
科技项目及其成果文献的相关性评估研究
2022-03-07 08:29梁继文杨建林王伟王飞
情报学报 2022年2期
梁继文,杨建林,王伟,王飞
(1.南京大学信息管理学院,南京 210023;2.江苏省数据工程与知识服务重点实验室,南京 210023;3.江苏省科学技术情报研究所,南京 210042)
1 引言
科技项目是侧重科学研究与技术开发的独立项目,旨在为社会经济发展与技术创新提供支持。近年来,国家在完善相应政策法规的同时,着力提升对科技项目的资助力度以鼓励科技创新,因此,科技项目肩负了更多的社会责任与使命。
高效的情报服务有助于提升科技项目政策法规的实施效果。科技项目后评估是情报服务流程中的核心环节:在科技项目通过考核之后,科技情报服务部门对有效的科技资源进行整合、组织与分析,获取的科技情报可对立项指南进行动态反馈,并提供指向性较强的科技情报服务,尤其是满足企业/产业的情报需求[1],更好地促进官产学研融合与科技知识成果转化,从总体上发挥科技情报服务的支持决策的功能。目前,科技项目管理中“重申请,轻评估”的现象时有发生,后期监管力度欠缺,如何提升科技项目后期管理的效果成为学界关注的重点。
现有研究多数围绕科技项目后评估指标体系的构建展开,指标主要由成果产出、获得奖励、培养人才等几部分构成[2]。成果评估部分倾向于使用文献外部计量指标,例如,以成果数量来评估项目完成程度与工作量、以成果的被引数量来评估项目的质量等,这与我国新时期科技评估“破四唯”的理念背道而驰。“重量化,轻质性”的成果评估会诱发一系列问题,例如,成果文献研究内容与其初始设定研究内容不符,实际项目完成情况与预期结果相去甚远,项目后评估的高分项目名不副实、影响评审公正性,等等。产生上述问题的根本原因在于未能对成果内容与科技项目的相关性进行评估,导致部分科技项目利用与项目自身不相关/低相关的成果文献充数。因此,对科技项目及其成果文献的相关性进行评估成为科技项目后评估体系中不可或缺的一环,这有助于科技项目产出更多高相关、高质量的成果,发挥更多的应用价值与社会效益。
本文拟选取2012—2019年江苏省的科技项目,使用基于伪标签的半监督学习方法,构建基于BERT(bidirectional encoder representations from transformers)架构的相似度计算模型,旨在通过科技项目与成果文献的语义特征,识别出部分相关性较低、研究内容相对不相符的“可疑”的成果文献。基于此对科技项目、成果文献以及科技报告中存在的问题进行分析,促进科技情报服务机构对科技报告资源的优化建设与合理利用,完善科技项目后评估体系,综合提升科技情报服务效率。
2 相关研究概述
通过同行评议来评估申请项目属于项目的“前评估”,而通过科技项目管理部门对科技项目的成果进行评价属于项目的“后评估”[3]。现有科技项目后评估研究可分为三类。
1)后评估指标体系构建研究
项目后评估主要发生在项目管理的验收评价与跟踪评价阶段,两个阶段具有不同的指标体系:首先,在验收评价阶段,主要基于科技管理的视角来构建指标体系,使用定性方法分析项目方案的合理性、项目完成度、完成质量等。其次,在跟踪评价阶段,主要基于绩效评估的视角构建指标体系,成果产出为“绩”,成果效益为“效”。成果产出评估大多使用定量指标,如成果论文/专利数量、成果被引数量、获奖数量等,而效益评估使用定性与定量的方法,定性分析经济/产业/技术的持续发展情况,定量计量新增产值/销售额等。
国家自然科学基金委员会管理科学部侧重于跟踪评价阶段,设置了六类一级评估指标:报告论著、学术创新、政策建议、效益水平、国际交流与人才培养[4];地方科技项目评估则将验收评价与跟踪评价两阶段相融合,综合构建评估指标体系[5-7]。
2)后评估方法研究
传统的科技项目后评估方法主要包含专家法、对比分析法、逻辑框架法、层次分析法、模糊层次分析法、模糊综合评估法等。近年来,学者进行了评估方法的创新,如基于DEMA(double exponen‐tial moving average)-模 糊 综 合 法[8]、数 据 包 络法[9-10]、加权分值计数[11]等方法构建绩效评估模型,以及使用新兴机器学习技术,如BP(back propaga‐tion)神经网络、SVM(support vector machines)等模型构建项目评估模型[12]。
