
融合注意力机制和Bi-LSTM 的旅游评价情感分析模型
2022-03-07 06:57陈玉娇陈崇成吕贵杰黄正睿
软件导刊 2022年2期
陈玉娇,陈崇成,吕贵杰,黄正睿
(福州大学 数字中国研究院(福建),福建 福州 350100)
0 引言
随着在线旅游网站的迅速发展,其上的评论文本数量急剧增加,这为旅行研究提供了重要数据来源。海量的评论数据揭示了公众的情感或态度,这对于旅游行业中的相关应用具有重要价值。在线评价的文本数据可以帮助研究人员和从业人员正确了解游客的旅游偏好和需求。在线评价的文本数据中所表达的意见对潜在旅游者的选择起着重要作用。
情感分析是一个可以从在线旅行评价文本中提取游客关于旅行目的地情感的过程,情感分析的结果构成了旅游决策的重要基础。因此,必须引入有效的情感分析技术以处理在线旅行评价文本数据。然而,在线旅行评价文本大部分是短文本,其特征在于情感分布不均,这使得难以获得准确的情感分析结果。Bi-LSTM 能够有效地获取上下文语义信息,注意力机制可突出评论语句中情感描述内容的重要部分。因此,本文提出融合注意力机制和Bi-LSTM 的旅游评价情感分析模型,更加精确地分析游客评价的情感倾向。
1 相关工作
近年来,随着人工智能的迅速发展,作为人工智能分支的自然语言在研究领域备受关注。许多学者利用自然语言技术对互联网信息进行情感分析,该研究是自然语言处理中最热门的话题。
情感分析被称为人工智能领域的王冠,旨在使用相应的技术手段挖掘和分析主观信息。传统的情感分析技术主要基于词典、规则的方法和基于机器学习的方法。基于词典、规则的方法侧重于识别文本中具有明显情感倾向的词语,并依据特定的规则预测情感。Grabner 等提出用于游客评论分类的情感分析词典;Liu 等使用基于词典的情感分析模型以分析澳大利亚目的地中国游客的在线评论。该技术需要大量的人工干预,最终分析结果过于依赖词典的质量和规则。随着信息量的快速增长,仅通过手动处理根本不可能完成任务。基于机器学习的方法凭借出色的模型构建能力,在自然语言处理任务中大放异彩,诸如朴素贝叶斯(Naive Bayes,NB)、支持向量机(Support Vector Machines,SVM)、最大熵等。Hao 等从新闻媒体的角度使用基于机器学习的情绪分析方法研究居民对旅游业态度的演变;Adhi 等设计一个基于朴素贝叶斯分类器和语义扩展方法的情感分析模型,实验表明该方法可以提高情感分析的准确性。但基于机器学习的方法过于依赖标注数据的质量并需要复杂的特征工程。近年来,随着深度学习的发展,越来越多的学者将基于神经网络的方法应用于情感分析。不同于传统的情感分析技术,深度学习不需要构造情感词典或语法分析,只需一定规模的训练数据集,就可训练得出高精度分类结果和泛化能力较好的深度学习模型。卷积神经网络(Convolutional Neural Networks,CNN)是最常应用于情感分析任务中的深度学习方法。