
推荐系统公平性评价方法:现状与展望
2022-03-05 07:51赵海燕陈庆奎
小型微型计算机系统 2022年3期
赵海燕,周 萍,陈庆奎,曹 健
1(上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海理工大学光电信息与计算机工程学院,上海200093) 2(上海交通大学 计算机科学与技术系,上海200030)
1 引 言
目前,推荐系统已经被广泛应用,它通过平台从用户的行为和信息中获取有用的数据,然后对数据进行学习,在此基础上,系统为用户针对每个潜在的候选物品计算出相关的评分或者对物品进行比较,根据评分或者比较结果对这些潜在候选物品进行排序,最后给出推荐列表.
在上述过程中,推荐系统可能产生不公平的结果,其原因来自多个方面.首先,一个主要的原因是数据本身存在的“偏见”(Bias)[1].例如,有研究表明,使用有偏见的数据训练的机器学习模型也将包含偏见,从而使得预测的结果也存在偏见[2],这将直接导致推荐系统的结果不公平性.例如,在电商平台上根据消费者以往的行为(包括浏览、购买等行为)对消费者进行个性化推荐时,行为数据比较丰富的消费者得到的推荐结果将更为集中于他的偏好产品中[3],这导致了更为严重的“信息茧房”现象;而对于平台的商家而言,在支付了与其他商家同等额度的佣金情况下,由于产品比较小众或浏览购买力度不够等原因导致该商家无法获得同等的曝光量,从而引发“马太效应”;在网络招聘平台,由于现实生活中从事高薪工作的女性较少而导致女性不太可能看到高薪工作的广告等[4].除此以外,推荐算法本身也可能存在偏见,例如,由于算法设计的问题,可能使得某一类型的群体在推荐质量或者其他方面比其他群体更有优势.
事实上,计算机系统中的偏见和歧视问题正成为社会学和技术研究的前沿[5].有偏见的计算机系统可能造成系统地、不公平地对某些个人或群体进行歧视,而对其他个人或群体有利.偏见-感知机器学习也是近年来的一个研究热点,其目的是构建无偏见的机器学习模型.为了实现这一目标人们进行了许多工作,从历史训练数据[6-10]或构造的机器学习模型[11-14]中检测和消除偏见.
推荐系统是机器学习的典型应用,因此,消除偏见,提高推荐系统结果的公平性也成为了当前的研究热点.与此同时,传统的推荐系统主要从相关性、多样性以及新颖性等指标出发进行质量评估,着重于提高预测用户与项目互动的准确性[15,16],而对推荐系统社会影响的关注也进一步使人们把公平性也纳入推荐系统的指标中.这些因素促使近年来许多研究者围绕推荐系统公平性问题展开了研究工作.
将偏见与公平性相比,偏见是一种客观现象,而公平性是一种社会性的主观评价准则.因此,提高推荐系统的公平性的前提是建立推荐系统公平性的指标,指标定义的不同将直接决定后续算法的差别.过去,研究者们提出了许多不同的指标,迫切需要对指标进行整理.本文分别从利益相关者、粒度以及推荐次数3个维度对指标进行了分类,详细地从利益相关者的维度对推荐系统的公平性评价指标进行了总结,并对这些指标的关系进行了分析.
2 推荐系统公平性的分类
推荐系统公平性可以从不同角度分类,本文从利益相关者、粒度以及推荐次数等维度对推荐的公平性指标进行分类.
推荐系统通常涉及到多个利益相关者[17].文献[18]将推荐系统从利益相关者的角度将分为3个部分:接受者、提供者、其他利益相关方.推荐系统中除了推荐物品接受方(用户)和推荐物品提供方,还有其他利益相关方,如提供推荐算法的平台和其他相关成员.例如,在美团外卖这样的平台上,我们可以观察到4个主要的利益相关者:1)使用该应用程序并接收不同顾客订单的商家(提供者);2)使用该应用程序消费下单的用户(接受者);3)将外卖从商家送到指定用户地址的外卖员(其他利益相关方);4)美团(其他利益相关方).因此,在研究推荐系统公平性时,需要满足多方利益相关者的需求与喜好.
文献[18]针对这3部分成员,提出了对应的公平性要求:
1)C (Customer)-fairness:接受者(用户)推荐公平性.要求推荐系统公平对待各类别的消费用户,从而保证受保护类别(由性别、年龄、国籍等来区分的不同群体)不被系统区别对待.
2)P (Provider)-fairness:提供者推荐公平性.要求推荐系统公平对待各类别项目(物品或服务)提供者,保证受保护类别有同样机会接触消费用户.
3)S (Supplement User)-fairness:其他利益相关者推荐公平性.要求推荐系统公平对待利益相关者的需求,例如美团外卖中外卖员的配送服务有距离、位置等需求,美团外卖平台有经济效益需求.
根据公平性针对的群体粒度分类可以划分为个体公平性和群组公平性.个体公平性要求相似的个体得到相似的对待,群组公平性要求不同群组的推荐结果是均衡的.根据推荐次数可以分为多次累计推荐公平性和单次推荐公平性.一般而言,离线推荐可以保证单次推荐的公平性,而线上推荐一般只能保证多次推荐的累计公平性.
3 符号说明
本文用A表示用户集,用户a∈A,共M个用户,I表示物品集,I中共有N个物品供推荐,物品w∈I.将敏感属性,即在推荐系统中会被区别对待的相关属性表示为G,t表示属性值,大部分属性值可以用二进制表示,使用0表示在推荐系统中受到歧视的群组,在推荐中应当对相关群体给予适当保护,称之为受保护群组,1表示推荐系统中受到偏爱的群组,称之为非受保护群组.