3)后评估结果应用研究
后评估的成果评估结果具有较高的应用价值,例如,基于国家自然科学基金委员会后评估结果分析特色结项单位、特优立项人、结项单位优势学科[4];基于地方科技管理部门后评估结果,围绕技术发展、资源配置、科技成果转化等情况进行不同省份间的横向对比[9-10,13]、省份内部的纵向分析[14],促进了区域间的合作与联动;基于文献计量指标分析科技项目对文献被引的影响、项目与引文的关系[15-17],或使用CiteSpace等科学计量软件,通过科学知识图谱将项目成果评估可视化[18]。
根据现有研究关注指标体系的构建与调整,或成果评估结果的应用与分析,可以看出,成果评估是后评估体系的核心。但相关研究侧重于从定量角度利用相关计量指标进行评价,缺乏对科技项目和成果文献的内容相关性评估。因此,有必要利用科技项目成果的内容特征完善科技项目后评估体系。
3 研究方法
本文以江苏省科技项目为例,通过语义匹配程度对科技项目及其成果文献的相关性评估进行探索与实践。
目前,科技文献数据库常常以成果信息为主,仅标注了科技项目的编号与名称,蕴含科技项目信息较少。由于科技项目名称长度受限,语义信息匮乏。此外,存在以下情况:①项目名称缺失,如项目名称为“江苏省XX项目”;②项目编号有误,如项目编号中数字1误写为L、数字2误写为Z等;③项目编号对应项目不唯一,如编号BK2XXX56同时对应“江苏省自然科学基金”与“江苏省高校自然科学基金”,编号BK2XXX26同时对应“江苏省自然科学基金”“南通市科技计划项目”与“南通市应用研究计划项目”。这些情况导致部分科技项目和成果文献不对应,需要进一步补充项目的相关信息。科技报告反映了科技项目的预期目标、研究内容与进展,记录了科研活动全流程,可以为科技项目提供补充信息[19]。因此,本文使用科技报告外部信息补充项目的外部特征,使用高度概括研究内容的科技报告摘要补充项目的内容特征。
现有研究常使用二分类方法判断文本相关性,但在本研究中存在以下难点:深度学习参数优化依赖大量标注数据,目前缺少面向中文科技文本的相关性标注数据集,而大量人工标注的准确性需要把控,时间成本较高,无监督学习则难度较大。本研究使用数据增强的方法(data augmentation)对少量标注数据进行扩充,用于缓解特征稀疏。本研究数据(详见第4.1节)具有以下特点:成果作者通常与项目负责人属于相同的学术社团/机构,即使成果内容与项目内容相关程度低,由于学术社团的研究领域相近,成果与项目仍同属于同一领域或相近研究方向。因此,模型需要对较小的语义差异敏感,通过数据的相似传递性来进行数据增强。具体过程为:若A与B相似,A与C相似,则可得B与C相似;若A与D不相似,则可得B/C与D不相似。使用该方法可将生成数据的相关性限定在一个可控差异的范围内,使模型对较小的语义差异更为敏感。
3.1 研究框架
本文的研究框架如图1所示,总体上由数据采集与预处理、无监督相似度排序与基于BERT的相似度计算三部分构成。
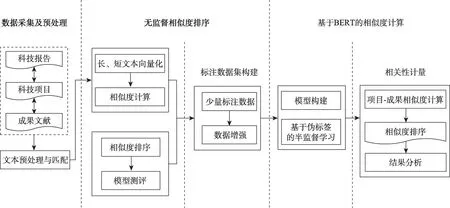
图1 科技项目及其成果文献相关性研究的总体框架
项目与成果的数据采集与预处理详见第4.1节。在无监督相似度排序部分,将标题/关键词短文本与摘要长文本向量化后,通过不同方法计算向量相似度来衡量项目-成果的浅层语义相似度,排序后获取不同阈值下最不相关的项目-成果,人工标注少量数据后,进行模型测评;使用相似度排序对数据进行强相关与不相关数据筛选,根据相似传递性进行数据增强构建标注数据集。在基于BERT的相似度计算部分,构建并训练基于BERT架构的相似度计算模型,对科技项目-成果文献的相似度进行计算并排序后,分析低相关成果文献。
3.2 模型构建
3.2.1 无监督语义相似度计算
在衡量文本相关程度时,现有研究常常计算文本余弦相似度,然后根据阈值来进行相似性判定,但余弦相似度衡量向量空间中的向量夹角,与数值差异相比,方向差异更为敏感。假设有科技项目Fa,对应成果文献Pa1、Pa2,在缺少语境与对照信息的前提下,即使cos(Fa,Pa1)>0.9也无法直接证明成果文献Pa1与项目Fa相关,因此,直接通过设定阈值进行判断的意义较小。本研究采用排序思想,即强相关成果文献研究内容与项目更相似。假设cos(Fa,Pa1)>cos(Fa,Pa2),则 与Pa2相 比,Pa1和Fa的相关性更高。
