文书作为法律应用文献中的法律文书文献,以司法文书为主,是反映司法活动的原始凭据。
传统的裁判文书分类体系以法律条文的分类体系为主,裁判文书涉及的量刑范围、施用的法律条文差异性大,具有特殊性,不利于传统搜索引擎按罪名分类标引体系进行检索。但是,此分类体系有助于我们按类别提取主题词。提取的主题词不仅有利于裁判文书做细粒度主题标引,也有助于我们对事实性文本内容进行表达。
另外,裁判文书的结构比较规范,主要分为原告(公诉机关)及委托代理人、被告及委托代理人、原(被)告的辩诉、书面证据列举、证人证言列举、法院意见、引用的法律条文以及法院审判人员信息,数据结构形式完整。
原告(公诉机关)及委托代理人、被告及委托代理人、书面证据列举、法院审判人员、引用的法律条文信息等结构化的数据信息,主要适用于关键词等传统检索方法,对用户的专业程度要求高。
原(被)告的辩诉、书面证据列举、证人证言列举、法院意见等非结构化信息,标引程度低,传统的检索系统处理方式简单,检索方式单一;但是,语言内容逻辑推理强,内容丰富,目前缺乏更深层次的语义理解技术。
传统的全文检索技术,忽略了裁判文书中的法院意见等关键结构信息;并且,裁判文书的这种规范化特征导致了用户的信息检索活动中,用户需要具备特有的专业法律知识,这种局限限制了检索系统的使用人群。
2.2 法律信息智能处理技术发展
法律文书在人工智能方向的应用已有国内学者[2]进行了详细概述,主要在文本信息处理、文本信息检索以及法律知识推理方向,甚至为中国相关法律的完善提供了依据,包括由人工智能等引起的法律问题。国外学者[3]总结了深度学习在大规模法律数据集上的使用,分别在文本分类、信息抽取以及信息检索三个研究方向进行了展望。
Giri等[4]认为法律文书用于信息检索需要构建语义网络,基本任务包括命名实体识别、词性标注、关系抽取等。张琳等[5]较早地使用了条件随机场(conditional random field,CRF)模型,并使用法律领域知识的相关词典对裁判文书中的罪名实体识别进行了研究,为后续法律知识推理提供了研究基础。黄菡等[6]在前人研究基础上,将主动学习过程的思想融入命名实体识别当中,使用CRF模型分别对罪名、刑罚、法律原则、法律概念以及法律条文进行识别,实现了对法律语料中的法律知识的自动识别。高丹等[7]结合深度学习的技术,在命名实体识别的基础上,提出了基于裁判文书的实体关系抽取的模型,该模型具有较好的抽取效果和较高的计算效率。这些工作极大地丰富了裁判文书的研究工作,为后续裁判文书的信息检索应用提供了基础。Li[8]提取英文法律文本的特征词,对法律领域的英文文本进行分类研究,结果显示,TF-IDF(term frequency-inverse document frequency)的 特 征 提 取算法能有效提升文本中法律条文的识别效果。陆伟等[9]和黄永等[10-12]在规范性文本上的结构化识别任务研究上取得了很好的效果。Zhuang等[13]为了识别目前纯文本的裁判文书潜在语义结构,提出了一种识别裁判文书结构的方法,并输出为XML文件形式,也为自动化提取裁判文书的结构信息奠定了基础。因此,本文在裁判文书的结构信息基础上提出了一种融入裁判文书的结构内容特征的智能推荐算法。
在法律领域的信息检索研究方向上,赵彦[14]论述了目前网络检索司法裁判文书的途径,总结出目前裁判文书检索的不足主要于在数据资源更新缓慢,以及缺乏对裁判文书横向和纵向资源的检索展示;认为需要多样化建立数据库,拓展裁判文书的智能检索。黄都培[15-16]利用本体构建的方法构建了一个法律主题词表,并提出了一个面向案例的法律信息语义检索模型,为法律领域的知识管理和信息检索提供了参考。邢启迪等[17]设计了一个法律文献关联模型,实现了SPARQL检索,从数据资源的层面上进行信息组织,实现了对细粒度资源的检索。