
三维Hilbert曲线层级演进模型与编码计算
2022-03-07 13:11:40吴宇豪曹雪峰余岸竹孙万忠
测绘学报 2022年1期
吴宇豪,曹雪峰,余岸竹,孙万忠
信息工程大学地理空间信息学院,河南 郑州 450001
全球离散网格系统(discrete global grid system,DGGS)是一种面向全球的新型多分辨率数据融合与地学模拟解决方案[1-3],它借助特定方法对地球空间进行均匀递归剖分,构建多分辨率的无缝不重叠网格结构,在数据操作中使用格元编码代替传统的地理空间坐标[4]。空间填充曲线以分形几何、代数等数学理论为支撑,刻画被遍历空间中各点在曲线上对应位置之间的关系及其随阶数的变化,具备构建抽象、严格、一般性的数学模型的理论潜力[5]。空间填充曲线编码较好地顾及了格元邻近关系表达的需求,在执行邻域操作时效率较高[6]。
研究人员经过广泛研究对比后发现,在众多空间填充曲线中,Hilbert曲线具有最好的空间聚簇性[7-8],即多维空间中位置相邻或相近的空间目标映射到Hilbert曲线上后能够保持最佳的邻近关系,可有效提高多维数据在磁盘等一维物理存储中的访问效率[9],已被广泛应用于网格单元编码研究领域[10]。文献[11]提出剖分影像金字塔模型及建塔策略,利用网格单元编码的唯一性和Hilbert曲线空间连续性对影像块进行索引与组织。文献[12]采用Hilbert曲线构建菱形网格单元编码模型,并配合提出Hilbert码与地理坐标的相互转换算法。文献[13]结合其八叉树结构,设计立体网格单元Hilbert编码方法,并针对多分辨率数据组织要求,提出紧致Hilbert索引[14]。文献[15]将地球圈层空间网格的研究范围扩展至地月空间,按照类似方法构建了地月圈层网格[16],分析给出了圈层网格Hilbert码与“行-列-高”码的转换方法,邻近圈层单元查找模型以及圈层单元拓扑模型[17]。文献[18]通过层次嵌套细分构建了规则的多分辨率时空网格,并基于Hilbert曲线提出一种时空数据索引方法。文献[19]面向时空数据设计了四维Hilbert码索引,并提出一种查询窗口与Hilbert码段的转换方式。文献[20]针对时空轨迹数据设计了一种时空网格系统,提出基于Hilbert曲线的时空数据索引进行轨迹数据管理。
格元Hilbert码的计算效率是影响全球离散网格系统中数据组织效率的关键之一,包括笛卡儿坐标(或地理坐标)至Hilbert码的转换计算以及邻近格元Hilbert码的计算等。笛卡儿坐标至Hilbert码转换计算的经典方法是由文献[21]针对二维空间构造提出的。该算法是基于Morton码的二进制位迭代法,算法复杂度为O(n2)。文献[22]对n维m阶Hilbert曲线的空间变换进行研究,提出基于空间坐标变换、自底向上的迭代生成算法,算法复杂度为O(nm)。文献[23]提出状态转移矩阵描述二维Hilbert的层级演进关系,将坐标变换转换为C++中的数组运算,减少了嵌套循环中迭代次数。文献[24]研究了三维Hilbert曲线的层级演进关系,给出了三维Hilbert曲线的初始地址表与层级演进表,但是其给出的地址表形式为若干个二进制数的简单集合,无法直接应用于编码运算。
邻近格元索引是空间聚类、查询等基本空间操作的基础[25]。计算得到邻近格元Hilbert码是实现邻近格元索引的前提。典型的邻近格元Hilbert码计算基于Morton码与Hilbert码之间的空间变换关系实现[26-27],分析其步骤可发现其存在两个缺点:①需要逐层级拆解,将Hilbert码转换为Morton码,耗费较长时间,单次拆解复杂度为O(n),n为Hilbert曲线维度。②当中心格元层级为m时,需要进行2次步长为m的循环,总时间复杂度为O(2nm),随着格元层级的增高,效率随之降低。文献[28]总结了二维Hilbert曲线的层级演进关系,通过记录中心格元在各层级中的相对位置,实现邻近格元Hilbert码计算,对比Morton码转换算法在效率上有较大提升,但是空间维度变化会带来空间填充顺序与演进关系的差异,导致二维Hilbert码算法无法直接应用至更高维度曲线中。
Hilbert曲线具有自相似性[5],其体现为曲线在不同层级间的形状特征是相似的,高阶曲线由多条低阶曲线做空间变换后相连构成。研究高低阶Hilbert曲线之间的层级演进关系将会为Hilbert码的计算效率带来显著提升,并为之后的空间分析带来新的模型与方法[15,24,29]。本文首先设计八叉树网格的Hilbert编码结构,然后构建Hilbert曲线层级演进模型,最后以层级演进模型为基础,分别解决笛卡儿坐标至Hilbert码转换计算、邻近格元Hilbert码计算问题。
1 格元Hilbert码设计
Hilbert空间填充曲线与网格单元(简称格元)之间的连续映射关系在数学角度上可描述为一种线段T至n维数据空间Rn上的连续映射函数,即线段T中的每一等份t与n维数据空间Rn中的每一格元Q之间的存在一一映射关系,格元Q的大小由线段的等分次数m确定。在Hilbert空间填充曲线的构造过程中,m-1阶曲线(低阶)至m阶曲线(高阶)的一次演进时,将各个维度等分为2m等份,那么n维数据空间Rn则被剖分为2mn个m层级格元Q,这些m层级格元Q与线段T的2mn等分的t之间一一对应,由同一个m-1格元剖分得到的2n个m层级格元的集合被称作Hilbert细胞[30]。