许多检索中用NDCG评价检索结果的相关性强度[19],推荐系统中往往也涉及大量排序工作,本文用r表示排序列表,排序的质量也需要被评价,所以使用U表示排序效用.推荐系统中涉及大量概率数据,用P表示相关概率.
推荐系统包含首页推荐和筛选推荐,首页推荐不需要用户输入筛选条件,系统直接为用户推荐物品.筛选推荐需要用户输入筛选条件,系统根据条件为用户推荐,用查询q表示用户输入的筛选条件.
4 物品提供方的公平性评价
通常情况下,推荐系统上的物品(项目)是由多方提供的.对于物品提供方而言,希望他们的物品能够接触到受众群体[20],以增加其销售量.因此,从推荐系统中候选物品的角度上来说,如何公平地给予所有候选物品被选择的机会成为推荐系统应当考虑的重要问题[21].
在不同的推荐环境下,公平性评价的侧重点不同,导致公平性的定义与评价标准也有所不同.本节结合不同的应用环境对物品提供方的推荐公平性评价进行总结.
4.1 基于Top-k排名的公平性
在推荐页面上,不同位置的物品受到的关注度是不同的,排名越靠前的物品用户越关注,用户接受推荐的可能性也越大[22],因此靠前的位置比靠后的位置更有必要评价公平性.针对排序的公平性,应该逐级计算公平程度并赋予每一级不同的重要性.
公平性定义的依据包括:
1)排名公平性:受保护群组应当在每一级排名(例如前10名、前100名)中都被公平对待,保证每一级中受保护群组的数量都占有一定的比例[22].
2)机会均等公平性:受保护群组和非受保护群组获得有利结果的机会均等[23],即推荐的候选物品中各群组比例与满足筛选条件的候选物品中的各群组比例一致.
3)统计均等公平性:推荐与排序过程中,受保护群组与非受保护群组的数量比例与整体统计对应比例一致[24].
依据上述公平性的依据,不同文献中提出了基于Top-k排名的公平性评价标准.
文献[22]认为排名列表应该尽可能根据候选物品的质量排序,即排名结果应该包含最符合筛选标准的候选物品,候选物品的质量应当逐名递减,同时,每一级分布也应满足排序群组公平性.该方法中以受保护群组在排序中的最小目标比例p作为输入,如果实际比例远低于目标比例,就表明排名是不公平的.文献[22]提出排序群组公平性(Ranked group fairness)评价标准,将排名Top-k中受保护元素的数量与使用伯努利(Bernoulli)试验随机挑选的受保护元素的预期数量进行比较.该标准是基于统计检验的,因此,文献[22]设置了一个显著性参数α,作为否定一个公平排名(第一类错误)的概率水准.统计量分布满足参数为n,p的二项分布累积函数,用F(x;n,p)表示.相关的公平性评价标准如下:
对于排序列表r,公平性表示的条件为:
一个公平的Top-k受保护组物品列表r0要满足显著性水平α和受保护组物品最小比例p的二项分布累积函数F(r0;k,p)>α.
公平性评价标准1:
排序群组公平性:所有的前k项(前10项、前20项、前30项……)的排序,均要求受保护群组的候选物品列表满足二项分布累积函数F(r0;k,p)>α.
另外,排序群组公平性要求对显著性水平逐级调整,文献[22]根据受保护组物品最小比例P、序列规模k和显著性水平α设计了算法对每一级αk分别进行了修正.
文献[25]在统计均等公平性的基础上,提出根据受保护群组物品在各层级排序中所占的比例与总体分布中所占比例的差异情况来评价公平性,并提出了3个评价标准:归一化折扣差异(Normalized discounted difference,rND)、归一化折扣KL散度(Normalized discounted KL-divergence,rKL)和归一化折扣比例(Normalized discounted ratio,rRD).
公平性评价标准2:
归一化折扣差异(rND):通过对各级Top-k与总集合中受保护群组候选物品比例的差异进行加权和计算(对排名位置对数折扣化获得权重值),再对加权和结果进行归一化作为评价值.
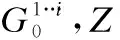
(1)
对于给定的N个候选物品和|G0|个受保护组候选物品,Z为最大的rND概率值.
公平性评价标准3:
归一化折扣KL散度 (rKL):使用KL散度计算Top-k与总集合中受保护群组候选物品比例差异,对不同层级的差异值进行加权和计算(对排名位置对数折扣化获得权重值),对加权和结果进行归一化作为评价值.
KL散度用于计算Top-i与总集合中受保护组候选物品的比例差异,计算方法如公式(2)所示:
(2)
各组候选物品在Top-i与总集合中的占比表示如公式(3)所示:
(3)
对对数折扣化KL散度进行归一化,计算方法如公式(4)所示:
(4)
与rND相比,rKL具有类似的效果,但曲线更加平滑,可能更有利于优化.
公平性评价标准4:
归一化折扣比例(rRD):分别计算受保护组候选物品和非受保护组候选物品在各层级中与整体集合中的分布(受保护组与非受保护组的物品数量之比),再计算各群组在各层级中与整体集合中的分布差异(各层级分布比值与整体分布比值之差),并进行加权和计算(对排名位置对数折扣化获得权重值),对加权和结果进行归一化作为评价值,计算方法如公式(5)所示:
(5)
该指标适用于受保护群体占少数的情况.