项目和成果文本主要包含标题、关键词短文本与摘要长文本,本文将长、短文本分而论之。对于摘要长文本,分别使用三种方法计算相似度。
(1)M1:使用词嵌入将文本向量化,将词向量相加求平均值获得句向量,计算句向量的余弦相似度。
(2)M2:根据词汇在文本中的重要程度计算词向量的权重,将加权词向量相加获取句向量,计算句向量的余弦相似度。
(3)WMD(word mover's distance):充分利用词嵌入的领域迁移能力的同时,不依赖标注数据,可将相似度计算任务转化为线性规划问题,并拥有全局最优解。
上述三种方法均使用word2vec进行词向量的训练,可将高维稀疏的文本表示为低维密集、蕴含丰富语义信息的分布式词向量,在一定程度上对标题与关键词短文本词向量进行扩展[20]。
对于关键词短文本,本文使用互信息均值来计算项目-成果相关程度。因为互信息较大的两个词经常同时出现,所以可以体现出两个词相互依赖程度。本文将成果与项目的关键词进行匹配。匹配不成功的成果关键词由多个词组成,将其分词后再次与项目关键词匹配。对于标题短文本,使用BERT[21]模型进行预训练,基于上下文语境,获取标题文本的动态句向量后计算余弦相似度。模型具体原理参见第3.2.2节。
3.2.2 基于BERT的相似度计算模型构建
1)融合模型
本文提出了基于BERT架构的多模型融合的相似度计算方法,模型示意图如图2所示。
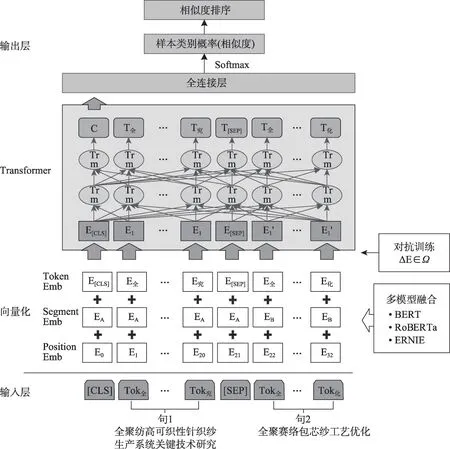
图2 基于BERT架构的融合模型示意图
BERT[21]是基于Transformer架构的语言表征模型,双向自注意力机制可以更好地提取上下文语义特征;在大规模语料上以masked language model与next sentence predict为目标进行无监督训练,使其具有较强的泛化能力。
在输入部分,BERT分别对两个输入的句子进行表示学习(sentence embedding),[CLS]是句子的首个Token,最终对应隐层的输出作为整个句子的向量表示;[SEP]是两个句子的分隔符。原始文本输入后,经过Token Embedding层、Segment Embed‐ding层与Position Embedding层,先将文本的Token转换成固定维度的向量,再将句子向量拼接,并且加入文本序列位置信息,最终得到动态向量来表征上下文语义。此外,模型对单字符进行了处理,避免了中文分词时歧义与领域未登录词带来的误差。在模型的输出部分接全连接层,取最后一层中每个句子的CLS作为模型的输出,然后输入全连接层,通过Softmax获取每个句子的类别概率。
BERT对文本进行mask时仅遮盖单字符,仅使用BERT处理中文任务时,会忽略较多实体/短语的语义信息,但科技文本学科特性强、存在大量领域实体与专业概念,实体/短语的语义信息不容忽视。因此,本文将ERNIE(enhanced representation through knowledge integration)与RoBERTa(a robustly opti‐mized BERT pretraining approach)两种模型与BERT模型进行集成。其中,ERNIE[22]在预训练中加入海量多源数据,处理中文时将实体/短语等先验知识masking,从而模型可以对这些先验知识建模并学习语义;RoBERTa-large-pair[23]是面向句对任务提出的预训练模型,采取动态mask,将BERT中的NSP(next sentence prediction)任务替换为连续长文本输入,使用了更大的batch以及BERT 10倍的预训练数据量,能够较好地提取句对的语义信息特征。综上所述,本文选用BERT、RoBERTa-large-pair与ERNIE三种模型进行模型融合。在输出部分使用反函数,获取各个模型Softmax归一化的特征值再求平均,增加样本概率差异,获取更多的语义信息。
2)对抗训练