图1 Hilbert码与Hilbert细胞Fig.1 Hilbert code and Hilbert cell
通过记录1至m阶曲线演进过程中,格元在每一个细胞中的填充顺序,可为格元设置唯一对应的Hilbert码,其编码形式如图1(a)所示。将m层级格元的Hilbert码记作hm,格元在各层级细胞中的填充顺序记作i1,i2,…,im,Hilbert码hm满足式(1)
hm=i1⊕i2⊕…⊕im
(1)
式中,符号⊕表示左移一位后相加。Hilbert码hm存在以下特性:①m层级格元的Hilbert码hm共有m位;②子格元Hilbert码与父格元Hilbert码只相差最后一位,子格元Hilbert码等于父格元Hilbert码左移一位后相加上子格元的填充顺序。
2 Hilbert曲线层级演进模型
2.1 Hilbert曲线状态向量





图2 24种填充顺序Fig.2 24 filling sequences

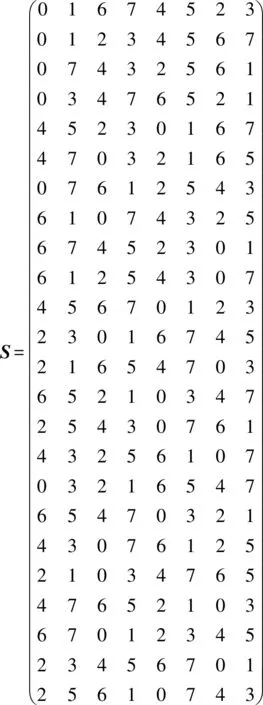
(2)
2.2 状态向量层级映射关系

表1 Hilbert曲线基因列表Tab.1 Hilbert curve gene list
以基因列表为基础,可对状态向量在层级间的映射关系进行如下推导。
由曲线构造过程可得,一个状态向量为sk的细胞(对应一个m层级格元),其各个子格元(m+1层级格元)的状态向量满足以下层级映射公式
(3)
式中,表达式sk⊗G[i]表示对状态向量sk的细胞做坐标变换G[i]后重新记录状态向量。


图3 状态向量s2的层级映射Fig.3 state vector s2’s level mapping diagram
(4)
以式(4)为基础,通过以下步骤递推可得其余状态向量的层级映射:①计算状态向量s2与状态向量sk(k≠2)之间的坐标变换G(k,2);②将式(4)左右两边各做坐标变换G(k,2),得状态向量sk满足以下映射关系
(5)
计算所有状态向量的层级映射关系后,引入演进矩阵E记录24种低阶状态向量与高阶状态向量间的映射关系,见式(6)