Kim首次将简单的卷积神经网络应用于句子分类并取得了良好结果,克服了传统机器学习的不足;Santos等使用两个卷积层以提取相关单词和句子的特征,并挖掘语义信息以改善诸如Twitter 之类的短文本情感分析;Liu等指出CNN 能够从时间或空间数据中学习局部特征,但缺乏学习顺序相关性的能力;Irsoy 等使用基于时间序列信息的递归神经网络获得句子表示,从而进一步提高了情感分类准确性。长短期记忆神经网络(Long Short-Term Memory,LSTM)考虑词语之间的序列依赖性,从而有效解决传统递归神经网络(Recursive Neural Network,RNN)出现的梯度消失问题。Law 等使用长短期记忆(LSTM)神经网络预测旅游流量,并证明LSTM 方法的性能优于其他传统方法。但是LSTM 只具有前向信息记忆能力,而不能对后向序列进行记忆,Bi-LSTM 随之被提出。Bi-LSTM 是LSTM 的进一步发展,可以更好地捕捉双向的语义依赖。李磊等提出融合对象识别和Bi-LSTM 模型情感分析模型,主要通过CNN 识别关键评价对象,将评价对象与文本信息进行融合并通过Bi-LSTM 模型分析最终的情感类别。但评价语句中的最重要部分是情感描述部分,表达用户观点,为了更加精确地分析游客评价的情感倾向,本文使用注意力机制突出评价语句中的核心部分。
注意力机制在成像领域的成功发展使其神经网络模型成为近年来研究的热点之一。Yin 等提出一种基于注意力机制的卷积神经网络。该模型分别在卷积层和池化层中构造注意力矩阵。通过不同网络层的注意力信息,可以了解句子对之间的相互依存关系。该模型还验证了注意力机制和卷积神经网络在自然语言处理任务中的有效性。张仰森等为提高分类性能,将情感符号融入注意力模型以增强情感语义;吴小华等提出一种结合Selfattention 和BiLSTM 的中文短文本情感分析模型,实验表明该模型能学到更多的文本自身关键特征,情感分类结果相较于BiLSTM 有所提高。虽然上述神经网络模型在情感分类任务中已经取得了巨大成功,但仍有较大改进空间。例如,针对旅游评价情感分析,情感词汇、否定副词(“如果不是”“从不”)、程度副词(“有点”“非常”)等资源具有较强的情感表现。但是,目前的深度神经网络模型对旅游评价情感分析时,这些资源尚未得到充分利用。为此,本文提出融合词性注意力机制和Bi-LSTM 的旅游评价情感分析模型,从词性角度出发,判断情感相关词语的词性并以其为核心词计算评价语句中各位置权重,以融合到Bi-LSTM评价语句的实际上下文信息中,突出情感相关词语的重要性,从而提高情感分析效果。
2 旅游评论情感分析模型