在模型中增加对抗训练(adversarial training)防止模型过拟合。对抗训练由Goodfellow等[24]提出并应用在图像领域,通过适当增加对抗训练会造成误判的干扰样本,来增强神经网络的鲁棒性。本文在表示学习阶段的embedding层加入对抗训练,构建对抗样本后加入初始词向量对embedding矩阵进行扰动,提升文本表示的质量。基本原理公式[25]为
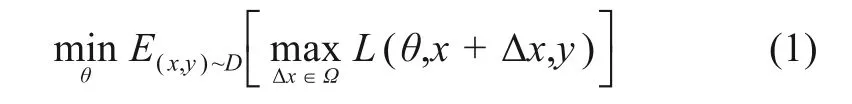
其中,x、y与D分别代表输入的数据、标签与训练集;Δx与Ω是对抗扰动与扰动空间;θ是模型参数;L(x+Δx,y;θ)则是单个样本的loss;max是实现原始数据对应对抗样本训练时的损失最大化。在计算Δx时,本文使用FGSM方法(fast gradient sign method)[24],即
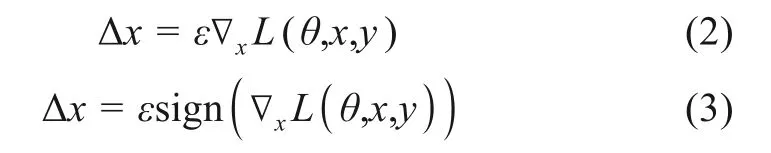
使用反向传播梯度下降后进行标准化,以防Δx过大。
3)半监督学习
深度学习模型中参数优化依赖于大量的标注数据,但实践研究中获取标注数据具有较高的人力成本与时间成本,而半监督学习可以在基于少量标注数据提取特征的同时,学习整体数据样本的分布与结构。本文将标注数据与未标注数据相结合,使用基于伪标签的半监督学习方法进行模型训练,旨在借助未标注数据提升模型整体性能[26-27]。半监督学习训练流程如图3所示,使用训练集中的标注数据训练模型,然后通过该模型预测未标注数据后生成伪标签,从而转化为有监督学习,完成模型训练。
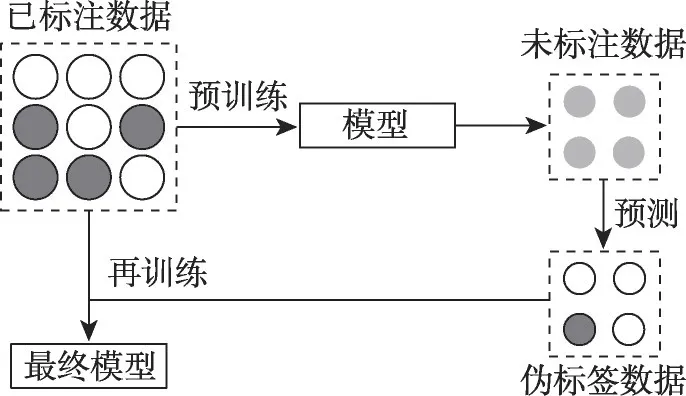
图3 基于伪标签的半监督学习
4 实验结果与分析
4.1 数据采集与预处理
实验数据由科技项目数据与成果文献数据组成。科技项目数据来自江苏省科技报告共享服务系统①http://www.jsstrs.cn/BaogaoLiulan.aspx,由项目基本信息与科技报告组成。成果文献数据涵盖论文与专利,但现有专利数据中缺少所属项目编号,无法确定项目的专利产出,因此,本文将成果文献限定为论文型成果,选取2012—2019年的江苏省科技项目,提取科技项目数据中的项目名称、项目编号与项目类型。通过科技项目的编号与名称获取科技报告,提取科技报告的报告名称、报告摘要、项目编号、报告关键词、技术领域、立项人单位等信息。成果文献数据通过项目的编号在CNKI(China National Knowledge Infrastructure)学术期刊数据库中进行匹配获取,提取匹配文献的标题、摘要、关键词、项目编号、作者单位以及中图分类号等信息。
首先,通过项目编号匹配项目与成果;其次,提取识别编号相同、但映射项目标题不同的成果数据,剔除不属于江苏省科技项目的成果;最后,对比项目、报告与成果数据中的项目名称与编号,进行多向匹配与信息修正。科技项目-成果文献呈一对一、一对多或多对一的关系,共获取到待评估项目-成果数据24036条。统计项目对应成果的数量分布,结果如图4所示。由图4可知,对应1篇成果文献的项目有1280项,占总数的25.54%;对应成果3篇及以下的项目共2765项,占总数的55.18%。
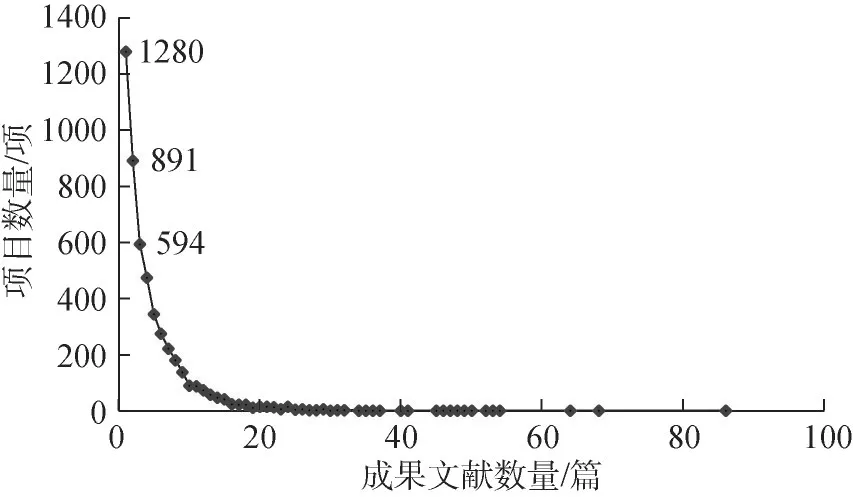
图4 不同成果数量的项目分布
按照项目类别对科技项目及其发文情况进行统计。基础类研究计划、重点研发计划、临床医学专项、政策引导类计划(产学研合作)项目的成果文献产出率较高,分别为65.05%、51.06%、90.32%与65.56%;而科技型企业中的创业企业孵育、企业技术创新类项目的成果文献产出率极低,仅为8.09%与6.45%,这是因为科技项目成果包含论文与专利两种形式,而企业为了保护自身知识与技术产权更倾向于申请专利。
对相互匹配的项目-成果的标题、摘要与关键词部分进行数据清洗,补全或删除缺失值,转换文本中的html(hyper text markup language)实体。观察报告摘要发现,大量报告摘要结尾部分存在过多关于项目成果数量的描述,如“发表文献x篇、培养硕博x名、获得省级奖励x项、申请专利x项”等,此类文本无法体现研究内容的语义,因此,在利用模式匹配识别此类内容后进行删除。此外,使用word2vec进行文本向量化时需进行中文分词,本文使用jieba分词,将科技报告与成果的关键词作为补充词典,用于提升领域文本分词的准确性。