(6)
状态演进矩阵E的第u行对应映射关系为
(7)
状态矩阵S与演进矩阵E是本文进行三维Hilbert曲线编码层级演进模型描述的重要工具:状态矩阵S记录了三维Hilbert曲线的填充顺序,演进矩阵E记录了三维Hilbert曲线填充顺序在高低阶曲线之间的变化趋势,两个矩阵相互配合实现三维Hilbert曲线层级演进模型的形式化描述。
在文献[22,30]中,基因列表只表示了Hilbert曲线某一种填充顺序在层级间的层级演进关系,因而在运算使用中需要临时通过多维度迭代计算,才能得出下一层级格元的填充顺序。本文中,首先,求取了三维Hilbert曲线所有情况的填充顺序,然后,推导所有填充顺序的层级演进关系,运算使用中可直接从层级演进关系模型中提取得到当前填充顺序与下一层级填充顺序,因此便于设计更加简洁直观的算法。
3 基于层级演进模型的格元Hilbert码计算
Hilbert曲线层级演进模型对曲线的填充顺序以及其在层级间的变化关系进行描述,在此基础上可以进行Hilbert曲线构造过程的复现,并设计实现格元Hilbert码计算方法。
3.1 笛卡儿坐标至Hilbert码计算
全球离散网格采用网格单元编码代替传统的二维、三维笛卡儿坐标参与运算。然而现有的多数地理空间数据仍然采用笛卡儿坐标给出,为保证现有数据能够融入全球离散网格系统中,需要设计相应的格元笛卡儿坐标至Hilbert码计算的方法。
笛卡儿坐标至Hilbert码的计算实质是对格元剖分和曲线演进的复现,即记录格元在各次曲线演进过程中所处的细胞填充顺序,故曲线演进过程复现的效率不同将导致计算效率存在差异。本文借助Hilbert曲线层级演进模型复现曲线演进过程,避免了各维度迭代步骤,具有直观简洁的特点。

以状态矩阵S与演进矩阵E为工具,本文的格元剖分和曲线演进复现思路如下:从1层级格元和1阶Hilbert曲线为起点,逐层级、阶级向高层级、阶级剖分演进,其中在各次剖分和演进过程中,先使用状态矩阵S判断当前格元的填充顺序,后使用演进矩阵E更新下一层级细胞的状态向量。图4给出了计算示意图,图中深色格元坐标P(3,0,3),采用状态矩阵S与演进矩阵E进行三次复现后,得到Hilbert码h3=042。计算过程的具体步骤如图5所示。