传统基于情感词典的方法,包括:①识别文本中的情感词与副词;②将情感词及其前面的否定副词、程度副词归为一组(如果有否定词副词,情感词则乘以-1;如果有程度副词,就乘以程度副词的程度值);③根据累计得分的正负判断极性。基于上述步骤可知,情感词与副词是文本中的重要信息,在情感分析中起到决定性作用。然而,基于情感词典的方法需要人工干预,泛化能力差;而Bi-LSTM能自主学习文本上下文语义信息,基于注意力机制选择重要信息可获得良好效果。为有效地突出情感相关词的作用,本文提出结合词性注意力与Bi-LSTM 的模型。不同于传统的Bi-LSTM 和注意力机制,文本采用Bi-LSTM 和词性注意力并行的结构,网络结构如图1 所示:①分别对评论语句进行词向量化、自然语言词性标注;②分别经过Bi-LSTM模型和词性注意力模型;③将两者结果融合,并将其输入到全连接层中;④通过Softmax 预测情感极性。
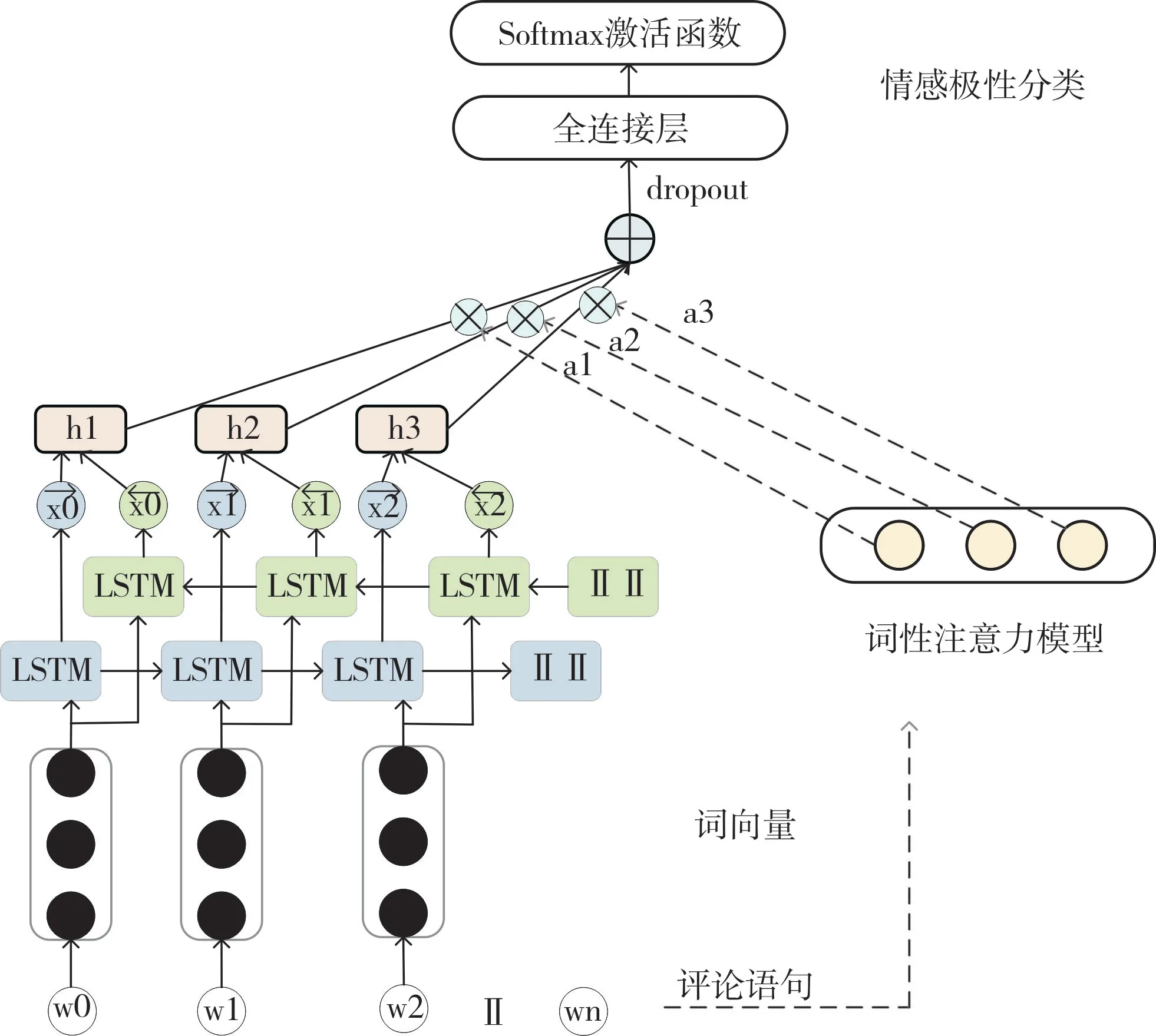
Fig.1 Part-of-speech attention mechanism-based Bi-LSTM图1 基于词性注意力机制的Bi-LSTM
2.1 词向量
在自然语言任务中,首先需要考虑词语在计算机中的表示方式。通常,有两种表示方式:离散表示和分布式表示。典型的离散表示是独热编码,这是一种传统的基于规则和基于统计的自然语义处理方法。但是该方法表示的词向量只能是单独个体,无法建立词与词之间的语义关系。为避免上述缺陷,本文采用分布式词嵌入方法将文本中的词映射到300 维的连续密集向量。常见的预训练词嵌入 有Word2Vec和Glove,本文采用Word2Vec 作为模型的输入表示。
2.2 双向长短期记忆神经网络(Bi-LSTM)
LSTM 与典型的RNN 框架一致,但是它使用不同的方式计算隐藏状态,从而可以解决RNN 中梯度消失问题。LSTM 的出色之处不是通过算法学习的,而是模型结构固有的优势。LSTM 由一系列重复的存储单元组成,每个单元包含3个不同功能的神经门:输入门、遗忘门和输出门。以下是这些门以自适应记住输入向量,忘记以前的历史,生成输出向量的过程。
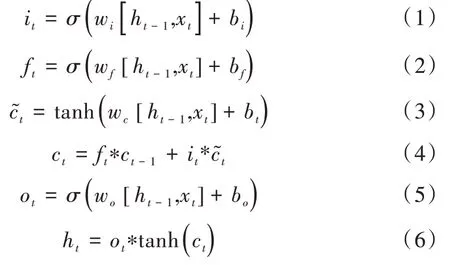
i
、f
、o
表示输入门、遗忘门与输出门,w
、w
、w
表示权重矩阵,b
、b
、b
表示偏置项,h
表示t
时刻的隐藏状态向量。LSTM 只考虑前向语义信息,而Bi-LSTM 充分考虑了序列上下文信息,由一个正向的长期短期记忆层和一个反向的长期短期记忆层组成。正向捕获序列的历史信息;反向捕获序列的将来信息。以上两层都连接到同一输出层。为了突出情感相关词语在句子中的作用,本文加入了词性注意力机制,将Bi-LSTM 的输出进行了微调。
2.3 词性注意力机制