Wagh等[18]基于裁判文书自身的专业性的特点,提出了基于概念的法院判决结果相似度的方法,该方法融入了法律专业概念信息,在结果表现上具有很强的竞争力。为了解决传统信息检索系统空间和时间利用的问题,Padayachy等[19]利用图数据库对法律文本数据进行存储,实验证明该方法有利于提高用户的信息检索效率,但是,该数据存储模型仅在少量数据上进行了验证。同样地,Kanapala等[20]为了解决检索法律类文本过程中产生的空间和时间消耗大的问题,提出了一种法律信息自动摘要的系统,结果显示自动摘要技术能有效提升信息检索的效率。
在传统信息检索方法的基础上,部分学者已经将深度学习等方法应用到法律领域的信息检索研究中。Marques等[21]用XGboost的方 法和FastText提 取文本特征,对法律文献的法律条文的推荐进行了排序改良。陈文哲等[22]认为,法律文书事件存在一个潜在的时间序列信息,利用文本中行为序列信息结合卷积神经网络模型对语料进行了法律条文预测。国内外已有学者研究法律领域内的知识问答系统,为用户所提出的法律纠纷提供参考解决方案[23-24]。目前,比较成熟的法律领域的应用方案是阿里实验室所提供的多任务下的电子商务法律人工智能,其利用特有的买卖双方的交易相关数据,为合同争议提供自动化解决方案[25]。但是,目前法律领域的智能检索研究数据多样性高,检索条件苛刻,而本文裁判文书的自动推荐框架检索条件宽松,类新闻的事实性文本更易于被用户所接受。
本文所使用的数据是事实性较强的新闻数据,用于模拟非专业用户的查询需求。新闻数据有口语化对事情经过的描述特征,与非专业用户的法律检索查询式描述相近。因此,本文将新闻类文本和裁判文书等规范化文本进行相似度匹配,扩展传统裁判文书检索系统的检索途径,实现依据事实性文本智能推荐裁判文书的功能框架。
3 相关模型
本文为了将裁判文书的结构信息和内容信息融入裁判文书信息检索系统中,利用BM25模型计算特征词和文档相似度,并用事实性文本中不同特征词的BM25值作为多维度特征融入相似度算法中,从而获得事实性文本和裁判文书的全局相似度。
BM25模型是一种评价搜索词和文档之间相关性的算法,其公式表达式为

本文利用SvmRank算法和LambdaMART算法对多维度特征词的BM25值进行拟合,实现对新闻语料和裁判文书之间的整体相似度计算。
Joachims[26]提出了基于SVM(support vector ma‐chine)[27]的排序学习算法SvmRank,将排序问题转化为一个二值分类问题。其基本思想是给定一个数据集{xi,yi},其中yi∈{1,…,R},存在一个函数h(x)满足h(xi)>h(xj)⇔yi>yj。因此,给定事实性文本的相关裁判文书文档集{xi,yi},则相关裁判文书文档关联对{xi,yi}及其相关性标注y构成训练数据ρ={(xi,xj),yi,j},yi,j表示裁判文书和事实性文本文档对之间的关系。设m=|ρ|,则SvmRank的优化问题可以转化为数学形式:

找到一个线性函数h(x),使训练语料集有相应的一个顺序,即有序回归。该算法可以融入新闻语料特征词BM25值表示的多维度向量,并有效提升文档相似度计算效果,从而计算新闻语料中特征词和裁判文书在整体上的相似度。
LambdaMART算法[28-30]目前在信息检索领域,特别在Yahoo!Learning to Rank挑战中取得了不错的成绩,其算法本质可以广泛应用在排序任务中,包括但不限于广告推荐、自动打分等。LambdaMART算法是由RankNet、LambdaRank等算法改进而来的。RankNet算法[28]基本思想是提供一个打分函数si=f(xi),其中xi表示事实性文本所提取的特征词向量表示;然后计算裁判文书文档i排在裁判文书文档j之前的概率值,其计算公式是P(Ui⊳Uj)=其 损 失 函 数指的是裁判文书文档i在裁判文书文档j之前的真实概率,Pi,j是裁判文书文档i在裁判文书文档j之前的预测概率。LambdaRank算法在RankNet算法的基础上提出了一个加速优化的算法,为在公式中引入信息检索评价指标提供了可能。