图4 笛卡儿坐标至Hilbert码计算Fig.4 Cartesian coordinate to Hilbert code calculation
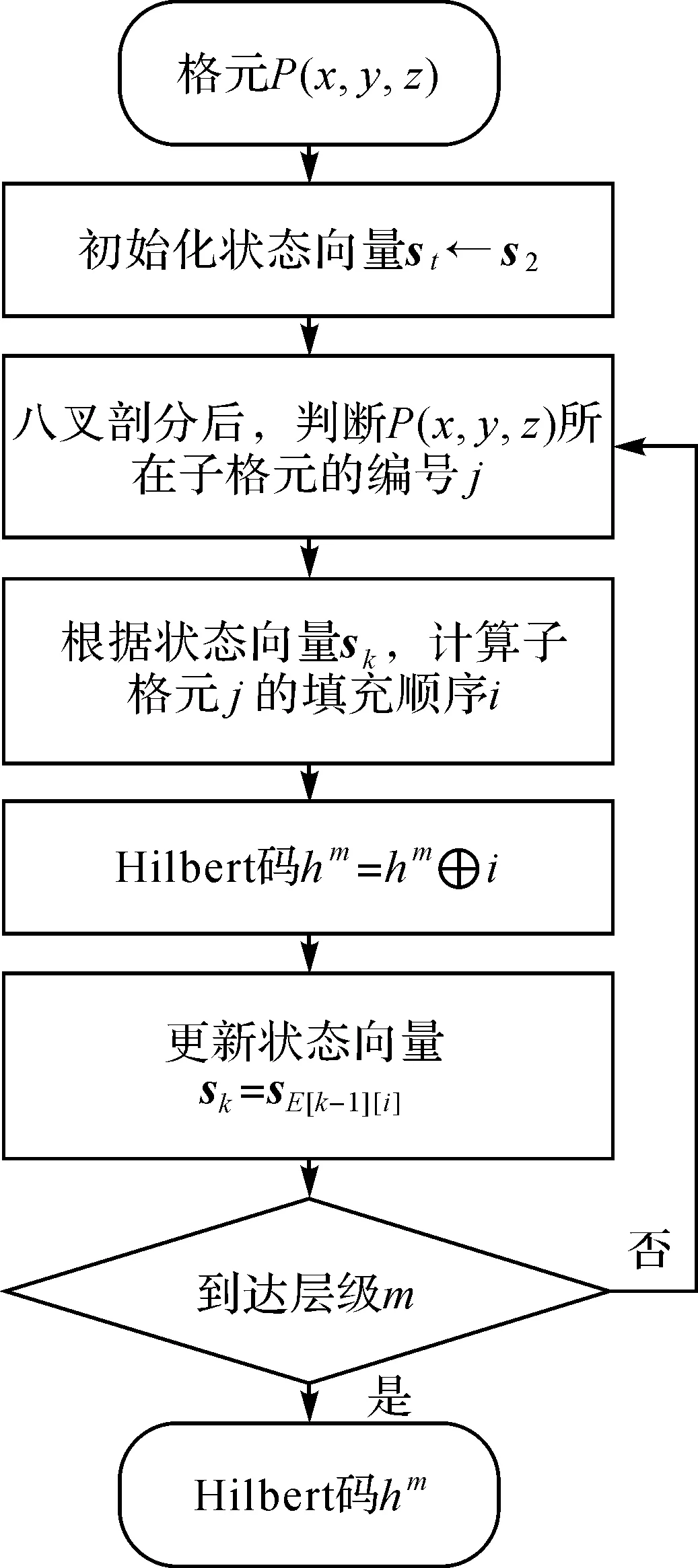
图5 笛卡儿坐标至Hilbert码计算流程Fig.5 calculation process from Cartesian coordinates to Hilbert code
文献[22]实现笛卡儿坐标至Hilbert码的转换计算过程中,单次运算共需要对n个维度上的坐标进行迭代变换,复杂度为O(n),算法共需要进行m次循环运算,其总时间复杂度为O(nm)。本文使用Hilbert曲线层级演进模型复现曲线构造过程,不存在迭代变换步骤,单次运算只需使用状态矩阵S查询填充顺序、演进矩阵E查询下一层级状态向量,查询复杂度为O(1),全程需进行m次循环,总时间复杂度为O(m),相比于文献[22]迭代算法复杂度更小。
3.2 邻近格元Hilbert码计算
邻近格元索引是空间聚类、邻近分析等空间操作的基础。本文以Hilbert曲线层级演进模型为基础,设计邻近格元Hilbert码计算方法,实现邻近格元索引。
在Hilbert码包含父格元与子格元的层级关系,子格元Hilbert码与父格元Hilbert码只相差最后一位,子格元Hilbert码等于父格元Hilbert码左移一位后相加上子格元的填充顺序。因此,通过Hilbert码位运算可实现父子单元的查询,位运算分为左移与右移两种形式:①右移运算。hm≫1,即m级格元Hilbert码右移1位得到其m-1级父格元的Hilbert码。②左移运算。hm≪1,即m级格元Hilbert码左移1位得到其m+1级子格元中第一个填充的子格元Hilbert码,若需计算第i个填充子格元的Hilbert码,则左移1位后将最后一位替换为i。
若通过右移运算可寻找到公共父格元,则可采用左移运算得到邻近格元。进行位运算的同时,需要对Hilbert曲线采取相应的退化与演进操作,以确定格元的填充顺序i以及父子格元的状态向量。

s(C(v,i))=sE[k-1][i]
(8)

s(v)=sr(k)+1
(9)
式中,r(k)表示演进矩阵E第i列中值为k的元素所在行数。获得父格元状态向量后,先依据填充顺序判断当前格元所处的子格元编号,后判断指定邻近方向DirN上邻近格元与中心格元是否同属于一个父格元(判断依据见表2)。若同属于一个父格元,则查询得到公共父格元,下一步开始演进过程。