采用人工的方式标注少量数据。将文本对分为“强相关”“弱相关”与“不相关”三类,由江苏省科学技术情报研究所专业人员与南京大学情报学专业博士研究生同时对成果文献大于40篇的15项科技项目进行标注并校对,获取项目-成果数据795条,15个项目的项目类型分布较为均衡,涵盖重点研发计划、基础研发计划、科技设施类、产学研合作等,技术领域涵盖医学、装备制造、电子信息、社会事业等。由初步分析标注数据可知,不同项目的标注结果差异较大:项目F1、F2、F10与F11所对应的成果文献全部相关;F4、F8、F6、F15、F9对应成果文献中,完全不相关类别占比偏少(<50%);F5、F3、F12、F7、F14对应成果文献中,完全不相关类别占比偏多(>50%)。
4.2 实验设计
4.2.1 无监督语义相似度排序
首先,使用word2vec在科技项目、成果文献的标题与摘要文本上训练词向量模型,选用基于当前词预测上下文的Skip-Gram结构,窗口大小设置为10,向量维度为256,词频阈值为5。然后,使用bert-serving-server②https://pypi.org/project/bert-serving-server/生成维度为768的标题短文本的动态句向量。最后,使用通过不同方法生成的句向量,分别计算项目-成果的余弦相似度、词移距离与互信息值。
在测评时,为选取与科技项目相关程度最低的成果文献,将不同模型计算出的项目-成果相似度分别按降序排序,排名最后的项目-成果相似度最低。设定阈值n来选取低于阈值、相关性最低的项目-成果数据,鉴于项目对应成果数量存在差异,本文从数量与占比两方面设定n值:5篇成果以及成果量的四分位数(25%)、三分位数(33.33%)与中位数(50%)。
针对不相关成果数量占比偏少的项目与占比偏多的项目,计算不同阈值n时的F值,结果如图5和图6所示。在F值方面,无监督模型测评值多数未超过70%,总体表现欠佳。在n的取值方面,由图5可知,在不相关成果占比较少的项目中情况各异,四分位数效果略好于其他阈值,且当n=5时,F值整体较低,即在成果内容差异较大的情况下,无监督模型仍未能对项目-成果的相关程度做出较好的区分;由图6可知,在不相关成果占比较多的项目中,中位数是较好的选择,但主要由于该类项目不相关成果文献量均超过总体半数所导致。在模型选取方面,如图5所示,项目F8在以四分位数为阈值时的BERT模型表现最好,F值为66.67%;如图6所示,项目F3在以中位数为阈值时的M1表现最 好,F值 为71.93%。总 体 来 看,M1、M2、WMD、BERT与互信息在多个项目中表现各异,没有在多个项目中均表现突出的模型。综上所述,仅通过将文本向量化,并计算向量浅层语义相似度的方法,无法较好地满足区分项目-成果的相关程度的需求。
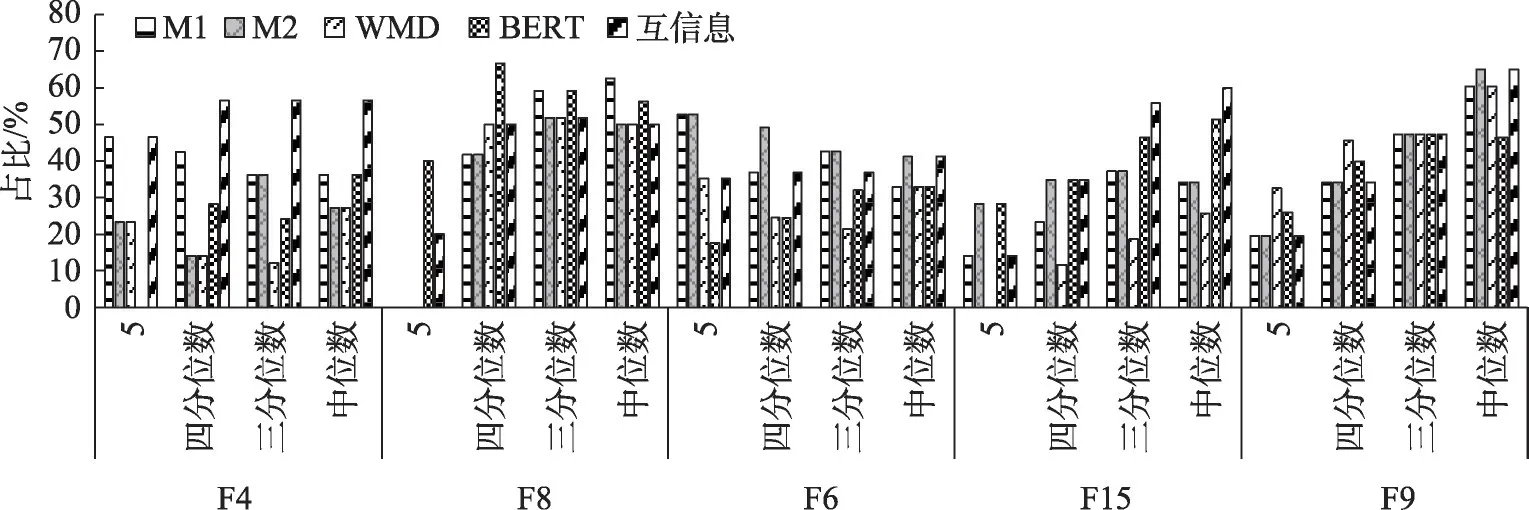
图5 不相关成果占比较少的项目相似度测评
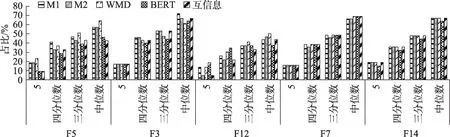
图6 不相关成果占比较多的项目相似度测评
4.2.2 基于BERT的语义相似度计算
构造本节实验的标注数据集。基于上文中无监督相似度计算模型,计算所有数据的相似度并排序,使用具有统计意义的四分位数作为筛选条件,分别取各模型相似度排序最高与最低的四分之一部分,取并集作为训练数据。鉴于不相关成果与强、弱相关成果的内容存在明显差异,因此,将强相关与弱相关类别合并为相关类别。与人工标注数据进行合并、去重后共得到4423条数据,其中相关数据2574条,不相关数据1849条。
进行数据增强后,保持数据集与原始数据的学科分布相似、类别平衡,获取标注数据18086条。分别提取数据中的标题与摘要,分别构建项目-成果标题短文本数据集、项目-成果摘要长文本数据集。将数据集按照7∶2∶1的比例划分为训练集、验证集与测试集。
1)实验设置
使用Python语言基于TensorFlow 1.12.0框架与Keras 2.2.4模块构建如图3所示的模型,在8G内存的Linux系统中搭载NVIDIA Quadro K1200 GPU,分别在项目-成果标题短文本与摘要长文本数据集上进行实验。