文献[26]根据机会均等公平性和统计均等公平性给出了Skew@k和归一化折扣累计KL散度(normalized discounted cumulative KL-divergence)两个公平性评价标准.一个理想的搜索结果或者推荐结果应当包含满足期望的受保护群组分布,这种期望的分布可以通过多种方式计算,包括但不限于遵守基线人口的相应分布、法律授权以及自愿承诺.提出的评价标准如下:
公平性评价标准5:
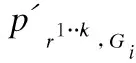
(6)
公平性评价标准6:
归一化折扣累计KL散度(NDKL):使用KL散度的方法来表示各层级中实际分布与期望分布的差异,再对各层级的分布差异进行加权和计算(对排名位置对数折扣化获得权重),最后,对加权和结果进行归一化,计算方法如公式(7)所示:
(7)
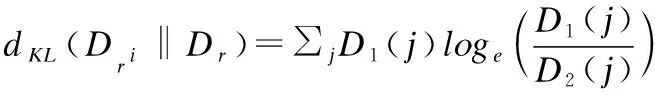
以上6个基于Top-k排序的公平性评价方法均针对各群组的排名分布衡量公平性,体现了排名位置(层级)越高的物品对公平性的评价越重要的思想,并且通过将各个层级中的分布与整体分布或期望分布做比较来评价公平性.
不同的是公平性评价标准1设计了受保护组物品的二项分布累积函数与受保护组物品数量的最小期望值,通过比较各层级二项分布累积函数值与最小期望值来评价Top-k排序的公平性;公平性价标准5选择有意义的k值计算该层级的实际分布比例与期望分布比例差异skew@k来评价公平性;公平性评价标准2,3,4,6分别计算各层级受保护组在不同的分布总体中的比例,与整体分布比例或期望分布比例比较,计算差异值,采用对排名位置对数折扣化作为权重,通过各层级差异值的加权和来评价Top-k排序的公平性,分布差异的计算方式也有所不同,本文对这4种公平性评价标准的分析与对比见表1.

表1 评价标准2,3,4,6的分析与对比Table 1 Analysis and comparison of evaluation standards 2,3,4,6
4.2 基于Top-k排名衍生量的公平性
本文在总结各种基于Top-k排名公平性的时候发现,仅仅讨论排名位置的公平性还是不够的.不同的曝光量往往会使得推荐系统为物品提供方带来的利益产生差异,曝光的有效性对最终结果的影响往往远远高于其他技术性因素[27].曝光量是由排名位置衍生而来的,排名高的位置获得的曝光量也大.因此,文献[28]提出了基于Top-k排名的衍生量公平性—基于曝光量的公平性.
由于物品的销量与曝光量直接相关,曝光程度的公平性对于物品提供者非常重要.文献[28]将候选物品曝光量的公平性定义为候选物品享有的曝光量不受物品群组特征的影响而减少或增加.
文献[28]指出公平的推荐系统不仅要保证推荐环境中各群组候选物品的平均曝光量相等,还应该保证与筛选条件强相关的物品排名位置高[29],获得该有的曝光量,使候选物品不会因群组特征而被恶意减少曝光量.因此,文献[28]提出应当在保证曝光量公平约束条件下使用概率排序原理(Probabilistic Ranking Principle)获得排序效用最大的排序,[28]从候选物品的群组比例、区别对待程度和经济效益三方面评价物品曝光量的公平性,给出了3个公平性约束:人口均等约束(Demographic Parity Constraints)、区别对待约束(Disparate Treatment Constraints)和区别影响约束(Disparate Impact Constraints).
曝光量在群组公平性中最直接的表现就是需要均衡分配曝光机会,因此文献[28]提出了人口均等公平性约束.对于一组排序,排序位置越高,对曝光量越重要,该位置所获得的曝光量就越大.对于查询q,候选物品wi排在第j位的概率为pi,j,位置j(j∈N)的重要性表示为vj,计算公式如公式(8)所示,在物品wi排序概率为P的条件下,物品wi曝光量为Exposure(wi|P),计算方法如公式(9)所示:
(8)
(9)
Gt群组内的平均曝光量表示为公式(10):
(10)
公平性评价标准7:
人口均等约束:在候选物品的排序列表中,受保护群组和非受保护群组的平均曝光量应当相等,如公式(11)所示:
Exposure(G0|P)=Exposure(G1|P)
(11)
文献[28]提出对于搜索平台,相关性的微小差异可能被放大,使得各群组的曝光量差异巨大.为了保证各推荐项目获得与其相关性大小相对应的曝光量[30],提出区别对待约束来保证各群组的曝光量与相关性成正例.文献[28]将各项目的平均相关性作为排序效用,使用区别对待率(Disparate Treatment Ratio)量化各群组曝光量受相关性影响的程度.使用表示排序的平均效用,ui表示候选物品wi的排序效用,针对查询q,各群组的平均效用表示方法如公式(12)所示:
(12)
其中,排序效用u可通过计算项目的平均相关性获得,项目w与查询q的相关性表示为λ(rel(w|q)),排序效用u的计算方法如公式(13)所示:
u(w|q)=∑a∈Aλ(rel(w|q))P(a|q)
(13)
公平性评价标准8:
区别对待约束:在候选物品的排序列表中,受保护群组和非受保护群组的平均曝光量与平均排序效用应如公式(14)所示成正比:
(14)
为量化各群组被区别对待程度的差异,用区别对待率(DTR)表示各群组平均曝光量与平均排序效用的比值差异,具体表示方法如公式(15)所示:
(15)
为继续探究各群组获得经济效益是否也存在不公平现象,文献[28]使用点击率作为评价经济效益的方法,提出用区别影响约束来保证由曝光量和相关性决定的点击率与平均效用成正比,从而保证各群组获得与其相关性大小相对应的经济效益,使用区别影响率(Disparate Impact Ratio)表示各群组获得的经济效益差异.CTR表示属性值为t的群组在排序概率P的条件下获得的平均经济效益(平均点击率),其计算方法如公式(16)所示:
(16)
公平性评价标准9:
区别影响约束:在候选物品的排序列表中,受保护群组和非受保护群组获得的平均经济效益与平均排序效用应如公式(17)所示成正比:
(17)
为量化各群组获得的经济效益差异,使用区别影响率(DIR)表示各群组所得的平均经济效益与平均排序效用的比值差异,其计算方法如公式(18)所示:
(18)
4.3 基于排序误差的公平性
基于误差的公平性要求预测模型对每组犯的“错误”程度都是同样的,它通过不同组的组内误差率来衡量,如真阳性率、真阴性率或分配到阳性类的概率[31].