表2 邻近格元编号Tab.2 Neighbor grid elements number

图6 邻近格元Hilbert码计算 Fig.6 Hilbert code calculation of neighbor grid elements

图7 邻近格元Hilbert码计算流程Fig.7 Calculation flow of Hilbert codes with neighbor grid elements
在文献[26]的转换算法中,为了生成邻近格元Hilbert码,需要通过2m次复杂度为O(n)的拆解转换步骤,其时间复杂度为O(2nm),因此随着格元层级m的增高,其计算效率将会逐渐降低。在本文计算方法中,采用Hilbert曲线层级演进模型实现了Hilbert曲线的退化与演进,无需将Hilbert码转换为其他类型的码或坐标,算法的时间复杂度为O(2k),k为中心格元与公共父格元之间的层级差。本文方法单次计算复杂度为O(1),相较文献[26]转换算法更低,且循环次数与格元层级无关,故计算效率更高。
4 试验与分析
为测试上述以Hilbert曲线层级演进模型为基础的算法效率,本文采用Visual C++ 2015开发工具分别实现了笛卡儿坐标至Hilbert码的迭代计算方法[22]与本文计算方法,以及Morton码转换邻近格元Hilbert码计算方法[26]与本文邻近格元Hilbert码计算方法。全部程序编译为Release版本,并在计算机(CPU Intel Core i7-7700K 双核4.2 GHz,内存64 GB,硬盘7200 r/min)上进行测试。
4.1 笛卡儿坐标至Hilbert码计算效率测试
为测试本文基于Hilbert曲线层级演进模型的笛卡儿坐标至Hilbert码计算效率,设计试验进行测试:首先,在不同计算次数、相同阶数情况下,测试本文算法完成计算所需时间,并与迭代算法进行对比。然后,在不同阶数、相同计算次数情况下,测试本文算法完成计算所需时间,并与迭代算法进行对比。测试具体数值设置如下。
(1) 随机生成5×106个格元P(x,y,z),使用本文计算方法和迭代计算方法生成格元对应的5-15阶Hilbert码,记录两种算法计算耗时,结果如图8(a)所示。
(2) 随机生成{1×105,2×105,…,20×105}个格元P(x,y,z),使用两种计算方法生成格元对应的10阶Hilbert码,记录两种算法计算耗时,结果如图8(b)所示。

图8 测试结果Fig.8 Test results
由测试结果可知:
(1) 图8(a)中,在计算不同阶数Hilbert码时,本文方法所需的转换时间随转换阶数的增加而呈上升趋势,在阶数15时,进行1次转换所需的平均时间约为0.8 μs;对比迭代方法,在不同阶数时,本文方法的计算耗时更少,效率更高,如表3所示在各组试验中,本文算法效率提升7%至23%。

表3 不同阶数5×106个格元计算测试结果对比Tab.3 Comparison of calculation results of 5×106 grid elements with different orders
(2) 图8(b)中,在计算不同次数的Hilbert码时,本文方法所需的转换时间随转换次数的增加而呈上升趋势,进行1次转换所需的平均时间约为0.7 μs;对比迭代方法,本文方法的计算耗时更少,效率更高,见表4。在各组试验中,本文算法效率提升8%至15%。