LambdaMART算法在LambdaRank算法的基础上采用MART(multiple additive regression tree)方法来优化目标函数,基本思想是训练一个弱模型的集成,组合每一个弱模型的预测,成为一个比单个模型的预测更强大和更准确的最终模型。
本文依据不同结构内容建立特征词索引,使用特征词对事实性文本内容进行表达,将多维度的特征词信息融入相似度算法中,并对模型的目标函数进行优化,从而计算事实性文本和裁判文书的全局相似度,以匹配具有多样性特征的裁判文书。
4 基于结构内容特征的裁判文书自动推荐框架
4.1 文本特征的选取
文本特征分为两个部分:①查询式的语义表达。本文使用新闻类事实性文本语料作为非专业用户的查询式。②裁判文书结构索引的构建。本文使用具有明显结构特征的裁判文书作为语料库,构建结构索引。
4.1.1 法律文本语料的特征词
(1)生产见习示教前30分钟,示教老师在多媒体等教学设备辅助下进行课程的讲授;2)学生到病房对患者进行生产实践,历时30分钟询问患者病史并对患者进行体格检查;3)回到教室后用约1小时由学生与老师进行总结。
裁判文书的刑事案件领域具有较强的粗粒度分类标准,即每个裁判文书都被赋予一个或多个的刑事罪名,该罪名的标签又可以视为裁判文书的标引词。因此,裁判文书的检索系统多以刑事罪名的分类系统作为裁判文书分类检索,也是目前最常见的检索手段。
裁判文书类的规范化文本具有较强的定性表达,如罪名表述、案件定性等。但是,新闻语料具有比较强的事件陈述性质,而裁判文书仅在庭审过程等结构中存在事件陈述性质的内容。因此,本文探究了从这类结构内容中提取关键词以增强文本相似度计算效果的思路。
目前,比较常见的特征词提取算法有TF-IDF算法、互信息、信息增益等。TF-IDF是一种经典的文本关键词提取算法,主要从特征词在所有文档中出现的次数和特征词在本文档出现的次数两个方面出发,计算特征词对于文档的相对权重,主要思想是弱化高频词、停用词对文献的影响。信息增益是通过计算该特征词t是否为一篇文章在类别c中出现的概率来得到的。互信息是通过计算特征词t能为类别c提供的信息量来获得的。
TF-IDF算法能在规范化文本中忽略掉常用词,提取与文本主题相似的主题词,这类主题词能有效描述文本中的主要事件动作,增强文本语义相似度计算效果。因此,本文选取TF-IDF作为特征词选取算法,从裁判文书中提取与罪名类型相关性高的特征词。在此基础上,用特征词对事实性文本进行语义表示,分别计算特征词与裁判文书之间的BM25值,融入SvmRank算法和LambdaMART算法中,从而计算裁判文书与事实性文本之间的整体相似度。
4.1.2 裁判文书的结构特征
裁判文书具有相对清晰的标准结构,而每个结构之间存在着相对固定的功能,裁判文书的结构范例如表1所示。

表1 裁判文书结构信息范例
庭审过程内容记载了辩护双方所提供的证据和供词,而法院意见部分一般为法院对事实部分的认定和描述,以及罪刑的审判,这类部分基本为半结构化数据。其中,原告(公诉机关)及委托代理人、被告及委托代理人这类信息多以结构化形式存储于数据库中,庭审过程和法院意见以非结构化文本数据为主。结构化数据已广泛用于目前的信息检索系统。
从裁判文书的非结构化数据上看,法院意见是法院对案件事实认定之后的陈述,对事件发生有较为明确的定性;而审判过程多为辩护双方的陈述,事件描述性内容较多,但是,部分事实法院不予认定。因此,裁判文书的不同结构内容信息会对信息检索系统在计算文本相似度时产生影响,主要表现在法院认定的事实与双方陈述意见存在差异,合理使用这类差异有助于扩大信息检索系统的查全率和查准率。陆伟等[9]、黄永等[10-12]对学术文本的结构功能识别开展了一系列研究,论述了文献结构功能对信息检索、关键词提取等研究的积极作用。与此同时,Zhuang等[13]在裁判文书结构识别的研究上开展了相关工作。因此,这类智能化抽取裁判文书的结构特征的研究有助于法律信息检索技术的改良。