所有词对上下文的情感都有不同的贡献,因此为词分配不同的权重是解决问题的一种有效方法。注意力机制最早是在图像处理领域提出的,其目的是在模型训练过程中关注某些特征信息。引入注意力机制为词分配不同的权重以突出重要部分,减少非关键词对文本情感的影响,增强对整个文本情感的理解。比如句子中的情感词(不好、贵等)可以反映评论者的情感倾向,为了更加关注这些情感词的分类,本文采用词性注意力机制。
旅游的评论中并不是每个词都包含情感信息成分,观点词绝大部分由形容词表示,副词对其进行修饰,副词包括否定副词、程度副词。本文首先利用词性标注的自然语言技术对旅游在线评论数据进行处理,将句子分割为不同词性的词语。将句子中形容词和副词确定为情感分析的核心词。根据局部注意力机制的思想给定固定窗口大小,随着其它词在窗口中远离核心词移动,其权重逐渐降低。鉴于此,本文以核心词为中心,为句子中每个词分配不同权重。
本文注意力模型中的w
与每一个词和核心词的距离有关,但不固定窗口大小。给出一个由n
个词组成的句子S
={s
,s
,…
,s
} 和核心词列表C
={c
,c
,…
,c
},m
∈n
,每个词的权重通过式(7)—式(8)计算得到。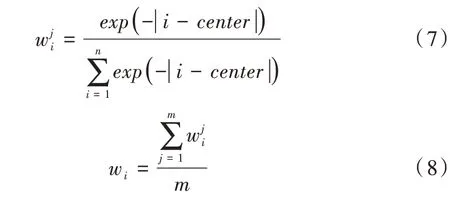
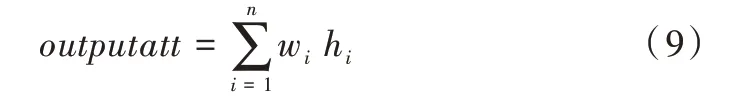
2.4 情感极性分类
情感分析实质上是一个分类任务,因而将outputatt
作为分类的特征,紧接一个大小为0.75 的Dropout
层,以减轻训练过程中的过拟合。通过全连接方式采用softmax
激活函数进行情感分类,计算如式(10)所示。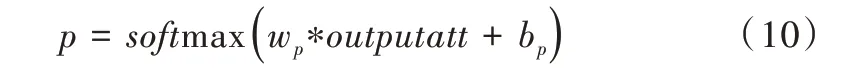
3 实验与分析
3.1 数据集
实验数据来自携程网站上的福建旅游在线评论。选取其一部分作为实验数据集,数据集包含11 041 条评论,其中5 557 条为正,5 484 条为负。按照4∶1 的比例将数据集分为训练集和测试集,情感评价数据集的样本如表1 所示。

Table 1 Samples in sentiment evaluation dataset表1 情感评价数据集样本
3.2 实验环境与参数设置
实验硬件平台是Intel(R)Core(TM)i7-6700 CPU@3.40 GHz(8 核CPU),16G 内存,Intel(R)HD Graphics 530。实验软件平台为Win10 操作系统,开发环境为Python3.7 编程语言。Python 的Tensorflow 库和Scikit-learn 库用于构建建议的情感分析方法和对比实验。
根据实验,已经测试了不同的超参数和设置。通过比较,最终选取以下参数:词向量的维度为300,学习率为0.000 01,dropout
取值为0.75,batch_size
取值为30,lstm_size
取值为32,迭代次数为20k。3.3 实验评价指标
使用准确率、精确度、召回率和F
1 得分评估模型性能。分类矩阵如表2 所示。
