
采用CNN-LSTM 与迁移学习的虚假评论检测
2022-03-07 06:57陈宇峰
软件导刊 2022年2期
陈宇峰
(兰州大学 数学与统计学院,甘肃 兰州 730000)
0 引言
信息化时代,互联网逐渐成为人们获取信息的重要渠道,出现了大量带有用户主观情感、语义丰富的短文本。面对还未接触或者不够了解的服务与产品,多数用户习惯于通过互联网获取有关信息,来自互联网的评价极大影响着用户的最终决策与选择。如用户在有关平台上预订酒店时,在其他条件合适的情况下往往会先参考酒店已入住者提供的评论,并根据评论做出是否预定该酒店的决定。因为互联网评价的这一作用,大量虚假评价也频繁出现在有关平台,而虚假的产品与服务评论不仅可能误导消费者的最终决策,还会对商家的信用产生较大影响。因此,高效识别网络的虚假评论具有重要的社会意义与经济价值[2]。
在互联网上发布虚假评论成本较低,普通用户对于虚假评论的识别能力较差,通常很难识别出带有欺骗性质的虚假评论,因此相关研究大多以虚假评论为实验研究对象。
1 相关研究
虚假评论文本的检测与识别方法很多,包括无监督学习、半监督学习和有监督学习,深度学习模型在虚假评论识别研究得到应用。深度学习模型识别主要分为基于内容的虚假评论文本识别与基于文本特征的虚假评论识别两种。Yan等提出的神经网络模型对于虚假评论信息检测的准确率达到85%;陶晶晶提出的基于并联方式的混合神经网络识别模型,在对虚假商品评论数据检测中达到90.3%的准确率。
本文基于酒店英文评价数据集deceptive-opinionspam-corpus,利用Doc2Vec 将文本向量化后作为特征集,结合TF-IDF 方法,使用CNN-LSTM 模型和迁移学习方法,构建了一个虚假英文评论分类模型,并在数据集deceptiveopinion-spam-corpus 上进行对比实验。实验结果表明,该模型对虚假评论的检测达到93.1%的准确率。
2 数据与方法
2.1 数据集
deceptive-opinion-spam-corpus 数据集是一个只有1 600 条评价的中小型数据集,包括对20 家芝加哥酒店真实和虚假的在线评论。deceptive-opinion-spam-corpus 数据集包含800条来自Mechanical Turk的虚假评价和800条来自TripAdvisor 与Expedia 的真实评价,其中正面评价与负面评价在真实评价与虚假评价中的占比均为1∶1,如图1所示。
本文对deceptive-opinion-spam-corpus 数据集的英文评论文本进行了数据预处理,预处理后的英文评论文本中不包含任何标点符号、特殊字符以及阿拉伯数字。

Fig.1 Distribution of dataset data图1 数据集中数据的分布
2.2 对照方法
本文使用基准方法为传统的Logistic 回归算法、朴素贝叶斯分类算法以及一种能够有效检测虚假文本的卷积神经网络模型,简称CNN1。CNN1 由三层卷积神经网络组成,每一层卷积神经网络都包含一层卷积层和最大池化层。Logistic 回归是一种广义的线性回归分析模型,是一种用于解决二分类问题的机器学习方法;朴素贝叶斯分类模型是一种快捷简单的机器学习分类算法,常为文本分类问题提供快速粗糙的基本方案,模型的数学基础是贝叶斯定理;卷积神经网络在很多领域表现优秀,可有效提取评论特征并进行识别。
对deceptive-opinion-spam-corpus 数据集进行数据预处理后,应用上述3 种算法,取训练集与测试集的比例为8∶2,对数据集中酒店评论文本的真实性进行检测并验证。