4.2 “新闻-裁判文书”推荐系统框架
本文的推荐系统框架主要分为:①裁判文书的结构化索引构建;②新闻语料文本特征提取。裁判文书结构索引构建,主要目的是实现裁判文书文本结构化,并对裁判文书不同的结构信息建立索引。新闻语料文本特征提取,主要目的是对新闻语料进行语义表示,提取特征词增强长文本检索效果。最后,根据相似度排序算法进行迭代学习,并输出相关裁判文书文档集。具体框架如图1所示。

图1 “新闻-裁判文书”推荐系统框架
裁判文书结构索引构建,包括对裁判文书的文本结构化和倒排索引的建立。本文所使用的裁判文书是结构信息人工标注规范的裁判文书文档集。本文通过对裁判文书不同结构信息的分词等文本预处理,形成了具有结构内容信息的裁判文书倒排索引。
新闻语料文本特征提取,包括对新闻语料文本的预处理和特征词提取。本文通过对文本进行分词处理剔除一些无意义的词汇和低频词,形成相应的新闻语料文档的词集,并用特征词提取算法形成的特征词词典对新闻语料进行特征词语义表示。
本文根据新闻语料的多类别特征词和裁判文书文档的BM25值形成多维度语义向量,并使用相应的文本相似度算法、LambdaMART算法和SvmRank算法计算新闻语料和裁判文书的语义相似度。用户可根据其算法按相关度降序排列推荐的裁判文档,根据需求对相关度高的裁判文书进行参考、获取知识,包括但不限于律师推荐、法律条文参考、证据固定等,满足使用类新闻的事实性文本内容获取相关法律类信息的检索需求。
5 实验设计与实施
5.1 实验语料集的建立
本文所使用的语料集,是以openlaw.cn提供的结构化语料库作为法律文书的全文语料集,用于提供相关法律文书的候选集。openlaw.cn提供的语料集不仅包含每个案例相应的案件罪行,也提供了法律文书的结构信息,方便用户检索。本次实验聚焦于刑事案件的文献,该类型的法律文献资料逻辑比较清晰,相关新闻多于民事案件,有助于数据的采集。其中,刑事案件文献共7320篇,其裁判文书案件的类型分布特点统计如表2所示。

表2 刑事案件的犯罪类型统计(前10位)
从表2可以明显看出,盗窃罪的犯罪类型明显高于其他罪刑;从第8位的抢劫罪开始,其他犯罪类型的文书数量有着明显下降的趋势,并且,根据统计数据显示,裁判文书涉及的犯罪类型共计175种,可以发现裁判文书的罪刑类别分布广,传统的分类检索体系加大了用户的信息检索难度。
另外,本文统计裁判文书记载的案件中所涉及的犯罪类型数,结果如表3所示。
从表3可知,法律文书涉及的罪名数呈阶梯式分布,涉及1个罪名的文书数量占76.67%,涉及2个罪名的文书数量为18.51%,而不少于3个罪名的文书数量为5%左右。由表3可知,裁判文书案件性质以单一罪名为主,但仍有约25%的裁判文书含有2个或2个以上的罪名。因此,裁判文书涉及的量刑范围、施用的法律条文差异性大,具有特殊性,不利于传统搜索引擎按罪名分类标引体系进行标引检索。这项统计结果正符合上文所总结的裁判文书的内容特点,也从侧面印证了本项实验研究的重要性。

表3 法律文书涉及的罪名数
本实验中的新闻语料集源于法律新闻网(http://www.chinalawnews.cn/)刑事案件中的150篇新闻。通过以下步骤进行处理:①筛选出经法院审理之后的新闻语料;②人工根据新闻内容对语料进行“案件类型”标注;③删除有判决信息的内容,只留下新闻陈述内容。最终获取到有效新闻语料75篇,其中15篇作为测试集,用于评价模型效果。