文献[32]定义了3个基于排序误差的公平性评价标准:排序均等误差(Rank Equality Error)、排序校准误差(Rank Calibration Error)和排序等值误差(Rank Parity Error).
公平性评价标准10:
排序均等误差:Gi组中成员被错误地排在Gj组中成员之上的次数为排序同等误差,然后用混合对的总数对误差进行归一化.公平的推荐系统应当满足受保护群组和非受保护群组的排序成对误差相等.φ(*)表示对数,φD表示错误排序对数,排序成对误差表示方法如公式(19)所示:
(19)
公平性评价标准11:
排序校准误差:至少包含一个Gi组成员的错误排序对即为Gi组的排序校准误差.再用包含Gi组成员的总对数对误差进行归一化,计算方法如公式(20)所示:
(20)
公平性评价标准12:
排序等值误差:Gi组成员排在Gj组成员之上的次数φi>j(I),然后用混合对的总数对误差进行归一化,计算方法如公式(21)所示:
(21)
基于排序误差对公平性进行衡量比较直接,但是它没有反应不同位置影响的差别,也没有反应错误的程度,比如,在正确情形下A比B排名高,那么在实际结果中B比A高一个位次,或者B比A高五个位次,两者错误的程度显然是不一样的.
4.4 基于因果图的公平性
文献[33]提出某些偏见可以由一些非敏感属性来解释,因此文献[33]使用因果图对偏见进行判别:将排名位置映射为候选物品质量的连续分数变量,建立因果图,该图中的数据由离散属性和连续得分组成,将路径特异效应技术推广到混合变量因果图中,通过设置阈值实现对直接偏见和间接偏见的识别.
在给定因果图中,X表示属性,x表示属性X对应的属性值,Y表示结果,y表示结果值.Pa(Y)表示结果的父节点.对于扰动δx=x,通过比较两种不同措施do(x′)和do(x″)干预后的分布差异来评估X对Y的总因果效应.总因果效应的一个常见度量是预期差异,即给定一个因果图H=(V,A),两个不相邻的变量X,Y⊆V,在两个干预do(x′)和do(x″)作用下,X在Y上的总因果效应表示为TE(x′,x″).文献[33]通过使用Bradley-Terry模型[34]将排名映射为分数后,为变量G(受保护属性),Z(非受保护属性)和S(分数)建立因果图,学习因果图的结构,获得期望值[·],总因果效应可通过公式(22)计算获得.
TE(x′,x″)=[·][Y|do(x′)]-[·][Y|do(x″)]
(22)
作为对总因果效应的扩展,Avin等人[35]提出了特定路径效应,该效应测量了干预效应沿X到Y因果路径子集传递的因果效应.用π表示因果路径的子集,干预效应沿π传递.
文献[33]定义特定路径效应为SEπ(x′,x″),对于给定一个因果图H=(V,A),两个不相邻的变量X,Y⊆V,和一个因果路径子集π,do(x′)和do(x″)表示特定路径效应π的两个干扰项,SEπ(x′,x″)表示方法见公式(23):
SEπ(x′,x″)=[·][Y|do(x″)]
(23)
总体因果效应通常不能正确地衡量直接偏见或间接偏见,应将其建模为特定路径效应.在形式上,定义πd为只包含受保护属性G→S(分数结果)的路径集.从G-S途径其他节点,定义πi为包含除去G→S直接路径集的所有因果路径的路径集.使用πd的特定路径效应SEπd(·)可以捕捉到直接偏见,πi的特定路径效应SEπi(·)捕捉间接偏见.文献[33]提出并证明间接偏见效应等于总因果效应加上“反向”的直接偏见效应,如公式(24)所示:
SEπi(x′,x″)=TE(x′,x″)+SEπd(x′,x″)
(24)
公平性评价标准13:
基于以上直接偏见和间接偏见的获取方法,文献[33]设置阈值(例如平等与人权委员会 (EHRC)认为0.05是男女性别薪酬差距的重要阈值)与直接偏见效应和间接偏见效应比较,对排序是否存在偏见进行判断.由于SEπd(G0,G1)和SEπi(G0,G1)的值可以是任意大的,文献针对相对差异DEi,DEd(即特定路径效应与非受保护组期望得分的比值,计算方法如公式(25)、(26)所示),给出了直接偏见和间接偏见的评价标准.
(25)
(26)
给定阈值τ,若受保护群组与非受保护群组的相对特定路径效应差异DEd(G1,G0)>τ或DEd(G1,G0)>τ,则认为排序中存在直接偏见;若DEi(G1,G0)>τ或DEi(G1,G0)>τ,则认为排序存在间接偏见.