Table 2 Classification matrix表2 分类矩阵
在此,TP
代表正类预测为正类的数量,FN
代表正类预测为负类的数量,FP
代表负类预测为正类的数量,TN
代表负类预测为负类的数量。根据TP
、FN
、FP
和TN
的数量分别计算准确率、精确率、召回率和F
1 得分。具体公式如式(11)—式(13)所示。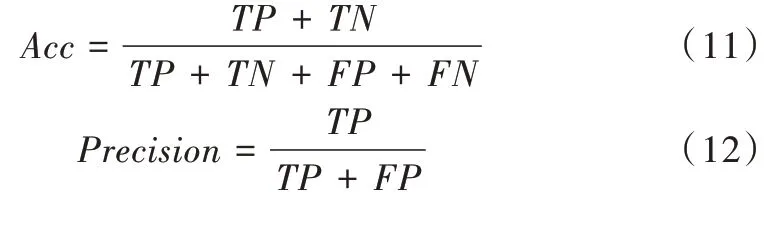
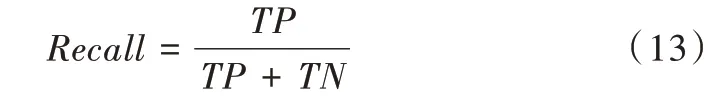
3.4 实验结果与分析
为了证明本文模型的有效性,将本文提出的模型与CNN、Bi-LSTM 模型、Bi-LSTM-CNN 模型以及自注意力机制与Bi-LSTM 结合的模型在旅游在线评论数据集上进行实验比较,比较指标包括准确性、召回率和F
1 得分。实验结果如表3 所示。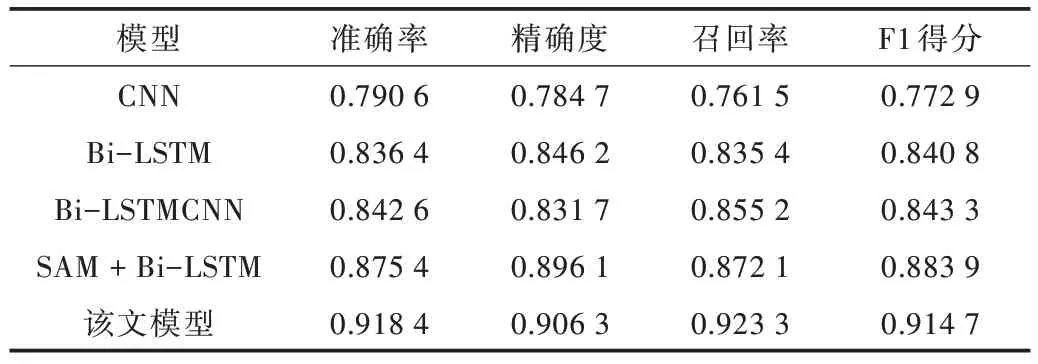
Table 3 Experimental results表3 实验结果
实验结果表明,Bi-LSTM 的总体性能由于能有效捕获上下文信息,而比CNN 的性能更好。而Bi-LSTM-CNN 模型具有比其他模型更高的度量指标,这证明了混合模型确实结合了CNN 和LSTM 的优势。与SAM+Bi-LSTM 相比,本文所提出的模型在处理“仙境一般云雾缭绕,门票也不贵”旅游评价情感分析时,充分考虑到评论语句中“仙境”“不贵“情感相关信息对分类任务起到重要作用的信息,有效地识别出该评论语句的情感倾向。本文模型在旅游情感分析上展现了较好的性能,准确率提高4.3%,精度提高1.02%,召回率提高5.12%,F
1 得分提高3.08%。4 结语
在互联网技术和社交网络飞速发展的时代,通过人工智能技术探索评论的情感倾向极具意义。针对当前情感分析任务中没有充分把握情感信息,导致分类精度不高的问题,本文通过Bi-LSTM 学习文本的上下文语义信息,建立词性注意力机制并赋予情感词更高的权值,以强化情感词的重要性。不同于传统Bi-LSTM 加注意力机制的模型,本文采用Bi-LSTM 和词性注意力并行的网络结构,具有更好的模型性能与分类精度。因此,Bi-LSTM 和词性注意力机制的结合在旅游情感分析方面具有实际应用价值。
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24
小雪花·成长指南(2022年1期)2022-04-09
三门峡职业技术学院学报(2021年4期)2021-04-19
电子制作(2019年19期)2019-11-23
传媒评论(2017年3期)2017-06-13
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
高中生学习·高三版(2014年3期)2014-04-29