相似度打分使用新闻语料的罪刑类型和法律文书的罪刑类型进行匹配评价,主要算法为汉明距离,罪刑类型越相近,相似度打分越高,即罪刑基本一致。其他语料的相关度默认为不相关文献,即为0。
5.2 实验结果评价
5.2.1 实验的评价指标
本次测评实验是改进检索系统的检索效果,使用NDCG(normalized discounted cumulative gain)对此次实验进行评价。NDCG是根据累计增益(cu‐mulative gain,CG)、折损累计增益(discounted cu‐mulative gain,DCG)的评价方法逐步改进而来的。
累计增益方法是指定位置上的相关性总和,指定位置p的CG计算公式为
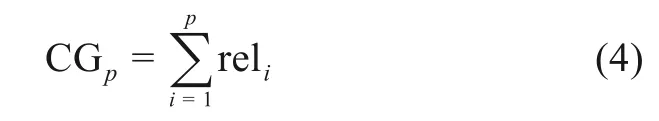
其中,rel表示位置i上的文献相关度。
折损累计增益方法是将检索结果的排序信息加入对检索结果的评价上,其位置p上的DCG计算公式为

评价指标NDCG是比较预测出的结果和理想中的预测结果,对预测出的检索结果进行归一化处理。前p个检索结果的评价公式为
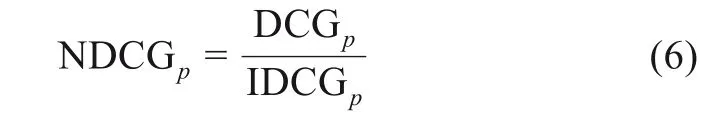
其中,IDCG表示理想中的检索结果,即根据相关度大小降序排列相关文档。
NDCG能很好地反映模型计算的相似度和理想相似度之间的差异,NDCG值越大,模型相似度估计的效果越好。本文将选取NDCG(1)、NDCG(5)来反映系统最相关文档的排序情况,选取NDCG(10)、NDCG(20)来表示系统返回较多文档时,相关文档的推荐情况,综合评判文本匹配模型检索效果。
本次实验的评价结果是取测试集中多个查询式的NDCG的平均值作为最终的评价指标。
5.2.2 实验结果比较
本次实验首先利用BM25算法对特征改进算法的效果进行了验证,主要包括将新闻语料用词袋模型表示,以及利用已知的裁判文书文本提取相关关键词对新闻语料进行标引,根据标引结果进行检索。实验结果如表4所示。
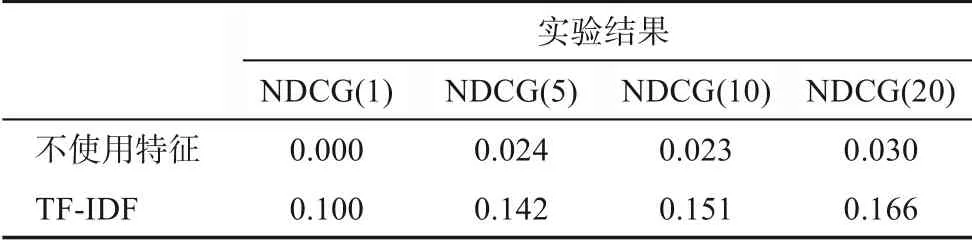
表4 特征词在BM25算法的表现
如表4所示,不使用特征的实验结果比利用TF-IDF提取特征词之后的文本表达要差。不使用特征词的BM25算法,由于新闻语料的文本较长,潜在查询词过多,增加了该算法相似度计算难度;并且文中含有的大量无意义词汇,如人名,对相似度计算无促进意义,因此,在使用特征词提取算法后,选取内涵丰富的非低频词,用于构建事实性文本的查询式,有利于提高事实性文本作为检索式的推荐结果。在后续实验中,我们将使用TF-IDF算法提取文本关键词,对文本进行标引,降低计算复杂度和提高模型的推荐效果。
同时,本文也将裁判文书的文本结构纳入文本匹配模型的考虑范畴并设计实验,结果如表5所示。
如表5所示,从不同文本匹配模型的表现结果来看,在法院意见部分,BM25模型表现结果最差,SvmRank模型和LambdaMART模型均有不同程度的提升。在使用审判过程和全文本结果结构内容特征时,BM25模型的检索效果仅在NDCG(1)和NDCG(5)的评测中高于SvmRank模型,在NDCG(10)和NDCG(20)的评测中,SvmRank效果明显高于BM25。分析其原因,可能是裁判文书的内容增加时,利用关键词匹配的方法,有利于文档中词的相互关联,使最相关文档排位靠前;SvmRank模型是在全局数据中找到一个有序回归的最佳界限,使相关性高的文档尽可能地排在相关性低的文档之前,因此,其在NDCG(10)和NDCG(20)的NDCG表现结果依然好于BM25算法。而LambdaMART模型在不同的文本结构下均优于其他检索模型。

表5 模型结果在不同结构上的表现