通过统计均等等评价方法判断公平性,再对不公平的排序进行重排序可能导致新的排序对非敏感属性中的部分群组存在偏见,从而产生新的不公平排序.因此,文献[33]通过使用公平性评价标准13对直接偏见和间接偏见同时进行识别,再对有偏见的排序数据进行修改或重排,从而获得公平的排序数据.
4.5 个性化推荐中物品提供方的公平性
个性化推荐考虑了用户的偏好,给每个用户提供的推荐结果可能是不一样的.文献[36]假定检索系统和排序系统的级联推荐系统给用户推荐个性化Top-k项目,检索系统从总候选集I中的N个项目里,筛出N′个项目的集合R.排序模型对N个项目打分,然后返回Top-k个项目,这里聚焦于排序模块.
排序器通过训练模型以预测用户的行为,再通过一个单调评分函数产生最终排序,向用户显示Top-k个项目.文献[36]提出了基于成对公平性的3个评价指标.
公平性评价标准14:
成对公平性:对于使用排序公式g的模型f,如果在物品被交互次数z相同的情况下,比较对c(j,j′)中,各群组中被点击的物品wj排在另一个未被点击物品wj′之前的可能性是相同的,则被认为满足成对公平性.此定义为我们提供了每个组中物品排名准确率的总体概念,如公式(27)所示:
(27)
公平性评价标准15:
组内成对公平性:对于使用排序公式g的模型f,如果在物品被交互程度相同的情况下,两个群组里各自内部中点击的物品排在另一个未点击物品之前的可能性是相同的,则被认为满足组内公平性,如公式(28)所示:
(28)
公平性评价标准16:
组间成对公平性:对于使用排序公式g的模型f,如果在物品被交互程度相同的情况下,两个群组中,一个群组中点击的物品排在另一个群组中未点击物品之前的可能性是相同的,则被认为满足组间成对公平性,如公式(29)所示:
(29)
将成对比较分为两种情况,即组内和组间比较,并且整体成对准确率是组间成对准确率和组内成对准确率的加权和,通过相应的点击和参与看到组间和组内成对的概率来确定权重值.
5 用户公平性
从用户的角度,推荐系统公平性关注的是在现实中不同的用户或用户组得到的推荐质量可能会有系统性的差别,或者他们得到的推荐在推荐项目的类型上有系统性的差别[37].
5.1 基于评分误差的用户公平性
评分预测是通过已知的用户历史评分记录预测未知的用户评分,文献[38,39]对用户在协同过滤算法中的评分预测误差提出了公平性评价方法.
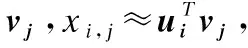
对于每个个体用户ai,使用均方估算误差作为个体损失li,使用Ω表示评分矩阵X中的索引集合.Ωj表示对物品wj进行评分的用户集合,Ωi表示用户ai评分过的物品评分集合.个体损失li的计算方法如公式(30)所示:
(30)
公平性评价标准17:
评分误差个体公平性:通过计算用户个体损失的平方差获得用户评分误差的不一致程度,从而衡量系统对用户个体的不公平程度.其计算方法如公式(31)所示:
(31)
类似地,可以将用户分为g个群组,同样采用均方估算误差计算群组Gi的损失函数Li,计算方法如公式(32)所示:
(32)
公平性评价标准18:
评分误差群组公平性:通过计算各用户群组损失的平方差获得各用户群组评分误差的不一致程度,从而衡量系统对各用户群组的不公平程度.计算方法如公式(33)所示:
(33)
文献[39]中分析了矩阵分解方法在应用中会导致的问题:人口学比例不平衡和观察偏差.这两种问题都会使系统给用户的推荐产生不公平现象.
1)人口学比例不均衡问题是由于各群组在数据集中出现的频率差异产生的.由于系统偏见或其他社会问题,使受保护群组中接受推荐的人数比不接受推荐的人数要少得多,而在非受保护群组中,接受推荐的人数可能比那些不接受推荐的人数多得多,从而使得受保护群组和非受保护群组中分别产生接受推荐的群体和不接受推荐的群体比例差异巨大,这种现象也被称之为“四相分离”.在这种情况下,推荐系统对受保护群组会给出带有偏见的推荐结果.
2)观察偏差是由于用户可能对不同类型的物品有不同的评分倾向产生的.如果系统从来没有对受保护群组推荐某类别物品,他们可能永远不会接触这类物品,算法也无法直接了解这种偏好.例如在一些理工科课程推荐中,如果很少推荐女性参加这些课程,那么这些课程中女性的培训数据可能会很少.
对于以上两种现象使推荐系统对用户的推荐产生不公平的情况,文献[39]提出了4个公平性评价标准,用来评价用户评分预测中不公平程度.