BERT预训练模型选用BERT-Base,ERNIE预训练模型选用ERNIE 1.0 Base中文版,将其由Paddle Paddle框架转换为适用于TensorFlow框架的结构;RoBERTa预训练模型选用RoBERTa-large-pair大句子对模型。
超 参 数设置为:BERT与ERNIE的batch_size为16,RoBERTa的batch_size为8,learning_rate为1e-5,dropout_rate为0.2,Epoch为5。此外,为了避免出现过拟合的情况,使用Early stopping方法。
在设置max_length参数时,成果与项目标题长度的均值为21,在训练标题短文本时,设置参数为32;成果与项目摘要长度的均值分别为334与404,但仍存在部分文本长度大于BERT模型可以处理的最长文本序列512。现有研究常采用截断法进行长文本处理:将长文本前128个字符+后382个字符拼接[28]。观察摘要文本后可知,规范的摘要均以目的或内容作为开头,并在结尾对研究内容进行总结,因此,开头与结尾文本满足实验要求。在训练摘要时,设置max_length为512。此外,需要保证训练集、验证集与测试集的数据独立同分布,训练集、验证集与测试集中的标题与摘要句长分布如图7a~图7d所示,由此可知分布大致相同,符合要求。
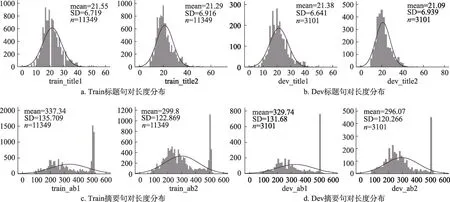
图7 Train、Dev标题句和摘要句长度分布
2)实验结果
本文使用精度A值、准确率P值、召回率R值以及F值作为测评指标,衡量模型总体语义区分能力,最终结果供模型测评使用,计算公式为
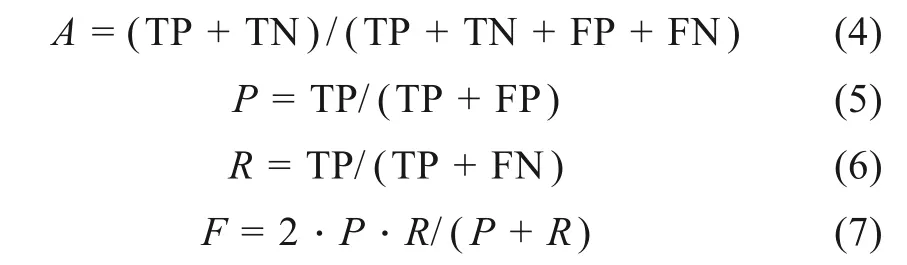
其中,TP表示不相关类别被正确判断为不相关类别的数量;FN表示不相关类别被误判为相关类别的数量;TN表示相关类别被正确判断为相关类别的数量;FP表示相关类别被误判为不相关类别的数量。
本文将实验数据按照7∶2∶1划分,分别作为训练集、验证集与测试集,使用五折交叉法训练模型。首先,使用训练集进行预训练(pre-train)。融合模型在训练标题短文本时耗时34550 s,ERNIE部分多次在epoch4发生early stopping;摘要长文本预训练共耗时73595 s,参数调整后在RoBERTa部分仍发生内存溢出,这是由于RoBERTa-large-piar预训练模型过大、摘要长文本计算量过大导致服务器内存溢出。在摘要长文本部分仅使用BERT与ERNIE进行模型融合。然后,使用模型预测未标注的原始数据,生成伪标签后,将伪标签数据与原始训练集融合、去重后再次进行模型训练(re-train)。在标题短文本部分训练耗时93517 s,其中BERT部分多次在epoch5发生early stopping;在摘要长文本部分训练耗时199001 s,同样在RoBERTa发生内存溢出。基于伪标签的半监督学习在计算复杂度与时间成本上明显高于有监督学习。
验证集用于衡量模型参数优化程度,因此,使用A值与损失函数值来体现训练集、验证集上的模型效果,使用A、P、R、F值衡量测试集的模型效果。使用训练集进行有监督训练的pre-train与使用基于伪标签的半监督学习的re-train实验结果分别如表1和表2所示。
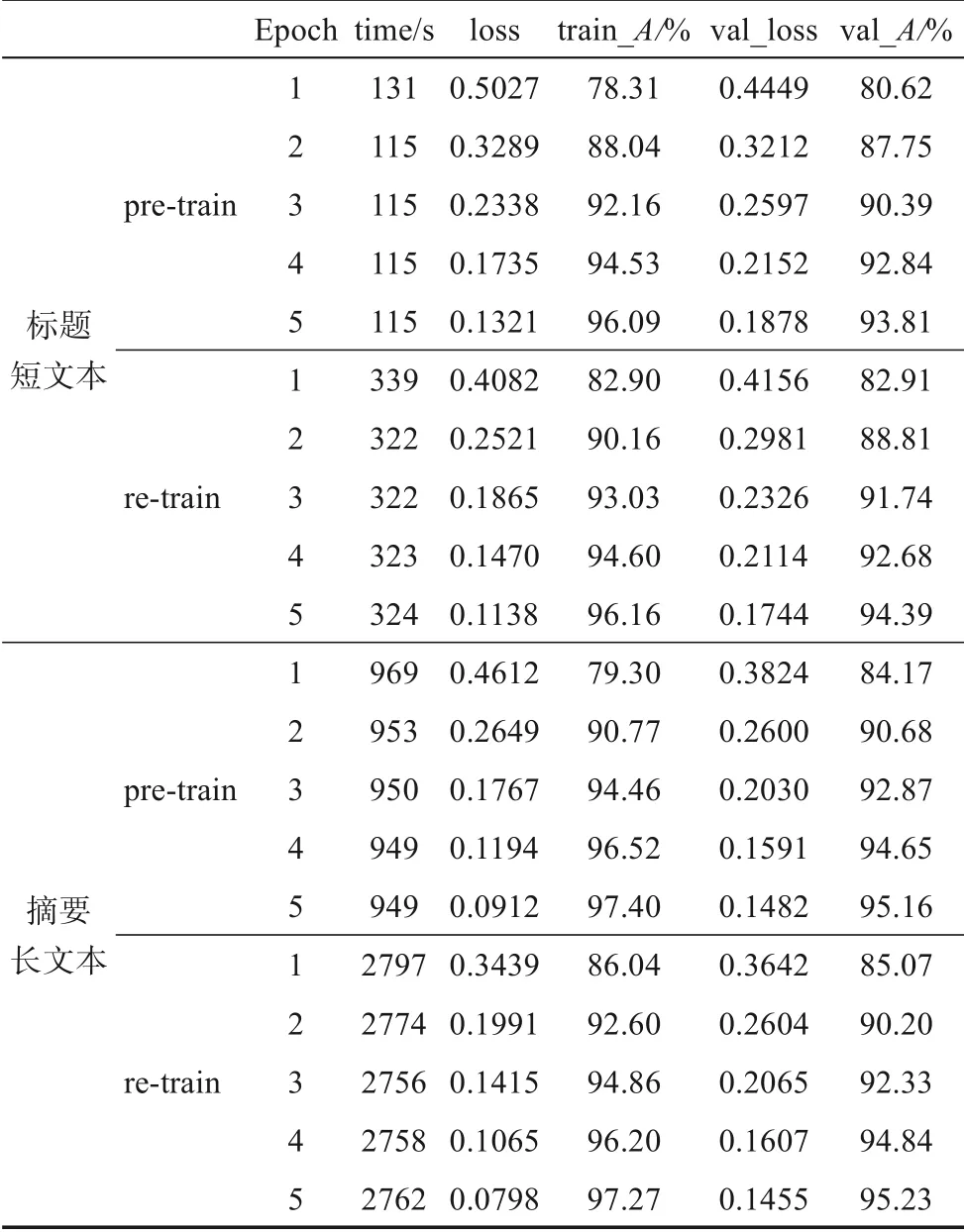
表1 训练集、验证集实验结果
由表1可知,实验过程中模型随着轮次的增加,loss值逐渐减小并趋于0,精度不断攀升并趋于1;总体上,基于摘要长文本的模型效果好于标题短文本的模型,使用基于伪标签的半监督学习效果与仅使用训练集的模型相比略有提升;使用摘要长文本训练模型的时间成本远远高于标题短文本。由表2可知,使用半监督方法训练模型的效果最好,在标题短文本与摘要长文本上F值分别为96.41%与98.94%,A值优于训练集与验证集的表现效果,未出现过拟合的情况。上述实验结果表明,本文构建的模型可以有效地区分语义差异较小的句对的相关性。
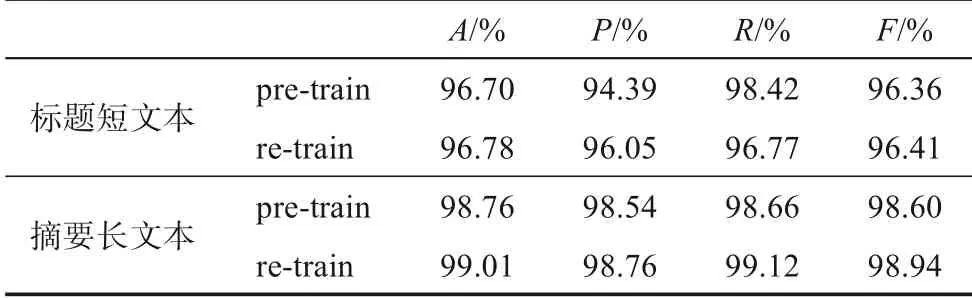
表2 测试集模型实验结果
4.3 结果分析
使用基于长文本训练所得的融合模型,计算项目-成果摘要文本的语义相似度并按升序排序。分析项目-成果相关性较低数据的外部特征与内容特征。