从不同的结构内容来看,以表现较好的Lamb‐daMART模型为例。该模型在NDCG(1)和NDCG(5)的评测中表现较好的是仅使用法院意见结构内容特征,在NDCG(10)和NDCG(20)的评测中,表现较好的是仅使用审判过程结构内容特征,而将两者综合时,模型的表现结果有一定程度的下降。分析其原因,可能是审判过程的文本中含有大量多角度陈述且事实不清的内容,如双方意见的陈述,其内容一定程度上法院不予承认,造成了文本相似度计算的偏差;但是,该内容有利于扩展潜在相关文档。因此,在仅使用法院意见结构内容特征时,Lamb‐daMART模型返回的前几个结果相关度排序更加相关,而使用审判过程结构内容特征时,该模型能返回更多的相关文本。而使用全文本的匹配方式时,模型效果趋于平均,不利于计算事实性文本和裁判文书之间的相似度。对于BM25算法而言,在对查询式进行特征提取之后,使用审判过程结构内容特征能有效提高查询效果,可能原因是在使用审判过程结构内容特征之后,BM25算法可以获得较大的匹配概率。而SvmRank算法在不同的结构内容特征下,其表现波动情况和LambdaMART模型类似,由于其结果表现太差,不具备对比条件。
因此,LambdaMART模型利用特征词提取算法构建文档相关度矩阵,并使用文本结构特征能有效提高仅使用全文本内容的检索效果,而使用法院意见的文本内容和使用审判过程的文本内容各有优劣。对于裁判文书推荐来说,本次实验使用的是有限的语料数据集,在目前裁判文书网所形成的大量数据集的情况下,利用法院意见部分做文本推荐工作会有较好的结果。
6 结语与展望
本文为了解决目前法律类搜索引擎在非专业用户中的局限性,扩大法律类信息检索的用户范围,在传统搜索引擎的法律条文检索和细粒度知识元的检索之外,提出了一种利用类新闻语料文本的智能推荐框架,来解决非专业用户在法律领域的信息检索问题。
裁判文书特有的内容特征为非专业用户的信息检索带来了困难,但也有助于我们从结构内容特征方向上对相关文档进行深度标引。从裁判文书的主题特征,即引用的法律条文、法院认定的罪型名称来看,裁判文书涉及罪刑广、牵涉法律条文多且部分裁判文书涉及多个罪名的认定,传统的分类体系不利于用户的信息检索。从裁判文书的结构内容特征来看,其结构比较明显,但是在不同的结构内容中呈现为不同的数据形式。裁判文书的结构化数据已经广泛用于目前的检索系统当中,而对于部分非结构化数据,以现有检索技术无法降低用户的检索难度。
针对非专业用户的裁判文书检索问题,本文利用裁判文书的特征词和结构内容特征,提出了一个基于结构内容特征的裁判文书自动推荐框架,改良了传统全文检索模型BM25在使用类新闻语料的事实性文本中进行检索的不足。在此基础之上,本文利用SvmRank算法和LambdaMART算法,融入裁判文书的结构内容信息,提升了依据类新闻语料的事实性文本进行信息检索的效果,从而更好地实现了非专业用户的法律信息检索需求。
最后,结合本次实验研究,裁判文书未来可以研究的主要方向包括:
(1)证据信息和陈述信息的信息抽取研究。本文在进行相似度计算时,由于目前信息抽取技术的局限性,无法将证据信息纳入相似度计算中,这类信息有助于帮助用户寻找关键信息点。
(2)裁判文书的知识图谱构建。未来研究可以重视法院意见和证据信息、陈述信息的关系抽取研究,有助于构建法律知识图谱,从实体、属性、关系三维度提高知识表示学习、知识获取、知识计算等模型效果,从而实现法律类信息搜索系统的自动问答。
猜你喜欢
中文信息(2022年3期)2022-12-07
计算机技术与发展(2022年8期)2022-08-23
计算机系统应用(2021年9期)2021-10-11
厦门大学学报(自然科学版)(2021年4期)2021-06-22
现代信息科技(2020年18期)2020-02-22
计算机应用与软件(2018年9期)2018-09-26
科技与创新(2018年2期)2018-01-09
外语教学理论与实践(2014年2期)2014-06-21
图书馆界(2013年5期)2013-03-11
教学与管理(理论版)(2009年9期)2009-11-04