公平性评价标准19:
数值不公平性(value unfairness )Vval:衡量物品wj在用户受保护群组和非受保护群组中的预测评分均值与真实评分均值之间误差的不一致程度.计算方法如公式(34)所示:
(34)
在用户ai对物品wj的评分矩阵X中,物品wj在各群组的评分均值计算方法如公式(35)所示:
(35)
公平性评价标准20:
绝对不公平性(absolute unfairness ):用来衡量物品wj在各群组中的预测评分均值与真实评分均值之间误差的绝对不一致性程度.计算方法如公式(36)所示:
(36)
公平性评价标准21:
低估不公平(underestimation unfairness):用于衡量物品在各群组中预测评分均值低于真实评分均值的情况.取各群组中预测评分被低估程度的最大值,用来评价受保护群组和非受保护群组预测评分被低估的不一致程度.计算方法如公式(37)所示:
(37)
公平性评价标准22:
高估不公平(overestimation unfairness ):用于衡量物品在各群组中预测评分均值高于真实评分均值的情况.取各群组预测评分被高估程度的最大值,用来比较受保护群组和非受保护群组预测评分被高估的不一致性程度.计算方法如公式(38)所示:
(38)
文献[39]通过比较各群组预测评分均值与真实评分均值的差值来评价各群组评分误差的不公平性,而文献[38]采用MSE的误差计算方式对用户的预测评分与真实评分的误差进行衡量,将评分误差作为用户损失,公平性评价标准采用对用户损失使用方差的形式计算不公平程度.对于评分预测的误差计算,常见的度量函数方差、RMSE、MSE和MAPE等误差形式.因此,本文认为对于用户损失(评分误差)的计算与公平性评价标准的计算,不仅可以使用方差与MSE的组合方式,还可以尝试对其他评分预测的误差计算方式进行组合来获取最合适的基于评分误差的公平性评价标准.
5.2 基于排序误差的用户公平性
对于不同用户,推荐系统为用户推荐的推荐质量可能存在不一致的现象,即各用户的推荐列表存在排序误差差异大的问题,导致一些群体或个体无法较准确地获得需要的物品.例如文献[40]提出传统的推荐系统可能会为参与更多交互的活跃用户提供更好的推荐性能,而不太活跃的用户最终可能无法享受相同的推荐体验.在某种程度上,这可能源于缺乏相关的用户-物品交互历史来准确地揭示用户偏好,最终导致不活跃用户推荐质量远不如活跃用户.对此,文献[40]从个体层面和群组层面分别提出了公平性评价标准,用于衡量不同用户存在不同推荐质量的不公平问题.
对于用户来说,最直观的质量要求是更喜欢的项目应该有更高的概率出现在推荐中,累计增益(Cumulative Gain)只需将用户对推荐列表中所有项目的偏好分数相加,即可获得用户对推荐结果的满意度[41,42].文献[40]采用NDCG的评价方法对Top-k排序的物品进行效用度量.
公平性评价标准23:
排序误差群组公平性:使用平均排序效用差异来度量系统对不同用户群组推荐的物品质量差异,使用公式(39)对排序效用进行衡量,计算方法如公式(40)所示:
U=NDCG@k
(39)
(40)
对于用户个体层面,文献[40]引用了基尼系数[43]来量化个体推荐质量的不公平程度,它的范围从0-1,其中1代表最大的不公平,而0代表完全平等.
公平性评价标准24:
排序误差个体公平性:对于任意两个不同的用户个体ax和ay,使用基尼系数计算个体推荐质量差异,计算方法如公式(41)所示:
(41)
5.3 面向类别的用户公平性
面向类别的用户公平性主要是指系统向具有多种类别的用户推荐也具有多种类别的物品时,系统推荐的物品类别是否满足所有类别用户的需要与偏好,对于喜爱同一类别物品的不同类别用户,系统是否会因用户类别而对用户区别推荐.
对于多类别物品的推荐系统,用户希望高频率看到自己需要的或喜爱的种类,喜欢相同种类的用户不会因为用户属性而被区别对待.因此,文献[44]从个体公平性和无嫉妒(envy-freeness)[45,46]中得到启发,提出了类间无嫉妒 (Inter-Category Envy-Freeness)公平性、总变动公平性(Total Variation Fairness)和组合公平性(Compositional Fairness).个体公平性要求相似的用户得到相似的对待[47],无论个人喜好如何,优先考虑是否会因个人属性而区别对待.无嫉妒要求每个用户更喜欢自己的分配,而不是其他人的,即算法中不考虑个人属性,而优先考虑个人喜好问题.
文献[44]中提出允许用户可以自主选择自己喜爱的物品类别,对于用户喜爱的物品类别,系统以较高的概率使用户可以看到,并且要求选择相同种类的相似用户看到的物品也相似.该文中总结出了以下3个条件保证推荐的公平性:
1)在选择的类别中,不仅要使用户获得一个接近于其他相似用户的分配,而且要得到一个和其他人一样好或更好的分配以满足个人的偏好.
2)对于非选择类别,不设置任何公平保障.因为从用户的角度来看,其他类别并不重要(无嫉妒).
3)虽然定义专注于每个用户的单次推荐,但可以设想这样一个系统,用户与平台的多次交互可以在每次交互中改变他们的首选类别,从而在每次个人交互中获得某一类别内的公平分配.
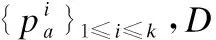
1)个体公平性:用户ax,ay∈I获得的结果分布为f(ax),f(ay),当所有用户都满足D(f(ax),f(ay))≤d(ax,ay),该分布满足个体公平性.
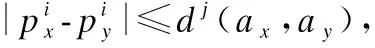
仅使用多任务公平性保证推荐物品类别内的用户公平性会存在两个漏洞:
1)故意不公平,一个物品提供商假装多个提供商对用户进行投标,会导致所有子结果差异之和等于个体差异之和.因此提供商可能会把个体获得的概率差异放大,导致不公平.
2)无意的不公平,一个提供商对用户ax,ay投放多个高质量物品,每个物品也可能对两个个体投标有很大差异,但个体相似度差异小.
文献[44]提出总变动公平性评价标准保证单一物品类别内的用户公平性.
公平性评价标准25:
总变动公平性:要求对于选择同一种物品的用户,概率分配向量不仅在物品组成上相似,还要在总的分配概率结果上相似,方法表示如公式(42)和公式(43)所示:
(42)
‖px-py‖1≤d(ax,ay)
(43)
对于多种物品类别间的公平性,文献[44]假设用户最喜爱自己所选的物品种类,而不对其他种类感兴趣.因此,提出了类间无嫉妒公平性评价标准保证多种物品类别间用户公平性.