1)外部特征分析
对摘要的文本长度比(成果/项目)进行统计。结果如图8所示。排序靠前、相似度较低部分的长度比分布的阈值大致为(0,6);排序靠后、相似度较高部分的文本长度比分布的阈值大致为(0,3.5)。由此可知,相关性较低的项目-成果中,存在项目摘要的长度远远低于成果摘要的长度的情况。较短的项目摘要对自身研究内容描述过于宏观与笼统,所含语义无法与成果内容相匹配。
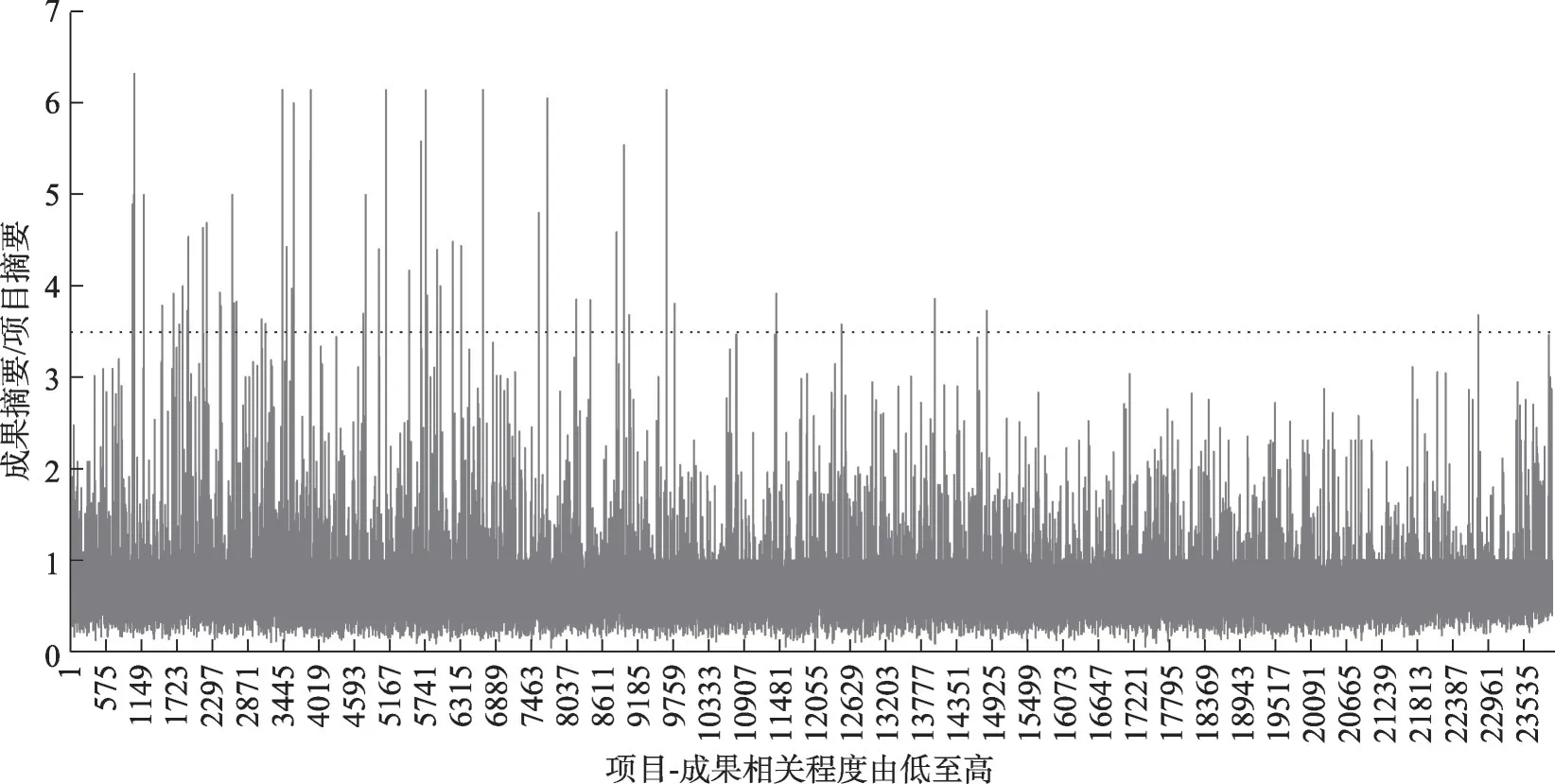
图8 成果摘要与项目摘要长度比
统计科技项目对应成果文献的数量。在24036条项目-成果文本数据中,以四分位数为基准取相似度较低的6009条数据,结果如图9a所示。其中,占比最多的是6~10个成果的科技项目,占比最少的单成果的科技项目为259项,仅占4.3%。单成果项目立项时间分布如图9b所示,项目多分布在2012—2015年,因此,不存在立项时间较短、成果发表周期较长导致成果较少这一问题。由此可知,在项目-成果相关程度较低的部分,仅对应一篇成果文献的项目较少。
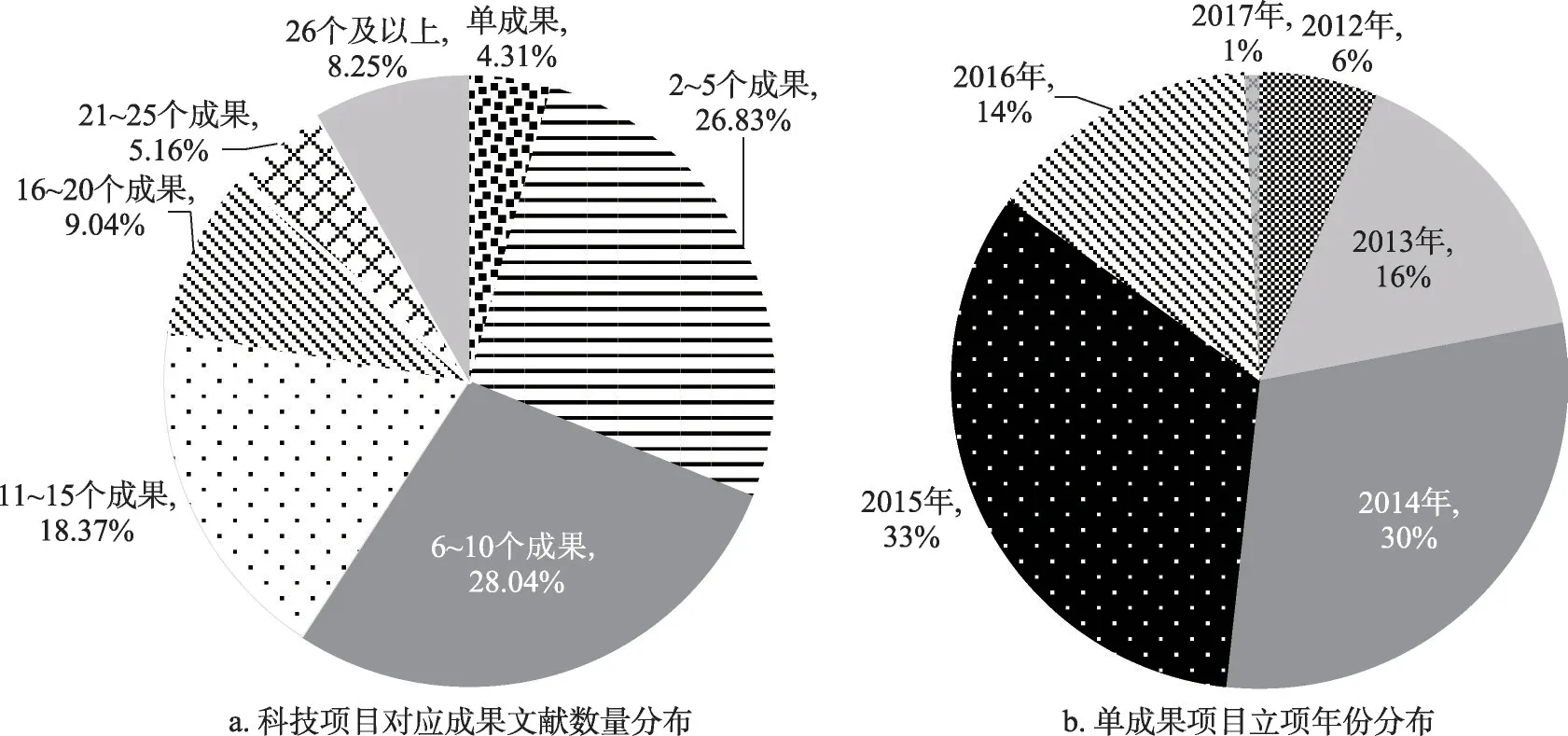
图9 项目立项年份及对应成果文献数量分布
对低相关数据中的项目类型特征进行分析。以对应论文型成果数量少于100的项目类型为主:“创新能力建设(研发机构类)”“科技型企业创业孵化”“科技型企业技术创新”“政策引导类计划(国际科技合作、软科学专项)”,在低相关数据中共对应成果59篇,占上述项目总成果178篇的1/3,因此,上述项目在产出论文型成果较少的前提下,仍有1/3的论文与项目相关程度较低。
2)内容特征分析
由表3可知,几种项目-成果低相关的典型示例:①成果与科技项目所属学科相同、方向相近,但研究内容无关;②成果与科技项目研究领域相近,但实则属于中图法分类号为G4/G6的教育大类,内容围绕与项目领域相关的教学改革、课程设置、教学方法、人才培养等方面展开,与项目真实研究内容无关;③成果为综述类文献,虽详细介绍了与项目相关技术方法的发展历程,但未能反应出科技项目的核心研究内容;④部分成果文献与项目研究方向与内容完全无关。
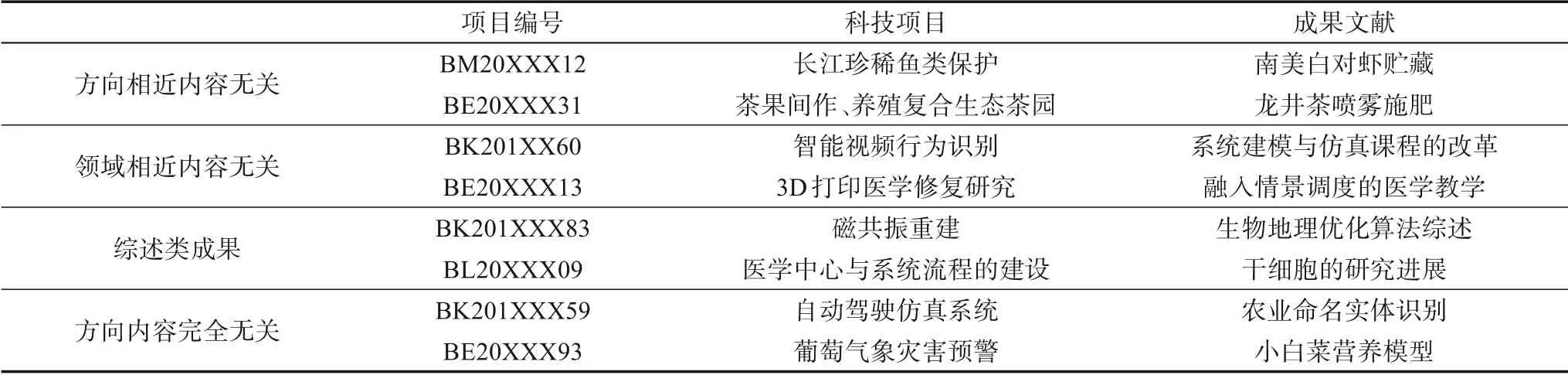
表3 低相关科技项目-成果文献实例
此外,模型存在将相关成果误判的情况,具体原因如下:①项目-成果摘要的写作文法差异较大。例如,项目BC201XX22成果摘要“酸甘化阴法肇始于仲景,以酸甘和合异类相使化阴生津,阴复濡润而不滋……”为古文,而项目摘要“中医临床医案采集平台大多采用C/S(client/server)模式建设,软件升级更新十分不便……”是白话文。②摘要里非中文字符较多。例如,成果摘要“{cDau(t)+f(t,u(t),v(t))=0,cDav(t)…}”,项目摘要“n维时标上Sobo‐lev空间及定义在该空间上函数的一些特性……”,模型无法将中文字符的语义与非中文字符的语义匹配。③在科技项目中存在数量可观的科技支撑类项目,该类项目主要为科研活动提供基础设施,如系统、体系、基地或科室的建设等,因此,摘要通常是对基础建设过程的描述,其成果文献的研究内容与项目相关但语义上存在较大差异。
3)上述情况的成因分析
①成果文献的数量在一定程度上反映了科技项目的研究体量与重要程度,文献可以从数量特征层面提升项目的重要性,因此,立项人会将无关成果划入项目产出。②项目未能如期完成,预计成果产出与学术价值均未达标,但立项人为通过后评估,将与项目无关的其他科研成果用来充数,用于满足成果数量指标。③随着高校近年来对科研经费管控力度增强,立项机构对经费用途进行严格的规范,论文的出版费用是重要的途径之一,将与项目无关的论文划入项目的产出,可解决出版费用。④在项目-成果低相关部分,仅有少部分的单成果项目,而以多成果项目居多。这意味着在多成果项目中,一定数量的“代表作”已经完成了项目额定/核心的研究内容,其余成果与项目关联较小。⑤部分成果内容与项目相关性较低,可能由于立项时间较短、期刊审稿流程与周期较长,部分相关成果尚未发表。⑥部分类型项目产出具有较强的技术性或知识产权敏感,因此,研究成果主要以论文之外的形式呈现,如专利、产品等。⑦基金论文比作为期刊评估体系中的重要指标,影响了期刊的收稿倾向。随着科技文献数量指数增长、论文录用难度加大,立项人为无关的成果进行项目“加冕”可增加论文录用概率。