最终结果如图2 所示。Logistic 回归算法的准确率score_1 为84.017 8%;朴素贝叶斯分类模型的准确率score_2 为79.910 7%;CNN1 的平均准确率score_3 为78.561 0%。
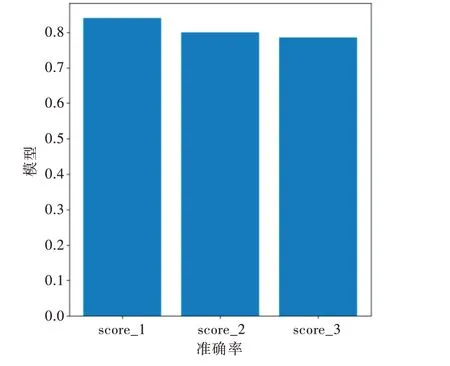
Fig.2 Experimental results of benchmark method图2 基准方法实验结果
2.3 有关算法
2.3.1 数据预处理及特征提取
首先对数据集deceptive-opinion-spam-corpus 的文本与标签数据进行预处理,再利用doc2vec 对文本数据进行特征提取并利用TF-IDF 方法将评论数据向量化。
Doc2vec 是基于Word2vec 模型提出的可以保留次序语义的语义模型,该模型在Word2vec 模型基础上增加了一个段落标识。Doc2Vec 能将句子或段落转化为固定长度的向量,且充分考虑了词序对语句或文档信息的影响,能很好结合上下文语境,保留语序信息。因此,Doc2vec 常用于处理短文本的自然语言处理问题。TF-IDF 模型是一类应用广泛的加权技术,经常被用来进行信息检索和数据挖掘。TF-IDF 模型的核心思想是,若某个词汇在文本出现概率较大,而该词汇在其他文本中出现概率较小,则此词汇具有更好的类别判别性能和分类泛用性。
数据预处理和特征提取方式如下:①将标签数据向量化;②对文本数据进行预处理,包括删除特殊字符和数字,将文本中的词语转化为词干形式等;③将数据集按比例随机划分为训练集、测试集和验证集;④将训练集中的文本数据利用doc2vec 方法进行特征提取;⑤利用TF-IDF 模型将数据集赋予权重并向量化。
2.3.2 基于CNN-LSTM 的模型
卷积神经网络(Convolutional Neural Networks,CNN)是一种专门用来处理具有类似网络结构数据的神经网络,其在图像处理上很优秀,不仅运行速度快、效率高,而且准确率高。其工作原理是首先通过卷积层进行图像特征提取,然后通过激活函数层使得特征提取达到一个非线性效果,从而使特征提取结果更好。经过多层卷积以及多层激活函数层后,通过池化层对提取出来的特征进行压缩。最后通过全连接层,对之前提取和处理过的特征进行连接,最终得到属于各个类别的概率值。而在文本分类领域中,卷积神经网络可以通过多个不同大小的卷积核实现对输入文档内容的特征提取。
长短期记忆网络(Long Short-Term Memory,LSTM)是对循环神经网络(Recurrent Neural Network,RNN)的改进,是为解决一般的RNN 存在的长期依赖问题而专门设计的。它在RNN 基础上对Cell 中的运算方式进行了改进,使得神经网络在训练和推断过程中具有一定的长时依赖性,不仅无需在学习过程中保存冗长的上下文信息,还可有效降低梯度消失的风险。因此,LSTM 模型多用于时间序列分析与自然语言处理等研究。
本文使用的CNN-LSTM 模型是将CNN 模型与LSTM 模型等结合并运用在自然语言处理研究中。CNN-LSTM 模型结合了CNN 和LSTM 这两种不同的深度学习模型的优点,在某些深度学习问题中,相比于单独使用CNN 模型或LSTM 模型能更有效地提高模型的准确率。
2.3.3 CNN-LSTM 与迁移学习模型
卷积神经网络的参数训练需要大量的标记样本数据,但本文的酒店评价样本规模不大,因此决定引入迁移学习方法,借助已经训练好的模型权重进一步学习。