公平性评价标准26:

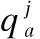
(44)
公平性评价标准27:
文献[44]使用无嫉妒和个体公平性的概念评价用户公平性,为面向类别的用户公平性提供了重要的研究方向.但[44]中仅考虑到用户个体层面的公平性,还未考虑用户群组层面上的公平性.我们还可以从用户群组层面考虑多类别用户面向多类别物品时的用户公平性,要求系统推荐满足各用户群组对物品类别的偏好与需求,喜爱同一类别物品的多类别用户不会因用户类别而被区别对待.再对类间公平性和类内公平性进行组合,从而获得多类别用户面向多类别物品时应满足的公平性要求.
6 其他利益相关方公平性
对于其他利益相关方的推荐公平性,文献[37]提出应当更多地从其他利益相关方的需求、喜好以及利益方面考虑公平性,使系统能够公平对待相关方的需求、喜好和利益.例如美团外卖平台就是一个多方利益相关方的软件,包括商家、消费者、平台和外卖骑手四方.
文献[49,50]提出平台位于框架的中心,调解物品提供者和用户之间的交易,并从本质上决定物品提供者收入的分配和用户体验的质量,进而通过某种方式从中获益.作为涉及到物品提供方和用户方以外的其他利益相关方的平台,在对用户进行推荐的同时,怎样保证平台利润在合理的范围内最大化?高收益物品给平台带来的利润高,但长时间高频率地对用户强行推荐高收益的物品,可能会导致用户的反感,使用户离开该系统,从而使平台的长期利益受损.相关性强但收益低的物品会使用户接受推荐的可能性更大,进而增加成交量,也会使利润增加.同时,不被推荐的物品提供方(商家)可能会由于用户的参与度低而退出平台.因此,平台的健康取决于用户和感兴趣的项目列表[17,37],平台收益合理地最大化需要平衡高利润物品与强相关性物品之间的关系.
外卖骑手是美团外卖应用程序的另一重要利益相关方,外卖骑手在商家和消费者之间往返,如何降低骑手之间的收益不平衡,同时使用户和商家的等待时间最短是保证骑手方公平性的一个重要方面,系统在向骑手分配订单的时候需要对骑手所在区域、距离、工作负荷等方面进行平衡.
因此,本文认为在多利益相关方的平台中,在保证用户和物品提供方的公平性的同时,保证其他利益相关方获得相对公平的收益也是推荐系统公平性研究的一个重要方向.
7 分析与展望
上述的分析总结如表2所示.
针对物品提供方公平性评价标准的分析与展望如下:
对于物品提供方,基于Top-k排名及其衍生量的公平性评价标准大多使用不同的分布函数对Top-k物品的分布进行统计计算,通过比较群组间的分布差异来评价排序的公平性;基于排序误差的公平性通过比较群组间预测模型排序的误差率来评价排序的公平性;基于因果图的公平性通过比较相同干扰下,群组间的路径效应差异来评价排序的公平性;个性化推荐系统的公平性通过比较群组间物品点击概率与物品排名之间的匹配度差异来评价排序的公平性.
基于以上对物品提供方公平性评价标准的分析与总结可以看出,物品提供方的公平性评价标准的侧重点各不相同.本文认为物品提供方的公平性评价标准可以继续进行改进,在到达一定程度统一的同时,使公平性评价标准的接受性更高.
排名位置对物品提供方来说至关重要,为不同位置赋予不同的权值是对物品提供方的公平性评价的一个重要方法.因此,本文认为可以将Top-k排序公平性与其他应用场景的公平性相结合获得更加统一并能被广泛使用的公平性评价标准.例如,基于排序误差的公平性评价标准10,11,12并没有对不同位置的排名错误赋予不同的影响力,可以将排序错误与Top-k排序公平性相结合,从而获得更加合理并与其他评价方法相对统一的公平性评价标准.
