
基于python对地摊经济信息的获取与分析
2022-03-04 12:51丁建霞王志鹏
科教导刊·电子版 2022年2期
丁建霞 王志鹏
(南阳师范学院物理与电子工程学院 河南·南阳 473061)
0 引言
在公共卫生事件面前,全国经济遭到了重创,地摊经济在一定程度上使全国的经济得到了回暖。为让经济有更快速的回升,利用Python在互联网上爬取与地摊经济有关的数据信息[1],进一步推动地摊经济的发展与全国经济的回温,更进一步向大众普及了python语言的使用,同时也在一定程度上推动了互联网的发展。
网络爬虫,也称为网络机器人[2],是一种按照一定的规则,自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL[3],在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
1 软件设计与实现
在python爬虫当中,每个python运行成功之后都有源代码和生成的目标文件组成:源代码包含了所有要执行的命令,只要语法和逻辑上均没有报错,目标文件就能生成我们所需要的东西。此项目需要获取到的是对影响“地摊经济”的因素,详细分析代码过程如下[4]:
(1)python库的引用。Python语言简洁的原因是它能调用多个库,库里面已经为使用者定义并写好了很多的所需要的东西,使用者只需明白其库的作用就能直接使用。此次编码用到的库如下:requests库,BeautifulSoup库和os库均为第三方导入的库,request库用于接口测试,可以节约使用者的大量工作,并满足http测试的需要;Beautiful-Soup库可以配合requests库的需要写爬虫[3];os库可方便把从网上搜索到的内容写入到文本中。

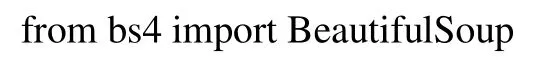
(2)要从互联网上大量获取与地摊经济有关的信息,需要爬取的大量的网站,此时需要用到每个网站的url地址,例如:
(3)在网络爬取信息的过程中,因为网站有robots协议,当访问太多时容易触发防控机制会禁止继续访问,此时为顺利访问网页,需要编写请求头:

(4)利用上面的请求头,用get进行访问。因访问过程容易出现乱码,需要解码换回能看懂的中文字符。

(5)对每个网页的标题进行提取,需要用到此网站的标题行的“选择器”,这样可以从大方向上查看我们所爬取到的信息是否正确,并试运行查看代码是否有出错。此时如果没有出错可继续进行接下来的代码编写,若语法出错则查看报错的点是什么,对该处进行修改;若逻辑方面出错则需重新整理思路。

(6)此时需要再写一个对网页内容进行爬取的代码即可,提取方式与上述相同。

(7)把爬取到的内容写入并保存到文本中

2 爬取结果分析与总结
通过对互联网上多个网页的内容爬取,以下展示爬取到的部分结果(为方便查看,对结果的格式稍作了整理)。如图1所示。

图1:爬取内容
为分析爬取到的内容,利用python的wordcloud对爬取到的做数据了词云图,出现的次数越多,字体的规格显示就会越大,表示出现的频率就越高,说明对于“地摊经济”的影响来说,这个因素的影响力越大。如图2所示。

图2:爬取内容词云图
3 结语
本文通过分析与地摊经济相关的网页结构,利用python语言及其强大的第三方库编写代码,获取其中影响地摊经济的数据信息,把信息进行整理及分析,并制作可视化词云图以方便查看,有效地降低了用户的时间成本并提供了参考意见。不足之处为只能获取单个网站的信息,在未来的工作中将把重点放在同时进行多个数据源的信息的获取,以获得更多更全的信息。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
中国农资(2019年44期)2019-12-03
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
名家名作(2017年3期)2017-09-15
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
光学精密工程(2016年4期)2016-11-07
电子测试(2015年18期)2016-01-14