5 数据准备与实验结果所揭示的科技报告质量监管问题
参考科技报告制度指导意见以及科技报告质量监管架构(图10),结合本文的数据准备与实验结果,发现微观层面的质量保障机制存在以下问题。
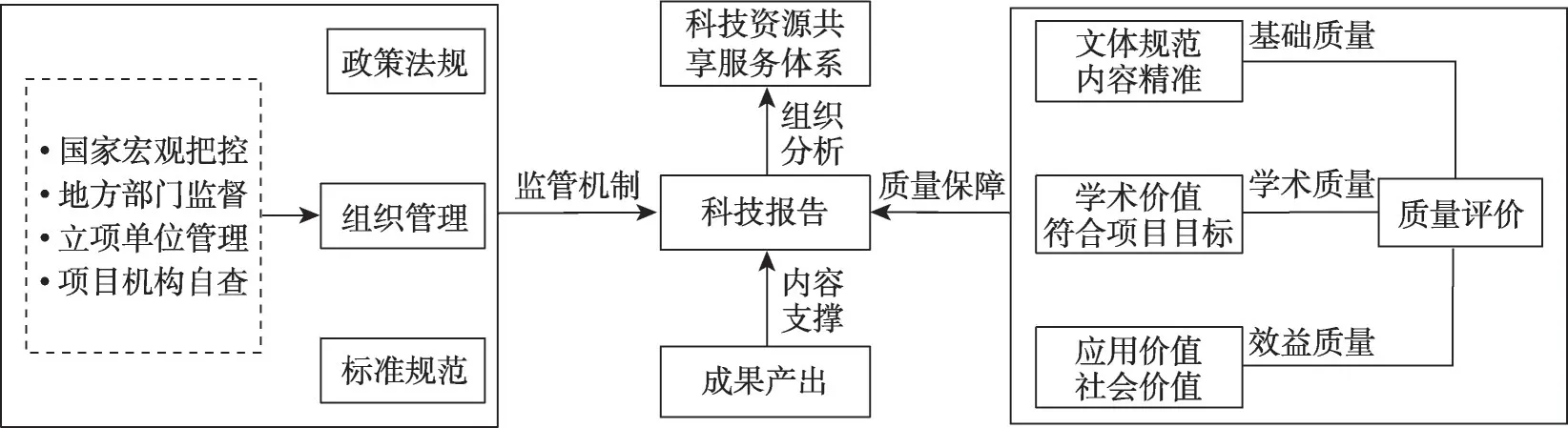
图10 科技报告质量监管架构
(1)基础质量层面。现有科技报告总体质量良莠不齐,项目标题、摘要的文体、内容与字数的规范性不尽人意。部分报告摘要开头着重描述研究背景,部分描述研究目的;部分报告摘要将主要研究内容逐条列出并详细阐述;部分报告摘要将总体研究内容一笔带过,而大篇幅描写所获奖项与培养人才等;部分报告直接以《江苏省科技项目报告》等类似文本作为报告标题;部分报告以“单位名称+研究报告”的格式命名,仅从报告标题无法获取任何与研究内容有关的语义信息;科技报告摘要文本长度从50~1000不等,内容密度差异较大。摘要作为总结性文本,规范的文体与精准的内容可以大大提升项目评估与审核的工作效率,同时也为报告撰写人提供了写作标准。此外,类似学术文献的半结构化的摘要会蕴含更多的语义信息与文本序列位置信息,有助于科技资源共享服务系统的构建与功能的完善。因此,应针对不同类型的项目,完善和细化科技报告摘要与全文的写作标准。
(2)学术质量方面。科技报告作为项目与成果的纽带,主要通过成果文献来体现其学术质量,目前存在成果产出与项目预期内容不符、相关程度较低以及项目产出成果数量较少等问题,科技报告并未能如实地对所有成果进行记录与描述,而多以与科技项目高度相关的成果为主。科技项目、科技报告与成果文献三者的研究内容应协调统一、高度相关,允许在一定范围内进行弹性调整。同时,不同类型项目性质不同,在后期评估监管时,应根据项目类型与评估需求设定合理的相似度阈值,调整评估要求中的成果类型(论文/专利/标准/软件等)与数量标准,设立以“标志性成果”为核心的“代表作制度”,保质保量提升评估工作,在总体上加强质量层面的监管力度。
(3)效益质量方面。科技项目在一定程度上代表了官产学研的科技创新与成果转化,因此,多数科技报告对研究的应用价值与技术价值进行了较好的展现,但由于目前公众对科技报告资源的利用率较低,且社会价值具有隐性与长期性,较难通过科技报告直接进行评估,因此在科技报告效益评估时应综合考虑成果效益。
6 结语
本文使用科技报告对科技项目信息进行补充,通过文本语义匹配的方法对科技项目及其对应成果文献的相关程度进行探索,基于小规模标注数据进行数据增强,提出了基于BERT融合模型的项目-成果文本相似度计算方式,并取得了较好的实验效果。研究结果发现,存在部分成果文献研究内容与项目预期研究内容不符、项目实际完成质量低的现象,这一现象警示人们需要透过量化特征、深入探索内容特征,完善科技后评估制度、加强科技项目监管,从而维护评审的公正性。此外,科技报告审核与科技项目后评估相辅相成,应加强科技报告监管力度、完善写作规范、细化审核标准,促进科技报告资源的利用,着力建设优质科技资源,全方位提升我国科技情报服务效率。
同时,本文存在如下局限:①囿于缺少面向中文科技文本的相关性标注数据集,本文使用的数据规模有待扩展、模型泛化能力有待提升。将在今后使用模型训练的同时,辅以人工校对,扩充数据集。②学科间跨领域合作较多,成果文献与科技项目相关性具有弹性,需要综合考虑学科特质、参考相似度排序结果,结合项目类型、根据实际需求,进一步设定不同相关程度的阈值,完善科技项目后评估指标体系。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
速读·下旬(2021年11期)2021-10-12
小读者之友(2020年8期)2020-09-01
大东方(2019年12期)2019-10-20
中国报道(2019年8期)2019-08-29
当代贵州(2018年21期)2018-08-29
科学与财富(2017年22期)2017-09-10
中国经济周刊(2017年20期)2017-06-01
商情(2017年1期)2017-03-22
长江学术(2016年4期)2016-03-11