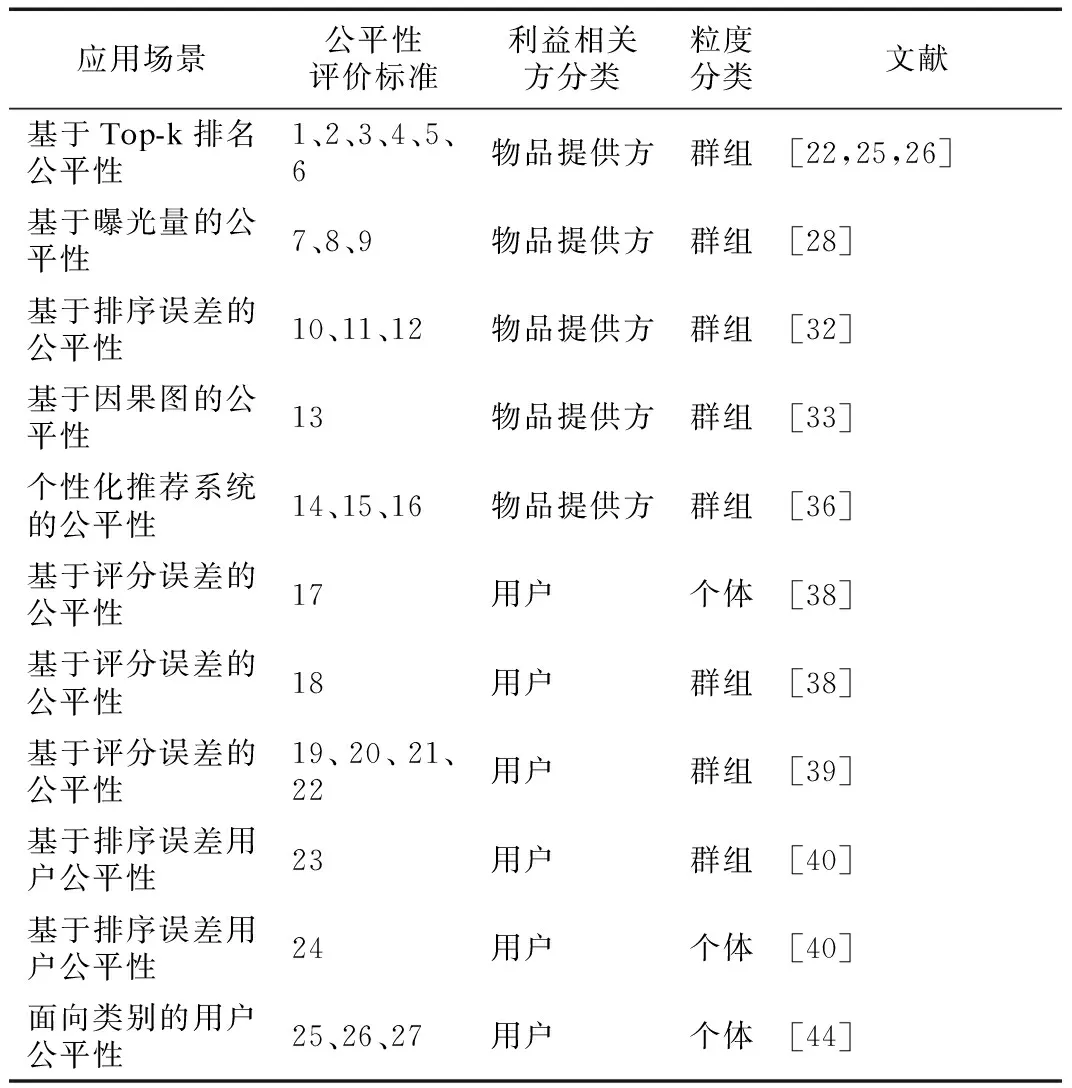
表2 公平性评价标准的分类Table 2 Classification of fairness evaluation standards
众多物品提供方公平性研究的关注点在于设定评价标准判断推荐物品列表是否公平,再对不公平列表重排得到符合标准的列表.但这些研究并没有考虑重排是否会导致其他非敏感属性的不公平,文献[33]使用因果图判断推荐列表中存在的直接偏见与间接偏见为研究对重排产生的非敏感属性不公平的问题提供了重要方向.
针对推荐物品接收方公平性评价标准的分析与展望如下:
物品接收方的公平性评价标准主要通过比较用户群组或个体间的评分预测误差差异与排序列表质量差异来评价物品接收方公平性,公平性评价方法的接受度比较高,但也比较单一.
评分误差的度量方法有方差、RMSE、MSE和MAP等,但鲜有文献对基于评分误差的用户公平性评价方法使用除MSE以外的评价方法度量公平性.因此,本文认为可以类比评分误差的度量方法,使用其他形式的误差评价函数对评分误差公平性进行度量.
面向类别的用户公平性为物品接收方的公平性评价标准提供了新的应用场景和研究方向,即为用户喜爱的物品分配较高概率的同时,保证选择同类别物品的用户个体获得的推荐结果相似.本文认为可以以面向类别的用户公平性评价方法为方向,从以下几个方面进一步研究用户公平性评价方法:
1)从用户群组层面进一步研究面向类别的用户公平性.
2)以用户偏好为方向研究用户公平性评价方法.
针对用户喜爱的物品类别或用户无感的物品类别设计相关的公平性评价指标.
对于其他利益相关方的公平性,研究成果较少.本文认为怎样有效保证推荐系统中的非用户及非候选物品的其他利益相关方的公平性,以及对于包含多方利益方的应用平台,怎样保证多方的公平性需要得到更多的关注和研究.
推荐系统本身是一个动态的社会技术系统,需要考虑到方方面面的因素,这就造成了推荐系统公平性衡量的复杂性.本文从多个维度对推荐系统公平性进行分类,每个维度的分类也有各种应用场景,每种应用场景的公平性评价标准也是多样的,从而导致推荐系统公平性的评价标准难以统一.因此,怎样将各种推荐系统公平性的评价标准联系在一起,使推荐系统公平性的评价方法达到一定的统一或者普遍的接受性需要进一步研究.
8 总 结
本文结合近几年的推荐系统公平性研究,重点从推荐信息的接收方(用户)、物品提供者和其他利益相关方3个方面对推荐系统的公平性评价方法进行了总结.可以看出,目前推荐系统的公平性方法呈现出多样化的特点,这一方面是因为公平性是一种社会主观准则,不同的利益主体可以有自己的利益需求和衡量方法;另一方面,这也是由该领域目前还处于研究阶段的早期决定的.为了推进该领域的工作,有必要建立几条公认的评价方法,从而促进公平性算法的研究,另一方面也可以深入探讨好的公平性评价应该具备的特点或特性,从而可以对公平性评价标准本身也进行评价.
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
福建基础教育研究(2019年6期)2019-05-28
小天使·一年级语数英综合(2019年2期)2019-01-10
计算机应用(2016年10期)2017-05-12
中小企业管理与科技·上旬刊(2016年12期)2017-01-05