表4 不同次数测试结果对比Tab.4 Comparison of test results of different times
分析差异产生原因,本文方法以Hilbert码的层级演进模型为基础,采用状态矩阵S与演进矩阵E复现Hilbert曲线演进过程,避免了多维度迭代的步骤,算法过程更加直接简洁,因而获得更高的效率。本文方法能够以微妙级时间为代价完成1次笛卡儿坐标至Hilbert码的转换,对比于迭代算法,计算耗时更少,效率更高。
4.2 邻近格元Hilbert码计算效率测试
为测试本文基于Hilbert曲线层级演进模型的邻近格元Hilbert,码计算效率,设计试验进行测试:首先,在相同层级、不同格元个数情况下,测试本文邻近格元Hilbert码计算方法完成计算所需时间,并与迭代算法进行对比。随后,在相同格元个数、不同格元层级情况下,测试本文邻近格元Hilbert码计算方法完成计算所需时间,并与迭代算法进行对比。测试试验具体数值设置如下。
(1) 在层级15情况下,随机选取当前层级的{1×106,2×106,…,8×106}个格元,使用Morton码转换邻近格元Hilbert码计算方法与本文邻近格元Hilbert码计算方法进行某一随机方向上邻近格元Hilbert码计算,记录两种算法计算耗时,结果如图9(a)所示。
(2) 在层级5—15下,随机选取当前层级中的1×106个格元,并分别采用两种计算方法进行某一随机方向上邻近格元Hilbert码计算,记录两种算法计算耗时,结果如图9(b)所示。
由测试结果可知:
(1) 图9(a)中,相同格元层级情况下,两种方法对应曲线随着格元个数的增加均匀上升,表明两种方法的计算所需时间均与格元个数呈正相关;对比同一格元数下,两种方法所需的计算时间,本文方法的计算时间均要少于转换方法,各组测试中本文算法效率提高4.0至4.5倍,见表5。

图9 测试结果Fig.9 Test results

表5 不同格元数测试结果对比Tab.5 Comparison of test results of different grid elements
(2) 图9(b)中,相同格元个数情况下,转换方法对应曲线随层级增加呈现较为均匀的增长趋势,说明其计算效率随层级的增加而线性降低;本文方法对应曲线较为平缓,随着层级的增加存在较为微小的波动,但计算耗时整体处于2 s以内,表明本文方法效率受层级影响较小。对比图9(b)中同一层级下,两种方法所需的计算时间,本文方法所需时间均小于转换方法。本文算法效率提升倍数随层级增加有扩大趋势,在层级15情况下,效率提升了4.4倍,见表6。

表6 不同层级测试结果对比Tab.6 Comparison of test results at different levels
分析差异产生原因,转换方法需要将Hilbert码通过层级拆解转换为Morton码后,才能实现邻近格元Hilbert码计算,其时间复杂度与层级呈线性相关;本文计算方法则是通过层级演进模型复现了填充顺序在层级间的变化关系,只需寻找公共父格元即可实现邻近格元Hilbert码计算,因而效率更高,且算法时间复杂度只与中心格元与公共父格元的层级差相关,计算效率不随中心格元的层级发生显著改变。综上所述,在邻近格元Hilbert码计算效率上,本文方法的效率优于转换方法。
5 总结与展望
高效、简便的网格单元编码运算及索引是全球离散网格系统的核心问题。作为网格编码研究的重要工具,Hilbert曲线网格编码实现了坐标等效降维表达,但是如何直接计算Hilbert曲线不同层级之间的变换、如何将格元多维空间结构与关系转换到一维Hilbert码的相关运算上仍然需要深入研究。本文对八叉树网格Hilbert曲线层级演进关系进行建模,采用状态矩阵S与演进矩阵E复现三维Hilbert曲线的演进过程。以层级演进模型为理论基础,设计笛卡儿坐标至Hilbert码计算方法以及邻近格元Hilbert码计算方法,避免现有算法中烦琐的迭代步骤,提高了Hilbert码层级属性的利用率,计算效率较高。下一步还需要研究如何在全球离散网格系统上运用Hilbert曲线层级演进模型这样的工具,包括:从局部欧氏空间到全球流形的变化带来方向、距离等度量不同,不同的全球离散网格系统在剖分方法上的不一致带来空间填充曲线具体实现等问题。
猜你喜欢
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
——笛卡儿自由意志理论探析
求是学刊(2019年6期)2019-11-27 13:18:12
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:38
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
中学生数理化·七年级数学人教版(2018年4期)2018-06-28 03:26:32
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
火控雷达技术(2016年3期)2016-02-06 02:30:28
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