GloVe 是一种无监督学习算法,用于获取单词的向量表示,模型得到的向量表示展示了词向量空间的线性子结构。GloVe 模型是在一个全局词—词共生矩阵的非零项上训练的,该矩阵列出在同一作者给定语料库中词与词共同出现的频率。GloVe 模型本质上是一个带有加权最小二乘目标的对数双线性模型,该模型背后的主要直觉是一个简单的观察,即单词共同出现的概率可能存在某些编码上的潜在意义,如考虑目标词ice 和steam 与词汇表中各种探测词的共现概率。表1 为来自60 亿单词语料库的一些实际概率。
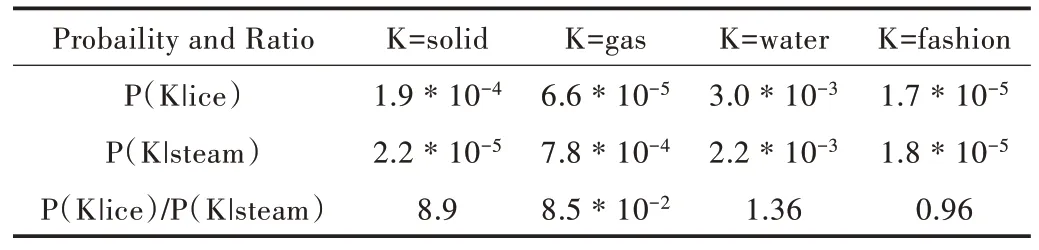
Table1 Co-occurrence probability of ice and steam表1 ice 与steam 的共现概率
glove.6B.300d 模型利用常规的GloVe 模型训练得到40 000个常用英文词向量,每个单词的对应词向量均为300 维。本文利用GloVe 模型训练得到glove.6B.300d 词向量,在CNN-LSTM 模型中结合glove.6B.300d 英文词向量模型,实现对deceptive-opinion-spam-corpus 数据集的迁移学习。通过迁移学习,一方面缩短了模型训练时间,另一方面有效增强了模型的泛化能力。
此外,由于deceptive-opinion-spam-corpus 数据集数据量较小,在模型构建完成后,利用10 折分层交叉验证对模型进行更加客观的评估,确保验证数据中每一类数据所占比例与原数据集中每一类数据所占比例相近,以避免极端数据选取情况下导致的实验结果失真,更加客观地评估模型对于训练集之外数据的匹配程度。
3 模型构建与实验结果
3.1 基于CNN-LSTM 的模型
在Window10 环境下,利用python 作为编程语言,以TensorFlow 作为后端,基于Keras 构造CNN-LSTM 模型。此模型共计4 段卷积网络,每一段卷积网络由一层卷积层和一层池化层构成。4 层卷积层的卷积核数分别为128、32、32、32。每层卷积网络后均为一个2×2 的最大池化层。为防止模型过拟合,在每层卷积层与池化层后加入参数为0.1~0.3 之间的Dropout 层,以增强模型泛化能力。通过4 段卷积神经网络后,将结果输入双向LSTM 模型中,最后进入一个全连接层(Dense)。模型结构如图3 所示。

Fig.3 CNN-LSTM model structure图3 CNN-LSTM 模型结构
将此CNN-LSTM 模型运用于deceptive-opinion-spamcorpus 数据集,训练数据与测试数据的数量比为8∶2,损失函数选取binary crossentropy 函数,激活函数选取softmax 函数,优化方法选取adaptive moment estimation算法。deceptive-opinion-spam-corpus 数据集中的英文评论数据经过处理后得到的形式如图4 所示。

Fig.4 Example of original data and its corresponding eigenvector图4 原始数据与其对应的特征向量示例
经过40 轮次迭代训练,模型训练过程的准确率与损失函数变化如图5 所示。由测试集准确率曲线和测试集损失曲线可以看出,模型在第25 轮迭代训练之后逐渐开始过拟合。最终CNN-LSTM 模型在测试集上得到的最高分类准确率为86.5%,在训练的第23 轮得到。
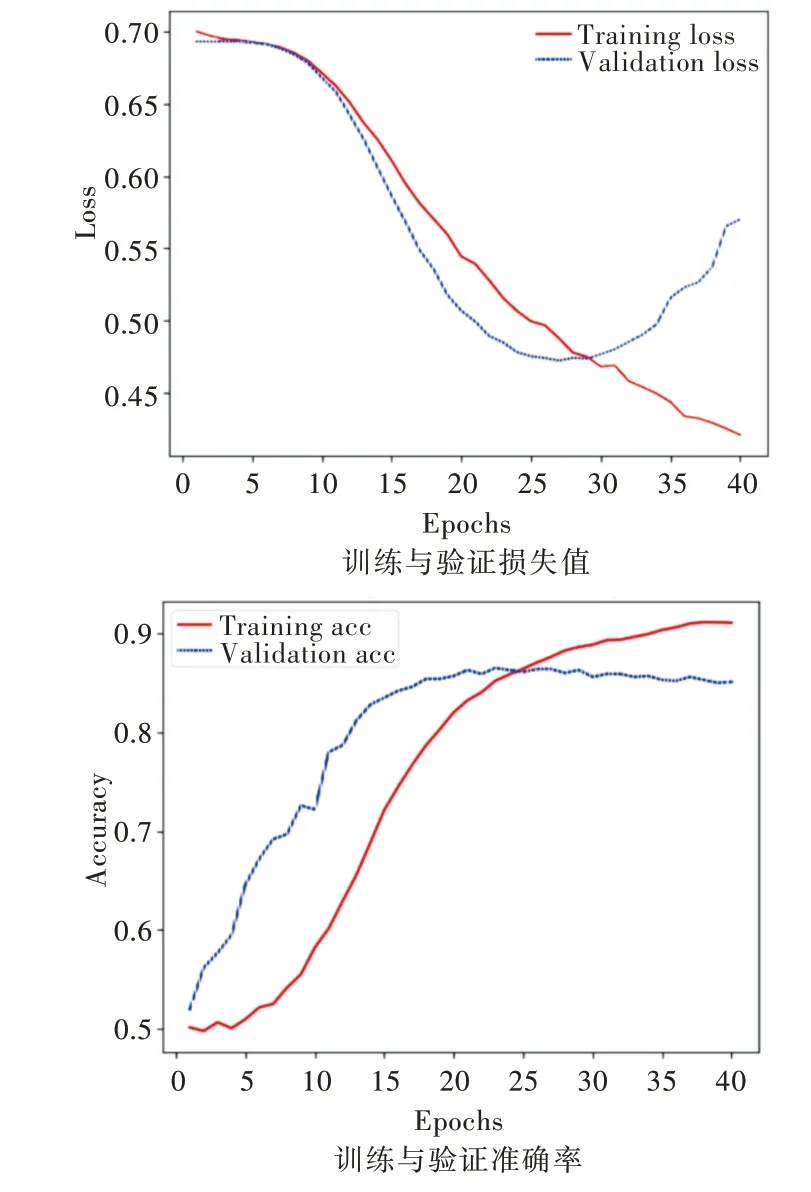
Fig.5 CNN-LSTM model training curve图5 CNN-LSTM 模型训练曲线(彩图扫OSID 码可见,下同)
3.2 基于CNN-LSTM 与迁移学习的模型
在CNN-LSTM 模型基础上,利用GloVe 模型训练得到300 维英文词向量模型glove.6B.300d,将其进行迁移学习,再在结合CNN-LSTM 模型在deceptive-opinion-spam-corpus 数据集上进行实验。迭代轮次设置为40 轮,损失函数、激活函数、优化方法均与前述模型相同。最后利用10 折分层交叉验证来对此模型的分类效果进行客观评估。
CNN-LSTM 与迁移学习结合的模型在测试集上的准确率变化曲线如图6 所示。其中两条实线为10 折分层交叉验证的验证准确率(val_acc)迭代曲线在每一迭代轮次中的最大值(最小值)所连成的曲线,虚线为10 折分层交叉验证在每一迭代轮次中的验证准确率平均值曲线。其中,平均验证准确率的最大值为93.1%,在迭代第25 轮时得到。所有训练的最大验证准确率为94.9%,在第25 轮K 值为7时取得。
4 实验数据分析
通过实验得到数据见表2。由表2 及上文数据可知,在基于酒店英文评论数据集deceptive-opinion-spam-corpus的真假评论分类任务中,本文提出的CNN-LSTM 与迁移学习模型有着较好的分类效果。其在deceptive-opinionspam-corpus 数据集的平均验证准确率可达93.10%,最高准确率可达94.9%,平均准确率明显好于其他模型。此外,对于CNN-LSTM 模型进行迁移学习后的准确率提升了约7%。

Fig.6 Model training iteration data图6 模型训练迭代数据

Table 2 Comparison of algorithm experimental results表2 算法实验结果对比 (%)
将模型参数保存,对整个deceptive-opinion-spam-corpus 数据集上的评论数据进行分类,并随机提取两条模型分类错误的文本,如图7 所示,其中(1)为虚假评论、(2)为真实评论。随机采访13 名受访者,在不告知任何信息情况下,仅有4 名受访者对于(1)与(2)的真实性判断全部正确。因此,单从文字表达上普通读者也难以判断(1)、(2)两条评论的真实性。

Fig.7 Original comment of wrong judgment of the model图7 模型判断错误的评论原文
5 结语
本文利用酒店英文评论数据集deceptive-opinionspam-corpus 作为实验数据集,在传统的CNN-LSTM 模型上进行改进。利用GloVe 模型的迁移学习方法,有效提高了虚假英文评论的识别能力,分类精度最高可达93%~94%。相比于经典的Logistic 回归算法和朴素贝叶斯分类算法以及CNN1算法,其分类准确率提升了16.52%~18.50%。由此得出结论,在虚假文本检测问题上,采用深度学习方法比传统方法有着更高的准确率,采用CNN-LSTM 与迁移学习相结合的模型能够进一步提高检测准确率。同时,对于其它类型的英文短文本分类问题也可尝试使用CNNLSTM 模型并结合GloVe 模型进行迁移学习。但由于互联网中短文本资源数量庞大且内容极为复杂多样,因此针对该领域的可用数据集少。此外,由于深度学习模型自身的特性,一般的深度学习模型跨领域可移植性差,导致其无法精准地处理多样化的任务与问题。因此,在实际应用中,采用迁移学习的方法仍存在提升空间,如何将小样本学习和迁移学习方法应用于短文本情感倾向分析值得后续进一步探讨。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
医学食疗与健康(2021年27期)2021-05-13
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电视技术(2014年19期)2014-03-11
